Optimización de Apache Hive con Apache Ambari en Azure HDInsight
Apache Ambari es una interfaz web para administrar y supervisar clústeres de HDInsight. Para más información sobre el uso de la interfaz de usuario web de Ambari, consulte Administración de clústeres de HDInsight con la interfaz de usuario web de Apache Ambari.
En las siguientes secciones se describen las opciones de configuración para optimizar el rendimiento general de Apache Hive.
- Para modificar los parámetros de configuración de Hive, seleccione Hive de la barra lateral Servicios.
- Navegue hasta la pestaña Configs (Configuraciones).
Establecer el motor de ejecución de Hive
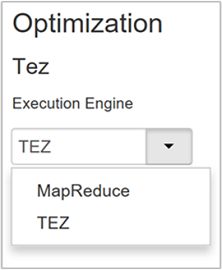
Hive proporciona dos motores de ejecución: MapReduce de Apache Hadoop y Apache TEZ. Tez es más rápido que MapReduce. Tez es el motor de ejecución predeterminado de los clústeres de HDInsight Linux. Para cambiar el motor de ejecución:
En la pestaña Configs (Configuraciones) de Hive, escriba motor de ejecución en el cuadro de filtro.
El valor predeterminado de la propiedad Optimización es Tez.
Optimizar asignadores
Hadoop intenta dividir (asignar) un único archivo en varios archivos y procesar los archivos resultantes en paralelo. El número de asignadores depende del número de divisiones. Los siguientes dos parámetros de configuración controlan el número de divisiones del motor de ejecución Tez:
tez.grouping.min-size: límite inferior en el tamaño de una división agrupada, con un valor predeterminado de 16 MB (16 777 216 bytes).tez.grouping.max-size: límite superior en el tamaño de una división agrupada, con un valor predeterminado de 1 GB (1 073 741 824 bytes).
Como directriz de rendimiento, disminuya estos dos parámetros para mejorar la latencia y aumentar el rendimiento.
Por ejemplo, para establecer cuatro tareas de asignador para un tamaño de datos de 128 MB, debe establecer cada uno de estos parámetros en 32 MB (33 554 432 bytes).
Para modificar los parámetros de límite, navegue a la pestaña Configs (Configuraciones) del servicio Tez. Expanda el panel General y busque los parámetros
tez.grouping.max-sizeytez.grouping.min-size.Establezca ambos parámetros en 33 554 432 bytes (32 MB).

Estos cambios afectan a todos los trabajos de Tez en el servidor. Para obtener un resultado óptimo, elija valores de parámetro adecuados.
Optimizar reductores
Apache ORC y Snappy ofrecen un alto rendimiento. Sin embargo, es posible que Hive tenga muy pocos reductores de forma predeterminada, y provoque cuellos de botella.
Por ejemplo, supongamos que tiene un tamaño de datos de entrada de 50 GB. Esos datos en formato ORC con compresión Snappy tiene un tamaño de 1 GB. Hive estima el número de reductores necesarios según esta fórmula: (número de bytes de entrada para los asignadores/hive.exec.reducers.bytes.per.reducer).
Con la configuración predeterminada, este ejemplo es de cuatro reductores.
El parámetro hive.exec.reducers.bytes.per.reducer especifica el número de bytes procesados por reductor. El valor predeterminado es de 64 MB. Ajustar este valor a la baja aumenta el paralelismo y puede mejorar el rendimiento. Ajustarlo demasiado a la baja también podría generar demasiados reductores y afectar negativamente al rendimiento. Este parámetro se basa en sus requisitos de datos específicos, la configuración de compresión y otros factores del entorno.
Para modificar el parámetro, navegue hasta la pestaña Configs (Configuraciones) de Hive y busque el parámetro Data per Reducer (Datos por reductor) en la página Configuración.
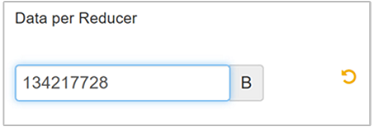
Seleccione Editar para modificar el valor a 128 MB (134 217 728 bytes) y, a continuación, presione ENTRAR para guardar los cambios.
Dado un tamaño de entrada de 1024 MB, con 128 MB de datos por reductor, hay ocho reductores (1024/128).
Un valor incorrecto para el parámetro Data per Reducer (Datos por reductor) puede dar lugar a un gran número de reductores, lo que afectaría negativamente al rendimiento de las consultas. Para limitar el número máximo de reductores, establezca
hive.exec.reducers.maxen un valor adecuado. El valor predeterminado es 1009.
Habilitar la ejecución en paralelo
Una consulta de Hive se ejecuta en una o varias fases. Si las fases independientes se pueden ejecutar en paralelo, aumentará el rendimiento de las consultas.
Para habilitar la ejecución de consultas en paralelo, navegue hasta la pestaña Configs (Configuraciones) de Hive y busque la propiedad
hive.exec.parallel. El valor predeterminado es false. Cambie el valor a true y, a continuación, presione ENTRAR para guardar el valor.Para limitar el número de trabajos que se van a ejecutar en paralelo, modifique la propiedad
hive.exec.parallel.thread.number. El valor predeterminado es 8.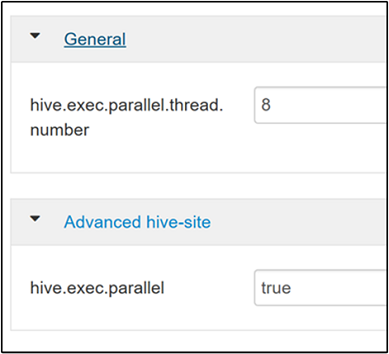
Habilitar la vectorización
Hive procesa los datos fila por fila. La vectorización dirige Hive para que procese los datos en bloques de 1024 filas en lugar de hacerlo fila por fila. La vectorización solo es aplicable al formato de archivo ORC.
Para habilitar la ejecución de consultas vectorizadas, navegue hasta la pestaña Configs (Configuraciones) de Hive y busque el parámetro
hive.vectorized.execution.enabled. El valor predeterminado es true para Hive 0.13.0 o posterior.Para habilitar la ejecución vectorizada para el lado de reducción de la consulta, establezca el parámetro
hive.vectorized.execution.reduce.enableden true. El valor predeterminado es false.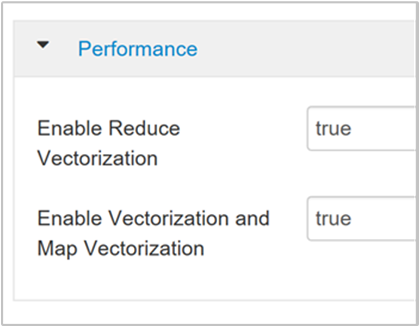
Habilitar la optimización basada en costos (CBO)
De forma predeterminada, Hive sigue un conjunto de reglas para buscar un plan de ejecución de consultas óptimo. La optimización basada en costos (CBO) evalúa varios planes para ejecutar una consulta. Luego asigna un costo a cada plan y, a continuación, determina el plan más barato para ejecutar una consulta.
Para habilitar CBO, vaya a Hive>Configs>Settings (Hive > Configuraciones > Configuración) y busque Enable Cost Based Optimizer (Habilitar optimizador basado en el costo) y, a continuación, cambie el botón de alternancia a On (Activado).

Los siguientes parámetros de configuración adicionales aumentan el rendimiento de las consulta de Hive cuando CBO está habilitado:
hive.compute.query.using.statsSi se establece en true, Hive usa las estadísticas almacenadas en su Metastore para responder a consultas simples como
count(*).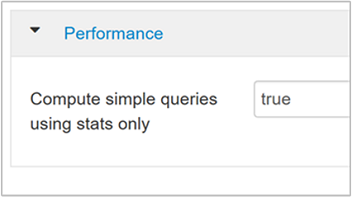
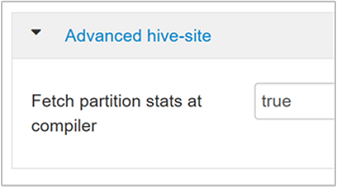
hive.stats.fetch.column.statsLas estadísticas de columnas se crean cuando se habilita CBO. Hive usa estadísticas de columnas, que se almacenan en Metastore, para optimizar las consultas. Capturar estadísticas de columnas para cada columna tarda más tiempo cuando el número de columnas es elevado. Si se establece en false, este valor deshabilita la captura de estadísticas de columnas de Metastore.
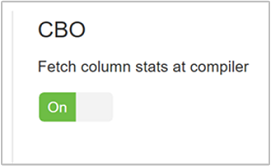
hive.stats.fetch.partition.statsLas estadísticas de partición básicas, como el número de filas, el tamaño de datos y el tamaño de archivo se almacenan en Metastore. Si se establece en true, las estadísticas de partición se capturan de Metastore. Cuando es false, el tamaño del archivo se captura desde el sistema de archivos. Y el número de filas se captura del esquema de fila.
