Configuración de puntos de conexión de flujo de datos de Azure Event Hubs y Kafka
Importante
En esta página se incluyen instrucciones para administrar componentes de Operaciones de IoT de Azure mediante manifiestos de implementación de Kubernetes, que se encuentra en versión preliminar. Esta característica se proporciona con varias limitacionesy no se debe usar para cargas de trabajo de producción.
Consulte Términos de uso complementarios para las versiones preliminares de Microsoft Azure para conocer los términos legales que se aplican a las características de Azure que se encuentran en la versión beta, en versión preliminar o que todavía no se han publicado para que estén disponibles con carácter general.
Para configurar la comunicación bidireccional entre los agentes de Operaciones de IoT de Azure y Apache Kafka, puede configurar un punto de conexión de flujo de datos. Esta configuración le permite especificar el punto de conexión, la seguridad de la capa de transporte (TLS), la autenticación y otras opciones.
Requisitos previos
- Una instancia de Operaciones de IoT de Azure
Azure Event Hubs
Azure Event Hubs es compatible con el protocolo Kafka y se puede usar con flujos de datos con algunas limitaciones.
Creación de un espacio de nombres de Azure Event Hubs y un centro de eventos
Primero, cree un espacio de nombres de Azure Event Hubs habilitado para Kafka
Luego, cree un centro de eventos en el espacio de nombres. Cada centro de eventos individual corresponde a un tema de Kafka. Puede crear varios centros de eventos en el mismo espacio de nombres para representar varios temas de Kafka.
Asignación de permisos a la identidad administrada
Para configurar un punto de conexión de flujo de datos para Azure Event Hubs, se recomienda usar una identidad administrada asignada por el usuario o asignada por el sistema. Este enfoque es seguro y elimina la necesidad de administrar las credenciales manualmente.
Una vez creado el espacio de nombres y el centro de eventos de Azure Event Hubs, debe asignar un rol a la identidad administrada de Operaciones de IoT de Azure que conceda permisos para enviar o recibir mensajes al centro de eventos.
Si usa la identidad administrada asignada por el sistema, en Azure Portal, vaya a la instancia de Operaciones de IoT de Azure y seleccione Información general. Copie el nombre de la extensión que se muestra después de la extensión de Arc de Operaciones de IoT de Azure. Por ejemplo, azure-iot-operations-xxxx7. La identidad administrada asignada por el sistema se puede encontrar con el mismo nombre de la extensión de Arc de Operaciones de IoT de Azure.
A continuación, vaya al espacio de nombres de Event Hubs >Control de acceso (IAM)>Agregar asignación de roles.
- En la pestaña Rol, seleccione un rol adecuado, como
Azure Event Hubs Data SenderoAzure Event Hubs Data Receiver. Esto proporciona a la identidad administrada los permisos necesarios para enviar o recibir mensajes para todos los centros de eventos del espacio de nombres. Para más información, consulte Autenticación de una aplicación con Microsoft Entra ID para acceder a los recursos de Event Hubs. - En la pestaña Miembros:
- Si usa la identidad administrada asignada por el sistema, para Asignar acceso a, seleccione la opción Usuario, grupo o entidad de servicio, seleccione + Seleccionar miembros y busque el nombre de la extensión de Arc de Operaciones de IoT de Azure.
- Si usa la identidad administrada asignada por el usuario, para Asignar acceso a, seleccione la opción Identidad administrada, seleccione + Seleccionar miembros y busque la identidad administrada asignada por el usuario configurada para conexiones en la nube.
Creación de un punto de conexión de flujo de datos para Azure Event Hubs
Una vez configurado el espacio de nombres y el centro de eventos de Azure Event Hubs, puede crear un punto de conexión de flujo de datos para el espacio de nombres de Azure Event Hubs habilitado para Kafka.
En la experiencia de operaciones, seleccione la pestaña Puntos de conexión de flujo de datos.
En Crear nuevo punto de conexión de flujo de datos, seleccione Azure Event Hubs>Nuevo.
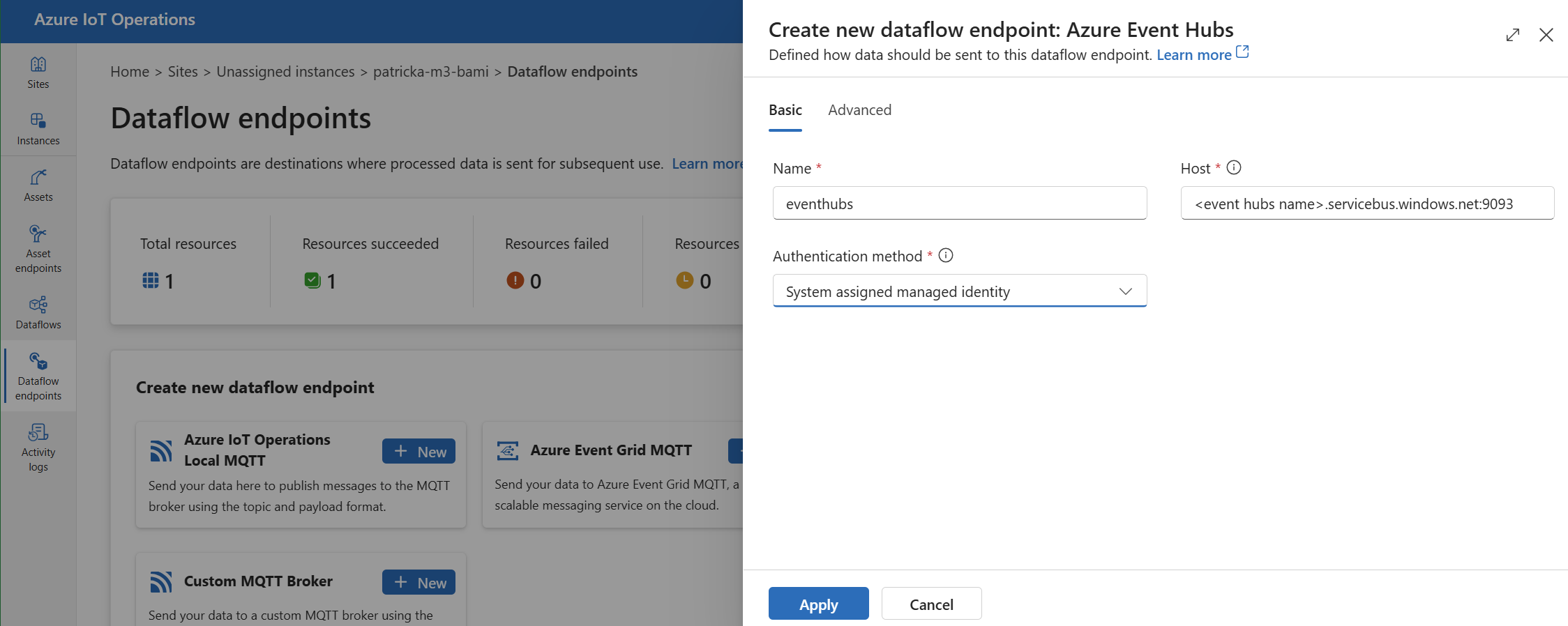
Escriba la siguiente configuración para el punto de conexión:
Configuración Descripción Nombre Nombre del punto de conexión del flujo de datos. Host Nombre de host del agente de Kafka con el formato <NAMESPACE>.servicebus.windows.net:9093. Incluya el número de puerto9093en la configuración de host para Event Hubs.Método de autenticación El método usado para la autenticación. Se recomienda elegir Identidad administrada asignada por el sistema o Identidad administrada asignada por el usuario. Seleccione Aplicar para aprovisionar el punto de conexión.
