Rendimiento y escalado horizontal en Durable Functions (Azure Functions)
Para optimizar el rendimiento y la escalabilidad, es importante comprender las características únicas de escalado de Durable Functions. En este artículo, se explica cómo se escalan los trabajos en función de la carga y cómo se pueden ajustar los distintos parámetros.
Escalado del trabajo
Una ventaja fundamental del concepto de la central de tareas es que el número de trabajos que procesan los elementos de trabajo de la central de tareas se puede ajustar continuamente. En concreto, las aplicaciones pueden agregar más trabajos (escalado horizontal) si el trabajo debe procesarse más rápidamente y pueden quitar los trabajos (reducción horizontal) si no hay suficiente trabajo para mantener ocupados a los roles de trabajo. Incluso es posible escalar a cero si la central de tareas está completamente inactiva. Cuando se escala a cero, no hay ningún trabajo; solo el controlador de escalado y el almacenamiento deben permanecer activos.
En el siguiente diagrama se ilustra este concepto:
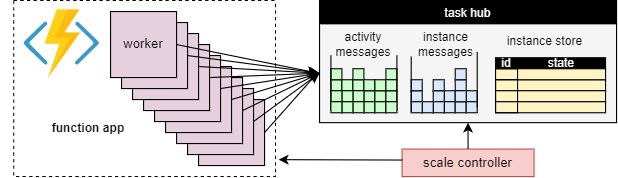
Escalado automático
Al igual que todas las instancias de Azure Functions que se ejecutan en los planes Consumo y Elástico Premium, Durable Functions admite el escalado automático a través del controlador de escalado de Azure Functions. El controlador de escalado supervisa cuánto tiempo tienen que esperar los mensajes y las tareas antes de que se procesen. En función de estas latencias, puede decidir si agregar o quitar trabajos.
Nota
A partir de Durable Functions 2.0, las aplicaciones de función se pueden configurar de modo que se ejecuten en los puntos de conexión de servicio protegidos mediante red virtual en el plan Elástico Premium. En esta configuración, los desencadenadores de Durable Functions inician solicitudes de escalado en lugar del controlador de escalado. Para obtener más información, consulte Supervisión de escala en entorno de ejecución.
En un plan Premium, el escalado automático puede ayudar a mantener el número de trabajos (y, por lo tanto, el costo operativo) aproximadamente proporcional a la carga que está experimentando la aplicación.
Uso de CPU
Las funciones de Orchestrator ejecutan su lógica varias veces debido a su comportamiento en la reproducción. Por tanto, es importante que los subprocesos de las funciones de Orchestrator no realicen tareas que hagan un uso intensivo de la CPU, realicen operaciones de E/S ni bloqueos por ningún motivo. Cualquier trabajo que requiera operaciones de E/S, bloqueos o varios subprocesos debe derivarse a las funciones de actividad.
Las funciones de actividad tienen el mismo comportamiento que las funciones normales desencadenadas por colas. Pueden realizar operaciones de E/S, ejecutar operaciones de uso intensivo de CPU y utilizar varios subprocesos con seguridad. Dado que los desencadenadores de actividad no tienen estado, se escalan horizontalmente a un número ilimitado de máquinas virtuales sin problema.
Las funciones de entidad también se ejecutan en un único subproceso y las operaciones se procesan de una en una. Pero las funciones de entidad no tienen ninguna restricción en cuanto al tipo de código que se puede ejecutar.
Tiempos de espera de función
Las funciones de actividad, orquestador y entidad están sujetas a los mismos tiempos de espera de función que todas las instancias de Azure Functions. Como regla general, Durable Functions trata los tiempos de espera de función de la misma manera que las excepciones no controladas producidas por el código de aplicación.
Por ejemplo, si se agota el tiempo de espera de una actividad, la ejecución de la función se registra como un error, se notifica al orquestador y controla el tiempo de espera igual que cualquier otra excepción: los reintentos se llevan a cabo si lo especifica la llamada, o bien se puede ejecutar un controlador de excepciones.
Procesamiento por lotes de operaciones de entidad
Para mejorar el rendimiento y reducir el costo, un único elemento de trabajo puede ejecutar un lote completo de operaciones de entidad. En los planes de consumo, cada lote se factura como una sola ejecución de función.
De forma predeterminada, el tamaño máximo del lote es 50 para planes de consumo y 5000 para todos los demás planes. El tamaño máximo del lote también se puede configurar en el archivo host.json. Si el tamaño máximo del lote es 1, el procesamiento por lotes se deshabilita de forma eficaz.
