Proveedor de Azure Storage (Azure Functions)
En este documento se describen las características del proveedor de Azure Storage para Durable Functions, con un enfoque en los aspectos de rendimiento y escalabilidad. El proveedor de Azure Storage es el proveedor predeterminado. Almacena los estados de instancia y las colas en una cuenta de Azure Storage (clásico).
Nota:
Para más información sobre los proveedores de almacenamiento compatibles con Durable Functions y poder compararlos, consulte la documentación sobre proveedores de almacenamiento de Durable Functions.
En el proveedor de Azure Storage, las colas de Azure Storage controlan toda la ejecución de funciones. La orquestación, el estado de la entidad y el historial se almacenan en tablas de Azure. Los blobs de Azure y las concesiones de blobs se usan para distribuir instancias y entidades de orquestación entre varias instancias de aplicación (también conocidas como trabajos o sencillamente máquinas virtuales). En esta sección se explica con más detalle los distintos artefactos de Azure Storage y cómo afectan tanto al rendimiento como a la escalabilidad.
Representación de almacenamiento
Una central de tareas conserva de manera duradera todos los estados de instancia y todos los mensajes. Para obtener una introducción rápida sobre cómo se usan para hacer un seguimiento del progreso de una orquestación, consulte el ejemplo de ejecución de la central de tareas.
El proveedor de Azure Storage representa la central de tareas en el almacenamiento mediante los componentes siguientes:
- Entre dos y tres tablas de Azure. Se usan dos tablas para representar historiales y estados de instancia. Si el Administrador de particiones de tabla está habilitado, se introduce una tercera tabla para almacenar información de partición.
- Una cola de Azure almacena los mensajes de actividad.
- Una o varias colas de Azure almacenan los mensajes de instancia. Cada una de estas denominadas colas de control representa una partición que se asigna a un subconjunto de todos los mensajes de instancia, en función del hash del identificador de instancia.
- Algunos contenedores de blobs adicionales se usan para conceder blobs o mensajes grandes.
Por ejemplo, una central de tareas denominada xyz con PartitionCount = 4 contiene las colas y tablas siguientes:

A continuación, describimos estos componentes y el rol que desempeñan con más detalle.
Tabla del historial
La tabla History es una tabla de Azure Storage que contiene los eventos del historial de todas las instancias de orquestación dentro de una central de tareas. El nombre de esta tabla está en formato TaskHubNameHistory. Según se ejecutan las instancias, se van agregando nuevas filas a esta tabla. La clave de partición de esta tabla proviene del identificador de instancia de la orquestación. Los identificadores de instancia son aleatorios de manera predeterminada, lo que garantiza una distribución óptima de las particiones internas en Azure Storage. La clave de fila de esta tabla es un número de secuencia que se usa para ordenar los eventos de historial.
Cuando es necesario ejecutar una instancia de orquestación, las filas correspondientes de la tabla History se cargan en la memoria mediante una consulta por rango dentro de una sola partición de tabla. Estos eventos del historial se reproducen luego en el código de función de orquestación para regresar a su estado de punto de control previo. El uso del historial de ejecución para reconstruir el estado de esta manera se ve influenciado por el patrón Event Sourcing.
Sugerencia
Los datos de orquestación almacenados en la tabla History incluyen cargas de salida de las funciones de actividad y del suborquestador. Las cargas de eventos externos también se almacenan en la tabla History. Dado que se carga todo el historial en memoria cada vez que un orquestador necesita ejecutarse, un historial lo suficientemente grande puede provocar una presión de memoria considerable en una máquina virtual determinada. La longitud y el tamaño del historial de orquestación se pueden reducir dividiendo las orquestaciones grandes en varias suborquestaciones, o bien reduciendo el tamaño de las salidas devueltas por las funciones de actividad y de suborquestador a las que llama. Como alternativa, puede reducir el uso de memoria disminuyendo las limitaciones de simultaneidad por máquina virtual para limitar el número de orquestaciones que se cargan en la memoria de manera simultánea.
Tabla Instances
La tabla Instances contiene los estados de todas las instancias de orquestación y entidad dentro de una central de tareas. Según se crean las instancias, se van agregando nuevas filas a esta tabla. La clave de partición de esta tabla es el identificador de instancia de orquestación o la clave de entidad, y la clave de fila es una cadena vacía. Hay una fila por cada instancia de orquestación o entidad.