Nota:
El tema de Kafka, o centro de eventos individual, se configura más adelante al crear el flujo de datos. El tema de Kafka es el destino de los mensajes de flujo de datos.
Uso de la cadena de conexión para la autenticación en Event Hubs
Importante
Para usar el portal de la experiencia de operaciones para administrar secretos,Operaciones de IoT de Azure debe habilitarse primero con la configuración segura mediante la configuración de una instancia de Azure Key Vault y la habilitación de identidades de carga de trabajo. Para obtener más información, consulte Habilitación de la configuración segura en la implementación de Operaciones de IoT de Azure.
En la página de configuración del punto de conexión del flujo de datos de experiencia de operaciones, seleccione la pestaña Básico y, después, elija Método de autenticación>SASL.
Escriba la siguiente configuración para el punto de conexión:
| Configuración | Descripción |
|---|---|
| Tipo SASL | Elija Plain. |
| Nombre del secreto sincronizado | Escriba el nombre del secreto de Kubernetes que contiene la cadena de conexión. |
| Referencia de nombre de usuario del secreto de token | Referencia al nombre de usuario o al secreto de token que se usa para la autenticación SASL. Selecciónelo de la lista de Key Vault o cree uno nuevo. El valor tiene que ser $ConnectionString. |
| Referencia de contraseña del secreto de token | Referencia a la contraseña o al secreto de token que se usa para la autenticación SASL. Selecciónelo de la lista de Key Vault o cree uno nuevo. El valor debe tener el formato Endpoint=sb://<NAMESPACE>.servicebus.windows.net/;SharedAccessKeyName=<KEY-NAME>;SharedAccessKey=<KEY>. |
Después de seleccionar Agregar referencia, si selecciona Crear nuevo, escriba la siguiente configuración:
| Configuración | Descripción |
|---|---|
| Nombre del secreto | Nombre del secreto en Azure Key Vault. Elija un nombre que sea fácil de recordar para seleccionar el secreto más adelante en la lista. |
| Valor secreto | Para el nombre de usuario, escriba $ConnectionString. Para la contraseña, escriba la cadena de conexión con el formato Endpoint=sb://<NAMESPACE>.servicebus.windows.net/;SharedAccessKeyName=<KEY-NAME>;SharedAccessKey=<KEY>. |
| Establecer fecha de activación | Si está activado, la fecha en la que se activa el secreto. |
| Establecimiento de la fecha de expiración | Si está activado, la fecha en la que expira el secreto. |
Para más información sobre los secretos, vea Creación y administración de secretos en Operaciones de IoT de Azure.
Limitaciones
Azure Event Hubs no admite todos los tipos de compresión que Kafka admite. Actualmente solo se admite la compresión GZIP en Azure Event Hubs premium y niveles dedicados. El uso de otros tipos de compresión podría producir errores.
Agentes Kafka personalizados
Para configurar un punto de conexión de flujo de datos para agentes de Kafka que no sean de Event-Hub, establezca el host, TLS, autenticación y otras opciones según sea necesario.
En la experiencia de operaciones, seleccione la pestaña Puntos de conexión de flujo de datos.
En Crear nuevo punto de conexión de flujo de datos, seleccione Agente de Kafka personalizado>Nuevo.