Nota
Si las operaciones de entidad individuales tardan mucho tiempo en ejecutarse, puede ser beneficioso limitar el tamaño máximo del lote para reducir el riesgo de tiempos de espera de función, en particular en los planes de consumo.
Almacenamiento en caché de instancias
Por lo general, para procesar un elemento de trabajo de orquestación, un trabajo tiene que hacer estas dos cosas:
- Capturar el historial de orquestación
- Reproducir el código de orquestador mediante el historial
Si el mismo trabajo está procesando varios elementos de trabajo para la misma orquestación, el proveedor de almacenamiento puede optimizar este proceso almacenando en caché el historial en la memoria del trabajo, lo que elimina el primer paso. Además, puede almacenar en caché el orquestador de ejecución media, lo que elimina también el segundo paso, la reproducción del historial.
El efecto típico del almacenamiento en caché es la E/S reducida en el servicio de almacenamiento subyacente y la mejora general del rendimiento y la latencia. Por otro lado, el almacenamiento en caché aumenta el consumo de memoria del trabajo.
El almacenamiento en caché de instancias es compatible actualmente con el proveedor de Azure Storage y el proveedor de almacenamiento de Netherite. En la tabla siguiente se ofrece una comparación.
| Proveedor de Azure Storage | Proveedor de almacenamiento de Netherite | Proveedor de almacenamiento de MSSQL | |
|---|---|---|---|
| Almacenamiento en caché de instancias | Compatible (Solo trabajo en proceso de .NET) |
Compatible | No compatible |
| Configuración predeterminada | Disabled | habilitado | N/D |
| Mecanismo | Sesiones extendidas | Caché de instancias | N/D |
| Documentación | Vea Sesiones extendidas. | Vea Caché de instancias. | N/D |
Sugerencia
El almacenamiento en caché puede reducir la frecuencia con la que se reproducen los historiales, pero no puede eliminar la reproducción por completo. Al desarrollar orquestadores, se recomienda encarecidamente probarlos en una configuración que deshabilite el almacenamiento en caché. El comportamiento de reproducción forzada predeterminado puede ser útil para detectar infracciones de restricciones de código de función de orquestador en tiempo de desarrollo.
Comparación de mecanismos de almacenamiento en caché
Los proveedores usan diferentes mecanismos para implementar el almacenamiento en caché y ofrecen parámetros diferentes para configurar el comportamiento del almacenamiento en caché.
- Las sesiones extendidas, como usa el proveedor de Azure Storage, mantienen los orquestadores de ejecución media en memoria hasta que están inactivos durante algún tiempo. Los parámetros para controlar este mecanismo son
extendedSessionsEnabledyextendedSessionIdleTimeoutInSeconds. Para más información, consulte la sección Sesiones extendidas de la documentación del proveedor de Azure Storage.
Nota
Las sesiones extendidas solo se admiten en el trabajo en proceso de .NET.
- La memoria caché de instancias, tal como la usa el proveedor de almacenamiento de Netherite, mantiene el estado de todas las instancias, incluidos sus historiales, en la memoria del trabajo, al tiempo que realiza un seguimiento de la memoria total utilizada. Si el tamaño de la memoria caché supera el límite configurado por
InstanceCacheSizeMB, se expulsan los datos de instancia menos usados recientemente. SiCacheOrchestrationCursorsse establece en true, la memoria caché también almacena los orquestadores de ejecución media junto con el estado de la instancia. Para más información, consulte la sección Caché de instancias de la documentación del proveedor de almacenamiento de Netherite.
Nota
Las cachés de instancias funcionan para todos los SDK de lenguaje, pero la opción CacheOrchestrationCursors solo está disponible para el trabajo en proceso de .NET.
Limitaciones de simultaneidad
Una sola instancia de trabajo puede ejecutar varios elementos de trabajo simultáneamente. Esto ayuda a aumentar el paralelismo y a utilizar de forma más eficaz los trabajos. Sin embargo, si un trabajo intenta procesar demasiados elementos de trabajo al mismo tiempo, puede agotar sus recursos disponibles, como la carga de CPU, el número de conexiones de red o la memoria disponible.
Para asegurarse de que un trabajo individual no se sobrecargue, puede ser necesario limitar la simultaneidad por instancia. Al limitar el número de funciones que se ejecutan simultáneamente en cada trabajo, podemos evitar agotar los límites de recursos de ese trabajo.
Nota
Las limitaciones de simultaneidad solo se aplican localmente, para limitar lo que cada trabajo procesa actualmente. Por lo tanto, estas limitaciones no limitan el rendimiento total del sistema.
