Azure Virtual Desktop es un servicio completo de virtualización de escritorio y de aplicaciones que se ejecuta en Microsoft Azure. Virtual Desktop ayuda a habilitar una experiencia segura de escritorio remoto que ayuda a las organizaciones a reforzar la resistencia empresarial. Ofrece administración simplificada, multisesión de Windows 10 y 11 Enterprise, y optimizaciones para aplicaciones de Microsoft 365 para la empresa. Con Virtual Desktop, puede implementar y escalar sus aplicaciones y escritorios de Windows en Azure en cuestión de minutos, al tiempo que proporciona características integradas de seguridad y cumplimiento para ayudar a proteger las aplicaciones y los datos.
A medida que siga habilitando el trabajo remoto para la organización con Virtual Desktop, es importante comprender sus funcionalidades de recuperación ante desastres (DR) y los procedimientos recomendados. Estos procedimientos refuerzan la confiabilidad entre regiones para ayudar a mantener los datos seguros y los empleados productivos. En este artículo, se proporcionan consideraciones sobre los requisitos previos de continuidad empresarial y recuperación ante desastres (BCDR), los pasos de implementación y los procedimientos recomendados. Obtendrá información sobre las opciones, las estrategias y la guía de arquitectura. El contenido de este documento le permite preparar un plan de BCDR correcto y puede ayudarle a aportar más resistencia a la empresa durante los eventos de tiempo de inactividad planeados y no planeados.
Hay varios tipos de desastres e interrupciones, y cada uno puede tener un impacto diferente. La resistencia y la recuperación se describen en profundidad para eventos locales y de toda la región, incluida la recuperación del servicio en otra región remota de Azure. Este tipo de recuperación se denomina recuperación ante desastres geográfica. Es fundamental crear la arquitectura de Virtual Desktop para lograr resistencia y disponibilidad. Debe proporcionar la máxima resistencia local para reducir el impacto de los eventos de error. Esta resistencia también reduce los requisitos para ejecutar los procedimientos de recuperación. En este artículo, también se proporciona información sobre la alta disponibilidad y los procedimientos recomendados.
Objetivos y ámbito
Los objetivos de esta guía son:
- Garantizar la máxima disponibilidad, resistencia y capacidad de recuperación ante desastres geográfica, a la vez que se minimiza la pérdida de datos para los datos de usuario importantes seleccionados.
- Minimizar el tiempo de recuperación.
Estos objetivos también se conocen como el objetivo de punto de recuperación (RPO) y el objetivo de tiempo de recuperación (RTO).
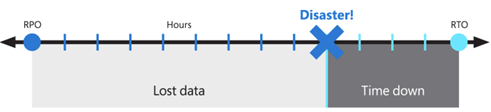
La solución propuesta proporciona alta disponibilidad local, protección frente a un error de una única zona de disponibilidad y protección frente a un error de toda la región de Azure. Se basa en una implementación redundante en otra región de Azure (secundaria) para recuperar el servicio. Aunque sigue siendo un procedimiento recomendado, Virtual Desktop y la tecnología que se usa para crear la BCDR no requieren que las regiones de Azure estén emparejadas. Las ubicaciones primaria y secundaria pueden ser cualquier combinación de regiones de Azure, si la latencia de red lo permite. El funcionamiento de grupos de hosts de AVD en varias regiones geográficas puede ofrecer más ventajas no limitadas a BCDR.
Para reducir el impacto de un error de una única zona de disponibilidad, use la resistencia para mejorar la alta disponibilidad:
- En la capa de proceso, distribuya los hosts de sesión de Virtual Desktop en diferentes zonas de disponibilidad.
- En la capa de almacenamiento, use la resistencia de zona siempre que sea posible.
- En la capa de redes, implemente puertas de enlace de red privada virtual (VPN) y Azure ExpressRoute con resistencia de zona.
- Para cada dependencia, revise el impacto de la interrupción de una única zona y planee las mitigaciones. Por ejemplo, implemente controladores de Dominio de Active Directory y otros recursos externos a los que accedan los usuarios de Virtual Desktop en varias zonas de disponibilidad.
Según el número de zonas de disponibilidad que use, evalúe el sobreaprovisionamiento del número de hosts de sesión para compensar la pérdida de una zona. Por ejemplo, incluso con (n-1) zonas disponibles, puede garantizar la experiencia de usuario y el rendimiento.
Nota:
Las zonas de disponibilidad de Azure son una característica de alta disponibilidad que puede mejorar la resistencia. Sin embargo, no las considere una solución de recuperación ante desastres capaz de proteger frente a desastres de toda la región.

Debido a las posibles combinaciones de tipos, opciones de replicación, funcionalidades del servicio y restricciones de disponibilidad en algunas regiones, se recomienda usar el componente Cloud Cache de FSLogix en lugar de mecanismos de replicación específicos del almacenamiento.
OneDrive no se trata en este artículo. Para más información sobre la redundancia y la alta disponibilidad, consulte Resistencia de datos de SharePoint y OneDrive en Microsoft 365.
En el resto de este artículo, obtendrá información sobre las soluciones para los dos tipos diferentes de grupos de hosts de Virtual Desktop. También se proporcionan observaciones para poder comparar esta arquitectura con otras soluciones:
- Personal: en este tipo de grupo de hosts, un usuario tiene un host de sesión asignado permanentemente, que nunca debe cambiar. Dado que es personal, esta máquina virtual puede almacenar datos de usuario. La suposición es usar técnicas de replicación y copia de seguridad para conservar y proteger el estado.
- Agrupado: a los usuarios se les asigna temporalmente una de las máquinas virtuales de host de sesión disponibles del grupo, ya sea directamente mediante un grupo de aplicaciones de escritorio o mediante aplicaciones remotas. Las máquinas virtuales no tienen estado y los perfiles y datos de usuario se almacenan en el almacenamiento externo o en OneDrive.
Se tratan las implicaciones de costos, pero el objetivo principal es proporcionar una implementación eficaz de recuperación ante desastres geográfica con una pérdida de datos mínima. Para más información sobre BCDR, consulte los siguientes recursos:
- Consideraciones sobre continuidad empresarial y recuperación ante desastres para Azure Virtual Desktop
- Recuperación ante desastres de Azure Virtual Desktop
Requisitos previos
Implemente la infraestructura principal y asegúrese de que esté disponible en la región principal y secundaria de Azure. Para obtener instrucciones sobre la topología de red, puede usar los modelos de conectividad y topología de red de Azure Cloud Adoption Framework:
- Topología tradicional de redes de Azure
- Topología de red de Virtual WAN (administrada por Microsoft)
En ambos modelos, implemente el grupo de hosts primario de Virtual Desktop y el entorno de recuperación ante desastres secundario dentro de diferentes redes virtuales de radio y conéctelos a cada centro de conectividad de la misma región. Coloque un centro de conectividad en la ubicación principal, un centro de conectividad en la ubicación secundaria y, a continuación, establezca la conectividad entre los dos.
El centro proporciona finalmente conectividad híbrida a recursos locales, servicios de firewall, recursos de identidad como controladores de dominio de Active Directory y recursos de administración como Log Analytics.
Debe tener en cuenta las aplicaciones de línea de negocio y la disponibilidad de los recursos dependientes cuando se conmuta por error a la ubicación secundaria.
Continuidad empresarial y recuperación ante desastres para el plano de control
Virtual Desktop ofrece continuidad empresarial y recuperación ante desastres para su plano de control con el fin de preservar los metadatos de los clientes durante las interrupciones. La plataforma Azure administra estos datos y procesos, y los usuarios no necesitan configurar ni ejecutar nada.

Virtual Desktop está diseñado para ser resistente a los errores de los componentes individuales y para poder recuperarse rápidamente de los errores. Cuando se produce una interrupción en una región, los componentes de la infraestructura del servicio realizan una conmutación por error en la ubicación secundaria y seguirán funcionando de forma habitual. Seguirá siendo posible acceder a los metadatos relacionados con el servicio, y los usuarios podrán conectarse a los hosts disponibles. Las conexiones de los usuarios finales permanecerán en línea si los hosts o el entorno del inquilino siguen siendo accesibles. Las ubicaciones de datos de Virtual Desktop son diferentes de la ubicación de la implementación de las máquinas virtuales del host de sesión del grupo de hosts. Es posible colocar los metadatos de Virtual Desktop en una de las regiones admitidas e implementar las máquinas virtuales en otra ubicación. Se proporcionan más detalles en el artículo Arquitectura y resistencia del servicio Virtual Desktop.
Activo-activo frente a activo-pasivo
Si distintos conjuntos de usuarios tienen distintos requisitos de BCDR, Microsoft recomienda usar varios grupos de hosts con configuraciones diferentes. Por ejemplo, los usuarios con una aplicación crítica podrían asignar un grupo de hosts totalmente redundante con funcionalidades de recuperación ante desastres geográfica. Sin embargo, los usuarios de desarrollo y pruebas pueden usar un grupo de hosts independiente sin recuperación ante desastres.
Para cada único grupo de hosts de Virtual Desktop, puede basar la estrategia de BCDR en un modelo activo-activo o activo-pasivo. En este escenario se presupone que un grupo de hosts específico atiende al mismo conjunto de usuarios de una ubicación geográfica.
- Activo-activo
Para cada grupo de hosts de la región primaria, se implementa un segundo grupo de hosts en la región secundaria.
Esta configuración proporciona un RTO de casi cero y RPO tiene un costo adicional.
No es necesario que un administrador intervenga ni realice la conmutación por error. Durante las operaciones normales, el grupo de hosts secundario proporciona al usuario recursos de Virtual Desktop.
Cada grupo de hosts tiene sus propias cuentas de almacenamiento (al menos una) para los perfiles de usuario persistentes.
Debe evaluar la latencia en función de la ubicación física del usuario y la conectividad disponible. En algunas regiones de Azure, como Oeste de Europa y Norte de Europa, la diferencia puede ser insignificante al acceder a las regiones primaria o secundaria. Puede validar este escenario mediante la herramienta Estimador de experiencia de Azure Virtual Desktop.
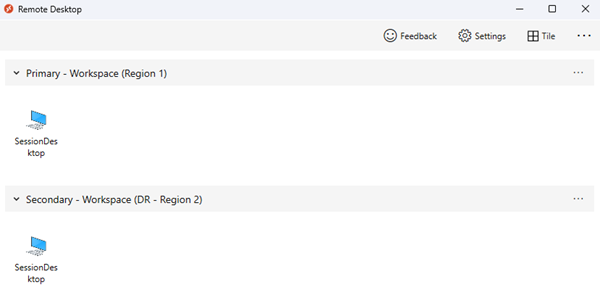
Los usuarios se asignan a diferentes grupos de aplicaciones, como el grupo de aplicaciones de escritorio (DAG) y el grupo de aplicaciones RemoteApp (RAG), en los grupos de hosts principal y secundario. En este caso, verán entradas duplicadas en su fuente de cliente de Virtual Desktop. Para evitar confusiones, use áreas de trabajo independientes de Virtual Desktop con nombres claros y etiquetas que reflejen el propósito de cada recurso. Informe a los usuarios sobre el uso de estos recursos.
Si necesita almacenamiento para administrar el perfil de FSLogix y los contenedores de ODFC por separado, use Cloud Cache para garantizar un RPO de casi cero.
- Para evitar conflictos de perfiles, no permita que los usuarios accedan a ambos grupos de hosts al mismo tiempo.
- Debido a la naturaleza activo-activo de este escenario, debe informar a los usuarios sobre cómo usar estos recursos de la manera adecuada.
Nota:
El uso de contenedores de ODFC independientes es un escenario avanzado de gran complejidad. Este modo de implementación solo se recomienda en algunos escenarios específicos.
- Activo-pasivo
- Como en el caso de activo-activo, para cada grupo de hosts de la región primaria, se implementa un segundo grupo de hosts en la región secundaria.
- La cantidad de recursos de proceso activos en la región secundaria se reduce en comparación con la región primaria, según el presupuesto disponible. Puede usar el escalado automático para proporcionar más capacidad de proceso, pero requiere más tiempo y no se garantiza la capacidad de Azure.
- Esta configuración proporciona un RTO mayor en comparación con el enfoque activo-activo, pero es menos costosa.
- Necesita la intervención del administrador para ejecutar un procedimiento de conmutación por error si se produce una interrupción de Azure. Normalmente, el grupo de hosts secundario no proporciona al usuario acceso a los recursos de Virtual Desktop.
- Cada grupo de hosts tiene sus propias cuentas de almacenamiento para los perfiles de usuario persistentes.
- Los usuarios que consumen servicios de Virtual Desktop con una latencia y un rendimiento óptimos solo se ven afectados si se produce una interrupción de Azure. Debe validar este escenario mediante la herramienta Estimador de experiencia de Azure Virtual Desktop. El rendimiento debe ser aceptable, incluso si se degrada, para el entorno de recuperación ante desastres secundario.
- Los usuarios se asignan a un único conjunto de grupos de aplicaciones, como aplicaciones de escritorio y remotas. Durante las operaciones normales, estas aplicaciones se encuentran en el grupo de hosts primario. Durante una interrupción y después de una conmutación por error, los usuarios se asignan a grupos de aplicaciones del grupo de hosts secundario. No se muestran entradas duplicadas en la fuente de cliente de Virtual Desktop del usuario, pueden usar la misma área de trabajo y todo es transparente para ellos.
- Si necesita almacenamiento para administrar el perfil de FSLogix y los contenedores de Office, use Cloud Cache para garantizar un RPO de casi cero.
- Para evitar conflictos de perfiles, no permita que los usuarios accedan a ambos grupos de hosts al mismo tiempo. Dado que este escenario es activo-pasivo, los administradores pueden aplicar este comportamiento en el nivel de grupo de aplicaciones. Solo después de un procedimiento de conmutación por error, el usuario puede acceder a cada grupo de aplicaciones del grupo host secundario. El acceso se revoca en el grupo de aplicaciones del grupo de hosts primario y se reasigna a un grupo de aplicaciones del grupo de hosts secundario.
- Ejecute una conmutación por error para todos los grupos de aplicaciones; de lo contrario, los usuarios que usan diferentes grupos de aplicaciones en grupos host diferentes podrían provocar conflictos de perfiles si no se administran de forma eficaz.
- Es posible permitir que un subconjunto específico de usuarios conmute por error de forma selectiva al grupo de hosts secundario y proporcione un comportamiento activo-activo limitado y una funcionalidad de conmutación por error de prueba. También es posible conmutar por error grupos de aplicaciones específicos, pero debe informar a los usuarios de que no usen recursos de diferentes grupos de hosts al mismo tiempo.
Para circunstancias específicas, puede crear un único grupo de hosts con una combinación de hosts de sesión ubicados en diferentes regiones. La ventaja de esta solución es que, si tiene un único grupo de hosts, no es necesario duplicar definiciones y asignaciones para aplicaciones remotas y de escritorio. Desafortunadamente, la recuperación ante desastres para grupos de hosts compartidos tiene varias desventajas:
- En el caso de los grupos de hosts agrupados, no es posible forzar a un usuario a un host de sesión de la misma región.
- Un usuario puede experimentar una mayor latencia y un rendimiento poco óptimo al conectarse a un host de sesión de una región remota.
- Si necesita almacenamiento para los perfiles de usuario, necesita una configuración compleja para administrar las asignaciones para los hosts de sesión en las regiones primaria y secundaria.
- Puede usar el modo de purga para deshabilitar temporalmente el acceso a los hosts de sesión ubicados en la región secundaria. Sin embargo, este método presenta más complejidad, sobrecarga de administración y uso ineficaz de los recursos.
- Puede mantener los hosts de sesión en un estado sin conexión en las regiones secundarias, pero presenta más complejidad y sobrecarga de administración.
Consideraciones y recomendaciones
General
Para implementar una configuración activo-activo o activo-pasivo mediante varios grupos de hosts y un mecanismo de caché en la nube de FSLogix, puedes crear el grupo de hosts dentro de la misma área de trabajo o en uno diferente, según el modelo. Este enfoque requiere que mantenga la alineación y las actualizaciones, manteniendo sincronizados ambos grupos de hosts y en el mismo nivel de configuración. Además de un nuevo grupo de hosts para la región de recuperación ante desastres secundaria, tiene que:
- Crear nuevos grupos de aplicaciones distintos y aplicaciones relacionadas para el nuevo grupo de hosts.
- Revocar las asignaciones de usuario al grupo de hosts primario y, a continuación, reasignarlas manualmente al nuevo grupo de hosts durante la conmutación por error.
Revisa las opciones de continuidad empresarial y recuperación ante desastres para FSLogix.
- No se cubre la recuperación de perfil en este documento.
- El caché en la nube (activo/pasivo) se incluye en este documento, pero se implementa utilizando el mismo grupo de host.
- La caché en la nube (activa/activa) se cubre en la parte restante de este documento.
Hay límites para los recursos de Virtual Desktop que se deben tener en cuenta en el diseño de una arquitectura de Virtual Desktop. Valide el diseño en función de los límites de servicio de Virtual Desktop.
Para diagnósticos y supervisión, se recomienda usar la misma área de trabajo de Log Analytics para el grupo de hosts primario y secundario. Con esta configuración, Azure Virtual Desktop Insights ofrece una vista unificada de la implementación en ambas regiones.
Sin embargo, el uso de un único destino de registro puede causar problemas si toda la región primaria no está disponible. La región secundaria no podrá usar el área de trabajo de Log Analytics en la región no disponible. Si esta situación es inaceptable, se podrían adoptar las siguientes soluciones:
- Use un área de trabajo de Log Analytics independiente para cada región y, a continuación, apunte los componentes de Virtual Desktop para iniciar sesión en su área de trabajo local.
- Pruebe y revise las funcionalidades de replicación y conmutación por error del área de trabajo de Logs Analytics.
Proceso
Para la implementación de ambos grupos de hosts en las regiones de recuperación ante desastres primaria y secundaria, debe distribuir la flota de máquinas virtuales del host de sesión en varias zonas de disponibilidad. Si las zonas de disponibilidad no están disponibles en la región local, puede usar un conjunto de disponibilidad para que la solución sea más resistente que con una implementación predeterminada.
La imagen maestra que se usa para la implementación del grupo de hosts en la región de recuperación ante desastres secundaria debe ser la misma que se usa para la primaria. Debe almacenar imágenes en Azure Compute Gallery y configurar varias réplicas de imagen en las ubicaciones primaria y secundaria. Cada réplica de imagen puede admitir una implementación en paralelo de un número máximo de máquinas virtuales y puede requerir más de una en función del tamaño del lote de implementación deseado. Para más información, consulte Almacenamiento y uso compartido de imágenes en Azure Compute Gallery.