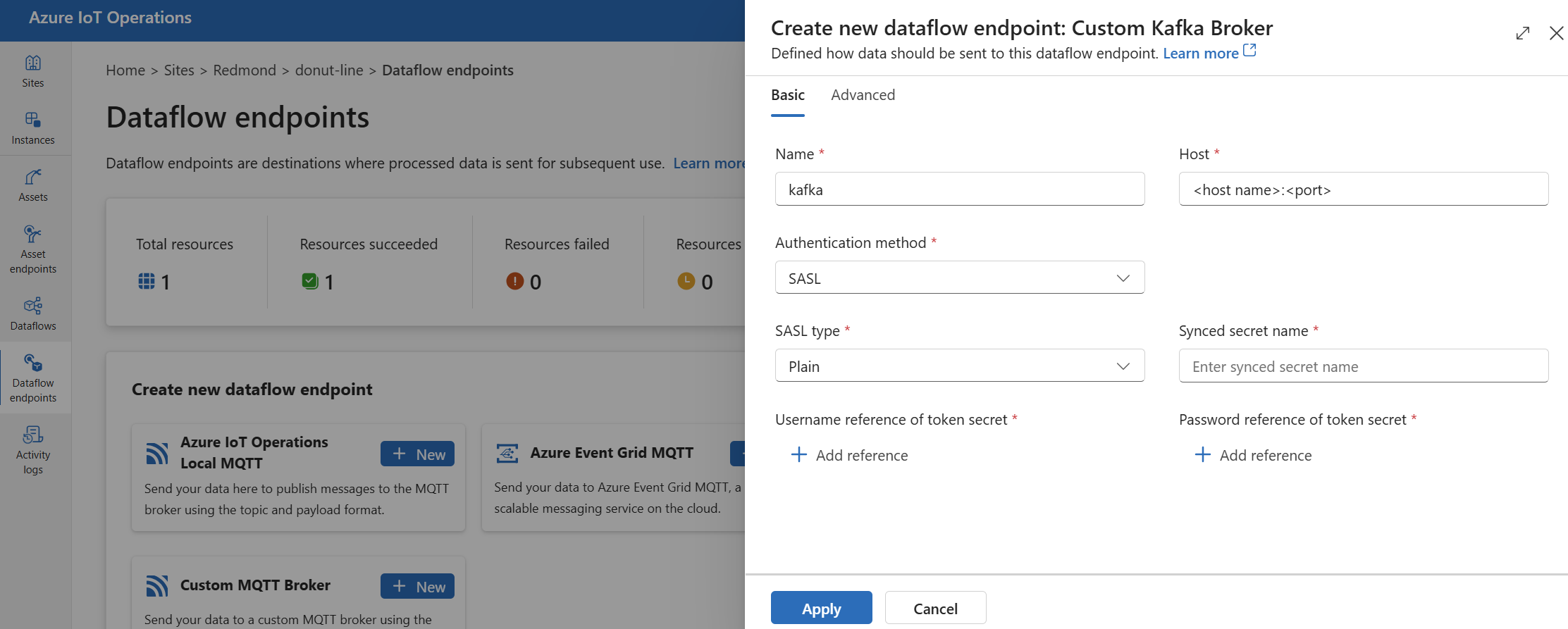
Escriba la siguiente configuración para el punto de conexión:
Configuración Descripción Nombre Nombre del punto de conexión del flujo de datos. Host Nombre de host del agente de Kafka con el formato <Kafka-broker-host>:xxxx. Incluya el número de puerto en la configuración del host.Método de autenticación El método usado para la autenticación. Elija SASL. Tipo SASL El tipo de autenticación SASL. Elija Plain, ScramSha256 o ScramSha512. Obligatorio si usa SASL. Nombre del secreto sincronizado Nombre del secreto. Obligatorio si usa SASL. Referencia de nombre de usuario del secreto de token Referencia al nombre de usuario en el secreto del token de SASL. Obligatorio si usa SASL. Seleccione Aplicar para aprovisionar el punto de conexión.
Nota:
Actualmente, la experiencia de operaciones no admite el uso de un punto de conexión de flujo de datos de Kafka como origen. Puede crear un flujo de datos con un punto de conexión de flujo de datos de Kafka de origen mediante Kubernetes o Bicep.
Para personalizar la configuración del punto de conexión, use las secciones siguientes para obtener más información.
Métodos de autenticación disponibles
Los siguientes métodos de autenticación están disponibles para los puntos de conexión de flujo de datos del agente de Kafka.
Identidad administrada asignada por el sistema
Antes de configurar el punto de conexión de flujo de datos, asigne un rol a la identidad administrada de Operaciones de IoT de Azure que conceda permiso para conectarse al agente de Kafka:
- En Azure Portal, vaya a la instancia de Operaciones de IoT de Azure y seleccione Información general.
- Copie el nombre de la extensión que se muestra después de la extensión de Arc de Operaciones de IoT de Azure. Por ejemplo, azure-iot-operations-xxxx7.
- Vaya al recurso en la nube que necesita para conceder permisos. Por ejemplo, vaya al espacio de nombres de Event Hubs >Control de acceso (IAM)>Agregar asignación de roles.
- En la pestaña Rol, seleccione un rol adecuado.
- En la pestaña Miembros, para Asignar acceso a, seleccione la opción Usuario, grupo o entidad de servicio, seleccione + Seleccionar miembros y busque la identidad administrada de Operaciones de IoT de Azure. Por ejemplo, azure-iot-operations-xxxx7.
A continuación, configure el punto de conexión de flujo de datos con la configuración de identidad administrada asignada por el sistema.
En la página de configuración del punto de conexión de flujo de datos de la experiencia de operaciones, seleccione la pestaña Básico y, después, elija Método de autenticación>Identidad administrada asignada por el sistema.
Esta configuración crea una identidad administrada con la audiencia predeterminada, que es la misma que el valor de host del espacio de nombres de Event Hubs en forma de https://<NAMESPACE>.servicebus.windows.net. Sin embargo, si necesita invalidar el público predeterminado, puede establecer el campo audience en el valor deseado.
No se admite en la experiencia de operaciones.
Identidad administrada asignada por el usuario
Para usar la identidad administrada asignada por el usuario para la autenticación, primero debe implementar Operaciones de IoT de Azure con la configuración segura habilitada. A continuación, debe configurar una identidad administrada asignada por el usuario para las conexiones en la nube. Para obtener más información, consulte Habilitación de la configuración segura en la implementación de Operaciones de IoT de Azure.
Antes de configurar el punto de conexión de flujo de datos, asigne un rol a la identidad administrada asignada por el usuario que conceda permiso para conectarse al agente de Kafka:
- En Azure Portal, vaya al recurso en la nube que necesita para conceder permisos. Por ejemplo, vaya al espacio de nombres de Event Grid >Control de acceso (IAM)>Agregar asignación de roles.
- En la pestaña Rol, seleccione un rol adecuado.
