Componente Partición y muestra
En este artículo se describe un componente del diseñador de Azure Machine Learning.
Use el componente Partición y muestra para llevar a cabo un muestreo en un conjunto de datos o para crear particiones del conjunto de datos.
El muestreo es una herramienta importante en Machine Learning porque permite reducir el tamaño de un conjunto de datos mientras mantiene la misma relación de valores. Este componente admite varias tareas relacionadas que son importantes en el aprendizaje automático:
División de los datos en varias subsecciones del mismo tamaño.
Puede usar las particiones para la validación cruzada o para asignar casos a grupos aleatorios.
Separación de los datos en grupos para trabajar con los datos de un grupo específico.
Después de asignar aleatoriamente casos a diferentes grupos, puede que deba modificar las características asociadas a un único grupo.
Muestreo.
Puede extraer un porcentaje de los datos, aplicar un muestreo aleatorio o elegir una columna para usarla para equilibrar el conjunto de datos y realizar el muestreo estratificado de sus valores.
Creación de un conjunto de datos más pequeño para las pruebas.
Si tiene una gran cantidad de datos, puede utilizar solo las n primeras filas al configurar la canalización y después cambiar al conjunto de datos completo cuando compile el modelo. También puede usar el muestreo para crear conjuntos de datos más pequeños para usarlos en el desarrollo.
Configuración del componente
Este componente admite los siguientes métodos para dividir los datos en particiones o para el muestreo. Elija el método en primer lugar y, luego, establezca las opciones adicionales que requiera el método.
- Head
- muestreo
- Asignar a plegamientos
- Seleccionar plegamiento
Obtener las N filas superiores de un conjunto de datos
Utilice este modo para obtener solo las n primeras filas. Esta opción es útil si quiere probar una canalización en un pequeño número de filas y no necesita compensar o muestrear los datos en ningún modo.
Agregue el componente Partición y muestra a la canalización de la interfaz y conecte el conjunto de datos.
Partition or sample mode (Modo de partición o muestra): establezca esta opción en Principal.
Number of rows to select (Número de filas que se deben seleccionar): escriba el número de filas que se devolverán.
El número de filas debe ser un entero no negativo. Si el número de filas seleccionadas es superior al número de filas del conjunto de datos, se devuelve el conjunto de datos completo.
Envíe la canalización.
El componente genera un único conjunto de datos que contiene solo el número especificado de filas. Las filas siempre se leen desde la parte superior del conjunto de datos.
Crear una muestra de datos
Esta opción es compatible con un muestreo aleatorio simple o un muestreo aleatorio estratificado. Esto es útil si quiere crear un conjunto de datos de muestra más pequeño representativo para las pruebas.
Agregue el componente Partición y muestra a la canalización y conecte el conjunto de datos.
Partition or sample mode (Modo de partición o muestra): establezca esta opción en Sampling (Muestreo).
Rate of sampling (Tasa de muestreo): especifique un valor entre 0 y 1. Este valor especifica el porcentaje de filas del conjunto de datos de origen que debe incluirse en el conjunto de datos de salida.
Por ejemplo, si quiere solo la mitad del conjunto de datos original, escriba
0.5para indicar que la tasa de muestreo debe ser de un 50 %.Las filas del conjunto de datos de entrada se ordenan de forma aleatoria y se colocan selectivamente en el conjunto de datos de salida, según la relación especificada.
Random seed for sampling (Inicialización aleatoria para el muestreo): opcionalmente, escriba un número entero que se usará como valor de inicialización.
Esta opción es importante si desea que las filas se dividan de la misma manera cada vez. El valor predeterminado es 0, lo que significa que se genera una inicialización inicial basada en el reloj del sistema. Este valor puede llevar a resultados ligeramente diferentes cada vez que ejecute la canalización.
Stratified split for sampling (División estratificada para el muestreo): seleccione esta opción si es importante que las filas del conjunto de datos se dividan uniformemente por alguna columna de clave antes del muestreo.
Para la Stratification key column for sampling (Columna de clave de estratificación para muestreo), seleccione una sola columna de estratos a fin de utilizarla al dividir el conjunto de datos. A continuación, las filas del conjunto de datos se dividen como sigue:
Todas las filas de entrada se agrupan (estratificadas) por los valores de la columna de estratos especificada.
Las filas se ordenan aleatoriamente dentro de cada grupo.
Cada grupo se agrega de forma selectiva al conjunto de datos de salida para cumplir con la relación especificada.
Envíe la canalización.
Con esta opción el componente genera un único conjunto de datos que contiene una muestra representativa de los datos. La salida no contiene la parte sin muestreo restante del conjunto de datos.
Dividir los datos en particiones
Use esta opción si desea dividir el conjunto de datos en subconjuntos de los datos. Esta opción también es útil cuando desea crear un número personalizado de plegamientos para la validación cruzada o dividir filas en varios grupos.
Agregue el componente Partición y muestra a la canalización y conecte el conjunto de datos.
Para el Partition or sample mode (Modo de partición o muestra), seleccione Assign to Folds (Asignar a plegamientos).
Use replacement in the partitioning (Usar reemplazo en la creación de particiones): seleccione esta opción si desea que la fila muestreada se vuelva a poner en el grupo de filas para poder reutilizarla. Como resultado, la misma fila podría asignarse a varios plegamientos.
Si no usa el reemplazo (opción predeterminada), la fila muestreada no se vuelve a colocar en el grupo de filas para poder reutilizarla. Como resultado, cada fila puede asignarse a solo un plegamiento.
Randomized split (División aleatoria): seleccione esta opción si desea que las filas se asignen aleatoriamente a plegamientos.
Si no selecciona esta opción, las filas se asignan a los subconjuntos con el método round-robin.
Random seed (Inicialización aleatoria): opcionalmente, escriba un número entero que se usará como el valor de inicialización. Esta opción es importante si desea que las filas se dividan de la misma manera cada vez. En caso contrario, el valor predeterminado de 0 significa que se usará una inicialización inicial aleatoria.
Specify the partitioner method (Especificar el método de particionador): indique cómo desea que los datos se distribuyan en cada partición, con estas opciones:
Partition evenly (Partición uniforme): use esta opción para colocar un número igual de filas en cada partición. Para especificar el número de particiones de salida, escriba un número entero en el cuadro Specify number of folds to split evenly into (Especificar el número de subconjuntos en el que realizar la división uniformemente).
Partition with customized proportions (Partición con proporciones personalizadas): Use esta opción para especificar el tamaño de cada partición como una lista separada por comas.
Por ejemplo, suponga que quiere crear tres particiones. La primera partición contendrá el 50 por ciento de los datos. Las dos particiones restantes contendrán cada una el 25 por ciento de los datos. En el cuadro List of proportions separated by comma (Lista de proporciones separadas por comas), escriba estos números: ,5, ,25, ,25.
La suma de todos los tamaños de partición debe ser exactamente 1.
Si escribe números que se suman menos de 1, se crea una partición adicional para contener las filas restantes. Por ejemplo, si escribe los valores ,2 y ,3, se crea una tercera partición que contiene el 50 por ciento restante de todas las filas.
Si escribe números que se suman a más de 1, se produce un error al ejecutar la canalización.
Stratified split (División estratificada): seleccione esta opción si desea que las filas se estratifiquen al dividir y, a continuación, elija la columna de estratos.
Envíe la canalización.
Con esta opción el componente genera varios conjuntos de datos. Los conjuntos de datos se particionan en función de las reglas especificadas.
Usar datos de una partición predefinida
Use esta opción cuando haya dividido un conjunto de datos en varias particiones y ahora quiera cargar cada partición para su posterior análisis o procesamiento.
Agregue el componente Partición y muestra a la canalización.
Conecte el componente a la salida de una instancia anterior de Partición y muestra. Esa instancia debe haber usado la opción Assign to Folds (Asignar a plegamientos) para generar algunas particiones.
Partition or sample mode (Modo de partición o muestra): seleccione Pick Fold (Seleccionar plegamiento).
Specify which fold to be sampled from (Especificar el plegamiento desde el que se debe muestrear): para seleccionar la partición que se va a usar, especifique su índice. Los índices de partición están basados en 1. Por ejemplo, si ha dividido el conjunto de datos en tres partes, las particiones tendrían los índices de 1, 2 y 3.
Si especifica un valor de índice no válido, se produce un error en tiempo de diseño: "Error 0018: Dataset contains invalid data" (El conjunto de datos contiene datos no válidos).
Además de agrupar el conjunto de datos por plegamientos, puede separar el conjunto de datos en dos grupos: un plegamiento de destino y todo lo demás. Para ello, escriba el índice de un único subconjunto y, luego, seleccione la opción Pick complement of the selected fold (Seleccionar complemento del subconjunto seleccionado), para obtener todo excepto los datos del subconjunto especificado.
Si trabaja con varias particiones, debe agregar más instancias del componente Partición y muestra para controlar cada partición.
Por ejemplo, el componente Partición y muestra de la segunda fila está establecido en Asignar a subconjuntos, mientras que el de la tercera fila lo está en Seleccionar subconjunto.
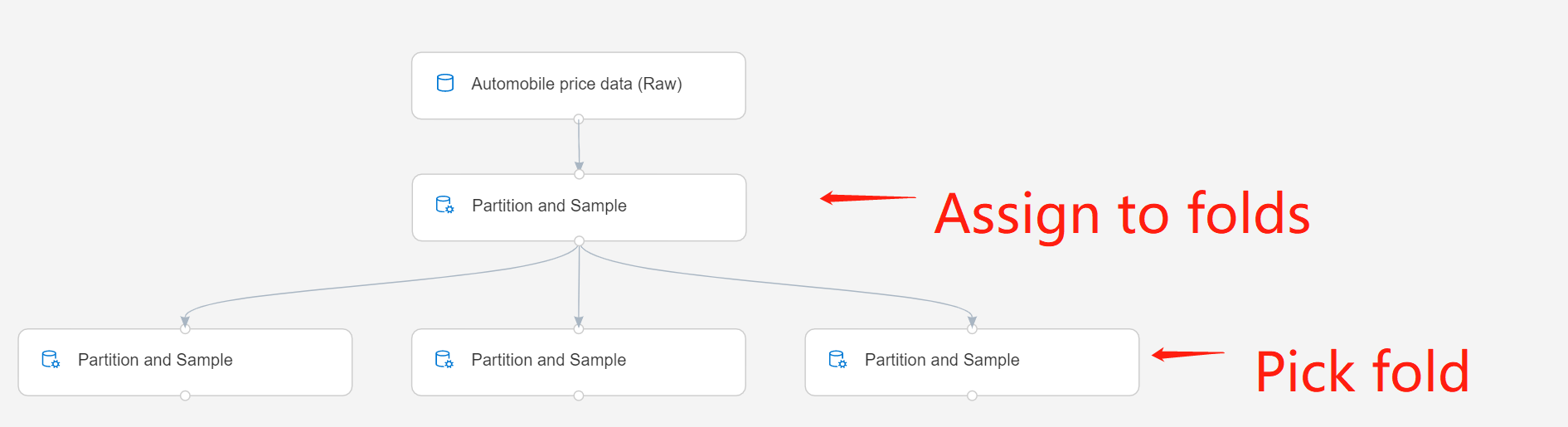
Envíe la canalización.
Con esta opción el componente genera un único conjunto de datos que contiene solo las filas asignadas a ese subconjunto.
Nota
No se pueden ver directamente las designaciones de subconjuntos. Solo están presentes en los metadatos.
Pasos siguientes
Vea el conjunto de componentes disponibles para Azure Machine Learning.