Optimización de las consultas de Azure Hive en Azure HDInsight
En este artículo se describen algunas de las optimizaciones de rendimiento más comunes que puede usar para mejorar el rendimiento de las consultas de Apache Hive.
Selección del tipo de clúster
En Azure HDInsight, puede ejecutar consultas de Apache Hive en unos cuantos tipos de clústeres.
Elija el tipo de clúster adecuado para ayudar a optimizar el rendimiento de sus necesidades de carga de trabajo:
- Elija el tipo de clúster Interactive Query para optimizar las consultas interactivas
ad hoc. - Elija el tipo de clúster Apache Hadoop para optimizar la consultas de Hive utilizadas como un proceso por lotes.
- Los tipos de clúster de Spark y HBase también pueden ejecutar consultas de Hive y pueden ser adecuados si va a ejecutar esas cargas de trabajo.
Para más información sobre la ejecución de consultas de Hive en diversos tipos de clúster de HDInsight, vea ¿Qué son Apache Hive y HiveQL en Azure HDInsight?
Escalar horizontalmente nodos de trabajo
El aumento del número de nodos de trabajo de un clúster de HDInsight permite que el trabajo use más asignadores y reductores para ejecutarse en paralelo. Hay dos formas de aumentar la escala en HDInsight:
Al crear un clúster, puede especificar el número de nodos de trabajo mediante Azure Portal, Azure PowerShell o la interfaz de la línea de comandos. Para más información, consulte Creación de clústeres de Hadoop en HDInsight. En la siguiente captura de pantalla se muestra la configuración del nodo de trabajo en Azure Portal:
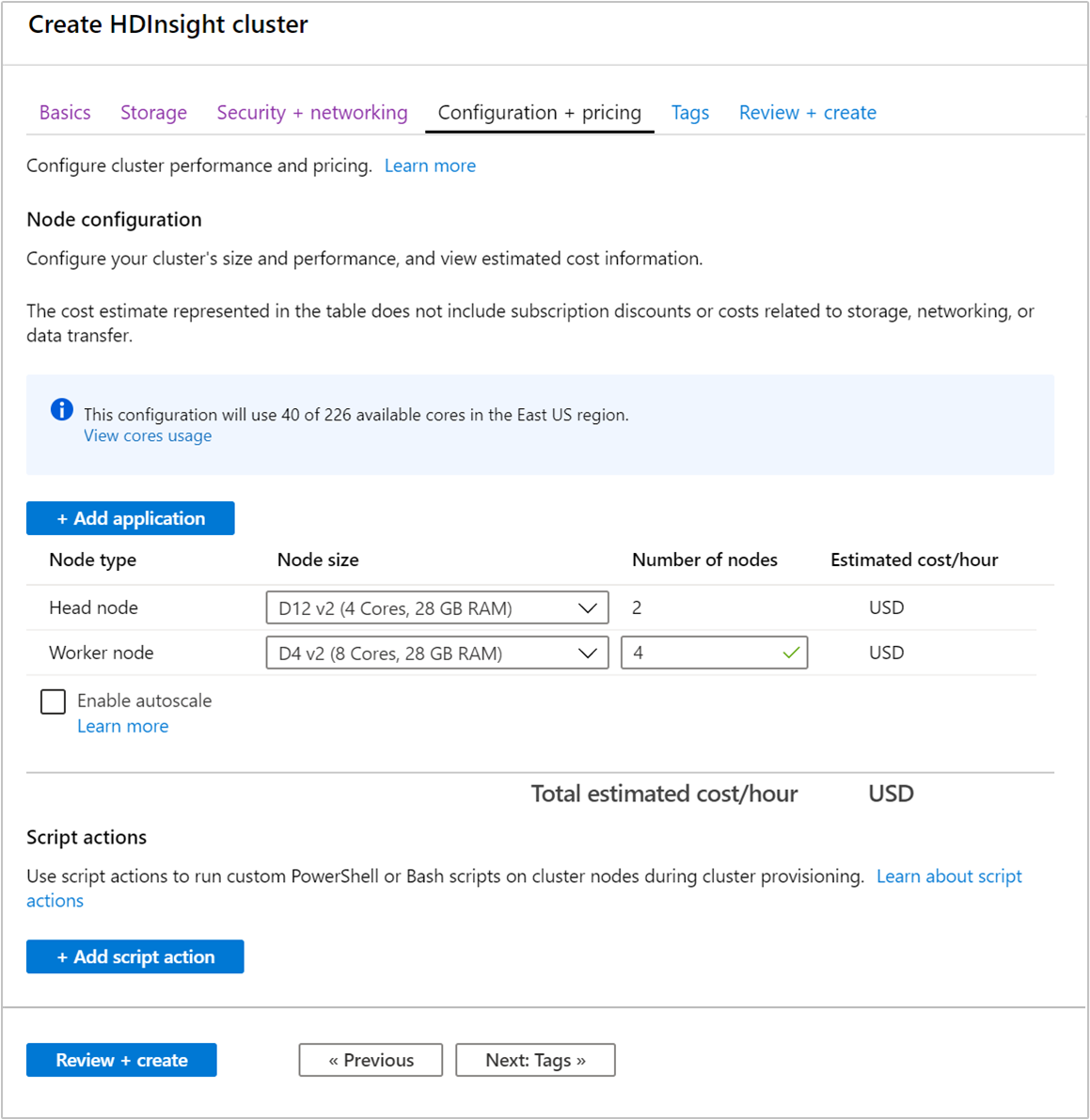
Después de la creación, también puede editar el número de nodos de trabajo para escalar horizontalmente un clúster sin volver a crear uno:
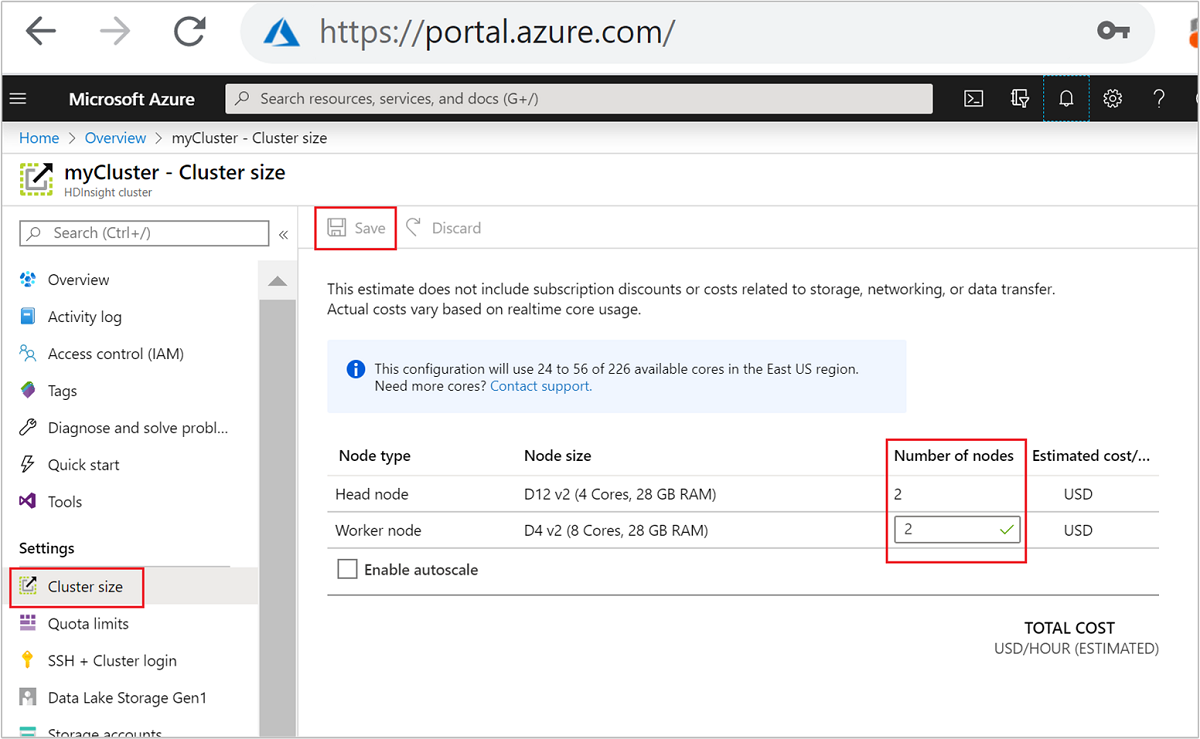
Para más información sobre la escalabilidad de HDInsight, vea Escalabilidad de clústeres de HDInsight.