- En la pestaña Miembros, para Asignar acceso a, seleccione la opción Identidad administrada y, a continuación, seleccione + Seleccionar miembros y busque la identidad administrada asignada por el usuario.
A continuación, configure el punto de conexión de flujo de datos con la configuración de identidad administrada asignada por el usuario.
En la página de configuración del punto de conexión de flujo de datos de la experiencia de operaciones, seleccione la pestaña Básico y, después, elija Método de autenticación>Identidad administrada asignada por el usuario.
Aquí, el ámbito es el público de la identidad administrada. El valor predeterminado es el mismo que el valor de host del espacio de nombres de Event Hubs en forma de https://<NAMESPACE>.servicebus.windows.net. Sin embargo, si necesita invalidar el público predeterminado, puede establecer el campo de ámbito en el valor deseado mediante Bicep o Kubernetes.
SASL
Para usar SASL para la autenticación, especifique el método de autenticación SASL y configure el tipo SASL, así como una referencia secreta con el nombre del secreto que contiene el token de SASL.
En la página de configuración del punto de conexión del flujo de datos de experiencia de operaciones, seleccione la pestaña Básico y, después, elija Método de autenticación>SASL.
Escriba la siguiente configuración para el punto de conexión:
| Configuración | Descripción |
|---|---|
| Tipo SASL | El tipo de autenticación SASL que se va a usar. Los tipos compatibles son Plain, ScramSha256 y ScramSha512. |
| Nombre del secreto sincronizado | Nombre del secreto de Kubernetes que contiene las el token de SASL. |
| Referencia de nombre de usuario del secreto de token | Referencia al nombre de usuario o al secreto de token que se usa para la autenticación SASL. |
| Referencia de contraseña del secreto de token | Referencia a la contraseña o al secreto de token que se usa para la autenticación SASL. |
Los tipos de SASL admitidos son:
PlainScramSha256ScramSha512
El secreto debe estar en el mismo espacio de nombres que el punto de conexión de flujo de datos de Kafka. El secreto debe tener el token de SASL como par clave-valor.
Anónimo
Para usar la autenticación anónima, actualice la sección de autenticación de la configuración de Kafka para usar el método Anónimo.
En la página de configuración del punto de conexión de flujo de datos de la experiencia de operaciones, seleccione la pestaña Básico y, después, elija Método de autenticación>Ninguno.
Configuración avanzada
Puede establecer la configuración avanzada para el punto de conexión de flujo de datos de Kafka, como TLS, certificado de CA de confianza, configuración de mensajería de Kafka, procesamiento por lotes y CloudEvents. Puede establecer esta configuración en el punto de conexión de flujo de datos de la pestaña del portal Avanzado o dentro del recurso del punto de conexión de flujo de datos.
En la experiencia de operaciones, seleccione el punto de conexión de flujo de datos de la pestaña Avanzado.
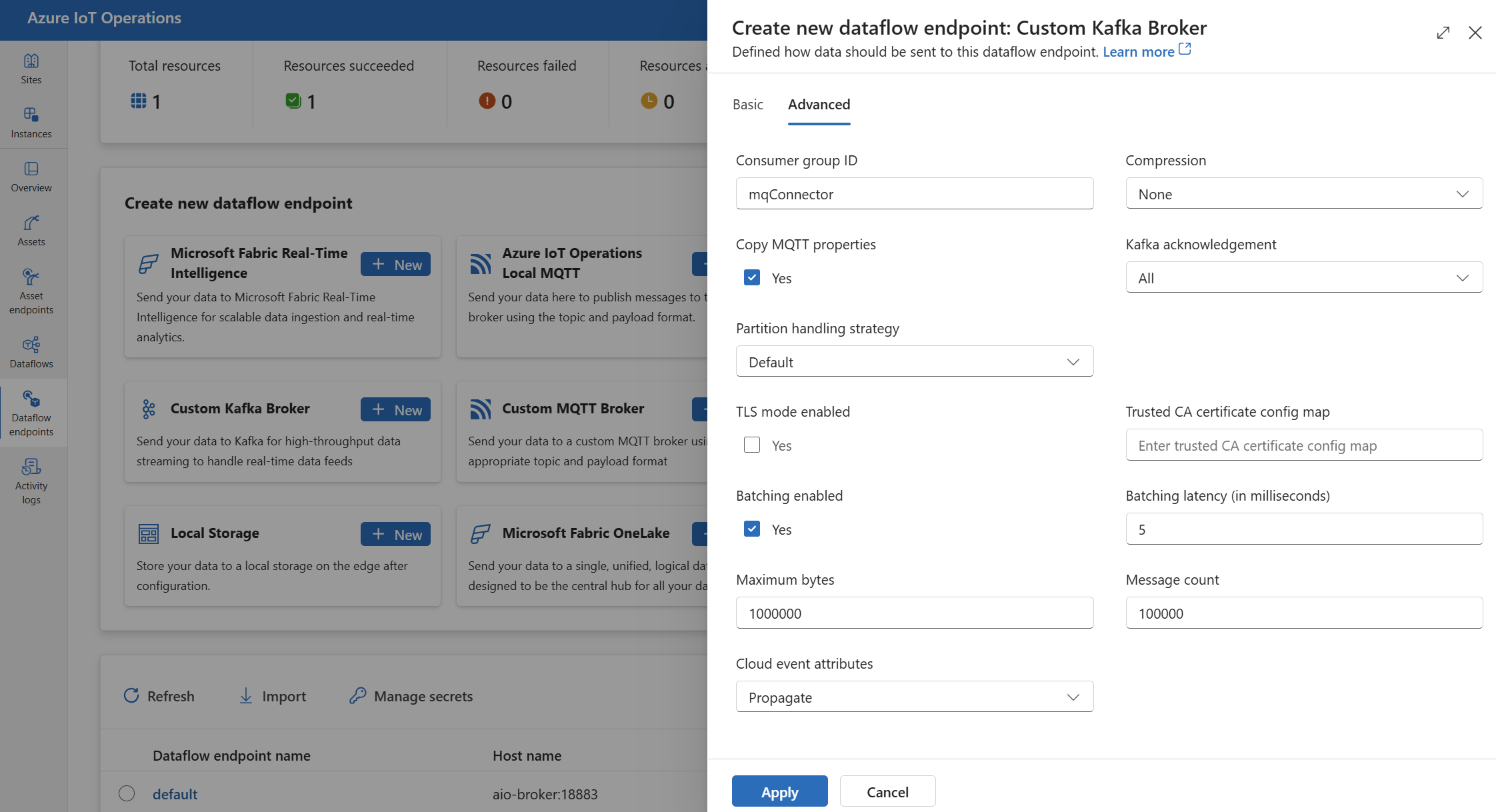
Configuración de TLS
Modo de TLS
Para habilitar o deshabilitar TLS para el punto de conexión de Kafka, actualice la configuración de mode en la configuración de TLS.
En la página de configuración del punto de conexión de flujo de datos de la experiencia de operaciones, seleccione la pestaña Avanzado y, a continuación, use la casilla situada junto a Modo TLS habilitado.
El modo TLS se puede establecer en Enabled o Disabled. Si el modo se establece en Enabled, el flujo de datos usa una conexión segura al agente de Kafka. Si el modo se establece en Disabled, el flujo de datos usa una conexión no segura al agente de Kafka.
Certificado de firma de confianza
Configure el certificado de entidad de certificación de confianza para el punto de conexión de Kafka para establecer una conexión segura con el agente de Kafka. Esta configuración es importante si el agente de Kafka usa un certificado autofirmado o un certificado firmado por una entidad de certificación personalizada que no es de confianza de forma predeterminada.
En la página de configuración del punto de conexión del flujo de datos de la experiencia de operaciones, seleccione la pestaña Avanzado y, a continuación, use el Mapa de configuración del certificado de entidad de certificación de confianza para especificar el ConfigMap que contiene el certificado de entidad de certificación de confianza.
Este ConfigMap debe contener el certificado de firma en formato PEM. ConfigMap debe estar en el mismo espacio de nombres que el recurso de flujo de datos de Kafka. Por ejemplo:
kubectl create configmap client-ca-configmap --from-file root_ca.crt -n azure-iot-operations
Sugerencia
Al conectarse a Azure Event Hubs, el certificado de firma no es necesario porque el servicio Event Hubs usa un certificado firmado por una entidad de certificación pública de confianza de forma predeterminada.
Identificador del grupo de consumidores
El identificador del grupo de consumidores se usa para identificar el grupo de consumidores que usa el flujo de datos para leer mensajes del tema de Kafka. El identificador del grupo de consumidores debe ser único dentro del agente de Kafka.
Importante
Cuando el punto de conexión de Kafka se usa como origen, se requiere el identificador del grupo de consumidores. De lo contrario, el flujo de datos no puede leer mensajes del tema de Kafka y se obtiene un error "Los puntos de conexión de origen de tipo Kafka deben tener definido un consumerGroupId".
En la página de configuración del punto de conexión de flujo de datos de la experiencia de operaciones, seleccione la pestaña Avanzado y, a continuación, use el campo Id. de grupo de consumidores para especificar el identificador del grupo de consumidores.
Esta configuración solo surte efecto si el punto de conexión se usa como origen (es decir, el flujo de datos es un consumidor).
Compresión
El campo de compresión habilita la compresión para los mensajes enviados a temas de Kafka. La compresión ayuda a reducir el ancho de banda de red y el espacio de almacenamiento necesarios para la transferencia de datos. Sin embargo, la compresión también agrega cierta sobrecarga y latencia al proceso. Los tipos de compresión admitidos se enumeran en la tabla siguiente.
| Valor | Descripción |
|---|---|
None |
No se aplica ninguna compresión ni procesamiento por lotes. Ninguno es el valor predeterminado si no se especifica ninguna compresión. |
Gzip |
Se aplican la compresión y el procesamiento por lotes de GZIP. GZIP es un algoritmo de compresión de uso general que ofrece un buen equilibrio entre la relación de compresión y la velocidad. Actualmente solo se admite la compresión GZIP en Azure Event Hubs premium y niveles dedicados. |
Snappy |
Se aplican la compresión y el procesamiento por lotes de Snappy. Snappy es un algoritmo de compresión rápido que ofrece una relación de compresión moderada y velocidad. Azure Event Hubs no admite este modo de compresión. |
Lz4 |
Se aplican la compresión y el procesamiento por lotes LZ4. LZ4 es un algoritmo de compresión rápido que ofrece una relación de compresión baja y alta velocidad. Azure Event Hubs no admite este modo de compresión. |
Para configurar la compresión:
En la página de configuración del punto de conexión de flujo de datos de la experiencia de operaciones, seleccione la pestaña Avanzado y, a continuación, use el campo Compresión para especificar el tipo de compresión.
Esta configuración solo surte efecto si el punto de conexión se usa como destino donde el flujo de datos es un productor.
Procesamiento por lotes
Además de la compresión, también puede configurar el procesamiento por lotes para los mensajes antes de enviarlos a temas de Kafka. El procesamiento por lotes permite agrupar varios mensajes y comprimirlos como una sola unidad, lo que puede mejorar la eficacia de compresión y reducir la sobrecarga de red.
| Campo | Descripción | Obligatorio |
|---|---|---|
mode |
Puede ser Enabled o Disabled. El valor predeterminado es Enabled porque Kafka no tiene una noción de mensajería no dispuesta en bloques. Si se establece en Disabled, el procesamiento por lotes se minimiza para crear un lote con un único mensaje cada vez. |
No |
latencyMs |
Intervalo de tiempo máximo en milisegundos que los mensajes se pueden almacenar en búfer antes de enviarse. Si se alcanza este intervalo, todos los mensajes almacenados en búfer se envían como un lote, independientemente de su cantidad o tamaño. Si no se establece, el valor predeterminado es 5. | No |
maxMessages |
Número máximo de mensajes que se pueden almacenar en búfer antes de enviarlos. Si se alcanza este número, todos los mensajes almacenados en búfer se envían como un lote, independientemente de su tamaño o de cuánto tiempo se almacenan en búfer. Si no se establece, el valor predeterminado es 100 000. | No |
maxBytes |
Tamaño máximo en bytes que se pueden almacenar en el búfer antes de enviarlos. Si se alcanza este tamaño, todos los mensajes almacenados en búfer se envían como un lote, independientemente de cuántos sean o de cuánto tiempo se almacenan en búfer. El valor predeterminado es 100 0000 (1 MB). | No |
Por ejemplo, si establece latencyMs en 1000, maxMessages en 100 y maxBytes en 1024, los mensajes se envían cuando hay 1000 mensajes en el búfer, o cuando hay 100 bytes en el búfer, o cuando transcurren 1024 milisegundos desde el último envío, lo que ocurra primero.
Para configurar el procesamiento por lotes:
En la página de configuración del punto de conexión de flujo de datos de la experiencia de operaciones, seleccione la pestaña Avanzado y, a continuación, use el campo Habilitado para el procesamiento por lotes para habilitar el procesamiento por lotes. Use los campos Latencia de procesamiento por lotes, Número máximo de bytes y Recuento de mensajes para especificar la configuración de procesamiento por lotes.
Esta configuración solo surte efecto si el punto de conexión se usa como destino donde el flujo de datos es un productor.
Estrategia de control de particiones
La estrategia de control de particiones controla cómo se asignan los mensajes a las particiones de Kafka al enviarlos a temas de Kafka. Las particiones de Kafka son segmentos lógicos de un tema de Kafka que habilitan el procesamiento paralelo y la tolerancia a errores. Cada mensaje de un tema de Kafka tiene una partición y un desplazamiento que se usan para identificar y ordenar los mensajes.
Esta configuración solo surte efecto si el punto de conexión se usa como destino donde el flujo de datos es un productor.
De forma predeterminada, un flujo de datos asigna mensajes a particiones aleatorias mediante un algoritmo round-robin. Sin embargo, puede usar diferentes estrategias para asignar mensajes a particiones en función de algunos criterios, como el nombre del tema MQTT o una propiedad de mensaje MQTT. Esto puede ayudarle a lograr un mejor equilibrio de carga, localidad de datos o ordenación de mensajes.
| Valor | Descripción |
|---|---|
Default |
Asigna mensajes a particiones aleatorias mediante un algoritmo round robin. Este es el valor predeterminado si no se especifica ninguna estrategia. |
Static |
Asigna mensajes a un número fijo de partición derivado del identificador de instancia del flujo de datos. Esto significa que cada instancia de flujo de datos envía mensajes a una partición diferente. Esto puede ayudar a lograr un mejor equilibrio de carga y localidad de datos. |
Topic |
Usa el nombre del tema MQTT del origen del flujo de datos como clave para la creación de particiones. Esto significa que los mensajes con el mismo nombre de tema MQTT se envían a la misma partición. Esto puede ayudar a lograr una mejor ordenación de mensajes y localidad de datos. |
Property |
Usa una propiedad de mensaje MQTT del origen del flujo de datos como clave para la creación de particiones. Especifique el nombre de la propiedad en el campo partitionKeyProperty. Esto significa que los mensajes con el mismo valor de propiedad se envían a la misma partición. Esto puede ayudar a lograr una mejor ordenación de mensajes y la localidad de datos en función de un criterio personalizado. |
Por ejemplo, si establece la estrategia de control de particiones en Property y la propiedad de clave de partición en device-id, los mensajes con la misma propiedad device-id se envían a la misma partición.
Para configurar la estrategia de control de particiones:
En la página de configuración del punto de conexión de flujo de datos de experiencia de operaciones, seleccione la pestaña Avanzado y, a continuación, use el campo Estrategia de control de particiones para especificar la estrategia de control de particiones. Use el campo Propiedad clave de partición para especificar la propiedad utilizada para la creación de particiones si la estrategia está establecida en Property.
Confirmaciones de Kafka
Las confirmaciones de Kafka (ACK) se usan para controlar la durabilidad y la coherencia de los mensajes enviados a temas de Kafka. Cuando un productor envía un mensaje a un tema de Kafka, puede solicitar distintos niveles de confirmaciones del agente de Kafka para asegurarse de que el mensaje se escribe correctamente en el tema y se replica en el clúster de Kafka.
Esta configuración solo surte efecto si el punto de conexión se usa como destino (es decir, el flujo de datos es un productor).
| Valor | Descripción |
|---|---|
None |
El flujo de datos no espera ninguna confirmación del agente de Kafka. Esta configuración es la opción más rápida pero menos duradera. |
All |
El flujo de datos espera a que el mensaje se escriba en la partición líder y en todas las particiones del seguidor. Esta configuración es la opción más lenta pero más duradera. Esta configuración también es la opción predeterminada |
One |
El flujo de datos espera a que el mensaje se escriba en la partición líder y al menos una partición del seguidor. |
Zero |
El flujo de datos espera a que el mensaje se escriba en la partición líder, pero no espera ninguna confirmación de los seguidores. Esto es más rápido que One pero menos duradero. |
Por ejemplo, si establece la confirmación de Kafka en All, el flujo de datos espera a que el mensaje se escriba en la partición de líder y en todas las particiones del seguidor antes de enviar el mensaje siguiente.
Para configurar las confirmaciones de Kafka:
En la página de configuración del punto de conexión de flujo de datos de experiencia de operaciones, seleccione la pestaña Avanzado y, a continuación, use el campo Confirmación de Kafka para especificar el nivel de confirmación de Kafka.
Esta configuración solo surte efecto si el punto de conexión se usa como destino donde el flujo de datos es un productor.