Azure Compute Gallery no es un recurso global. Se recomienda tener al menos una galería secundaria en la región secundaria. En la región primaria, cree una galería, una definición de imagen de máquina virtual y una versión de imagen de máquina virtual. A continuación, cree los mismos objetos también en la región secundaria. Al crear la versión de la imagen de máquina virtual, existe la posibilidad de copiar la versión de la imagen de máquina virtual creada en la región primaria especificando la galería, la definición de imagen de máquina virtual y la versión de imagen de máquina virtual usada en la región primaria. Azure copia la imagen y crea una versión de imagen de máquina virtual local. Es posible ejecutar esta operación mediante Azure Portal o el comando de la CLI de Azure, tal como se describe a continuación:
Creación de una definición de imagen y una versión de imagen
No todas las máquinas virtuales del host de sesión de las ubicaciones de recuperación ante desastres secundarias deben estar activas y en ejecución todo el tiempo. Inicialmente, debe crear un número suficiente de máquinas virtuales y, después, usar un mecanismo de autoescala, como los Planes de escalado. Con estos mecanismos, es posible mantener la mayoría de los recursos de proceso en un estado sin conexión o desasignado para reducir los costos.
También es posible usar la automatización para crear hosts de sesión en la región secundaria solo cuando sea necesario. Este método optimiza los costos, pero en función del mecanismo que use, podría requerir un RTO más largo. Este enfoque no permite pruebas de conmutación por error sin una nueva implementación y no permite la conmutación por error selectiva para grupos específicos de usuarios.

Nota:
Debe encender cada máquina virtual de host de sesión durante unas horas al menos una vez cada 90 días para actualizar el token de autenticación necesario para conectarse al plano de control de Virtual Desktop. También debe aplicar periódicamente revisiones de seguridad y actualizaciones de aplicaciones.
- Tener hosts de sesión en un estado sin conexión o desasignado en la región secundaria no garantiza que la capacidad esté disponible en caso de desastre en toda la región primaria. También se aplica si se implementan nuevos hosts de sesión a petición cuando es necesario y con el uso de Site Recovery. La capacidad de proceso solo se puede garantizar si los recursos relacionados ya están asignados y activos.
Importante
Azure Reservations no proporciona capacidad garantizada en la región.
En escenarios de uso de Cloud Cache, se recomienda usar el nivel Premium para discos administrados.
Storage
En esta guía, usará al menos dos cuentas de almacenamiento independientes para cada grupo de hosts de Virtual Desktop. Una es para el contenedor de perfiles de FSLogix y otra para los datos del contenedor de Office. También necesita una cuenta de almacenamiento más para los paquetes MSIX. Se aplican las siguientes consideraciones:
- Puede usar un recurso compartido de Azure Files y Azure NetApp Files como alternativas de almacenamiento. Para comparar las opciones, consulte las opciones de almacenamiento del contenedor de FSLogix.
- Un recurso compartido de Azure Files puede proporcionar resistencia de zona mediante la opción de resistencia de almacenamiento con redundancia de zona (ZRS), si está disponible en la región.
- No puede usar la característica de almacenamiento con redundancia geográfica en las situaciones siguientes:
- Necesita una región que no tenga ningún par. Los pares de regiones para el almacenamiento con redundancia geográfica son fijos y no se pueden cambiar.
- Usa el nivel Premium.
- El RPO y el RTO son mayores en comparación con el mecanismo de Cloud Cache de FSLogix.
- No es fácil probar la conmutación por error y la conmutación por recuperación en un entorno de producción.
- Azure NetApp Files requiere más consideraciones:
- La redundancia de zona aún no está disponible. Si el requisito de resistencia es más importante que el rendimiento, use un recurso compartido de Azure Files.
- Azure NetApp Files pueden ser zonales, es decir, los clientes pueden decidir a qué zona de disponibilidad de Azure (única) asignar.
- La replicación entre zonas se puede establecer en el nivel de volumen para proporcionar resistencia de zona, pero la replicación se produce de forma asincrónica y requiere conmutación por error manual. Este proceso requiere un objetivo de punto de recuperación (RPO) y un objetivo de tiempo de recuperación (RTO) que sean mayores que cero. Antes de usar esta característica, revise los requisitos y consideraciones para la replicación entre zonas.
- Se puede usar Azure NetApp Files con una VPN con redundancia de zona y puertas de enlace de ExpressRoute, si se utiliza la característica de redes estándar, que se podría usar para la resistencia de redes. Para más información, consulte Topologías de red admitidas.
- Azure Virtual WAN es compatible cuando se usa junto con las redes estándar de Azure NetApp Files. Para más información, consulte Topologías de red admitidas.
- Azure NetApp Files tiene un mecanismo de replicación entre regiones. Se aplican las siguientes consideraciones:
- No está disponible en todas las regiones.
- La replicación entre regiones de los pares de regiones de volumen de Azure NetApp Files puede ser diferente de los pares de regiones de almacenamiento de Azure.
- No se puede usar al mismo tiempo con la replicación entre zonas.
- La conmutación por error no es transparente y la conmutación por recuperación requiere la reconfiguración del almacenamiento.
- Límites
- Hay límites en el tamaño, las operaciones de entrada y salida por segundo (IOPS) y MBps de ancho de banda tanto para el recurso compartido de Azure Files como para las cuentas de almacenamiento y los volúmenes de Azure NetApp Files. Si es necesario, es posible usar más de uno para el mismo grupo de hosts en Virtual Desktop mediante la configuración por grupo en FSLogix. Sin embargo, esta configuración requiere más planeamiento y configuración.
La cuenta de almacenamiento que use para los paquetes de aplicaciones MSIX debe ser distinta de las demás cuentas para perfiles y contenedores de Office. Están disponibles las siguientes opciones de recuperación ante desastres geográfica:
- Una cuenta de almacenamiento con el almacenamiento con redundancia geográfica habilitado, en la región primaria
- La región secundaria es fija. Esta opción no es adecuada para el acceso local si hay una conmutación por error de la cuenta de almacenamiento.
- Dos cuentas de almacenamiento independientes, una en la región primaria y otra en la región secundaria (recomendado)
- Use almacenamiento con redundancia de zona al menos para la región primaria.
- Cada grupo de hosts de cada región tiene acceso de almacenamiento local a los paquetes MSIX con baja latencia.
- Copie los paquetes MSIX dos veces en ambas ubicaciones y registre los paquetes dos veces en ambos grupos de hosts. Asigne usuarios a los grupos de aplicaciones dos veces.
FSLogix
Microsoft recomienda usar las siguientes características y configuración de FSLogix:
Si el contenido del contenedor de perfiles debe tener una administración de BCDR independiente y tiene requisitos diferentes en comparación con el contenedor de Office, debe dividirlos.
