Archivado de notas de la versión
Resumen
Azure HDInsight es uno de los servicios más populares entre los clientes de empresa para el análisis de código abierto en Azure. Suscríbase a las notas de la versión de HDInsight para obtener información actualizada sobre HDInsight y todas las versiones de HDInsight.
Para suscribirse, haga clic en el botón "inspeccionar" en el banner y esté atento a las versiones de HDInsight.
Información de la versión
Fecha de publicación: 22 de octubre de 2024
Nota:
Se trata de una versión de revisión y mantenimiento para el proveedor de recursos. Para obtener más información, consulte Proveedor de recursos.
Azure HDInsight publica periódicamente actualizaciones de mantenimiento para ofrecer correcciones de errores, mejoras de rendimiento y revisiones de seguridad, lo que garantiza mantenerse al día con estas actualizaciones garantiza un rendimiento y confiabilidad óptimos.
Esta nota de versión se aplica a
![]() Versión de HDInsight 5.1.
Versión de HDInsight 5.1.
![]() Versión de HDInsight 5.0.
Versión de HDInsight 5.0.
![]() Versión de HDInsight 4.0.
Versión de HDInsight 4.0.
La versión de HDInsight se pondrá a disposición de todas las regiones durante varios días. Esta nota de la versión es aplicable al número de imagen 2409240625. ¿Cómo comprobar el número de imagen?
HDInsight usa prácticas de implementación segura que implican la implementación gradual de regiones. Pueden pasar hasta 10 días hábiles hasta que haya una nueva versión disponible en todas las regiones.
Versiones del SO
- HDInsight 5.1: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 4.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
Nota:
Ubuntu 18.04 es compatible con el mantenimiento extendido de seguridad (ESM) por el equipo Azure Linux para Azure HDInsight de julio de 2023, versiones posteriores.
Para ver versiones específicas de la carga de trabajo, consulte Versiones de componentes de HDInsight 5.x.
Actualizado
Compatibilidad con la autenticación basada en MSI disponible para Azure Blob Storage.
- Azure HDInsight ahora admite la autenticación basada en OAuth para acceder a Azure Blob Storage aprovechando Azure Active Directory (AAD) e identidades administradas (MSI). Con esta mejora, HDInsight usa identidades administradas asignadas por el usuario para acceder a Azure Blob Storage. Para más información, consulte Identidades administradas para los recursos de Azure.
El servicio HDInsight ha realizando la transición para usar equilibradores de carga estándar para todas sus configuraciones de clúster debido al anuncio de desuso del equilibrador de carga básico de Azure.
Nota:
Este cambio está disponible en todas las regiones. Vuelva a crear el clúster para consumir este cambio. Para obtener ayuda, póngase en contacto con el equipo de soporte técnico.
Importante
Cuando utilice su propia red virtual (VNet personalizada) durante la creación del clúster, tenga en cuenta que la creación del clúster no se realizará correctamente una vez que se habilite este cambio. Se recomienda hacer referencia a la guía de migración para volver a crear el clúster. Para obtener ayuda, póngase en contacto con el equipo de soporte técnico.
 Próximamente
Próximamente
Retirada de máquinas virtuales de la serie A Básica y Estándar.
- El 31 de agosto de 2024 retiraremos las máquinas virtuales de las series Basic y Standard A. Antes de esa fecha, deberá migrar las cargas de trabajo a máquinas virtuales de la serie Av2, que proporcionan más memoria por vCPU y almacenamiento más rápido en unidades de estado sólido (SSD).
- Para evitar interrupciones del servicio, migre las cargas de trabajo de las máquinas virtuales de la serie A Básica y Estándar a las máquinas virtuales de la serie Av2 antes del 31 de agosto de 2024.
Notificaciones de retirada para HDInsight 4.0 y HDInsight 5.0.
Si tiene más preguntas, póngase en contacto con el Soporte técnico de Azure.
Puede obtener más información sobre HDInsight en Azure HDInsight: Microsoft Q&A.
Estamos escuchando: Le invitamos a agregar más ideas y otros temas aquí y votarlos: Ideas de HDInsight y seguirnos para obtener más actualizaciones sobre Comunidad de AzureHDInsight.
Nota:
Recomendamos a los clientes que usen las versiones más recientes de imágenes de HDInsight, ya que aportan lo mejor de código abierto actualizaciones, actualizaciones de Azure y correcciones de seguridad. Para obtener más información, consulte Procedimientos recomendados.
Fecha de lanzamiento: 30 de agosto de 2024
Nota:
Se trata de una versión de revisión y mantenimiento para el proveedor de recursos. Para obtener más información, consulte Proveedor de recursos.
Azure HDInsight publica periódicamente actualizaciones de mantenimiento para ofrecer correcciones de errores, mejoras de rendimiento y revisiones de seguridad, lo que garantiza mantenerse al día con estas actualizaciones garantiza un rendimiento y confiabilidad óptimos.
Esta nota de versión se aplica a
![]() Versión de HDInsight 5.1.
Versión de HDInsight 5.1.
![]() Versión de HDInsight 5.0.
Versión de HDInsight 5.0.
![]() Versión de HDInsight 4.0.
Versión de HDInsight 4.0.
La versión de HDInsight se pondrá a disposición de todas las regiones durante varios días. Esta nota de versión es aplicable al número de imagen 2407260448. ¿Cómo comprobar el número de imagen?
HDInsight usa prácticas de implementación segura que implican la implementación gradual de regiones. Pueden pasar hasta 10 días hábiles hasta que haya una nueva versión disponible en todas las regiones.
Versiones del SO
- HDInsight 5.1: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 4.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
Nota:
Ubuntu 18.04 es compatible con el mantenimiento extendido de seguridad (ESM) por el equipo Azure Linux para Azure HDInsight de julio de 2023, versiones posteriores.
Para ver versiones específicas de la carga de trabajo, consulte Versiones de componentes de HDInsight 5.x.
Problema corregido
- Corrección de errores de base de datos predeterminada.
Próximamente
-
Retirada de máquinas virtuales de la serie A Básica y Estándar.
- El 31 de agosto de 2024 retiraremos las máquinas virtuales de las series Basic y Standard A. Antes de esa fecha, deberá migrar las cargas de trabajo a máquinas virtuales de la serie Av2, que proporcionan más memoria por vCPU y almacenamiento más rápido en unidades de estado sólido (SSD).
- Para evitar interrupciones del servicio, migre las cargas de trabajo de las máquinas virtuales de la serie A Básica y Estándar a las máquinas virtuales de la serie Av2 antes del 31 de agosto de 2024.
- Notificaciones de retirada para HDInsight 4.0 y HDInsight 5.0.
Si tiene más preguntas, póngase en contacto con el Soporte técnico de Azure.
Puede obtener más información sobre HDInsight en Azure HDInsight: Microsoft Q&A.
Estamos escuchando: Le invitamos a agregar más ideas y otros temas aquí y votarlos: Ideas de HDInsight y seguirnos para obtener más actualizaciones sobre Comunidad de AzureHDInsight.
Nota:
Recomendamos a los clientes que usen las versiones más recientes de imágenes de HDInsight, ya que aportan lo mejor de código abierto actualizaciones, actualizaciones de Azure y correcciones de seguridad. Para obtener más información, consulte Procedimientos recomendados.
Fecha de lanzamiento: 09 de agosto de 2024
Esta nota de versión se aplica a
![]() Versión de HDInsight 5.1.
Versión de HDInsight 5.1.
![]() Versión de HDInsight 5.0.
Versión de HDInsight 5.0.
![]() Versión de HDInsight 4.0.
Versión de HDInsight 4.0.
La versión de HDInsight se pondrá a disposición de todas las regiones durante varios días. Esta nota de versión es aplicable al número de imagen 2407260448. ¿Cómo comprobar el número de imagen?
HDInsight usa prácticas de implementación segura que implican la implementación gradual de regiones. Pueden pasar hasta 10 días hábiles hasta que haya una nueva versión disponible en todas las regiones.
Versiones del SO
- HDInsight 5.1: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 4.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
Nota:
Ubuntu 18.04 es compatible con el mantenimiento extendido de seguridad (ESM) por el equipo Azure Linux para Azure HDInsight de julio de 2023, versiones posteriores.
Para ver versiones específicas de la carga de trabajo, consulte Versiones de componentes de HDInsight 5.x.
Actualizaciones
Adición del agente de Azure Monitor para Log Analytics en HDInsight
Adición de SystemMSI y DCR automatizado para Log Analytics, dada la desuso de Nueva experiencia de Azure Monitor (versión preliminar).
Nota:
El número de imagen efectivo 2407260448, los clientes que usan el portal para análisis de registros tendrán una experiencia predeterminada de Agente de Azure Monitor. En caso de que desee cambiar a la experiencia de Azure Monitor (versión preliminar), puede anclar los clústeres a imágenes antiguas mediante la creación de una solicitud de soporte técnico.
Fecha de lanzamiento: 05 de julio de 2024
Nota:
Se trata de una versión de revisión y mantenimiento para el proveedor de recursos. Para obtener más información, consulte Proveedor de recursos
Problemas corregidos
Las etiquetas HOBO sobrescriben las etiquetas de usuario.
- Las etiquetas HOBO sobrescriben etiquetas de usuario en subrecursos en la creación de clústeres de HDInsight.
Fecha de lanzamiento: 19 de junio de 2024
Esta nota de versión se aplica a
![]() Versión de HDInsight 5.1.
Versión de HDInsight 5.1.
![]() Versión de HDInsight 5.0.
Versión de HDInsight 5.0.
![]() Versión de HDInsight 4.0.
Versión de HDInsight 4.0.
La versión de HDInsight se pondrá a disposición de todas las regiones durante varios días. Esta nota de versión es aplicable al número de imagen 2406180258. ¿Cómo comprobar el número de imagen?
HDInsight usa prácticas de implementación segura que implican la implementación gradual de regiones. Pueden pasar hasta 10 días hábiles hasta que haya una nueva versión disponible en todas las regiones.
Versiones del SO
- HDInsight 5.1: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 4.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
Nota:
Ubuntu 18.04 es compatible con el mantenimiento extendido de seguridad (ESM) por el equipo Azure Linux para Azure HDInsight de julio de 2023, versiones posteriores.
Para ver versiones específicas de la carga de trabajo, consulte Versiones de componentes de HDInsight 5.x.
Problemas corregidos
Mejoras de seguridad
Mejoras en Log Analytics de HDInsight con compatibilidad con identidad administrada del sistema para el proveedor de recursos de HDInsight.
Adición de una nueva actividad para actualizar la versión del agente de
mdsdpara la imagen anterior (creada antes de 2024).Habilitación de MISE en la puerta de enlace como parte de las mejoras continuas de Migración de MSAL.
Incorpore Spark Thrift Server
Httpheader hiveConfa Jetty HTTP ConnectionFactory.Revierte RANGER-3753 y RANGER-3593.
La implementación
setOwnerUserdada en la versión de Ranger 2.3.0 tiene un problema de regresión crítico cuando Hive lo usa. En Ranger 2.3.0, cuando HiveServer2 intenta evaluar las directivas, Ranger Client intenta obtener el propietario de la tabla de hive llamando a metastore en la función setOwnerUser que básicamente realiza una llamada al almacenamiento para comprobar el acceso a esa tabla. Este problema hace que las consultas se ejecuten lentamente cuando Hive se ejecuta en 2.3.0 Ranger.
Nuevas regiones agregadas
- Norte de Italia
- Centro de Israel
- Centro de España
- Centro de México
- JIO de India central
Agregar a las notas de archivo de junio de 2024
Próximamente
-
Retirada de máquinas virtuales de la serie A Básica y Estándar.
- El 31 de agosto de 2024 retiraremos las máquinas virtuales de las series Basic y Standard A. Antes de esa fecha, deberá migrar las cargas de trabajo a máquinas virtuales de la serie Av2, que proporcionan más memoria por vCPU y almacenamiento más rápido en unidades de estado sólido (SSD).
- Para evitar interrupciones del servicio, migre las cargas de trabajo de las máquinas virtuales de la serie A Básica y Estándar a las máquinas virtuales de la serie Av2 antes del 31 de agosto de 2024.
- Notificaciones de retirada para HDInsight 4.0 y HDInsight 5.0.
Si tiene más preguntas, póngase en contacto con el Soporte técnico de Azure.
Puede obtener más información sobre HDInsight en Azure HDInsight: Microsoft Q&A.
Estamos escuchando: Le invitamos a agregar más ideas y otros temas aquí y votarlos: Ideas de HDInsight y seguirnos para obtener más actualizaciones sobre Comunidad de AzureHDInsight.
Nota:
Recomendamos a los clientes que usen las versiones más recientes de imágenes de HDInsight, ya que aportan lo mejor de código abierto actualizaciones, actualizaciones de Azure y correcciones de seguridad. Para obtener más información, consulte Procedimientos recomendados.
Fecha de publicación: 16 de mayo de 2024
Esta nota de versión se aplica a
![]() Versión de HDInsight 5.0.
Versión de HDInsight 5.0.
![]() Versión de HDInsight 4.0.
Versión de HDInsight 4.0.
La versión de HDInsight se pondrá a disposición de todas las regiones durante varios días. Esta nota de versión es aplicable al número de imagen 2405081840. ¿Cómo comprobar el número de imagen?
HDInsight usa prácticas de implementación segura que implican la implementación gradual de regiones. Pueden pasar hasta 10 días hábiles hasta que haya una nueva versión disponible en todas las regiones.
Versiones del SO
- HDInsight 5.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 4.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
Nota:
Ubuntu 18.04 es compatible con el mantenimiento extendido de seguridad (ESM) por el equipo Azure Linux para Azure HDInsight de julio de 2023, versiones posteriores.
Para ver versiones específicas de la carga de trabajo, consulte Versiones de componentes de HDInsight 5.x.
Problemas corregidos:
- Se ha agregado la API en la puerta de enlace para obtener el token de Keyvault, como parte de la iniciativa SFI.
- En la nueva tabla monitor de registro
HDInsightSparkLogs, para el tipo de registroSparkDriverLog, faltaban algunos de los campos. Por ejemplo,LogLevel & Message. Esta versión agrega los campos que faltan a los esquemas y corrige el formato deSparkDriverLog. - Los registros de Livy no están disponibles en la tabla de supervisión
SparkDriverLogde Log Analytics, lo que se debe a un problema con la ruta de acceso del origen del registro de Livy y el análisis de registros regex en las configuracionesSparkLivyLog. - Cualquier clúster de HDInsight, con ADLS Gen2 como cuenta de almacenamiento principal, puede aprovechar el acceso basado en MSI a cualquiera de los recursos de Azure (por ejemplo, SQL, Keyvaults) que se usa en el código de la aplicación.
Próximamente
-
Retirada de máquinas virtuales de la serie A Básica y Estándar.
- El 31 de agosto de 2024 retiraremos las máquinas virtuales de las series Basic y Standard A. Antes de esa fecha, deberá migrar las cargas de trabajo a máquinas virtuales de la serie Av2, que proporcionan más memoria por vCPU y almacenamiento más rápido en unidades de estado sólido (SSD).
- Para evitar interrupciones del servicio, migre las cargas de trabajo de las máquinas virtuales de la serie A Básica y Estándar a las máquinas virtuales de la serie Av2 antes del 31 de agosto de 2024.
- Notificaciones de retirada para HDInsight 4.0 y HDInsight 5.0.
Si tiene más preguntas, póngase en contacto con el Soporte técnico de Azure.
Puede obtener más información sobre HDInsight en Azure HDInsight: Microsoft Q&A.
Estamos escuchando: Le invitamos a agregar más ideas y otros temas aquí y votarlos: Ideas de HDInsight y seguirnos para obtener más actualizaciones sobre Comunidad de AzureHDInsight.
Nota:
Recomendamos a los clientes que usen las versiones más recientes de imágenes de HDInsight, ya que aportan lo mejor de código abierto actualizaciones, actualizaciones de Azure y correcciones de seguridad. Para obtener más información, consulte Procedimientos recomendados.
Fecha de versión: 15 de abril de 2024
Esta nota de versión se aplica a la ![]() versión de HDInsight 5.1.
versión de HDInsight 5.1.
La versión de HDInsight se pondrá a disposición de todas las regiones durante varios días. Esta nota de versión es aplicable al número de imagen 2403290825. ¿Cómo comprobar el número de imagen?
HDInsight usa prácticas de implementación segura que implican la implementación gradual de regiones. Pueden pasar hasta 10 días hábiles hasta que haya una nueva versión disponible en todas las regiones.
Versiones del SO
- HDInsight 5.1: Ubuntu 18.04.5 LTS Linux Kernel 5.4
Nota:
Ubuntu 18.04 es compatible con el mantenimiento extendido de seguridad (ESM) por el equipo Azure Linux para Azure HDInsight de julio de 2023, versiones posteriores.
Para ver versiones específicas de la carga de trabajo, consulte Versiones de componentes de HDInsight 5.x.
Problemas corregidos:
- Correcciones de errores para Ambari DB, Hive Warehouse Controller (HWC), Spark, HDFS
- Correcciones de errores para el módulo de Log Analytics para HDInsightSparkLogs
- Correcciones de CVE para Proveedor de recursos de HDInsight.
Próximamente
-
Retirada de máquinas virtuales de la serie A Básica y Estándar.
- El 31 de agosto de 2024 retiraremos las máquinas virtuales de las series Basic y Standard A. Antes de esa fecha, deberá migrar las cargas de trabajo a máquinas virtuales de la serie Av2, que proporcionan más memoria por vCPU y almacenamiento más rápido en unidades de estado sólido (SSD).
- Para evitar interrupciones del servicio, migre las cargas de trabajo de las máquinas virtuales de la serie A Básica y Estándar a las máquinas virtuales de la serie Av2 antes del 31 de agosto de 2024.
- Notificaciones de retirada para HDInsight 4.0 y HDInsight 5.0.
Si tiene más preguntas, póngase en contacto con el Soporte técnico de Azure.
Puede obtener más información sobre HDInsight en Azure HDInsight: Microsoft Q&A.
Estamos escuchando: Le invitamos a agregar más ideas y otros temas aquí y votarlos: Ideas de HDInsight y seguirnos para obtener más actualizaciones sobre Comunidad de AzureHDInsight.
Nota:
Recomendamos a los clientes que usen las versiones más recientes de imágenes de HDInsight, ya que aportan lo mejor de código abierto actualizaciones, actualizaciones de Azure y correcciones de seguridad. Para obtener más información, consulte Procedimientos recomendados.
Fecha de lanzamiento: 15 de febrero de 2024
Esta versión se aplica a las versiones de HDInsight 4.x y 5.x. La versión de HDInsight se pondrá a disposición de todas las regiones durante varios días. Esta versión es aplicable al número de imagen 2401250802. ¿Cómo comprobar el número de imagen?
HDInsight usa prácticas de implementación segura que implican la implementación gradual de regiones. Pueden pasar hasta 10 días hábiles hasta que haya una nueva versión disponible en todas las regiones.
Versiones del SO
- HDInsight 4.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.1: Ubuntu 18.04.5 LTS Linux Kernel 5.4
Nota:
Ubuntu 18.04 es compatible con el mantenimiento extendido de seguridad (ESM) por el equipo Azure Linux para Azure HDInsight de julio de 2023, versiones posteriores.
En el caso de las versiones específicas de la carga de trabajo, consulte
Nuevas características
- Compatibilidad de Apache Ranger con Spark SQL en Spark 3.3.0 (HDInsight versión 5.1) con el paquete de seguridad Enterprise. Obtenga más información al respecto aquí.
Problemas corregidos:
- Correcciones de seguridad de los componentes de Ambari y Oozie
Próximamente
- Retirada de máquinas virtuales de la serie A Básica y Estándar.
- El 31 de agosto de 2024 retiraremos las máquinas virtuales de las series Basic y Standard A. Antes de esa fecha, deberá migrar las cargas de trabajo a máquinas virtuales de la serie Av2, que proporcionan más memoria por vCPU y almacenamiento más rápido en unidades de estado sólido (SSD).
- Para evitar interrupciones del servicio, migre las cargas de trabajo de las máquinas virtuales de la serie A Básica y Estándar a las máquinas virtuales de la serie Av2 antes del 31 de agosto de 2024.
Si tiene más preguntas, póngase en contacto con el Soporte técnico de Azure.
Puede obtener más información sobre HDInsight en Azure HDInsight: Microsoft Q&A
Estamos escuchando: Le damos la bienvenida para agregar más ideas y otros temas aquí y votarlos: ideas de HDInsight y seguirnos para obtener más actualizaciones sobre Comunidad de AzureHDInsight
Nota:
Recomendamos a los clientes que usen las versiones más recientes de imágenes de HDInsight, ya que aportan lo mejor de código abierto actualizaciones, actualizaciones de Azure y correcciones de seguridad. Para obtener más información, consulte Procedimientos recomendados.
Pasos siguientes
- Azure HDInsight: Preguntas más frecuentes
- Configuración de la programación de aplicación de revisiones del SO para clústeres de HDInsight basado en Linux
- Notas de la versión anteriores
Azure HDInsight es uno de los servicios más populares entre los clientes de empresa para el análisis de código abierto en Azure. Si quiere suscribirse a las notas de la versión, vea las versiones de este repositorio de GitHub.
Fecha de publicación: 10 de enero de 2024
Esta versión de revisión se aplica a las versiones de HDInsight 4.x y 5.x. La versión de HDInsight se pondrá a disposición de todas las regiones durante varios días. Esta versión es aplicable al número de imagen 2401030422. ¿Cómo comprobar el número de imagen?
HDInsight usa prácticas de implementación segura que implican la implementación gradual de regiones. Pueden pasar hasta 10 días hábiles hasta que haya una nueva versión disponible en todas las regiones.
Versiones del SO
- HDInsight 4.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.1: Ubuntu 18.04.5 LTS Linux Kernel 5.4
Nota:
Ubuntu 18.04 es compatible con el mantenimiento extendido de seguridad (ESM) por el equipo Azure Linux para Azure HDInsight de julio de 2023, versiones posteriores.
En el caso de las versiones específicas de la carga de trabajo, consulte
Problemas corregidos
- Correcciones de seguridad de los componentes de Ambari y Oozie
Próximamente
- Retirada de máquinas virtuales de la serie A Básica y Estándar.
- El 31 de agosto de 2024 retiraremos las máquinas virtuales de las series Basic y Standard A. Antes de esa fecha, deberá migrar las cargas de trabajo a máquinas virtuales de la serie Av2, que proporcionan más memoria por vCPU y almacenamiento más rápido en unidades de estado sólido (SSD).
- Para evitar interrupciones del servicio, migre las cargas de trabajo de las máquinas virtuales de la serie A Básica y Estándar a las máquinas virtuales de la serie Av2 antes del 31 de agosto de 2024.
Si tiene más preguntas, póngase en contacto con el Soporte técnico de Azure.
Puede obtener más información sobre HDInsight en Azure HDInsight: Microsoft Q&A
Estamos escuchando: Le damos la bienvenida para agregar más ideas y otros temas aquí y votarlos: ideas de HDInsight y seguirnos para obtener más actualizaciones sobre Comunidad de AzureHDInsight
Nota:
Recomendamos a los clientes que usen las versiones más recientes de imágenes de HDInsight, ya que aportan lo mejor de código abierto actualizaciones, actualizaciones de Azure y correcciones de seguridad. Para obtener más información, consulte Procedimientos recomendados.
Fecha de publicación: 26 de octubre de 2023
Esta versión se aplica a la versión de HDInsight 4.x y 5.x. HDInsight estará disponible para todas las regiones durante varios días. Esta versión es aplicable al número de imagen 2310140056. ¿Cómo comprobar el número de imagen?
HDInsight usa prácticas de implementación segura que implican la implementación gradual de regiones. Pueden pasar hasta 10 días hábiles hasta que haya una nueva versión disponible en todas las regiones.
Versiones del SO
- HDInsight 4.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.1: Ubuntu 18.04.5 LTS Linux Kernel 5.4
En el caso de las versiones específicas de la carga de trabajo, consulte
Novedades
HDInsight anuncia la disponibilidad general de HDInsight 5.1 a partir del 1 de noviembre de 2023. Esta versión incluye una actualización de pila completa a los componentes de código abierto y las integraciones de Microsoft.
- Últimas versiones de código abierto: HDInsight 5.1 viene con la última versión estable de código abierto disponible. Los clientes pueden beneficiarse de todas las características de código abierto más recientes, mejoras de rendimiento de Microsoft y correcciones de errores.
- Seguro: las últimas versiones incluyen las correcciones de seguridad más recientes, tanto de código abierto como de Microsoft.
- Menor TCO: con mejoras de rendimiento, los clientes pueden reducir el costo operativo, junto con la escalabilidad automática mejorada.
Permisos de clúster para un almacenamiento seguro
- Los clientes pueden especificar (durante la creación del clúster) si se debe usar un canal seguro para los nodos de clúster de HDInsight para conectar la cuenta de almacenamiento.
Creación de clústeres de HDInsight con redes virtuales personalizadas.
- Para mejorar la posición de seguridad general de los clústeres de HDInsight, los clústeres de HDInsight que usan redes virtuales personalizadas deben asegurarse de que el usuario debe tener permiso para
Microsoft Network/virtualNetworks/subnets/join/actionpara realizar operaciones de creación. El cliente podría enfrentar errores de creación si esta comprobación no está habilitada.
- Para mejorar la posición de seguridad general de los clústeres de HDInsight, los clústeres de HDInsight que usan redes virtuales personalizadas deben asegurarse de que el usuario debe tener permiso para
Clústeres ABFS que no son ESP [Permisos de clúster para lectura de Word]
- Los clústeres ABFS que no son de ESP restringen a los usuarios de grupos que no son de Hadoop a ejecutar comandos de Hadoop para las operaciones de almacenamiento. Este cambio mejora la posición de seguridad del clúster.
Actualización de cuota insertada.
- Ahora puede solicitar un aumento de cuota directamente desde la página Mi cuota. Con la llamada a la API directa es mucho más rápido. En caso de que se produzca un error en la llamada API, puede crear una nueva solicitud de soporte técnico para el aumento de la cuota.
Próximamente
La longitud máxima del nombre del clúster se cambiará de 59 a 45 caracteres para mejorar la posición de seguridad de los clústeres. Este cambio se implementará en todas las regiones a partir de la próxima versión.
Retirada de máquinas virtuales de la serie A Básica y Estándar.
- El 31 de agosto de 2024, retiraremos las máquinas virtuales básicas y estándar de la serie A. Antes de esa fecha, deberá migrar las cargas de trabajo a máquinas virtuales de la serie Av2, que proporcionan más memoria por vCPU y almacenamiento más rápido en unidades de estado sólido (SSD).
- Para evitar interrupciones del servicio, migre las cargas de trabajo de las máquinas virtuales de la serie A Básica y Estándar a las máquinas virtuales de la serie Av2 antes del 31 de agosto de 2024.
Si tiene más preguntas, póngase en contacto con el Soporte técnico de Azure.
Puede obtener más información sobre HDInsight en Azure HDInsight: Microsoft Q&A
Estamos escuchando: Le damos la bienvenida para agregar más ideas y otros temas aquí y votarlos: ideas de HDInsight y seguirnos para obtener más actualizaciones sobre Comunidad de AzureHDInsight
Nota:
Esta versión aborda los siguientes CVE publicados por MSRC el 12 de septiembre de 2023. La acción es actualizar a la imagen más reciente 2308221128 o 2310140056. Se recomienda a los clientes planear en consecuencia.
| CVE | severity | Título de CVE | Comentario |
|---|---|---|---|
| CVE-2023-38156 | Importante | Vulnerabilidad de elevación de privilegios de Apache Ambari de Azure HDInsight | Se incluye en 2308221128 de imagen o 2310140056 |
| CVE-2023-36419 | Importante | Vulnerabilidad de elevación de privilegios de Apache Oozie Workflow Scheduler de Azure HDInsight | Aplicar acción Script en los clústeres o actualizar a la imagen 2310140056 |
Nota:
Recomendamos a los clientes que usen las versiones más recientes de imágenes de HDInsight, ya que aportan lo mejor de código abierto actualizaciones, actualizaciones de Azure y correcciones de seguridad. Para obtener más información, consulte Procedimientos recomendados.
Fecha de publicación: 7 de septiembre de 2023
Esta versión se aplica a la versión de HDInsight 4.x y 5.x. HDInsight estará disponible para todas las regiones durante varios días. Esta versión es aplicable al número de imagen 2308221128. ¿Cómo comprobar el número de imagen?
HDInsight usa prácticas de implementación segura que implican la implementación gradual de regiones. Pueden pasar hasta 10 días hábiles hasta que haya una nueva versión disponible en todas las regiones.
Versiones del SO
- HDInsight 4.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.1: Ubuntu 18.04.5 LTS Linux Kernel 5.4
En el caso de las versiones específicas de la carga de trabajo, consulte
Importante
Esta versión aborda los siguientes CVE publicados por MSRC el 12 de septiembre de 2023. La acción es actualizar a la imagen más reciente 2308221128. Se recomienda a los clientes planear en consecuencia.
| CVE | severity | Título de CVE | Comentario |
|---|---|---|---|
| CVE-2023-38156 | Importante | Vulnerabilidad de elevación de privilegios de Apache Ambari de Azure HDInsight | Incluida en la imagen de 2308221128 |
| CVE-2023-36419 | Importante | Vulnerabilidad de elevación de privilegios de Apache Oozie Workflow Scheduler de Azure HDInsight | Aplicación de la acción Script en los clústeres |
Próximamente
- La longitud máxima del nombre del clúster se cambiará de 59 a 45 caracteres para mejorar la posición de seguridad de los clústeres. Este cambio se implementará el 30 de septiembre de 2023.
- Permisos de clúster para un almacenamiento seguro
- Los clientes pueden especificar (durante la creación del clúster) si se debe usar un canal seguro para que los nodos de clúster de HDInsight se comuniquen con la cuenta de almacenamiento.
- Actualización de cuota insertada.
- Las cuotas de solicitud aumentan directamente desde la página Mi cuota, que será una llamada API directa, que es más rápida. Si se produce un error en la llamada API, los clientes deben crear una nueva solicitud de soporte técnico para aumentar la cuota.
- Creación de clústeres de HDInsight con redes virtuales personalizadas.
- Para mejorar la posición de seguridad general de los clústeres de HDInsight, los clústeres de HDInsight que usan redes virtuales personalizadas deben asegurarse de que el usuario debe tener permiso para
Microsoft Network/virtualNetworks/subnets/join/actionpara realizar operaciones de creación. Los clientes deberán planificar en consecuencia, ya que este cambio será una comprobación obligatoria para evitar errores en la creación de clústeres antes del 30 de septiembre de 2023.
- Para mejorar la posición de seguridad general de los clústeres de HDInsight, los clústeres de HDInsight que usan redes virtuales personalizadas deben asegurarse de que el usuario debe tener permiso para
- Retirada de máquinas virtuales de la serie A Básica y Estándar.
- El 31 de agosto de 2024 retiraremos las máquinas virtuales de las series Basic y Standard A. Antes de esa fecha, deberá migrar las cargas de trabajo a máquinas virtuales de la serie Av2, que proporcionan más memoria por vCPU y almacenamiento más rápido en unidades de estado sólido (SSD). Para evitar interrupciones del servicio, migre las cargas de trabajo de las máquinas virtuales de la serie A Básica y Estándar a las máquinas virtuales de la serie Av2 antes del 31 de agosto de 2024.
- Clústeres ABFS que no son ESP [Permisos de clúster para lectura de Word]
- Planee introducir un cambio en los clústeres de ABFS que no son de ESP, lo que impide que los usuarios que no son de Hadoop ejecuten comandos de Hadoop para las operaciones de almacenamiento. Este cambio para mejorar la posición de seguridad del clúster. Los clientes deben planear las actualizaciones antes del 30 de septiembre de 2023.
Si tiene más preguntas, póngase en contacto con el Soporte técnico de Azure.
Puede obtener más información sobre HDInsight en Azure HDInsight: Microsoft Q&A
Le invitamos a agregar más propuestas e ideas y otros temas aquí y votar por ello: HDInsight Community (azure.com).
Nota:
Recomendamos a los clientes que usen las versiones más recientes de imágenes de HDInsight, ya que aportan lo mejor de código abierto actualizaciones, actualizaciones de Azure y correcciones de seguridad. Para obtener más información, consulte Procedimientos recomendados.
Fecha de publicación: 25 de julio de 2023
Esta versión se aplica a la versión de HDInsight 4.x y 5.x. HDInsight estará disponible para todas las regiones durante varios días. Esta versión es aplicable al número de imagen 2307201242. ¿Cómo comprobar el número de imagen?
HDInsight usa prácticas de implementación segura que implican la implementación gradual de regiones. Pueden pasar hasta 10 días hábiles hasta que haya una nueva versión disponible en todas las regiones.
Versiones del SO
- HDInsight 4.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.1: Ubuntu 18.04.5 LTS Linux Kernel 5.4
En el caso de las versiones específicas de la carga de trabajo, consulte
 Novedades
Novedades
- HDInsight 5.1 ahora es compatible con el clúster de ESP.
- La versión actualizada de Ranger 2.3.0 y Oozie 5.2.1 ahora forman parte de HDInsight 5.1
- El clúster de Spark 3.3.1 (HDInsight 5.1) viene con Hive Warehouse Connector (HWC) 2.1, que funciona junto con el clúster de Interactive Query (HDInsight 5.1).
- Ubuntu 18.04 es compatible con ESM (mantenimiento extendido de seguridad) por el equipo Azure Linux para Azure HDInsight de julio de 2023, versiones posteriores.
Importante
Esta versión aborda los siguientes CVE publicados por MSRC el 8 de agosto de 2023. La acción es actualizar a la imagen más reciente 2307201242. Se recomienda a los clientes planear en consecuencia.
| CVE | severity | Título de CVE |
|---|---|---|
| CVE-2023-35393 | Importante | Vulnerabilidad de suplantación de identidad de Apache Hive |
| CVE-2023-35394 | Importante | Vulnerabilidad de suplantación de identidad de Azure HDInsight Jupyter Notebook |
| CVE-2023-36877 | Importante | Vulnerabilidad de suplantación de identidad de Azure Apache Oozie |
| CVE-2023-36881 | Importante | Vulnerabilidad de suplantación de identidad de Azure Apache Ambari |
| CVE-2023-38188 | Importante | Vulnerabilidad de suplantación de identidad de Azure Apache Hadoop |
Próximamente
- La longitud máxima del nombre del clúster se cambiará de 59 a 45 caracteres para mejorar la posición de seguridad de los clústeres. Los clientes deben planear las actualizaciones antes del 30 de septiembre de 2023.
- Permisos de clúster para un almacenamiento seguro
- Los clientes pueden especificar (durante la creación del clúster) si se debe usar un canal seguro para que los nodos de clúster de HDInsight se comuniquen con la cuenta de almacenamiento.
- Actualización de cuota insertada.
- Las cuotas de solicitud aumentan directamente desde la página Mi cuota, que será una llamada API directa, que es más rápida. Si se produce un error en la llamada API, los clientes deben crear una nueva solicitud de soporte técnico para aumentar la cuota.
- Creación de clústeres de HDInsight con redes virtuales personalizadas.
- Para mejorar la posición de seguridad general de los clústeres de HDInsight, los clústeres de HDInsight que usan redes virtuales personalizadas deben asegurarse de que el usuario debe tener permiso para
Microsoft Network/virtualNetworks/subnets/join/actionpara realizar operaciones de creación. Los clientes deberán planificar en consecuencia, ya que este cambio será una comprobación obligatoria para evitar fallas en la creación de clústeres antes del 30 de septiembre de 2023.
- Para mejorar la posición de seguridad general de los clústeres de HDInsight, los clústeres de HDInsight que usan redes virtuales personalizadas deben asegurarse de que el usuario debe tener permiso para
- Retirada de máquinas virtuales de la serie A Básica y Estándar.
- El 31 de agosto de 2024, retiraremos las máquinas virtuales de las series Basic y Standard A. Antes de esa fecha, deberá migrar las cargas de trabajo a máquinas virtuales de la serie Av2, que proporcionan más memoria por vCPU y almacenamiento más rápido en unidades de estado sólido (SSD). Para evitar interrupciones del servicio, migre las cargas de trabajo de las máquinas virtuales de la serie A Básica y Estándar a las máquinas virtuales de la serie Av2 antes del 31 de agosto de 2024.
- Clústeres ABFS que no son ESP [Permisos de clúster para lectura de Word]
- Planee introducir un cambio en los clústeres de ABFS que no son de ESP, lo que impide que los usuarios que no son de Hadoop ejecuten comandos de Hadoop para las operaciones de almacenamiento. Este cambio para mejorar la posición de seguridad del clúster. Los clientes deben planear las actualizaciones antes del 30 de septiembre de 2023.
Si tiene más preguntas, póngase en contacto con el Soporte técnico de Azure.
Puede obtener más información sobre HDInsight en Azure HDInsight: Microsoft Q&A
Le damos la bienvenida para agregar más propuestas e ideas y otros temas aquí y votar por ellos: HDInsight Community (azure.com) y seguirnos para obtener más actualizaciones sobre X
Nota:
Recomendamos a los clientes que usen las versiones más recientes de imágenes de HDInsight, ya que aportan lo mejor de código abierto actualizaciones, actualizaciones de Azure y correcciones de seguridad. Para obtener más información, consulte Procedimientos recomendados.
Fecha de publicación: 8 de mayo de 2023
Esta versión se aplica a la versión de HDInsight 4.x y 5.x. HDInsight está disponible para todas las regiones durante varios días. Esta versión es aplicable al número de imagen 2304280205. ¿Cómo comprobar el número de imagen?
HDInsight usa prácticas de implementación segura que implican la implementación gradual de regiones. Pueden pasar hasta 10 días hábiles hasta que haya una nueva versión disponible en todas las regiones.
Versiones del SO
- HDInsight 4.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
En el caso de las versiones específicas de la carga de trabajo, consulte
![]()
Azure HDInsight 5.1 actualizado con
- Apache HBase 2.4.11
- Apache Phoenix 5.1.2
- Apache Hive 3.1.2
- Apache Spark 3.3.1
- Apache Tez 0.9.1
- Apache Zeppelin 0.10.1
- Apache Livy 0.5
- Apache Kafka 3.2.0
Nota:
- Todos los componentes están integrados con Hadoop 3.3.4 y ZK 3.6.3
- Todos los componentes actualizados anteriores ahora están disponibles en clústeres que no son ESP para la versión preliminar pública.
![]()
Escalabilidad automática mejorada para HDInsight
Azure HDInsight ha realizado importantes mejoras de estabilidad y latencia en la escalabilidad automática, Entre los cambios esenciales se encuentran la mejora del bucle de comentarios para las decisiones de escalado, una mejora significativa de la latencia del escalado y la compatibilidad con la retirada de los nodos retirados, Más información sobre las mejoras, cómo configurar y migrar el clúster a la escalabilidad automática mejorada. La funcionalidad de escalabilidad automática mejorada está disponible a partir del 17 de mayo de 2023 en todas las regiones admitidas.
Azure HDInsight ESP para Apache Kafka 2.4.1 ahora está disponible con carácter general.
Azure HDInsight ESP para Apache Kafka 2.4.1 se encuentra en versión preliminar pública desde abril de 2022. Después de mejoras importantes en las correcciones y la estabilidad de CVE, Azure HDInsight ESP Kafka 2.4.1 ahora está disponible con carácter general y está listo para cargas de trabajo de producción. Obtenga más información sobre la configuración y la migración.
Administración de cuotas para HDInsight
HDInsight asigna actualmente la cuota a las suscripciones de cliente en un nivel regional. Los núcleos asignados a los clientes son genéricos y no se clasifican en un nivel de familia de máquinas virtuales (por ejemplo,
Dv2,Ev3,Eav4, etc.).HDInsight introdujo una vista mejorada, que proporciona un detalle y una clasificación de cuotas para máquinas virtuales de nivel familiar. Esta característica permite a los clientes ver las cuotas actuales y restantes de una región en el nivel de familia de máquinas virtuales. Con la vista mejorada, los clientes tienen una visibilidad más completa para planear cuotas y una mejor experiencia de usuario. Esta característica está disponible actualmente en HDInsight 4.x y 5.x para la región Este de EE. UU. EUAP. Más adelante estará disponible en más regiones.
Para más información, consulte Planeamiento de la capacidad del clúster en Azure HDInsight | Microsoft Learn.
![]()
- Centro de Polonia
- La longitud máxima del nombre del clúster se cambia de 59 a 45 caracteres para mejorar la posición de seguridad de los clústeres.
- Permisos de clúster para un almacenamiento seguro
- Los clientes pueden especificar (durante la creación del clúster) si se debe usar un canal seguro para que los nodos de clúster de HDInsight se comuniquen con la cuenta de almacenamiento.
- Actualización de cuota insertada.
- Las cuotas de solicitud aumentan directamente desde la página Mi cuota, que es una llamada API directa, que es más rápida. Si se produce un error en la llamada API, los clientes deben crear una nueva solicitud de soporte técnico para aumentar la cuota.
- Creación de clústeres de HDInsight con redes virtuales personalizadas.
- Para mejorar la posición de seguridad general de los clústeres de HDInsight, los clústeres de HDInsight que usan redes virtuales personalizadas deben asegurarse de que el usuario debe tener permiso para
Microsoft Network/virtualNetworks/subnets/join/actionpara realizar operaciones de creación. Los clientes tendrían que planear en consecuencia, ya que sería una comprobación obligatoria para evitar errores de creación de clústeres.
- Para mejorar la posición de seguridad general de los clústeres de HDInsight, los clústeres de HDInsight que usan redes virtuales personalizadas deben asegurarse de que el usuario debe tener permiso para
- Retirada de máquinas virtuales de la serie A Básica y Estándar.
- El 31 de agosto de 2024, retiraremos las máquinas virtuales de las series Basic y Standard A. Antes de esa fecha, deberá migrar las cargas de trabajo a máquinas virtuales de la serie Av2, que proporcionan más memoria por vCPU y almacenamiento más rápido en unidades de estado sólido (SSD). Para evitar interrupciones del servicio, migre las cargas de trabajo de las máquinas virtuales de la serie A Básica y Estándar a las máquinas virtuales de la serie Av2 antes del 31 de agosto de 2024.
- Clústeres de ABFS que no son ESP [permisos de clúster para lectura mundial]
- Planee introducir un cambio en los clústeres de ABFS que no son de ESP, lo que impide que los usuarios que no son de Hadoop ejecuten comandos de Hadoop para las operaciones de almacenamiento. Este cambio para mejorar la posición de seguridad del clúster. Los clientes deben planear las actualizaciones.
Fecha de publicación: 28 de febrero de 2023
Esta versión se aplica a HDInsight 4.0. y 5.0, 5.1. La versión de HDInsight está disponible en todas las regiones durante varios días. Esta versión es aplicable al número de imagen 2302250400. ¿Cómo comprobar el número de imagen?
HDInsight usa prácticas de implementación segura que implican la implementación gradual de regiones. Pueden pasar hasta 10 días hábiles hasta que haya una nueva versión disponible en todas las regiones.
Versiones del SO
- HDInsight 4.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
En el caso de las versiones específicas de la carga de trabajo, consulte
Importante
Microsoft ha emitido CVE-2023-23408, que se corrige en la versión actual y se recomienda a los clientes actualizar sus clústeres a la imagen más reciente.
![]()
HDInsight 5.1
Hemos empezado a implementar una nueva versión de HDInsight 5.1. Todas las nuevas versiones de código abierto se agregan como versiones incrementales en HDInsight 5.1.
Para más información, vea la sección Versión de HDInsight 5.1.0.
![]()
Actualización de Kafka 3.2.0 (versión preliminar)
- Kafka 3.2.0 incluye varias características y mejoras importantes.
- Se ha actualizado Zookeeper a la versión 3.6.3
- Compatibilidad con Kafka Streams
- Garantías de entrega más sólidas para el productor de Kafka habilitado de forma predeterminada.
-
log4j1.x se reemplaza conreload4j. - Envíe una sugerencia al líder de la partición para recuperarla.
-
JoinGroupRequestyLeaveGroupRequesttienen una razón adjunta. - Se han agregado métricas8 de recuento de agente.
- Mejoras en el reflejo de
Maker2.
Actualización de HBase 2.4.11 (versión preliminar)
- Esta versión tiene nuevas características, como la adición de nuevos tipos de mecanismos de almacenamiento en caché para la caché de bloques, la capacidad de modificar
hbase:meta tabley ver la tablahbase:metadesde la interfaz de usuario web de HBase.
Actualización de Phoenix 5.1.2 (versión preliminar)
- Se ha actualizado la versión de Phoenix a la versión 5.1.2 en esta versión. Esta actualización incluye Phoenix Query Server. El servidor proxy de Phoenix Query Server está formado por el controlador JDBC de Phoenix estándar y proporciona un protocolo de conexión compatible con versiones anteriores para invocar ese controlador JDBC.
CV de Ambari
- Se han corregido varios CV de Ambari.
Nota:
ESP no es compatible con Kafka y HBase en esta versión.
![]()
Pasos siguientes
- Escalado automático
- Escalabilidad automática con una latencia mejorada y varias mejoras
- Limitación del cambio de nombre del clúster
- La longitud máxima del nombre del clúster se cambia de 59 a 45 en Public, Azure China y Azure Government.
- Permisos de clúster para un almacenamiento seguro
- Los clientes pueden especificar (durante la creación del clúster) si se debe usar un canal seguro para que los nodos de clúster de HDInsight se comuniquen con la cuenta de almacenamiento.
- Clústeres de ABFS que no son ESP [permisos de clúster para lectura mundial]
- Planee introducir un cambio en los clústeres de ABFS que no son de ESP, lo que impide que los usuarios que no son de Hadoop ejecuten comandos de Hadoop para las operaciones de almacenamiento. Este cambio para mejorar la posición de seguridad del clúster. Los clientes deben planear las actualizaciones.
- Actualizaciones de código abierto
- Apache Spark 3.3.0 y Hadoop 3.3.4 están en desarrollo en HDInsight 5.1 e incluyen varias características nuevas, rendimiento y otras mejoras importantes.
Nota
Recomendamos a los clientes que usen las versiones más recientes de imágenes de HDInsight, ya que aportan lo mejor de código abierto actualizaciones, actualizaciones de Azure y correcciones de seguridad. Para obtener más información, consulte Procedimientos recomendados.
Fecha de publicación: 12 de diciembre de 2022
Esta versión se aplica a HDInsight 4.0. y la versión 5.0 de HDInsight se pone a disposición de todas las regiones durante varios días.
HDInsight usa prácticas de implementación segura que implican la implementación gradual de regiones. Pueden pasar hasta 10 días hábiles hasta que haya una nueva versión disponible en todas las regiones.
Versiones del SO
- HDInsight 4.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
![]()
- Log Analytics: los clientes pueden habilitar la supervisión clásica para obtener la versión 14.19 de OMS más reciente. Para quitar versiones anteriores, deshabilite y habilite la supervisión clásica.
- Cierre de sesión automático de la interfaz de usuario de Ambari debido a la inactividad. Para más información, consulte aquí.
- Spark: en esta versión se incluye una versión nueva y optimizada de Spark 3.1.3. Hemos probado Apache Spark 3.1.2 (versión anterior) y Apache Spark 3.1.3 (versión actual) mediante el banco de pruebas TPC-DS. La prueba se realizó mediante la SKU E8 V3, para Apache Spark en una carga de trabajo de 1 TB. Apache Spark 3.1.3 (versión actual) superó el rendimiento de Apache Spark 3.1.2 (versión anterior) en más del 40 % en tiempo de ejecución total de consultas para las consultas TPC-DS con las mismas especificaciones de hardware. El equipo de Microsoft Spark agregó optimizaciones disponibles en Azure Synapse con Azure HDInsight. Para más información, consulte Aceleración de las cargas de trabajo de datos con actualizaciones de rendimiento a Apache Spark 3.1.2 en Azure Synapse
![]()
- Centro de Catar
- Norte de Alemania
![]()
HDInsight se ha alejado de Azul Zulu Java JDK 8 a
Adoptium Temurin JDK 8, que admite entornos de ejecución certificados por TCK de alta calidad y tecnología asociada para su uso en todo el ecosistema de Java.HDInsight se ha migrado a
reload4j. Los cambios delog4json aplicables a- Apache Hadoop
- Apache Zookeeper
- Apache Oozie
- Apache Ranger
- Apache Sqoop
- Apache Pig
- Apache Ambari
- Apache Kafka
- Spark de Apache
- Apache Zeppelin
- Apache Livy
- Apache Rubix
- Apache Hive
- Apache Tez
- HBase Apache
- OMI
- Apache Pheonix
![]()
HDInsight implementa TLS1.2 de ahora en adelante y las versiones anteriores se actualizan en la plataforma. Si ejecuta cualquier aplicación sobre HDInsight y usa TLS 1.0 y 1.1, actualice a TLS 1.2 para evitar cualquier interrupción en los servicios.
Para obtener más información, consulte Habilitación de la seguridad de la capa de transporte (TLS).
![]()
Fin de la compatibilidad con clústeres de Azure HDInsight en Ubuntu 16.04 LTS desde el 30 de noviembre de 2022. HDInsight ha comenzado a publicar imágenes de clúster con Ubuntu 18.04 desde el 27 de junio de 2021. Se recomienda a nuestros clientes que ejecutan clústeres con Ubuntu 16.04 recompilar sus clústeres con las imágenes de HDInsight más recientes antes del 30 de noviembre de 2022.
Para obtener más información sobre cómo comprobar la versión de Ubuntu del clúster, consulte aquí.
Ejecute el comando "lsb_release -a" en el terminal.
Si el valor de la propiedad "Description" en la salida es "Ubuntu 16.04 LTS", esta actualización se aplica al clúster.
![]()
- Compatibilidad con una selección de Availability Zones para clústeres de Kafka y HBase (acceso de escritura).
Correcciones de errores de código abierto
Correcciones de errores de Hive
| Correcciones de errores | JIRA de Apache |
|---|---|
| HIVE-26127 | Error INSERT OVERWRITE: archivo no encontrado |
| HIVE-24957 | Resultados incorrectos cuando la subconsulta tiene COALESCE en el predicado de correlación |
| HIVE-24999 | HiveSubQueryRemoveRule genera un plan no válido para la subconsulta IN con varias correlaciones. |
| HIVE-24322 | Si hay inserción directa, el id. de intento debe comprobarse al leer los errores del manifiesto |
| HIVE-23363 | Actualización de la dependencia DataNucleus a la versión 5.2 |
| HIVE-26412 | Creación de una interfaz para capturar ranuras disponibles y agregar el valor predeterminado |
| HIVE-26173 | Actualización de derbi a 10.14.2.0 |
| HIVE-25920 | Subir Xerce2 a 2.12.2. |
| HIVE-26300 | Actualización de la versión de enlace de datos de Jackson a la versión 2.12.6.1+ para evitar CVE-2020-36518 |
Fecha de lanzamiento: 10/08/2022
Esta versión se aplica a HDInsight 4.0. La versión de HDInsight se pone a disposición de todas las regiones durante varios días.
HDInsight usa prácticas de implementación segura que implican la implementación gradual de regiones. Pueden pasar hasta 10 días hábiles hasta que haya una nueva versión disponible en todas las regiones.
![]()
Nueva característica
1. Conexión de discos externos en clústeres de Hadoop/Spark de HDI
El clúster de HDInsight incluye espacio en disco predefinido basado en SKU. Este espacio puede no ser suficiente en escenarios de trabajo grandes.
Esta nueva característica permite agregar más discos en el clúster, que se usa como directorio local del administrador de nodos. Agregue el número de discos a los nodos de trabajo durante la creación del clúster de HIVE y Spark, mientras que los discos seleccionados forman parte de los directorios locales del administrador de nodos.
Nota
Los discos agregados solo están configurados para los directorios locales del administrador de nodos.
Para más información, consulte aquí.
2. Análisis de registro selectivo
El análisis de registro selectivo ahora está disponible en todas las regiones para la versión preliminar pública. Puede conectar el clúster a un área de trabajo de Log Analytics. Una vez habilitado, puede ver los registros y las métricas, como registros de seguridad de HDInsight, Yarn Resource Manager, métricas del sistema, etc. Puede supervisar las cargas de trabajo y ver cómo afectan a la estabilidad del clúster. El registro selectivo permite habilitar o deshabilitar todas las tablas o habilitar tablas selectivas en el área de trabajo de Log Analytics. Puede ajustar el tipo de origen de cada tabla, ya que en la nueva versión de la supervisión de Geneva una tabla tiene varios orígenes.
- El sistema de supervisión de Geneva utiliza mdsd (demonio MDS), que es un agente de supervisión fluido para recopilar registros mediante una capa de registro unificada.
- El registro selectivo usa la acción de script para deshabilitar o habilitar tablas y sus tipos de registro. Puesto que no abre ningún puerto nuevo ni cambia ninguna configuración de seguridad existente, no hay cambios de seguridad.
- La acción de script se ejecuta en paralelo en todos los nodos especificados y cambia los archivos de configuración para deshabilitar o habilitar tablas y sus tipos de registro.
Para más información, consulte aquí.
![]()
Fijo
Análisis de registros de actividad de Azure AD con registros de Azure Monitor
Log Analytics integrado con Azure HDInsight que ejecuta OMS versión 13 requiere una actualización a la versión 14 de OMS para aplicar las actualizaciones de seguridad más recientes. Los clientes que usan la versión anterior del clúster con la versión 13 de OMS deben instalar la versión 14 de OMS para cumplir los requisitos de seguridad. (Cómo comprobar la versión e instalar la 14)
Cómo comprobar su versión actual de OMS
- Inicie sesión en el clúster con SSH.
- Ejecute el siguiente comando en el cliente de SSH.
sudo /opt/omi/bin/ominiserver/ --version

Cómo actualizar su versión de OMS de 13 a 14.
- Inicie sesión en el Portal de Azure
- En el grupo de recursos, seleccione el recurso de clúster de HDInsight.
- Seleccione Acciones de script
- En el panel Enviar acción de script, elija Tipo de script como personalizado.
- Pegue el siguiente vínculo en el cuadro de URL del script de Bash: https://hdiconfigactions.blob.core.windows.net/log-analytics-patch/OMSUPGRADE14.1/omsagent-vulnerability-fix-1.14.12-0.sh
- Seleccione Tipos de nodo.
- Seleccione Crear
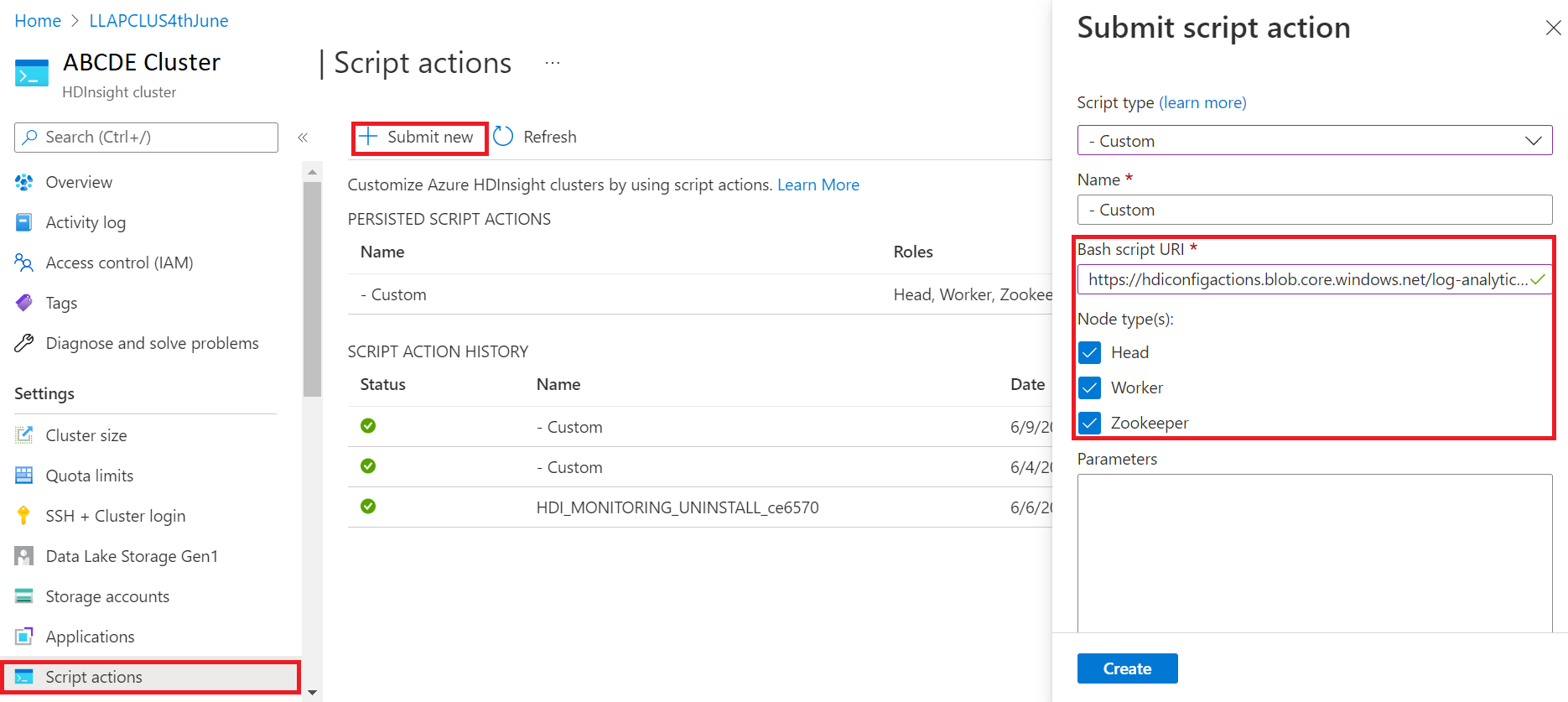
Compruebe la correcta instalación del parche mediante los pasos siguientes:
Inicie sesión en el clúster con SSH.
Ejecute el siguiente comando en el cliente de SSH.
sudo /opt/omi/bin/ominiserver/ --version
Otras correcciones de errores.
- La CLI del registro de Yarn no puede recuperar los registros si hay algún
TFiledañado o vacío. - Se ha resuelto un error de detalles de la entidad de servicio no válida al obtener el token de OAuth de Azure Active Directory.
- Se ha mejorado la confiabilidad de la creación de clústeres cuando se configuran más de 100 nodos trabajados.
Correcciones de errores de código abierto
Corrección de errores de TEZ
| Correcciones de errores | JIRA de Apache |
|---|---|
| Error de compilación de Tez: no se encontró FileSaver.js | TEZ-4411 |
Excepción de FS incorrecta cuando el almacenamiento y el scratchdir están en FS diferentes |
TEZ-4406 |
| TezUtils.createConfFromByteString en la configuración de más de 32 MB produce una excepción com.google.protobuf.CodedInputStream | TEZ-4142 |
| TezUtils::createByteStringFromConf debe usar snappy en lugar de DeflaterOutputStream | TEZ-4113 |
| Actualización de la dependencia protobuf a 3.x | TEZ-4363 |
Correcciones de errores de Hive
| Correcciones de errores | JIRA de Apache |
|---|---|
| Optimizaciones de rendimiento en la generación dividida ORC | HIVE-21457 |
| Evita leer la tabla como ACID cuando el nombre de la tabla comience por "delta", pero la tabla no es transaccional y se usa la estrategia de división de BI | HIVE-22582 |
| Elimina una llamada de FS#exists de AcidUtils#getLogicalLength | HIVE-23533 |
| Vectorización de OrcAcidRowBatchReader.computeOffset y optimización de cubos | HIVE-17917 |
Problemas conocidos
HDInsight es compatible con Apache HIVE 3.1.2. Debido a un error en esta versión, la versión de Hive se muestra como 3.1.0 en interfaces de Hive. Sin embargo, no hay ningún impacto en la funcionalidad.
Fecha de lanzamiento: 10/08/2022
Esta versión se aplica a HDInsight 4.0. La versión de HDInsight se pone a disposición de todas las regiones durante varios días.
HDInsight usa prácticas de implementación segura que implican la implementación gradual de regiones. Pueden pasar hasta 10 días hábiles hasta que haya una nueva versión disponible en todas las regiones.
![]()
Nueva característica
1. Conexión de discos externos en clústeres de Hadoop/Spark de HDI
El clúster de HDInsight incluye espacio en disco predefinido basado en SKU. Este espacio puede no ser suficiente en escenarios de trabajo grandes.
Esta nueva característica permite agregar más discos en el clúster, que se usarán como directorio local del administrador de nodos. Agregue el número de discos a los nodos de trabajo durante la creación del clúster de HIVE y Spark, mientras que los discos seleccionados forman parte de los directorios locales del administrador de nodos.
Nota
Los discos agregados solo están configurados para los directorios locales del administrador de nodos.
Para más información, consulte aquí.
2. Análisis de registro selectivo
El análisis de registro selectivo ahora está disponible en todas las regiones para la versión preliminar pública. Puede conectar el clúster a un área de trabajo de Log Analytics. Una vez habilitado, puede ver los registros y las métricas, como registros de seguridad de HDInsight, Yarn Resource Manager, métricas del sistema, etc. Puede supervisar las cargas de trabajo y ver cómo afectan a la estabilidad del clúster. El registro selectivo permite habilitar o deshabilitar todas las tablas o habilitar tablas selectivas en el área de trabajo de Log Analytics. Puede ajustar el tipo de origen de cada tabla, ya que en la nueva versión de la supervisión de Geneva una tabla tiene varios orígenes.
- El sistema de supervisión de Geneva utiliza mdsd (demonio MDS), que es un agente de supervisión fluido para recopilar registros mediante una capa de registro unificada.
- El registro selectivo usa la acción de script para deshabilitar o habilitar tablas y sus tipos de registro. Puesto que no abre ningún puerto nuevo ni cambia ninguna configuración de seguridad existente, no hay cambios de seguridad.
- La acción de script se ejecuta en paralelo en todos los nodos especificados y cambia los archivos de configuración para deshabilitar o habilitar tablas y sus tipos de registro.
Para más información, consulte aquí.
![]()
Fijo
Análisis de registros de actividad de Azure AD con registros de Azure Monitor
Log Analytics integrado con Azure HDInsight que ejecuta OMS versión 13 requiere una actualización a la versión 14 de OMS para aplicar las actualizaciones de seguridad más recientes. Los clientes que usan la versión anterior del clúster con la versión 13 de OMS deben instalar la versión 14 de OMS para cumplir los requisitos de seguridad. (Cómo comprobar la versión e instalar la 14)
Cómo comprobar su versión actual de OMS
- Inicie sesión en el clúster con SSH.
- Ejecute el siguiente comando en el cliente de SSH.
sudo /opt/omi/bin/ominiserver/ --version
Cómo actualizar su versión de OMS de 13 a 14.
- Inicie sesión en el Portal de Azure
- En el grupo de recursos, seleccione el recurso de clúster de HDInsight.
- Seleccione Acciones de script
- En el panel Enviar acción de script, elija Tipo de script como personalizado.
- Pegue el siguiente vínculo en el cuadro de URL del script de Bash: https://hdiconfigactions.blob.core.windows.net/log-analytics-patch/OMSUPGRADE14.1/omsagent-vulnerability-fix-1.14.12-0.sh
- Seleccione Tipos de nodo.
- Seleccione Crear
Compruebe la correcta instalación del parche mediante los pasos siguientes:
Inicie sesión en el clúster con SSH.
Ejecute el siguiente comando en el cliente de SSH.
sudo /opt/omi/bin/ominiserver/ --version
Otras correcciones de errores.
- La CLI del registro de Yarn no puede recuperar los registros si hay algún
TFiledañado o vacío. - Se ha resuelto un error de detalles de la entidad de servicio no válida al obtener el token de OAuth de Azure Active Directory.
- Se ha mejorado la confiabilidad de la creación de clústeres cuando se configuran más de 100 nodos trabajados.