Consulte la entrada de blog Hive Cost Based Optimization (Optimización basada en costos de Hive) en Analytics en el blog de Azure para más información.
Habilitar la compresión intermedia
Las tareas de asignación crean archivos intermedios que se usan en las tareas de reductor. La compresión intermedia reduce el tamaño de los archivos intermedios.
Los trabajos de Hadoop suelen ser un cuello de botella de E/S. La compresión de datos puede acelerar la E/S y transferencia de red en general.
Los tipos de compresión disponibles son:
| Formato | Herramienta | Algoritmo | Extensión de archivo | ¿Divisible? |
|---|---|---|---|---|
| Gzip | Gzip | DEFLATE | .gz |
No |
| Bzip2 | Bzip2 | Bzip2 | .bz2 |
Sí |
| LZO | Lzop |
LZO | .lzo |
Sí, si está indexado |
| Snappy | N/D | Snappy | Snappy | No |
Como norma general, es importante tener un método de compresión divisible, ya que, de lo contrario, se crearán pocos mapeadores. Si los datos de entrada son texto, bzip2 es la mejor opción. Para el formato ORC, Snappy es la opción de compresión más rápida.
Para habilitar la compresión intermedia, navegue hasta la pestaña Configs (Configuraciones) de Hive y, a continuación, establezca el parámetro
hive.exec.compress.intermediateen true. El valor predeterminado es false.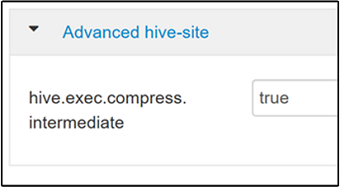
Nota:
Para comprimir archivos intermedios, elija un códec de compresión con un costo de CPU más bajo, aunque el códec no tenga una salida de compresión alta.
Para establecer el códec de compresión intermedio, agregue la propiedad personalizada
mapred.map.output.compression.codecal archivohive-site.xmlomapred-site.xml.Para agregar un valor personalizado:
a. Vaya a Hive>Configs>Advanced>Custom hive-site (Hive > Configuraciones > Avanzadas > Sitio de Hive personalizado).
b. Seleccione Add Property... (Agregar propiedad) en la parte inferior del panel Custom hive-site (Sitio de Hive personalizado).
c. En la ventana Agregar propiedad, escriba
mapred.map.output.compression.codeccomo la clave yorg.apache.hadoop.io.compress.SnappyCodeccomo el valor.d. Seleccione Agregar.
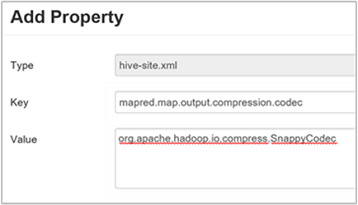
Este valor comprimirá el archivo intermedio mediante la compresión Snappy. Una vez agregada, la propiedad aparece en el panel Custom hive-site (Sitio de Hive personalizado).
Nota
Este procedimiento modifica el archivo
$HADOOP_HOME/conf/hive-site.xml.
Comprimir la salida final
También es posible comprimir la salida final de Hive.
Para habilitar la salida final de Hive, navegue hasta la pestaña Configs (Configuraciones) de Hive y, a continuación, establezca el parámetro
hive.exec.compress.outputen true. El valor predeterminado es false.Para elegir el códec de compresión de salida, agregue la propiedad personalizada
mapred.output.compression.codecal panel Custom hive-site (Sitio de Hive personalizado), como se describe en el paso 3 de la sección anterior.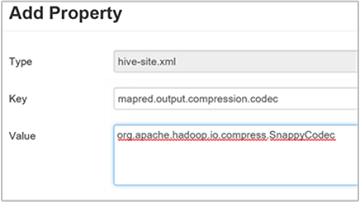
Habilitar de ejecución especulativa
La ejecución especulativa inicia un cierto número de tareas duplicadas para detectar y denegar la lista del seguimiento de tareas de ejecución lenta. A la vez mejora la ejecución general del trabajo mediante la optimización de los resultados de las tareas individuales.
La ejecución especulativa no debe activarse para las tareas MapReduce de ejecución prolongada con grandes cantidades de entradas.