Uso de Apache Tez en lugar de MapReduce
Apache Tez es un motor de ejecución alternativo al motor de MapReduce. Los clústeres de HDInsight basados en Linux tienen Tez habilitada de forma predeterminada.
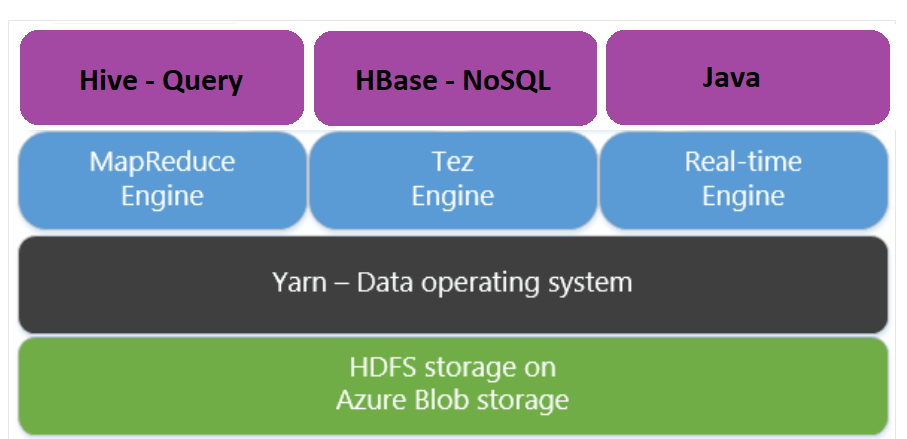
Tez es más rápido porque:
- Ejecuta el grafo acíclico dirigido (DAG) como un único trabajo en el motor de MapReduce. El DAG requiere que cada conjunto de asignadores vaya seguido de un conjunto de reductores. Este requisito hace que se pongan en marcha varios trabajos MapReduce para cada consulta de Hive. Tez no tiene tal restricción y puede procesar un DAG complejo como un trabajo, lo que minimiza la sobrecarga de inicio del trabajo.
- Evita escrituras innecesarias. Se usan varios trabajos para procesar la misma consulta de Hive en el motor de MapReduce. La salida de cada trabajo de MapReduce se escribe en HDFS para los datos intermedios. Puesto que Tez minimiza el número de trabajos para cada consulta de Hive, puede evitar escrituras innecesarias.
- Reduce retrasos de inicio. Tez puede reducir mejor el retraso de inicio disminuyendo el número de asignadores que necesita para iniciar y mejorando también la optimización.
- Reutiliza contenedores. Siempre que sea posible, Tez reutiliza contenedores para asegurarse de que se reduce la latencia del reinicio de contenedores.
- Técnicas de optimización continua. Tradicionalmente, la optimización se realizó durante la fase de compilación. Sin embargo, hay más información disponible acerca de las entradas que permiten una mejor optimización en tiempo de ejecución. Tez usa las técnicas de optimización continua que le permiten optimizar más el plan en la fase de tiempo de ejecución.
Para obtener más detalles sobre estos conceptos, consulte Apache TEZ.
Puede realizar cualquier consulta de Hive habilitada con Tez anteponiendo a la consulta el siguiente comando set:
set hive.execution.engine=tez;
Creación de particiones de Hive
Las operaciones de E/S son el principal cuello de botella de rendimiento para ejecutar consultas de Hive. El rendimiento se puede mejorar si se puede reducir la cantidad de datos que deben leerse. De forma predeterminada, las consultas de Hive examinan tablas completas de Hive. Sin embargo, para las consultas que solo necesitan examinar una pequeña cantidad de datos (por ejemplo, consultas con filtrado), esto crea una sobrecarga innecesaria. La creación de particiones de Hive permite a las consultas de Hive tener acceso solo a la cantidad de datos necesaria en las tablas de Hive.
