hll_merge() (función de agregación)
Se aplica a: ✅Microsoft Fabric✅Azure Data Explorer✅Azure Monitor✅Microsoft Sentinel
Combina los resultados de HLL en el grupo en un único valor HLL.
Nota:
No se pueden combinar valores hll creados con valores de precisión diferentes. Para obtener más información, vea hll().
Nota:
Esta función se usa junto con el operador summarize.
Para obtener más información, consulte el algoritmo subyacente (HyperLogLog) y la precisión de la estimación.
Sintaxis
hll_merge
(
Hll)
Obtenga más información sobre las convenciones de sintaxis.
Parámetros
| Nombre | Type | Obligatorio | Descripción |
|---|---|---|---|
| hll | string |
✔️ | Nombre de columna que contiene valores HLL que se van a combinar. |
Devoluciones
La función devuelve los valores HLL combinados de hll en todo el grupo.
Nota:
- Los resultados de hll(), hll_if() y hll_merge() se pueden almacenar y recuperar posteriormente. Por ejemplo, es posible que quiera crear un resumen de usuario único diario, que luego se puede usar para calcular recuentos semanales. Sin embargo, la representación binaria precisa de estos resultados puede cambiar con el tiempo. No hay ninguna garantía de que estas funciones produzcan resultados idénticos para entradas idénticas y, por tanto, no se recomienda confiar en ellas.
- Use la función dcount_hll para calcular las
dcountfunciones de agregación hll() y hll_merge().
Ejemplo
En el ejemplo siguiente se muestran los resultados de HLL en un grupo combinado en un único valor HLL.
StormEvents
| summarize hllRes = hll(DamageProperty) by bin(StartTime,10m)
| summarize hllMerged = hll_merge(hllRes)
Salida
Los resultados muestran solo los cinco primeros resultados en la matriz.
| hllMerged |
|---|
| [[1024,14],["-6903255281122589438","-7413697181929588220","-2396604341988936699","5824198135224880646","-6257421034880415225", ...],[]] |
Precisión de la estimación
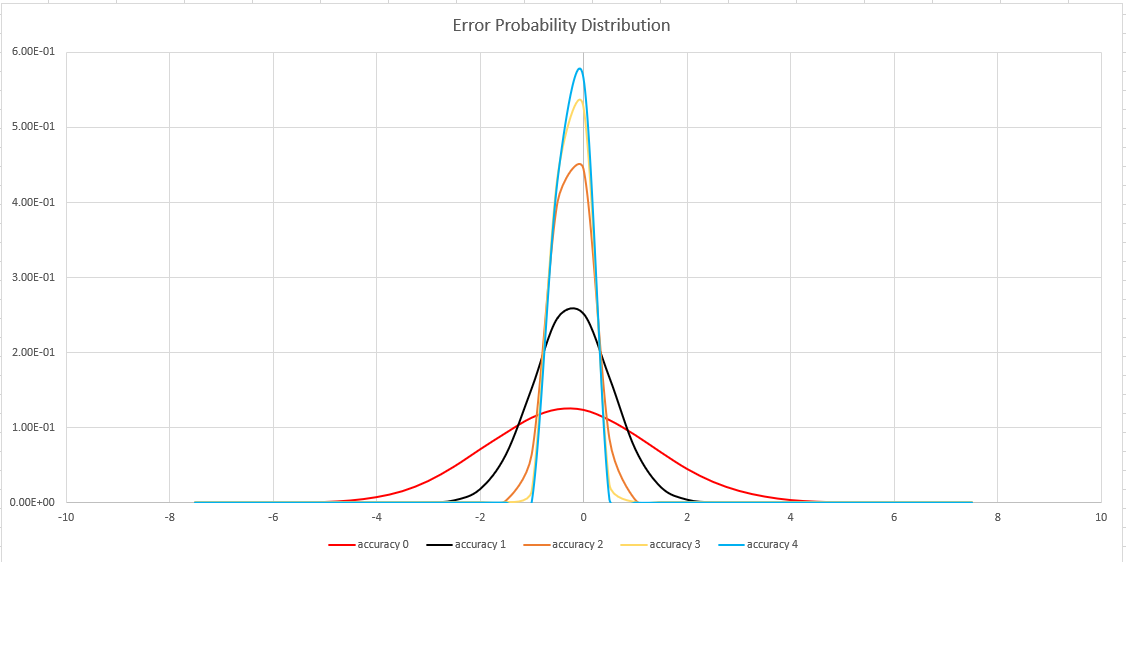
Esta función usa una variante del algoritmo HyperLogLog (HLL), que realiza una estimación estocástica de la cardinalidad establecida. El algoritmo proporciona una "manija" que se puede usar para equilibrar la precisión y el tiempo de ejecución por tamaño de memoria:
| Precisión | Error (%) | Recuento de entradas |
|---|---|---|
| 0 | 1.6 | 212 |
| 1 | 0.8 | 214 |
| 2 | 0,4 | 216 |
| 3 | 0,28 | 217 |
| 4 | 0,2 | 218 |
Nota:
La columna "recuento de entradas" es el número de contadores de 1 byte en la implementación HLL.
El algoritmo incluye algunas disposiciones para realizar un recuento perfecto (cero errores), si la cardinalidad del conjunto es lo suficientemente pequeña:
- Cuando el nivel de precisión es
1, se devuelven 1000 valores. - Cuando el nivel de precisión es
2, se devuelven 8000 valores.
El límite de errores es probabilístico, no un enlace teórico. El valor es la desviación estándar de la distribución de errores (sigma) y el 99,7 % de las estimaciones tendrá un error relativo de menos de 3 x sigma.
En la imagen siguiente se muestra la función de distribución de probabilidad del error de estimación relativa, en porcentajes, para todas las configuraciones de precisión compatibles: