La máquina virtual Linux de Azure no arranca después de aplicar los cambios del kernel.
Se aplica a: ✔️ Máquinas virtuales Linux
Nota:
CentOS al que se hace referencia en este artículo es una distribución de Linux y llegará al final del ciclo de vida (EOL). Tenga en cuenta su uso y planifique en consecuencia. Para obtener más información, consulte Guía de fin de vida de CentOS.
En este artículo se proporcionan soluciones a un problema en el que una máquina virtual Linux no se puede arrancar después de aplicar los cambios del kernel.
Requisitos previos
Asegúrese de que la consola serie está habilitada y funcional en la máquina virtual Linux.
Identificación del problema de arranque relacionado con el kernel
Para identificar un problema de arranque relacionado con el kernel, compruebe la cadena de pánico del kernel específica. Para ello, use la CLI de Azure o Azure Portal para ver la salida del registro de la consola serie de la máquina virtual en el panel de diagnóstico de arranque o en el panel de consola serie.
Un error de pánico del kernel es similar al siguiente resultado y se mostrará al final del registro de la consola serie:
Probing EDD (edd=off to disable)... ok
Memory KASLR using RDRAND RDTSC...
[ 300.206297] Kernel panic - xxxxxxxx
[ 300.207216] CPU: 1 PID: 1 Comm: swapper/0 Tainted: G ------------ T 3.xxx.x86_64 #1
Solución de problemas en línea
Sugerencia
Si tiene una copia de seguridad reciente de la máquina virtual, restaure la máquina virtual desde la copia de seguridad para corregir el problema de arranque.
La consola serie es el método más rápido para resolver el problema de arranque. Permite corregir directamente el problema sin tener que presentar el disco del sistema a una máquina virtual de recuperación. Asegúrese de cumplir los requisitos previos necesarios para la distribución. Para más información, consulte Consola serie de máquina virtual para Linux.
Identifique el problema de arranque específico relacionado con el kernel.
Use la consola serie de Azure para interrumpir la máquina virtual en el menú GRUB y seleccionar cualquier kernel anterior para arrancarla. Para obtener más información, consulte Sistema de arranque en la versión anterior del kernel.
Vaya a la sección correspondiente para resolver el problema de arranque específico relacionado con el kernel:
Una vez resuelto el problema de arranque relacionado con el kernel, reinicie la máquina virtual para que pueda arrancar a través de la versión más reciente del kernel.
Solución de problemas sin conexión
Sugerencia
Si tiene una copia de seguridad reciente de la máquina virtual, restaure la máquina virtual desde la copia de seguridad para corregir el problema de arranque.
Si la consola serie de Azure no funciona en la máquina virtual específica o no es una opción de la suscripción, solucione el problema de arranque mediante una máquina virtual de rescate o reparación. Para ello, siga estos pasos:
Utilice comandos de reparación de VM para crear una VM de reparación que tenga adjunta una copia del disco del SO de la VM afectada. Monte la copia de los sistemas de archivos del SO en la VM de reparación mediante chroot.
Nota:
Como alternativa, puede crear una máquina virtual de rescate manualmente mediante el Azure Portal. Para más información, consulte Solución de problemas de una máquina virtual Linux mediante la conexión del disco del sistema operativo a una máquina virtual de recuperación mediante el Azure Portal.
Identifique el problema de arranque específico relacionado con el kernel.
Vaya a la sección correspondiente para resolver el problema de arranque específico relacionado con el kernel:
Una vez resuelto el problema de arranque relacionado con el kernel, realice las siguientes acciones:
- Salga de chroot.
- Desmonte la copia de los sistemas de archivos de la máquina virtual de rescate/reparación.
- Ejecute el comando
az vm repair restorepara intercambiar el disco de SO reparado con el disco de SO original de la VM. Para obtener más documentación e instrucciones, vea el paso 5 en Reparar una máquina virtual de Windows mediante los comandos de reparación de máquinas virtuales de Azure. - Valide si la máquina virtual puede arrancar echando un vistazo a la consola serie de Azure o intentando conectarse a la máquina virtual.
Si faltan contenidos importantes relacionados con el kernel, falta toda
/bootla partición u otro contenido importante y no se pueden recuperar, se recomienda restaurar la máquina virtual a partir de una copia de seguridad. Para obtener más información, consulte Cómo restaurar los datos de Azure VM en el portal de Azure.
Sistema de arranque en la versión anterior del kernel
Uso de la consola serie de Azure
Reinicie la máquina virtual mediante la consola serie de Azure.
- Seleccione el botón apagar situado en la parte superior de la ventana de la consola serie.
- Seleccione la opción Reiniciar máquina virtual (duro).
Una vez que se reanude la conexión de la consola serie, verá un contador de cuenta atrás en la esquina superior izquierda de la ventana de la consola serie. Presione la tecla ESCAPE para interrumpir la máquina virtual en el menú GRUB.
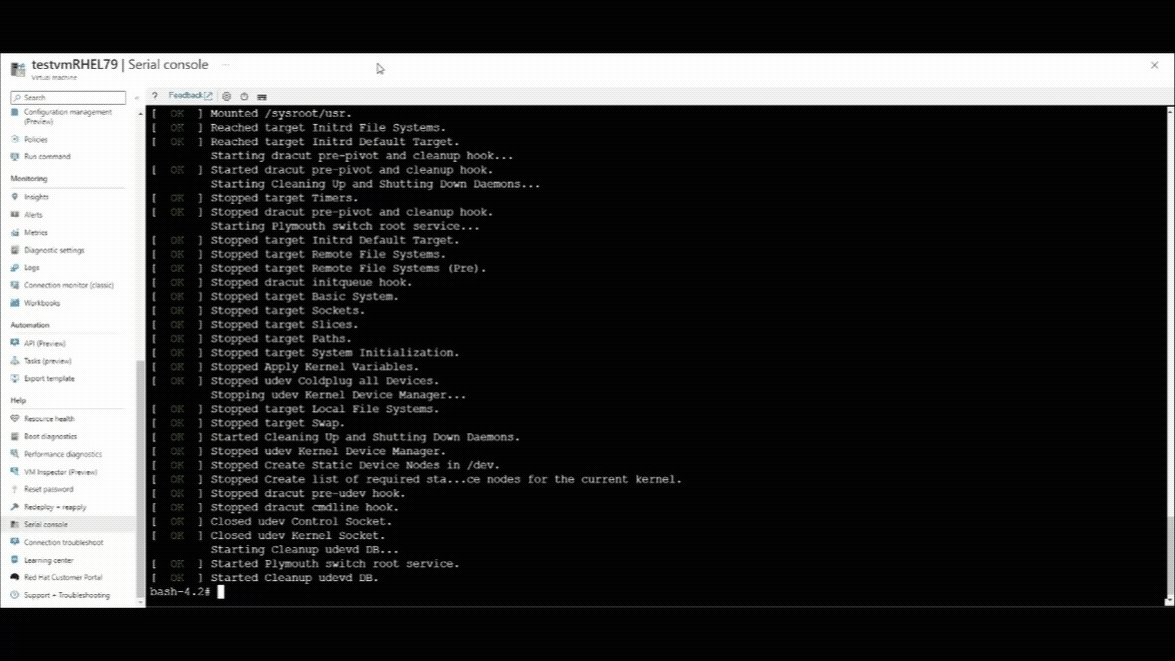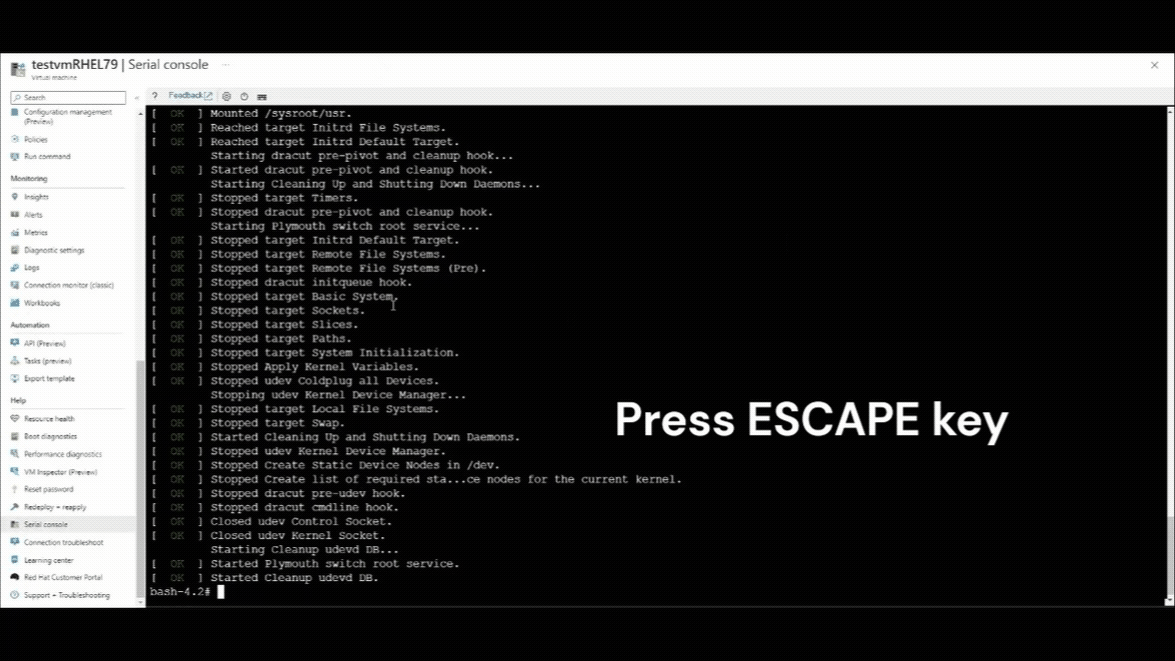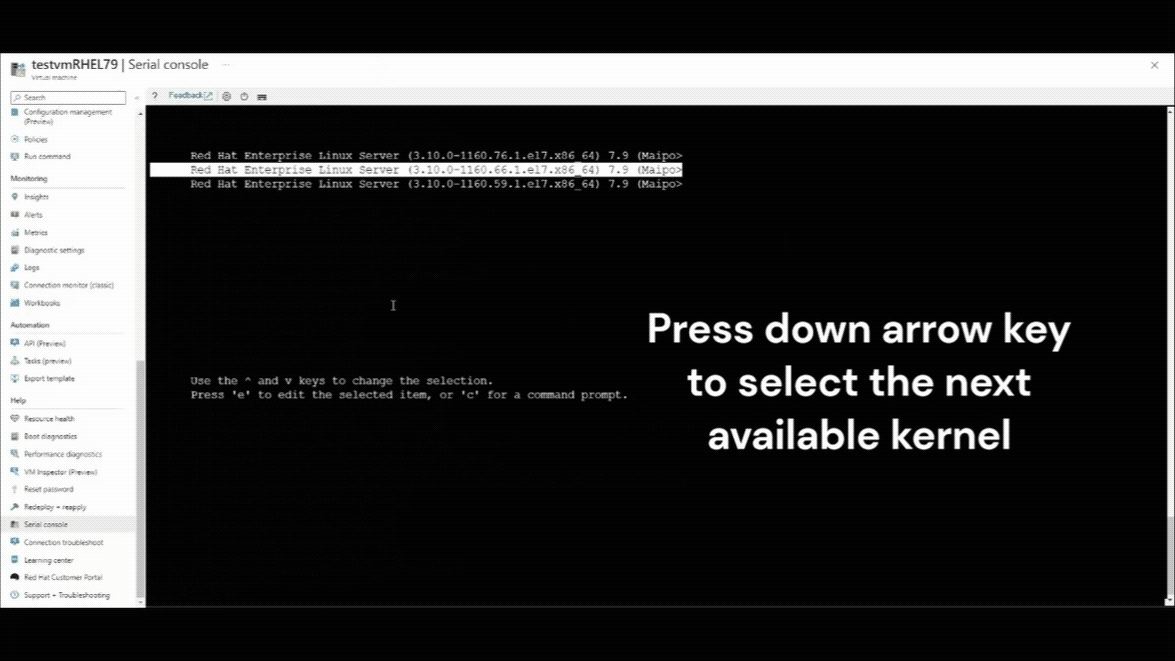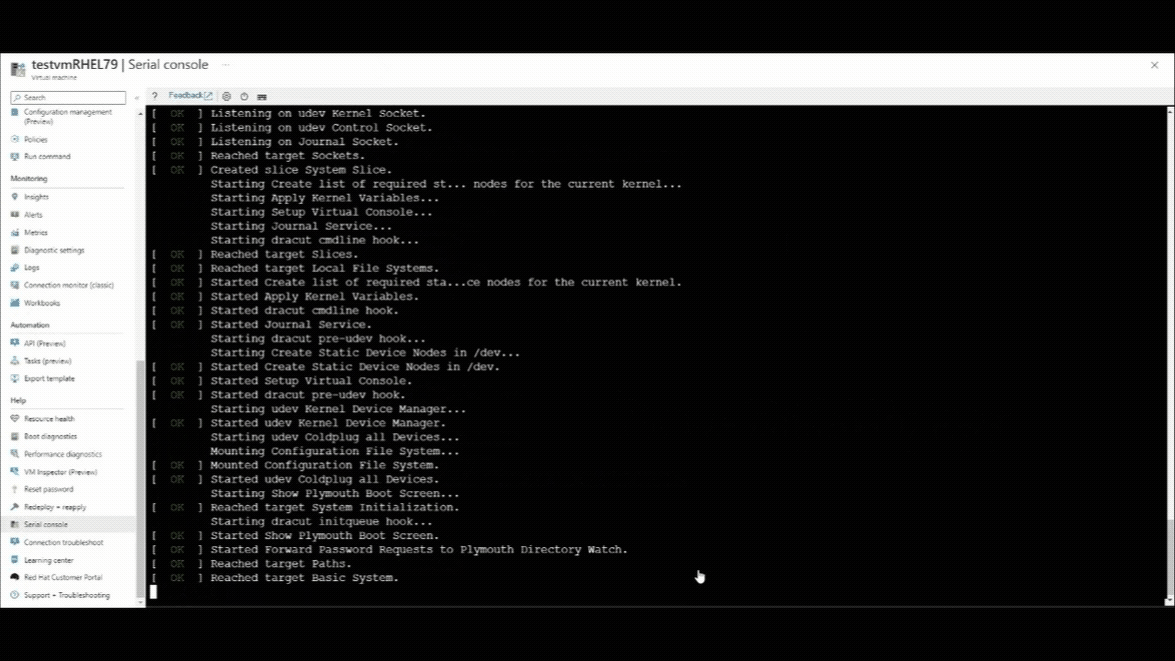
Presione la tecla de flecha abajo para seleccionar cualquier versión anterior del kernel.
Cambie la
GRUB_DEFAULTvariable en el archivo /etc/default/grub como se indica en Cambio manual de la versión predeterminada del kernel. Se trata de un cambio persistente.

Nota:
Si solo aparece una versión del kernel en el menú GRUB, siga el enfoque de solución de problemas sin conexión para solucionar este problema desde una máquina virtual de reparación.
Uso de máquinas virtuales de reparación (scripts ALAR)
Ejecute el siguiente comando de Bash en Azure Cloud Shell para crear una máquina virtual de reparación. Para más información, consulte Uso de la reparación automática de Linux (ALAR) de Azure para corregir una máquina virtual Linux: opción de kernel.
az vm repair create --verbose -g $RGNAME -n $VMNAME --repair-username rescue --repair-password 'password!234' --copy-disk-name repairdiskcopyEjecute el siguiente comando para reemplazar el kernel roto por la versión instalada anteriormente:
az vm repair run --verbose -g $RGNAME -n $VMNAME --run-id linux-alar2 --parameters kernel --run-on-repair az vm repair restore --verbose -g $RGNAME -n $VMNAME
Nota:
Si solo hay una versión del kernel instalada en el sistema, siga el enfoque de solución de problemas sin conexión para solucionar este problema desde una máquina virtual de reparación.
Cambio manual de la versión predeterminada del kernel
Para modificar la versión predeterminada del kernel desde una máquina virtual de reparación (dentro de chroot) o en una máquina virtual en ejecución, siga estos pasos:
Nota:
Si se realiza una reversión de degradación del kernel, seleccione la versión de kernel más reciente en lugar de la anterior.
RHEL 7, Oracle Linux 7 y CentOS 7
Valide la lista de kernels disponibles en el archivo de configuración de GRUB ejecutando uno de los siguientes comandos:
Máquinas virtuales de Gen1:
cat /boot/grub2/grub.cfg | grep menuentryMáquinas virtuales de Gen2:
cat /boot/efi/EFI/*/grub.cfg | grep menuentry
Establezca el nuevo kernel predeterminado y especifique el título del kernel correspondiente ejecutando el siguiente comando:
# grub2-set-default 'Red Hat Enterprise Linux Server, with Linux 3.10.0-123.el7.x86_64'Nota:
Reemplace por
Red Hat Enterprise Linux Server, with Linux 3.10.0-123.el7.x86_64el título de entrada de menú correspondiente.Compruebe que el nuevo kernel predeterminado es el deseado ejecutando el siguiente comando:
grub2-editenv listAsegúrese de que el valor de la
GRUB_DEFAULTvariable en el archivo /etc/default/grub está establecidosaveden . Para modificarlo, asegúrese de regenerar el archivo de configuración de GRUB para aplicar los cambios.
RHEL 8/9 y CentOS 8
Para enumerar los kernels disponibles, ejecute el siguiente comando:
ls -l /boot/vmlinuz-*Establezca el nuevo kernel predeterminado ejecutando el siguiente comando:
grubby --set-default /boot/vmlinuz-4.18.0-372.19.1.el8_6.x86_64Nota:
Reemplace por
4.18.0-372.19.1.el8_6.x86_64la versión del kernel correspondiente.Compruebe que el nuevo kernel predeterminado es el deseado ejecutando el siguiente comando:
grubby --default-kernel
SLES 12/15, Ubuntu 18.04/20.04
Para enumerar los kernels disponibles en el archivo de configuración de GRUB, ejecute el siguiente comando:
Máquinas virtuales de Gen1:
SLES 12/15:
cat /boot/grub2/grub.cfg | grep menuentryUbuntu 18.04/20.04:
cat /boot/grub/grub.cfg | grep menuentry
Máquinas virtuales de Gen2:
cat /boot/efi/EFI/*/grub.cfg | grep menuentry
Establezca el nuevo kernel predeterminado modificando el valor de la
GRUB_DEFAULTvariable en el archivo /etc/default/grub . Para la versión de kernel más reciente instalada en el sistema, el valor predeterminado es 0. El siguiente kernel disponible se establece en "1>2".vi /etc/default/grub GRUB_DEFAULT="1>2"Nota:
Para obtener más información sobre cómo configurar la
GRUB_DEFAULTvariable, consulte SUSE Boot Loader GRUB2 y Ubuntu Grub2/Setup. Como referencia: el valor de menuentry de nivel superior es 0, el primer valor de submenú de nivel superior es 1 y cada valor de menuentry anidado comienza por 0. Por ejemplo, "1>2" es el tercer menú del primer submenú.Vuelva a generar el archivo de configuración de GRUB para aplicar los cambios. Siga las instrucciones de Reinstalar GRUB y volver a generar el archivo de configuración de GRUB para la distribución de Linux y la generación de máquinas virtuales correspondientes.
Pánico del kernel: no sincronización: VFS: no se puede montar la raíz fs en un bloque desconocido(0,0)
Este error se produce debido a una actualización reciente del sistema (kernel). Normalmente se ve en distribuciones basadas en RHEL. Puede identificar este problema desde la consola serie de Azure. Verá cualquiera de los siguientes mensajes de error:
"Kernel panic - not syncing: VFS: Unable to mount root fs on unknown-block(0,0)"
[ 301.026129] Kernel panic - not syncing: VFS: Unable to mount root fs on unknown-block(0,0) [ 301.027122] CPU: 0 PID: 1 Comm: swapper/0 Tainted: G ------------ T 3.10.0-1160.36.2.el7.x86_64 #1 [ 301.027122] Hardware name: Microsoft Corporation Virtual Machine/Virtual Machine, BIOS 090008 12/07/2018 [ 301.027122] Call Trace: [ 301.027122] [<ffffffff82383559>] dump_stack+0x19/0x1b [ 301.027122] [<ffffffff8237d261>] panic+0xe8/0x21f [ 301.027122] [<ffffffff8298b794>] mount_block_root+0x291/0x2a0 [ 301.027122] [<ffffffff8298b7f6>] mount_root+0x53/0x56 [ 301.027122] [<ffffffff8298b935>] prepare_namespace+0x13c/0x174 [ 301.027122] [<ffffffff8298b412>] kernel_init_freeable+0x222/0x249 [ 301.027122] [<ffffffff8298ab28>] ? initcall_blcklist+0xb0/0xb0 [ 301.027122] [<ffffffff82372350>] ? rest_init+0x80/0x80 [ 301.027122] [<ffffffff8237235e>] kernel_init+0xe/0x100 [ 301.027122] [<ffffffff82395df7>] ret_from_fork_nospec_begin+0x21/0x21 [ 301.027122] [<ffffffff82372350>] ? rest_init+0x80/0x80 [ 301.027122] Kernel Offset: 0xc00000 from 0xffffffff81000000 (relocation range: 0xffffffff80000000-0xffffffffbfffffff)"error: no se encontró el archivo '/initramfs-*.img'
error: no se encontró el archivo '/initramfs-3.10.0-1160.36.2.el7.x86_64.img'.
Este tipo de error indica que el archivo initramfs no se genera, el archivo de configuración de GRUB tiene la entrada initrd que falta después de un proceso de aplicación de revisiones o una configuración incorrecta manual de GRUB.
Antes de reiniciar un servidor, se recomienda validar la configuración y /boot el contenido de GRUB si hay una actualización del kernel ejecutando uno de los comandos siguientes. Es importante asegurarse de que la actualización se realiza y no faltan archivos initramfs.