Correcciones de errores de código abierto
Corrección de errores de TEZ
| Correcciones de errores | JIRA de Apache |
|---|---|
| Error de compilación de Tez: no se encontró FileSaver.js | TEZ-4411 |
Excepción de FS incorrecta cuando el almacenamiento y el scratchdir están en FS diferentes |
TEZ-4406 |
| TezUtils.createConfFromByteString en la configuración de más de 32 MB produce una excepción com.google.protobuf.CodedInputStream | TEZ-4142 |
| TezUtils::createByteStringFromConf debe usar snappy en lugar de DeflaterOutputStream | TEZ-4113 |
| Actualización de la dependencia protobuf a 3.x | TEZ-4363 |
Correcciones de errores de Hive
| Correcciones de errores | JIRA de Apache |
|---|---|
| Optimizaciones de rendimiento en la generación dividida ORC | HIVE-21457 |
| Evita leer la tabla como ACID cuando el nombre de la tabla comience por "delta", pero la tabla no es transaccional y se usa la estrategia de división de BI | HIVE-22582 |
| Elimina una llamada de FS#exists de AcidUtils#getLogicalLength | HIVE-23533 |
| Vectorización de OrcAcidRowBatchReader.computeOffset y optimización de cubos | HIVE-17917 |
Problemas conocidos
HDInsight es compatible con Apache HIVE 3.1.2. Debido a un error en esta versión, la versión de Hive se muestra como 3.1.0 en interfaces de Hive. Sin embargo, no hay ningún impacto en la funcionalidad.
Fecha de lanzamiento: 03/06/2022
Esta versión se aplica a HDInsight 4.0. La versión de HDInsight se pone a disposición de todas las regiones durante varios días. Esta fecha de lanzamiento indica la fecha de lanzamiento de la primera región. Si no ve los cambios siguientes, espere unos días a que la versión se active en su región.
Cambios destacados
El conector de Hive Warehouse (HWC) en Spark v3.1.2
El conector de Hive Warehouse (HWC) le permite aprovechar las ventajas de las características exclusivas de Hive y Spark para crear aplicaciones eficaces de macrodatos. HWC solo se admite actualmente para Spark v2.4. Esta característica agrega valor empresarial al permitir transacciones ACID en tablas de Hive mediante Spark. Esta característica es útil para los clientes que usan Hive y Spark en su patrimonio de datos. Para obtener más información, consulte Apache Spark y Hive - Hive Warehouse Connector - Azure HDInsight | Microsoft Docs
Ambari
- Cambios en la mejora del escalado y el aprovisionamiento
- HDI Hive ahora es compatible con la versión 3.1.2 del OSS
La versión de HDI Hive 3.1 se ha actualizado a OSS Hive 3.1.2. Esta versión tiene todas las correcciones y características disponibles en la versión de Hive 3.1.2. en código abierto.
Nota
Spark
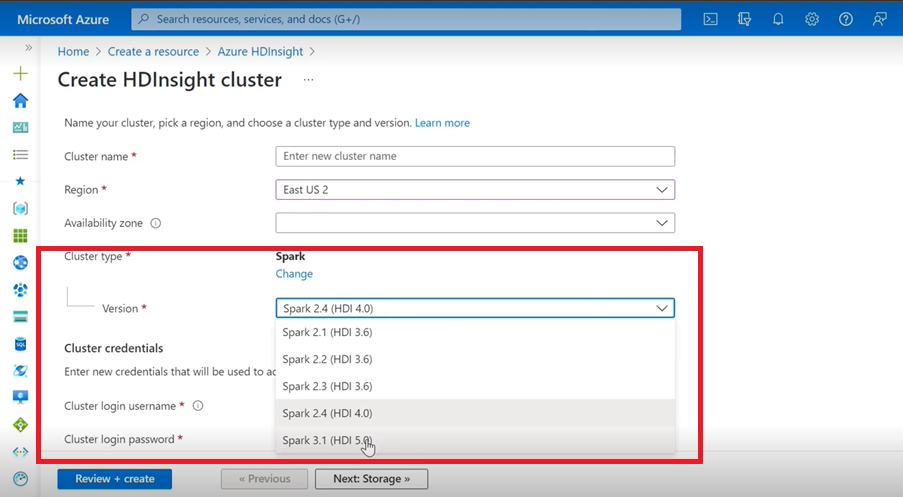
- Si usa la interfaz de usuario de Azure para crear un clúster de Spark para HDInsight, verá en la lista desplegable otra versión de Spark 3.1. (HDI 5.0) junto con las versiones anteriores. Esta versión es una versión con el nombre de Spark 3.1. (HDI 4.0). Es solo un cambio de nivel de interfaz de usuario, que no afecta en nada a los usuarios existentes o a los usuarios que ya usan la plantilla de ARM.
Nota
Interactive Query
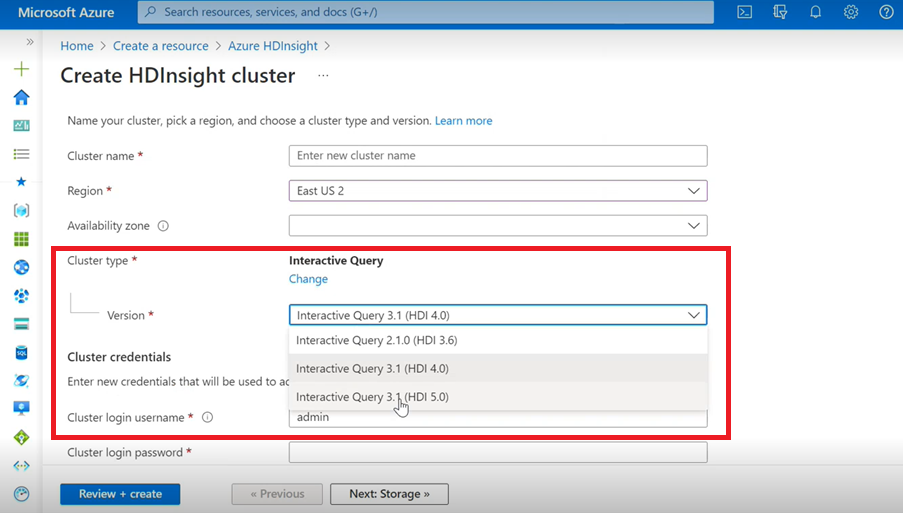
- Si va a crear un clúster de Interactive Query, verá en la lista desplegable otra versión como Interactive Query 3.1 (HDI 5.0).
- Si va a usar la versión de Spark 3.1 junto con Hive que requiere compatibilidad con ACID, debe seleccionar esta versión, Interactive Query 3.1 (HDI 5.0).
Corrección de errores de TEZ
| Correcciones de errores | JIRA de Apache |
|---|---|
| TezUtils.createConfFromByteString en la configuración de más de 32 MB produce una excepción com.google.protobuf.CodedInputStream | TEZ-4142 |
| TezUtils createByteStringFromConf debe usar snappy en lugar de DeflaterOutputStream | TEZ-4113 |
Correcciones de errores de HBase
| Correcciones de errores | JIRA de Apache |
|---|---|
TableSnapshotInputFormat debe usar ReadType.STREAM para examinar HFiles |
HBASE-26273 |
| Agregar opción para deshabilitar scanMetrics en TableSnapshotInputFormat | HBASE-26330 |
| Corrección para ArrayIndexOutOfBoundsException cuando se ejecuta el equilibrador | HBASE-22739 |
Correcciones de errores de Hive
| Correcciones de errores | JIRA de Apache |
|---|---|
| Excepción de puntero nulo al insertar datos con la cláusula «distribute by» con la optimización de ordenación dynpart | HIVE-18284 |
| Se produce un error en el comando MSCK REPAIR con filtrado de particiones mientras se quitan particiones | HIVE-23851 |
| Se ha iniciado una excepción incorrecta si capacidad<=0 | HIVE-25446 |
| Compatibilidad con la carga en paralelo para HastTables: interfaces | HIVE-25583 |
| Incluir MultiDelimitSerDe en HiveServer2 de forma predeterminada | HIVE-20619 |
| Quitar las clases glassfish.jersey y mssql-jdbc de jdbc-standalone jar | HIVE-22134 |
| Excepción de puntero nulo al ejecutar la compactación en una tabla MM. | HIVE-21280 |
Se produce un error en la consulta de gran volumen de Hive a través de knox cuando se produce un error de escritura de canalización rota |
HIVE-22231 |
| Agregar la capacidad de usuario para establecer el usuario de enlace | HIVE-21009 |
| Implementar UDF para interpretar la fecha y la marca de tiempo mediante su representación interna y el calendario híbrido Gregoriano-Juliano | HIVE-22241 |
| Opción Beeline para mostrar o no mostrar el informe de ejecución | HIVE-22204 |
| Tez: SplitGenerator intenta buscar archivos de plan, que no existen para Tez | HIVE-22169 |
Quitar registro costoso de la caché hotpath de LLAP |
HIVE-22168 |
| UDF: FunctionRegistry se sincroniza en la clase org.apache.hadoop.hive.ql.udf.UDFType | HIVE-22161 |
| Impedir la creación del appender de enrutamiento de consultas si la propiedad está establecida en FALSE | HIVE-22115 |
| Eliminar la sincronización entre consultas para partition-eval | HIVE-22106 |
| Omitir la configuración del directorio temporal de Hive durante la planeación | HIVE-21182 |
| Omitir la creación de directorios temporales para Tez si RPC está activado | HIVE-21171 |
Cambiar los UDF de Hive para usar el motor regex Re2J |
HIVE-19661 |
| Las tablas en clúster migradas mediante bucketing_version 1 en Hive 3 usan bucketing_version 2 para las inserciones | HIVE-22429 |
| Creación de depósitos: la versión 1 de la creación de depósitos está realizando particiones de datos de manera incorrecta | HIVE-21167 |
| Agregar el encabezado de licencia de ASF al archivo recién agregado | HIVE-22498 |
| Mejoras de la herramienta de esquema para admitir mergeCatalog | HIVE-22498 |
| Hive con TEZ UNION ALL y UDTF da como resultado la pérdida de datos | HIVE-21915 |
| Dividir archivos de texto incluso si existe encabezado o pie de página | HIVE-21924 |
| MultiDelimitSerDe devuelve resultados incorrectos en la última columna cuando el archivo cargado tiene más columnas de las que están presentes en el esquema de tabla | HIVE-22360 |
| Cliente externo de LLAP: es necesario reducir la superficie de LlapBaseInputFormat#getSplits() | HIVE-22221 |
| El nombre de columna con palabra clave reservada no ha escapado al reescribir la consulta que incluye la combinación con la tabla que tiene la columna de máscara (Zoltan Matyus a través de Zoltan Haindrich) | HIVE-22208 |
Impedir el apagado de LLAP en la excepción RuntimeException relacionada con AMReporter |
HIVE-22113 |
| El controlador de servicio de estado de LLAP puede quedarse bloqueado con un Id. de aplicación de Yarn incorrecto | HIVE-21866 |
| OperationManager.queryIdOperation no limpia correctamente varios queryIds | HIVE-22275 |
| Reducir un administrador de nodos bloquea el reinicio del servicio LLAP | HIVE-22219 |
| StackOverflowError cuando se quitan muchas particiones | HIVE-15956 |
| Error en la comprobación de acceso cuando se quita un directorio temporal | HIVE-22273 |
| Corrección de los resultados incorrectos y de la excepción ArrayOutOfBound en combinaciones externas izquierdas de mapa con condiciones de límite específicas | HIVE-22120 |
| Eliminación de la etiqueta de administración de distribución de pom.xml | HIVE-19667 |
| El tiempo de análisis puede ser alto si hay subconsultas profundamente anidadas | HIVE-21980 |
Para ALTER TABLE t SET TBLPROPERTIES ('EXTERNAL'='TRUE'); los cambios de atributo de TBL_TYPE no se reflejan para texto sin mayúsculas |
HIVE-20057 |
JDBC: HiveConnection sombrea las interfaces log4j |
HIVE-18874 |
Actualización de las direcciones URL del repositorio en poms: versión 3.1 de la rama |
HIVE-21786 |
Pruebas de DBInstall interrumpidas en master y branch-3.1 |
HIVE-21758 |
| Cargar datos en una tabla en depósitos está ignorando las especificaciones de particiones y carga los datos en la partición predeterminada | HIVE-21564 |
| Las consultas con la condición de combinación de tener marca de tiempo o marca de tiempo con zona horaria local literal inician la excepción SemanticException | HIVE-21613 |
| Analizar estadísticas de proceso cuando la columna no elimina el directorio de almacenamiento provisional en HDFS | HIVE-21342 |
| Cambio incompatible en el cálculo del depósito de Hive | HIVE-21376 |
| Proporcionar un autorizador de reserva cuando no haya ningún otro autorizador en uso | HIVE-20420 |
| Algunas invocaciones alterPartitions inician 'NumberFormatException: null' | HIVE-18767 |
| HiveServer2: en algunos casos, el asunto autenticado previamente para el transporte http no se conserva durante toda la duración de la comunicación http | HIVE-20555 |
Fecha de lanzamiento: 10/03/2022
Esta versión se aplica a HDInsight 4.0. La versión de HDInsight se pone a disposición de todas las regiones durante varios días. Esta fecha de lanzamiento indica la fecha de lanzamiento de la primera región. Si no ve los cambios siguientes, espere unos días a que la versión se active en su región.
Las versiones del sistema operativo de esta versión son:
- HDInsight 4.0: Ubuntu 18.04.5
Spark 3.1 ya está disponible con carácter general
Spark 3.1 ahora está disponible con carácter general en la versión HDInsight 4.0. Esta versión incluye:
- Ejecución de consultas adaptables
- Conversión de la unión mediante combinación de ordenación en combinación hash de difusión
- Optimizador de Catalyst para Spark
- Recorte dinámico de particiones
- Los clientes podrán crear nuevos clústeres de Spark 3.1 y no clústeres de Spark 3.0 (versión preliminar).
Para obtener más información, consulte Apache Spark 3.1 ya está disponible con carácter general en HDInsight en Microsoft Tech Community.
Para obtener una lista completa de las mejoras, consulte las Notas de la versión de Apache Spark 3.1.
Para obtener más información sobre migración, consulte la guía de migración.
Kafka 2.4 ya está disponible con carácter general
Kafka 2.4.1 ya está disponible con carácter general. Para obtener más información, consulte las Notas de la versión de Kafka 2.4.1. Otras características incluyen la disponibilidad de MirrorMaker 2, nueva métrica y categoría de la partición del tema AtMinIsr, mejora en el tiempo de actividad del agente por carga lenta de mmap a petición de los archivos de índice, más métricas de consumidor para observar el comportamiento del sondeo de usuarios.
El tipo de datos Map en HWC ahora se admite en HDInsight 4.0
Esta versión incluye compatibilidad con tipos de datos Map para HWC 1.0 (Spark 2.4) a través de la aplicación spark-shell y todos los demás clientes de Spark compatibles con HWC. Las siguientes mejoras se incluyen como cualquier otro tipo de datos:
Un usuario puede:
- Crear una tabla de Hive con cualquier columna que contenga el tipo de datos Map, insertar datos en ella y leer los resultados de ella.
- Crear un dataframe de Apache Spark con el tipo Map y realizar lecturas y escrituras por lotes o secuencias.
Nuevas regiones
HDInsight ha ampliado su presencia geográfica a dos nuevas regiones: Este de China 3 y Norte de China 3.
Cambios de portabilidad con versiones anteriores de OSS
La portabilidad con versiones anteriores de OSS que se incluye en Hive, incluido HWC 1.0 (Spark 2.4), que admite el tipo de datos Map.
Estas son las instancias de JIRA de Apache de esta versión portadas a una versión anterior de OSS:
| Característica afectada | JIRA de Apache |
|---|---|
| Las consultas SQL directas de metastore con IN/(NOT IN) deben dividirse en función de los parámetros máximos permitidos por SQL DB. | HIVE-25659 |
Actualizar log4j 2.16.0 a 2.17.0 |
HIVE-25825 |
Actualizar versión de Flatbuffer |
HIVE-22827 |
| Compatibilidad con el tipo de datos Map de forma nativa en formato Arrow | HIVE-25553 |
| Cliente externo de LLAP: controla los valores anidados cuando la estructura primaria es NULL | HIVE-25243 |
| Actualización de la versión de Arrow a 0.11.0 | HIVE-23987 |
Avisos sobre elementos en desuso
Azure Virtual Machine Scale Sets en HDInsight
HDInsight ya no usará Azure Virtual Machine Scale Sets para aprovisionar los clústeres, no se espera ningún cambio importante. Los clústeres de HDInsight existentes en conjuntos de escalado de máquinas virtuales no se ven afectados, ya que los clústeres nuevos de las imágenes más recientes ya no usarán Virtual Machine Scale Sets.
El escalado de cargas de trabajo de Azure HDInsight HBase ahora solo se admitirán mediante el escalado manual
A partir del 1 de marzo de 2022, HDInsight solo admitirá el escalado manual para HBase, los clústeres en ejecución no se verán afectados. Los nuevos clústeres de HBase no podrán habilitar el escalado automático basado en programación. Para obtener más información sobre cómo escalar manualmente un clúster de HBase, consulte nuestra documentación sobre Escalado manual de clústeres de Azure HDInsight.
Fecha de lanzamiento: 27/12/2021
Esta versión se aplica a HDInsight 4.0. La versión de HDInsight se pone a disposición de todas las regiones durante varios días. Esta fecha de lanzamiento indica la fecha de lanzamiento de la primera región. Si no ve los cambios siguientes, espere unos días a que la versión se active en su región.
Las versiones del sistema operativo de esta versión son:
- HDInsight 4.0: Ubuntu 18.04.5 LTS
La imagen de HDInsight 4.0 se ha actualizado para mitigar la vulnerabilidad de Log4j, como se describe en la Respuesta de Microsoft a CVE-2021-44228 Apache Log4j 2.
Nota:
- Los clústeres de HDI 4.0 creados después del 27 de diciembre de 2021 a las 00:00 UTC se crean con una versión actualizada de la imagen que mitiga las vulnerabilidades de
log4j. Por tanto, los clientes no necesitan aplicar revisiones ni reiniciar estos clústeres. - En el caso de los clústeres de HDInsight 4.0 creados entre el 16 de diciembre de 2021 a las 01:15 UTC y el 27 de diciembre del mismo año a las 00:00 UTC, en HDInsight 3.6 o en suscripciones ancladas después del 16 de diciembre de 2021, la revisión se aplica automáticamente en la hora siguiente a la creación del clúster; sin embargo, posteriormente los clientes deben reiniciar sus nodos para que se termine de aplicar la revisión (excepto en el caso de los nodos de administración de Kafka, que se reinician automáticamente).
Fecha de lanzamiento: 27/07/2021
Esta versión se aplica a HDInsight 3.6 y HDInsight 4.0. La versión de HDInsight se pone a disposición de todas las regiones durante varios días. Esta fecha de lanzamiento indica la fecha de lanzamiento de la primera región. Si no ve los cambios siguientes, espere unos días a que la versión se active en su región.
Las versiones del sistema operativo de esta versión son:
- HDInsight 3.6: Ubuntu 16.04.7 LTS
- HDInsight 4.0: Ubuntu 18.04.5 LTS
Nuevas características
La compatibilidad de Azure HDInsight con la conectividad pública restringida está disponible con carácter general el 15 de octubre de 2021
Azure HDInsight ahora admite conectividad pública restringida en todas las regiones. A continuación, se muestran algunos de los aspectos más destacados de esta funcionalidad:
- Posibilidad de revertir la comunicación entre el proveedor de recursos y el clúster de forma que sea de salida desde el clúster al proveedor de recursos
- Posibilidad de traer sus propios recursos habilitados para Private Link (por ejemplo, almacenamiento, SQL, almacén de claves) para que el clúster de HDInsight solo acceda a los recursos a través de la red privada.
- No se aprovisionan recursos en ninguna dirección IP pública
Con esta nueva funcionalidad, también puede omitir las reglas de etiquetas de servicio del grupo de seguridad de red (NSG) de entrada para las direcciones IP de administración de HDInsight. Más información sobre cómo restringir la conectividad pública
La compatibilidad de Azure HDInsight con Azure Private Link está disponible con carácter general el 15 de octubre de 2021
Ahora puede usar puntos de conexión privados para conectarse a los clústeres de HDInsight a través de un vínculo privado. El vínculo privado se puede usar en escenarios entre redes virtuales en los que el emparejamiento de redes virtuales no está disponible o habilitado.
Azure Private Link le permite acceder a los servicios PaaS de Azure (por ejemplo, Azure Storage y SQL Database) y a los servicios hospedados en Azure que son propiedad de los clientes, o a los servicios de asociados, a través de un punto de conexión privado de la red virtual.
El tráfico entre la red virtual y el servicio viaja por la red troncal de Microsoft. Ya no es necesario exponer el servicio a la red pública de Internet.
Más información en Habilitación de Private Link.
Nueva experiencia de integración de Azure Monitor (versión preliminar)
La nueva experiencia de integración de Azure Monitor estará disponible en versión preliminar en Este de EE. UU. y Oeste de Europa con esta versión. Obtenga más información sobre la nueva experiencia de Azure Monitor aquí.
Desuso
La versión de HDInsight 3.6 quedará en desuso a partir del 1 de octubre de 2022.
Cambios de comportamiento
HDInsight Interactive Query solo admite el escalado automático basado en programación
A medida que los escenarios de los clientes se vuelven más maduros y diversos, vamos identificando algunas limitaciones con la escala automática basada en la carga de Interactive Query (LLAP). Estas limitaciones se deben a la naturaleza de la dinámica de las consultas de LLAP, problemas de precisión en la predicción de carga futura y problemas en la redistribución de tareas del programador LLAP. Debido a estas limitaciones, es posible que los usuarios vean que sus consultas se ejecutan más lentamente en clústeres LLAP cuando el escalado automático está habilitado. El impacto en el rendimiento puede superar las ventajas relativas al costo de la escalabilidad automática.
A partir de julio de 2021, la carga de trabajo de Interactive Query en HDInsight solo admite la escalabilidad automática basada en programación. Ya no puede habilitar el escalado automático basado en la carga en clústeres Interactive Query nuevos. Los clústeres en ejecución existentes pueden seguir ejecutándose con las limitaciones conocidas descritas anteriormente.
Microsoft recomienda pasar a un escalado automático basado en programación para LLAP. Puede analizar el patrón de uso actual del clúster a través del panel de Grafana Hive. Para más información, consulte Escalado automático de clústeres de Azure HDInsight.
Próximos cambios
En las próximas versiones, se realizan los siguientes cambios.
Se quitará el componente LLAP integrado en el clúster ESP Spark
El clúster HDInsight 4.0 ESP Spark tiene componentes LLAP integrados que se ejecutan en ambos nodos principales. Los componentes de LLAP del clúster ESP Spark se agregaron originalmente para HDInsight 3.6 ESP Spark, pero no tiene ningún caso de usuario real para HDInsight 4.0 ESP Spark. En la próxima versión programada en septiembre de 2021, HDInsight quitará el componente LLAP integrado del clúster HDInsight 4.0 ESP Spark. Este cambio le ayuda a descargar la carga de trabajo del nodo principal y a evitar confusiones entre los tipos de clúster ESP Spark y ESP Interactive Hive.
Nueva región
- Oeste de EE. UU. 3
- Oeste de la India
Jio - Centro de Australia
Cambio de versión de componentes
La siguiente versión de componente ha cambiado con esta versión:
- Versión de ORC de 1.5.1 a 1.5.9
En este documento puede encontrar las versiones actuales de los componentes para HDInsight 4.0 y HDInsight 3.6.
Instancias de JIRA portadas a una versión anterior
Estas son las instancias de Apache JIRA de esta versión portadas a una versión anterior:
| Característica afectada | JIRA de Apache |
|---|---|
| Fecha / marca de tiempo | HIVE-25104 |
| HIVE-24074 | |
| HIVE-22840 | |
| HIVE-22589 | |
| HIVE-22405 | |
| HIVE-21729 | |
| HIVE-21291 | |
| HIVE-21290 | |
| UDF | HIVE-25268 |
| HIVE-25093 | |
| HIVE-22099 | |
| HIVE-24113 | |
| HIVE-22170 | |
| HIVE-22331 | |
| ORC | HIVE-21991 |
| HIVE-21815 | |
| HIVE-21862 | |
| Esquema de tabla | HIVE-20437 |
| HIVE-22941 | |
| HIVE-21784 | |
| HIVE-21714 | |
| HIVE-18702 | |
| HIVE-21799 | |
| HIVE-21296 | |
| Administración de cargas de trabajo | HIVE-24201 |
| Compactación | HIVE-24882 |
| HIVE-23058 | |
| HIVE-23046 | |
| Vista materializada | HIVE-22566 |
Corrección de precios para Virtual Machines HDInsight Dv2
El 25 de abril de 2021 se corrigió un error de precios para la serie de máquinas virtuales Dv2 en HDInsight. El error de precios produjo un cargo reducido en las facturas de algunos clientes antes del 25 de abril y, con la corrección, los precios ahora coinciden con lo que se había anunciado en la página de precios y la calculadora de precios de HDInsight. El error de precios afectaba a los clientes de las siguientes regiones que usaban máquinas virtuales Dv2:
- Centro de Canadá
- Este de Canadá
- Este de Asia
- Norte de Sudáfrica
- Sudeste de Asia
- Centro de Emiratos Árabes Unidos
A partir del 25 de abril de 2021, figurará en su cuenta la cantidad corregida de máquinas virtuales Dv2. Las notificaciones de los clientes se enviaron a los propietarios de la suscripción antes del cambio. Puede usar la calculadora de precios, la página de precios de HDInsight o la hoja de creación de un clúster de HDInsight de Azure Portal para ver los costos corregidos de las máquinas virtuales Dv2 en su región.
No es necesaria ninguna otra acción por su parte. La corrección de precios solo se aplicará para el uso a partir del 25 de abril de 2021 en las regiones especificadas, y no a ningún uso anterior a esta fecha. Para asegurarse de que tiene la solución más eficaz y rentable, se recomienda revisar los precios, VCPU y RAM de los clústeres Dv2 y comparar las especificaciones de Dv2 con las máquinas virtuales Ev3 para ver si la solución se beneficiaría del uso de una de las series de máquinas virtuales más recientes.
Fecha de lanzamiento: 02/06/2021
Esta versión se aplica a HDInsight 3.6 y HDInsight 4.0. La versión de HDInsight se pone a disposición de todas las regiones durante varios días. Esta fecha de lanzamiento indica la fecha de lanzamiento de la primera región. Si no ve los cambios siguientes, espere unos días a que la versión se active en su región.
Las versiones del sistema operativo de esta versión son:
- HDInsight 3.6: Ubuntu 16.04.7 LTS
- HDInsight 4.0: Ubuntu 18.04.5 LTS
Nuevas características
Actualización de la versión del sistema operativo
Como se comenta en el ciclo de versiones de Ubuntu, el kernel de Ubuntu 16.04 alcanza el final del ciclo de vida (EOL) en abril de 2021. Hemos empezado a implementar la nueva imagen de clúster de HDInsight 4.0 que se ejecuta en Ubuntu 18.04 en esta versión. Los clústeres de HDInsight 4.0 recién creados se ejecutan en Ubuntu 18.04 de forma predeterminada una vez que esté disponible. Los clústeres existentes en Ubuntu 16.04 se ejecutan tal y como están con soporte técnico completo.
HDInsight 3.6 seguirá funcionando en Ubuntu 16.04. Cambiará a soporte técnico Basic (desde el soporte técnico Standard) a partir del 1 de julio de 2021. Para más información sobre las fechas y las opciones de soporte técnico, consulte las versiones de Azure HDInsight. Ubuntu 18.04 no será compatible con HDInsight 3.6. Si quiere usar Ubuntu 18.04, tendrá que migrar los clústeres a HDInsight 4.0.
Tiene que quitar y volver a crear los clústeres si quiere mover los clústeres existentes de HDInsight 4.0 a Ubuntu 18.04. Planee crear o volver a crear los clústeres una vez sea compatible con Ubuntu 18.04.
Después de crear el nuevo clúster, puede conectarse mediante SSH al clúster y ejecutar sudo lsb_release -a para comprobar que se ejecuta en Ubuntu 18.04. Se recomienda probar primero las aplicaciones en las suscripciones de prueba antes de pasar a producción.
Optimizaciones de escalado en clústeres de escritura acelerada de HBase
HDInsight ha realizado algunas mejoras y optimizaciones en el escalado de clústeres habilitados para escritura acelerada de HBase. Obtenga más información sobre la escritura acelerada de HBase.
Desuso
No hay desuso en esta versión.
Cambios de comportamiento
Deshabilitación del tamaño de máquina virtual Standard_A5 como nodo principal para HDInsight 4.0
El nodo principal del clúster de HDInsight es responsable de inicializar y administrar el clúster. El tamaño Standard_A5 de máquina virtual tiene problemas de confiabilidad como nodo principal para HDInsight 4.0. A partir de esta versión, los clientes no podrán crear nuevos clústeres con el tamaño Standard_A5 de máquina virtual como nodo principal. Puede usar otras máquinas virtuales de 2 núcleos, como E2_v3 o E2s_v3. Los clústeres existentes se ejecutarán tal cual. Se recomienda encarecidamente una máquina virtual de 4 núcleos como mínimo para que el nodo principal garantice la alta disponibilidad y confiabilidad de los clústeres de HDInsight de producción.
El recurso de la interfaz de red no es visible para clústeres que se ejecutan en conjuntos de escalado de máquinas virtuales de Azure.
HDInsight se está migrando gradualmente a conjuntos de escalado de máquinas virtuales de Azure. Los clientes ya no pueden ver las interfaces de red de las máquinas virtuales de los clústeres que usan conjuntos de escalado de máquinas virtuales de Azure.
Próximos cambios
En las próximas versiones, se realizarán los siguientes cambios.
HDInsight Interactive Query solo admite el escalado automático basado en programación
A medida que los escenarios de los clientes se vuelven más maduros y diversos, vamos identificando algunas limitaciones con la escala automática basada en la carga de Interactive Query (LLAP). Estas limitaciones se deben a la naturaleza de la dinámica de las consultas de LLAP, problemas de precisión en la predicción de carga futura y problemas en la redistribución de tareas del programador LLAP. Debido a estas limitaciones, es posible que los usuarios vean que sus consultas se ejecutan más lentamente en clústeres LLAP cuando el escalado automático está habilitado. El impacto en el rendimiento puede superar las ventajas relativas al costo de la escalabilidad automática.
A partir de julio de 2021, la carga de trabajo de Interactive Query en HDInsight solo admite la escalabilidad automática basada en programación. Ya no puede habilitar el escalado automático en clústeres Interactive Query nuevos. Los clústeres en ejecución existentes pueden seguir ejecutándose con las limitaciones conocidas descritas anteriormente.
Microsoft recomienda pasar a un escalado automático basado en programación para LLAP. Puede analizar el patrón de uso actual del clúster a través del panel de Grafana Hive. Para más información, consulte Escalado automático de clústeres de Azure HDInsight.
La nomenclatura del host de máquina virtual se cambiará el 1 de julio de 2021.
Ahora HDInsight usa máquinas virtuales de Azure para aprovisionar el clúster. El servicio se migra gradualmente a conjuntos de escalado de máquinas virtuales de Azure. Esta migración cambiará el formato de nombre de FQDN del nombre de host del clúster y no se garantiza que los números del nombre de host estén ordenados secuencialmente. Si desea obtener los nombres de FQDN de cada nodo, consulte Buscar los nombres de host de los nodos de clúster.
Traslado a conjuntos de escalado de máquinas virtuales
Ahora HDInsight usa máquinas virtuales de Azure para aprovisionar el clúster. El servicio se migra gradualmente a conjuntos de escalado de máquinas virtuales de Azure. Todo el proceso puede tardar unos meses. Después de migrar las regiones y las suscripciones, los clústeres de HDInsight recién creados se ejecutarán en conjuntos de escalado de máquinas virtuales sin acciones del cliente. No se espera ningún cambio importante.
Fecha de lanzamiento: 24/03/2021
Nuevas características
Versión preliminar de Spark 3.0
HDInsight agregó compatibilidad con Spark 3.0.0 a HDInsight 4.0 como una característica en vista previa.
Versión preliminar de Kafka 2.4
HDInsight agregó compatibilidad con Kafka 2.4.1 a HDInsight 4.0 como una característica en vista previa.
Compatibilidad con la serie Eav4
HDInsight ha agregado compatibilidad con la serie Eav4 en esta versión.
