Componente Importación de datos
En este artículo se describe un componente del diseñador de Azure Machine Learning.
Use este componente para cargar datos en una canalización de aprendizaje automático desde los servicios de datos en la nube existentes.
Nota
Toda la funcionalidad proporcionada por este componente se puede realizar mediante el almacén de datos y los y conjuntos de datos en la página de aterrizaje del área de trabajo. Se recomienda usar el almacén de datos y el conjunto de datos que incluye características adicionales, como la supervisión de datos. Para obtener más información, vea los artículos sobre cómo obtener acceso a datos y cómo registrar conjuntos de datos. Después de registrar un conjunto de datos, puede encontrarlo en la categoría Conjuntos de datos ->My datasets (Mis conjuntos de datos) de la interfaz del diseñador. Este componente está reservado para los usuarios de Studio (clásico) para una experiencia familiar.
El componente Importación de datos admite la lectura de datos de los siguientes orígenes:
- URL mediante HTTP
- Almacenamientos en la nube de Azure a través de almacenes de datos)
- Azure Blob Container
- Recurso compartido de archivos de Azure
- Azure Data Lake
- Azure Data Lake Gen2
- Azure SQL Database
- Azure PostgreSQL
Antes de usar el almacenamiento en la nube, debe registrar primero un almacén de datos en el área de trabajo de Azure Machine Learning. Para obtener más información, consulte Cómo acceder a datos.
Después de definir los datos que desee y conectarse al origen, Importación de datos deduce el tipo de datos de cada columna basándose en los valores que contiene y carga los datos en la canalización del diseñador. La salida de Importación de datos es un conjunto de datos que puede utilizarse con todas las canalizaciones del diseñador.
Si cambian los datos de origen, puede actualizar el conjunto de datos y agregar nuevos datos volviendo a ejecutar la Importación de datos.
Advertencia
Si el área de trabajo está en una red virtual, debe configurar los almacenes de datos para usar las características de visualización de datos del diseñador. Para más información sobre cómo usar los almacenes de datos y los conjuntos de datos en una red virtual, consulte Uso de Azure Machine Learning Studio en una instancia de Azure Virtual Network.
Procedimiento para configurar la importación de datos
Agregue el componente Importar datos a la canalización. Puede encontrar el componente en la categoría Entrada y salida de datos del diseñador.
Seleccione el componente para abrir el panel derecho.
Seleccione Origen de datos y elija el tipo de origen de datos. Podría ser HTTP o almacén de datos.
Si elige almacén de datos, puede seleccionar los almacenes de datos existentes que ya están registrados en el área de trabajo de Azure Machine Learning o crear un nuevo almacén de datos. A continuación, defina la ruta a los datos que se van a importar en el almacén de datos. Puede examinar fácilmente la ruta de acceso; para ello, seleccione Examinar ruta.

Nota
El componente Importación de datoses solo para datos tabulares. Si quiere importar varios archivos de datos tabulares a la vez, se necesitan las siguientes condiciones, o se producirán errores:
- Para incluir todos los archivos de datos en la carpeta, debe especificar
folder_name/**en Path (Ruta de acceso). - Todos los archivos de datos deben estar codificados en Unicode-8.
- Todos los archivos de datos deben tener los mismos números y nombres de columna.
- El resultado de la importación de varios archivos de datos es la concatenación de todas las filas de varios archivos en orden.
- Para incluir todos los archivos de datos en la carpeta, debe especificar
Seleccione el esquema de vista previa para filtrar las columnas que desea incluir. También puede definir la configuración avanzada, como el delimitador en las opciones del análisis.
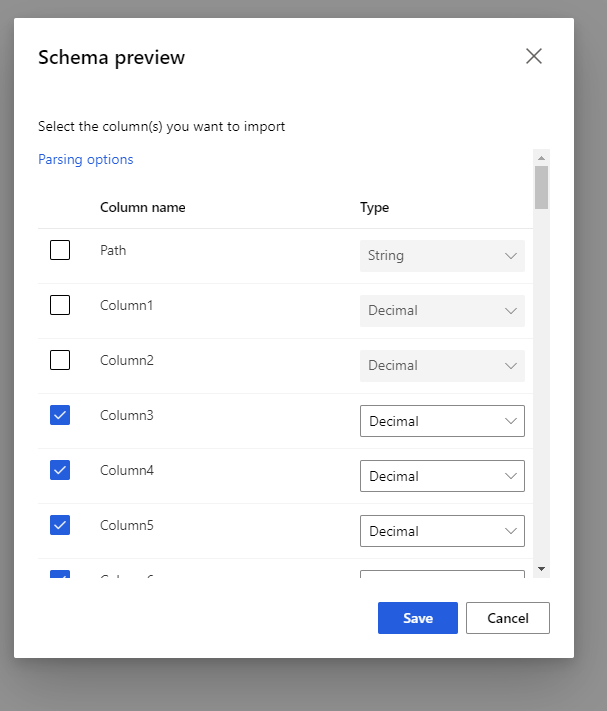
La casilla Regenerar salida decide si se va a ejecutar el componente para regenerar la salida en tiempo de ejecución.
No está activada de manera predeterminada, lo que significa que si el componente se ha ejecutado con los mismos parámetros anteriormente, el sistema reutiliza la salida de la última ejecución para reducir el tiempo de ejecución.
Si está activada, el sistema vuelve a ejecutar el componente para volver a generar la salida. Por lo tanto, seleccione esta opción cuando se actualicen los datos subyacentes en el almacenamiento, ya que puede ayudar a obtener los datos más recientes.
Envíe la canalización.
Cuando la importación de datos carga los datos en el diseñador, deduce el tipo de datos de cada columna basándose en los valores que contiene, numéricos o categóricos.
Si el encabezado está presente, se utiliza para asignar nombres a las columnas del conjunto de datos de salida.
Si no existe ningún encabezado de columna en los datos, se generan nuevos nombres de columna con el formato col1, col2... , coln *.

Results
Cuando haya terminado la importación, haga clic con el botón derecho en el conjunto de datos de salida y seleccione Visualize (Visualizar) para ver si los datos se han importado correctamente.
Si quiere guardar los datos para usarlos de nuevo, en lugar de importar un nuevo conjunto de datos cada vez que se ejecute la canalización, seleccione el icono Registrar conjunto de datos en la pestaña Salidas y registros del panel derecho del componente. Escriba un nombre para el conjunto de datos. El conjunto de datos guardado conserva los datos en el momento del guardado. El conjunto de datos no se actualiza cuando se vuelve a ejecutar la canalización, incluso si cambia el conjunto de datos de la canalización. lo que puede ser útil para tomar instantáneas de los datos.
Después de importar los datos, es posible que tenga que realizar algunos preparativos adicionales para el modelado y análisis:
Use Editar metadatos para cambiar los nombres de columna, para controlar una columna como un tipo de datos diferente, o para indicar que algunas columnas son etiquetas o características.
Use Seleccionar columnas de conjunto de datos para seleccionar un subconjunto de columnas para transformar o usar en el modelado. Puede volver a unir fácilmente las columnas transformadas o quitadas al conjunto de datos original mediante el componenteAgregar columnas.
Use Partición y muestra para dividir el conjunto de datos, realizar un muestreo u obtener las primeras n filas.
Limitaciones
Debido a la limitación del acceso al almacén de datos, si la canalización de inferencia contiene el componente Importar datos, se quita automáticamente cuando se implementa en el punto de conexión en tiempo real.
Pasos siguientes
Vea el conjunto de componentes disponibles para Azure Machine Learning.