Guía de modelado de Power BI para Power Platform
Microsoft Dataverse es la plataforma de datos estándar para muchos productos de aplicaciones empresariales de Microsoft, incluidas las aplicaciones de lienzo de Dynamics 365 Customer Engagement y Power Apps, y también Dynamics 365 Customer Voice (anteriormente Microsoft Forms Pro), aprobaciones de Power Automate, Portales de Power Apps y otros.
En este artículo se proporcionan instrucciones sobre cómo crear un modelo de datos de Power BI que se conecta a Dataverse. Describe las diferencias entre un esquema de Dataverse y un esquema de Power BI optimizado y proporciona instrucciones para expandir la visibilidad de los datos de la aplicación empresarial en Power BI.
Debido a su facilidad de configuración, implementación rápida y adopción generalizada, Dataverse almacena y administra un volumen creciente de datos en entornos de organizaciones. Esto significa que hay una necesidad aún mayor (y oportunidad) para integrar el análisis con esos procesos. Las oportunidades incluyen:
- Informe sobre todos los datos de Dataverse más allá de las restricciones de los gráficos integrados.
- Proporcionar un acceso sencillo a informes relevantes filtrados contextualmente dentro de un registro específico.
- Mejorar el valor de los datos de Dataverse mediante su integración con datos externos.
- Aprovechar las ventajas de la inteligencia artificial (IA) integrada de Power BI sin necesidad de escribir código complejo.
- Aumentar la adopción de soluciones de Power Platform aumentando su utilidad y valor.
- Ofrecer el valor de los datos de la aplicación a los responsables de la toma de decisiones empresariales.
Conexión de Power BI a Dataverse
La conexión de Power BI a Dataverse implica la creación de un modelo de datos de Power BI. Puede elegir entre tres métodos para crear un modelo de Power BI.
- Importar datos de Dataverse mediante el conector de Dataverse: este método almacena en caché los datos de Dataverse en un modelo de Power BI. Ofrece un rendimiento rápido gracias a las consultas en memoria. También ofrece flexibilidad de diseño a los modeladores, lo que les permite integrar datos de otros orígenes. Debido a estos puntos fuertes, la importación de datos es el modo predeterminado al crear un modelo en Power BI Desktop.
- Importar datos de Dataverse mediante azure Synapse Link: este método es una variación del método de importación, ya que también almacena en caché los datos en el modelo de Power BI, pero lo hace mediante la conexión a Azure Synapse Analytics. Mediante Azure Synapse Link para Dataverse, las tablas de Dataverse se replican continuamente en Azure Synapse o Azure Data Lake Storage (ADLS) Gen2. Este enfoque se usa para informar sobre cientos de miles o incluso millones de registros en entornos de Dataverse.
- Crear una conexión directQuery mediante el conector de Dataverse: este método es una alternativa a la importación de datos. Un modelo DirectQuery solo consta de metadatos que definen la estructura del modelo. Cuando un usuario abre un informe, Power BI envía consultas nativas a Dataverse para recuperar datos. Considere la posibilidad de crear un modelo de DirectQuery cuando los informes deben mostrar datos de Dataverse casi en tiempo real o cuando Dataverse debe aplicar la seguridad basada en roles para que los usuarios solo puedan ver los datos a los que tienen privilegios de acceso.
Importante
Aunque un modelo de DirectQuery puede ser una buena alternativa cuando necesita informes casi en tiempo real o la aplicación de la seguridad de Dataverse en un informe, puede dar lugar a un rendimiento lento para ese informe.
Puede obtener información sobre las consideraciones de DirectQuery más adelante en este artículo.
Para determinar el método adecuado para el modelo de Power BI, debe tener en cuenta lo siguiente:
- Rendimiento de las consultas
- Volumen de datos
- Latencia de datos
- Seguridad basada en roles
- Complejidad de la instalación
Sugerencia
Para obtener una explicación detallada sobre los marcos de modelos (importación, DirectQuery o compuesto), sus ventajas y limitaciones, y las características para ayudar a optimizar los modelos de datos de Power BI, consulte Elección de un marco de modelos de Power BI.
Rendimiento de las consultas
Las consultas enviadas a los modelos de importación son más rápidas que las consultas nativas enviadas a orígenes de datos de DirectQuery. Esto se debe a que los datos importados se almacenan en caché en la memoria y se optimizan para las consultas analíticas (operaciones de filtro, grupo y resumen).
Por el contrario, los modelos DirectQuery solo recuperan datos del origen después de que el usuario abra un informe, lo que da lugar a segundos de retraso a medida que se representa el informe. Además, las interacciones del usuario en el informe requieren que Power BI vuelva a consultar el origen, lo que reduce aún más la capacidad de respuesta.
Volumen de datos
Al desarrollar un modelo de importación, debe esforzarse por minimizar los datos cargados en el modelo. Esto es especialmente así en el caso de los modelos de gran tamaño, o bien de los modelos que se prevé que vayan a crecer hasta alcanzar un gran tamaño con el tiempo. Para obtener más información, vea Técnicas de reducción de datos para modelos de importación.
Una conexión DirectQuery a Dataverse es una buena elección cuando el resultado de la consulta del informe no es grande. Un resultado de consulta grande tiene más de 20.000 filas en las tablas de origen del informe o el resultado devuelto al informe después de aplicar filtros es superior a 20.000 filas. En este caso, puede crear un informe de Power BI mediante el conector de Dataverse.
Nota:
El tamaño de fila de 20.000 no es un límite estricto. Sin embargo, cada consulta de origen de datos debe devolver un resultado en un plazo de 10 minutos. Más adelante en este artículo descubrirá cómo trabajar dentro de esas limitaciones y sobre otras consideraciones de diseño de Dataverse DirectQuery.
Puede mejorar el rendimiento de los modelos semánticos más grandes mediante el conector de Dataverse para importar los datos en el modelo de datos.
Incluso modelos semánticos más grandes, con varios cientos de miles o incluso millones de filas, puede beneficiarse del uso de Azure Synapse Link para Dataverse. Este enfoque configura una canalización administrada en curso que copia los datos de Dataverse en ADLS Gen2 como archivos CSV o Parquet. Después, Power BI puede consultar un grupo de SQL sin servidor Azure Synapse para cargar un modelo de importación.
Latencia de datos
Cuando los datos de Dataverse cambian rápidamente y los usuarios necesitan ver los datos actuales, un modelo de DirectQuery puede proporcionar resultados de consulta casi en tiempo real.
Sugerencia
Puede crear un informe de Power BI que use la actualización automática de páginas para mostrar actualizaciones en tiempo real, pero solo cuando el informe se conecte a un modelo de DirectQuery.
Los modelos de importación de datos deben completar una actualización de datos para permitir la generación de informes sobre los cambios recientes en los datos. Tenga en cuenta que hay limitaciones en el número de operaciones diarias de actualización de datos programadas. Puede programar hasta ocho actualizaciones al día en una capacidad compartida. En una capacidad Premium o capacidad de Microsoft Fabric, puede programar hasta 48 actualizaciones al día, lo que puede lograr una frecuencia de actualización de 15 minutos.
Importante
En ocasiones, este artículo hace referencia a Power BI Premium o a sus suscripciones de capacidad (SKU P). Tenga en cuenta que Microsoft está consolidando actualmente las opciones de compra y retirando las SKU de Power BI Premium por capacidad. Los clientes nuevos y existentes deben considerar la posibilidad de comprar suscripciones de capacidad de Fabric (SKU F) en su lugar.
Para obtener más información, consulte Actualización importante sobre las licencias de Power BI Premium y Preguntas más frecuentes sobre Power BI Premium.
También puede considerar el uso de la actualización incremental para lograr actualizaciones más rápidas y un rendimiento casi en tiempo real (solo disponible con Premium o Fabric).
Seguridad basada en roles
Cuando es necesario aplicar la seguridad basada en roles, puede influir directamente en la elección del marco de modelos de Power BI.
Dataverse puede aplicar una seguridad compleja basada en roles para controlar el acceso de registros específicos a usuarios específicos. Por ejemplo, es posible que un vendedor pueda ver solo sus oportunidades de ventas, mientras que el administrador de ventas puede ver todas las oportunidades de ventas para todos los vendedores. Puede adaptar el nivel de complejidad en función de las necesidades de su organización.
Un modelo de DirectQuery basado en Dataverse puede conectarse mediante el contexto de seguridad del usuario del informe. De este modo, el usuario del informe solo verá los datos a los que puede acceder. Este enfoque puede simplificar el diseño del informe, lo que proporciona un rendimiento aceptable.
Para mejorar el rendimiento, puede crear un modelo de importación que se conecte a Dataverse en su lugar. En este caso, puede agregar seguridad de nivel de fila (RLS) al modelo, si es necesario.
Nota:
Es posible que sea difícil replicar cierta seguridad basada en roles de Dataverse como Power BI RLS, especialmente cuando Dataverse exige permisos complejos. Además, podría requerir una administración continua para mantener los permisos de Power BI sincronizados con los permisos de Dataverse.
Para más información sobre la Power BI RLS, consulte Seguridad de nivel de fila (RLS) con Power BI Desktop.
Complejidad de la instalación
El uso del conector de Dataverse en Power BI (ya sea para los modelos de importación o DirectQuery) es sencillo y no requiere ningún software especial ni permisos elevados de Dataverse. Esta es una ventaja para organizaciones o departamentos que se están iniciando.
La opción Azure Synapse Link requiere acceso de administrador del sistema a Dataverse y determinados permisos de Azure. Estos permisos de Azure son necesarios para configurar la cuenta de almacenamiento y un área de trabajo de Synapse.
Procedimientos recomendados
En esta sección se describen los patrones de diseño (y los antipatrones) que debe tener en cuenta al crear un modelo de Power BI que se conecte a Dataverse. Solo algunos de estos patrones son exclusivos de Dataverse, pero tienden a ser desafíos comunes para los creadores de Dataverse cuando tratan de crear informes de Power BI.
Centrarse en un caso de uso específico
En lugar de intentar resolver todo, céntrese en el caso de uso específico.
Esta recomendación es probablemente la más común y fácilmente el antipatrón más difícil de evitar. Intentar crear un único modelo que logre todas las necesidades de informes de autoservicio es un desafío. La realidad es que los modelos exitosos se crean para responder a preguntas sobre un conjunto central de hechos sobre un único tema principal. Aunque esto podría parecer limitar inicialmente el modelo, es realmente lo que permite, ya que puede optimizar y optimizar el modelo para responder a preguntas dentro de ese tema.
Para ayudar a asegurarse de que tiene un conocimiento claro del propósito del modelo, formule las siguientes preguntas.
- ¿Qué área de temas admitirá este modelo?
- ¿Quién es la audiencia objetivo del informe?
- ¿Qué preguntas están intentando responder los informes?
- ¿Cuál es el modelo semántico viable mínimo?
Resista la combinación de varias áreas de temas en un único modelo solo porque el usuario del informe tiene preguntas en varias áreas de temas que quieren abordar mediante un único informe. Al dividir ese informe en varios informes, cada uno con un enfoque en un tema diferente (o tabla de hechos), puede generar modelos mucho más eficaces, escalables y administrables.
Diseño de un esquema de estrella
Es posible que los desarrolladores y administradores de Dataverse que se sientan cómodos con el esquema de Dataverse puedan reproducir el mismo esquema en Power BI. Este enfoque es un antipatrón y es probablemente el más difícil de superar, ya que simplemente se siente correcto mantener la coherencia.
Dataverse, como modelo relacional, es adecuado para su propósito. Sin embargo, no está diseñado como un modelo analítico optimizado para informes analíticos. El patrón más frecuente para los datos de análisis de modelado es un diseño de esquema de estrella. El esquema de estrella es un enfoque de modelado maduro ampliamente adoptado por los almacenes de datos relacionales. Requiere que los modeladores clasifiquen las tablas del modelo como dimensiones o hechos. Los informes pueden filtrar o agrupar usando columnas de la tabla de dimensiones y pueden resumir las columnas de la tabla de hechos.
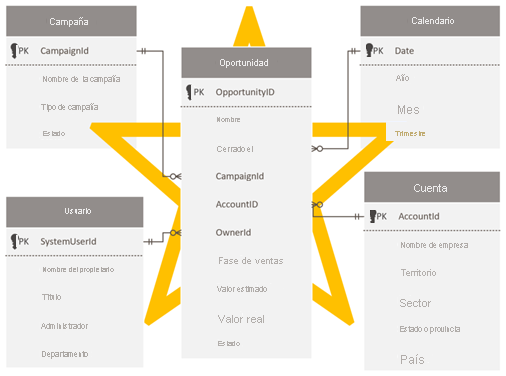
Para más información, vea Descripción de un esquema de estrella e importancia para Power BI.
Optimización de consultas de Power Query
El motor de mashup Power Query se esfuerza por lograr el plegado de consultas siempre que sea posible por motivos de eficiencia. Una consulta que logra el plegado del procesamiento de consultas en el sistema de origen.
En este caso, el sistema de origen, Dataverse, solo tiene que entregar resultados filtrados o resumidos a Power BI. Una consulta plegada suele ser significativamente más rápida y eficaz que una consulta que no se dobla.
Para obtener más información sobre cómo puede lograr el plegado de consultas, consulte plegado de consultas de Power Query.
Nota:
Optimizar Power Query es un tema amplio. Para comprender mejor lo que Power Query está haciendo en la creación y en el tiempo de actualización del modelo en Power BI Desktop, consulte Diagnósticos de consultas.
Minimizar el número de columnas de consulta
De forma predeterminada, cuando se usa Power Query para cargar una tabla de Dataverse, recupera todas las filas y todas las columnas. Al consultar una tabla de usuario del sistema, por ejemplo, podría contener más de 1000 columnas. Las columnas de los metadatos incluyen relaciones con otras entidades y búsquedas en etiquetas de opción, por lo que el número total de columnas crece con la complejidad de la tabla Dataverse.
Intentar recuperar datos de todas las columnas es un antipatrón. A menudo da como resultado operaciones de actualización de datos extendidas y provocará un error en la consulta cuando el tiempo necesario para devolver los datos supere los 10 minutos.
Se recomienda recuperar solo las columnas necesarias para los informes. A menudo es una buena idea volver a evaluar y refactorizar las consultas cuando se completa el desarrollo de informes, lo que le permite identificar y quitar columnas sin usar. Para obtener más información, vea Técnicas de reducción de datos para modelos de importación (Eliminar columnas innecesarias).
Además, asegúrese de introducir el paso Eliminar columnas de Power Query al principio para que se vuelva a plegar al origen. De este modo, Power Query puede evitar el trabajo innecesario de extraer datos de origen solo para descartarlos más adelante (en un paso desarrollado).
Si tiene una tabla que contiene muchas columnas, podría resultar poco práctico usar el generador de consultas interactivas de Power Query. En este caso, puede empezar creando una consulta en blanco. A continuación, puede usar el Editor avanzado para pegar una consulta mínima que crea un punto de partida.
Tenga en cuenta la siguiente consulta que recupera datos de solo dos columnas de la tabla account.
let
Source = CommonDataService.Database("demo.crm.dynamics.com", [CreateNavigationProperties=false]),
dbo_account = Source{[Schema="dbo", Item="account"]}[Data],
#"Removed Other Columns" = Table.SelectColumns(dbo_account, {"accountid", "name"})
in
#"Removed Other Columns"
Escritura de consultas nativas
Cuando tiene requisitos de transformación específicos, puede lograr un mejor rendimiento mediante una consulta nativa escrita en Dataverse SQL, que es un subconjunto de Transact-SQL. Puede escribir una consulta nativa para:
- Reducir el número de filas (mediante una
WHEREcláusula ). - Agregar datos (mediante las cláusulas
GROUP BYyHAVING). - Combinar tablas de forma específica (mediante la sintaxis
JOINoAPPLY). - Use funciones SQL admitidas.
Para más información, consulte:
Ejecutar consultas nativas con la opción EnableFolding
Power Query ejecuta una consulta nativa mediante la función Value.NativeQuery.
Al usar esta función, es importante agregar la opción EnableFolding=true para asegurarse de que las consultas se vuelven a plegar al servicio Dataverse. Una consulta nativa no se plegará a menos que se agregue esta opción. La habilitación de esta opción puede dar lugar a mejoras significativas en el rendimiento, hasta un 97 % más rápido en algunos casos.
Tenga en cuenta la siguiente consulta que usa una consulta nativa para obtener las columnas seleccionadas de la tabla account. La consulta nativa se plegará porque se establece la opción EnableFolding=true.
let
Source = CommonDataService.Database("demo.crm.dynamics.com"),
dbo_account = Value.NativeQuery(
Source,
"SELECT A.accountid, A.name FROM account A"
,null
,[EnableFolding=true]
)
in
dbo_account
Puede esperar lograr las mayores mejoras de rendimiento al recuperar un subconjunto de datos de un gran volumen de datos.
Sugerencia
La mejora del rendimiento también puede depender de cómo Power BI consulta la base de datos de origen. Por ejemplo, una medida que usa la COUNTDISTINCT función DAX no mostró casi ninguna mejora con o sin la sugerencia de plegado. Cuando se reescribió la fórmula de medida para usar la SUMX función DAX, la consulta plegada dio lugar a una mejora del 97 % en la misma consulta sin la sugerencia.
Para más información, consulte Value.NativeQuery. (La opción EnableFolding no está documentada porque es específica de solo determinados orígenes de datos).
Acelerar la fase de evaluación
Si usa el conector de Dataverse (anteriormente conocido como Common Data Service), puede agregar la opción CreateNavigationProperties=false para acelerar la fase de evaluación de una importación de datos.
La fase de evaluación de una importación de datos recorre en iteración los metadatos de su origen para determinar todas las relaciones de tabla posibles. Esos metadatos pueden ser extensos, especialmente para Dataverse. Al agregar esta opción a la consulta, Power Query puede saber que no pretende usar esas relaciones. La opción permite a Power BI Desktop omitir esa fase de la actualización y pasar a recuperar los datos.
Nota:
No use esta opción cuando la consulta dependa de las columnas de relación expandidas.
Considere un ejemplo que recupera datos de la tabla account. Contiene tres columnas relacionadas con el territorio: territory, territoryidy territoryidname.
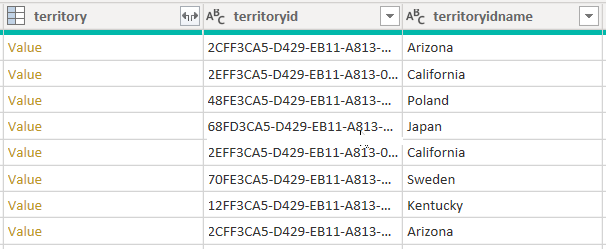
Al establecer la opción CreateNavigationProperties=false, las columnas territoryid y territoryidname permanecerán, pero se excluirá la columna territory, que es una columna relacional (muestra enlaces del valor ). Es importante comprender que las columnas de Power Query de relación son un concepto diferente para modelar las relaciones, que propagan filtros entre tablas de modelo.
Considere la siguiente consulta que usa la opción CreateNavigationProperties=false (en el paso Origen) para acelerar la fase de evaluación de una importación de datos.
let
Source = CommonDataService.Database("demo.crm.dynamics.com"
,[CreateNavigationProperties=false]),
dbo_account = Source{[Schema="dbo", Item="account"]}[Data],
#"Removed Other Columns" = Table.SelectColumns(dbo_account, {"accountid", "name", "address1_stateorprovince", "address1_country", "industrycodename", "territoryidname"}),
#"Renamed Columns" = Table.RenameColumns(#"Removed Other Columns", {{"name", "Account Name"}, {"address1_country", "Country"}, {"address1_stateorprovince", "State or Province"}, {"territoryidname", "Territory"}, {"industrycodename", "Industry"}})
in
#"Renamed Columns"
Al usar esta opción, es probable que experimente una mejora significativa del rendimiento cuando una tabla de Dataverse tiene muchas relaciones con otras tablas. Por ejemplo, dado que la tabla SystemUser está relacionada con todas las demás tablas de la base de datos, el rendimiento de actualización de esta tabla se beneficiaría estableciendo la opción CreateNavigationProperties=false.
Nota:
Esta opción puede mejorar el rendimiento de la actualización de datos de las tablas de importación o las tablas en modo de almacenamiento dual, incluido el proceso de aplicación de cambios de ventana del Editor de Power Query. No mejora el rendimiento del filtrado cruzado interactivo de las tablas del modo de almacenamiento de DirectQuery.
Resolución de etiquetas de elección en blanco
Si detecta que las etiquetas de elección de Dataverse están en blanco en Power BI, podría deberse a que las etiquetas no se han publicado en el punto de conexión del flujo de datos tabular (TDS).
En este caso, abra el portal de Dataverse Maker, vaya al área Soluciones y seleccione Publicar todas las personalizaciones. El proceso de publicación actualizará el punto de conexión de TDS con los metadatos más recientes, lo que hará que las etiquetas de opción estén disponibles para Power BI.
Modelos semánticos más grandes con Azure Synapse Link
Dataverse incluye la capacidad de sincronizar tablas con Azure Data Lake Storage (ADLS) y después conectarse a esos datos a través de un área de trabajo de Azure Synapse. Con un esfuerzo mínimo, puede configurar Azure Synapse Link para rellenar los datos de Dataverse en Azure Synapse y permitir que los equipos de datos detecten información más detallada.
Azure Synapse Link permite una replicación continua de los datos y metadatos de Dataverse en el lago de datos. También proporciona un grupo de SQL sin servidor integrado como un origen de datos adecuado para las consultas de Power BI.
Los puntos fuertes de este enfoque son significativos. Los clientes obtienen la capacidad de ejecutar cargas de trabajo de análisis, inteligencia empresarial y aprendizaje automático en datos de Dataverse mediante varios servicios avanzados. Los servicios avanzados incluyen Apache Spark, Power BI, Azure Data Factory, Azure Databricks y Azure Machine Learning.
Cree un Azure Synapse Link para Dataverse
Para crear un Azure Synapse Link para Dataverse, necesitará los siguientes requisitos previos.
- Acceso del administrador del sistema al entorno de Dataverse.
- Para Azure Data Lake Storage:
- Debe tener una cuenta de almacenamiento para usarla con ADLS Gen2.
- Debe tener asignado acceso de propietario de datos de Storage Blob y Colaborador de datos de Storage Blob a la cuenta de almacenamiento. Para obtener más información, consulte Control de acceso basado en roles (Azure RBAC).
- La cuenta de almacenamiento debe habilitar el espacio de nombres jerárquico.
- Se recomienda que la cuenta de almacenamiento use almacenamiento con redundancia geográfica con acceso de lectura (RA-GRS).
- Para el área de trabajo de Synapse:
- Debe tener acceso a un área de trabajo de Synapse y tener asignado acceso del administrador de Synapse. Para más información, consulte Roles y ámbitos integrados de RBAC de Synapse.
- El área de trabajo debe estar en la misma región que la cuenta de almacenamiento de ADLS Gen2.
La configuración implica iniciar sesión en Power Apps y conectar Dataverse al área de trabajo de Azure Synapse. Una experiencia similar al asistente le permite crear un vínculo seleccionando la cuenta de almacenamiento y las tablas que se van a exportar. Azure Synapse Link copia los datos en el almacenamiento de ADLS Gen2 y crea automáticamente vistas en el grupo de SQL integrado Azure Synapse sin servidor. Después, puede conectarse a esas vistas para crear un modelo de Power BI.
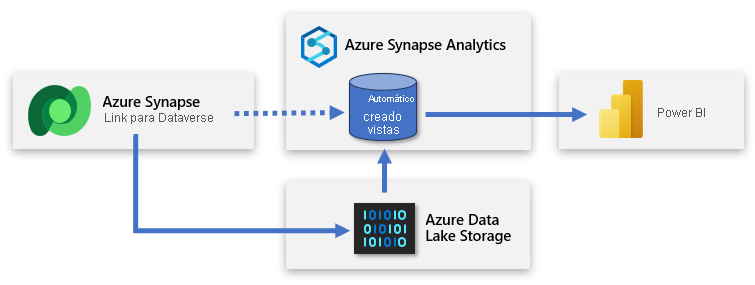
Sugerencia
Para obtener documentación completa sobre cómo crear, administrar y supervisar Azure Synapse Link, consulte Creación de Azure Synapse Link para Dataverse con el área de trabajo de Azure Synapse.
Creación de una segunda base de datos SQL sin servidor
Puede crear una segunda base de datos SQL sin servidor y usarla para agregar vistas de informe personalizadas. De este modo, puede presentar un conjunto simplificado de datos al creador de Power BI que les permita crear un modelo basado en datos útiles y relevantes. La nueva base de datos SQL sin servidor se convierte en la conexión de origen principal del creador y una representación fácil de usar de los datos de origen del lago de datos.