Movimiento a conjuntos de escalado de máquinas virtuales
Ahora HDInsight usa máquinas virtuales de Azure para aprovisionar el clúster. El servicio se migra gradualmente a conjuntos de escalado de máquinas virtuales de Azure. Todo el proceso puede tardar unos meses. Después de migrar las regiones y las suscripciones, los clústeres de HDInsight recién creados se ejecutarán en conjuntos de escalado de máquinas virtuales sin acciones del cliente. No se espera ningún cambio importante.
Desuso
No hay desuso en esta versión.
Cambios de comportamiento
La versión predeterminada del clúster cambiará a la 4.0
La versión predeterminada del clúster de HDInsight cambiará de la 3.6 a la 4.0. Para más información sobre las versiones disponibles, consulte este artículo. Más información sobre las novedades de HDInsight 4.0.
Los tamaños de máquina virtual del clúster predeterminado se cambiaron a la serie Ev3
Los tamaños de máquina virtual del clúster predeterminado se cambiaron de la serie D a la serie Ev3. Este cambio se aplica a los nodos principales y los nodos de trabajo. Para evitar que este cambio afecte a los flujos de trabajo probados, especifique los tamaños de máquina virtual que desea usar en la plantilla de Resource Manager.
El recurso de la interfaz de red no es visible para clústeres que se ejecutan en conjuntos de escalado de máquinas virtuales de Azure.
HDInsight se está migrando gradualmente a conjuntos de escalado de máquinas virtuales de Azure. Los clientes ya no pueden ver las interfaces de red de las máquinas virtuales de los clústeres que usan conjuntos de escalado de máquinas virtuales de Azure.
Próximos cambios
En las próximas versiones, se realizarán los siguientes cambios.
HDInsight Interactive Query solo admite el escalado automático basado en programación
A medida que los escenarios de los clientes se vuelven más maduros y diversos, vamos identificando algunas limitaciones con la escala automática basada en la carga de Interactive Query (LLAP). Estas limitaciones se deben a la naturaleza de la dinámica de las consultas de LLAP, problemas de precisión en la predicción de carga futura y problemas en la redistribución de tareas del programador LLAP. Debido a estas limitaciones, es posible que los usuarios vean que sus consultas se ejecutan más lentamente en clústeres LLAP cuando el escalado automático está habilitado. El impacto en el rendimiento puede superar las ventajas relativas al costo de la escala automática.
A partir de julio de 2021, la carga de trabajo de Interactive Query en HDInsight solo admite la escalabilidad automática basada en programación. Ya no puede habilitar el escalado automático en clústeres Interactive Query nuevos. Los clústeres en ejecución existentes pueden seguir ejecutándose con las limitaciones conocidas descritas anteriormente.
Microsoft recomienda pasar a un escalado automático basado en programación para LLAP. Puede analizar el patrón de uso actual del clúster a través del panel de Grafana Hive. Para más información, consulte Escalado automático de clústeres de Azure HDInsight.
Actualización de la versión del sistema operativo
Los clústeres de HDInsight se ejecutan actualmente en Ubuntu 16.04 LTS. Como se comenta en el ciclo de versiones de Ubuntu,el kernel de Ubuntu 16.04 alcanzará el final del ciclo de vida (EOL) en abril de 2021. Comenzaremos a implementar la nueva imagen de clúster de HDInsight 4.0 que se ejecuta en Ubuntu 18.04 en mayo de 2021. Los clústeres de HDInsight 4.0 recién creados se ejecutarán en Ubuntu 18.04 de forma predeterminada una vez que esté disponible. Los clústeres existentes en Ubuntu 16.04 se ejecutarán tal y como están con soporte técnico completo.
HDInsight 3.6 seguirá funcionando en Ubuntu 16.04. El soporte técnico estándar terminará el 30 de junio de 2021 y cambiará a soporte técnico Basic a partir del 1 de julio de 2021. Para más información sobre las fechas y las opciones de soporte técnico, consulte las versiones de Azure HDInsight. Ubuntu 18.04 no será compatible con HDInsight 3.6. Si desea usar Ubuntu 18.04, deberá migrar los clústeres a HDInsight 4.0.
Debe quitar y volver a crear los clústeres si desea mover los existentes a Ubuntu 18.04. Planee crear o volver a crear el clúster una vez sea compatible con Ubuntu 18.04. Se enviará otra notificación cuando la nueva imagen esté disponible en todas las regiones.
Se recomienda encarecidamente probar previamente las acciones de script y las aplicaciones personalizadas implementadas en nodos perimetrales en una máquina virtual Ubuntu 18.04. Puede crear una máquina virtual Ubuntu Linux en la versión 18.04-LTS y, a continuación, crear y usar un par de claves de Secure Shell (SSH) en la máquina virtual para ejecutar y probar las acciones de script y las aplicaciones personalizadas implementadas en los nodos perimetrales.
Deshabilitación del tamaño de máquina virtual Standard_A5 como nodo principal para HDInsight 4.0
El nodo principal del clúster de HDInsight es responsable de inicializar y administrar el clúster. El tamaño Standard_A5 de máquina virtual tiene problemas de confiabilidad como nodo principal para HDInsight 4.0. A partir de la próxima versión de mayo de 2021, los clientes no podrán crear clústeres con el tamaño Standard_A5 de máquina virtual como nodo principal. Puede usar otras máquinas virtuales de 2 núcleos, como E2_v3 o E2s_v3. Los clústeres existentes se ejecutarán tal cual. Se recomienda encarecidamente una máquina virtual de 4 núcleos como mínimo para que el nodo principal garantice la alta disponibilidad y confiabilidad de los clústeres de HDInsight de producción.
Corrección de errores
HDInsight continúa realizando mejoras en la confiabilidad y el rendimiento del clúster.
Cambio de versión de componentes
Se ha agregado compatibilidad con Spark 3.0.0 y Kafka 2.4.1 como versión preliminar. En este documento puede encontrar las versiones actuales de los componentes para HDInsight 4.0 y HDInsight 3.6.
Fecha de lanzamiento: 05/02/2021
Esta versión se aplica a HDInsight 3.6 y HDInsight 4.0. La versión de HDInsight se pone a disposición de todas las regiones durante varios días. Esta fecha de lanzamiento indica la fecha de lanzamiento de la primera región. Si no ve los cambios siguientes, espere unos días a que la versión se active en su región.
Nuevas características
Compatibilidad con la serie Dav4
HDInsight ha agregado compatibilidad con la serie Dav4 en esta versión. Obtenga más información sobre la serie Dav4 aquí.
Disponibilidad general del proxy de REST de Kafka
El proxy REST de Kafka le permite interactuar con el clúster de Kafka mediante una API REST a través de HTTPS. El proxy de REST de Kafka está disponible con carácter general a partir de esta versión. Obtenga más información sobre el proxy de REST de Kafka aquí.
Movimiento a conjuntos de escalado de máquinas virtuales
Ahora HDInsight usa máquinas virtuales de Azure para aprovisionar el clúster. El servicio se migra gradualmente a conjuntos de escalado de máquinas virtuales de Azure. Todo el proceso puede tardar unos meses. Después de migrar las regiones y las suscripciones, los clústeres de HDInsight recién creados se ejecutarán en conjuntos de escalado de máquinas virtuales sin acciones del cliente. No se espera ningún cambio importante.
Desuso
Tamaños de máquina virtual deshabilitados
A partir del 9 de enero de 2021, HDInsight impedirá que todos los clientes creen clústeres con los tamaños de máquina virtual standard_A8, standard_A9, standard_A10 y standard_A11. Los clústeres existentes se ejecutarán tal cual. Considere pasar a HDInsight 4.0 para evitar la posible interrupción del sistema o del soporte técnico.
Cambios de comportamiento
El tamaño de la máquina virtual del clúster predeterminado cambia a la serie Ev3
Los tamaños de las máquinas virtuales del clúster predeterminado se cambiarán de la serie D a la serie Ev3. Este cambio se aplica a los nodos principales y los nodos de trabajo. Para evitar que este cambio afecte a los flujos de trabajo probados, especifique los tamaños de máquina virtual que desea usar en la plantilla de Resource Manager.
El recurso de la interfaz de red no es visible para clústeres que se ejecutan en conjuntos de escalado de máquinas virtuales de Azure.
HDInsight se está migrando gradualmente a conjuntos de escalado de máquinas virtuales de Azure. Los clientes ya no pueden ver las interfaces de red de las máquinas virtuales de los clústeres que usan conjuntos de escalado de máquinas virtuales de Azure.
Próximos cambios
En las próximas versiones, se realizarán los siguientes cambios.
La versión predeterminada del clúster cambiará a la 4.0
A partir de febrero de 2021, la versión predeterminada del clúster de HDInsight cambiará de la 3.6 a la 4.0. Para más información sobre las versiones disponibles, consulte este artículo. Más información sobre las novedades de HDInsight 4.0.
Actualización de la versión del sistema operativo
HDInsight está actualizando la versión del sistema operativo de Ubuntu 16.04 a 18.04. La actualización se completará antes de abril de 2021.
Fin del soporte técnico de HDInsight 3.6 el 30 de junio de 2021
El soporte técnico para HDInsight 3.6 finaliza. A partir del 30 de junio de 2021, los clientes no pueden crear clústeres de HDInsight 3.6. Los clústeres existentes se ejecutarán tal cual sin la compatibilidad de Microsoft. Considere pasar a HDInsight 4.0 para evitar la posible interrupción del sistema o del soporte técnico.
Cambio de versión de componentes
No hay cambio de versión de componentes para esta versión. En este documento puede encontrar las versiones actuales de los componentes para HDInsight 4.0 y HDInsight 3.6.
Fecha de lanzamiento: 18/11/2020
Esta versión se aplica a HDInsight 3.6 y HDInsight 4.0. La versión de HDInsight se pone a disposición de todas las regiones durante varios días. Esta fecha de lanzamiento indica la fecha de lanzamiento de la primera región. Si no ve los cambios siguientes, espere unos días a que la versión se active en su región.
Nuevas características
Rotación de claves automática para el cifrado de claves administradas por el cliente en reposo
A partir de esta versión, los clientes pueden usar las direcciones URL de clave de cifrado sin versión de Azure KeyVault para el cifrado de claves administradas por el cliente en reposo. HDInsight rotará automáticamente las claves a medida que expiren o se reemplacen por versiones nuevas. Consulte más detalles aquí.
Posibilidad de seleccionar diferentes tamaños de máquina virtual de Zookeeper para Spark, Hadoop y Machine Learning Services
Anteriormente, HDInsight no admitía la personalización del tamaño de nodo de Zookeeper para los tipos de clúster de Spark, Hadoop y Machine Learning Services. De manera predeterminada, serán tamaños de máquina virtual A2_v2 o A2, que se proporcionan de forma gratuita. A partir de esta versión, puede seleccionar el tamaño de máquina virtual de Zookeeper que sea más adecuado para su escenario. Se cobrarán los nodos de Zookeeper con un tamaño de máquina virtual que no sea A2_v2 o A2. Las máquinas virtuales A2_v2 y A2 todavía se proporcionan de forma gratuita.
Movimiento a conjuntos de escalado de máquinas virtuales
Ahora HDInsight usa máquinas virtuales de Azure para aprovisionar el clúster. A partir de esta versión, el servicio se migrará gradualmente a conjuntos de escalado de máquinas virtuales de Azure. Todo el proceso puede tardar unos meses. Después de migrar las regiones y las suscripciones, los clústeres de HDInsight recién creados se ejecutarán en conjuntos de escalado de máquinas virtuales sin acciones del cliente. No se espera ningún cambio importante.
Desuso
Desuso del clúster de Machine Learning de HDInsight 3.6
El soporte técnico del tipo de clúster de servicios de Machine Learning de HDInsight 3.6 finalizará el 31 de diciembre de 2020. A partir de entonces, los clientes no podrán crear clústeres de servicios de Machine Learning de HDInsight 3.6. Los clústeres existentes se ejecutarán tal cual sin la compatibilidad de Microsoft. Compruebe la expiración del soporte técnico de las versiones y los tipos de clúster de HDInsight aquí.
Tamaños de máquina virtual deshabilitados
A partir del 16 de noviembre de 2020, HDInsight impedirá que los nuevos clientes creen clústeres con los tamaños de máquina virtual standard_A8, standard_A9, standard_A10 y standard_A11. Esta medida no afectará a los clientes existentes que hayan usado estos tamaños de máquina virtual en los últimos tres meses. A partir del 9 de enero de 2021, HDInsight impedirá que todos los clientes creen clústeres con los tamaños de máquina virtual standard_A8, standard_A9, standard_A10 y standard_A11. Los clústeres existentes se ejecutarán tal cual. Considere pasar a HDInsight 4.0 para evitar la posible interrupción del sistema o del soporte técnico.
Cambios de comportamiento
Incorporación de comprobaciones de las reglas de NSG antes de la operación de escalado
HDInsight ha incorporado comprobaciones de los grupos de seguridad de red (NSG) y las rutas definidas por el usuario (UDR) en la operación de escalado. Esta misma validación se realiza durante el escalado de clústeres, así como durante su creación. Gracias a estas pruebas, se pueden evitar errores imprevisibles. Si no se superan correctamente, se producirán errores en el escalado. Para más información acerca de cómo configurar correctamente los NSG y las UDR, consulte este artículo sobre las direcciones IP de administración de HDInsight.
Cambio de versión de componentes
No hay cambio de versión de componentes para esta versión. En este documento puede encontrar las versiones actuales de los componentes para HDInsight 4.0 y HDInsight 3.6.
Fecha de lanzamiento: 09/11/2020
Esta versión se aplica a HDInsight 3.6 y HDInsight 4.0. La versión de HDInsight se pone a disposición de todas las regiones durante varios días. Esta fecha de lanzamiento indica la fecha de lanzamiento de la primera región. Si no ve los cambios siguientes, espere unos días a que la versión se active en su región.
Nuevas características
HDInsight Identity Broker (HIB) se encuentra ahora disponible con carácter general
HDInsight Identity Broker (HIB), que permite la autenticación OAuth de clústeres ESP, se encuentra ahora disponible con carácter general en esta versión. Los clústeres de HIB creados después de esta versión tendrán las características de HIB más recientes:
- Alta disponibilidad (HA)
- Compatibilidad con la autenticación multifactor (MFA)
- Los usuarios federados inician sesión sin sincronización de hash de contraseña en AAD-DS. Para más información, consulte la documentación de HIB.
Movimiento a conjuntos de escalado de máquinas virtuales
Ahora HDInsight usa máquinas virtuales de Azure para aprovisionar el clúster. A partir de esta versión, el servicio se migrará gradualmente a conjuntos de escalado de máquinas virtuales de Azure. Todo el proceso puede tardar unos meses. Después de migrar las regiones y las suscripciones, los clústeres de HDInsight recién creados se ejecutarán en conjuntos de escalado de máquinas virtuales sin acciones del cliente. No se espera ningún cambio importante.
Desuso
Desuso del clúster de Machine Learning de HDInsight 3.6
El soporte técnico del tipo de clúster de servicios de Machine Learning de HDInsight 3.6 finalizará el 31 de diciembre de 2020. A partir de entonces, los clientes no podrán crear clústeres de servicios de Machine Learning de HDInsight 3.6. Los clústeres existentes se ejecutarán tal cual sin la compatibilidad de Microsoft. Compruebe la expiración del soporte técnico de las versiones y los tipos de clúster de HDInsight aquí.
Tamaños de máquina virtual deshabilitados
A partir del 16 de noviembre de 2020, HDInsight impedirá que los nuevos clientes creen clústeres con los tamaños de máquina virtual standard_A8, standard_A9, standard_A10 y standard_A11. Esta medida no afectará a los clientes existentes que hayan usado estos tamaños de máquina virtual en los últimos tres meses. A partir del 9 de enero de 2021, HDInsight impedirá que todos los clientes creen clústeres con los tamaños de máquina virtual standard_A8, standard_A9, standard_A10 y standard_A11. Los clústeres existentes se ejecutarán tal cual. Considere pasar a HDInsight 4.0 para evitar la posible interrupción del sistema o del soporte técnico.
Cambios de comportamiento
No hay cambios de comportamiento en esta versión.
Próximos cambios
En las próximas versiones, se realizarán los siguientes cambios.
Posibilidad de seleccionar diferentes tamaños de máquina virtual de Zookeeper para Spark, Hadoop y Machine Learning Services
Actualmente, HDInsight no admite la personalización del tamaño de nodo de Zookeeper para los tipos de clúster de Spark, Hadoop y Machine Learning Services. De manera predeterminada, serán tamaños de máquina virtual A2_v2 o A2, que se proporcionan de forma gratuita. En la próxima versión, puede seleccionar el tamaño de máquina virtual de Zookeeper que sea más adecuado para su escenario. Se cobrarán los nodos de Zookeeper con un tamaño de máquina virtual que no sea A2_v2 o A2. Las máquinas virtuales A2_v2 y A2 todavía se proporcionan de forma gratuita.
La versión predeterminada del clúster cambiará a la 4.0
A partir de febrero de 2021, la versión predeterminada del clúster de HDInsight cambiará de la 3.6 a la 4.0. Para más información sobre las versiones disponibles, vea las versiones compatibles. Más información sobre las novedades de HDInsight 4.0
Fin del soporte técnico de HDInsight 3.6 el 30 de junio de 2021
El soporte técnico para HDInsight 3.6 finaliza. A partir del 30 de junio de 2021, los clientes no pueden crear clústeres de HDInsight 3.6. Los clústeres existentes se ejecutarán tal cual sin la compatibilidad de Microsoft. Considere pasar a HDInsight 4.0 para evitar la posible interrupción del sistema o del soporte técnico.
Corrección de errores
HDInsight continúa realizando mejoras en la confiabilidad y el rendimiento del clúster.
Corrección del problema para reiniciar las máquinas virtuales del clúster
Se ha corregido el problema con el reinicio de las máquinas virtuales del clúster. Puede usar de nuevo PowerShell o la API REST para reiniciar los nodos del clúster.
Cambio de versión de componentes
No hay cambio de versión de componentes para esta versión. En este documento puede encontrar las versiones actuales de los componentes para HDInsight 4.0 y HDInsight 3.6.
Fecha de lanzamiento: 08/10/2020
Esta versión se aplica a HDInsight 3.6 y HDInsight 4.0. La versión de HDInsight se pone a disposición de todas las regiones durante varios días. Esta fecha de lanzamiento indica la fecha de lanzamiento de la primera región. Si no ve los cambios siguientes, espere unos días a que la versión se active en su región.
Nuevas características
Clústeres privados de HDInsight sin dirección IP pública y vínculo privado (versión preliminar)
HDInsight ahora admite la creación de clústeres sin una dirección IP pública y acceso de vínculo privado a los clústeres en la versión preliminar. Los clientes pueden usar la nueva configuración de red avanzada para crear un clúster totalmente aislado sin ninguna dirección IP pública y usar sus propios puntos de conexión privados para tener acceso al clúster.
Movimiento a conjuntos de escalado de máquinas virtuales
Ahora HDInsight usa máquinas virtuales de Azure para aprovisionar el clúster. A partir de esta versión, el servicio se migrará gradualmente a conjuntos de escalado de máquinas virtuales de Azure. Todo el proceso puede tardar unos meses. Después de migrar las regiones y las suscripciones, los clústeres de HDInsight recién creados se ejecutarán en conjuntos de escalado de máquinas virtuales sin acciones del cliente. No se espera ningún cambio importante.
Desuso
Desuso del clúster de Machine Learning de HDInsight 3.6
El soporte técnico del tipo de clúster de servicios de Machine Learning de HDInsight 3.6 finalizará el 31 de diciembre de 2020. Los clientes no crearán nuevos clústeres de servicios de Machine Learning 3.6 a partir de entonces. Los clústeres existentes se ejecutarán tal cual sin la compatibilidad de Microsoft. Compruebe la expiración del soporte técnico de las versiones y los tipos de clúster de HDInsight aquí.
Cambios de comportamiento
No hay cambios de comportamiento en esta versión.
Próximos cambios
En las próximas versiones, se realizarán los siguientes cambios.
Posibilidad de seleccionar diferentes tamaños de máquina virtual de Zookeeper para Spark, Hadoop y Machine Learning Services
Actualmente, HDInsight no admite la personalización del tamaño de nodo de Zookeeper para los tipos de clúster de Spark, Hadoop y Machine Learning Services. De manera predeterminada, serán tamaños de máquina virtual A2_v2 o A2, que se proporcionan de forma gratuita. En la próxima versión, puede seleccionar el tamaño de máquina virtual de Zookeeper que sea más adecuado para su escenario. Se cobrarán los nodos de Zookeeper con un tamaño de máquina virtual que no sea A2_v2 o A2. Las máquinas virtuales A2_v2 y A2 todavía se proporcionan de forma gratuita.
Corrección de errores
HDInsight continúa realizando mejoras en la confiabilidad y el rendimiento del clúster.
Cambio de versión de componentes
No hay cambio de versión de componentes para esta versión. En este documento puede encontrar las versiones actuales de los componentes para HDInsight 4.0 y HDInsight 3.6.
Fecha de lanzamiento: 28/09/2020
Esta versión se aplica a HDInsight 3.6 y HDInsight 4.0. La versión de HDInsight se pone a disposición de todas las regiones durante varios días. Esta fecha de lanzamiento indica la fecha de lanzamiento de la primera región. Si no ve los cambios siguientes, espere unos días a que la versión se active en su región.
Nuevas características
La escalabilidad automática para Interactive Query con HDInsight 4.0 ya está disponible con carácter general.
La escalabilidad automática para el tipo de clúster de Interactive Query está disponible ahora con carácter general (GA) para HDInsight 4.0. Todos los clústeres de Interactive Query 4.0 creados después del 27 de agosto de 2020 tendrán soporte técnico de disponibilidad general para la escalabilidad automática.
El clúster de HBase admite ADLS Gen2 Premium
HDInsight admite ahora ADLS Gen2 Premium como cuenta de almacenamiento principal para los clústeres de HDInsight HBase 3.6 y 4.0. En combinación con las escrituras aceleradas, puede obtener un mejor rendimiento para los clústeres de HBase.
Distribución de particiones de Kafka en dominios de error de Azure
Un dominio de error es una agrupación lógica del hardware subyacente en un centro de datos de Azure. Todos los dominios de error comparten la fuente de energía y el conmutador de red. Antes de HDInsight, Kafka puede almacenar todas las réplicas de las particiones en el mismo dominio de error. A partir de esta versión, HDInsight admite ahora la distribución automática de las particiones de Kafka basadas en los dominios de error de Azure.
Cifrado en tránsito
Los clientes pueden habilitar el cifrado en tránsito entre los nodos del clúster mediante el cifrado IPsec con claves administradas por la plataforma. Esta opción se puede habilitar en el momento de la creación del clúster. Vea más detalles sobre cómo habilitar el cifrado en tránsito.
Cifrado en el host
Cuando se habilita el cifrado en el host, los datos almacenados en el host de máquina virtual se cifran en reposo y se transmiten cifrados al servido de almacenamiento. A partir de esta versión, puede habilitar el cifrado en el host en el disco de datos temporal al crear el clúster. El cifrado en el host solo se admite en algunas SKU de máquina virtual en regiones limitadas. HDInsight es compatible con las siguientes SKU y configuración de nodo. Vea más detalles sobre cómo habilitar el cifrado en el host.
Movimiento a conjuntos de escalado de máquinas virtuales
Ahora HDInsight usa máquinas virtuales de Azure para aprovisionar el clúster. A partir de esta versión, el servicio se migrará gradualmente a conjuntos de escalado de máquinas virtuales de Azure. Todo el proceso puede tardar unos meses. Después de migrar las regiones y las suscripciones, los clústeres de HDInsight recién creados se ejecutarán en conjuntos de escalado de máquinas virtuales sin acciones del cliente. No se espera ningún cambio importante.
Desuso
No hay ningún desuso en esta versión.
Cambios de comportamiento
No hay cambios de comportamiento en esta versión.
Próximos cambios
En las próximas versiones, se realizarán los siguientes cambios.
Posibilidad de seleccionar diferentes SKU de Zookeeper para Spark, Hadoop y Machine Learning Services
Actualmente, HDInsight no admite el cambio del SKU de Zookeeper para los tipos de clúster de Spark, Hadoop y Machine Learning Services. Usa el SKU A2_v2/A2 para los nodos de Zookeeper y a los clientes no se les cobra por ellos. En la próxima versión, los clientes pueden cambiar la SKU de Zookeeper SKU para Spark, Hadoop y Machine Learning Services cuando sea necesario. Se cobrarán los nodos Zookeeper con una SKU que no sea A2_v2/A2. La SKU predeterminada seguirá siendo A2_V2/A2 y no tendrá cargo alguno.
Corrección de errores
HDInsight continúa realizando mejoras en la confiabilidad y el rendimiento del clúster.
Cambio de versión de componentes
No hay cambio de versión de componentes para esta versión. En este documento puede encontrar las versiones actuales de los componentes para HDInsight 4.0 y HDInsight 3.6.
Fecha de lanzamiento: 09/08/2020
Esta versión se aplica solo a HDInsight 4.0. La versión de HDInsight se pone a disposición de todas las regiones durante varios días. Esta fecha de lanzamiento indica la fecha de lanzamiento de la primera región. Si no ve los cambios siguientes, espere unos días a que la versión se active en su región.
Nuevas características
Soporte técnico de SparkCruise
SparkCruise es un sistema de reutilización automática de cálculos para Spark. Selecciona subexpresiones comunes que se puedan materializar en función de la carga de trabajo de consultas pasadas. SparkCruise materializa estas subexpresiones como parte del procesamiento de consultas, y la reutilización de cálculos se aplica automáticamente en segundo plano. Puede beneficiarse de SparkCruise sin tener que modificar el código de Spark.
Soporte técnico de la vista de Hive para HDInsight 4.0
La vista de Hive de Apache Ambari está diseñada para ayudarle a crear, optimizar y ejecutar consultas de Hive desde el explorador web. La vista de Hive se admite de forma nativa en los clústeres de HDInsight 4.0 a partir de esta versión. No se aplica a los clústeres ya existentes. Para obtener la vista de Hive integrada, debe quitar y volver a crear el clúster.
Soporte técnico de la vista de Tez para HDInsight 4.0
La vista Apache Tez se usa para realizar un seguimiento de la ejecución del trabajo de Hive Tez y depurarlo. La vista de Tez se admite de forma nativa para HDInsight 4.0 a partir de esta versión. No se aplica a los clústeres ya existentes. Para obtener la vista de Tez integrada, debe colocar y volver a crear el clúster.
Desuso
Desuso de Spark 2.1 y 2.2 para el clúster de Spark de HDInsight 3.6
A partir del 1 de julio de 2020, los clientes no podrán crear clústeres de Spark con Spark 2.1 y 2.2 en HDInsight 3.6. Los clústeres existentes se ejecutarán tal cual sin la compatibilidad de Microsoft. Considere la posibilidad de pasar a Spark 2.3 en HDInight 3.6 a partir del 30 de junio de 2020 para evitar la posible interrupción del sistema o del soporte técnico.
Desuso de Spark 2.3 y 4.0 para el clúster de Spark de HDInsight 4.0
A partir del 1 de julio de 2020, los clientes no podrán crear clústeres de Spark con Spark 2.3 en HDInsight 4.0. Los clústeres existentes se ejecutarán tal cual sin la compatibilidad de Microsoft. Considere la posibilidad de pasar a Spark 2.4 en HDInight 4.0 a partir del 30 de junio de 2020 para evitar la posible interrupción del sistema o del soporte técnico.
Desuso de Kafka 1.1 en el clúster de Kafka de HDInsight 4.0
A partir del 1 de julio de 2020, los clientes no podrán crear clústeres de Kafka con Kafka 1.1 en HDInsight 4.0. Los clústeres existentes se ejecutarán tal cual sin la compatibilidad de Microsoft. Considere la posibilidad de pasar a Kafka 2.1 en HDInight 4.0 a partir del 30 de junio de 2020 para evitar la posible interrupción del sistema o del soporte técnico.
Cambios de comportamiento
Cambio de versión de la pila de Ambari
En esta versión, la versión de Ambari se cambia de 2.x.x.x a 4.1. Puede comprobar la versión de la pila (HDInsight 4.1) en Ambari: Ambari > Usuario > Versiones.
Próximos cambios
No habrá cambios importantes que requieran su atención.
Corrección de errores
HDInsight continúa realizando mejoras en la confiabilidad y el rendimiento del clúster.
Las instancias de JIRA siguientes se trasladan a Hive:
Las siguientes instancias de JIRA se llevan a HBase:
Cambio de versión de componentes
No hay cambio de versión de componentes para esta versión. En este documento puede encontrar las versiones actuales de los componentes para HDInsight 4.0 y HDInsight 3.6.
Problemas conocidos
Se ha corregido un problema de Azure Portal, en el que los usuarios experimentaban un error cuando creaban un clúster de Azure HDInsight mediante una autenticación de SSH de tipo clave pública. Cuando los usuarios hacían clic en Revisar y crear, recibían el error "No debe contener tres caracteres consecutivos del nombre de usuario de SSH". Este problema se ha corregido, pero es posible que deba actualizar la memoria caché del explorador; para ello, presione Ctrl + F5 para cargar la vista corregida. La solución a este problema consistió en crear un clúster con una plantilla de Resource Manager.
Fecha de lanzamiento: 13/07/2020
Esta versión se aplica a HDInsight 3.6 y 4.0. La versión de HDInsight se pone a disposición de todas las regiones durante varios días. Esta fecha de lanzamiento indica la fecha de lanzamiento de la primera región. Si no ve los cambios siguientes, espere unos días a que la versión se active en su región.
Nuevas características
Compatibilidad con Caja de seguridad del cliente para Microsoft Azure
Azure HDInsight ahora es compatible con Caja de seguridad del cliente de Azure. Proporciona una interfaz para que los clientes puedan revisar y aprobar, o rechazar, las solicitudes de acceso a datos de los clientes. Se utiliza cuando un ingeniero de Microsoft necesita acceder a los datos del cliente durante una solicitud de soporte técnico. Para más información, consulte Caja de seguridad del cliente de Microsoft Azure.
Directivas de punto de conexión de servicio para el almacenamiento
Los clientes ahora pueden usar directivas de puntos de conexión de servicio (SEP) en la subred del clúster de HDInsight. Más información sobre la directiva de punto de conexión de servicio de Azure.
Desuso
Desuso de Spark 2.1 y 2.2 para el clúster de Spark de HDInsight 3.6
A partir del 1 de julio de 2020, los clientes no podrán crear clústeres de Spark con Spark 2.1 y 2.2 en HDInsight 3.6. Los clústeres existentes se ejecutarán tal cual sin la compatibilidad de Microsoft. Considere la posibilidad de pasar a Spark 2.3 en HDInight 3.6 a partir del 30 de junio de 2020 para evitar la posible interrupción del sistema o del soporte técnico.
Desuso de Spark 2.3 y 4.0 para el clúster de Spark de HDInsight 4.0
A partir del 1 de julio de 2020, los clientes no podrán crear clústeres de Spark con Spark 2.3 en HDInsight 4.0. Los clústeres existentes se ejecutarán tal cual sin la compatibilidad de Microsoft. Considere la posibilidad de pasar a Spark 2.4 en HDInight 4.0 a partir del 30 de junio de 2020 para evitar la posible interrupción del sistema o del soporte técnico.
Desuso de Kafka 1.1 en el clúster de Kafka de HDInsight 4.0
A partir del 1 de julio de 2020, los clientes no podrán crear clústeres de Kafka con Kafka 1.1 en HDInsight 4.0. Los clústeres existentes se ejecutarán tal cual sin la compatibilidad de Microsoft. Considere la posibilidad de pasar a Kafka 2.1 en HDInight 4.0 a partir del 30 de junio de 2020 para evitar la posible interrupción del sistema o del soporte técnico.
Cambios de comportamiento
No hay ningún comportamiento al que haya que prestar atención.
Próximos cambios
En las próximas versiones, se realizarán los siguientes cambios.
Posibilidad de seleccionar diferentes SKU de Zookeeper para Spark, Hadoop y Machine Learning Services
Actualmente, HDInsight no admite el cambio del SKU de Zookeeper para los tipos de clúster de Spark, Hadoop y Machine Learning Services. Usa el SKU A2_v2/A2 para los nodos de Zookeeper y a los clientes no se les cobra por ellos. En la próxima versión, los clientes podrán cambiar la SKU de Zookeeper SKU para Spark, Hadoop y Machine Learning Services cuando sea necesario. Se cobrarán los nodos Zookeeper con una SKU que no sea A2_v2/A2. La SKU predeterminada seguirá siendo A2_V2/A2 y no tendrá cargo alguno.
Corrección de errores
HDInsight continúa realizando mejoras en la confiabilidad y el rendimiento del clúster.
Problema de Hive Warehouse Connector corregido
En la versión anterior había un problema con la facilidad de uso de Hive Warehouse Connector, pero ya se ha corregido.
Se ha reparado el problema de que Zeppelin Notebook trunca los ceros a la izquierda
Zeppelin truncaba de forma incorrecta los ceros a la izquierda en la salida de la tabla en formato de cadena. En esta versión se ha corregido ese problema.
Cambio de versión de componentes
No hay cambio de versión de componentes para esta versión. En este documento puede encontrar las versiones actuales de los componentes para HDInsight 4.0 y HDInsight 3.6.
Fecha de lanzamiento: 11/06/2020
Esta versión se aplica a HDInsight 3.6 y 4.0. La versión de HDInsight se pone a disposición de todas las regiones durante varios días. Esta fecha de lanzamiento indica la fecha de lanzamiento de la primera región. Si no ve los cambios siguientes, espere unos días a que la versión se active en su región.
Nuevas características
Movimiento a conjuntos de escalado de máquinas virtuales
Ahora, HDInsight usa máquinas virtuales de Azure para aprovisionar el clúster. A partir de esta versión, los nuevos clústeres de HDInsight comienzan a usar el conjunto de escalado de máquinas virtuales de Azure. El cambio se implementa gradualmente, y no se producirá ningún cambio importante. Consulte más información sobre los conjuntos de escalado de máquinas virtuales de Azure.
Reinicio de máquinas virtuales en un clúster de HDInsight
En esta versión, se admite el reinicio de máquinas virtuales en el clúster de HDInsight para reiniciar los nodos que no responden. Actualmente solo puede hacerlo a través de la API, pero en un futuro se admitirán PowerShell y la CLI. Para obtener más información sobre la API, vea este documento.
Desuso
Desuso de Spark 2.1 y 2.2 para el clúster de Spark de HDInsight 3.6
A partir del 1 de julio de 2020, los clientes no podrán crear clústeres de Spark con Spark 2.1 y 2.2 en HDInsight 3.6. Los clústeres existentes se ejecutarán tal cual sin la compatibilidad de Microsoft. Considere la posibilidad de pasar a Spark 2.3 en HDInight 3.6 a partir del 30 de junio de 2020 para evitar la posible interrupción del sistema o del soporte técnico.
Desuso de Spark 2.3 y 4.0 para el clúster de Spark de HDInsight 4.0
A partir del 1 de julio de 2020, los clientes no podrán crear clústeres de Spark con Spark 2.3 en HDInsight 4.0. Los clústeres existentes se ejecutarán tal cual sin la compatibilidad de Microsoft. Considere la posibilidad de pasar a Spark 2.4 en HDInight 4.0 a partir del 30 de junio de 2020 para evitar la posible interrupción del sistema o del soporte técnico.
Desuso de Kafka 1.1 en el clúster de Kafka de HDInsight 4.0
A partir del 1 de julio de 2020, los clientes no podrán crear clústeres de Kafka con Kafka 1.1 en HDInsight 4.0. Los clústeres existentes se ejecutarán tal cual sin la compatibilidad de Microsoft. Considere la posibilidad de pasar a Kafka 2.1 en HDInight 4.0 a partir del 30 de junio de 2020 para evitar la posible interrupción del sistema o del soporte técnico.
Cambios de comportamiento
Cambio de tamaño del nodo principal del clúster de Spark de ESP
El tamaño de nodo principal mínimo permitido para un clúster de Spark de ESP cambia a Standard_D13_V2. Las máquinas virtuales que tienen núcleos y memoria insuficientes como nodo principal pueden provocar problemas en el clúster de ESP debido a su capacidad relativamente baja de CPU y memoria. A partir de esta versión, use las SKU posteriores a Standard_D13_V2 y Standard_E16_V3 como nodo principal para los clústeres de Spark de ESP.
Se requiere una máquina virtual de 4 núcleos como mínimo para el nodo principal
Se requiere una máquina virtual de 4 núcleos como mínimo para que el nodo principal garantice la alta disponibilidad y confiabilidad de los clústeres de HDInsight. A partir del 6 de abril de 2020, los clientes solo pueden elegir una máquina virtual de cuatro núcleos o más como nodo principal para los nuevos clústeres de HDInsight. Los clústeres existentes seguirán ejecutándose según lo previsto.
Cambio de aprovisionamiento del nodo de trabajo del clúster
Cuando el 80 % de los nodos de trabajo están listos, el clúster entra en la fase operativa. En esta fase, los clientes pueden realizar todas las operaciones del plano de datos, como ejecutar scripts y trabajos. No obstante, no pueden realizar ninguna operación de plano de control, como el escalado o la reducción vertical. Solo se admite la eliminación.
Después de la fase operativa, el clúster espera otros 60 minutos por el 20 % restante de los nodos de trabajo. Al final de este período de 60 minutos, el clúster pasa a la fase de ejecución, incluso si todos los nodos de trabajo todavía no están disponibles. Una vez que un clúster entra en la fase de ejecución, se puede usar de la forma habitual. Se aceptan las operaciones del plan de control, como el escalado o la reducción vertical, y las operaciones del plan de datos, como la ejecución de scripts y trabajos. Si algunos de los nodos de trabajo solicitados no están disponibles, el clúster se marcará como correcto parcialmente. Se le cobrará por los nodos que se hayan implementado correctamente.
Creación de una entidad de servicio nueva a través de HDInsight
Anteriormente, con la creación de un clúster, los clientes podían crear una nueva entidad de servicio para acceder a la cuenta de ADLS Gen 1 conectada en Azure Portal. A partir del 15 de junio de 2020, no se pueden crear entidades de servicio en el flujo de trabajo de creación de HDInsight; solo se admite la entidad de servicio existente. Consulte Creación de una entidad de servicio y certificados mediante Azure Active Directory.
Tiempo de espera para acciones de script con creación de clústeres
HDInsight admite la ejecución de acciones de script con la creación de clústeres. A partir de esta versión, todas las acciones de script con creación de clústeres deben finalizar en 60 minutos, o agotarán el tiempo de espera. Las acciones de script enviadas a los clústeres que se están ejecutando no se ven afectadas. Consulte más detalles aquí.
Próximos cambios
No habrá cambios importantes que requieran su atención.
Corrección de errores
HDInsight continúa realizando mejoras en la confiabilidad y el rendimiento del clúster.
Cambio de versión de componentes
HBase 2.0 a 2.1.6
La versión de HBase se actualiza de la versión 2.0 a 2.1.6.
Spark 2.4.0 a 2.4.4
La versión de Spark se actualiza de la versión 2.4.0 a 2.4.4.
Kafka 2.1.0 a 2.1.1
La versión de Kafka se actualiza de la versión 2.1.0 a 2.1.1.
En este documento puede encontrar las versiones actuales de los componentes para HDInsight 4.0 y HDInsight 3.6.
Problemas conocidos
Problema con Hive Warehouse Connector
En esta versión hay un problema con Hive Warehouse Connector. que se corregirá en la próxima versión. El problema no afecta a los clústeres creados antes de esta versión. Si es posible, evite quitar y volver a crear el clúster. Si necesita más ayuda al respecto, abra una incidencia de soporte técnico.
Fecha de lanzamiento: 09/01/2020
Esta versión se aplica a HDInsight 3.6 y 4.0. La versión de HDInsight se pone a disposición de todas las regiones durante varios días. Esta fecha de lanzamiento indica la fecha de lanzamiento de la primera región. Si no ve los cambios siguientes, espere unos días a que la versión se active en su región.
Nuevas características
Cumplimiento de TLS 1.2
Seguridad de la capa de transporte (TLS) y Capa de sockets seguros (SSL) son protocolos criptográficos que proporcionan la seguridad de las comunicaciones a través de una red de equipos. Más información sobre TLS. HDInsight usa TLS 1.2 en los puntos de conexión de HTTP públicos, pero todavía se admite TLS 1.1 para la compatibilidad con versiones anteriores.
Con esta versión, los clientes pueden optar por recibir solo TLS 1.2 para todas las conexiones a través del punto de conexión de clúster público. Para admitir esto, se introduce la nueva propiedad minSupportedTlsVersion que puede especificarse durante la creación del clúster. Si no se establece la propiedad, el clúster sigue siendo compatible con TLS 1.0, 1.1 y 1.2, que es el mismo comportamiento de hoy en día. Los clientes pueden establecer el valor de esta propiedad en "1.2", lo que significa que el clúster solo admite TLS 1.2 y versiones posteriores. Para más información, consulte Seguridad de la capa de transporte.
Traiga su propia clave para el cifrado de discos
Todos los discos administrados en HDInsight están protegidos con Azure Storage Service Encryption (SSE). Los datos en esos discos se cifran de forma predeterminada mediante claves administradas por Microsoft. A partir de esta versión, puede usar Bring Your Own Key (BYOK) para el cifrado de discos y administrarlo con Azure Key Vault. El cifrado de BYOK es una configuración en un paso durante la creación del clúster sin ningún otro costo. Solo ha de registrar HDInsight como identidad administrada con Azure Key Vault y agregar la clave de cifrado al crear el clúster. Para obtener más información, consulte Cifrado de disco mediante claves administradas por el cliente.
Desuso
No hay elementos en desuso en esta versión. Para prepararse para las próximas entradas en desuso, consulte Próximos cambios.
Cambios de comportamiento
No hay cambios de comportamiento en esta versión. Para prepararse para los próximos cambios, consulte Próximos cambios.
Próximos cambios
En las próximas versiones, se realizarán los siguientes cambios.
Desuso de Spark 2.1 y 2.2 para el clúster de Spark de HDInsight 3.6
A partir del 1 de julio de 2020, los clientes no podrán crear clústeres de Spark con Spark 2.1 y 2.2 en HDInsight 3.6. Los clústeres existentes se ejecutarán tal cual sin la compatibilidad de Microsoft. Considere la posibilidad de pasar a Spark 2.3 en HDInsight 3.6 antes del 30 de junio de 2020 para evitar la posible interrupción del sistema o del soporte técnico.
Desuso de Spark 2.3 y 4.0 para el clúster de Spark de HDInsight 4.0
A partir del 1 de julio de 2020, los clientes no podrán crear clústeres de Spark con Spark 2.3 en HDInsight 4.0. Los clústeres existentes se ejecutarán tal cual sin la compatibilidad de Microsoft. Considere la posibilidad de pasar a Spark 2.4 en HDInsight 4.0 antes del 30 de junio de 2020 para evitar la posible interrupción del sistema o del soporte técnico.
Desuso de Kafka 1.1 en el clúster de Kafka de HDInsight 4.0
A partir del 1 de julio de 2020, los clientes no podrán crear clústeres de Kafka con Kafka 1.1 en HDInsight 4.0. Los clústeres existentes se ejecutarán tal cual sin la compatibilidad de Microsoft. Considere la posibilidad de pasar a Kafka 2.1 en HDInight 4.0 a partir del 30 de junio de 2020 para evitar la posible interrupción del sistema o del soporte técnico. Para más información, consulte Migración de cargas de trabajo de Apache Kafka a Azure HDInsight 4.0.
HBase 2.0 a 2.1.6
En la próxima versión de HDInsight 4.0, la versión de HBase se actualizará de 2.0 a 2.1.6
Spark 2.4.0 a 2.4.4
En la próxima versión de HDInsight 4.0, la versión de Spark se actualizará de 2.4.0 a 2.4.4
Kafka 2.1.0 a 2.1.1
En la próxima versión de HDInsight 4.0, la versión de Kafka se actualizará de 2.1.0 a 2.1.1
Se requiere una máquina virtual de 4 núcleos como mínimo para el nodo principal
Se requiere una máquina virtual de 4 núcleos como mínimo para que el nodo principal garantice la alta disponibilidad y confiabilidad de los clústeres de HDInsight. A partir del 6 de abril de 2020, los clientes solo pueden elegir una máquina virtual de cuatro núcleos o más como nodo principal para los nuevos clústeres de HDInsight. Los clústeres existentes seguirán ejecutándose según lo previsto.
Cambio de tamaño del nodo del clúster de Spark de ESP
En la próxima versión, el tamaño de nodo mínimo permitido para un clúster de Spark de ESP se cambiará a Standard_D13_V2. Las máquinas virtuales de la serie A pueden provocar problemas en el clúster de ESP debido a su capacidad de CPU y memoria relativamente baja. Las máquinas virtuales de la serie A quedarán en desuso para crear nuevos clústeres de ESP.
Movimiento a conjuntos de escalado de máquinas virtuales
Ahora HDInsight usa máquinas virtuales de Azure para aprovisionar el clúster. En la próxima versión, HDInsight usará los conjuntos de escalado de máquinas virtuales de Azure en su lugar. Consulte más información sobre los conjuntos de escalado de máquinas virtuales de Azure.
Corrección de errores
HDInsight continúa realizando mejoras en la confiabilidad y el rendimiento del clúster.
Cambio de versión de componentes
No hay cambio de versión de componentes para esta versión. Aquí puede encontrar las versiones actuales de los componentes para HDInsight 4.0 y HDInsight 3.6.
Fecha de lanzamiento: 17/12/2019
Esta versión se aplica a HDInsight 3.6 y 4.0.
Nuevas características
Etiquetas de servicio
Las etiquetas de servicio simplifican la seguridad de las máquinas virtuales y las redes virtuales de Azure, permitiéndole restringir fácilmente el acceso de red a los servicios de Azure. Puede usar etiquetas de servicio en las reglas del grupo de seguridad de red (NSG) para permitir o denegar el tráfico a un servicio específico de Azure, globalmente o por región de Azure. Azure proporciona el mantenimiento de las direcciones IP subyacentes a cada etiqueta. Las etiquetas de servicio de HDInsight de los grupos de seguridad de red (NSG) son grupos de direcciones IP para los servicios de mantenimiento y administración. Estos grupos ayudan a minimizar la complejidad de la creación de reglas de seguridad. Los clientes de HDInsight pueden habilitar la etiqueta de servicio mediante Azure Portal, PowerShell y la API de REST. Para más información, consulte Etiquetas de servicio del grupo de seguridad de red (NSG) para Azure HDInsight.
Base de datos de Ambari personalizada
HDInsight ahora permite usar su propia base de datos SQL para Apache Ambari. Puede configurar esta base de datos de Ambari personalizada en Azure Portal o mediante una plantilla de Resource Manager. Esta característica le permite elegir la base de datos SQL adecuada para sus necesidades de procesamiento y capacidad. También se puede actualizar fácilmente para cumplir los requisitos de crecimiento del negocio. Para más información, consulte Configuración de clústeres de HDInsight con una base de datos de Ambari personalizada.

Desuso
No hay elementos en desuso en esta versión. Para prepararse para las próximas entradas en desuso, consulte Próximos cambios.
Cambios de comportamiento
No hay cambios de comportamiento en esta versión. Para prepararse para los próximos cambios de comportamiento, consulte Próximos cambios.
Próximos cambios
En las próximas versiones, se realizarán los siguientes cambios.
Cumplimiento de Seguridad de la capa de transporte (TLS) 1.2
Seguridad de la capa de transporte (TLS) y Capa de sockets seguros (SSL) son protocolos criptográficos que proporcionan la seguridad de las comunicaciones a través de una red de equipos. Para más información, consulte Seguridad de la capa de transporte. Aunque los clústeres de Azure HDInsight aceptan conexiones TLS 1.2 en puntos de conexión HTTPS públicos, todavía se admite TLS 1.1 para la compatibilidad con versiones anteriores de clientes más antiguos.
A partir de la siguiente versión, podrá elegir y configurar los nuevos clústeres de HDInsight para que solo acepten conexiones TLS 1.2.
Más adelante en el año, a partir del 30/6/2020, Azure HDInsight aplicará TLS 1.2 o versiones posteriores para todas las conexiones HTTPS. Se recomienda asegurarse de que todos los clientes están listos para trabajar con TLS 1.2 o versiones posteriores.
Movimiento a conjuntos de escalado de máquinas virtuales
Ahora HDInsight usa máquinas virtuales de Azure para aprovisionar el clúster. A partir de febrero de 2020 (la fecha exacta se comunicará más adelante), HDInsight usará conjuntos de escalado de máquinas virtuales de Azure en su lugar. Consulte más información sobre los conjuntos de escalado de máquinas virtuales de Azure.
Cambio de tamaño del nodo del clúster de Spark de ESP
En la próxima versión:
- El tamaño de nodo mínimo permitido para un clúster de Spark de ESP se cambiará a Standard_D13_V2.
- Las máquinas virtuales de la serie A dejarán de usarse para crear nuevos clústeres de ESP, ya que las máquinas virtuales de la serie A podrían causar problemas en el clúster de ESP debido a una capacidad de memoria y CPU relativamente bajas.
HBase 2.0 a 2.1
En la próxima versión de HDInsight 4.0, la versión de HBase se actualizará de 2.0 a 2.1.
Corrección de errores
HDInsight continúa realizando mejoras en la confiabilidad y el rendimiento del clúster.
Cambio de versión de componentes
Hemos ampliado la compatibilidad con HDInsight 3.6 al 31 de diciembre de 2020. Puede encontrar más detalles en Versiones admitidas de HDInsight.
No hay cambio de versión de componentes para HDInsight 4.0.
Apache Zeppelin en HDInsight 3.6: 0.7.0-->0.7.3.
Puede encontrar las versiones de componentes más actualizadas en este documento.
Nuevas regiones
Norte de Emiratos Árabes Unidos
Las direcciones IP de administración de Norte de Emiratos Árabes Unidos son: 65.52.252.96 y 65.52.252.97.
Fecha de lanzamiento: 07/11/2019
Esta versión se aplica a HDInsight 3.6 y 4.0.
Nuevas características
HDInsight Identity Broker (HIB) (versión preliminar)
HDInsight Identity Broker (HIB) permite a los usuarios iniciar sesión en Apache Ambari mediante la autenticación multifactor (MFA) y obtener los vales de Kerberos necesarios sin necesidad de hash de contraseña en Azure Active Directory Domain Services (AAD-DS). Actualmente, HIB solo está disponible para los clústeres implementados mediante la plantilla de Azure Resource Manager (ARM).
Proxy de API de REST de Kafka (versión preliminar)
El proxy de API de REST de Kafka proporciona una implementación de un solo clic del proxy de REST de alta disponibilidad con un clúster de Kafka mediante la autorización segura de Azure AD y el protocolo OAuth.
Escalado automático
La escalabilidad automática en Azure HDInsight ya está disponible con carácter general en todas las regiones para los tipos de clúster de Apache Spark y Hadoop. Esta característica permite administrar las cargas de trabajo de análisis de macrodatos de un modo más rentable y productivo. Ahora puede optimizar el uso de los clústeres de HDInsight y pagar solo por lo que necesita.
En función de sus requisitos, puede elegir escalabilidad automática basada en la carga o basada en una programación. La escalabilidad automática basada en la carga puede escalar o reducir verticalmente el tamaño del clúster según las necesidades de recursos en ese momento, mientras que la escalabilidad automática basada en una programación cambia el tamaño del clúster según la programación que se haya definido previamente.
La escalabilidad automática para cargas de trabajo de HBase y LLAP también está en versión preliminar pública. Para más información, consulte Escalado automático de clústeres de Azure HDInsight.
Escrituras aceleradas de HDInsight para Apache HBase
Escrituras aceleradas usa discos administrados SSD premium de Azure para mejorar el rendimiento del registro de escritura previa (WAL) de Apache HBase. Para más información, consulte Escrituras aceleradas de Azure HDInsight para Apache HBase.
Base de datos de Ambari personalizada
HDInsight ofrece ahora una nueva capacidad para permitir que los usuarios usen su propia instancia de SQL DB para Ambari. Ahora los clientes pueden elegir la instancia correcta de SQL DB para Ambari y actualizarla con facilidad en función de sus propios requisitos de crecimiento empresarial. La implementación se realiza mediante una plantilla de Azure Resource Manager. Para más información, consulte Configuración de clústeres de HDInsight con una base de datos de Ambari personalizada.
Las máquinas virtuales de la serie F están ahora disponibles con HDInsight
Las máquinas virtuales (VM) de la serie F son una buena opción para empezar a trabajar con HDInsight con requisitos de procesamiento ligeros. Con un precio de lista por hora inferior, la serie F tiene la mejor relación precio/rendimiento en la cartera de Azure en función de la unidad de Azure Compute (ACU) por vCPU. Para más información, consulte Selección del tamaño de VM correcto para el clúster de Azure HDInsight.
Desuso
Desuso de las máquinas virtuales de la serie G
A partir de esta versión, ya no están disponibles las máquinas virtuales de la serie G en HDInsight.
Desuso de la máquina virtual Dv1
A partir de esta versión, han quedado en desuso las máquinas virtuales Dv1 con HDInsight. Cuando los clientes soliciten máquinas virtuales Dv1, se servirán automáticamente máquinas virtuales Dv2. No hay diferencia de precio entre las máquinas virtuales Dv1 y Dv2.
Cambios de comportamiento
Cambio de tamaño del disco administrado del clúster
HDInsight proporciona espacio en disco administrado con el clúster. A partir de esta versión, el tamaño de disco administrado de cada nodo del nuevo clúster creado se cambia a 128 GB.
Próximos cambios
En las próximas versiones, se realizarán los siguientes cambios.
Movimiento a conjuntos de escalado de máquinas virtuales
Ahora HDInsight usa máquinas virtuales de Azure para aprovisionar el clúster. A partir de diciembre, HDInsight usará los conjuntos de escalado de máquinas virtuales de Azure en su lugar. Consulte más información sobre los conjuntos de escalado de máquinas virtuales de Azure.
HBase 2.0 a 2.1
En la próxima versión de HDInsight 4.0, la versión de HBase se actualizará de 2.0 a 2.1.
Desuso de las máquinas virtuales de la serie A para el clúster de ESP
Las máquinas virtuales de la serie A pueden provocar problemas en el clúster de ESP debido a su relativa poca capacidad de CPU y memoria. En la próxima versión, las máquinas virtuales de la serie A quedarán en desuso para crear nuevos clústeres de ESP.
Corrección de errores
HDInsight continúa realizando mejoras en la confiabilidad y el rendimiento del clúster.
Cambio de versión de componentes
No hay cambio de versión de los componentes para esta versión. Puede encontrar las versiones actuales de los componentes para HDInsight 4.0 y HDInsight 3.6 aquí.
Fecha de lanzamiento: 07/08/2019
Versiones de componentes
Las versiones oficiales de Apache de todos los componentes de HDInsight 4.0 se indican a continuación. Todos los componentes enumerados aquí son lanzamientos de las versiones estables más recientes disponibles.
- Apache Ambari 2.7.1
- Apache Hadoop 3.1.1
- Apache HBase 2.0.0
- Apache Hive 3.1.0
- Apache Kafka 1.1.1, 2.1.0
- Apache Mahout 0.9.0+
- Apache Oozie 4.2.0
- Apache Phoenix 4.7.0
- Apache Pig 0.16.0
- Apache Ranger 0.7.0
- Apache Slider 0.92.0
- Apache Spark 2.3.1, 2.4.0
- Apache Sqoop 1.4.7
- Apache TEZ 0.9.1
- Apache Zeppelin 0.8.0
- Apache ZooKeeper 3.4.6
A veces, se agrupan versiones posteriores de componentes de Apache en la distribución de HDP, además de las versiones indicadas anteriormente. En este caso, estas versiones posteriores se muestran en la tabla de versiones Technical Preview y no deben sustituir a las versiones de componentes de Apache de la lista anterior en un entorno de producción.
Información sobre la revisión de Apache
Para más información sobre las revisiones disponibles en HDInsight 4.0, consulte la lista de revisiones de cada producto en la tabla siguiente.
| Nombre de producto | Información sobre la revisión |
|---|---|
| Ambari | Información sobre la revisión de Ambari |
| Hadoop | Información sobre la revisión de Hadoop |
| HBase | Información sobre la revisión de HBase |
| Hive | En esta versión se proporciona Hive 3.1.0 sin ninguna revisión de Apache extra. |
| Kafka | En esta versión se proporciona Kafka 1.1.1 sin ninguna revisión de Apache extra. |
| Oozie | Información sobre la revisión de Oozie |
| Phoenix | Información sobre la revisión de Phoenix |
| Pig | Información sobre la revisión de Pig |
| Ranger | Información sobre la revisión de Ranger |
| Spark | Información sobre la revisión de Spark |
| Sqoop | En esta versión se proporciona Sqoop 1.4.7 sin ninguna revisión de Apache extra. |
| Tez | En esta versión se proporciona Tez 0.9.1 sin ninguna revisión de Apache extra. |
| Zeppelin | En esta versión se proporciona Zeppelin 0.8.0 sin ninguna revisión de Apache extra. |
| Zookeeper | Información sobre la revisión de Zookeeper |
Se han corregido las vulnerabilidades y exposiciones comunes
Para más información sobre los problemas de seguridad resueltos en esta versión, vea el documento de Hortonworks sobre las vulnerabilidades y exposiciones comunes resueltas en HDP 3.0.1.
Problemas conocidos
Replicación incompleta de HBase seguro con la instalación predeterminada
En HDInsight 4.0, realice los pasos siguientes:
Habilite la comunicación entre clústeres.
Inicie sesión en el nodo principal activo.
Descargue un script para habilitar la replicación con el siguiente comando:
sudo wget https://raw.githubusercontent.com/Azure/hbase-utils/master/replication/hdi_enable_replication.shEscriba el comando
sudo kinit <domainuser>.Escriba el siguiente comando para ejecutar el script:
sudo bash hdi_enable_replication.sh -m <hn*> -s <srclusterdns> -d <dstclusterdns> -sp <srcclusterpasswd> -dp <dstclusterpasswd> -copydata
Para HDInsight 3.6
Inicie sesión en HMaster ZK activo.
Descargue un script para habilitar la replicación con el siguiente comando:
sudo wget https://raw.githubusercontent.com/Azure/hbase-utils/master/replication/hdi_enable_replication.shEscriba el comando
sudo kinit -k -t /etc/security/keytabs/hbase.service.keytab hbase/<FQDN>@<DOMAIN>.Escriba el siguiente comando:
sudo bash hdi_enable_replication.sh -s <srclusterdns> -d <dstclusterdns> -sp <srcclusterpasswd> -dp <dstclusterpasswd> -copydata
Phoenix Sqlline deja de funcionar después de migrar el clúster de HBase a HDInsight 4.0
Siga estos pasos:
- Elimine las siguientes tablas de Phoenix:
SYSTEM.FUNCTIONSYSTEM.SEQUENCESYSTEM.STATSSYSTEM.MUTEXSYSTEM.CATALOG
- Si alguna de las tablas no se puede eliminar, reinicie HBase para borrar las conexiones a las tablas.
- Vuelva a ejecutar
sqlline.py. Phoenix volverá a crear todas las tablas que se eliminaron en el paso 1. - Vuelva a generar las tablas y vistas de Phoenix de los datos de HBase.
Phoenix Sqlline deja de funcionar después de la replicación de metadatos de HBase Phoenix de HDInsight 3.6 a 4.0
Siga estos pasos:
- Antes de realizar la replicación, vaya al clúster de 4.0 de destino y ejecute
sqlline.py. Este comando generará tablas de Phoenix comoSYSTEM.MUTEXySYSTEM.LOG, que solo existen en 4.0. - Elimine las tablas siguientes:
SYSTEM.FUNCTIONSYSTEM.SEQUENCESYSTEM.STATSSYSTEM.CATALOG
- Inicie la replicación de HBase.
Desuso
Apache Storm y los servicios de ML no están disponibles en HDInsight 4.0.
Fecha de lanzamiento: 14/04/2019
Nuevas características
Las nuevas actualizaciones y capacidades se dividen en las siguientes categorías:
Actualización de Hadoop y otros proyectos de código abierto: Además de los más de 1000 errores solucionados en más de 20 proyectos de código abierto, esta actualización contiene una versión nueva de Spark (2.3) y Kafka (1.0).
Actualización de R Server 9.1 a Machine Learning Services 9.3: Con esta versión, se proporciona a los científicos de datos y a los ingenieros lo mejor del código abierto, optimizado con innovaciones en los algoritmos y la facilidad de la operacionalización, todo ello disponible en el lenguaje que prefieran y con la velocidad de Apache Spark. Esta versión va más allá de las funcionalidades que se ofrecen en R Server, ya que añade compatibilidad con Python, lo que ha provocado el cambio del nombre del clúster de R Server a ML Services.
Compatibilidad con Azure Data Lake Storage Gen2: HDInsight admitirá la versión preliminar de Azure Data Lake Storage Gen2. En las regiones disponibles, los clientes podrán elegir una cuenta de ADLS Gen2 como almacén principal o secundario para sus clústeres de HDInsight.
Actualizaciones de HDInsight Enterprise Security Package: (versión preliminar) los puntos de conexión de servicio de red virtual admiten Azure Blob Storage, ADLS Gen1, Azure Cosmos DB y Azure DB.
Versiones de componentes
Las versiones oficiales de Apache de todos los componentes de HDInsight 3.6 se indican a continuación. Todos los componentes enumerados aquí son versiones oficiales de Apache de las versiones estables más recientes disponibles.
Apache Hadoop 2.7.3
Apache HBase 1.1.2
Apache Hive 1.2.1
Apache Hive 2.1.0
Apache Kafka 1.0.0
Apache Mahout 0.9.0+
Apache Oozie 4.2.0
Apache Phoenix 4.7.0
Apache Pig 0.16.0
Apache Ranger 0.7.0
Apache Slider 0.92.0
Apache Spark 2.2.0/2.3.0
Apache Sqoop 1.4.6
Apache Storm 1.1.0
Apache TEZ 0.7.0
Apache Zeppelin 0.7.3
Apache ZooKeeper 3.4.6
A veces, se agrupan versiones posteriores de algunos componentes de Apache en la distribución de HDP, además de las versiones indicadas anteriormente. En este caso, estas versiones posteriores se muestran en la tabla de versiones Technical Preview y no deben sustituir a las versiones de componentes de Apache de la lista anterior en un entorno de producción.
Información sobre la revisión de Apache
Hadoop
En esta versión se proporciona Hadoop Common 2.7.3 y las siguientes revisiones de Apache:
HADOOP 13190: mencionar LoadBalancingKMSClientProvider en la documentación de KMS HA.
HADOOP 13227: AsyncCallHandler debe usar una arquitectura basada en eventos para controlar las llamadas asincrónicas.
HADOOP 14104: el cliente debe pedir siempre el elemento namenode para la ruta de acceso del proveedor de KMS.
HADOOP 14799: actualizar nimbus-jose-jwt a 4.41.1.
HADOOP 14814: corregir el cambio incompatible de API en FsServerDefaults para HADOOP-14104.
HADOOP 14903: agregar explícitamente json-smart al archivo pom.xml.
HADOOP-15042: PageBlobInputStream.skip() de Azure puede devolver un valor negativo cuando numberOfPagesRemaining es 0.
HADOOP-15255: compatibilidad de conversión de mayúsculas y minúsculas para nombres de grupo en LdapGroupsMapping.
HADOOP-15265: excluir json-smart explícitamente de hadoop-auth pom.xml.
HDFS-7922: ShortCircuitCache#close no libera ScheduledThreadPoolExecutors.
HDFS-8496: llamar a stopWriter() con el bloqueo de FSDatasetImpl puede bloquear otros subprocesos (cmccabe).
HDFS-10267: "sincronizados" adicionales en FsDatasetImpl#recoverAppend y FsDatasetImpl#recoverClose.
HDFS 10489: dfs.encryption.key.provider.uri en desuso para las zonas de cifrado de HDFS.
HDFS 11384: agregar una opción para que el equilibrador disperse llamadas de getBlocks a fin de evitar la punta de rpc.CallQueueLength de NameNode.
HDFS-11689:
DFSClient%isHDFSEncryptionEnabledarrojó una nueva excepción que interrumpió el código de subárbolhacky.HDFS-11711: DN no debe eliminar el bloque cuando se emite la excepción "Demasiados archivos abiertos".
HDFS-12347: TestBalancerRPCDelay#testBalancerRPCDelay produce un error con frecuencia.
HDFS-12781: Después de que
Datanodeesté fuera de servicio, en la interfaz de usuario deNamenode, en la pestañaDatanodese arroja un mensaje de advertencia.HDFS-13054: Control de PathIsNotEmptyDirectoryException en la llamada de eliminación de
DFSClient.HDFS-13120: la diferencia de instantáneas podría estar dañada después de concat.
YARN-3742: YARN RM se apagará si la creación de
ZKClientagota el tiempo de espera.YARN 6061: agregar un elemento UncaughtExceptionHandler para subprocesos críticos en RM.
YARN-7558: el comando yarn logs no puede obtener los registros de los contenedores en ejecución si está habilitada la autenticación de la interfaz de usuario.
YARN-7697: se produce un error al capturar los registros de una aplicación finalizada, aunque la agregación al registro se haya completado.
HDP 2.6.4 proporcionaba Hadoop Common 2.7.3 y las siguientes revisiones de Apache:
HADOOP-13700: Quitar la excepción
IOExceptionno emitida de las firmas TrashPolicy#initialize y #getInstance.HADOOP 13709: capacidad de limpiar los subprocesos generados por el shell cuando finaliza el proceso.
HADOOP-14059: Mensaje de error tipográfico en
s3arename(self, subdir).HADOOP 14542: agregar IOUtils.cleanupWithLogger que acepta la API de registrador slf4j.
HDFS 9887: los tiempos de expiración de socket de WebHdfs deben ser configurables.
HDFS 9914: corregir el tiempo de expiración de conexión o lectura configurable de WebhDFS.
MAPREDUCE 6698: aumentar el tiempo de expiración en TestUnnecessaryBlockingOnHist oryFileInfo.testTwoThreadsQueryingDifferentJobOfSameUser.
YARN-4550: algunas pruebas de TestContainerLanch generan errores en un entorno de configuración regional distinto del inglés.
YARN 4717: TestResourceLocalizationService.testPublicResourceInitializesLocalDir genera errores intermitentemente debido a la excepción IllegalArgumentException de limpieza.
YARN 5042: montar /sys/fs/cgroup en contenedores de Docker como montaje de solo lectura.
YARN-5318: corregir el error intermitente de prueba de TestRMAdminService#te stRefreshNodesResourceWithFileSystemBasedConfigurationProvider.
YARN 5641: el localizador deja archivos de archivado tar una vez completado el contenedor.
YARN-6004: refactorizar TestResourceLocalizationService#testDownloadingResourcesOnContainer para que tenga menos de 150 líneas.
YARN 6078: los contenedores se atascaban en estado localizando.
YARN 6805: NPE en LinuxContainerExecutor debido a código de salida PrivilegedOperationException NULL.
HBase
En esta versión se proporciona HBase 1.1.2 y las siguientes revisiones de Apache.
HBASE 13376: mejoras en el equilibrador de la carga estocástico.
HBASE-13716: dejar de usar FSConstants de Hadoop.
HBASE-13848: acceder a las contraseñas de InfoServer SSL a través de la API del proveedor de credenciales.
HBASE 13947: usar MasterServices en lugar del servidor en AssignmentManager.
HBASE 14135: copia de seguridad y restauración de Backport Hbase 3: combinar las imágenes de copia de seguridad.
HBASE 14473: procesar localización de región en paralelo.
HBASE-14517: Mostrar versión de
regionserver'sen la página maestra de estado.HBASE 14606: las pruebas TestSecureLoadIncrementalHFiles agotaban el tiempo de espera en la compilación de tronco en Apache.
HBASE 15210: deshacer el registro agresivo del equilibrador de la carga en decenas de líneas por milisegundo.
HBASE 15515: mejorar LocalityBasedCandidateGenerator en el equilibrador.
HBASE-15615: Tiempo de suspensión erróneo cuando
RegionServerCallabledeba volver a intentar.HBASE-16135: nunca se debe eliminar PeerClusterZnode en rs de los quitados del mismo nivel.
HBASE 16570: procesar localización de región en paralelo en el inicio.
HBASE-16810: El equilibrador de HBase emite la excepción ArrayIndexOutOfBoundsException cuando los
regionserversse encuentran en /hbase/draining znode y descargados.HBASE 16852: error de TestDefaultCompactSelection en branch-1.3.
HBASE-17387: reducir la sobrecarga del informe de excepciones en RegionActionResult para multi().
HBASE 17850: utilidad de reparación del sistema de copia de seguridad.
HBASE 17931: asignar tablas del sistema a servidores con la versión más alta.
HBASE 18083: hacer que el número de subprocesos de limpieza de archivos grande o pequeño sea configurable en HFileCleaner.
HBASE-18084: mejorar CleanerChore para limpiar el directorio que consume más espacio en disco.
HBASE 18164: función de costo de localización mucho más rápida, así como el generador de candidatos.
HBASE-18212: en modo Independiente con el sistema de archivos local, HBase registra el mensaje de advertencia: No se ha podido invocar el método "unbuffer" en la clase org.apache.hadoop.fs.FSDataInputStream.
HBASE-18808: sincronización de la configuración ineficaz en BackupLogCleaner#getDeletableFiles().
HBASE-19052: FixedFileTrailer debería reconocer la clase CellComparatorImpl en branch-1.x.
HBASE-19065: HRegion#bulkLoadHFiles() debe esperar a que el elemento Region#flush() simultáneo finalice.
HBASE-19285: agregar histogramas de latencia por tabla.
HBASE-19393: Error HTTP 413 FULL head al tener acceso a la interfaz de usuario de HBase mediante SSL.
HBASE-19395: [branch-1] TestEndToEndSplitTransaction.testMasterOpsWhileSplitting produce un error con NPE.
HBASE-19421: branch-1 no se compila en Hadoop 3.0.0.
HBASE 19934: HBaseSnapshotException cuando las réplicas de lectura están habilitadas y se toma una instantánea en línea después de la división de la región.
HBASE-20008: [backport] NullPointerException al restaurar una instantánea después de la división de una región.
Hive
Esta versión proporciona Hive 1.2.1 y Hive 2.1.0, además de las revisiones siguientes:
Revisiones de Apache de Hive 1.2.1:
HIVE-10697: ObjectInspectorConvertors#UnionConvertor realiza una conversión defectuosa.
HIVE-11266: resultado incorrecto de count(*) en función de las estadísticas de tabla para tablas externas.
HIVE 12245: compatibilidad de comentarios de columna para una tabla de copia de seguridad de HBase.
HIVE-12315: corregir doble división entre cero vectorizada.
HIVE-12360: búsqueda incorrecta en ORC sin comprimir con aplicación de predicado.
HIVE 12378: excepción en el campo binario HBaseSerDe.serialize.
HIVE-12785: se interrumpe la vista con tipo de unión y UDF para la estructura.
HIVE-14013: la tabla de descripción no muestra Unicode correctamente.
HIVE-14205: Hive no es compatible con el tipo de unión con el formato de archivo AVRO.
HIVE-14421: FS.deleteOnExit contiene referencias a archivos _tmp_space.db.
HIVE-15563: Omitir excepción de transición de estado de operación no válida en SQLOperation.runQuery para exponer la excepción real.
HIVE-15680: resultados incorrectos cuando hive.optimize.index.filter=true y se hace referencia a la misma tabla ORC dos veces en la consulta, en modo MR.
HIVE 15883: error de decimal en inserción de tabla asignada de HBase en Hive.
HIVE-16232: compatibilidad de cálculo de estadísticas para columnas en QuotedIdentifier.
HIVE 16828: con CBO habilitado, la consulta en vistas con particiones emite la excepción IndexOutOfBoundException.
HIVE-17013: eliminar solicitud con una subconsulta basada en la selección en una vista.
HIVE-17063: error al insertar la partición de sobrescritura en una tabla externa cuando se coloca la partición primero.
HIVE 17259: JDBC de Hive no reconoce columnas UNIONTYPE.
HIVE-17419: el comando ANALYZE TABLE...COMPUTE STATISTICS FOR COLUMNS muestra estadísticas calculadas para tablas enmascaradas.
HIVE-17530: Excepción ClassCastException al convertir
uniontype.HIVE-17621: la configuración del sitio de Hive se omite durante el cálculo de división de HCatInputFormat.
HIVE-17636: Agregar prueba multiple_agg.q para
blobstores.HIVE-17729: agregar pruebas de BlobStore relacionadas con base de datos y explicación.
HIVE-17731: Agregar una opción
compatde compatibilidad con versiones anteriores para usuarios externos a HIVE-11985.HIVE-17803: con la consulta múltiple de Pig, 2 instancias de HCatStorer que escriban en la misma tabla se pisarán las salidas entre sí.
HIVE-17829: ArrayIndexOutOfBoundsException: tablas de copia de seguridad en HBASE con esquema de Avro en
Hive2.HIVE-17845: la inserción no funciona si las columnas de la tabla de destino no están en minúsculas.
HIVE-17900: las estadísticas de análisis en columnas desencadenadas por Compactor generan SQL con formato incorrecto con > 1 columna de partición.
HIVE-18026: optimización de la configuración de entidad de seguridad webhcat de Hive.
HIVE-18031: Compatibilidad de replicación para la operación de modificar base de datos.
HIVE-18090: el latido de ACID genera un error cuando Metastore se conecta a través de credenciales de Hadoop.
HIVE-18189: la consulta de Hive devuelve resultados incorrectos cuando hive.groupby.orderby.position.alias se establece en true.
HIVE-18258: Vectorización: se interrumpe el lado de reducción de GROUP BY MERGEPARTIAL con columnas duplicadas.
HIVE-18293: Hive no puede compactar tablas contenidas en una carpeta que no es propiedad de la identidad que ejecuta HiveMetaStore.
HIVE-18327: quitar la dependencia de HiveConf innecesaria para MiniHiveKdc.
HIVE-18341: agregar compatibilidad de carga de REPL para agregar espacios de nombres "sin procesar" para TDE con las mismas claves de cifrado.
HIVE-18352: introducir una opción METADATAONLY mientras se realiza REPL DUMP para permitir integraciones de otras herramientas.
HIVE-18353: CompactorMR debe llamar a jobclient.close() para desencadenar la limpieza.
HIVE-18390: IndexOutOfBoundsException cuando se consulta una vista con particiones en ColumnPruner.
HIVE-18429: la compactación debe controlar el caso que no genera ninguna salida.
HIVE-18447: JDBC: proporcionar una manera para que los usuarios de JDBC pasen información de cookies a través de la cadena de conexión.
HIVE-18460: Compactor no pasa las propiedades de tabla al escritor ORC.
HIVE-18467: compatibilidad del volcado de almacén completo, carga + creación, colocación de eventos de base de datos (Anishek Agarwal, revisado por Sankar Hariappan).
HIVE-18551: Vectorización: VectorMapOperator intenta escribir demasiadas columnas de vector para Hybrid Grace.
HIVE-18587: puede que la inserción de evento DML intente calcular una suma de comprobación en directorios.
HIVE-18613: extender JsonSerDe para que admita el tipo BINARY.
HIVE-18626: la cláusula "with" de carga de REPL no pasa configuración a las tareas.
HIVE-18660: PCR no distingue entre particiones y columnas virtuales.
HIVE-18754: REPL STATUS debe admitir la cláusula "with".
HIVE-18754: REPL STATUS debe admitir la cláusula "with".
HIVE-18788: limpiar las entradas en PreparedStatement de JDBC.
HIVE-18794: la cláusula "with" de carga de REPL no pasa configuración a las tareas para tablas sin particiones.
HIVE-18808: fortalecer compactación cuando se produce un error de actualización de estadísticas.
HIVE-18817: Excepción ArrayIndexOutOfBounds durante la lectura de la tabla ACID.
HIVE-18833: error al fusionar mediante combinación automática cuando se "inserta en el directorio como orcfile".
HIVE-18879: no permitir elemento incrustado en UDFXPathUtil debe funcionar si xercesImpl.jar está en classpath.
HIVE-18907: crear utilidad para corregir el problema de índice de clave ACID de HIVE-18817.
Revisiones de Apache de Hive 2.1.0:
HIVE-14013: la tabla de descripción no muestra Unicode correctamente.
HIVE-14205: Hive no es compatible con el tipo de unión con el formato de archivo AVRO.
HIVE-15563: Omitir excepción de transición de estado de operación no válida en SQLOperation.runQuery para exponer la excepción real.
HIVE-15680: resultados incorrectos cuando hive.optimize.index.filter=true y se hace referencia a la misma tabla ORC dos veces en la consulta, en modo MR.
HIVE 15883: error de decimal en inserción de tabla asignada de HBase en Hive.
HIVE-16757: quitar las llamadas a AbstractRelNode.getRows en desuso.
HIVE 16828: con CBO habilitado, la consulta en vistas con particiones emite la excepción IndexOutOfBoundException.
HIVE-17063: error al insertar la partición de sobrescritura en una tabla externa cuando se coloca la partición primero.
HIVE 17259: JDBC de Hive no reconoce columnas UNIONTYPE.
HIVE-17530: Excepción ClassCastException al convertir
uniontype.HIVE-17600: hacer que "enforceBufferSize" de OrcFile pueda establecerse por el usuario.
HIVE-17601: mejorar el control de errores en LlapServiceDriver.
HIVE-17613: quitar los grupos de objetos para asignaciones cortas del mismo subproceso.
HIVE-17617: la acumulación de un conjunto de resultados vacío debe contener la agrupación del conjunto de agrupaciones vacías.
HIVE-17621: la configuración del sitio de Hive se omite durante el cálculo de división de HCatInputFormat.
HIVE-17629: CachedStore: tener una configuración de elementos aprobados y no aprobados para permitir el almacenamiento en caché selectivo de tablas o particiones y permitir la lectura durante la preparación previa.
HIVE-17636: Agregar prueba multiple_agg.q para
blobstores.HIVE-17702: control incorrecto de isRepeating en el lector decimal en ORC.
HIVE-17729: agregar pruebas de BlobStore relacionadas con base de datos y explicación.
HIVE-17731: Agregar una opción
compatde compatibilidad con versiones anteriores para usuarios externos a HIVE-11985.HIVE-17803: con la consulta múltiple de Pig, 2 instancias de HCatStorer que escriban en la misma tabla se pisarán las salidas entre sí.
HIVE-17845: la inserción no funciona si las columnas de la tabla de destino no están en minúsculas.
HIVE-17900: las estadísticas de análisis en columnas desencadenadas por Compactor generan SQL con formato incorrecto con > 1 columna de partición.
HIVE-18006: optimizar la superficie de memoria de HLLDenseRegister.
HIVE-18026: optimización de la configuración de entidad de seguridad webhcat de Hive.
HIVE-18031: Compatibilidad de replicación para la operación de modificar base de datos.
HIVE-18090: el latido de ACID genera un error cuando Metastore se conecta a través de credenciales de Hadoop.
HIVE-18189: Ordenar por posición no funciona cuando
cboestá deshabilitado.HIVE-18258: Vectorización: se interrumpe el lado de reducción de GROUP BY MERGEPARTIAL con columnas duplicadas.
HIVE-18269: LLAP: las E/S rápidas de
llapcon canalización de procesamiento lenta pueden dar lugar a memoria insuficiente.HIVE-18293: Hive no puede compactar tablas contenidas en una carpeta que no es propiedad de la identidad que ejecuta HiveMetaStore.
HIVE-18318: el lector de registro LLAP debe comprobar la interrupción incluso cuando no se bloquea.
HIVE-18326: LLAP Tez Scheduler: solo tareas con prioridad si hay una dependencia entre ellas.
HIVE-18327: quitar la dependencia de HiveConf innecesaria para MiniHiveKdc.
HIVE-18331: agregar reinicio de sesión cuando TGT expire y algún registro/lambda.
HIVE-18341: agregar compatibilidad de carga de REPL para agregar espacios de nombres "sin procesar" para TDE con las mismas claves de cifrado.
HIVE-18352: introducir una opción METADATAONLY mientras se realiza REPL DUMP para permitir integraciones de otras herramientas.
HIVE-18353: CompactorMR debe llamar a jobclient.close() para desencadenar la limpieza.
HIVE-18384: ConcurrentModificationException en la biblioteca
log4j2.x.HIVE-18390: IndexOutOfBoundsException cuando se consulta una vista con particiones en ColumnPruner.
HIVE-18447: JDBC: proporcionar una manera para que los usuarios de JDBC pasen información de cookies a través de la cadena de conexión.
HIVE-18460: Compactor no pasa las propiedades de tabla al escritor ORC.
HIVE-18462: (explicar con formato para consultas con combinación de asignaciones contiene columnExprMap con nombre de columna sin formato).
HIVE-18467: compatibilidad de volcado de almacén completo, carga + creación y colocación de eventos de base de datos.
HIVE-18488: a los lectores ORC de LLAP les faltan comprobaciones NULL.
HIVE-18490: la consulta con EXISTS y NOT EXISTS con predicado no equivalente puede producir un resultado incorrecto.
HIVE-18506: LlapBaseInputFormat: índice de matriz negativa.
HIVE-18517: Vectorización: corregir VectorMapOperator para aceptar VRB y comprobar la marca vectorizada correctamente para admitir el almacenamiento en caché de LLAP.
HIVE-18523: corregir la fila de resumen en caso de que no haya entradas.
HIVE-18528: las estadísticas agregadas a ObjectStore obtienen un resultado incorrecto.
HIVE-18530: la replicación debe omitir la tabla MM (por ahora).
HIVE-18548: Corrección al importar
log4j.HIVE-18551: Vectorización: VectorMapOperator intenta escribir demasiadas columnas de vector para Hybrid Grace.
HIVE-18577: SemanticAnalyzer.validate tiene algunas llamadas de Metastore sin puntos.
HIVE-18587: puede que la inserción de evento DML intente calcular una suma de comprobación en directorios.
HIVE-18597: LLAP: Siempre empaquetar el archivo JAR de la API de
log4j2paraorg.apache.log4j.HIVE-18613: extender JsonSerDe para que admita el tipo BINARY.
HIVE-18626: la cláusula "with" de carga de REPL no pasa configuración a las tareas.
HIVE-18643: no comprobar si hay operaciones ACID en las particiones archivadas.
HIVE-18660: PCR no distingue entre particiones y columnas virtuales.
HIVE-18754: REPL STATUS debe admitir la cláusula "with".
HIVE-18788: limpiar las entradas en PreparedStatement de JDBC.
HIVE-18794: la cláusula "with" de carga de REPL no pasa configuración a las tareas para tablas sin particiones.
HIVE-18808: fortalecer compactación cuando se produce un error de actualización de estadísticas.
HIVE-18815: quitar función no usada en HPL/SQL.
HIVE-18817: Excepción ArrayIndexOutOfBounds durante la lectura de la tabla ACID.
HIVE-18833: error al fusionar mediante combinación automática cuando se "inserta en el directorio como orcfile".
HIVE-18879: no permitir elemento incrustado en UDFXPathUtil debe funcionar si xercesImpl.jar está en classpath.
HIVE-18944: la posición de los conjuntos de agrupación se establece incorrectamente durante DPP.
Kafka
En esta versión se proporciona Kafka 1.0.0 y las siguientes revisiones de Apache.
KAFKA-4827: conexión Kafka: error de caracteres especiales en el nombre del conector.
KAFKA-6118: error transitorio en kafka.api.SaslScramSslEndToEndAuthorizationTest.testTwoConsumersWithDifferentSaslCredentials.
KAFKA-6156: JmxReporter no puede controlar las rutas de acceso de directorio de estilo Windows.
KAFKA-6164: subprocesos ClientQuotaManager impiden el apagado cuando se encuentra un error al cargar registros.
KAFKA-6167: la marca de tiempo en el directorio de secuencias contiene un signo de dos puntos, que es un carácter no válido.
KAFKA-6179: RecordQueue.clear() no borra la lista mantenida de MinTimestampTracker.
KAFKA-6185: fuga de memoria del selector con alta probabilidad de falta de memoria en caso de conversión hacia abajo.
KAFKA-6190: GlobalKTable nunca termina de restaurar al consumir mensajes transaccionales.
KAFKA-6210: IllegalArgumentException si se usa 1.0.0 para inter.broker.protocol.version o log.message.format.version.
KAFKA-6214: el uso de réplicas en espera con un almacén con el estado en memoria causa el bloqueo de secuencias.
KAFKA 6215: KafkaStreamsTest genera un error en el tronco.
KAFKA-6238: problemas con la versión de protocolo al aplicar una actualización gradual a 1.0.0.
KAFKA-6260: AbstractCoordinator no controla claramente la excepción NULL.
KAFKA-6261: el registro de solicitud emite una excepción si acks=0.
KAFKA-6274: Mejorar nombres generados automáticamente del almacén de estados de origen de
KTable.
Mahout
En HDP-2.3.x y 2.4.x, en lugar de enviar una versión de Mahout específica de Apache, se sincroniza con un punto de revisión concreto en el tronco de Apache Mahout. Este punto de revisión es posterior a la versión 0.9.0, pero anterior a la versión 0.10.0. Proporciona un gran número de correcciones de errores y mejoras funcionales a través de la versión 0.9.0, pero proporciona una versión estable de la funcionalidad de Mahout antes de la conversión completa a la nueva instancia de Mahout basada en Spark en la versión 0.10.0.
El punto de revisión elegido para Mahout en HDP 2.3.x y 2.4.x es de la rama "mahout-0.10.x" de Apache Mahout, a partir del 19 de diciembre de 2014, revisión 0f037cb03e77c096 en GitHub.
En HDP-2.5.x y 2.6.x, se ha quitado la biblioteca "commons-httpclient" de Mahout porque se considera una biblioteca obsoleta con posibles problemas de seguridad y se actualiza el cliente de Hadoop en Mahout a la versión 2.7.3, la misma versión que se usa en HDP-2.5. Como resultado:
Los trabajos de Mahout compilados previamente tendrán que volver a compilarse en el entorno HDP-2.5 o 2.6.
Hay una pequeña posibilidad de que algunos trabajos de Mahout produzcan errores "ClassNotFoundException" o de "no se pudo cargar la clase" relacionados con "org.apache.commons.httpclient", "net.java.dev.jets3t" o los prefijos de nombre de la clase relacionada. Si se producen estos errores, puede considerar si se deben instalar manualmente los archivos JAR necesarios en la classpath para el trabajo, si el riesgo de problemas de seguridad en la biblioteca obsoleta es aceptable en su entorno.
Hay una posibilidad incluso menor de que en algunos trabajos de Mahout se produzcan bloqueos en las llamadas de código de cliente HBase a las bibliotecas comunes de Hadoop por problemas de compatibilidad binaria. Lamentablemente, no hay manera de resolver este problema, salvo que se revierta a la versión HDP-2.4.2 de Mahout, lo que puede provocar problemas de seguridad. Nuevamente, esto es poco común y no es probable que se produzca en cualquier conjunto de trabajos de Mahout determinado.
Oozie
En esta versión se proporciona Oozie 4.2.0 con las siguientes revisiones de Apache.
OOZIE-2571: agregar la propiedad de Maven spark.scala.binary.version para que se puede usar Scala 2.11.
OOZIE-2606: establecer spark.yarn.jars para corregir Spark 2.0 con Oozie.
OOZIE-2658: --driver-class-path puede sobrescribir classpath en SparkMain.
OOZIE-2787: Oozie distribuye el jar de aplicación dos veces, lo que provoca un error del trabajo de Spark.
OOZIE-2792: La acción de
Hive2no analiza correctamente el id. de aplicación de Spark del archivo de registro cuando Hive está en Spark.OOZIE-2799: configuración de la ubicación del registro para SQL de Spark en Hive.
OOZIE-2802: Error en la acción de Spark en Spark 2.1.0 debido a
sharelibsduplicados.OOZIE-2923: mejorar el análisis de opciones de Spark.
OOZIE-3109: SCA: Scripts entre sitios: Reflejado.
OOZIE-3139: Oozie valida el flujo de trabajo de forma incorrecta.
OOZIE-3167: actualizar la versión de Tomcat en la rama Oozie 4.3.
Phoenix
En esta versión se proporciona Phoenix 4.7.0 y las siguientes revisiones de Apache:
PHOENIX-1751: realizar agregaciones, ordenación, etc., en preScannerNext en lugar de postScannerOpen.
PHOENIX-2714: estimación correcta de bytes en BaseResultIterators y exponer como interfaz.
PHOENIX-2724: consultar con un gran número de indicadores es más lento en comparación a hacerlo sin estadísticas.
PHOENIX-2855: la solución alternativa de incrementar TimeRange no se serializa para HBase 1.2.
PHOENIX-3023: rendimiento lento cuando las consultas de límite se ejecutan en paralelo de forma predeterminada.
PHOENIX-3040: no usar indicadores para ejecutar las consultas en serie.
PHOENIX-3112: el análisis parcial de filas no se controla correctamente.
PHOENIX-3240: Excepción ClassCastException de cargador de Pig.
PHOENIX-3452: NULLS FIRST/NULL LAST no debe afectar si GROUP BY conserva el orden.
PHOENIX-3469: criterio de ordenación incorrecto para la clave principal DESC para NULLS LAST/NULLS FIRST.
PHOENIX-3789: ejecutar llamadas de mantenimiento del índice de región en postBatchMutateIndispensably.
PHOENIX-3865: IS NULL no devuelve resultados correctos cuando no se filtra con la primera familia de columnas.
PHOENIX-4290: se realiza el recorrido de tabla completo para DELETE cuando la tabla tiene índices inmutables.
PHOENIX-4373: la clave de longitud variable de índice local puede tener valores NULL finales al realizar operaciones upsert.
PHOENIX-4466: java.lang.RuntimeException: código de respuesta 500: ejecutando un trabajo de Spark para conectar con el servidor de consultas Phoenix y datos de carga.
PHOENIX-4489: pérdida de conexión de HBase en trabajos MR de Phoenix.
PHOENIX-4525: desbordamiento de enteros en la ejecución de GroupBy.
PHOENIX-4560: ORDER BY con GROUP BY no funciona si está presente WHERE en la columna de
pk.PHOENIX-4586: UPSERT SELECT no tiene en cuenta los operadores de comparación para las subconsultas.
PHOENIX-4588: clonar expresión también si sus elementos secundarios contienen Determinism.PER_INVOCATION.
Pig
En esta versión se proporciona Pig 0.16.0 con las siguientes revisiones de Apache.
Ranger
En esta versión se proporciona Ranger 0.7.0 y las siguientes revisiones de Apache:
RANGER-1805: mejora de código para seguir los procedimientos recomendados en js.
RANGER-1960: tomar en consideración el nombre de tabla de la instantánea para su eliminación.
RANGER-1982: error de la mejora para Analytics Metric de Ranger Admin y Ranger KMS.
RANGER-1984: las entradas de registro de auditoría de HBase pueden no mostrar todas las etiquetas asociadas con la columna a la que se accede.
RANGER-1988: corregir aleatoriedad insegura.
RANGER-1990: agregar compatibilidad con SSL MySQL unidireccional en Ranger Admin.
RANGER-2006: Solucionar los problemas detectados por el análisis de código estático en el rango
usersyncpara el origen de sincronización deldap.RANGER-2008: La evaluación de directiva produce errores para condiciones de directiva de varias líneas.
Control deslizante
En esta versión se proporciona Slider 0.92.0 sin ninguna revisión de Apache extra.
Spark
En esta versión se proporciona Spark 2.3.0 y las siguientes revisiones de Apache:
SPARK-13587: compatibilidad de virtualenv en pyspark.
SPARK-19964: evitar la lectura de repositorios remotos en SparkSubmitSuite.
SPARK-22882: prueba de ML para el streaming estructurado: ml.classification.
SPARK-22915: pruebas de streaming para spark.ml.feature, de la N a la Z.
SPARK-23020: corregir otra carrera en la prueba del iniciador en proceso.
SPARK-23040: devuelve el iterador interrumpible para el lector de orden aleatorio.
SPARK-23173: evitar la creación de archivos Parquet dañados al cargar datos de JSON.
SPARK-23264: corregir scala.MatchError en literals.sql.out.
SPARK-23288: corregir las métricas de salida con el receptor de Parquet.
SPARK-23329: corregir la documentación de funciones trigonométricas.
SPARK-23406: habilitar autocombinaciones de secuencia a secuencia para branch-2.3.
SPARK-23434: Spark no debería advertir al "directorio de metadatos" de una ruta de acceso de archivo HDFS.
SPARK-23436: inferir la partición como fecha solo si se puede convertir a fecha.
SPARK-23457: registrar los agentes de escucha de finalización de tarea en primer lugar en ParquetFileFormat.
SPARK-23462: mejorar el mensaje de error de campo que falta en "StructType".
SPARK-23490: comprobar storage.locationUri con la tabla existente en CreateTable.
SPARK-23524: no se debe comprobar la corrupción de los bloques grandes de orden aleatorio locales.
SPARK-23525: compatibilidad de ALTER TABLE CHANGE COLUMN COMMENT para tabla externa de Hive.
SPARK-23553: las pruebas no deben presuponer el valor predeterminado de "spark.sql.sources.default".
SPARK-23569: permitir pandas_udf para trabajar con funciones de tipo anotado de estilo python3.
SPARK-23570: agregar Spark 2.3.0 en HiveExternalCatalogVersionsSuite.
SPARK-23598: hacer que los métodos en BufferedRowIterator sean públicos para evitar errores en tiempo de ejecución para una consulta de gran tamaño.
SPARK-23599: agregar un generador de UUID de números pseudoaleatorios.
SPARK-23599: usar RandomUUIDGenerator la expresión Uuid.
SPARK-23601: Quitar archivos
.md5de la versión.SPARK-23608: agregar sincronización en SHS entre las funciones attachSparkUI y detachSparkUI para evitar el problema de modificación simultánea a los controladores de Jetty.
SPARK-23614: corregir el intercambio de reutilización incorrecto cuando se usa el almacenamiento en caché.
SPARK-23623: evitar el uso simultáneo de consumidores en caché en CachedKafkaConsumer (branch-2.3).
SPARK-23624: revisar documento del método pushFilters en Datasource V2.
SPARK-23628: calculateParamLength no debe devolver 1 + número de expresiones.
SPARK-23630: permitir que las personalizaciones de configuración de Hadoop del usuario surtan efecto.
SPARK-23635: la variable env del ejecutor de Spark se sobrescribe por la misma variable env de AM de nombre.
SPARK-23637: Yarn podría asignar más recursos si un mismo ejecutor se termina varias veces.
SPARK-23639: obtener el token antes que el cliente Metastore de init en la CLI de SparkSQL.
SPARK-23642: Corrección de la subclase de AccumulatorV2 isZero
scaladoc.SPARK-23644: usar ruta de acceso absoluta para la llamada de REST en SHS.
SPARK-23645: agregar documentos RE "pandas_udf" con argumentos de palabra clave.
SPARK-23649: la omisión de caracteres no se permite en UTF-8.
SPARK-23658: InProcessAppHandle usa una clase incorrecta en getLogger.
SPARK-23660: corregir excepción en modo de clúster de Yarn cuando la aplicación finaliza rápidamente.
SPARK-23670: corregir fuga de memoria en SparkPlanGraphWrapper.
SPARK-23671: corregir condición para habilitar el grupo de subprocesos SHS.
SPARK-23691: usar la utilidad sql_conf en pruebas de PySpark siempre que sea posible.
SPARK-23695: corregir el mensaje de error para pruebas de streaming de Kinesis.
SPARK-23706: spark.conf.get(value, default=None) debería producir None en PySpark.
SPARK 23728: corregir pruebas ML con excepciones esperadas al ejecutar pruebas de streaming.
SPARK 23729: respetar fragmento de URI al resolver globs.
SPARK 23759: no se puede enlazar la interfaz de usuario de Spark al nombre de host o IP específico.
SPARK 23760: CodegenContext.withSubExprEliminationExprs debe guardar o restaurar el estado CSE correctamente.
SPARK-23769: Quitar los comentarios que deshabilitan innecesariamente la comprobación de
Scalastyle.SPARK 23788: corregir la carrera en StreamingQuerySuite.
SPARK 23802: PropagateEmptyRelation puede dejar el plan de consulta en estado sin resolver.
SPARK 23806: Broadcast.unpersist puede provocar una excepción grave cuando se usa con una asignación dinámica.
SPARK 23808: establecer la sesión de Spark predeterminada en las sesiones de Spark solo para pruebas.
SPARK 23809: getOrCreate debe establecer la SparkSession activa.
SPARK 23816: las tareas terminadas deben omitir FetchFailures.
SPARK 23822: mejorar el mensaje de error para discrepancias de esquema de Parquet.
SPARK 23823: mantener el origen en transformExpression.
SPARK 23827: StreamingJoinExec debe garantizar que los datos de entrada se dividan en un número específico de particiones.
SPARK 23838: la consulta SQL en ejecución se muestra como "completada" en la pestaña SQL.
SPARK 23881: corregir prueba no confiable JobCancellationSuite."interruptible iterator of shuffle reader".
Sqoop
En esta versión se proporciona Sqoop 1.4.6 sin ninguna revisión de Apache extra.
Storm
En esta versión se proporciona Storm 1.1.1 y las siguientes revisiones de Apache:
STORM-2652: excepción emitida en el método abierto JmsSpout.
STORM-2841: testNoAcksIfFlushFails UT produce un error con NullPointerException.
STORM-2854: exponer IEventLogger para permitir la conexión al registro de eventos.
STORM-2870: FileBasedEventLogger pierde ExecutorService no de daemon, lo que impide que el proceso termine.
STORM 2960: mejor enfatizar la importancia de la configuración de la cuenta de sistema operativo adecuado para los procesos de Storm.
Tez
En esta versión se proporciona Tez 0.7.0 y las siguientes revisiones de Apache:
- TEZ-1526: LoadingCache para TezTaskID lento para trabajos de gran tamaño.
Zeppelin
En esta versión se proporciona Zeppelin 0.7.3 sin ninguna revisión de Apache extra.
ZEPPELIN-3072: la interfaz de usuario de Zeppelin se lentifica o no responde si hay demasiados notebooks.
ZEPPELIN-3129: la interfaz de usuario de Zeppelin no cierra sesión en Internet Explorer.
ZEPPELIN-903: Reemplazar CXF por
Jersey2.
ZooKeeper
En esta versión se proporciona ZooKeeper 3.4.6 y las siguientes revisiones de Apache:
ZOOKEEPER 1256: ClientPortBindTest no funciona en macOS X.
ZOOKEEPER-1901: [JDK8] ordenar los elementos secundarios para la comparación en pruebas AsyncOps.
ZOOKEEPER 2423: actualizar versión de Netty debido a la vulnerabilidad de seguridad (CVE-2014-3488).
ZOOKEEPER 2693: ataque DOS con palabras de cuatro letras (4lw) en wchp/wchc.
ZOOKEEPER-2726: La revisión introduce una condición de carrera potencial.
Se han corregido las vulnerabilidades y exposiciones comunes
Esta sección abarca todas las vulnerabilidades y exposiciones (CVE) comunes que se solucionan en esta versión.
CVE-2017-7676
| Resumen: La evaluación de directivas de Apache Ranger omite los caracteres después del carácter comodín "*" |
|---|
| Gravedad: Crítico |
| Proveedor: Hortonworks |
| Versiones afectadas: versiones de HDInsight 3.6, incluidas las versiones 0.5.x/0.6.x/0.7.0 de Apache Ranger |
| Usuarios afectados: entornos que usan directivas de Ranger con caracteres después del carácter comodín "*", como *test, test*.txt |
| Impacto: el buscador de coincidencias de recursos de directiva omite los caracteres después del carácter comodín "*", lo que puede provocar un comportamiento imprevisto. |
| Detalle de la corrección: el buscador de coincidencias de recursos de directiva de Ranger se actualizó para controlar correctamente las coincidencias con caracteres comodín. |
| Acción recomendada: actualizar a HDI 3.6 (con Apache Ranger 0.7.1 o posterior). |
CVE-2017-7677
| Resumen: el autorizador de Apache Ranger Hive debe comprobar el permiso RWX cuando se especifica una ubicación externa |
|---|
| Gravedad: Crítico |
| Proveedor: Hortonworks |
| Versiones afectadas: versiones de HDInsight 3.6, incluidas las versiones 0.5.x/0.6.x/0.7.0 de Apache Ranger |
| Usuarios afectados: entornos que usan una ubicación externa para las tablas de Hive |
| Impacto: en entornos que usan una ubicación externa para las tablas de Hive, el autorizador de Apache Ranger Hive debe comprobar el permiso RWX para la ubicación externa especificada para crear una tabla. |
| Detalle de la corrección: el autorizador de Hive de Ranger se actualizó para controlar correctamente la comprobación de permisos para la ubicación externa. |
| Acción recomendada: los usuarios deben actualizar a HDI 3.6 (con Apache Ranger 0.7.1 o posterior). |
CVE-2017-9799
| Resumen: posible ejecución de código como usuario incorrecto en Apache Storm |
|---|
| Gravedad: Importante |
| Proveedor: Hortonworks |
| Versiones afectadas: HDP 2.4.0, HDP-2.5.0, HDP-2.6.0 |
| Usuarios afectados: usuarios que usan Storm en modo seguro y BlobStore para distribuir topología en función de los artefactos o usan BlobStore para distribuir recursos de topología. |
| Impacto: en algunas situaciones y configuraciones de Storm es teóricamente posible que el propietario de una topología engañe al supervisor para iniciar un trabajo como otro usuario no raíz. En el peor de los casos, esto podría provocar que las credenciales seguras del otro usuario se vieran comprometidas. Esta vulnerabilidad solo se aplica a las instalaciones de Apache Storm con seguridad habilitada. |
| Mitigación: actualizar a HDP-2.6.2.1 ya que actualmente no hay soluciones alternativas. |
CVE-2016-4970
| Resumen: handler/ssl/OpenSslEngine.java en Netty 4.0.x antes de la versión 4.0.37. Final y 4.1.x antes de 4.1.1. La versión final permite a los atacantes remotos generar una denegación del servicio (bucle infinito) |
|---|
| Gravedad: Moderado |
| Proveedor: Hortonworks |
| Versiones afectadas: HDP 2.x.x desde 2.3.x |
| Usuarios afectados: todos los usuarios que usan HDFS. |
| Impacto: el impacto es bajo ya que Hortonworks no usa OpenSslEngine.java directamente en el código base de Hadoop. |
| Acción recomendada: actualizar a HDP 2.6.3. |
CVE-2016-8746
| Resumen: problema al buscar coincidencias de rutas de acceso de Apache Ranger en la evaluación de directivas |
|---|
| Gravedad: Normal |
| Proveedor: Hortonworks |
| Versiones afectadas: todas las versiones de HDP 2.5, incluidas las versiones 0.6.0/0.6.1/0.6.2 de Apache Ranger |
| Usuarios afectados: todos los usuarios de la herramienta de administración de directivas de Ranger. |
| Impacto: el motor de directivas de Ranger encuentra coincidencias incorrectas de las rutas de acceso en determinadas condiciones cuando una directiva contiene comodines y marcas recursivas. |
| Detalle de la corrección: se ha corregido la lógica de evaluación de directivas |
| Acción recomendada: los usuarios deben actualizar a HDP 2.5.4 o posterior (con Apache Ranger 0.6.3 o posterior ) o HDP 2.6 o posterior (con Apache Ranger 0.7.0 o posterior ) |
CVE-2016-8751
| Resumen: problema de scripting almacenado entre sitios de Apache Ranger |
|---|
| Gravedad: Normal |
| Proveedor: Hortonworks |
| Versiones afectadas: todas las versiones 2.3/2.4/2.5 de HDP, incluidas las versiones 0.5.x/0.6.0/0.6.1/0.6.2 de Apache Ranger |
| Usuarios afectados: todos los usuarios de la herramienta de administración de directivas de Ranger. |
| Impacto: Apache Ranger es vulnerable a scripting almacenado entre sitios al escribir condiciones de directivas personalizadas. Los usuarios administradores pueden almacenar parte de código JavaScript arbitrario que se ejecuta cuando los usuarios habituales inician sesión y las directivas de acceso. |
| Detalle de la corrección: se ha agregado lógica para sanear la entrada del usuario. |
| Acción recomendada: los usuarios deben actualizar a HDP 2.5.4 o posterior (con Apache Ranger 0.6.3 o posterior ) o HDP 2.6 o posterior (con Apache Ranger 0.7.0 o posterior ) |
Se han corregido problemas de soporte técnico
Los problemas corregidos representan problemas seleccionados que se registraron anteriormente a través del soporte técnico de Hortonworks, pero ahora se tratan en la versión actual. Estos problemas se han notificado en versiones anteriores dentro de la sección de problemas conocidos; lo que significa que se han notificado por clientes o se han identificado por el equipo de ingeniería de calidad de Hortonworks.
Resultados incorrectos
| Id. del error | JIRA de Apache | Resumen |
|---|---|---|
| BUG-100019 | YARN-8145 | yarn rmadmin - getGroups no devuelve grupos actualizados de usuario. |
| BUG-100058 | PHOENIX-2645 | Los caracteres comodín no coinciden con los caracteres de nueva línea. |
| BUG-100266 | PHOENIX-3521, PHOENIX-4190 | Resultados incorrectos con índices locales. |
| BUG-88774 | HIVE-17617, HIVE-18413, HIVE-18523 | error de query36, no coincidencia de recuento de filas |
| BUG-89765 | HIVE-17702 | Control incorrecto de isRepeating en el lector decimal en ORC. |
| BUG-92293 | HADOOP-15042 | PageBlobInputStream.skip() de Azure puede devolver un valor negativo cuando numberOfPagesRemaining es 0. |
| BUG-92345 | ATLAS-2285 | Interfaz de usuario: se ha cambiado el nombre de la búsqueda guardada con el atributo de fecha. |
| BUG-92563 | HIVE-17495, HIVE-18528 | Las estadísticas agregadas a ObjectStore obtienen un resultado incorrecto. |
| BUG-92957 | HIVE-11266 | Resultado incorrecto de count(*) en función de las estadísticas de tabla para tablas externas |
| BUG-93097 | RANGER-1944 | El filtro de acción para la auditoría de administrador no funciona. |
| BUG-93335 | HIVE-12315 | vectorization_short_regress.q tiene un problema de resultado incorrecto para un cálculo doble |
| BUG-93415 | HIVE-18258, HIVE-18310 | Vectorización: se interrumpe el lado de reducción de GROUP BY MERGEPARTIAL con columnas duplicadas. |
| BUG-93939 | ATLAS-2294 | Se agregó un parámetro "description" adicional al crear un tipo. |
| BUG-94007 | PHOENIX-1751, PHOENIX-3112 | Las consultas de Phoenix devuelven valores NULL debido a filas parciales de HBase |
| BUG-94266 | HIVE-12505 | Insertar sobrescritura en la misma zona de cifrado en modo silencioso no puede quitar algunos archivos existentes. |
| BUG-94414 | HIVE-15680 | Resultados incorrectos cuando hive.optimize.index.filter=true y se hace referencia a la misma tabla ORC dos veces en la consulta. |
| BUG-95048 | HIVE-18490 | La consulta con EXISTS y NOT EXISTS con predicado no equivalente puede producir un resultado incorrecto. |
| BUG-95053 | PHOENIX-3865 | IS NULL no devuelve resultados correctos cuando no se filtra con la primera familia de columnas. |
| BUG-95476 | RANGER-1966 | La inicialización del motor de directiva no crea enriquecedores de contexto en algunos casos. |
| BUG-95566 | SPARK-23281 | La consulta genera resultados en orden incorrecto cuando una cláusula order by compuesta hace referencia a columnas originales y los alias. |
| BUG-95907 | PHOENIX-3451, PHOENIX-3452, PHOENIX-3469, PHOENIX-4560 | Solución de problemas con ORDER BY ASC cuando la consulta contiene agregación. |
| BUG-96389 | PHOENIX-4586 | UPSERT SELECT no tiene en cuenta los operadores de comparación para las subconsultas. |
| BUG-96602 | HIVE-18660 | PCR no distingue entre particiones y columnas virtuales. |
| BUG-97686 | ATLAS-2468 | Problema de la [búsqueda básica] con casos OR cuando se usa NEQ con tipos numéricos |
| BUG-97708 | HIVE-18817 | Excepción ArrayIndexOutOfBounds durante la lectura de la tabla ACID. |
| BUG-97864 | HIVE-18833 | Error al fusionar mediante combinación automática cuando se "inserta en el directorio como orcfile". |
| BUG-97889 | RANGER-2008 | La evaluación de directiva produce errores para condiciones de directiva de varias líneas. |
| BUG-98655 | RANGER-2066 | Una columna con etiquetas en la familia de columnas autoriza el acceso a la familia de columnas de HBase. |
| BUG-99883 | HIVE-19073, HIVE-19145 | StatsOptimizer puede alterar columnas de constantes |
Otros
| Id. del error | JIRA de Apache | Resumen |
|---|---|---|
| BUG-100267 | HBASE-17170 | HBase también reintenta DoNotRetryIOException debido a diferencias del cargador de clases. |
| BUG-92367 | YARN-7558 | El comando "yarn logs" no puede obtener los registros de los contenedores en ejecución si está habilitada la autenticación de la interfaz de usuario. |
| BUG-93159 | OOZIE-3139 | Oozie valida el flujo de trabajo de forma incorrecta. |
| BUG-93936 | ATLAS-2289 | Código de inicio y detención de servidor incrustado Kafka/Zookeeper que se debe sacar fuera de la implementación de KafkaNotification. |
| BUG-93942 | ATLAS-2312 | Use objetos ThreadLocal DateFormat para evitar el uso simultáneo de varios subprocesos. |
| BUG-93946 | ATLAS-2319 | Interfaz de usuario: la eliminación de una etiqueta en la posición 25 o superior de la lista de etiquetas tanto de la estructura plana como de árbol necesita una actualización para quitar la etiqueta de la lista. |
| BUG-94618 | YARN-5037, YARN-7274 | Capacidad de deshabilitar la elasticidad en el nivel de cola de hojas |
| BUG-94901 | HBASE-19285 | Agregar histogramas de latencia por tabla. |
| BUG-95259 | HADOOP-15185, HADOOP-15186 | Actualizar el conector de adls para que use la versión actual del SDK de ADLS |
| BUG-95619 | HIVE-18551 | Vectorización: VectorMapOperator intenta escribir demasiadas columnas de vector para Hybrid Grace. |
| BUG-97223 | SPARK-23434 | Spark no debería advertir al "directorio de metadatos" de una ruta de acceso de archivo HDFS |
Rendimiento
| Id. del error | JIRA de Apache | Resumen |
|---|---|---|
| BUG-83282 | HBASE-13376, HBASE-14473, HBASE-15210, HBASE-15515, HBASE-16570, HBASE-16810, HBASE-18164 | Cálculo de localización rápido en el equilibrador. |
| BUG-91300 | HBASE-17387 | Reducir la sobrecarga del informe de excepciones en RegionActionResult para multi(). |
| BUG-91804 | TEZ-1526 | LoadingCache para TezTaskID lento para trabajos de gran tamaño. |
| BUG-92760 | ACCUMULO-4578 | Cancelar compactación de operación FATE no libera el bloqueo del espacio de nombres. |
| BUG-93577 | RANGER-1938 | Solr para la configuración de auditoría no usa DocValues eficazmente. |
| BUG-93910 | HIVE-18293 | Hive no puede compactar tablas contenidas en una carpeta que no es propiedad de la identidad que ejecuta HiveMetaStore. |
| BUG-94345 | HIVE-18429 | La compactación debe controlar el caso que no genera ninguna salida. |
| BUG-94381 | HADOOP-13227, HDFS-13054 | Control de la orden RequestHedgingProxyProvider RetryAction: FAIL < RETRY < FAILOVER_AND_RETRY. |
| BUG-94432 | HIVE-18353 | CompactorMR debe llamar a jobclient.close() para desencadenar la limpieza. |
| BUG-94869 | PHOENIX-4290, PHOENIX-4373 | Fila solicitada fuera del intervalo para Get en HRegion de tabla local Phoenix indexada con sal. |
| BUG-94928 | HDFS-11078 | Corregir NPE en LazyPersistFileScrubber. |
| BUG-94964 | HIVE-18269, HIVE-18318, HIVE-18326 | Varias correcciones LLAP |
| BUG-95669 | HIVE-18577, HIVE-18643 | Cuando se ejecuta una consulta de actualizar o eliminar en una tabla de particiones de ACID, HS2 lee cada partición. |
| BUG-96390 | HDFS-10453 | El subproceso ReplicationMonitor podría bloquearse durante un largo periodo de tiempo debido a la carrera entre la replicación y la eliminación del mismo archivo en un clúster grande. |
| BUG-96625 | HIVE-16110 | Reversión de "Vectorización: compatibilidad del valor 2 CASE WHEN en lugar de retroceder a VectorUDFAdaptor" |
| BUG-97109 | HIVE-16757 | El uso de getRows() en desuso en lugar del nuevo estimateRowCount(RelMetadataQuery...) tiene consecuencias graves de rendimiento. |
| BUG-97110 | PHOENIX-3789 | Ejecutar llamadas de mantenimiento del índice de región en postBatchMutateIndispensably. |
| BUG-98833 | YARN-6797 | TimelineWriter no consume totalmente la respuesta POST. |
| BUG-98931 | ATLAS-2491 | Actualizar el enlace de Hive para usar notificaciones de Atlas v2. |
Posible pérdida de datos
| Id. del error | JIRA de Apache | Resumen |
|---|---|---|
| BUG-95613 | HBASE-18808 | Comprobación de la configuración ineficaz en BackupLogCleaner#getDeletableFiles() |
| BUG-97051 | HIVE-17403 | Concatenación con error de tablas transaccionales y no administrados. |
| BUG-97787 | HIVE-18460 | Compactor no pasa las propiedades de tabla al escritor ORC. |
| BUG-97788 | HIVE-18613 | Extender JsonSerDe para que admita el tipo BINARY. |
Error de consulta
| Id. del error | JIRA de Apache | Resumen |
|---|---|---|
| BUG-100180 | CALCITE-2232 | Error de aserción en AggregatePullUpConstantsRule al ajustar los índices de agregado. |
| BUG-100422 | HIVE-19085 | FastHiveDecimal abs(0) establece el signo en +ve |
| BUG-100834 | PHOENIX-4658 | IllegalStateException: requestSeek no puede llamarse en ReversedKeyValueHeap. |
| BUG-102078 | HIVE-17978 | Las consultas 58 y 83 de TPCDS generan excepciones en la vectorización. |
| BUG-92483 | HIVE-17900 | Las estadísticas de análisis en columnas desencadenadas por Compactor generan SQL con formato incorrecto con > 1 columna de partición. |
| BUG-93135 | HIVE-15874, HIVE-18189 | La consulta de Hive devuelve resultados incorrectos cuando hive.groupby.orderby.position.alias se establece en true. |
| BUG-93136 | HIVE-18189 | Ordenar por posición no funciona cuando cbo está deshabilitado |
| BUG-93595 | HIVE-12378, HIVE-15883 | Error de decimal y columnas binarias en la inserción de tabla asignada de HBase en Hive. |
| BUG-94007 | PHOENIX-1751, PHOENIX-3112 | Las consultas de Phoenix devuelven valores NULL debido a filas parciales de HBase |
| BUG-94144 | HIVE-17063 | error al insertar partición de sobrescritura en una tabla externa cuando se coloca la partición primero |
| BUG-94280 | HIVE-12785 | Se interrumpe la vista con tipo de unión y UDF para "convertir" la estructura |
| BUG-94505 | PHOENIX-4525 | Desbordamiento de enteros en la ejecución de GroupBy. |
| BUG-95618 | HIVE-18506 | LlapBaseInputFormat: índice de matriz negativa. |
| BUG-95644 | HIVE-9152 | CombineHiveInputFormat: error en la consulta de Hive en Tez con la excepción java.lang.IllegalArgumentException. |
| BUG-96762 | PHOENIX-4588 | Clonar expresión también si sus elementos secundarios contienen Determinism.PER_INVOCATION |
| BUG-97145 | HIVE-12245, HIVE-17829 | Compatibilidad de comentarios de columna para una tabla de copia de seguridad de HBase. |
| BUG-97741 | HIVE-18944 | La posición de los conjuntos de agrupación se establece incorrectamente durante DPP |
| BUG-98082 | HIVE-18597 | LLAP: Siempre empaquetar el archivo JAR de la API de log4j2 para org.apache.log4j |
| BUG-99849 | N/D | La creación de una nueva tabla desde un asistente de archivos intenta usar la base de datos predeterminada. |
Seguridad
| Id. del error | JIRA de Apache | Resumen |
|---|---|---|
| BUG-100436 | RANGER-2060 | El proxy de Knox con knox-sso no funciona para Ranger |
| BUG-101038 | SPARK-24062 | Error "Conexión rechazada" del intérprete %Spark de Zeppelin, "Debe especificarse un secreto..." en HiveThriftServer. |
| BUG-101359 | ACCUMULO-4056 | Actualizar versión de commons-collection a 3.2.2 en la publicación. |
| BUG-54240 | HIVE-18879 | No permitir elemento incrustado en UDFXPathUtil debe funcionar si xercesImpl.jar está en classpath. |
| BUG-79059 | OOZIE-3109 | Caracteres de escape específicos de HTML de streaming de registro |
| BUG-90041 | OOZIE-2723 | La licencia de JSON.org ahora es CatX. |
| BUG-93754 | RANGER-1943 | La autorización de Ranger Solr se omite cuando la colección está vacía o es NULL. |
| BUG-93804 | HIVE-17419 | El comando ANALYZE TABLE...COMPUTE STATISTICS FOR COLUMNS muestra estadísticas calculadas para tablas enmascaradas. |
| BUG-94276 | ZEPPELIN-3129 | La interfaz de usuario de Zeppelin no cierra sesión en Internet Explorer |
| BUG-95349 | ZOOKEEPER-1256, ZOOKEEPER-1901 | Actualización de netty |
| BUG-95483 | N/D | Corrección de CVE-2017-15713 |
| BUG-95646 | OOZIE-3167 | Actualizar la versión de Tomcat en la rama Oozie 4.3. |
| BUG-95823 | N/D |
Knox: Actualizar Beanutils |
| BUG-95908 | RANGER-1960 | La autenticación de HBase no tiene en cuenta el espacio de nombres de tabla para la eliminación de instantánea. |
| BUG-96191 | FALCON-2322, FALCON-2323 | Actualizar las versiones Jackson y Spring para evitar vulnerabilidades de seguridad. |
| BUG-96502 | RANGER-1990 | Agregar compatibilidad con SSL MySQL unidireccional en Ranger Admin. |
| BUG-96712 | FLUME-3194 | Actualizar Derby a la versión más reciente (1.14.1.0). |
| BUG-96713 | FLUME-2678 | Actualizar Xalan a 2.7.2 para que se haga cargo de la vulnerabilidad CVE-2014-0107. |
| BUG-96714 | FLUME-2050 | Actualizar a log4j2 (cuando sea de disponibilidad general) |
| BUG-96737 | N/D | Utilice métodos del sistema de archivos de E/S de Java para tener acceso a archivos locales |
| BUG-96925 | N/D | Actualizar Tomcat de 6.0.48 a 6.0.53 en Hadoop. |
| BUG-96977 | FLUME-3132 | Actualizar las dependencias de biblioteca jasper de Tomcat |
| BUG-97022 | HADOOP-14799, HADOOP-14903, HADOOP-15265 | Actualizar biblioteca Nimbus-JOSE-JWT con una versión superior a 4.39. |
| BUG-97101 | RANGER-1988 | Corregir aleatoriedad insegura. |
| BUG-97178 | ATLAS-2467 | Actualización de dependencia para Spring y nimbus-jose-jwt. |
| BUG-97180 | N/D | Actualizar Nimbus-jose-jwt. |
| BUG-98038 | HIVE-18788 | Limpiar las entradas en PreparedStatement de JDBC. |
| BUG-98353 | HADOOP-13707 | Reversión de "Si Kerberos está habilitado mientras HTTP SPNEGO no está configurado, no se puede obtener acceso a algunos vínculos" |
| BUG-98372 | HBASE-13848 | Obtener acceso a las contraseñas de InfoServer SSL a través de la API del proveedor de credenciales. |
| BUG-98385 | ATLAS-2500 | Agregar más encabezados a la respuesta de Atlas. |
| BUG-98564 | HADOOP-14651 | Actualizar versión okhttp a 2.7.5. |
| BUG-99440 | RANGER-2045 | Las columnas de la tabla de Hive sin ninguna directiva de permiso explícito aparecen con el comando 'desc table'. |
| BUG-99803 | N/D | Oozie debe deshabilitar la carga de la clase dinámica de HBase. |
Estabilidad
| Id. del error | JIRA de Apache | Resumen |
|---|---|---|
| BUG-100040 | ATLAS-2536 | NPE en enlace de Atlas Hive. |
| BUG-100057 | HIVE-19251 | ObjectStore.getNextNotification con LIMIT debe usar menos memoria. |
| BUG-100072 | HIVE-19130 | NPE se emite cuando REPL LOAD aplica el evento de colocar partición. |
| BUG-100073 | N/D | Demasiadas conexiones close_wait de hiveserver para el nodo de datos |
| BUG-100319 | HIVE-19248 | REPL LOAD no genera un error si se produce un error en la copia de archivos. |
| BUG-100352 | N/D | CLONE: la lógica de purga de RM examina /registry znode con demasiada frecuencia. |
| BUG-100427 | HIVE-19249 | Replicación: la cláusula WITH no pasa la configuración para la tarea correctamente en todos los casos. |
| BUG-100430 | HIVE-14483 | java.lang.ArrayIndexOutOfBoundsException org.apache.orc.impl.TreeReaderFactory$BytesColumnVectorUtil.commonReadByteArrays |
| BUG-100432 | HIVE-19219 | REPL DUMP incremental debe emitir un error si se limpian los eventos solicitados. |
| BUG-100448 | SPARK-23637, SPARK-23802, SPARK-23809, SPARK-23816, SPARK-23822, SPARK-23823, SPARK-23838, SPARK-23881 | Actualizar Spark2 a 2.3.0+ (4/11) |
| BUG-100740 | HIVE-16107 | JDBC: HttpClient debe reintentar una vez más en NoHttpResponseException. |
| BUG-100810 | HIVE-19054 | Se produce un error en la replicación de funciones de Hive. |
| BUG-100937 | MAPREDUCE-6889 | Agregar la API Job#close para apagar los servicios de cliente MR. |
| BUG-101065 | ATLAS-2587 | Establecer la lectura de ACL para znode de /apache_atlas/active_server_info en alta disponibilidad para que el proxy de Knox la lea. |
| BUG-101093 | STORM-2993 | Storm HDFS bolt emite la excepción ClosedChannelException cuando se usa la directiva de rotación de tiempo. |
| BUG-101181 | N/D | PhoenixStorageHandler no controla AND correctamente en un predicado. |
| BUG-101266 | PHOENIX-4635 | Pérdida de conexión de HBase en org.apache.phoenix.hive.mapreduce.PhoenixInputFormat. |
| BUG-101458 | HIVE-11464 | Falta la información de linaje si hay varias salidas. |
| BUG-101485 | N/D | Hive Metastore Thrift API es lenta y provoca que expire el tiempo de cliente. |
| BUG-101628 | HIVE-19331 | Error de replicación incremental de Hive en la nube. |
| BUG-102048 | HIVE-19381 | Error de replicación de función de Hive en la nube con FunctionTask. |
| BUG-102064 | N/D | Error de las pruebas de replicación \[ onprem to onprem \] de Hive en ReplCopyTask |
| BUG-102137 | HIVE-19423 | Error de las pruebas de replicación \[ Onprem to Cloud \] de Hive en ReplCopyTask |
| BUG-102305 | HIVE-19430 | Volcados de memoria insuficiente de Hive Metastore y HS2. |
| BUG-102361 | N/D | Una inserción múltiple da lugar a una única inserción replicada en el clúster de Hive de destino ( onprem - s3 ) |
| BUG-87624 | N/D | La habilitación del registro de eventos de Storm hace que los trabajos terminen continuamente. |
| BUG-88929 | HBASE-15615 | Tiempo de suspensión incorrecto cuando RegionServerCallable necesita un reintento. |
| BUG-89628 | HIVE-17613 | Quitar los grupos de objetos para asignaciones cortas del mismo subproceso. |
| BUG-89813 | N/D | SCA: Corrección del código: el método no sincronizado invalida el método sincronizado. |
| BUG-90437 | ZEPPELIN-3072 | La interfaz de usuario de Zeppelin se lentifica o no responde si hay demasiados notebooks. |
| BUG-90640 | HBASE-19065 | HRegion#bulkLoadHFiles() debe esperar a que el elemento Region#flush() simultáneo finalice |
| BUG-91202 | HIVE-17013 | Eliminar solicitud con una subconsulta basada en la selección en una vista. |
| BUG-91350 | KNOX-1108 | NiFiHaDispatch no conmuta por error. |
| BUG-92054 | HIVE-13120 | Propagar doAs al generar divisiones de ORC. |
| BUG-92373 | FALCON-2314 | Lanzar la versión de TestNG a 6.13.1 para evitar la dependencia de BeanShell. |
| BUG-92381 | N/D | Errores de testContainerLogsWithNewAPI y testContainerLogsWithOldAPI UT |
| BUG-92389 | STORM-2841 | testNoAcksIfFlushFails UT produce un error con NullPointerException. |
| BUG-92586 | SPARK-17920, SPARK-20694, SPARK-21642, SPARK-22162, SPARK-22289, SPARK-22373, SPARK-22495, SPARK-22574, SPARK-22591, SPARK-22595, SPARK-22601, SPARK-22603, SPARK-22607, SPARK-22635, SPARK-22637, SPARK-22653, SPARK-22654, SPARK-22686, SPARK-22688, SPARK-22817, SPARK-22862, SPARK-22889, SPARK-22972, SPARK-22975, SPARK-22982, SPARK-22983, SPARK-22984, SPARK-23001, SPARK-23038, SPARK-23095 | Actualizar Spark2 a 2.2.1 (16 de enero) |
| BUG-92680 | ATLAS-2288 | Excepción NoClassDefFoundError al ejecutar el script import-hive cuando se crea la tabla de Hbase mediante Hive. |
| BUG-92760 | ACCUMULO-4578 | Cancelar compactación de operación FATE no libera el bloqueo del espacio de nombres. |
| BUG-92797 | HDFS-10267, HDFS-8496 | La reducción de datanode bloquea las contenciones en determinados casos de uso. |
| BUG-92813 | FLUME-2973 | Interbloqueo en el receptor de HDFS. |
| BUG-92957 | HIVE-11266 | Resultado incorrecto de count(*) en función de las estadísticas de tabla para tablas externas |
| BUG-93018 | ATLAS-2310 | En la alta disponibilidad, el nodo pasivo redirige la solicitud con una codificación de dirección URL incorrecta. |
| BUG-93116 | RANGER-1957 | Usersync de Ranger no sincroniza los usuarios o los grupos periódicamente cuando se habilita la sincronización incremental. |
| BUG-93361 | HIVE-12360 | Búsqueda incorrecta en ORC sin comprimir con aplicación de predicado. |
| BUG-93426 | CALCITE-2086 | HTTP/413 en determinadas circunstancias, debido a los encabezados de autorización de gran tamaño. |
| BUG-93429 | PHOENIX-3240 | ClassCastException de cargador de Pig. |
| BUG-93485 | N/D | No se puede obtener la tabla mytestorg.apache.hadoop.hive.ql.metadata.InvalidTableException: No se encontró la tabla al ejecutar el análisis de tabla en columnas en LLAP |
| BUG-93512 | PHOENIX-4466 | java.lang.RuntimeException: código de respuesta 500: ejecutando un trabajo de Spark para conectar con el servidor de consultas Phoenix y datos de carga. |
| BUG-93550 | N/D | Zeppelin %spark.r no funciona con spark1 debido a falta de coincidencia de la versión de Scala. |
| BUG-93910 | HIVE-18293 | Hive no puede compactar tablas contenidas en una carpeta que no es propiedad de la identidad que ejecuta HiveMetaStore. |
| BUG-93926 | ZEPPELIN-3114 | Los notebooks y los intérpretes no se guardan en Zeppelin después de >1d pruebas de esfuerzo. |
| BUG-93932 | ATLAS-2320 | Clasificación de "*" con consulta produce la excepción de servidor interno 500. |
| BUG-93948 | YARN-7697 | NM se desactiva con memoria insuficiente debido a la fuga de log-aggregation (part#1) |
