Recomendaciones para la respuesta a incidentes de seguridad
Se aplica a la recomendación de lista de comprobación de seguridad del marco de trabajo bien diseñado de Azure:
| SE:12 | Defina y pruebe los procedimientos de respuesta a incidentes eficaces que abarcan un espectro de incidentes, desde problemas localizados hasta la recuperación ante desastres. Defina claramente qué equipo o individuo ejecuta un procedimiento. |
|---|
En esta guía se describen las recomendaciones para implementar una respuesta a incidentes de seguridad para una carga de trabajo. Si hay un riesgo de seguridad para un sistema, un enfoque de respuesta sistemática a incidentes ayuda a reducir el tiempo necesario para identificar, administrar y mitigar los incidentes de seguridad. Estos incidentes pueden amenazar la confidencialidad, integridad y disponibilidad de los sistemas y datos de software.
La mayoría de las empresas tienen un equipo de operaciones de seguridad central (también conocido como Security Operations Center (SOC) o SecOps. La responsabilidad del equipo de operaciones de seguridad es detectar, priorizar y evaluar rápidamente posibles ataques. El equipo también supervisa los datos de telemetría relacionados con la seguridad e investiga las infracciones de seguridad.
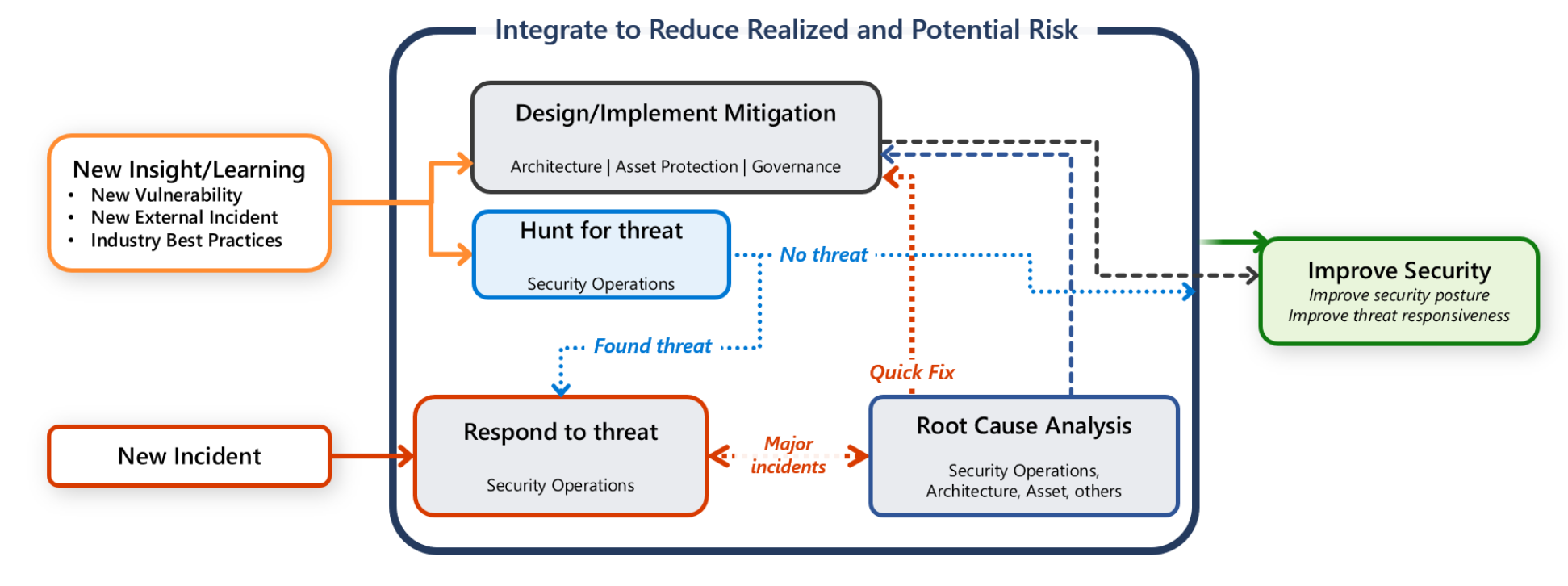
Sin embargo, también tiene la responsabilidad de proteger la carga de trabajo. Es importante que las actividades de comunicación, investigación y búsqueda sean un esfuerzo colaborativo entre el equipo de cargas de trabajo y el equipo de SecOps.