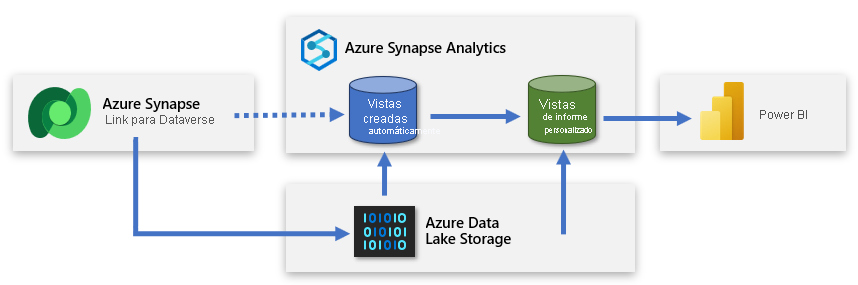
Este enfoque ofrece datos a Power BI centrados, enriquecidos y filtrados.
Puede crear una base de datos SQL sin servidor en el área de trabajo de Azure Synapse mediante Azure Synapse Studio. Seleccione Sin servidor como el tipo de base de datos SQL y escriba un nombre para la base de datos. Power Query puede conectarse a esta base de datos mediante la conexión al punto de conexión SQL del área de trabajo.
Creación de vistas personalizadas
Puede crear vistas personalizadas que encapsulan consultas de grupo de SQL sin servidor. Estas vistas servirán como orígenes sencillos y limpios de datos a los que se conecta Power BI. Las vistas deben:
- Incluir etiquetas asociadas a los campos de elección.
- Reducir la complejidad incluyendo solo las columnas necesarias para el modelado de datos.
- Filtre las filas innecesarias, como los registros inactivos.
Tenga en cuenta la siguiente vista que recupera los datos de la campaña.
CREATE VIEW [VW_Campaign]
AS
SELECT
[base].[campaignid] AS [CampaignID]
[base].[name] AS [Campaign],
[campaign_status].[LocalizedLabel] AS [Status],
[campaign_typecode].[LocalizedLabel] AS [Type Code]
FROM
[<MySynapseLinkDB>].[dbo].[campaign] AS [base]
LEFT OUTER JOIN [<MySynapseLinkDB>].[dbo].[OptionsetMetadata] AS [campaign_typecode]
ON [base].[typecode] = [campaign_typecode].[option]
AND [campaign_typecode].[LocalizedLabelLanguageCode] = 1033
AND [campaign_typecode].[EntityName] = 'campaign'
AND [campaign_typecode].[OptionSetName] = 'typecode'
LEFT OUTER JOIN [<MySynapseLinkDB>].[dbo].[StatusMetadata] AS [campaign_status]
ON [base].[statuscode] = [campaign_Status].[status]
AND [campaign_status].[LocalizedLabelLanguageCode] = 1033
AND [campaign_status].[EntityName] = 'campaign'
WHERE
[base].[statecode] = 0;
Observe que la vista incluye solo cuatro columnas, cada una con alias con un nombre descriptivo. También hay una WHERE cláusula para devolver solo las filas necesarias, en este caso campañas activas. Además, la vista consulta la tabla de campañas que está unida a las tablas OptionsetMetadata y StatusMetadata , que recuperan etiquetas de elección.
Sugerencia
Para obtener más información sobre cómo recuperar metadatos, consulte Acceso a etiquetas de elección directamente desde Azure Synapse Link para Dataverse.
Consulta de tablas adecuadas
Azure Synapse Link para Dataverse garantiza que los datos se sincronicen continuamente con los datos del lago de datos. En el caso de la actividad de uso elevado, las escrituras y lecturas simultáneas pueden crear bloqueos que provocan errores en las consultas. Para garantizar la fiabilidad al recuperar datos, se sincronizan dos versiones de los datos de tabla en Azure Synapse.
- datos casi en tiempo real: proporciona una copia de los datos sincronizados desde Dataverse a través de Azure Synapse Link de forma eficaz mediante la detección de los datos que han cambiado desde que se extrajo inicialmente o se sincronizó por última vez.
- Datos instantáneos: Proporciona una copia de solo lectura de los datos casi en tiempo real, los cuales se actualizan a intervalos regulares (en este caso, cada hora). Los nombres de las tablas de datos de instantáneas tienen _partitioned anexados a su nombre.
Si prevé que se ejecutará simultáneamente un gran volumen de operaciones de lectura y escritura, recupere datos de las tablas de instantáneas para evitar errores de consulta.
Para obtener más información, consulte Acceso a datos casi en tiempo real y datos de instantáneas de solo lectura.
Conectar con Synapse Analytics
Para consultar un grupo SQL sin servidor de Azure Synapse, necesitará su punto de conexión SQL del área de trabajo. Puede recuperar el punto de conexión de Synapse Studio abriendo las propiedades del grupo de SQL sin servidor.
En Power BI Desktop, puede conectarse a Azure Synapse mediante el conector SQL de Azure Synapse Analytics. Cuando se le solicite el servidor, escriba el punto de conexión SQL del área de trabajo.
Consideraciones para DirectQuery
Hay muchos casos de uso cuando el modo de almacenamiento DirectQuery puede resolver sus requisitos. Sin embargo, el uso de DirectQuery puede afectar negativamente al rendimiento del informe de Power BI. Un informe que usa una conexión DirectQuery a Dataverse no será tan rápido como un informe que use un modelo de importación. Debe importar datos a Power BI siempre que sea posible.
Se recomienda tener en cuenta los temas de esta sección al trabajar con DirectQuery.
Para obtener más información sobre cómo determinar cuándo trabajar con el modo de almacenamiento DirectQuery, consulte Elegir un marco de modelo de Power BI.
Uso de tablas de dimensiones en modo de almacenamiento dual
Se establece una tabla de modo de almacenamiento dual para usar los modos de almacenamiento de importación y DirectQuery. En el momento de la consulta, Power BI determina el modo más eficaz que se usará. Siempre que sea posible, Power BI intenta satisfacer las consultas mediante el uso de datos importados porque es más rápido.
Debe considerar la posibilidad de establecer tablas de dimensiones en modo de almacenamiento dual, cuando corresponda. De este modo, los objetos visuales de segmentación de datos y las listas de tarjetas de filtro, que a menudo se basan en columnas de tabla de dimensiones, se representarán más rápidamente porque se consultarán a partir de datos importados.
Importante
Cuando una tabla de dimensiones necesita heredar el modelo de seguridad de Dataverse, no es adecuado usar el modo de almacenamiento dual.
Las tablas de hechos, que normalmente almacenan grandes volúmenes de datos, deben permanecer como tablas de modo de almacenamiento de DirectQuery. Se filtrarán por las tablas de dimensiones del modo de almacenamiento dual relacionadas, que se pueden combinar con la tabla de hechos para lograr un filtrado y una agrupación eficaces.
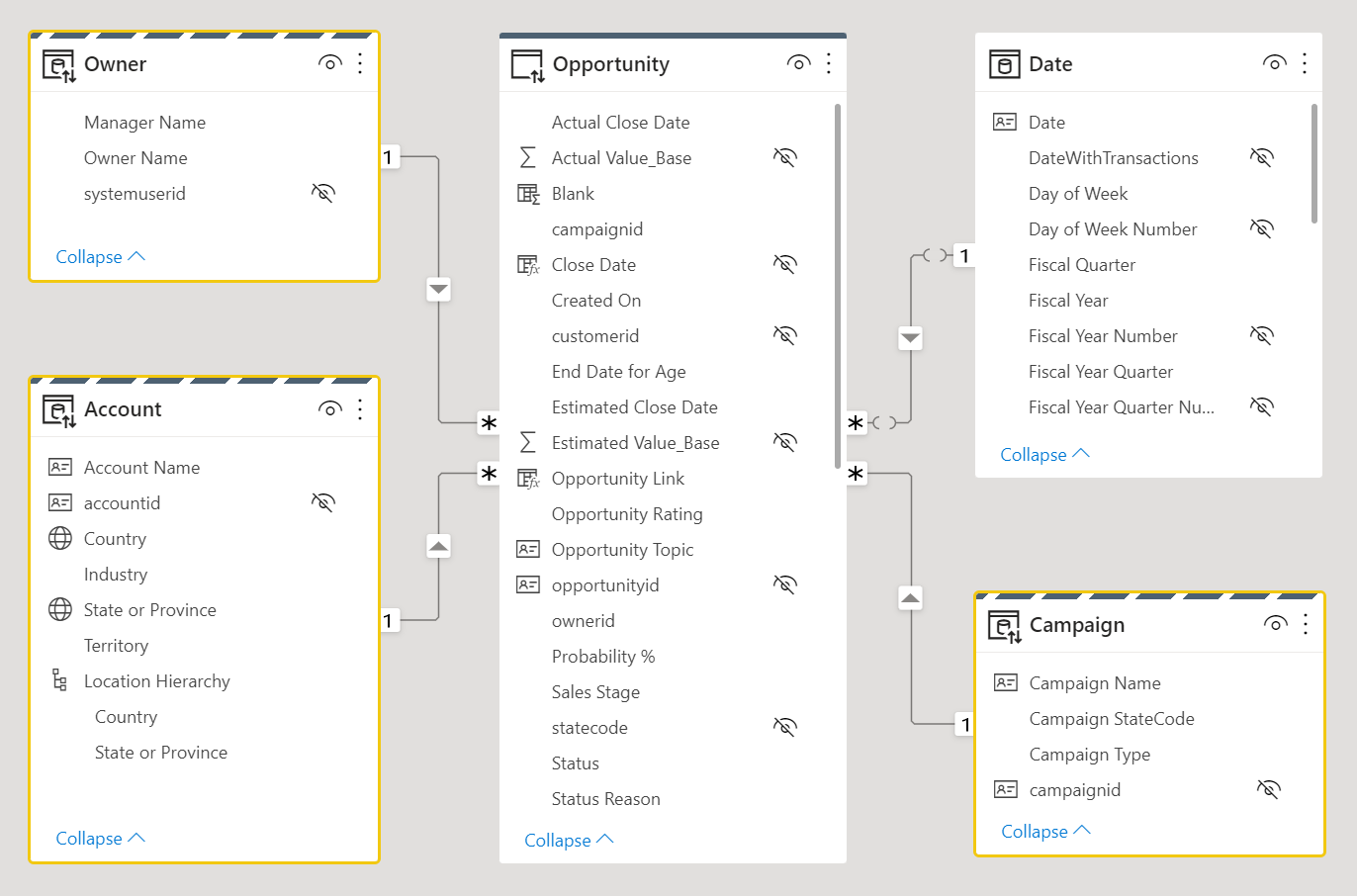
Considere el siguiente diseño de modelos de datos: Tres tablas de dimensiones, Owner, Accounty Campaign tienen un borde superior seccionado, lo que significa que se establecen en modo de almacenamiento dual.
Para obtener más información sobre el modo de almacenamiento de tablas, icluido el almacenamiento dual, consulte Administración del modo de almacenamiento en Power BI Desktop.
Habilitar el inicio de sesión único
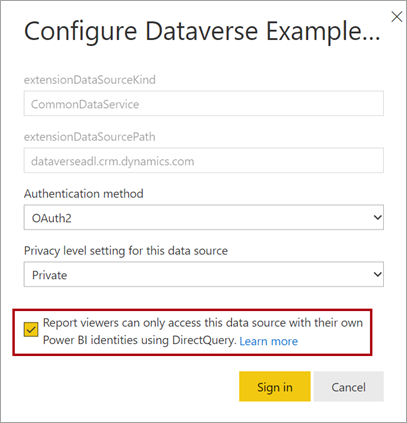
Al publicar un modelo de DirectQuery en el servicio Power BI, puede usar la configuración del modelo semántico para habilitar el inicio de sesión único (SSO) mediante microsoft Entra ID OAuth2 para los usuarios del informe. Debe habilitar esta opción cuando las consultas de Dataverse deben ejecutarse en el contexto de seguridad del usuario del informe.
Cuando la opción SSO está habilitada, Power BI envía las credenciales autenticadas de Microsoft Entra del usuario del informe en las consultas a Dataverse. Esta opción permite a Power BI respetar la configuración de seguridad que se configura en el origen de datos, como la seguridad de nivel de fila.
Para más información, consulte Inicio de sesión único (SSO) para orígenes de DirectQuery.
Replicación de filtros "My" (Mis) en Power Query
Al usar Microsoft Dynamics 365 Customer Engagement (CE) y Power Apps basado en modelos basado en Dataverse, puede crear vistas que muestren solo los registros en los que un campo de nombre de usuario, como Owner, es igual al usuario actual. Por ejemplo, puede crear vistas denominadas "Mis oportunidades abiertas", "Mis casos activos" y otras.
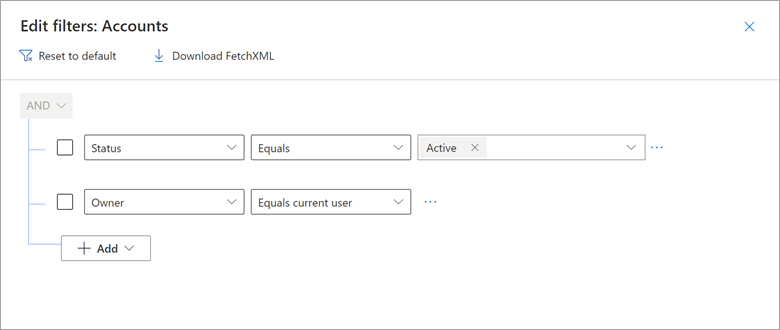
Considere un ejemplo de cómo la vista Mis cuentas activas de Dynamics 365 incluye un filtro en el que Propietario es igual a usuario actual.
Puede reproducir este resultado en Power Query mediante una consulta nativa que inserta el CURRENT_USER token.
Considere el ejemplo siguiente que muestra una consulta nativa que devuelve las cuentas del usuario actual. En la cláusula WHERE, observe que el token de CURRENT_USER filtra la columna ownerid.
let
Source = CommonDataService.Database("demo.crm.dynamics.com", [CreateNavigationProperties=false],
dbo_account = Value.NativeQuery(Source, "
SELECT
accountid, accountnumber, ownerid, address1_city, address1_stateorprovince, address1_country
FROM account
WHERE statecode = 0
AND ownerid = CURRENT_USER
", null, [EnableFolding]=true])
in
dbo_account
Al publicar el modelo en el servicio Power BI, debe habilitar el inicio de sesión único (SSO) para que Power BI envíe las credenciales de Microsoft Entra autenticadas del usuario del informe a Dataverse.
Creación de modelos de importación adicionales
Puede crear un modelo de DirectQuery que aplique permisos de Dataverse sabiendo que el rendimiento será lento. Después, puede complementar este modelo con modelos de importación que tienen como destino temas o audiencias específicos que podrían aplicar permisos de RLS.
Por ejemplo, un modelo de importación podría proporcionar acceso a todos los datos de Dataverse, pero no aplicar ningún permiso. Este modelo sería adecuado para los ejecutivos que ya tienen acceso a todos los datos de Dataverse.
Como otro ejemplo, cuando Dataverse aplica permisos basados en roles por región de ventas, podría crear un modelo de importación y replicar esos permisos mediante RLS. Como alternativa, puede crear un modelo para cada región de ventas. Después, podría conceder permiso de lectura a esos modelos (modelos semánticos) a los vendedores de cada región. Para facilitar la creación de estos modelos regionales, puede usar parámetros y plantillas de informe. Para obtener más información, consulte Creación y uso de plantillas de informe en Power BI Desktop.
Contenido relacionado
Para más información sobre este artículo, consulte los recursos siguientes.