Sugerencia
En algunos casos, la limitación de la simultaneidad por trabajo puede aumentar realmente el rendimiento total del sistema. Esto puede ocurrir cuando cada rol de trabajo asume menos trabajo, lo que hace que el controlador de escalado agregue más trabajos para mantenerse en las colas, lo que aumenta el rendimiento total.
Configuración de limitaciones
Los límites de simultaneidad de las funciones de actividad, orquestador y entidad se pueden configurar en el archivo host.json. La configuración relevante es durableTask/maxConcurrentActivityFunctions para las funciones de actividad y durableTask/maxConcurrentOrchestratorFunctions para las funciones de orquestador y de entidad. Esta configuración controla el número máximo de funciones de orquestador, entidad o actividad que se cargan en la memoria en un único rol de trabajo.
Nota:
Las orquestaciones y entidades solo se cargan en la memoria cuando están procesando eventos u operaciones de forma activa, o bien si el almacenamiento en caché de instancias está habilitado. Después de ejecutar su lógica y esperar (es decir, pulsar una instrucción await (C#) o yield (JavaScript, Python) en el código de función de orquestador), se pueden descargar de la memoria. Las orquestaciones y entidades que se descargan de la memoria no cuentan para la limitación maxConcurrentOrchestratorFunctions. Aunque haya millones de orquestaciones o entidades en estado "En ejecución", solo se tienen en cuenta para el límite cuando se cargan en la memoria activa. Una orquestación que programa una función de actividad de forma similar no cuenta para la limitación si la orquestación está esperando a que la actividad termine de ejecutarse.
Functions 2.0
{
"extensions": {
"durableTask": {
"maxConcurrentActivityFunctions": 10,
"maxConcurrentOrchestratorFunctions": 10
}
}
}
Functions 1.x
{
"durableTask": {
"maxConcurrentActivityFunctions": 10,
"maxConcurrentOrchestratorFunctions": 10
}
}
Consideraciones de entorno de ejecución de lenguaje
El entorno de ejecución de lenguaje que seleccione puede imponer restricciones de simultaneidad estrictas o sus funciones. Por ejemplo, es posible que las aplicaciones de Durable Function escritas en Python o PowerShell solo puedan admitir la ejecución de una sola función a la vez en una sola máquina virtual. Esto puede dar lugar a problemas de rendimiento significativos si no se tienen en cuenta. Por ejemplo, si un orquestador se expande a 10 actividades, pero el entorno de ejecución de lenguaje restringe la simultaneidad a una sola función, 9 de las 10 funciones de actividad quedarán bloqueadas a la espera de una oportunidad para ejecutarse. Además, estas 9 actividades bloqueadas no podrán equilibrar la carga en ningún otro trabajo porque el entorno de ejecución de Durable Functions ya los habrá cargado en la memoria. Esto se vuele especialmente problemático si las funciones de actividad son de ejecución prolongada.
Si el entorno de ejecución de lenguaje que el usuario utiliza implica una restricción en la simultaneidad, este debe actualizar la configuración de simultaneidad de Durable Functions para que coincida con la configuración de simultaneidad de su entorno de ejecución de lenguaje. Esto garantiza que el entorno de ejecución de Durable Functions no intentará ejecutar más funciones simultáneamente de las que permite el entorno de ejecución del lenguaje, de modo que las actividades pendientes equilibren la carga en otras máquinas virtuales. Por ejemplo, si el usuario tiene una aplicación de Python que restringe la simultaneidad a 4 funciones (quizás solo está configurada con 4 subprocesos en un único proceso de trabajo de lenguaje o 1 subproceso en 4 procesos de trabajo de lenguaje), debe establecer tanto maxConcurrentOrchestratorFunctions como maxConcurrentActivityFunctions en 4.
Para obtener más información y recomendaciones de rendimiento para Python, consulte Mejora del rendimiento de las aplicaciones de Python en Azure Functions. Las técnicas mencionadas en esta documentación de referencia para desarrolladores de Python pueden tener un impacto considerable en el rendimiento y la escalabilidad de Durable Functions.
Recuento de particiones
Algunos de los proveedores de almacenamiento usan un mecanismo de creación de particiones y permiten especificar un parámetro partitionCount.
Al usar particiones, los trabajos no compiten directamente por elementos de trabajo individuales. En su lugar, los elementos de trabajo se agrupan primero en particiones partitionCount. A continuación, estas particiones se asignan a los trabajos. Este enfoque con particiones para la distribución de la carga puede ayudar a reducir el número total de accesos de almacenamiento necesarios. Además, puede habilitar el almacenamiento en caché de instancias y mejorar la situación porque crea afinidad: el mismo trabajo procesa todos los elementos de trabajo de la misma instancia.
Nota:
La creación de particiones limita el escalado horizontal porque, en la mayoría de los trabajos partitionCount, pueden procesar elementos de trabajo de una cola con particiones.
En la tabla siguiente se muestra, para cada proveedor de almacenamiento, qué colas tienen particiones y el intervalo permitido y los valores predeterminados para el parámetro partitionCount.
| Proveedor de Azure Storage | Proveedor de almacenamiento de Netherite | Proveedor de almacenamiento de MSSQL | |
|---|---|---|---|
| Mensajes de instancia | Partitioned | Partitioned | Sin particiones |
| Mensajes de actividad | Sin particiones | Partitioned | Sin particiones |
partitionCount predeterminado |
4 | 12 | N/D |
partitionCount máximo |
16 | 32 | N/D |
| Documentación | Vea Escalabilidad horizontal del orquestador. | Vea Consideraciones sobre el recuento de particiones. | N/D |
Advertencia
Una vez creada la central de tareas, el número de particiones ya no se puede modificar. Por lo tanto, es aconsejable establecerlo en un valor lo suficientemente grande como para atender las futuras necesidades de escalado horizontal de la instancia de la central de tareas.
Configuración del número de particiones
El parámetro partitionCount se puede especificar en el archivo host.json. El siguiente fragmento de código de host.json de ejemplo establece la propiedad durableTask/storageProvider/partitionCount (o durableTask/partitionCount en Durable Functions 1.x) en 3.
Durable Functions 2.x
{
"extensions": {
"durableTask": {
"storageProvider": {
"partitionCount": 3
}
}
}
}
Durable Functions 1.x
{
"extensions": {
"durableTask": {
"partitionCount": 3
}
}
}
Consideraciones para minimizar las latencias de invocación
En circunstancias normales, las solicitudes de invocación (a actividades, orquestadores, entidades, etc.) deben procesarse con bastante rapidez. Sin embargo, no hay ninguna garantía sobre la latencia máxima de cualquier solicitud de invocación, ya que depende de factores como: el tipo de comportamiento de escala del plan de App Service, la configuración de simultaneidad y el tamaño del trabajo pendiente de la aplicación. Por lo tanto, se recomienda invertir en pruebas de esfuerzo para medir y optimizar las latencias finales de la aplicación.
Destinos del rendimiento
Si prevé utilizar Durable Functions para una aplicación de producción, es importante tener en cuenta los requisitos de rendimiento en una fase temprana del proceso de planeamiento. Algunos de los escenarios de uso básicos son:
- Ejecución de actividad secuencial: este escenario describe una función de orquestador que ejecuta una serie de funciones de actividad una tras otra. Se parece en gran medida al ejemplo de encadenamiento de funciones.
- Ejecución de actividad en paralelo: este escenario describe una función de orquestador que ejecuta numerosas funciones de actividad en paralelo mediante el patrón de distribución ramificada de entrada/salida.
- Procesamiento de respuestas en paralelo: este escenario es la segunda mitad del patrón de distribución ramificada de entrada/salida. Se centra en el rendimiento de la distribución ramificada de entrada. Es importante tener en cuenta que, a diferencia de la distribución ramificada de salida, la distribución ramificada de entrada se realiza mediante una única instancia de la función de orquestador y, por lo tanto, solo se puede ejecutar en una sola máquina virtual.
- Procesamiento de eventos externos: este escenario representa una única instancia de la función de orquestador que espera en eventos externos, uno a uno.
- Procesamiento de operaciones de entidad: En este escenario se pone a prueba la rapidez con la que una solaEntidad del contador puede procesar un flujo constante de operaciones.
Proporcionamos cifras de rendimiento para estos escenarios en la documentación correspondiente de los proveedores de almacenamiento. En concreto:
- Para el proveedor de Azure Storage, vea Objetivos de rendimiento.
- Para el proveedor de almacenamiento de Netherite, vea Escenarios básicos.
- Para el proveedor de almacenamiento de MSSQL, vea Pruebas comparativas de rendimiento de orquestación.
Sugerencia
A diferencia de la distribución ramificada de salida, las operaciones de la distribución ramificada de entrada están limitadas a una sola máquina virtual. Si la aplicación utiliza el patrón de distribución ramificada de entrada/salida, y le preocupa el rendimiento de la distribución ramificada de entrada, considere la posibilidad de subdividir la distribución ramificada de salida de la función de actividad entre varias suborquestaciones.