Copiar propiedades de MQTT
De forma predeterminada, la copia de configuración de propiedades MQTT está habilitada. Estas propiedades de usuario incluyen valores como subject que almacena el nombre del activo que envía el mensaje.
En la página de configuración del punto de conexión de flujo de datos de la experiencia de operaciones, seleccione la pestaña Avanzado y, después, use la casilla situada junto al campo Copiar propiedades MQTT para activar o desactivar la copia de propiedades MQTT.
En las secciones siguientes se describe cómo se traducen las propiedades MQTT a los encabezados de usuario de Kafka y viceversa cuando la configuración está habilitada.
El punto de conexión de Kafka es un destino
Cuando un punto de conexión de Kafka es un destino de flujo de datos, todas las propiedades definidas por la especificación MQTT v5 se traducen encabezados de usuario de Kafka. Por ejemplo, un mensaje MQTT v5 con "Tipo de contenido" que se reenvía a Kafka se traduce en el encabezado de usuario de Kafka "Content Type":{specifiedValue}. Se aplican reglas similares a otras propiedades MQTT integradas, definidas en la tabla siguiente.
| Propiedad MQTT | Comportamiento traducido |
|---|---|
| Indicador de formato de carga | Clave: "Indicador de formato de carga" Valor: "0" (la carga es bytes) o "1" (la carga es UTF-8) |
| Tema de respuestas | Clave: "Tema de respuestas" Valor: copia del tema de respuesta del mensaje original. |
| Intervalo de expiración de mensajes | Clave: "Intervalo de expiración de mensajes" Valor: representación UTF-8 del número de segundos antes de que expire el mensaje. Consulte propiedad Intervalo de expiración de mensajes para obtener más detalles. |
| Datos de correlación: | Clave: "Datos de correlación" Valor: copia de datos de correlación del mensaje original. A diferencia de muchas propiedades MQTT v5 codificadas con UTF-8, los datos de correlación pueden ser datos arbitrarios. |
| Tipo de contenido: | Clave: "Tipo de contenido" Valor: copia de tipo de contenido del mensaje original. |
Los pares de valor clave de propiedad de usuario MQTT v5 se traducen directamente a encabezados de usuario de Kafka. Si un encabezado de usuario de un mensaje tiene el mismo nombre que una propiedad MQTT integrada (por ejemplo, un encabezado de usuario denominado "Datos de correlación") entonces no está definido el reenvío del valor de la propiedad de especificación MQTT v5 o la propiedad de usuario.
Los flujos de datos nunca reciben estas propiedades de un agente MQTT. Por lo tanto, un flujo de datos nunca los reenvía:
- Alias de tema
- Identificadores de suscripción
La propiedad de intervalo de expiración de mensajes
El intervalo de expiración del mensaje especifica cuánto tiempo puede permanecer un mensaje en un agente MQTT antes de descartarse.
Cuando un flujo de datos recibe un mensaje MQTT con el intervalo de expiración del mensaje especificado, es:
- Registra la hora de recepción del mensaje.
- Antes de que se emita el mensaje al destino, se resta el tiempo que ha estado el mensaje en cola del tiempo de intervalo de expiración original.
- Si el mensaje no ha expirado (la operación anterior es > 0), el mensaje se emite al destino y contiene la hora de expiración del mensaje actualizada.
- Si el mensaje ha expirado (la operación anterior es <= 0), el destino no emite el mensaje.
Ejemplos:
- Un flujo de datos recibe un mensaje MQTT con intervalo de expiración de mensajes = 3600 segundos. El destino correspondiente está desconectado temporalmente, pero es capaz de volver a conectarse. Pasan 1 000 segundos antes de enviar este mensaje MQTT al destino. En este caso, el mensaje del destino tiene su intervalo de expiración de mensajes establecido en 2 600 (3 600 - 1 000) segundos.
- El flujo de datos recibe un mensaje MQTT con intervalo de expiración de mensajes = 3600 segundos. El destino correspondiente está desconectado temporalmente, pero es capaz de volver a conectarse. Sin embargo, en este caso, se tardan 4 000 segundos en volver a conectarse. El mensaje ha expirado y el flujo de datos no reenvía este mensaje al destino.
El punto de conexión de Kafka es un origen de flujo de datos
Nota:
Hay un problema conocido al usar el punto de conexión de Event Hubs como origen de flujo de datos donde el encabezado Kafka se daña como su traducido a MQTT. Esto solo ocurre si se usa Event Hub, aunque el cliente de Event Hub que usa AMQP en segundo plano. Por ejemplo, "foo"="bar", se traduce "foo", pero el valor se convierte en"\xa1\x03bar".
Cuando un punto de conexión de Kafka es un origen de flujo de datos, los encabezados de usuario de Kafka se traducen a las propiedades MQTT v5. En la tabla siguiente se describe cómo se traducen los encabezados de usuario de Kafka a las propiedades MQTT v5.
| Encabezado de Kafka | Comportamiento traducido |
|---|---|
| Clave | Clave: "Clave" Valor: copia de la clave del mensaje original. |
| Marca de tiempo | Clave: "Marca de tiempo" Valor: codificación UTF-8 de la marca de tiempo de Kafka, que es el número de milisegundos desde la época de Unix. |
Los pares clave-valor de encabezado de usuario de Kafka, siempre que estén codificados en UTF-8, se traducen directamente en propiedades de clave -valor de usuario MQTT.
Errores de coincidencia de binario o UTF-8
MQTT v5 solo puede admitir propiedades basadas en UTF-8. Si el flujo de datos recibe un mensaje de Kafka que contiene uno o varios encabezados que no son UTF-8, el flujo de datos hará lo siguiente:
- Quitará la propiedad o las propiedades infractoras.
- Reenvíe el resto del mensaje siguiendo las reglas anteriores.
Las aplicaciones que requieren transferencia binaria en encabezados de origen de Kafka => las propiedades de destino MQTT deben codificarlas primero en UTF-8, por ejemplo, a través de Base64.