- El contenedor de Office solo tiene contenido almacenado en caché que se puede volver a crear o volver a rellenar desde el origen si se produce un desastre. Con el contenedor de Office, es posible que no tenga que conservar las copias de seguridad, lo que puede reducir los costos.
- Cuando se usan cuentas de almacenamiento diferentes, solo puede habilitar las copias de seguridad en el contenedor de perfiles. O bien, debe tener una configuración diferente, como el período de retención, el almacenamiento usado, la frecuencia y el RTO/RPO.
Cloud Cache es un componente FSLogix en el que puede especificar varias ubicaciones de almacenamiento de perfiles y replicar de forma asincrónica los datos de perfil, todo ello sin depender de ningún mecanismo de replicación de almacenamiento subyacente. Si se produce un error en la primera ubicación de almacenamiento o no es accesible, Cloud Cache conmuta por error automáticamente para usar la secundaria y agregará eficazmente una capa de resistencia. Use Cloud Cache para replicar los contenedores de perfiles y de Office entre diferentes cuentas de almacenamiento en las regiones primaria y secundaria.

Debe habilitar Cloud Cache dos veces en el registro de la máquina virtual del host de sesión, una vez para el contenedor de perfiles y una vez para el contenedor de Office. Es posible no habilitar Cloud Cache para el contenedor de Office, pero no habilitarlo podría provocar una desalineación de datos entre la región de recuperación ante desastres primaria y secundaria si hay conmutación por error y conmutación por recuperación. Pruebe este escenario cuidadosamente antes de usarlo en producción.
Cloud Cache es compatible con la configuración de división de perfiles y por grupo. La configuración por grupo requiere un diseño cuidadoso y el planeamiento de grupos y pertenencias de Active Directory. Debe asegurarse de que todos los usuarios forman parte exactamente de un grupo y ese grupo se usa para conceder acceso a los grupos de hosts.
El parámetro CCDLocations especificado en el registro para el grupo de hosts en la región de recuperación ante desastres secundaria se revierte en el orden, en comparación con la configuración de la región primaria. Para más información, consulte Tutorial: Configuración de Cloud Cache para redirigir los contenedores de perfiles o el contenedor de Office a varios proveedores.
Sugerencia
Este artículo se centra en un escenario específico. Los escenarios adicionales se describen en Opciones de alta disponibilidad para FSLogix y Opciones de continuidad empresarial y recuperación ante desastres para FSLogix.

En el ejemplo siguiente, se muestra una configuración de Cloud Cache y las claves del Registro relacionadas:
Región primaria: Norte de Europa
Identificador URI de la cuenta de almacenamiento del contenedor de perfiles = \northeustg1\profiles
- Ruta de acceso de la clave del Registro = HKEY_LOCAL_MACHINE > SOFTWARE > FSLogix > Profiles
- Valor de CCDLocations = type=smb,connectionString=\northeustg1\profiles;type=smb,connectionString=\westeustg1\profiles
Nota
Si descargó previamente las plantillas de FSLogix, puede realizar las mismas configuraciones a través de la consola de administración de la directiva de grupo de Active Directory. Para más detalles sobre cómo configurar el objeto de directiva de grupo para FSLogix, consulte la guía Uso de archivos de plantilla de directiva de grupo de FSLogix.

Identificador URI de la cuenta de almacenamiento del contenedor de Office= \northeustg2\odcf
Ruta de acceso de la clave del Registro = HKEY_LOCAL_MACHINE > SOFTWARE >Policy > FSLogix > ODFC
Valor de CCDLocations = type=smb,connectionString=\northeustg2\odfc;type=smb,connectionString=\westeustg2\odfc



Nota
En las capturas de pantalla anteriores, no se mencionan todas las claves del Registro recomendadas para FSLogix y Cloud Cache, por motivos de brevedad y simplicidad. Para obtener más información, consulte Ejemplos de configuración de FSLogix.
Región secundaria = Oeste de Europa
- Identificador URI de la cuenta de almacenamiento del contenedor de perfiles = \westeustg1\profiles
- Ruta de acceso de la clave del Registro = HKEY_LOCAL_MACHINE > SOFTWARE > FSLogix > Profiles
- Valor de CCDLocations = type=smb,connectionString=\westeustg1\profiles;type=smb,connectionString=\northeustg1\profiles
- Identificador URI de la cuenta de almacenamiento del contenedor de Office= \westeustg2\odcf
- Ruta de acceso de la clave del Registro = HKEY_LOCAL_MACHINE > SOFTWARE >Policy > FSLogix > ODFC
- Valor de CCDLocations = type=smb,connectionString=\westeustg2\odfc;type=smb,connectionString=\northeustg2\odfc
Replicación de Cloud Cache
Los mecanismos de configuración y replicación de Cloud Cache garantizan la replicación de los datos de perfil entre distintas regiones con una pérdida de datos mínima. Puesto que el mismo archivo de perfil de usuario solo se puede abrir en modo de lectura y escritura mediante un solo proceso, se debe evitar el acceso simultáneo, por lo que los usuarios no deben abrir una conexión a ambos grupos de hosts al mismo tiempo.

Descargue un archivo Visio de esta arquitectura.
Flujo de datos
Un usuario de Virtual Desktop inicia el cliente de Virtual Desktop y, a continuación, abre una aplicación de escritorio o una aplicación remota publicada asignada al grupo de hosts de la región primaria.
FSLogix recupera el perfil de usuario y los contenedores de Office y, a continuación, monta el VHD/X de almacenamiento subyacente desde la cuenta de almacenamiento ubicada en la región primaria.
Al mismo tiempo, el componente de Cloud Cache inicializa la replicación entre los archivos de la región primaria y los archivos de la región secundaria. Para este proceso, Cloud Cache, en la región primaria, adquiere un bloqueo exclusivo de lectura y escritura en estos archivos.
El mismo usuario de Virtual Desktop ahora quiere iniciar otra aplicación publicada asignada en el grupo de hosts de la región secundaria.
El componente de FSLogix que se ejecuta en el host de sesión de Virtual Desktop de la región secundaria intenta montar los archivos VHD/X del perfil de usuario desde la cuenta de almacenamiento local. Pero se produce un error en el montaje, ya que estos archivos están bloqueados por el componente de Cloud Cache que se ejecuta en el host de sesión de Virtual Desktop en la región primaria.
En la configuración predeterminada de FSLogix y Cloud Cache, el usuario no puede iniciar sesión y se realiza un seguimiento de un error en los registros de diagnóstico de FSLogix, ERROR_LOCK_VIOLATION 33 (0x21).