Basado en BIOS: sistemas Gen1
# ls -l /boot # cat /boot/grub2/grub.cfgBasado en UEFI: sistemas Gen2
# ls -l /boot # cat /boot/efi/EFI/*/grub.cfg
Regeneración de initramfs que faltan mediante scripts ALAR de máquina virtual de reparación de Azure
Cree una máquina virtual de reparación mediante la ejecución de la siguiente línea de comandos de Bash con Azure Cloud Shell. Para más información, consulte Uso de la reparación automática de Linux (ALAR) de Azure para corregir una máquina virtual Linux: opción initrd.
az vm repair create --verbose -g $RGNAME -n $VMNAME --repair-username rescue --repair-password 'password!234' --copy-disk-name repairdiskcopyVuelva a generar la imagen initrd/initramfs y vuelva a generar el archivo de configuración de GRUB si falta la entrada initrd. Para ello, ejecute el siguiente comando:
az vm repair run --verbose -g $RGNAME -n $VMNAME --run-id linux-alar2 --parameters initrd --run-on-repair az vm repair restore --verbose -g $RGNAME -n $VMNAMEUna vez ejecutado el comando restore, reinicie la máquina virtual original y compruebe que puede arrancar.
Regeneración manual de initramfs que faltan
Importante
- Si puede arrancar la máquina virtual mediante una versión anterior del kernel o dentro de chroot desde la máquina virtual de reparación o rescate, vuelva a generar initramfs que falta manualmente.
- Para volver a generar initramfs que faltan manualmente desde una máquina virtual de reparación, asegúrese de que ya se ha seguido el paso 1 en Solución de problemas sin conexión y de que esos comandos se ejecutan dentro de chroot.
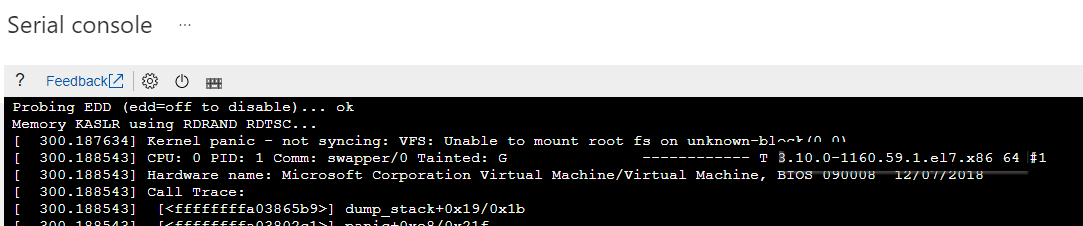
Identifique la versión específica del kernel que tiene problemas con el arranque. Puede extraer la información de versión del error de pánico del kernel correspondiente.
Consulte la captura de pantalla siguiente como ejemplo. El error de pánico del kernel muestra que la versión del kernel es "3.10.0-1160.59.1.el7.x86_64":
Vuelva a generar el archivo initramfs que falta ejecutando uno de los siguientes comandos:
RHEL/CentOS/Oracle Linux 7/8
sudo depmod -a 3.10.0-1160.59.1.el7.x86_64 sudo dracut -f /boot/initramfs-3.10.0-1160.59.1.el7.x86_64.img 3.10.0-1160.59.1.el7.x86_64Importante
Reemplace por
3.10.0-1160.59.1.el7.x86_64la versión del kernel correspondiente.SLES 12/15
sudo depmod -a 5.3.18-150300.38.53-azure sudo dracut -f /boot/initrd-5.3.18-150300.38.53-azure 5.3.18-150300.38.53-azureImportante
Reemplace por
5.3.18-150300.38.53-azurela versión del kernel correspondiente.Ubuntu 18.04
sudo depmod -a 5.4.0-1077-azure sudo mkinitramfs -k -o /boot/initrd.img-5.4.0-1077-azureImportante
Reemplace por
5.4.0-1077-azurela versión del kernel correspondiente.
Vuelva a generar el archivo de configuración de GRUB. Siga las instrucciones de Reinstalar GRUB y volver a generar el archivo de configuración de GRUB para la distribución de Linux y la generación de máquinas virtuales correspondientes.
Si los pasos anteriores se realizan desde una máquina virtual de reparación, siga el paso 3 en Solución de problemas sin conexión. Si los pasos anteriores se realizan desde la consola serie de Azure, siga el método de solución de problemas en línea.
Reinicie la máquina virtual a través de la versión de kernel más reciente.
Pánico del kernel: no sincronización: intento de matar init
Identifique este problema desde la consola serie de Azure. Verá una salida similar a la siguiente:
dracut Warning: Boot has failed. To debug this issue add "rdshell" to the kernel command line.
Kernel panic - not syncing: Attempted to kill init!
Pid: 1, comm: init Not tainted 2.6.32-754.17.1.el6.x86_64 #1
Call Trace:
[<ffffffff81558bfa>] ? panic+0xa7/0x18b
[<ffffffff81130370>] ? perf_event_exit_task+0xc0/0x340
[<ffffffff81086433>] ? do_exit+0x853/0x860
[<ffffffff811a33b5>] ? fput+0x25/0x30
[<ffffffff81564272>] ? system_call_after_swapgs+0xa2/0x152
[<ffffffff81086498>] ? do_group_exit+0x58/0xd0
[<ffffffff81086527>] ? sys_exit_group+0x17/0x20
[<ffffffff81564357>] ? system_call_fastpath+0x35/0x3a
[<ffffffff8156427e>] ? system_call_after_swapgs+0xae/0x152
Este tipo de pánico del kernel se produce debido a las siguientes causas posibles:
Faltan archivos y directorios importantes.
Faltan bibliotecas y paquetes importantes de núcleos del sistema
Consulte las secciones siguientes para obtener detalles y soluciones de causa. Asegúrese de que los comandos se ejecutan desde una máquina virtual de reparación o rescate dentro de un entorno chroot, como se indica en Solución de problemas sin conexión.