En esta guía se proporcionan recomendaciones para usted y el equipo de cargas de trabajo para ayudarle a detectar, evaluar e investigar rápidamente los ataques.
Definiciones
| Término | Definición |
|---|---|
| Alerta | Notificación que contiene información sobre un incidente. |
| Fidelidad de alertas | Precisión de los datos que determina una alerta. Las alertas de alta fidelidad contienen el contexto de seguridad necesario para realizar acciones inmediatas. Las alertas de baja fidelidad carecen de información o contienen ruido. |
| Falso positivo | Una alerta que indica un incidente que no se ha producido. |
| Incidente | Evento que indica el acceso no autorizado a un sistema. |
| Respuesta a incidentes | Proceso que detecta, responde y mitiga los riesgos asociados a un incidente. |
| Evaluación de errores | Una operación de respuesta a incidentes que analiza los problemas de seguridad y prioriza su mitigación. |
Estrategias de diseño principales
Usted y su equipo realizan operaciones de respuesta a incidentes cuando hay una señal o alerta para un riesgo potencial. Las alertas de alta fidelidad contienen un amplio contexto de seguridad que facilita a los analistas tomar decisiones. Las alertas de alta fidelidad producen un número bajo de falsos positivos. En esta guía se supone que un sistema de alertas filtra señales de baja fidelidad y se centra en las alertas de alta fidelidad que podrían indicar un incidente real.
Designar contactos de notificación de incidentes
Las alertas de seguridad deben llegar a las personas adecuadas de su equipo y de su organización. Establezca un punto de contacto designado en el equipo de carga de trabajo para recibir notificaciones de incidentes. Estas notificaciones deben incluir la mayor cantidad de información posible sobre el recurso que está en peligro y el sistema. La alerta debe incluir los pasos siguientes para que el equipo pueda acelerar las acciones.
Se recomienda registrar y administrar las notificaciones y acciones de incidentes mediante herramientas especializadas que mantienen una pista de auditoría. Mediante el uso de herramientas estándar, puede conservar evidencias que podrían ser necesarias para posibles investigaciones legales. Busque oportunidades para implementar la automatización que puede enviar notificaciones en función de las responsabilidades de las partes responsables. Mantenga una cadena clara de comunicación e informes durante un incidente.
Aproveche las soluciones de administración de eventos de información de seguridad (SIEM) y las soluciones de respuesta automatizada de orquestación de seguridad (SOAR) que proporciona su organización. Como alternativa, puede adquirir herramientas de administración de incidentes y animar a su organización a estandarizarlas para todos los equipos de cargas de trabajo.
Investigación con un equipo de evaluación de prioridades
El miembro del equipo que recibe una notificación de incidente es responsable de configurar un proceso de evaluación de prioridades que implique a las personas adecuadas en función de los datos disponibles. El equipo de evaluación de prioridades, a menudo llamado equipo puente, debe aceptar el modo y el proceso de comunicación. ¿Este incidente requiere discusiones asincrónicas o llamadas de puente? ¿Cómo debe realizar el seguimiento del equipo y comunicar el progreso de las investigaciones? ¿Dónde puede el equipo acceder a los recursos de incidentes?
La respuesta a incidentes es una razón fundamental para mantener la documentación actualizada, como el diseño arquitectónico del sistema, la información en un nivel de componente, la privacidad o la clasificación de seguridad, los propietarios y los puntos clave de contacto. Si la información es inexacta o obsoleta, el equipo de puente pierde tiempo valioso intentando comprender cómo funciona el sistema, quién es responsable de cada área y cuál podría ser el efecto del evento.
Para realizar investigaciones adicionales, implique a las personas adecuadas. Puede incluir un administrador de incidentes, un responsable de seguridad o clientes potenciales centrados en cargas de trabajo. Para mantener la evaluación de prioridades centrada, excluya a las personas que están fuera del ámbito del problema. A veces, los equipos independientes investigan el incidente. Puede haber un equipo que investigue inicialmente el problema e intente mitigar el incidente y otro equipo especializado que pueda realizar análisis forenses para una investigación profunda para determinar problemas amplios. Puede poner en cuarentena el entorno de carga de trabajo para permitir que el equipo forense realice sus investigaciones. En algunos casos, el mismo equipo podría controlar toda la investigación.
En la fase inicial, el equipo de evaluación de prioridades es responsable de determinar el vector potencial y su efecto en la confidencialidad, integridad y disponibilidad (también denominado CIA) del sistema.
Dentro de las categorías de CIA, asigne un nivel de gravedad inicial que indique la profundidad del daño y la urgencia de la corrección. Se espera que este nivel cambie con el tiempo, ya que se detecta más información en los niveles de evaluación de prioridades.
En la fase de detección, es importante determinar un curso inmediato de acciones y planes de comunicación. ¿Hay algún cambio en el estado en ejecución del sistema? ¿Cómo se puede contener el ataque para detener una mayor explotación? ¿Necesita el equipo enviar comunicación interna o externa, como una divulgación responsable? Considere la detección y el tiempo de respuesta. Es posible que esté obligado legalmente a notificar algunos tipos de infracciones a una autoridad normativa dentro de un período de tiempo específico, que suele ser horas o días.
Si decide apagar el sistema, los pasos siguientes conducen al proceso de recuperación ante desastres (DR) de la carga de trabajo.
Si no apaga el sistema, determine cómo corregir el incidente sin afectar a la funcionalidad del sistema.
Recuperación de un incidente
Trate un incidente de seguridad como un desastre. Si la corrección requiere una recuperación completa, use los mecanismos de recuperación ante desastres adecuados desde una perspectiva de seguridad. El proceso de recuperación debe evitar las posibilidades de periodicidad. De lo contrario, la recuperación de una copia de seguridad dañada vuelve a introducir el problema. Al volver a implementar un sistema con la misma vulnerabilidad, se produce el mismo incidente. Valide los pasos y procesos de conmutación por error y conmutación por recuperación.
Si el sistema sigue funcionando, evalúe el efecto en las partes en ejecución del sistema. Siga supervisando el sistema para asegurarse de que se cumplen o se reajustan otros objetivos de confiabilidad y rendimiento mediante la implementación de procesos de degradación adecuados. No ponga en peligro la privacidad debido a la mitigación.
El diagnóstico es un proceso interactivo hasta que se identifica el vector y se identifica una posible corrección y reserva. Después del diagnóstico, el equipo trabaja en la corrección, que identifica y aplica la corrección necesaria en un período aceptable.
Las métricas de recuperación miden cuánto tiempo se tarda en corregir un problema. En caso de cierre, puede haber una urgencia en relación con los tiempos de corrección. Para estabilizar el sistema, se tarda tiempo en aplicar correcciones, revisiones y pruebas e implementar actualizaciones. Determine estrategias de contención para evitar daños adicionales y la propagación del incidente. Desarrolle procedimientos de erradicación para eliminar completamente la amenaza del medio ambiente.
Compensación: hay un equilibrio entre los objetivos de confiabilidad y los tiempos de corrección. Durante un incidente, es probable que no cumpla otros requisitos no funcionales o funcionales. Por ejemplo, es posible que tenga que deshabilitar partes del sistema mientras investiga el incidente, o incluso es posible que tenga que desconectar todo el sistema hasta determinar el ámbito del incidente. Los responsables de la toma de decisiones empresariales deben decidir explícitamente cuáles son los objetivos aceptables durante el incidente. Especifique claramente la persona responsable de esa decisión.
Información sobre un incidente
Un incidente descubre brechas o puntos vulnerables en un diseño o implementación. Es una oportunidad de mejora que se basa en las lecciones de aspectos de diseño técnico, automatización, procesos de desarrollo de productos que incluyen pruebas y la eficacia del proceso de respuesta a incidentes. Mantenga registros detallados de incidentes, incluidas las acciones realizadas, las escalas de tiempo y los resultados.
Se recomienda encarecidamente realizar revisiones estructuradas posteriores a incidentes, como análisis de causa principal y retrospectivas. Realice un seguimiento y priorice el resultado de esas revisiones y considere la posibilidad de usar lo que aprende en los diseños de cargas de trabajo futuros.
Los planes de mejora deben incluir actualizaciones de los simulacros y pruebas de seguridad, como los simulacros de continuidad empresarial y recuperación ante desastres (BCDR). Use el riesgo de seguridad como escenario para realizar una exploración en profundidad de BCDR. Los detalles pueden validar cómo funcionan los procesos documentados. No debe haber varios cuadernos de estrategias de respuesta a incidentes. Use un único origen que se pueda ajustar en función del tamaño del incidente y de la extensión o localización del efecto. Los simulacros se basan en situaciones hipotéticas. Realice simulacros en un entorno de bajo riesgo e incluya la fase de aprendizaje en los simulacros.
Realice revisiones posteriores a incidentes o postmortems para identificar puntos débiles en el proceso de respuesta y las áreas para mejorar. En función de las lecciones que aprende del incidente, actualice el plan de respuesta a incidentes (IRP) y los controles de seguridad.
Definir un plan de comunicación
Implemente un plan de comunicación para notificar a los usuarios una interrupción y informar a las partes interesadas internas sobre la corrección y las mejoras. Es necesario notificar a otras personas de la organización cualquier cambio en la línea de base de seguridad de la carga de trabajo para evitar incidentes futuros.
Genere informes de incidentes para uso interno y, si es necesario, con fines legales o de cumplimiento normativo. Además, adopte un informe de formato estándar (una plantilla de documento con secciones definidas) que el equipo de SOC usa para todos los incidentes. Asegúrese de que cada incidente tiene un informe asociado antes de cerrar la investigación.
Facilitación de Azure
Microsoft Sentinel es una solución SIEM y SOAR. Se trata de solución única para la detección de alertas, la visibilidad de amenazas, la búsqueda proactiva y la respuesta a amenazas. Para obtener más información, consulte ¿Qué es Microsoft Sentinel?
Asegúrese de que el portal de inscripción de Azure incluye información de contacto del administrador para que las operaciones de seguridad se puedan notificar directamente a través de un proceso interno. Para obtener más información, consulte Actualización de la configuración de notificación.
Para más información sobre cómo establecer un punto de contacto designado que reciba notificaciones de incidentes de Azure de Microsoft Defender for Cloud, consulte Configuración de notificaciones por correo electrónico para alertas de seguridad.
Alineación de la organización
Cloud Adoption Framework para Azure proporciona instrucciones sobre el planeamiento de la respuesta a incidentes y las operaciones de seguridad. Para obtener más información, consulte Operaciones de seguridad.
Vínculos relacionados
- Creación automática de incidentes a partir de alertas de seguridad de Microsoft
- Realizar la búsqueda de amenazas de un extremo a otro mediante la característica de búsqueda
- Configuración de notificaciones por correo electrónico para alertas de seguridad
- Información general sobre la respuesta a incidentes
- Introducción a la preparación para incidentes de Microsoft Azure
- Exploración e investigación de incidentes en Microsoft Sentinel
- Control de seguridad: respuesta a incidentes
- Soluciones SOAR en Microsoft Sentinel
- Aprendizaje: Introducción a la preparación de incidentes de Azure
- Actualización de la configuración de notificaciones de Azure Portal
- ¿Qué es un SOC?
- ¿Qué es Microsoft Sentinel?
Lista de comprobación de seguridad
Consulte el conjunto completo de recomendaciones.