Identidad
Una de las dependencias más importantes de Virtual Desktop es la disponibilidad de la identidad de usuario. Para acceder a escritorios virtuales completamente remotos y aplicaciones remotas desde los hosts de sesión, los usuarios deben poder autenticarse. Microsoft Entra ID es el servicio de identidad en la nube centralizado de Microsoft que permite esta funcionalidad. Microsoft Entra ID siempre se usa para autenticar a los usuarios para Virtual Desktop. Los hosts de sesión se pueden unir al mismo inquilino de Microsoft Entra o a un dominio de Active Directory mediante Active Directory Domain Services (AD DS) o Microsoft Entra Domain Services (Microsoft Entra Domain Services), lo que le proporciona una opción de opciones de configuración flexibles.
Microsoft Entra ID
- Es un servicio global de varias regiones y resistente con alta disponibilidad. No se requiere ninguna otra acción en este contexto como parte de un plan de BCDR de Virtual Desktop.
Active Directory Domain Services
- Para que Active Directory Domain Services sea resistente y de alta disponibilidad, incluso si hay un desastre en toda la región, debe implementar al menos dos controladores de dominio (DC) en la región primaria de Azure. Estos controladores de dominio deben estar en diferentes zonas de disponibilidad, si es posible, y debe garantizar la replicación adecuada con la infraestructura de la región secundaria y, finalmente, en el entorno local. Debe crear al menos un controlador de dominio más en la región secundaria con el catálogo global y los roles de DNS. Para obtener más información, consulte Implementación de Active Directory Domain Services (AD DS) en una red virtual de Azure.
Microsoft Entra Connect
Si usa Microsoft Entra ID con Active Directory Domain Services y, a continuación, Microsoft Entra Connect para sincronizar los datos de identidad de usuario entre Active Directory Domain Services y Microsoft Entra ID, debe tener en cuenta la resistencia y la recuperación de este servicio para la protección frente a un desastre permanente.
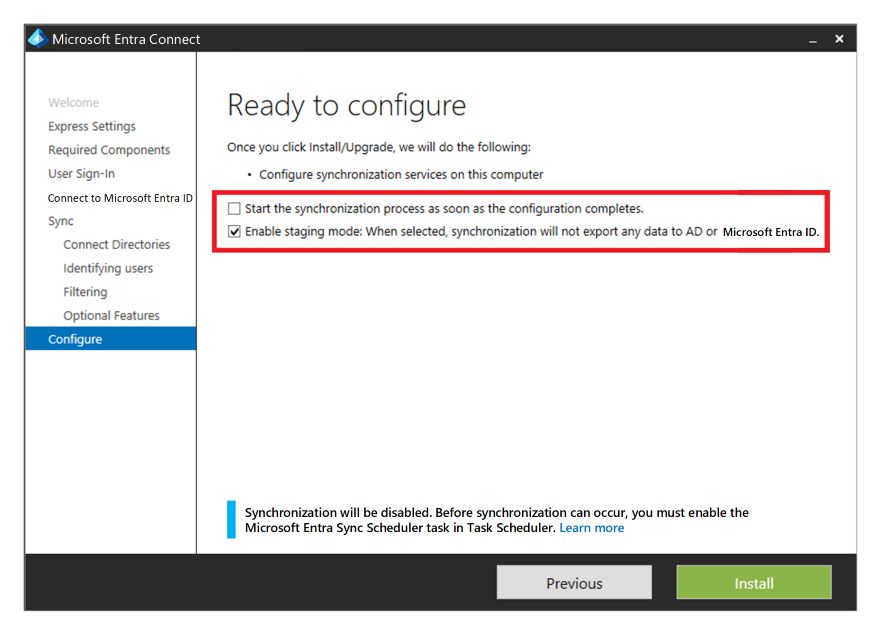
Puede proporcionar alta disponibilidad y recuperación ante desastres mediante la instalación de una segunda instancia del servicio en la región secundaria y la habilitación del modo de almacenamiento provisional.
Si hay una recuperación, el administrador debe promover la instancia secundaria quitándola del modo de almacenamiento provisional. Debe seguir el mismo procedimiento que al colocar un servidor en modo de almacenamiento provisional. Las credenciales de administrador global de Microsoft Entra son necesarias para realizar esta configuración.
Servicios de dominio de Microsoft Entra
- Puede usar Microsoft Entra Domain Services en algunos escenarios como alternativa a Active Directory Domain Services.
- Ofrece alta disponibilidad.
- Si la recuperación ante desastres geográfica está en el ámbito de su escenario, debe implementar otra réplica en la región secundaria de Azure mediante un conjunto de réplicas. También puede usar esta característica para aumentar la alta disponibilidad en la región primaria.
Diagramas de arquitectura
Grupo de hosts personal

Descargue un archivo Visio de esta arquitectura.
Grupo de hosts agrupado

Descargue un archivo Visio de esta arquitectura.
Conmutación por error y conmutación por recuperación
Escenario de grupo de hosts personal
Nota
En esta sección, solo se trata el modelo activo-pasivo; un modelo activo-activo no requiere conmutación por error ni intervención del administrador.
La conmutación por error y la conmutación por recuperación de un grupo de hosts personal es diferente, ya que no se usan Cloud Cache ni almacenamiento externo para los contenedores de perfiles y de Office. Todavía puede usar la tecnología de FSLogix para guardar los datos en un contenedor desde el host de sesión. No hay ningún grupo de hosts secundario en la región de recuperación ante desastres, por lo que no es necesario crear más áreas de trabajo ni recursos de Virtual Desktop para replicar y alinear. Puede usar Site Recovery para replicar las máquinas virtuales del host de sesión.
Puede usar Site Recovery en varios escenarios diferentes. Para Virtual Desktop, use la arquitectura de recuperación ante desastres de Azure en Azure con Azure Site Recovery.
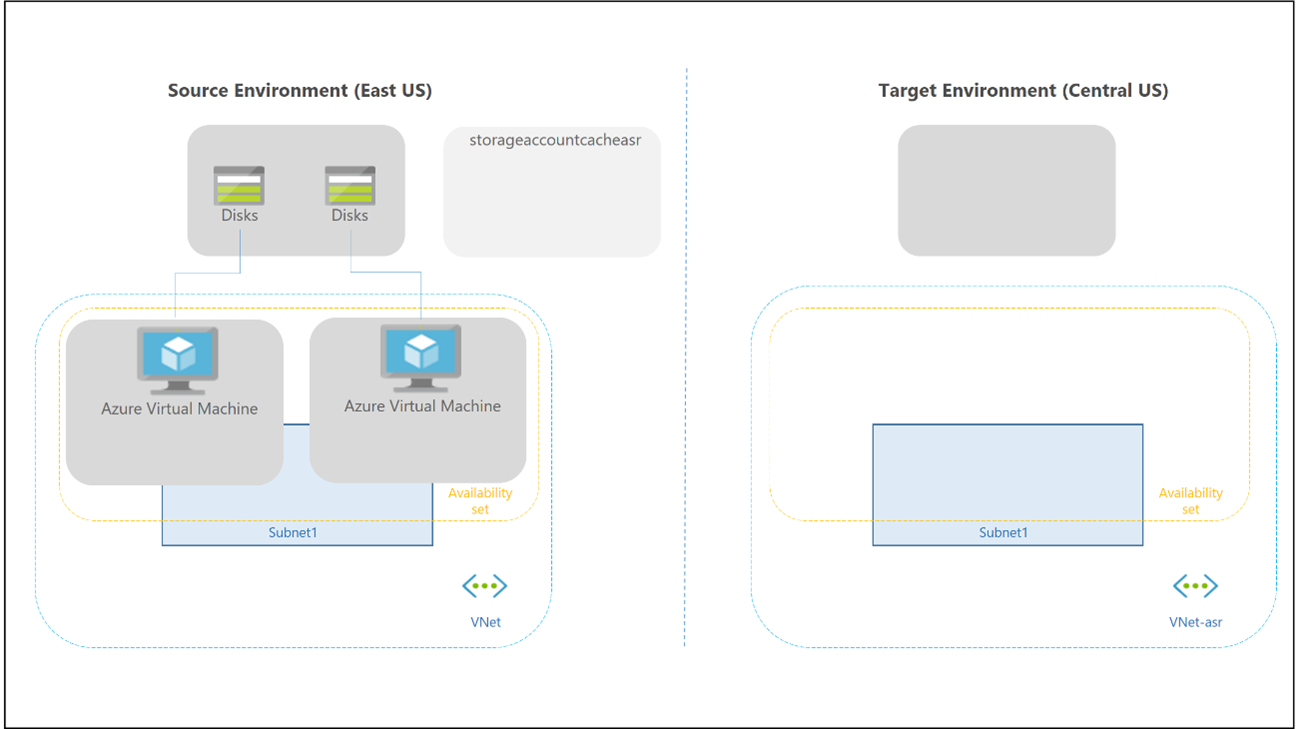
Se aplican las siguientes consideraciones y recomendaciones:
- La conmutación por error de Site Recovery no es automática: un administrador debe desencadenarla mediante el uso de Azure Portal, Powershell o la API.
- Puede crear scripts y automatizar toda la configuración y las operaciones de Site Recovery mediante PowerShell.
- Site Recovery tiene un RTO declarado en su acuerdo de nivel de servicio (SLA). La mayoría de las veces, Site Recovery puede conmutar por error las máquinas virtuales en cuestión de minutos.
- Puede usar Site Recovery con Azure Backup. Para más información, consulte Compatibilidad para usar Site Recovery con Azure Backup.
- Debe habilitar Site Recovery en el nivel de máquina virtual, ya que no hay integración directa en la experiencia del portal de Virtual Desktop. También debe desencadenar la conmutación por error y la conmutación por recuperación en el nivel de máquina virtual individual.
- Site Recovery proporciona funcionalidad de conmutación por error de prueba en una subred independiente para máquinas virtuales generales de Azure. No use esta característica para las máquinas virtuales de Virtual Desktop, ya que tendría dos hosts de sesión de Virtual Desktop idénticos que llaman al plano de control del servicio al mismo tiempo.
- Site Recovery no mantiene las extensiones de máquina virtual durante la replicación. Si habilita extensiones personalizadas para las máquinas virtuales del host de sesión de Virtual Desktop, debe volver a habilitar las extensiones después de la conmutación por error o la conmutación por recuperación. Las extensiones integradas de Virtual Desktop joindomain y Microsoft.PowerShell.DSC solo se usan cuando se crea una máquina virtual de host de sesión. Es seguro perderlas después de una primera conmutación por error.
- Asegúrese de revisar la matriz de compatibilidad para la recuperación ante desastres de máquinas virtuales de Azure entre regiones de Azure y comprobar los requisitos, las limitaciones y la matriz de compatibilidad del escenario de recuperación ante desastres de Azure a Azure con Site Recovery, especialmente las versiones admitidas del sistema operativo.
- Al conmutar por error una máquina virtual de una región a otra, esta se inicia en la región de recuperación ante desastres de destino con un estado no protegido. La conmutación por recuperación es posible, pero el usuario debe volver a proteger las máquinas virtuales de la región secundaria y, a continuación, habilitar la replicación en la región primaria.
- Ejecute pruebas periódicas de los procedimientos de conmutación por error y conmutación por recuperación. Después, documente una lista exacta de los pasos y las acciones de recuperación en función de su entorno específico de Virtual Desktop.
Escenario de grupo de hosts agrupado
Una de las características deseadas de un modelo de recuperación ante desastres activo-activo es que no es necesaria la intervención del administrador para recuperar el servicio si hay una interrupción. Los procedimientos de conmutación por error solo son necesarios en una arquitectura activo-pasivo.
En un modelo activo-pasivo, la región de recuperación ante desastres secundaria debe estar inactiva, con unos recursos mínimos configurados y activos. La configuración se debe mantener alineada con la región primaria. Si hay una conmutación por error, las reasignaciones de todos los usuarios a todos los grupos de escritorio y aplicaciones para las aplicaciones remotas del grupo de hosts de recuperación ante desastres secundario se producen al mismo tiempo.
Es posible tener un modelo activo-activo y una conmutación por error parcial. Si el grupo de hosts solo se usa para proporcionar grupos de escritorio y de aplicaciones, puede particionar a los usuarios en varios grupos de Active Directory no superpuestos y reasignar el grupo a grupos de aplicaciones y de escritorio de los grupos de hosts de recuperación ante desastres primario o secundario. Un usuario no debe tener acceso a ambos grupos de hosts al mismo tiempo. Si hay varios grupos de aplicaciones y aplicaciones, es posible que los grupos de usuarios que use para asignar usuarios se superpongan. En este caso, es difícil implementar una estrategia activo-activo. Cada vez que un usuario inicia una aplicación remota en el grupo de hosts primario, FSLogix carga el perfil de usuario en una máquina virtual de host de sesión. Intentar hacer lo mismo en el grupo de hosts secundario podría provocar un conflicto en el disco del perfil subyacente.
Advertencia
De manera predeterminada, la configuración del registro de FSLogix prohíbe el acceso simultáneo al mismo perfil de usuario desde varias sesiones. En este escenario de BCDR, no debe cambiar este comportamiento y dejar un valor de 0 para la clave del Registro ProfileType.
Esta es la situación inicial y las suposiciones de configuración:
- Los grupos de hosts de la región primaria y las regiones de recuperación ante desastres secundarias se alinean durante la configuración, incluido Cloud Cache.
- En los grupos de hosts, se ofrecen a los usuarios tanto el escritorio DAG1 como APPG2 y los grupos de aplicaciones remotas APPG3.
- En el grupo de hosts de la región primaria, se usan los grupos de usuarios de Active Directory GRP1, GRP2 y GRP3 para asignar los usuarios a DAG1, APPG2 y APPG3. Estos grupos pueden tener pertenencias de usuario superpuestas, pero dado que el modelo aquí usa activo-pasivo con conmutación por error completa, no es un problema.
En los pasos siguientes, se describe cuándo se produce una conmutación por error, después de una recuperación ante desastres planeada o no planeada.
- En el grupo de hosts primario, quite las asignaciones de usuario de los grupos GRP1, GRP2 y GRP3 para los grupos de aplicaciones DAG1, APPG2 y APPG3.
- Hay una desconexión forzada para todos los usuarios conectados del grupo de hosts primario.
- En el grupo de hosts secundario, donde están configurados los mismos grupos de aplicaciones, debe conceder acceso de usuario a DAG1, APPG2 y APPG3 mediante los grupos GRP1, GRP2 y GRP3.
- Revise y ajuste la capacidad del grupo de hosts en la región secundaria. En este caso, es posible que quiera confiar en un plan de autoescala para encender automáticamente los hosts de sesión. También puede iniciar manualmente los recursos necesarios.
Los pasos y el flujo de la conmutación por recuperación son similares y puede ejecutar todo el proceso varias veces. Cloud Cache y la configuración de las cuentas de almacenamiento garantizan que se repliquen los datos del contenedor de perfiles y de Office. Antes de la conmutación por recuperación, asegúrese de que se recuperan la configuración del grupo de hosts y los recursos de proceso. Para la parte del almacenamiento, si se produce una pérdida de datos en la región primaria, Cloud Cache replica los datos del contenedor de perfiles y de Office desde el almacenamiento de la región secundaria.
También es posible implementar un plan de conmutación por error de prueba con algunos cambios de configuración, sin afectar al entorno de producción.
- Cree algunas cuentas de usuario nuevas en Active Directory para producción.
- Cree un nuevo grupo de Active Directory llamado GRP-TEST y asigne usuarios.
- Asigne acceso a DAG1, APPG2 y APPG3 mediante el grupo GRP-TEST.
- Proporcione instrucciones a los usuarios del grupo GRP-TEST para probar las aplicaciones.
- Pruebe el procedimiento de conmutación por error mediante el grupo GRP-TEST para quitar el acceso del grupo de hosts primario y conceder acceso al grupo de recuperación ante desastres secundario.
Recomendaciones importantes:
- Automatice el proceso de conmutación por error mediante PowerShell, la CLI de Azure u otra API o herramienta disponible.
- Pruebe periódicamente todo el procedimiento de conmutación por error y conmutación por recuperación.
- Realice una comprobación periódica de la alineación de la configuración para asegurarse de que los grupos de hosts de la región primaria y la de desastres secundaria están sincronizados.
Backup
Una suposición en esta guía es que hay división de perfiles y separación de datos entre los contenedores de perfiles y los contenedores de Office. FSLogix permite esta configuración y el uso de cuentas de almacenamiento independientes. Una vez en cuentas de almacenamiento independientes, puede usar diferentes directivas de copia de seguridad.
Para el contenedor de ODFC, si el contenido representa solo datos almacenados en caché que se pueden volver a crear desde el almacén de datos en línea, como Microsoft 365, no es necesario hacer una copia de seguridad de los datos.
Si es necesario hacer una copia de seguridad de los datos del contenedor de Office, puede usar un almacenamiento menos costoso o un período de retención y una frecuencia de copia de seguridad diferentes.
Para un tipo de grupo de hosts personal, debe ejecutar la copia de seguridad en el nivel de máquina virtual del host de sesión. Este método solo se aplica si los datos se almacenan localmente.
Si usa OneDrive y la redirección de carpetas conocidas, es posible que desaparezca el requisito de guardar los datos dentro del contenedor.
Nota
La copia de seguridad de OneDrive no se tiene en cuenta en este artículo y escenario.
A menos que haya otro requisito, la copia de seguridad del almacenamiento en la región primaria debe ser suficiente. La copia de seguridad del entorno de recuperación ante desastres no se usa normalmente.
Para un recurso compartido de Azure Files, use Azure Backup.
- Para el tipo de resistencia del almacén, use el almacenamiento con redundancia de zona si no es necesario el almacenamiento de la copia de seguridad fuera del sitio o la región. Si se requieren esas copias de seguridad, use el almacenamiento con redundancia geográfica.
Azure NetApp Files proporciona su propia solución de copia de seguridad integrada.
- Asegúrese de comprobar la disponibilidad de características de la región, junto con los requisitos y las limitaciones.
Las cuentas de almacenamiento independientes que se usan para MSIX también deben estar cubiertas por una copia de seguridad si los repositorios de paquetes de aplicación no se pueden volver a crear fácilmente.
Colaboradores
Microsoft mantiene este artículo. Originalmente lo escribieron los siguientes colaboradores.
Creadores de entidad de seguridad:
- Ben Martin Baur | Arquitecto de soluciones en la nube
- Igor Pagliai | Ingeniero principal de FastTrack for Azure (FTA)
Otros colaboradores:
- Nelson Del Villar | Arquitecto de soluciones en la nube, Infraestructura básica de Azure
- Jason Martinez | Escritor técnico
Pasos siguientes
- Plan de recuperación ante desastres de Virtual Desktop
- Continuidad empresarial y recuperación ante desastres para Virtual Desktop - Cloud Adoption Framework
- Cloud Cache para crear resistencia y disponibilidad