La creación de particiones de Hive se implementa mediante la reorganización de los datos sin procesar en nuevos directorios. Cada partición tiene su propio directorio de archivos. El usuario define la creación de particiones. En el siguiente diagrama se ilustra la creación de particiones de una tabla de Hive por la columna Año. Se crea un nuevo directorio para cada año.
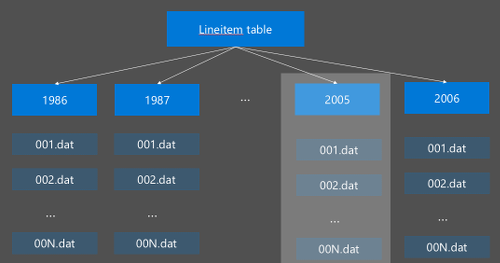
Algunas consideraciones de particiones:
- No cree particiones insuficientes: la creación de particiones en columnas con solo unos pocos valores puede generar pocas particiones. Por ejemplo, la creación de particiones por sexo solo crea dos particiones (hombres y mujeres); por lo que solo se reduce la latencia a un máximo de la mitad.
- No cree particiones en exceso: por el contrario, la creación de una partición en una columna con un valor único (por ejemplo, id. de usuario) da lugar a varias particiones. La creación de particiones en exceso provoca mucho esfuerzo en el nodo de nombre del clúster, ya que tiene que administrar una gran cantidad de directorios.
- Evite el sesgo de datos : elija su clave de creación de particiones con cuidado de manera que todas las particiones tengan el mismo tamaño. Por ejemplo, la creación de particiones en la columna Estado puede sesgar la distribución de datos. Puesto que el estado de California tiene una población treinta veces mayor que Vermont, el tamaño de la partición puede estar sesgado y el rendimiento puede variar significativamente.
Para crear una tabla de particiones, use la cláusula Particionado por :
CREATE TABLE lineitem_part
(L_ORDERKEY INT, L_PARTKEY INT, L_SUPPKEY INT,L_LINENUMBER INT,
L_QUANTITY DOUBLE, L_EXTENDEDPRICE DOUBLE, L_DISCOUNT DOUBLE,
L_TAX DOUBLE, L_RETURNFLAG STRING, L_LINESTATUS STRING,
L_SHIPDATE_PS STRING, L_COMMITDATE STRING, L_RECEIPTDATE STRING,
L_SHIPINSTRUCT STRING, L_SHIPMODE STRING, L_COMMENT STRING)
PARTITIONED BY(L_SHIPDATE STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS TEXTFILE;
Cuando se cree la tabla con particiones, puede crear las particiones estáticas o las particiones dinámicas.
La creación de particiones estáticas significa que ya tendrá datos particionados en los directorios apropiados. Con particiones estáticas, agregue particiones de Hive manualmente según la ubicación del directorio. El siguiente fragmento de código es un ejemplo.
INSERT OVERWRITE TABLE lineitem_part PARTITION (L_SHIPDATE = '5/23/1996 12:00:00 AM') SELECT * FROM lineitem WHERE lineitem.L_SHIPDATE = '5/23/1996 12:00:00 AM' ALTER TABLE lineitem_part ADD PARTITION (L_SHIPDATE = '5/23/1996 12:00:00 AM') LOCATION 'wasb://sampledata@ignitedemo.blob.core.windows.net/partitions/5_23_1996/'La partición dinámica significa que desea que Hive cree particiones automáticamente para usted. Puesto que ya ha creado la tabla de creación particiones a partir de la tabla de almacenamiento provisional, lo único que debe hacer es insertar datos en la tabla con particiones:
SET hive.exec.dynamic.partition = true; SET hive.exec.dynamic.partition.mode = nonstrict; INSERT INTO TABLE lineitem_part PARTITION (L_SHIPDATE) SELECT L_ORDERKEY as L_ORDERKEY, L_PARTKEY as L_PARTKEY, L_SUPPKEY as L_SUPPKEY, L_LINENUMBER as L_LINENUMBER, L_QUANTITY as L_QUANTITY, L_EXTENDEDPRICE as L_EXTENDEDPRICE, L_DISCOUNT as L_DISCOUNT, L_TAX as L_TAX, L_RETURNFLAG as L_RETURNFLAG, L_LINESTATUS as L_LINESTATUS, L_SHIPDATE as L_SHIPDATE_PS, L_COMMITDATE as L_COMMITDATE, L_RECEIPTDATE as L_RECEIPTDATE, L_SHIPINSTRUCT as L_SHIPINSTRUCT, L_SHIPMODE as L_SHIPMODE, L_COMMENT as L_COMMENT, L_SHIPDATE as L_SHIPDATE FROM lineitem;
Para obtener más información, consulte Partitioned Tables (Tablas con particiones).
Usar el formato ORCFile
Hive admite diferentes formatos de archivo. Por ejemplo:
- Texto: el formato de archivo predeterminado y funciona con la mayoría de escenarios.
- Avro: funciona bien en escenarios de interoperabilidad.
- ORC/Parquet: idóneo para el rendimiento.
El formato ORC (Optimized Row Columnar) es una manera muy eficaz de almacenar datos de Hive. En comparación con otros formatos, ORC tiene las siguientes ventajas:
- compatibilidad con tipos complejos, entre los que se incluye DateTime, y tipos complejos y semiestructurados.
- hasta un 70 % de compresión.
- realiza una indexación cada 10 000 filas, lo que permite omitir filas.
- una reducción importante en el tiempo de ejecución.
Para habilitar el formato ORC, debe crear primero una tabla con la cláusula Almacenados como ORC:
CREATE TABLE lineitem_orc_part
(L_ORDERKEY INT, L_PARTKEY INT,L_SUPPKEY INT, L_LINENUMBER INT,
L_QUANTITY DOUBLE, L_EXTENDEDPRICE DOUBLE, L_DISCOUNT DOUBLE,
L_TAX DOUBLE, L_RETURNFLAG STRING, L_LINESTATUS STRING,
L_SHIPDATE_PS STRING, L_COMMITDATE STRING, L_RECEIPTDATE STRING,
L_SHIPINSTRUCT STRING, L_SHIPMODE STRING, L_COMMENT STRING)
PARTITIONED BY(L_SHIPDATE STRING)
STORED AS ORC;
A continuación, inserte datos en la tabla ORC desde la tabla de almacenamiento temporal. Por ejemplo:
INSERT INTO TABLE lineitem_orc
SELECT L_ORDERKEY as L_ORDERKEY,
L_PARTKEY as L_PARTKEY ,
L_SUPPKEY as L_SUPPKEY,
L_LINENUMBER as L_LINENUMBER,
L_QUANTITY as L_QUANTITY,
L_EXTENDEDPRICE as L_EXTENDEDPRICE,
L_DISCOUNT as L_DISCOUNT,
L_TAX as L_TAX,
L_RETURNFLAG as L_RETURNFLAG,
L_LINESTATUS as L_LINESTATUS,
L_SHIPDATE as L_SHIPDATE,
L_COMMITDATE as L_COMMITDATE,
L_RECEIPTDATE as L_RECEIPTDATE,
L_SHIPINSTRUCT as L_SHIPINSTRUCT,
L_SHIPMODE as L_SHIPMODE,
L_COMMENT as L_COMMENT
FROM lineitem;
Puede leer más sobre el formato ORC en el manual del lenguaje Apache Hive.
Vectorización
La vectorización permite a Hive procesar un lote de 1024 filas juntas en lugar de procesar una fila cada vez. Esto significa que las operaciones sencillas se realizan con mayor rapidez porque se necesita ejecutar menos código interno.
Para habilitar la vectorización, anteponga a su consulta de Hive la siguiente configuración:
set hive.vectorized.execution.enabled = true;
Para obtener más información, vea Ejecución de consultas vectorizadas.
Otros métodos de optimización
Hay más métodos de optimización que puede considerar, por ejemplo:
- Creación de depósitos de Hive: una técnica que permite agrupar o segmentar grandes conjuntos de datos para optimizar el rendimiento de las consultas.
- Optimización de combinación: optimización de la planeación de la ejecución de consultas de Hive para mejorar la eficacia de las combinaciones y reducir la necesidad de sugerencias de usuario. Para obtener más información, vea Optimización de combinación.
- Aumento de reductores.
Pasos siguientes
En este artículo, ha aprendido varios métodos comunes de optimización de consultas de Hive. Para más información, vea los siguientes artículos: