Operador summarize
Se aplica a: ✅Microsoft Fabric✅Azure Data Explorer✅Azure Monitor✅Microsoft Sentinel
Crea una tabla que agrega el contenido de la tabla de entrada.
Sintaxis
T | summarize [ SummarizeParameters ] [[Column =] Aggregation [, ...]] [by [Column =] GroupExpression [, ...]]
Obtenga más información sobre las convenciones de sintaxis.
Parámetros
| Nombre | Type | Obligatorio | Descripción |
|---|---|---|---|
| Column | string |
Nombre de la columna de resultado. El valor predeterminado es un nombre derivado de la expresión. | |
| Agregación | string |
✔️ | una llamada a una función de agregación como count() o avg(), con nombres de columna como argumentos. |
| GroupExpression | escalares | ✔️ | expresión escalar que puede hacer referencia a los datos de entrada. La salida tendrá tantos registros como valores únicos tienen todas las expresiones de grupo. |
| SummarizeParameters | string |
Cero o más parámetros separados por espacios en forma de Valor de nombre = que controlan el comportamiento. Consulte parámetros admitidos. |
Nota:
Cuando la tabla de entrada está vacía, el resultado depende de si se usa GroupExpression:
- Si no se especifica GroupExpression, la salida será una fila única (vacía).
- Si se especifica GroupExpression, la salida no tendrá ninguna fila.
Parámetros admitidos
| Nombre | Descripción |
|---|---|
hint.num_partitions |
Especifica el número de particiones usadas para compartir la carga de consultas en los nodos del clúster. Consulte la consulta aleatoria. |
hint.shufflekey=<key> |
La consulta shufflekey comparte la carga de consultas en los nodos del clúster mediante una clave para crear particiones de datos. Consulte la consulta aleatoria. |
hint.strategy=shuffle |
La consulta de estrategia shuffle comparte la carga de consultas en los nodos del clúster, donde cada nodo procesará una partición de los datos. Consulte la consulta aleatoria. |
Devoluciones
Las filas de entrada están organizadas en grupos que tienen los mismos valores que las expresiones by . A continuación, las funciones de agregación especificadas se calculan sobre cada grupo, generando una fila para cada grupo. El resultado contiene las columnas by y también al menos una columna para cada agregación procesada. (Algunas funciones de agregación devuelven varias columnas.)
El resultado tiene tantas filas como el número de combinaciones únicas de los valores de by (que puede ser cero). Si no se especifica ninguna clave de grupo, el resultado tiene un único registro.
Para resumir intervalos de valores numéricos, use bin() para reducir los intervalos a valores discretos.
Nota:
- Aunque puede proporcionar expresiones arbitrarias para las expresiones de agregación y las de agrupación, resulta más eficaz usar nombres de columna simples, o bien aplicar
bin()a una columna numérica. - Ya no se admiten las ejecuciones de discretizaciones automáticas cada hora para las columnas de datetime. Use la discretización explícita en su lugar. Por ejemplo,
summarize by bin(timestamp, 1h).
Valores predeterminados de agregaciones
En la siguiente tabla se resumen los valores predeterminados de las agregaciones:
| Operador | Valor predeterminado |
|---|---|
count(), countif(), dcount(), dcountif(), count_distinct(), sum(), sumif(), variance(), varianceif(), , stdev()stdevif() |
0 |
make_bag(), make_bag_if(), make_list(), make_list_if(), , make_set(), make_set_if() |
matriz dinámica vacía ([]) |
| Todos los demás | null |
Nota:
Al aplicar estos agregados a entidades que incluyen valores NULL, se omiten los valores NULL y no se factoriza en el cálculo. Para obtener ejemplos, vea Agregados valores predeterminados.
Ejemplos
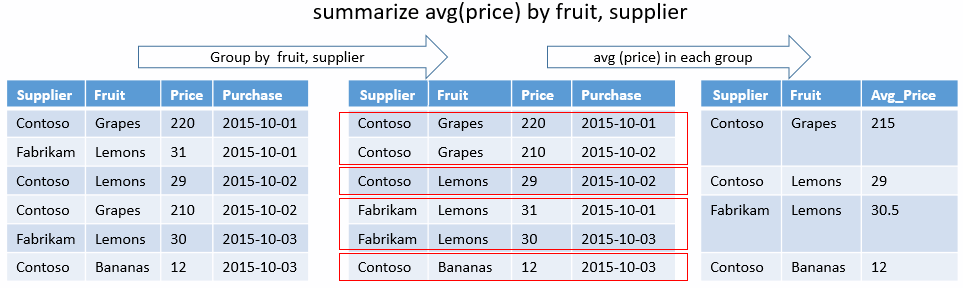
Combinación única
La consulta siguiente determina qué combinaciones únicas de State y EventType hay para tormentas que dieron lugar a lesiones directas. No hay ninguna función de agregación, solo claves de agrupación. La salida solo mostrará las columnas de esos resultados.