>=64 KB errores de coincidencia de propiedades
Las propiedades MQTT v5 deben ser inferiores a 64 KB. Si el flujo de datos recibe un mensaje de Kafka que contiene uno o varios encabezados que es >= 64KB, el flujo de datos hará lo siguiente:
- Quitará la propiedad o las propiedades infractoras.
- Reenvíe el resto del mensaje siguiendo las reglas anteriores.
Traducción de propiedades al usar Event Hubs y productores que usan AMQP
Si tiene un cliente que reenvía mensajes, un punto de conexión de origen de flujo de datos de Kafka realiza cualquiera de las siguientes acciones:
- Envío de mensajes a Event Hubs mediante bibliotecas de cliente como Azure.Messaging.EventHubs
- Uso de AMQP directamente
Hay matices de traducción de propiedades que se deben tener en cuenta.
Debería realizar una de las siguientes acciones:
- Evitar el envío de propiedades
- Si debe enviar propiedades, envíe valores codificados como UTF-8.
Cuando Event Hubs traduce las propiedades de AMQP a Kafka, incluye los tipos codificados de AMQP subyacentes en su mensaje. Para obtener más información sobre el comportamiento, vea Intercambio de eventos entre consumidores y productores mediante distintos protocolos.
En el ejemplo de código siguiente cuando el punto de conexión del flujo de datos recibe el valor "foo":"bar", recibe la propiedad como <0xA1 0x03 "bar">.
using global::Azure.Messaging.EventHubs;
using global::Azure.Messaging.EventHubs.Producer;
var propertyEventBody = new BinaryData("payload");
var propertyEventData = new EventData(propertyEventBody)
{
Properties =
{
{"foo", "bar"},
}
};
var propertyEventAdded = eventBatch.TryAdd(propertyEventData);
await producerClient.SendAsync(eventBatch);
El punto de conexión de flujo de datos no puede reenviar la propiedad de carga <0xA1 0x03 "bar"> a un mensaje MQTT porque los datos no son UTF-8. Sin embargo, si especifica una cadena UTF-8, el punto de conexión de flujo de datos traduce la cadena antes de enviarlo a MQTT. Si usa una cadena UTF-8, el mensaje MQTT tendrá "foo":"bar" como propiedades de usuario.
Solo se traducen los encabezados UTF-8. Por ejemplo, dado el siguiente escenario en el que la propiedad se establece como float:
Properties =
{
{"float-value", 11.9 },
}
El punto de conexión de flujo de datos descarta los paquetes que contienen el campo "float-value".
No se reenvían todas las propiedades de datos de eventos, incluidas propertyEventData.correlationId. Para más información, consulte Propiedades del usuario de eventos,
CloudEvents
CloudEvents son una manera de describir los datos de eventos de una manera común. La configuración de CloudEvents se usa para enviar o recibir mensajes en el formato CloudEvents. Puede usar CloudEvents para arquitecturas controladas por eventos en las que distintos servicios necesitan comunicarse entre sí en los mismos o diferentes proveedores de nube.
Las opciones CloudEventAttributes son Propagate o CreateOrRemap.
En la página de configuración del punto de conexión de flujo de datos de la experiencia de operaciones, seleccione la pestaña Avanzado y, a continuación, use el campo Atributos de eventos en la nube para especificar la configuración de CloudEvents.
En las siguientes secciones se describe cómo se propagan o se vuelven a aplicar las propiedades de CloudEvent.
Propagación de la configuración
Las propiedades de CloudEvent se pasan a través de los mensajes que contienen las propiedades necesarias. Si el mensaje no contiene las propiedades necesarias, el mensaje se pasa tal como está. Si están presentes las propiedades necesarias, se agrega un prefijo ce_ al nombre de la propiedad CloudEvent.
| Nombre | Obligatorio | Valor de ejemplo | Nombre de salida | Valor de salida |
|---|---|---|---|---|
specversion |
Sí | 1.0 |
ce-specversion |
Pasó a través tal y como está |
type |
Sí | ms.aio.telemetry |
ce-type |
Pasó a través tal y como está |
source |
Sí | aio://mycluster/myoven |
ce-source |
Pasó a través tal y como está |
id |
Sí | A234-1234-1234 |
ce-id |
Pasó a través tal y como está |
subject |
No | aio/myoven/telemetry/temperature |
ce-subject |
Pasó a través tal y como está |
time |
No | 2018-04-05T17:31:00Z |
ce-time |
Pasó a través tal y como está. No se ha vuelto a marcar. |
datacontenttype |
No | application/json |
ce-datacontenttype |
Se ha cambiado al tipo de contenido de datos de salida después de la fase de transformación opcional. |
dataschema |
No | sr://fabrikam-schemas/123123123234234234234234#1.0.0 |
ce-dataschema |
Si se proporciona un esquema de transformación de datos de salida en la configuración de transformación, dataschema se cambia al esquema de salida. |
Configuración CreateOrRemap
Las propiedades de CloudEvent se pasan a través de los mensajes que contienen las propiedades necesarias. Si el mensaje no contiene las propiedades necesarias, se generan las propiedades.
| Nombre | Obligatorio | Nombre de salida | Valor generado si falta |
|---|---|---|---|
specversion |
Sí | ce-specversion |
1.0 |
type |
Sí | ce-type |
ms.aio-dataflow.telemetry |
source |
Sí | ce-source |
aio://<target-name> |
id |
Sí | ce-id |
UUID generado en el cliente de destino |
subject |
No | ce-subject |
Tema de salida en el que se envía el mensaje |
time |
No | ce-time |
Generado como RFC 3339 en el cliente de destino |
datacontenttype |
No | ce-datacontenttype |
Se ha cambiado al tipo de contenido de datos de salida después de la fase de transformación opcional |
dataschema |
No | ce-dataschema |
Esquema definido en el registro de esquemas |
Pasos siguientes
Para obtener más información sobre los flujos de datos, consulte Creación de un flujo de datos.