Faltan archivos y directorios importantes
Faltan archivos y directorios importantes de Linux debido a un error humano. Por ejemplo, los archivos se eliminan accidentalmente o los daños en el sistema de archivos.
Valide el contenido del disco del sistema operativo después de conectar la copia del disco del sistema operativo a una máquina virtual de reparación y montar los sistemas de archivos correspondientes mediante chroot. Puede comparar las salidas con las de una máquina virtual en funcionamiento que ejecuta la misma versión del sistema operativo.
ls -l / ls -l /usr/lib ls -l /usr/lib64 ls -lR / | moreRestaure los archivos que faltan desde una copia de seguridad. Para más información, consulte Recuperación de archivos de la copia de seguridad de máquinas virtuales de Azure. En función del número de archivos que faltan, es posible que sea mejor realizar una restauración completa de la máquina virtual. Para obtener más información, consulte Cómo restaurar los datos de Azure VM en el portal de Azure.
Faltan bibliotecas y paquetes importantes de núcleos del sistema
Las bibliotecas, archivos o paquetes principales del sistema importantes se eliminan del sistema o se dañan. Para resolver este problema, vuelva a instalar las bibliotecas, archivos o paquetes afectados. Esta solución funciona en distribuciones basadas en RPM, como máquinas virtuales Red Hat/CentOS/SUSE. Para otras distribuciones de Linux, se recomienda restaurar la máquina virtual a partir de la copia de seguridad.
Para realizar la reinstalación, siga estos pasos:
Cree una máquina virtual de rescate mediante una imagen sin procesar con la misma versión y generación del sistema operativo que la máquina virtual afectada.
Acceda al entorno chroot en la máquina virtual de rescate para solucionar el problema.
sudo chroot /rescueLa salida del comando indicará qué biblioteca falta o está dañada, como se muestra a continuación:
/bin/bash: error while loading shared libraries: libc.so.6: cannot open shared object file: No such file or directoryCompruebe todos los paquetes del sistema y su estado correspondiente en la máquina virtual de rescate. Compare la salida con una máquina virtual correcta que ejecute la misma versión del sistema operativo.
sudo rpm --verify --all --root=/rescueEste es un ejemplo del resultado del comando:
error: Failed to dlopen /usr/lib64/rpm-plugins/systemd_inhibit.so /lib64/librt.so.1: undefined symbol: __pthread_attr_copy, version GLIBC_PRIVATE S.5....T. c /etc/dnf/dnf.conf S.5....T. c /etc/ssh/sshd_config .M....... /boot/efi/EFI/BOOT/BOOTX64.EFI .M....... /boot/efi/EFI/BOOT/fbx64.efi .M....... /boot/efi/EFI/redhat/BOOTX64.CSV .M....... /boot/efi/EFI/redhat/mmx64.efi .M....... /boot/efi/EFI/redhat/shimx64-redhat.efi .M....... /boot/efi/EFI/redhat/shimx64.efi missing /run/motd.d .M....... g /var/spool/anacron/cron.daily .M....... g /var/spool/anacron/cron.monthly .M....... g /var/spool/anacron/cron.weekly missing /lib64/libc-2.28.so <------- .M....... /boot/efi/EFI/redhat S.5....T. c /etc/security/pwquality.confLa línea
missing /lib64/libc-2.28.sode salida está relacionada con el error anterior en el paso 2 e indica que falta el paquete libc-2.28.so . Sin embargo, se puede modificar el paquete libc-2.28.so . En este caso, la salida se mostrará.M.....en lugar demissing. Se hace referencia al paquete libc-2.28.so como ejemplo en los pasos siguientes.En la máquina virtual de rescate, compruebe qué paquete contiene la biblioteca /lib64/libc-2.28.so.
sudo rpm -qf /lib64/libc-2.28.soglibc-2.28-127.0.1.el8.x86_64Nota:
La salida mostrará el paquete que debe volver a instalarse, incluido el nombre y la versión del paquete. La versión del paquete puede ser diferente de la instalada en la máquina virtual afectada.
En la máquina virtual afectada, compruebe qué versión del paquete glibc está instalada.
sudo rpm -qa --all --root=/rescue | grep -i glibcglibc-common-2.28-211.0.1.el8.x86_64 glibc-gconv-extra-2.28-211.0.1.el8.x86_64 glibc-2.28-211.0.1.el8.x86_64 <---- glibc-langpack-en-2.28-211.0.1.el8.x86_64Descargue el paquete glibc-2.28-211.0.1.el8.x86_64. Puede descargarlo desde el sitio web oficial del proveedor del sistema operativo o desde la máquina virtual de rescate mediante una herramienta de administración de paquetes como
yumdownloaderozypper install --download-only <packagename>en función del sistema operativo que esté ejecutando.Este es un ejemplo del uso de la
yumdownloaderherramienta :cd /tmp sudo yumdownloader glibc-2.28-211.0.1.el8.x86_64Last metadata expiration check: 0:03:24 ago on Thu 25 May 2023 02:36:25 PM UTC. glibc-2.28-211.0.1.el8.x86_64.rpm 8.7 MB/s | 2.2 MB 00:00Vuelva a instalar el paquete afectado en la máquina virtual de rescate.
sudo rpm -ivh --root=/rescue /tmp/glibc-*.rpm --replacepkgs --replacefileswarning: /tmp/glibc-2.28-211.0.1.el8.x86_64.rpm: Header V3 RSA/SHA256 Signature, key ID ad986da3: NOKEY Verifying... ################################# [100%] Preparing... ################################# [100%] Updating / installing... 1:glibc-2.28-211.0.1.el8 ################################# [100%]Acceda al entorno chroot de la máquina virtual de rescate para validar la reinstalación.
sudo chroot /rescueDesactive la máquina virtual de rescate y cambie el disco del sistema operativo a la máquina virtual afectada.
Permisos de archivo incorrectos
Los permisos de archivos de todo el sistema incorrectos se modifican debido a un error humano (por ejemplo, alguien se ejecuta chmod 777 en / u otros sistemas de archivos del sistema operativo importantes). Para resolver este problema, restaure los permisos de archivo. Esta solución funciona en distribuciones basadas en RPM, como máquinas virtuales Red Hat/CentOS/SUSE. Para otras distribuciones de Linux, se recomienda restaurar la máquina virtual a partir de la copia de seguridad.
Para restaurar los permisos de archivo, ejecute el siguiente comando después de adjuntar la copia del disco del sistema operativo a una máquina virtual de reparación y montar los sistemas de archivos correspondientes mediante chroot:
rpm -a --setperms
rpm --setugids --all
chmod u+s /bin/sudo
chmod 660 /etc/sudoers.d/*
chmod 644 /etc/ssh/*.pub
chmod 640 /etc/ssh/*.key
Nota:
No ejecute este comando en la ejecución de sistemas de producción.
Si el problema sigue existiendo después de recuperar manualmente los permisos de archivo correspondientes, realice una restauración a partir de la copia de seguridad.
Faltan particiones
En los casos en /usrlos que los sistemas de archivos , /opt, /var/home, , /tmpy / se distribuyen entre diferentes particiones, los datos pueden ser inaccesibles debido a problemas en el nivel de particiones, lo que puede deberse a errores durante las operaciones de cambio de tamaño de partición u otros.
En este escenario, si documenta el diseño de la tabla de particiones original, con los sectores inicial y final exactos para cada una de las particiones originales, y no se realizan más modificaciones en el sistema, como la creación de nuevos sistemas de archivos, vuelva a crear las particiones mediante el mismo diseño original con herramientas como fdisk (para tablas de particiones MBR) o gdisk (para tablas de particiones GPT) para obtener acceso al sistema de archivos que falta.
Si este enfoque no funciona, realice una restauración a partir de la copia de seguridad.
Problemas de SELinux
Los permisos SELinux incorrectos podrían impedir que el sistema acceda a archivos importantes. Para resolver el problema, siga estos pasos:
Para comprobar si el sistema tiene problemas debido a permisos SELinux incorrectos, inicie el sistema con SELinux deshabilitado agregando la opción de kernel selinux=0 a la línea de GRUB linux16.
Si el sistema puede arrancar, ejecute el siguiente comando para desencadenar una nueva etiqueta de SELinux en tiempo de arranque y reiniciar el sistema:
touch /.autorelabelSi la máquina virtual todavía no puede arrancar, realice una restauración completa de la máquina virtual a partir de la copia de seguridad. Para obtener más información, consulte Cómo restaurar los datos de Azure VM en el portal de Azure.
Otros problemas de arranque relacionados con el kernel
En este artículo se tratan los pánicos de kernel de Linux más comunes identificados en Azure. Para más información sobre escenarios comunes de pánico de kernel, consulte Pánico del kernel en máquinas virtuales Linux de Azure: eventos comunes de pánico de kernel.
Hay otros posibles pánicos de kernel importantes que podrían provocar ningún escenario de arranque o de shell seguro (SSH).
Asegúrese de ejecutar los comandos desde una máquina virtual de reparación dentro de un entorno chroot, como se indica en Solución de problemas sin conexión. Si el sistema ya se ha arrancado en una versión anterior del kernel, estos comandos también se pueden ejecutar desde la máquina virtual original mediante privilegios raíz o sudo, como se indica en Solución de problemas en línea.
Actualización reciente del kernel
Si el kernel entra en pánico después de una actualización reciente del kernel, arranque la máquina virtual en la versión anterior del kernel. Para obtener más información, consulte Sistema de arranque en la versión anterior del kernel.
También puede comprobar si ya hay una versión más reciente del kernel publicada por el proveedor de distribución de Linux e instalarla. Para obtener más información sobre cómo instalar la versión más reciente del kernel, consulte Proceso de actualización del kernel.
Degradación reciente del kernel
Si el kernel entra en pánico después de una degradación reciente del kernel, vuelva al kernel instalado más reciente. También puede comprobar si ya hay una versión más reciente del kernel publicada por el proveedor de distribución de Linux e instalarla. Para obtener más información sobre cómo instalar la versión más reciente del kernel, consulte Proceso de actualización del kernel.
Para arrancar el sistema en la versión de kernel más reciente, siga las instrucciones de Cambiar manualmente la versión predeterminada del kernel, pero seleccione el primer kernel que aparece en el menú GRUB. En una modificación manual, podría establecer el GRUB_DEFAULT valor en 0 y volver a generar el archivo de configuración de GRUB correspondiente.
Cambios en el módulo de kernel
Es posible que experimente un pánico del kernel relacionado con un nuevo módulo de kernel o un módulo de kernel que falta. Para obtener detalles sobre el módulo de kernel específico que provoca problemas (si los hay), compruebe el seguimiento de pánico del kernel correspondiente.
Para validar los módulos de kernel cargados y los deshabilitados en los archivos /etc/modprobe.d/*.conf , ejecute uno de los siguientes comandos:
RHEL/CentOS/Oracle Linux 7/8
lsinitrd /boot/initramfs-3.10.0-1160.59.1.el7.x86_64.img lsmod cat /etc/modprobe.d/*.confImportante
Reemplace por
3.10.0-1160.59.1.el7.x86_64la versión del kernel correspondiente.SLES 12/15
lsinitrd /boot/initrd-5.3.18-150300.38.53-azure lsmod cat /etc/modprobe.d/*.confImportante
Reemplace por
5.3.18-150300.38.53-azurela versión del kernel correspondiente.Ubuntu 18.04
lsinitramfs /boot/initrd.img-5.4.0-1077-azure lsmod cat /etc/modprobe.d/*.confImportante
Reemplace por
5.4.0-1077-azurela versión del kernel correspondiente.
Para quitar cualquier módulo de kernel específico, ejecute el siguiente comando y vuelva a generar los initramfs si es necesario.
rmmod <kernel_module_name>
Si un servicio del sistema usa el módulo de kernel específico, deshabilite mediante la ejecución del systemctl disable <serviceName> comando o systemctl stop <serviceName> .
Cambios recientes en la configuración del sistema operativo
Identifique los cambios recientes en la configuración del kernel que puedan causar problemas. Para resolver los problemas, ajuste esas opciones o revierta los cambios de configuración.
Ejecute el siguiente comando para buscar parámetros de kernel persistentes configurados en cualquiera de los siguientes archivos:
cat /etc/systctl.conf
cat /etc/sysctl.d/*
Ejecute el comando siguiente para analizar los parámetros de kernel actuales y sus valores actuales:
sysctl -a
Nota:
Ejecute este comando en un sistema en ejecución y no desde un entorno chroot.
Archivos que faltan posibles
Para obtener más información sobre este tipo de problema, consulte Faltan archivos y directorios importantes.
Permisos incorrectos en archivos
Para obtener más información sobre este tipo de problema, consulte Permisos de archivo incorrectos.
Faltan particiones
Para obtener más información sobre este tipo de problema, consulte Faltan particiones.
Errores de kernel
Identifique este problema desde la consola serie de Azure. Este tipo de problema tendrá un aspecto similar al siguiente resultado:
[5275698.017004] kernel BUG at XXX/YYY.c:72!
[5275698.017004] invalid opcode: 0000 [#1] SMP
Este tipo de pánico del kernel está asociado a errores de kernel o errores de kernel de terceros.
Para corregir errores de kernel, busque la base de conocimiento del proveedor mediante la cadena bug del kernel y busque problemas conocidos en la versión del kernel correspondiente que ejecuta el sistema. Estos son algunos recursos importantes del proveedor:
Analizador de operaciones con error del kernel de Red Hat
Esta herramienta está diseñada para ayudarle a diagnosticar un bloqueo del kernel. Al escribir un texto, vmcore-dmesg.txt o un archivo, incluidos uno o varios mensajes de oops de kernel, le guiará a través del diagnóstico del problema de bloqueo del kernel.
-
Para acceder a los recursos de Red Hat, vincule las cuentas de Microsoft Azure y Red Hat. Para obtener más información, consulte Cómo los clientes de Microsoft Azure pueden acceder al Portal de clientes de Red Hat.
Se recomienda mantener todos los sistemas actualizados para descartar los posibles errores ya corregidos en las versiones más recientes del kernel. Para obtener más información, consulte Proceso de actualización del kernel.
Si se requiere un análisis adicional del proveedor, configure y habilite kdump para generar un volcado de memoria del núcleo:
- Configuración de Kdump en máquinas virtuales basadas en Red Hat.
- Configuración del volcado de memoria del bloqueo de kernel en máquinas virtuales Ubuntu.
- Configuración del volcado de memoria del núcleo del kernel en máquinas virtuales SLES
Proceso de actualización del kernel
Para instalar la versión más reciente del kernel disponible, ejecute uno de los siguientes comandos:
RHEL/CentOS/Oracle Linux
yum update kernelSLES 12/15
zypper refresh zypper update kernel*Ubuntu 18.04/20.04
apt update apt install linux-azure
Para volver a instalar una versión específica del kernel, ejecute uno de los siguientes comandos. Asegúrese de que no se inicia en la misma versión del kernel que intenta reinstalar. Para obtener más información, consulte Sistema de arranque en la versión anterior del kernel.
RHEL/CentOS/Oracle Linux
yum reinstall kernel-3.10.0-1160.59.1.el7.x86_64Importante
Reemplace por
3.10.0-1160.59.1.el7.x86_64la versión del kernel correspondiente.SLES 12/15
zypper refresh zypper install -f kernel-azure-5.3.18-150300.38.75.1.x86_64Importante
Reemplace por
kernel-azure-5.3.18-150300.38.75.1.x86_64la versión del kernel correspondiente.Ubuntu 18.04/20.04
apt update apt install --reinstall linux-azure=5.4.0.1091.68Importante
Reemplace por
5.4.0.1091.68la versión del kernel correspondiente.
Para actualizar el sistema y aplicar los cambios disponibles más recientes, ejecute uno de los siguientes comandos:
RHEL/CentOS/Oracle Linux
yum updateSLES 12/15
zypper refresh zypper updateUbuntu 18.04/20.04
apt update apt upgrade
Los pánicos del kernel pueden estar relacionados con cualquiera de los siguientes elementos. Para obtener más información, consulte Pánicos del kernel en tiempo de ejecución.
- Cambios en la carga de trabajo de la aplicación.
- Errores de desarrollo de aplicaciones o aplicaciones.
- Problemas relacionados con el rendimiento, etc.
Pasos siguientes
Si el error de arranque específico no es un problema de arranque relacionado con el kernel, consulte Solución de problemas de errores de arranque de Azure Linux Virtual Machines para obtener más opciones de solución de problemas.
Ponte en contacto con nosotros para obtener ayuda
Si tiene preguntas o necesita ayuda, cree una solicitud de soporte o busque consejo en la comunidad de Azure. También puede enviar comentarios sobre el producto con los comentarios de la comunidad de Azure.