StormEvents
| where InjuriesDirect > 0
| summarize by State, EventType
Salida
En la tabla siguiente solo se muestran las 5 primeras filas. Para ver la salida completa, ejecute la consulta.
| State | EventType |
|---|---|
| TEXAS | Viento de tormenta |
| TEXAS | Riada |
| TEXAS | Clima de invierno |
| TEXAS | Viento fuerte |
| TEXAS | Inundación |
| ... | ... |
Marca de tiempo mínima y máxima
Busca las tormentas y aguaceros con precipitaciones mínimas y máximas en Hawái. No hay ninguna cláusula de agrupar por, así que hay una sola fila en la salida:
StormEvents
| where State == "HAWAII" and EventType == "Heavy Rain"
| project Duration = EndTime - StartTime
| summarize Min = min(Duration), Max = max(Duration)
Salida
| Min | Max |
|---|---|
| 01:08:00 | 11:55:00 |
Recuento de valores únicos
La consulta siguiente calcula el número de tipos de eventos de storm únicos para cada estado y ordena los resultados por el número de tipos de tormenta únicos:
StormEvents
| summarize TypesOfStorms=dcount(EventType) by State
| sort by TypesOfStorms
Salida
En la tabla siguiente solo se muestran las 5 primeras filas. Para ver la salida completa, ejecute la consulta.
| State | TypesOfStorms |
|---|---|
| TEXAS | 27 |
| CALIFORNIA | 26 |
| PENSILVANIA | 25 |
| GEORGIA | 24 |
| ILLINOIS | 23 |
| ... | ... |
Histograma
En el ejemplo siguiente se calcula un histograma con los tipos de eventos de tormenta que indicaban tormentas que duraban más de 1 día. Como Duration tiene muchos valores, debe usar bin() para agrupar los valores en intervalos de 1 día.
StormEvents
| project EventType, Duration = EndTime - StartTime
| where Duration > 1d
| summarize EventCount=count() by EventType, Length=bin(Duration, 1d)
| sort by Length
Salida
| EventType | Length | EventCount |
|---|---|---|
| Sequía | 30.00:00:00 | 1646 |
| Wildfire | 30.00:00:00 | 11 |
| Heat (Calor) | 30.00:00:00 | 14 |
| Inundación | 30.00:00:00 | 20 |
| Lluvia intensa | 29.00:00:00 | 42 |
| ... | ... | ... |
Valores predeterminados de los agregados
Cuando la entrada del operador summarize tiene al menos una clave de agrupación vacía, el resultado también está vacío.
Cuando la entrada del operador summarize no tiene ninguna clave de agrupación vacía, el resultado son los valores predeterminados de los agregados que se usan en summarizePara obtener más información, vea Valores predeterminados de agregaciones.
datatable(x:long)[]
| summarize any_x=take_any(x), arg_max_x=arg_max(x, *), arg_min_x=arg_min(x, *), avg(x), buildschema(todynamic(tostring(x))), max(x), min(x), percentile(x, 55), hll(x) ,stdev(x), sum(x), sumif(x, x > 0), tdigest(x), variance(x)
Salida
| any_x | arg_max_x | arg_min_x | avg_x | schema_x | max_x | min_x | percentile_x_55 | hll_x | stdev_x | sum_x | sumif_x | tdigest_x | variance_x |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| NaN | 0 | 0 | 0 | 0 |
El resultado de avg_x(x) es NaN debido a dividirlo por 0.
datatable(x:long)[]
| summarize count(x), countif(x > 0) , dcount(x), dcountif(x, x > 0)
Salida
| count_x | countif_ | dcount_x | dcountif_x |
|---|---|---|---|
| 0 | 0 | 0 | 0 |
datatable(x:long)[]
| summarize make_set(x), make_list(x)
Salida
| set_x | list_x |
|---|---|
| [] | [] |
El promedio agregado suma todos los valores que no son null y solo cuenta aquellos que formaron parte del cálculo (no se tienen en cuenta los valores null).
range x from 1 to 4 step 1
| extend y = iff(x == 1, real(null), real(5))
| summarize sum(y), avg(y)
Salida
| sum_y | avg_y |
|---|---|
| 15 | 5 |
El recuento normal contará los valores NULL:
range x from 1 to 2 step 1
| extend y = iff(x == 1, real(null), real(5))
| summarize count(y)
Salida
| count_y |
|---|
| 2 |
range x from 1 to 2 step 1
| extend y = iff(x == 1, real(null), real(5))
| summarize make_set(y), make_set(y)
Salida
| set_y | set_y1 |
|---|---|
| [5,0] | [5,0] |