Esta tabla se utiliza para satisfacer tanto las solicitudes de consulta de instancia de código como las llamadas de API HTTP de consulta de estado. En última instancia es coherente con el contenido de la tabla History mencionada anteriormente. El uso de una tabla de Azure Storage independiente para satisfacer con eficiencia operaciones de consulta de instancias de esta manera se ve influenciada por el patrón Command and Query Responsibility Segregation (CQRS).
Sugerencia
La creación de particiones de la tabla Instances permite almacenar millones de instancias de orquestación sin ningún impacto perceptible en el rendimiento o la escala del entorno de ejecución. Sin embargo, el número de instancias puede tener un impacto significativo en el rendimiento de las consultas de instancias múltiples. Para controlar la cantidad de datos almacenados en estas tablas, considere la posibilidad de purgar periódicamente los datos de instancia antiguos.
Tabla de particiones
Nota:
Esta tabla solo se muestra en el centro de tareas cuando Table Partition Manager está habilitado. Para aplicarlo, configure la configuración useTablePartitionManagement en el archivo host.json de la aplicación.
La tabla Particiones almacena el estado de las particiones de la aplicación de Durable Functions y se usa para distribuir particiones entre los trabajos de la aplicación. Hay una fila por partición.
Colas
Las funciones de orquestador, entidad y actividad se desencadenan mediante colas internas de la central de tareas de la aplicación de funciones. El uso de colas de este modo proporciona garantías de entrega confiable de mensajes "al menos una vez". Hay dos tipos de colas en Durable Functions: de control y de elementos de trabajo.
Cola de elementos de trabajo
En Durable Functions hay una cola de elementos de trabajo por cada central de tareas. Se trata de una cola básica y se comporta del mismo modo que cualquier otra cola queueTrigger en Azure Functions. Esta cola se usa para desencadenar funciones de actividad sin estado al eliminar de la cola un único mensaje a la vez. Cada uno de estos mensajes contiene no solo entradas de la función de actividad, sino también metadatos adicionales, como qué función se debe ejecutar. Cuando una aplicación de Durable Functions admita el escalado horizontal de varias máquinas virtuales, estas compiten para adquirir las tareas de la cola de elementos de trabajo.
Colas de control
Hay varias colas de control por central de tareas en Durable Functions. Una cola de control es más sofisticada que una cola de elementos de trabajo, más sencilla. Las colas de control se usan para desencadenar las funciones de orquestador y entidad con estado. Dado que las instancias de la función de orquestador y de entidad son singletons con estado, es importante que cada orquestación o entidad solo se procese por un trabajo a la vez. Para lograr esta restricción, cada instancia o entidad de orquestación se asigna a una única cola de control. Estas colas de control tienen equilibrio de carga entre los trabajos para garantizar que cada una de ellas se procese únicamente por un trabajo cada vez. Encontrará más detalles sobre este comportamiento en las secciones siguientes.
Las colas de control contienen varios tipos de mensajes del ciclo de vida de la orquestación. Algunos ejemplos son los mensajes de control del orquestador, los mensajes de respuesta de la función de actividad y los del temporizador. Como máximo, se pueden eliminar 32 mensajes de una cola de control en un único sondeo. Estos mensajes contienen datos de carga y metadatos, entre los que se incluyen para qué instancia de orquestación están previstos. Si hay varios mensajes eliminados de la cola previstos para la misma instancia de orquestación, se procesarán como un lote.
Los mensajes de la cola de control se sondean constantemente mediante un subproceso en segundo plano. El tamaño de lote de los sondeos de cola se controla mediante el valor controlQueueBatchSize de host.jsen y tiene un valor predeterminado de 32 (el valor máximo admitido por colas de Azure). El número máximo de mensajes de la cola de control capturados previamente almacenados en un búfer de memoria se controla mediante el valor controlQueueBufferThreshold de host.jsen. El valor predeterminado de controlQueueBufferThreshold varía en función de distintos factores, como el tipo de plan de hospedaje. Para obtener más información sobre esta configuración, consulte la documentación del esquema de host.js.
Sugerencia
Aumentar el valor de controlQueueBufferThreshold permite que una sola orquestación o entidad procese eventos más rápidamente. Sin embargo, aumentar este valor también puede dar lugar a un uso de memoria más elevado. El aumento del uso de memoria se debe en parte a la extracción de más mensajes de la cola y, en parte, a la captura de más historiales de orquestación en la memoria. Por lo tanto, disminuir el valor de controlQueueBufferThreshold puede ser una manera eficaz de reducir el uso de memoria.