Para habilitar la ejecución especulativa, navegue hasta la pestaña Configs (Configuraciones) de Hive y, a continuación, establezca el parámetro
hive.mapred.reduce.tasks.speculative.executionen true. El valor predeterminado es false.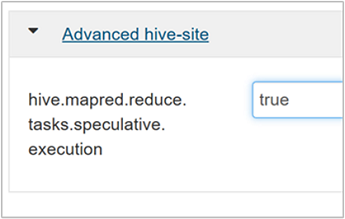
Optimizar las particiones dinámicas
Hive permite crear particiones dinámicas al insertar registros en una tabla, sin predefinir cada una de las particiones. Esta capacidad es una característica muy eficaz. Aunque, por otra parte, puede dar lugar a la creación de un gran número de particiones. También puede crear un gran número de archivos para cada partición.
Para que Hive realice particiones dinámicas, el valor del parámetro
hive.exec.dynamic.partitiondebe ser true (valor predeterminado).Cambie el modo de partición dinámica a strict. En modo strict, al menos una partición debe ser estática. Este valor impide las consultas sin filtro de partición en la cláusula WHERE, es decir, strict impide las consultas que examinan todas las particiones. Navegue hasta la pestaña Configs (Configuraciones) de Hive y, a continuación, establezca
hive.exec.dynamic.partition.modeen strict. El valor predeterminado es nonstrict.Para limitar el número de particiones dinámicas que se va a crear, modifique el parámetro
hive.exec.max.dynamic.partitions. El valor predeterminado es 5 000.Para limitar el número total de particiones dinámicas por nodo, modifique
hive.exec.max.dynamic.partitions.pernode. El valor predeterminado es 2 000.
Habilitar el modo local
El modo local permite que Hive realice todas las tareas de un trabajo en una único máquina. A veces incluso en un único proceso. Este valor mejora el rendimiento de las consultas si los datos de entrada son pequeños y la sobrecarga que supone el inicio de las tareas para las consultas, consume un porcentaje significativo de la ejecución de la consulta global.
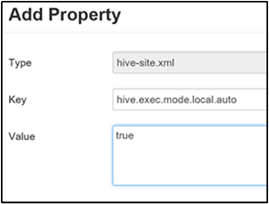
Para habilitar el modo local, agregue el parámetro hive.exec.mode.local.auto al panel Custom hive-site (Sitio de Hive personalizado), como se explica en el paso 3 de la sección Habilitar la compresión intermedia.
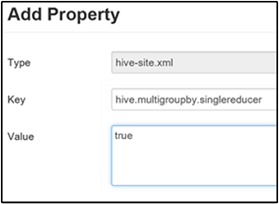
Establecer una consulta MultiGROUP BY de MapReduce única
Cuando esta propiedad está establecida en true, una consulta MultiGROUP BY con claves de agrupación comunes genera un único trabajo de MapReduce.
Para habilitar el comportamiento, agregue el parámetro hive.multigroupby.singlereducer al panel Custom hive-site (Sitio de Hive personalizado), como se explica en el paso 3 de la sección Habilitar la compresión intermedia.
Optimizaciones de Hive adicionales
En las secciones siguientes se describen las optimizaciones adicionales relacionadas con Hive que puede establecer.
Unir optimizaciones
El tipo de unión predeterminado en Hive es una unión aleatoria. En Hive, asignadores especiales leen la entrada y emiten un par de clave-valor de unión a un archivo intermedio. Hadoop ordena y combina estos pares en una fase aleatoria. Esta fase aleatoria es costosa. Al seleccionar la unión correcta en función de los datos puede mejorar significativamente el rendimiento.
| Tipo de unión | Si | Cómo | Configuración de Hive | Comentarios |
|---|---|---|---|---|
| Unión aleatoria |
|
|
No se requiere ninguna configuración de Hive importante | Funciona siempre |
| Unión de asignación |
|
|
hive.auto.convert.join=true |
Acción rápida, pero limitada |
| Ordenar el cubo de fusión mediante combinación | Si ambas tablas están:
|
Cada proceso:
|
hive.auto.convert.sortmerge.join=true |
Eficaz |
Optimizaciones del motor de ejecución
Recomendaciones adicionales para optimizar el motor de ejecución de Hive:
| Configuración | Recomendado | Valor predeterminado de HDInsight |
|---|---|---|
hive.mapjoin.hybridgrace.hashtable |
True = más seguro y más lento; false = más rápido | false |
tez.am.resource.memory.mb |
Límite superior de 4 GB para la mayor parte | Ajustado automáticamente |
tez.session.am.dag.submit.timeout.secs |
300+ | 300 |
tez.am.container.idle.release-timeout-min.millis |
20000+ | 10000 |
tez.am.container.idle.release-timeout-max.millis |
40000+ | 20000 |