Entrenamiento de un modelo de reconocimiento del lenguaje conversacional
Una vez que haya completado el etiquetado de las expresiones, puede iniciar el entrenamiento de un modelo. El entrenamiento es el proceso en el que el modelo aprende de las expresiones etiquetadas.
Para entrenar un modelo, inicie un trabajo de entrenamiento. Solo los trabajos completados correctamente crean un modelo. Los trabajos de entrenamiento expiran después de siete días, después de este tiempo ya no podrá recuperar los detalles del trabajo. Si el trabajo de entrenamiento se completó correctamente y se creó un modelo, éste no se verá afectado por la expiración del trabajo. Solo puede tener un trabajo de entrenamiento ejecutándose a la vez y no puede iniciar otros trabajos en el mismo proyecto.
Los tiempos de entrenamiento pueden ir desde unos pocos segundos cuando se trata de proyectos sencillos, hasta un par de horas cuando se alcanza el límite máximo de expresiones.
La evaluación del modelo se desencadena automáticamente después de que el entrenamiento se haya completado correctamente. El proceso de evaluación se inicia mediante el modelo entrenado para ejecutar predicciones en las expresiones del conjunto de pruebas y compara los resultados previstos con las etiquetas proporcionadas (que establecen una línea base de verdad).
Prerrequisitos
- Un proyecto creado correctamente con una cuenta de Azure Blob Storage configurada
- Expresiones con etiqueta
Equilibrar los datos de entrenamiento
En lo que respecta a los datos de entrenamiento, intente mantener el esquema bien equilibrado. La inclusión de grandes cantidades de una intención y muy pocas de otras da como resultado un modelo sesgado hacia intenciones concretas.
Para solucionar este escenario, es posible que tenga que reducir el conjunto de entrenamiento. O bien, es posible que tenga que agregarlo. Para reducir tamaño, puede hacer lo siguiente:
- Deshacerse de un determinado porcentaje de los datos de entrenamiento aleatoriamente.
- Analizar el conjunto de datos y quitar entradas duplicadas sobrerrepresentadas, que es más sistemática.
Para agregar al conjunto de entrenamiento, en Language Studio, en la pestaña Etiquetado de datos, seleccione Sugerir expresiones. Reconocimiento del lenguaje conversacional envía una llamada a Azure OpenAI para generar expresiones similares.

También debe buscar "patrones" no deseados en el conjunto de entrenamiento. Por ejemplo, busque si el conjunto de entrenamiento de una intención determinada está en minúsculas o comienza con una frase determinada. En tales casos, el modelo que entrena podría aprender estos sesgos no deseados en el conjunto de entrenamiento en lugar de ser capaces de generalizar.
Se recomienda introducir la diversidad de mayúsculas y minúsculas en el conjunto de formación. Si se espera que el modelo controle las variaciones, asegúrese de tener un conjunto de entrenamiento que también refleje esa diversidad. Por ejemplo, incluya algunas expresiones en mayúsculas y minúsculas según corresponda.
División de datos
Antes de iniciar el proceso de entrenamiento, las expresiones etiquetadas del proyecto se dividen en un conjunto de entrenamiento y un conjunto de pruebas. Cada uno de ellos sirve una función diferente. El conjunto de entrenamiento se usa para entrenar el modelo, es el conjunto a partir del cual el modelo aprende las expresiones etiquetadas. El conjunto de pruebas es un conjunto ciego que no se introduce en el modelo durante el entrenamiento, sino solo durante la evaluación.
Una vez entrenado el modelo correctamente, éste puede usarse para hacer predicciones a partir de los enunciados del conjunto de pruebas. Estas predicciones se usan para calcular lasmétricas de evaluación. Se recomienda asegurarse de que todos los intentos y entidades se representan adecuadamente tanto en el conjunto de entrenamiento como en el de prueba.
El reconocimiento del lenguaje conversacional admite dos métodos para la división de datos:
- Dividir automáticamente el conjunto de pruebas de los datos de entrenamiento: el sistema dividirá los datos etiquetados entre los conjuntos de entrenamiento y pruebas, según los porcentajes especificados. La división de porcentaje recomendada es del 80 % para el entrenamiento y el 20 % para las pruebas.
Nota
Si elige la opción Automatically splitting the testing set from training data (Dividir automáticamente el conjunto de pruebas de los datos de entrenamiento), solo los datos asignados al conjunto de entrenamiento se dividirán según los porcentajes proporcionados.
- Usar una división manual de los datos de entrenamiento y de prueba: Este método permite a los usuarios definir qué expresiones deben pertenecer a cada conjunto. Este paso solo se activa si se agregan expresiones al conjunto de prueba durante el etiquetado.
Modelo de entrenamiento
CLU admite dos modos para entrenar los modelos
El entrenamiento estándar usa algoritmos de aprendizaje automático rápidos para entrenar los modelos con relativa rapidez. Actualmente solo está disponible para inglés y está deshabilitado para cualquier proyecto que no use inglés (EE. UU.) o inglés (Reino Unido) como su idioma principal. Esta opción de entrenamiento es gratuita. El entrenamiento estándar permite agregar expresiones y probarlas rápidamente sin costo alguno. Las puntuaciones de evaluación que se muestran deben guiarle sobre dónde realizar cambios en el proyecto y agregar más expresiones. Una vez que haya iterado varias veces y realizado mejoras incrementales, puede considerar el uso del entrenamiento avanzado para entrenar otra versión del modelo.
El entrenamiento avanzado usa la última tecnología de aprendizaje automático para personalizar modelos con los datos. Se espera que esto muestre mejores puntuaciones de rendimiento para los modelos y le permitirá usar también las funcionalidades multilingües de CLU. El entrenamiento avanzado tiene un precio diferente. Consulte la información de precios para obtener más información.
Use las puntuaciones de evaluación para guiar sus decisiones. Puede haber ocasiones en las que un ejemplo específico se prediga de forma incorrecta en el entrenamiento avanzado, a diferencia de lo que ocurre cuando se usa el modo de entrenamiento estándar. Sin embargo, si los resultados generales de la evaluación son mejores utilizando el modo avanzado, se recomienda utilizar el modelo final. Si no es el caso y no desea usar ninguna funcionalidad multilingüe, puede seguir usando el modelo entrenado con el modo estándar.
Nota
Debería esperar ver una diferencia en los comportamientos de las puntuaciones de confianza de la intención entre los modos de entrenamiento, ya que cada algoritmo calibra sus puntuaciones de forma diferente.
Entrenamiento de un modelo
Para empezar a entrenar el modelo desde Language Studio:
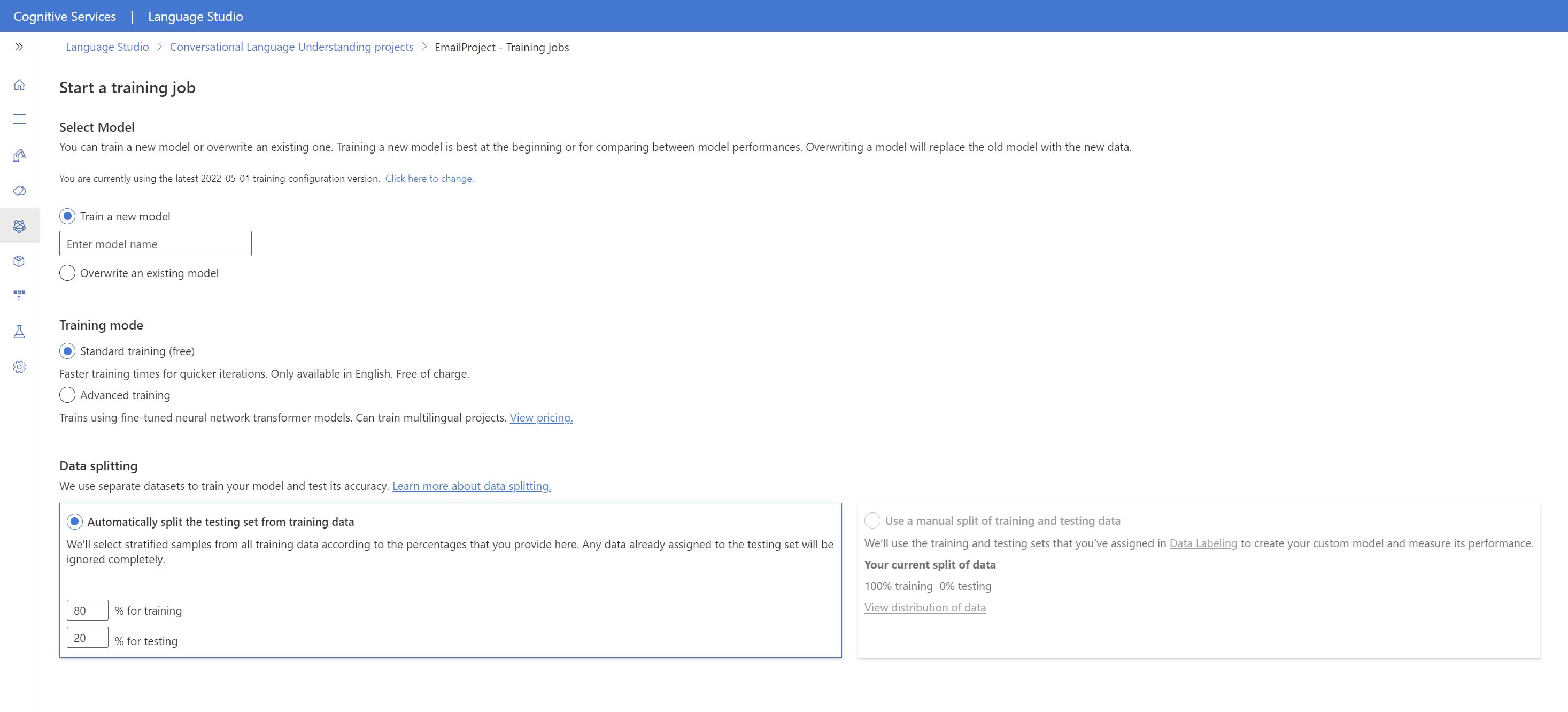
Seleccione Entrenar modelo en el menú de la izquierda.
Seleccione Iniciar un trabajo de entrenamiento en el menú superior.
Seleccione Entrenar un nuevo modelo y escriba el nombre del nuevo modelo en el cuadro de texto. De lo contrario, para reemplazar un modelo existente por un modelo entrenado en los nuevos datos, seleccione Sobrescribir un modelo existente y, a continuación, seleccione un modelo existente. La sobrescritura de un modelo entrenado es irreversible, pero no afectará a los modelos implementados hasta que implemente el nuevo modelo.
Seleccionar datos de entrenamiento. Puede elegir Entrenamiento estándar para un entrenamiento más rápido, pero solo está disponible para inglés. También puede elegir Formación avanzada compatible con otros idiomas y proyectos multilingües, pero implica tiempos de entrenamiento más largos. Más información sobre los modos de entrenamiento.
Seleccione un método de división de datos. Puede elegir Dividir automáticamente el conjunto de pruebas de los datos de entrenamiento, y el sistema dividirá las expresiones entre los conjuntos de entrenamiento y pruebas, según los porcentajes especificados. También puede usar una división manual de datos de entrenamiento y pruebas; esta opción solo se habilita si han agregado expresiones al conjunto de pruebas al etiquetar las expresiones.
Seleccione el botón Entrenar.
Seleccione el identificador del trabajo de entrenamiento de la lista. Aparecerá un panel en el que podrá comprobar el progreso del entrenamiento, el estado del trabajo y otros detalles de este trabajo.
Nota
- Los trabajos de entrenamiento completados correctamente serán los únicos que generarán modelos.
- El entrenamiento puede durar entre un par de minutos y un par de horas en función del número de expresiones.
- Solo puede haber un trabajo de entrenamiento ejecutándose en un momento dado. No se pueden iniciar otros trabajos de entrenamiento dentro del mismo proyecto hasta que se complete el trabajo en ejecución.
- El aprendizaje automático que se usa para entrenar modelos se actualiza periódicamente. Para entrenar en una versión de configuración anterior, seleccione Seleccione aquí para cambiar en la página Iniciar un trabajo de entrenamiento y elija una versión anterior.

Cancelación del trabajo de entrenamiento
Para cancelar un trabajo de entrenamiento desde Language Studio
- En la página Modelo de entrenamiento, seleccione el trabajo de entrenamiento que desea cancelar y seleccione Cancelar en el menú superior.