Sondeo de cola
La extensión Durable Task implementa un algoritmo de interrupción exponencial aleatorio para reducir el efecto del sondeo de cola inactiva en los costos de transacción de almacenamiento. Cuando encuentra un mensaje, el entorno de ejecución busca inmediatamente otro mensaje. Si no encuentra ningún mensaje, espera un intervalo de tiempo concreto antes de volver a intentarlo. Después de varios intentos fallidos para obtener un mensaje de la cola, el tiempo de espera sigue aumentando hasta que alcanza el tiempo de espera máximo, predeterminado en 30 segundos.
El retraso de sondeo máximo se configura mediante la propiedad maxQueuePollingInterval en el archivo host.json. El establecimiento de esta propiedad en un valor más alto puede provocar mayores latencias de procesamiento de mensajes. Las latencias elevadas solo se pueden esperar después de períodos de inactividad. El establecimiento de esta propiedad en un valor más bajo puede provocar costos de almacenamiento más elevados debido al mayor número de transacciones de almacenamiento.
Nota:
Cuando se ejecuta en los planes Consumo y Prémium de Azure Functions, la controladora de escala de Azure Functions sondea todas las colas de control y de elementos de trabajo cada 10 segundos. Este sondeo adicional es necesario para determinar cuándo activar instancias de aplicaciones de funciones y tomar decisiones de escalado. En el momento de escribir este artículo, este intervalo de 10 segundos es constante y no se puede configurar.
Retrasos en el inicio de la orquestación
Las instancias de las orquestaciones se inician con la inserción de un mensaje ExecutionStarted en una de las colas de control de la central de tareas. En determinadas condiciones, se pueden observar retrasos de varios segundos entre el momento en que se programa la ejecución de una orquestación y el momento en el que se inicia la ejecución. Durante este intervalo de tiempo, la instancia de la orquestación permanece en estado Pending. Hay dos causas posibles de este retraso:
Colas de control pendientes: si la cola de control de esta instancia contiene un gran número de mensajes, puede tardar un tiempo antes de que el entorno de ejecución reciba y procese el mensaje
ExecutionStarted. Los trabajos pendientes de mensajes se pueden producir cuando las orquestaciones procesan muchos eventos simultáneamente. Entre los eventos que van a la cola de control se incluyen los eventos de inicio de orquestación, finalización de actividad, temporizadores duraderos, terminación y eventos externos. Si este retraso se produce en circunstancias normales, considere la posibilidad de crear una nueva central de tareas con un mayor número de particiones. La configuración de más particiones hace que el runtime cree más colas de control para la distribución de la carga. Cada partición se corresponde con una cola de control con una relación de 1:1, con un máximo de 16 particiones.Retrasos en los sondeos de retroceso: otra causa común de los retrasos de la orquestación es el comportamiento de los sondeos de retroceso que se ha descrito anteriormente para las colas de control. Sin embargo, este retraso solo se espera cuando una aplicación se escala horizontalmente a dos o más instancias. Si solo hay una instancia de aplicación o si la instancia de aplicación que inicia la orquestación es la misma que sondea la cola de control de destino, no habrá retraso en el sondeo de la cola. Los retrasos de los sondeos de retroceso se pueden reducir mediante la actualización de las opciones del archivo host.json, tal y como se ha descrito anteriormente.
Datos BLOB
En la mayoría de los casos, Durable Functions no usa blobs de Azure Storage para conservar los datos. Sin embargo, las colas y las tablas tienen límites de tamaño que pueden impedir que Durable Functions persista todos los datos necesarios en una fila de almacenamiento o en un mensaje de cola. Por ejemplo, cuando un dato que es necesario conservar en una cola tenga más de 45 KB cuando se serializa, Durable Functions comprimirá los datos y los almacenará en un blob. Cuando los datos persisten en el almacenamiento de blobs de esta manera, Durable Functions almacena una referencia a ese BLOB en la fila de la tabla o en el mensaje de la cola. Cuando Durable Functions tenga que recuperar los datos, los recuperará automáticamente del blob. Estos blobs se almacenan en el contenedor de blobs <taskhub>-largemessages.
Consideraciones de rendimiento
Los pasos adicionales de compresión y de operación de blobs para los mensajes de gran tamaño pueden ser caros en relación con los costos de CPU y de latencia de E/S. Además, Durable Functions tiene que cargar los datos persistentes en la memoria y puede hacerlo para muchas ejecuciones de función diferentes al mismo tiempo. Como consecuencia, la persistencia de las cargas de datos de gran tamaño también puede provocar un uso elevado de la memoria. Para minimizar la sobrecarga de memoria, considere la posibilidad de conservar manualmente las cargas de datos de gran tamaño (por ejemplo, en almacenamiento de blobs) y, en su lugar, pasar las referencias a estos datos. De este modo, el código puede cargar los datos solo cuando sea necesario para evitar cargas redundantes durante la reproducción de la función de orquestador. Sin embargo, no se recomienda almacenar cargas en los discos locales, ya que no se garantiza que el estado en disco esté disponible, dado que las funciones pueden ejecutarse en VM diferentes a lo largo de su duración.
Selección de una cuenta de almacenamiento
Las colas, tablas y blobs usados por Durable Functions se crean en una cuenta de Azure Storage configurada. Se puede especificar la cuenta que se va a usar mediante el valor durableTask/storageProvider/connectionStringName (o durableTask/azureStorageConnectionStringName en Durable Functions 1.x) del archivo host.json.
{
"extensions": {
"durableTask": {
"storageProvider": {
"connectionStringName": "MyStorageAccountAppSetting"
}
}
}
}
Tenga en cuenta estas consideraciones al elegir la cuenta de almacenamiento que usa la aplicación de funciones de Durable:
- Si no se especifica, se utiliza la cuenta de almacenamiento
AzureWebJobsStoragepredeterminada. - Cuando sea posible, debe usar la autenticación de Microsoft Entra con identidades administradas para proteger la conexión de la cuenta de almacenamiento. Para más información, consulte Configuración de Durable Functions con identidad administrada.
- En el caso de las cargas de trabajo sensibles al rendimiento, debe configurar una cuenta de almacenamiento que no sea la predeterminada (
AzureWebJobsStorage). Durable Functions utiliza Azure Storage de forma intensiva y el uso de una cuenta de almacenamiento dedicada aísla el uso del almacenamiento de Durable Functions del uso interno por parte del host de Azure Functions. - Las cuentas estándar de uso general de Azure Storage son necesarias cuando se usa el proveedor de Azure Storage. En la actualidad, no se admiten los restantes tipos de cuenta de almacenamiento.
- Se recomienda encarecidamente usar cuentas de almacenamiento de uso general v1 heredadas para Durable Functions. Las cuentas de almacenamiento v2 más recientes pueden ser mucho más caras para cargas de trabajo de Durable Functions. Para obtener más información sobre los tipos de cuentas de Azure Storage, consulte la documentación general acerca de la cuenta de Azure Storage.
Escalabilidad horizontal del orquestador
Aunque las funciones de actividad se pueden escalar horizontalmente de forma infinita mediante la adición de más máquinas virtuales elásticamente, las instancias y entidades de orquestador individuales están limitadas para habitar en una única partición, y el número máximo de particiones está limitado por el valor partitionCount de su host.json.
Nota
En general, las funciones de orquestador se han diseñado para que sean ligeras y no necesiten grandes capacidades de computación. Por tanto, no es necesario crear un gran número de particiones de cola de control para obtener un rendimiento excelente para las orquestaciones. La mayor parte del trabajo pesado se realiza en las funciones de actividad sin estado, que se pueden escalar en horizontal infinitamente.
El número de colas de control se define en el archivo host.json. El siguiente fragmento de código de host.json de ejemplo establece la propiedad durableTask/storageProvider/partitionCount (o durableTask/partitionCount en Durable Functions 1.x) en 3. Tenga en cuenta que hay tantas colas de control como particiones.
{
"extensions": {
"durableTask": {
"storageProvider": {
"partitionCount": 3
}
}
}
}
Una central de tareas se puede configurar con entre 1 y 16 particiones. Si no se especifica, el número de participaciones predeterminado es 4.
Durante los escenarios de bajo tráfico, la aplicación se reducirá horizontalmente, por lo que las particiones serán administradas por un pequeño número de trabajos. Como ejemplo, considere el siguiente diagrama.
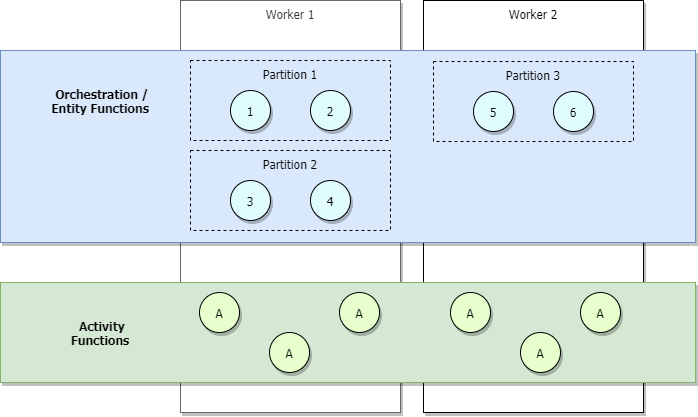
En el diagrama anterior, vemos que los orquestadores del 1 al 6 tienen equilibrio de carga entre las particiones. Del mismo modo, las particiones, como las actividades, tienen equilibrio de carga entre los trabajos. Las particiones tienen equilibrio de carga entre los trabajos, independientemente del número de orquestadores que se inicien.
Si está ejecutando los planes Consumo o Elástico Premium de Azure Functions, o si tiene configurado el escalado automático basado en la carga, se asignarán más trabajos a medida que aumente el tráfico y las particiones acabarán por equilibrar la carga entre todos los trabajos. Si continuamos escalando horizontalmente, cada partición se administrará finalmente por un único trabajo. Por otro lado, las actividades seguirán teniendo un equilibrio de carga en todos los trabajos. Esto se puede observar en la siguiente imagen.
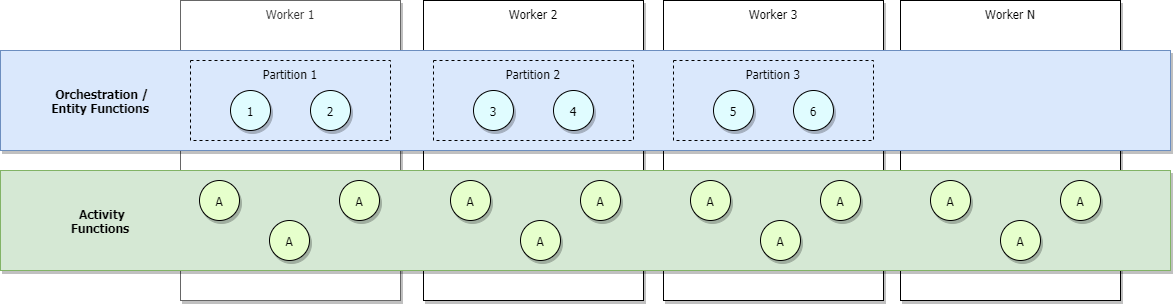
El límite superior del número máximo de orquestaciones simultáneas activas en un momento dado es igual al número de trabajos asignados a su aplicación por su valor para maxConcurrentOrchestratorFunctions. Este límite superior puede ser más preciso cuando las particiones se escalan de manera horizontal por completo entre los trabajos. Cuando se hayan escalado por completo de manera horizontal, y dado que cada trabajo tendrá solo una instancia de host de Functions, el número máximo de instancias de orquestador simultáneas activas será igual al número de particiones por su valor para maxConcurrentOrchestratorFunctions.
Nota
En este contexto, activo significa que una orquestación o entidad se carga en la memoria y que procesa nuevos eventos. Si la orquestación o entidad está esperando más eventos, como el valor devuelto de una función de actividad, se descarga de la memoria y ya no se considera activa. Las orquestaciones y entidades se volverán a cargar posteriormente en la memoria solo cuando haya nuevos eventos que procesar. No existe un número máximo práctico de orquestaciones o entidades totales que se puedan ejecutar en una sola máquina virtual, incluso si todas están en estado "En ejecución". La única limitación es el número de instancias de entidad o orquestación activas simultáneamente.
En la imagen siguiente se muestra un escenario con un escalado horizontal completo en el que se agregan más orquestadores pero algunos están inactivos (en gris).
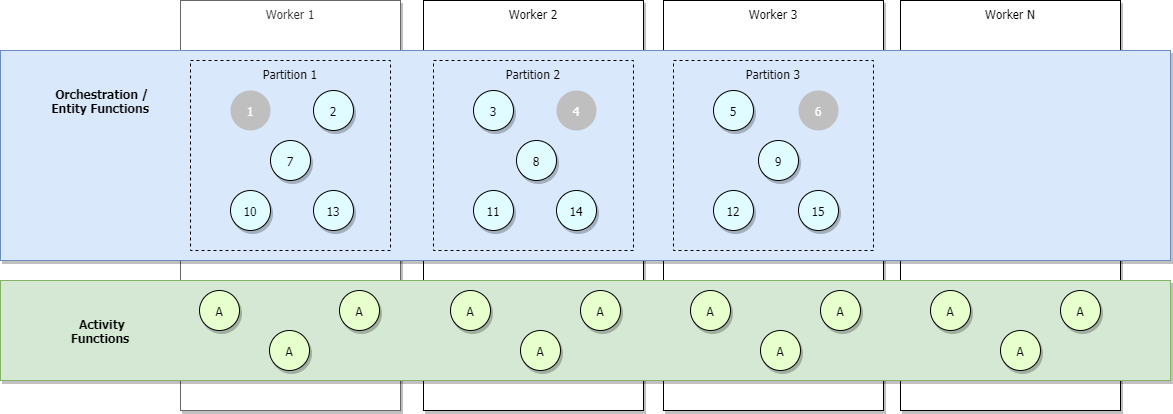
Durante el escalado horizontal, se pueden redistribuir las concesiones de la cola de control entre las instancias de host de Functions para asegurarse de que las particiones se distribuyen uniformemente. Estas concesiones se implementan internamente como concesiones de almacenamiento de blobs de Azure y garantizan que solo se ejecuta una instancia o entidad de orquestación individual en una única instancia de host a la vez. Si una central de tareas está configurada con tres particiones (y, por lo tanto, tres colas de control), las entidades y las instancias de orquestación pueden tener equilibrio de carga en las tres instancias de host que albergan las concesiones. Se pueden agregar máquinas virtuales adicionales para aumentar la capacidad de ejecución de la función de actividad,
El siguiente diagrama ilustra cómo interactúa el host de Azure Functions con las entidades de almacenamiento en un entorno de escalado horizontal.
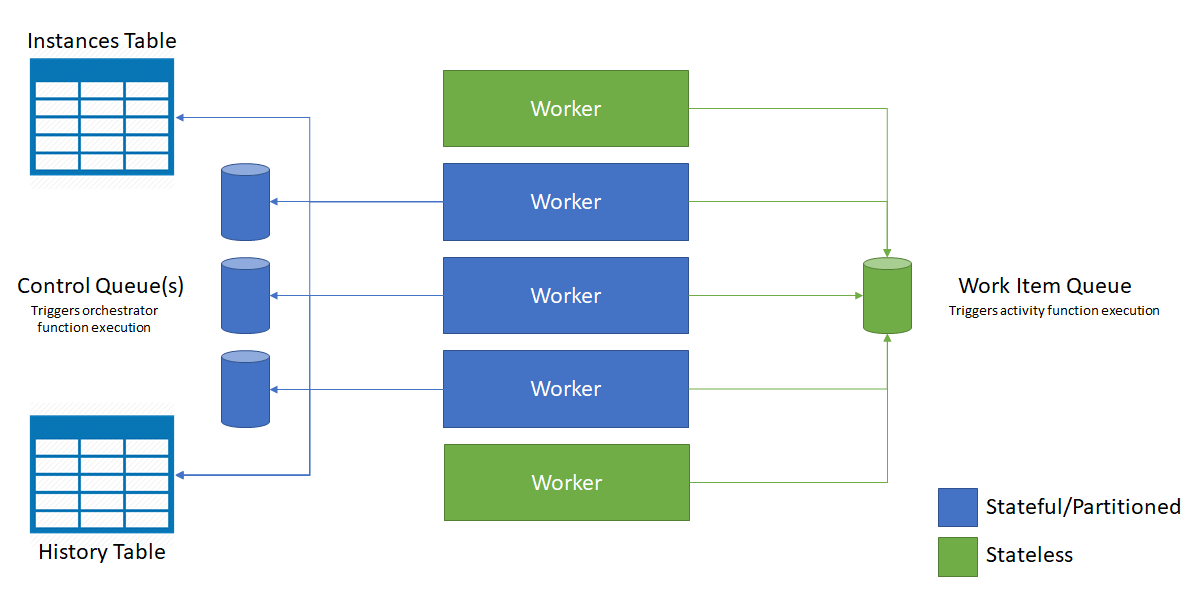
Tal como se muestra en el diagrama anterior, todas las máquinas virtuales compiten por los mensajes en la cola de elementos de trabajo. Sin embargo, solo tres de ellas pueden adquirir mensajes de las colas de control y cada una bloquea una sola cola de control.
Las instancias de orquestación y entidades se distribuyen entre todas las instancias de la cola de control. La distribución se realiza al aplicar un algoritmo hash al identificador de instancia de la orquestación o el par de nombre y clave de la entidad. Los identificadores de instancia de orquestación son, de forma predeterminada, GUID aleatorios que aseguran que las instancias se distribuyen equitativamente entre todas las colas de control.
En general, las funciones de orquestador se han diseñado para que sean ligeras y no necesiten grandes capacidades de computación. Por tanto, no es necesario crear un gran número de particiones de cola de control para obtener un rendimiento excelente para las orquestaciones. La mayor parte del trabajo pesado se realiza en las funciones de actividad sin estado, que se pueden escalar en horizontal infinitamente.
Sesiones extendidas
Sesiones extendidas es un mecanismo de almacenamiento en caché que mantiene las orquestaciones y entidades en memoria incluso después de que terminen de procesar mensajes. El efecto típico de habilitar sesiones extendidas es un número de operaciones de E/S reducido en lo que respecta al almacenamiento duradero subyacente y al rendimiento mejorado general.
Puede habilitar sesiones extendidas si establece durableTask/extendedSessionsEnabled en true en el archivo host.json. El valor durableTask/extendedSessionIdleTimeoutInSeconds se puede usar para controlar cuánto tiempo se retiene una sesión inactiva en memoria:
{
"extensions": {
"durableTask": {
"extendedSessionsEnabled": true,
"extendedSessionIdleTimeoutInSeconds": 30
}
}
}
Functions 1.0
{
"durableTask": {
"extendedSessionsEnabled": true,
"extendedSessionIdleTimeoutInSeconds": 30
}
}
Hay dos posibles inconvenientes de este valor que se deben tener en cuenta:
- Hay un aumento general en el uso de memoria de la aplicación de funciones porque las instancias inactivas no se descargan de la memoria tan rápidamente.
- Puede haber una disminución general del rendimiento si hay varias ejecuciones de funciones de orquestador o entidad simultáneas, distintas y de corta duración.
Por ejemplo, si durableTask/extendedSessionIdleTimeoutInSeconds se establece en 30 segundos, un episodio de función de orquestador o entidad de corta duración que se ejecuta en menos de 1 segundo sigue ocupando memoria durante 30 segundos. También se descuenta de la cuota durableTask/maxConcurrentOrchestratorFunctions mencionada antes, lo que puede evitar que se ejecuten otras funciones de orquestador o entidad.
En las secciones siguientes se describen los efectos concretos de las sesiones extendidas en las funciones de orquestador y entidad.
Nota:
Las sesiones extendidas solo se admiten actualmente en lenguajes .NET, como C# (solo modelo en proceso) o F#. Establecer extendedSessionsEnabled en true para otras plataformas puede conducir a problemas en tiempo de ejecución, como el error silencioso en la ejecución de las funciones desencadenadas por la actividad y la orquestación.
Reproducción de una función de orquestador
Tal como se ha mencionado anteriormente, las funciones de orquestador se reproducen con el contenido de la tabla History. De forma predeterminada, el código de la función de orquestador se reproduce cada vez que se elimina un lote de mensajes de una cola de control. Incluso si usa el patrón de distribución ramificada de entrada y salida y está esperando a que se completen todas las tareas (por ejemplo, con Task.WhenAll() en .NET, context.df.Task.all() en JavaScript, o context.task_all() en Python), habrá repeticiones que se produzcan a medida que se procesen lotes de respuestas de tareas a lo largo del tiempo. Cuando se habilitan sesiones extendidas, las instancias de funciones de orquestador se mantienen en memoria más tiempo y se pueden procesar mensajes nuevos sin una reproducción de historial completa.
La mejora del rendimiento de las sesiones extendidas suele notarse en las siguientes situaciones:
- Cuando hay un número limitado de instancias de orquestación que se ejecutan simultáneamente.
- Cuando las orquestaciones tienen un gran número de acciones secuenciales (por ejemplo, cientos de llamadas a funciones de actividad) que se completan rápidamente.
- Cuando las orquestaciones se ramifican en un gran número de acciones que se completan aproximadamente al mismo tiempo.
- Cuando las funciones de orquestador necesitan procesar mensajes grandes o realizar un procesamiento de datos con un uso intensivo de la CPU.
En todas las demás situaciones no suele notarse ninguna mejora del rendimiento para las funciones de orquestador.
Nota
Esta configuración solo se debe usar una vez que haya sido desarrollada y probada totalmente una función de orquestador. El comportamiento de reproducción agresivo predeterminado puede ser útil para detectar infracciones de restricciones de código de función del orquestador durante el desarrollo, por lo que está deshabilitado de forma predeterminada.
Destinos del rendimiento
En la tabla siguiente se muestran los números de rendimiento máximo esperados para los escenarios descritos en la sección Objetivos de rendimiento del artículo Rendimiento y escala.
"Instancia" hace referencia a una sola instancia de una función de orquestador que se ejecuta en una única y pequeña máquina virtual (A1) de Azure App Service. En todos los casos, se supone que las sesiones extendidas están habilitadas. Los resultados reales pueden variar según el trabajo de CPU o de E/S realizado por el código de la función.
| Escenario | Rendimiento máximo |
|---|---|
| Ejecución de actividad secuencial | 5 actividades por segundo y por instancia |
| Ejecución de actividad en paralelo (distribución ramificada de salida) | 100 actividades por segundo y por instancia |
| Procesamiento de respuestas en paralelo (distribución ramificada de entrada) | 150 respuestas por segundo y por instancia |
| Procesamiento de eventos externos | 50 eventos por segundo y por instancia |
| Procesamiento de operaciones de entidad | 64 operaciones por segundo |
Si no ve las cifras de rendimiento que espera, y el uso de CPU y de memoria parece correcto, compruebe si la causa está relacionada con el mantenimiento de la cuenta de almacenamiento. La extensión de Durable Functions puede colocar una carga importante en una cuenta de Azure Storage y unas cargas suficientemente altas pueden provocar limitaciones en la cuenta de almacenamiento.
Sugerencia
En algunos casos, el usuario puede aumentar significativamente el rendimiento de los eventos externos, la actividad de distribución ramificada de entrada y las operaciones de entidad si aumenta el valor de la configuración controlQueueBufferThreshold en host.jsen. Aumentar este valor por encima de su valor predeterminado hace que el proveedor de almacenamiento del marco de tareas de Durable utilice más memoria para capturar previamente estos eventos de forma más agresiva, lo que reduce retrasos asociados con la eliminación de mensajes de las colas de control de Azure Storage. Para obtener más información, consulte la documentación de referencia de host.json.
Plan de Consumo flexible
El Plan de Consumo flexible es un plan de hospedaje de Azure Functions que proporciona muchas de las ventajas del plan de consumo, incluido un modelo de facturación sin servidor, al tiempo que agrega características útiles, como redes privadas, selección de tamaño de memoria de instancia y compatibilidad completa con la autenticación de identidad administrada.
Azure Storage es actualmente el único proveedor de almacenamiento admitido para Durable Functions cuando se hospeda en el plan de Consumo flexible.
Debe seguir estas recomendaciones de rendimiento al hospedar Durable Functions en el plan de Consumo flexible:
- Establezca el recuento de instancias siempre listos para el grupo
durableen1. Esto garantiza que siempre haya una instancia lista para controlar las solicitudes relacionadas con Durable Functions, lo que reduce el inicio en frío de la aplicación. - Reduzca el intervalo de sondeo de cola a 10 segundos o menos. Dado que este tipo de plan es más sensible a los retrasos de sondeo en cola, reducir el intervalo de sondeo ayudará a aumentar la frecuencia de las operaciones de sondeo, lo que garantiza que las solicitudes se administran más rápido. Sin embargo, las operaciones de sondeo más frecuentes provocarán un mayor costo de la cuenta de Azure Storage.
Procesamiento de alto rendimiento
La arquitectura del back-end de Azure Storage pone ciertas limitaciones en la escalabilidad y el rendimiento teórico máximo de Durable Functions. Si las pruebas muestran que Durable Functions de Azure Storage no cumple sus requisitos de rendimiento, debe considerar el uso del proveedor de almacenamiento Netherite para Durable Functions.
Para comparar el rendimiento factible de varios escenarios básicos, consulte la sección Escenarios básicos de la documentación del proveedor de almacenamiento de Netherite.
Microsoft Research diseñó y desarrolló el back-end de almacenamiento de Netherite. Usa Azure Event Hubs y la tecnología de base de datos FASTER además de blobs en páginas de Azure. El diseño de Netherite permite un procesamiento de orquestaciones y entidades significativamente más elevado en comparación con otros proveedores. En algunos escenarios de referencia, se ha demostrado que el rendimiento aumenta en más de un orden de magnitud en comparación con el proveedor de Azure Storage predeterminado.
Para más información sobre los proveedores de almacenamiento compatibles con Durable Functions y poder compararlos, consulte la documentación sobre proveedores de almacenamiento de Durable Functions.