| BUG-93965 | ATLAS-2229 | Búsqueda DSL: el atributo no de cadena orderby produce una excepción. |
| BUG-93986 | YARN-7697 | NM se desactiva con memoria insuficiente debido a la fuga de log-aggregation (part#2) |
| BUG-94030 | ATLAS-2332 | Error al crear tipo con atributos que tienen datatype de colección anidado. |
| BUG-94080 | YARN-3742, YARN-6061 | Ambos RM están en modo de espera en el clúster seguro. |
| BUG-94081 | HIVE-18384 | ConcurrentModificationException en la biblioteca log4j2.x |
| BUG-94168 | N/D | Yarn RM se desactiva con el registro del servicio en el estado incorrecto de ERROR. |
| BUG-94330 | HADOOP-13190, HADOOP-14104, HADOOP-14814, HDFS-10489, HDFS-11689 | HDFS debe admitir varios KMS Uris |
| BUG-94345 | HIVE-18429 | La compactación debe controlar el caso que no genera ninguna salida. |
| BUG-94372 | ATLAS-2229 | Consulta DSL: hive_table name = ["t1","t2"] emite excepción de consulta DSL no válida |
| BUG-94381 | HADOOP-13227, HDFS-13054 | Control de la orden RequestHedgingProxyProvider RetryAction: FAIL < RETRY < FAILOVER_AND_RETRY. |
| BUG-94432 | HIVE-18353 | CompactorMR debe llamar a jobclient.close() para desencadenar la limpieza. |
| BUG-94575 | SPARK-22587 | Se produce un error en el trabajo de Spark si fs.defaultFS y el jar de la aplicación tienen direcciones URL diferentes. |
| BUG-94791 | SPARK-22793 | Fuga de memoria en el servidor Thrift de Spark. |
| BUG-94928 | HDFS-11078 | Corregir NPE en LazyPersistFileScrubber. |
| BUG-95013 | HIVE-18488 | A los lectores ORC de LLAP les faltan comprobaciones NULL. |
| BUG-95077 | HIVE-14205 | Hive no es compatible con el tipo de unión con el formato de archivo AVRO. |
| BUG-95200 | HDFS-13061 | SaslDataTransferClient#checkTrustAndSend no debe confiar en un canal de confianza parcial |
| BUG-95201 | HDFS-13060 | Agregar un BlacklistBasedTrustedChannelResolver para TrustedChannelResolver. |
| BUG-95284 | HBASE-19395 | [branch-1] TestEndToEndSplitTransaction.testMasterOpsWhileSplitting produce un error con NPE |
| BUG-95301 | HIVE-18517 | Vectorización: corregir VectorMapOperator para aceptar VRB y comprobar la marca vectorizada correctamente para admitir el almacenamiento en caché de LLAP. |
| BUG-95542 | HBASE-16135 | Nunca se debe eliminar PeerClusterZnode en rs de los quitados del mismo nivel |
| BUG-95595 | HIVE-15563 | Omitir excepción de transición de estado de operación no válida en SQLOperation.runQuery para exponer la excepción real. |
| BUG-95596 | YARN-4126, YARN-5750 | Error en TestClientRMService. |
| BUG-96019 | HIVE-18548 | Corrección de la importación log4j |
| BUG-96196 | HDFS-13120 | La diferencia de instantáneas podría estar dañada después de concat. |
| BUG-96289 | HDFS-11701 | NPE de host sin resolver provoca errores permanentes de DFSInputStream. |
| BUG-96291 | STORM-2652 | Excepción emitida en el método abierto JmsSpout. |
| BUG-96363 | HIVE-18959 | Evitar la creación de grupo adicional de subprocesos en LLAP. |
| BUG-96390 | HDFS-10453 | El subproceso ReplicationMonitor podría bloquearse durante un largo periodo de tiempo debido a la carrera entre la replicación y la eliminación del mismo archivo en un clúster grande. |
| BUG-96454 | YARN-4593 | Interbloqueo en AbstractService.getConfig(). |
| BUG-96704 | FALCON-2322 | ClassCastException durante el suministro de submitAndSchedule. |
| BUG-96720 | SLIDER-1262 | Error del control deslizante de functests en el entorno Kerberized |
| BUG-96931 | SPARK-23053, SPARK-23186, SPARK-23230, SPARK-23358, SPARK-23376, SPARK-23391 | Actualización de Spark2 (19 de febrero) |
| BUG-97067 | HIVE-10697 | ObjectInspectorConvertors#UnionConvertor does a faulty conversion |
| BUG-97244 | KNOX-1083 | El tiempo de expiración predeterminado de HttpClient debe ser un valor razonable. |
| BUG-97459 | ZEPPELIN-3271 | Opción para deshabilitar el programador. |
| BUG-97511 | KNOX-1197 | AnonymousAuthFilter no se agrega cuando authentication = Anonymous en el servicio. |
| BUG-97601 | HIVE-17479 | No se limpian las consultas de actualizar o eliminar de los directorios de almacenamiento provisional. |
| BUG-97605 | HIVE-18858 | Propiedades del sistema en la configuración del trabajo no resueltas al enviar el trabajo MR. |
| BUG-97674 | OOZIE-3186 | Oozie no puede usar la configuración vinculada mediante jceks://file/... |
| BUG-97743 | N/D | Excepción java.lang.NoClassDefFoundError al implementar la topología de Storm. |
| BUG-97756 | PHOENIX-4576 | Corregir las pruebas LocalIndexSplitMergeIT con errores. |
| BUG-97771 | HDFS-11711 | DN no debe eliminar el bloque cuando se emite la excepción "Demasiados archivos abiertos". |
| BUG-97869 | KNOX-1190 | Se ha interrumpido el soporte técnico para el SSO de Knox para Google OIDC. |
| BUG-97879 | PHOENIX-4489 | Pérdida de conexión de HBase en trabajos MR de Phoenix. |
| BUG-98392 | RANGER-2007 | El tique de Kerberos de tagsync de Ranger no puede renovarse. |
| BUG-98484 | N/D | La replicación incremental de Hive en la nube no funciona. |
| BUG-98533 | HBASE-19934, HBASE-20008 | La restauración de instantáneas de HBase produce errores debido a una excepción de puntero Null. |
| BUG-98555 | PHOENIX-4662 | NullPointerException en TableResultIterator.java en reenvío de caché. |
| BUG-98579 | HBASE-13716 | Dejar de usar FSConstants de Hadoop. |
| BUG-98705 | KNOX-1230 | Muchas solicitudes simultáneas para Knox alteran la dirección URL |
| BUG-98983 | KNOX-1108 | NiFiHaDispatch no conmuta por error. |
| BUG-99107 | HIVE-19054 | La replicación de la función debe usar "hive.repl.replica.functions.root.dir" como raíz. |
| BUG-99145 | RANGER-2035 | Errores de acceso a servicedefs con implClass vacía con el back-end de Oracle. |
| BUG-99160 | SLIDER-1259 | El control deslizante no funciona en entornos de host múltiple. |
| BUG-99239 | ATLAS-2462 | La importación de Sqoop para todas las tablas produce NPE para ninguna tabla proporcionada en el comando. |
| BUG-99301 | ATLAS-2530 | Nueva línea al principio del nombre del atributo de hive_process and hive_column_lineage |
| BUG-99453 | HIVE-19065 | La comprobación de la compatibilidad de cliente Metastore debe incluir syncMetaStoreClient. |
| BUG-99521 | N/D | ServerCache para HashJoin no se vuelve a crear cuando se crea una instancia iteradores. |
| BUG-99590 | PHOENIX-3518 | Fuga de memoria en RenewLeaseTask. |
| BUG-99618 | SPARK-23599, SPARK-23806 | Actualización de Spark2 a 2.3.0+ (3/28) |
| BUG-99672 | ATLAS-2524 | Enlace de Hive con notificaciones V2: control incorrecto de una operación "alter view as". |
| BUG-99809 | HBASE-20375 | Quitar el uso de getCurrentUserCredentials en el módulo spark-hbase. |
Compatibilidad
| Id. del error | JIRA de Apache | Resumen |
|---|---|---|
| BUG-87343 | HIVE-18031 | Compatibilidad de replicación para la operación de modificar base de datos. |
| BUG-91293 | RANGER-2060 | El proxy de Knox con knox-sso no funciona para Ranger |
| BUG-93116 | RANGER-1957 | Usersync de Ranger no sincroniza los usuarios o los grupos periódicamente cuando se habilita la sincronización incremental. |
| BUG-93577 | RANGER-1938 | Solr para la configuración de auditoría no usa DocValues eficazmente. |
| BUG-96082 | RANGER-1982 | Error en la mejora para Analytics Metric de Ranger Admin y Ranger Kms |
| BUG-96479 | HDFS-12781 | Después de que Datanode esté fuera de servicio, en la interfaz de usuario de Namenode, en la pestaña Datanode se arroja un mensaje de advertencia. |
| BUG-97864 | HIVE-18833 | Error al fusionar mediante combinación automática cuando se "inserta en el directorio como orcfile". |
| BUG-98814 | HDFS-13314 | Opcionalmente, NameNode debe salir si detecta daño FsImage. |
Actualización
| Id. del error | JIRA de Apache | Resumen |
|---|---|---|
| BUG-100134 | SPARK-22919 | Revertir "Lanzar versiones de httpclient de Apache". |
| BUG-95823 | N/D |
Knox: Actualizar Beanutils |
| BUG-96751 | KNOX-1076 | Actualizar nimbus-jose-jwt a 4.41.2. |
| BUG-97864 | HIVE-18833 | Error al fusionar mediante combinación automática cuando se "inserta en el directorio como orcfile". |
| BUG-99056 | HADOOP-13556 | Cambiar Configuration.getPropsWithPrefix para usar getProps en lugar del iterador. |
| BUG-99378 | ATLAS-2461, ATLAS-2554 | Utilidad de migración para exportar datos de Atlas en DB de gráficos Titan. |
Facilidad de uso
| Id. del error | JIRA de Apache | Resumen |
|---|---|---|
| BUG-100045 | HIVE-19056 | IllegalArgumentException en FixAcidKeyIndex cuando el archivo ORC tiene 0 filas. |
| BUG-100139 | KNOX-1243 | Normalizar los DN requeridos que están configurados en el servicio KnoxToken |
| BUG-100570 | ATLAS-2557 | Corregir para permitir buscar grupos lookup de Hadoop ldap cuando hay grupos de UGI establecidos incorrectamente o que no están vacíos |
| BUG-100646 | ATLAS-2102 | Mejoras de la interfaz de usuario de Atlas: Página de resultados de la búsqueda |
| BUG-100737 | HIVE-19049 | Agregar compatibilidad para modificar la tabla, agregar columnas para Druid. |
| BUG-100750 | KNOX-1246 | Actualizar configuración del servicio en Knox para admitir las configuraciones más recientes de Ranger. |
| BUG-100965 | ATLAS-2581 | Regresión con las notificaciones del enlace de Hive V2: Mover la tabla a otra base de datos |
| BUG-84413 | ATLAS-1964 | Interfaz de usuario: compatibilidad para ordenar las columnas en la tabla de búsqueda. |
| BUG-90570 | HDFS-11384, HDFS-12347 | Agregar una opción para que el equilibrador disperse llamadas de getBlocks a fin de evitar la punta de rpc.CallQueueLength de NameNode. |
| BUG-90584 | HBASE-19052 | FixedFileTrailer debería reconocer la clase CellComparatorImpl en branch-1.x. |
| BUG-90979 | KNOX-1224 | El proxy de KnoxHADispatcher prestará soporte a Atlas en alta disponibilidad. |
| BUG-91293 | RANGER-2060 | El proxy de Knox con knox-sso no funciona para Ranger |
| BUG-92236 | ATLAS-2281 | Guardar las consultas con filtro de atributo de etiqueta o tipo con filtros NULL y no NULL. |
| BUG-92238 | ATLAS-2282 | La búsqueda favorita guardada solo aparece al actualizar después de la creación, cuando hay más de 25 búsquedas favoritas. |
| BUG-92333 | ATLAS-2286 | El tipo precompilado "kafka_topic" no debe declarar el atributo "topic" como único |
| BUG-92678 | ATLAS-2276 | El valor de ruta de acceso de la entidad de tipo hdfs_path se establece en hive-bridge. |
| BUG-93097 | RANGER-1944 | El filtro de acción para la auditoría de administrador no funciona. |
| BUG-93135 | HIVE-15874, HIVE-18189 | La consulta de Hive devuelve resultados incorrectos cuando hive.groupby.orderby.position.alias se establece en true. |
| BUG-93136 | HIVE-18189 | Ordenar por posición no funciona cuando cbo está deshabilitado |
| BUG-93387 | HIVE-17600 | Hacer que "enforceBufferSize" de OrcFile pueda establecerse por el usuario. |
| BUG-93495 | RANGER-1937 | Ranger tagsync debe procesar la notificación ENTITY_CREATE para admitir la función de importación de Atlas |
| BUG-93512 | PHOENIX-4466 | java.lang.RuntimeException: código de respuesta 500: ejecutando un trabajo de Spark para conectar con el servidor de consultas Phoenix y datos de carga. |
| BUG-93801 | HBASE-19393 | Error HTTP 413 FULL head al tener acceso a la interfaz de usuario de HBase mediante SSL. |
| BUG-93804 | HIVE-17419 | El comando ANALYZE TABLE...COMPUTE STATISTICS FOR COLUMNS muestra estadísticas calculadas para tablas enmascaradas. |
| BUG-93932 | ATLAS-2320 | Clasificación de "*" con consulta produce la excepción de servidor interno 500. |
| BUG-93933 | ATLAS-2286 | El tipo precompilado "kafka_topic" no debe declarar el atributo "topic" como único |
| BUG-93938 | ATLAS-2283, ATLAS-2295 | Actualizaciones de la interfaz de usuario para clasificaciones. |
| BUG-93941 | ATLAS-2296, ATLAS-2307 | Mejora de la búsqueda básica para excluir, opcionalmente, las entidades de subtipo y sub-classification-types. |
| BUG-93944 | ATLAS-2318 | Interfaz de usuario: al hacer clic dos veces en una etiqueta secundaria, se selecciona la primaria |
| BUG-93946 | ATLAS-2319 | Interfaz de usuario: la eliminación de una etiqueta en la posición 25 o superior de la lista de etiquetas tanto de la estructura plana como de árbol necesita una actualización para quitar la etiqueta de la lista. |
| BUG-93977 | HIVE-16232 | Compatibilidad de cálculo de estadísticas para columnas en QuotedIdentifier. |
| BUG-94030 | ATLAS-2332 | Error al crear tipo con atributos que tienen datatype de colección anidado. |
| BUG-94099 | ATLAS-2352 | El servidor Atlas debe proporcionar la configuración para especificar la validez de Kerberos DelegationToken |
| BUG-94280 | HIVE-12785 | Se interrumpe la vista con tipo de unión y UDF para "convertir" la estructura |
| BUG-94332 | SQOOP-2930 | Exec de trabajo de Sqoop no reemplaza las propiedades genéricas de trabajo guardadas. |
| BUG-94428 | N/D | Soporte de Knox para la API de REST del agente de Profiler Dataplane |
| BUG-94514 | ATLAS-2339 | Interfaz de usuario: las modificaciones en las "columnas" de la vista de resultados de la búsqueda básica también afectan a DSL. |
| BUG-94515 | ATLAS-2169 | Error al eliminar cuando se configura la eliminación permanente. |
| BUG-94518 | ATLAS-2329 | Aparece la interfaz de usuario de Atlas Multiple Hovers si el usuario hace clic en otra etiqueta que es incorrecta |
| BUG-94519 | ATLAS-2272 | Guardar el estado de las columnas arrastradas con la API para guardar búsqueda. |
| BUG-94627 | HIVE-17731 | agregar una opción compat de compatibilidad con versiones anteriores para usuarios externos a HIVE-11985 |
| BUG-94786 | HIVE-6091 | Se crean archivos de pipeout vacíos para crear o cerrar la conexión |
| BUG-94793 | HIVE-14013 | La tabla de descripción no muestra Unicode correctamente. |
| BUG-94900 | OOZIE-2606, OOZIE-2658, OOZIE-2787, OOZIE-2802 | Establecer spark.yarn.jars para corregir Spark 2.0 con Oozie. |
| BUG-94901 | HBASE-19285 | Agregar histogramas de latencia por tabla. |
| BUG-94908 | ATLAS-1921 | Interfaz de usuario: Búsqueda con atributos entity y trait: la interfaz de usuario no realiza la comprobación de intervalo y permite proporcionar valores fuera de los límites para los tipos de datos entero y flotante. |
| BUG-95086 | RANGER-1953 | Mejora en la lista de la página user-group. |
| BUG-95193 | SLIDER-1252 | Error del agente del control deslizante con errores de validación de SSL con Python 2.7.5-58 |
| BUG-95314 | YARN-7699 | queueUsagePercentage viene como INF para la llamada de la API de REST getApp |
| BUG-95315 | HBASE-13947, HBASE-14517, HBASE-17931 | Asignar tablas del sistema a servidores con la versión más alta. |
| BUG-95392 | ATLAS-2421 | Actualizaciones de notificación para admitir las estructuras de datos V2. |
| BUG-95476 | RANGER-1966 | La inicialización del motor de directiva no crea enriquecedores de contexto en algunos casos. |
| BUG-95512 | HIVE-18467 | Compatibilidad de volcado de almacén completo, carga + creación y colocación de eventos de base de datos. |
| BUG-95593 | N/D | Extender utilidades de BD de Oozie para admitir la creación de Spark2sharelib |
| BUG-95595 | HIVE-15563 | Omitir excepción de transición de estado de operación no válida en SQLOperation.runQuery para exponer la excepción real. |
| BUG-95685 | ATLAS-2422 | Exportación: compatibilidad de la exportación basada en tipos. |
| BUG-95798 | PHOENIX-2714, PHOENIX-2724, PHOENIX-3023, PHOENIX-3040 | No usar indicadores para ejecutar las consultas en serie. |
| BUG-95969 | HIVE-16828, HIVE-17063, HIVE-18390 | Se produce un error en la vista con particiones con FAILED: IndexOutOfBoundsException Index: 1, Size: 1 |
| BUG-96019 | HIVE-18548 | Corrección de la importación log4j |
| BUG-96288 | HBASE-14123, HBASE-14135, HBASE-17850 | Copia de seguridad y restauración de Backport HBase 2.0 |
| BUG-96313 | KNOX-1119 | La entidad de seguridad OAuth/OpenID Pac4J debe ser configurable |
| BUG-96365 | ATLAS-2442 | El usuario con permiso de solo lectura en el recurso de entidad no puede realizar una búsqueda básica. |
| BUG-96479 | HDFS-12781 | Después de que Datanode esté fuera de servicio, en la interfaz de usuario de Namenode, en la pestaña Datanode se arroja un mensaje de advertencia. |
| BUG-96502 | RANGER-1990 | Agregar compatibilidad con SSL MySQL unidireccional en Ranger Admin. |
| BUG-96718 | ATLAS-2439 | Actualizar el enlace de Sqoop para usar notificaciones V2. |
| BUG-96748 | HIVE-18587 | Puede que la inserción de evento DML intente calcular una suma de comprobación en directorios |
| BUG-96821 | HBASE-18212 | En modo independiente con el sistema de archivos local, HBase registra el mensaje de advertencia: No se pudo invocar el método "unbuffer" en la clase org.apache.hadoop.fs.FSDataInputStream |
| BUG-96847 | HIVE-18754 | REPL STATUS debe admitir la cláusula "with". |
| BUG-96873 | ATLAS-2443 | La captura requería atributos de entidad en mensajes DELETE salientes. |
| BUG-96880 | SPARK-23230 | Cuando hive.default.fileformat es otros tipos de archivo, la creación de una tabla textfile causa un error serde |
| BUG-96911 | OOZIE-2571, OOZIE-2792, OOZIE-2799, OOZIE-2923 | Mejorar el análisis de opciones de Spark. |
| BUG-97100 | RANGER-1984 | Las entradas de registro de auditoría de HBase pueden no mostrar todas las etiquetas asociadas con la columna a la que se accede |
| BUG-97110 | PHOENIX-3789 | Ejecutar llamadas de mantenimiento del índice de región en postBatchMutateIndispensably. |
| BUG-97145 | HIVE-12245, HIVE-17829 | Compatibilidad de comentarios de columna para una tabla de copia de seguridad de HBase. |
| BUG-97409 | HADOOP-15255 | Compatibilidad de conversión de mayúsculas y minúsculas para nombres de grupo en LdapGroupsMapping. |
| BUG-97535 | HIVE-18710 | Extender inheritPerms a ACID en Hive 2.X. |
| BUG-97742 | OOZIE-1624 | Patrón de exclusión para los JAR sharelib |
| BUG-97744 | PHOENIX-3994 | La prioridad de RPC de índice sigue dependiendo de la propiedad de fábrica del controlador en hbase-site.xml. |
| BUG-97787 | HIVE-18460 | Compactor no pasa las propiedades de tabla al escritor ORC. |
| BUG-97788 | HIVE-18613 | Extender JsonSerDe para que admita el tipo BINARY. |
| BUG-97899 | HIVE-18808 | Fortalecer compactación cuando se produce un error de actualización de estadísticas. |
| BUG-98038 | HIVE-18788 | Limpiar las entradas en PreparedStatement de JDBC. |
| BUG-98383 | HIVE-18907 | Crear utilidad para corregir el problema de índice de clave ACID de HIVE-18817. |
| BUG-98388 | RANGER-1828 | Práctica recomendada de codificación: agregar más encabezados en Ranger. |
| BUG-98392 | RANGER-2007 | El tique de Kerberos de tagsync de Ranger no puede renovarse. |
| BUG-98533 | HBASE-19934, HBASE-20008 | La restauración de instantáneas de HBase produce errores debido a una excepción de puntero Null. |
| BUG-98552 | HBASE-18083, HBASE-18084 | Hacer que el número de subprocesos de limpieza de archivos grande o pequeño sea configurable en HFileCleaner. |
| BUG-98705 | KNOX-1230 | Muchas solicitudes simultáneas para Knox alteran la dirección URL |
| BUG-98711 | N/D | La distribución de NiFi no puede usar SSL bidireccional sin modificaciones de service.xml. |
| BUG-98880 | OOZIE-3199 | Permitir que la restricción de propiedad del sistema se configurable. |
| BUG-98931 | ATLAS-2491 | Actualizar el enlace de Hive para usar notificaciones de Atlas v2. |
| BUG-98983 | KNOX-1108 | NiFiHaDispatch no conmuta por error. |
| BUG-99088 | ATLAS-2511 | Proporcionar opciones para importar la base de datos o tablas de manera selectiva desde Hive a Atlas. |
| BUG-99154 | OOZIE-2844, OOZIE-2845, OOZIE-2858, OOZIE-2885 | Error de consulta de Spark con la excepción "java.io.FileNotFoundException: hive-site.xml (permiso denegado)". |
| BUG-99239 | ATLAS-2462 | La importación de Sqoop para todas las tablas produce NPE para ninguna tabla proporcionada en el comando. |
| BUG-99636 | KNOX-1238 | Corregir la configuración de Truststore personalizado para la puerta de enlace. |
| BUG-99650 | KNOX-1223 | El proxy Knox de Zeppelin no redirige /api/ticket según lo previsto |
| BUG-99804 | OOZIE-2858 | HiveMain, ShellMain y SparkMain no deben sobrescribir las propiedades y los archivos de configuración localmente. |
| BUG-99805 | OOZIE-2885 | La ejecución de acciones de Spark no debe necesitar Hive en classpath. |
| BUG-99806 | OOZIE-2845 | Reemplazar el código basado en reflexión que establece la variable en HiveConf. |
| BUG-99807 | OOZIE-2844 | Aumentar la estabilidad de las acciones de Oozie cuando falta log4j.properties o no se puede leer |
| RMP-9995 | AMBARI-22222 | Cambiar druid y usar el directorio /var/druid en lugar de /apps/druid en el disco local. |
Cambios de comportamiento
| Componente de Apache | JIRA de Apache | Resumen | Detalles |
|---|---|---|---|
| Spark 2.3 | N/D | Modificaciones documentadas en las notas de la versión de Apache Spark | - Existe un documento "Deprecation" (Desuso) y una guía "Change of behavior" (Cambio de comportamiento), https://spark.apache.org/releases/spark-release-2-3-0.html#deprecations - En la parte SQL, existe otra guía detallada "Migration" (Migración) (desde 2.2 a 2.3), https://spark.apache.org/docs/latest/sql-programming-guide.html#upgrading-from-spark-sql-22-to-23| |
| Spark | HIVE-12505 | El trabajo de Spark se completa correctamente, pero hay un error de cuota completa de disco HDFS. |
Escenario: se ejecuta insert overwrite con una cuota establecida en la carpeta Papelera del usuario que ejecuta el comando. Comportamiento anterior: el trabajo terminaba correctamente, aunque no pudiera mover los datos a la Papelera. El resultado puede contener erróneamente algunos de los datos previamente presentes en la tabla. Nuevo comportamiento: cuando se produce un error al mover a la carpeta Papelera, los archivos se eliminan permanentemente. |
| Kafka 1.0 | N/D | Modificaciones documentadas en las notas de la versión de Apache Spark | https://kafka.apache.org/10/documentation.html#upgrade_100_notable |
| Hive/Ranger | Se requieren más directivas de Ranger Hive para INSERT OVERWRITE |
Escenario: Se requieren más directivas de Ranger Hive para INSERT OVERWRITE. Comportamiento anterior: las consultas INSERT OVERWRITE de Hive eran correctas como de costumbre. Nuevo comportamiento: las consultas INSERT OVERWRITE de Hive producen errores de forma inesperada después de actualizar a HDP-2.6 con el error: Error al compilar la instrucción: FAILED: HiveAccessControlException ha denegado el permiso: el usuario jdoe no tiene privilegios de escritura en /tmp/*(state=42000,code=40000) A partir de HDP-2.6.0, las consultas INSERT OVERWRITE de Hive requieren una directiva de Ranger URI para permitir las operaciones de escritura, incluso si el usuario tiene privilegios de escritura concedidos a través de la directiva HDFS. Solución alternativa o acción esperada del cliente: 1. Crear una nueva directiva en el repositorio de Hive. 2. En la lista desplegable donde se ve la base de datos, seleccione el identificador URI. 3. Actualizar la ruta de acceso (por ejemplo: /tmp/*). 4. Agregar los usuarios y el grupo y guardar. 5. Volver a intentar la consulta de inserción. |
|
| HDFS | N/D | HDFS debe admitir varios KMS Uris |
Comportamiento anterior: se usaba la propiedad dfs.encryption.key.provider.uri para configurar la ruta de acceso del proveedor KMS. Nuevo comportamiento: dfs.encryption.key.provider.uri está ahora en desuso en favor de hadoop.security.key.provider.path para configurar la ruta de acceso del proveedor KMS. |
| Zeppelin | ZEPPELIN-3271 | Opción para deshabilitar el programador. |
Componente afectado: Servidor de Zeppelin Comportamiento anterior: en versiones anteriores de Zeppelin, no había ninguna opción para deshabilitar el programador. Nuevo comportamiento: de forma predeterminada, los usuarios ya no verán el programador, ya que está deshabilitado de forma predeterminada. Solución alternativa o acción esperada del cliente: si quiere habilitar el programador, deberá agregar azeppelin.notebook.cron.enable con el valor true en el sitio de zeppelin personalizado en la configuración de Zeppelin de Ambari. |
Problemas conocidos
Integración de HDInsight con ADLS Gen 2 Hay dos problemas en los clústeres de HDInsight ESP que utilizan Azure Data Lake Storage Gen 2 con directorios y permisos de usuario:
Los directorios de inicio para los usuarios no se están creando en el nodo principal 1. Como alternativa, cree los directorios manualmente y cambie la propiedad al UPN del usuario correspondiente.
Los permisos en el directorio /hdp no están actualmente configurados en 751. Debe establecerse en
chmod 751 /hdp chmod –R 755 /hdp/apps
Spark 2.3
[SPARK-23523][SQL] Resultado incorrecto causado por la regla OptimizeMetadataOnlyQuery
[SPARK-23406] Errores en las autocombinaciones de secuencia a secuencia
Los notebooks de ejemplo de Spark no están disponibles cuando Azure Data Lake Storage (Gen2) es el almacenamiento predeterminado del clúster.
Paquete de seguridad de la empresa
- El servidor Spark Thrift no acepta conexiones de clientes ODBC.
Pasos para la solución alternativa:
- Espere unos 15 minutos después de la creación del clúster.
- Compruebe en la interfaz de usuario de Ranger la existencia de hivesampletable_policy.
- Reinicie el servicio de Spark. La conexión de STS debería funcionar ahora.
- El servidor Spark Thrift no acepta conexiones de clientes ODBC.
Pasos para la solución alternativa:
Solución alternativa para el error de comprobación del servicio de Ranger
RANGER 1607: solución alternativa para el error de comprobación del servicio de Ranger durante la actualización a HDP 2.6.2 desde versiones anteriores de HDP.
Nota
Solo cuando Ranger está habilitado para SSL.
Este problema surge cuando se intenta actualizar a HDP-2.6.1 desde versiones anteriores de HDP a través de Ambari. Ambari usa una llamada de curl para realizar una comprobación de servicio al servicio de Ranger en Ambari. Si la versión JDK usada por Ambari es JDK-1.7, se producirá el error siguiente en la llamada de curl:
curl: (35) error:14077410:SSL routines:SSL23_GET_SERVER_HELLO:sslv3 alert handshake failureEl motivo de este error es que la versión de Tomcat usada en Ranger es Tomcat-7.0.7*. Usar JDK-1.7 entra en conflicto con los cifrados predeterminados proporcionados en Tomcat-7.0.7*.
Puede resolver este problema de dos maneras:
Actualizar el JDK usado en Ambari de JDK-1.7 a JDK-1.8. Consulte la sección Change the JDK Version (Cambiar la versión de JDK) en la guía de referencia de Ambari.
Si desea seguir con la compatibilidad de un entorno JDK-1.7:
Agregue la propiedad ranger.tomcat.ciphers en la sección ranger-admin-site en la configuración de Ambari Ranger con el siguiente valor:
SSL_RSA_WITH_RC4_128_MD5, SSL_RSA_WITH_RC4_128_SHA, TLS_RSA_WITH_AES_128_CBC_SHA, SSL_RSA_WITH_3DES_EDE_CBC_SHA
Si su entorno está configurado para Ranger-KMS, agregue la propiedad ranger.tomcat.ciphers en la sección theranger-kms-site de la configuración de Ambari Ranger con el siguiente valor:
SSL_RSA_WITH_RC4_128_MD5, SSL_RSA_WITH_RC4_128_SHA, TLS_RSA_WITH_AES_128_CBC_SHA, SSL_RSA_WITH_3DES_EDE_CBC_SHA
Nota:
Los valores anotados son ejemplos de trabajo y pueden no ser indicativos de su entorno. Asegúrese de que la manera en que establece estas propiedades coincide con cómo está configurado su entorno.
RangerUI: texto de escape de condición de directiva especificado en forma de directiva
Componente afectado: Ranger
Descripción del problema
Si un usuario quiere crear una directiva con condiciones de directiva personalizadas y la expresión o el texto contiene caracteres especiales, la aplicación de la directiva no funcionará. Los caracteres especiales se convierten a ASCII antes de guardar la directiva en la base de datos.
Caracteres especiales: y <> " ` '
Por ejemplo, la condición tags.attributes['type']='abc' se convertiría en lo siguiente después de guardar la directiva.
tags.attds['dsds']='cssdfs'
Para ver la condición de directiva con estos caracteres, abra la directiva en modo de edición.
Solución alternativa
Opción 1: crear o actualizar la directiva por medio de la API de REST de Ranger
Dirección URL de REST: http://<host>:6080/service/plugins/policies
Creación de directiva con condición de directiva:
En el ejemplo siguiente, creará la directiva con etiquetas como "tags-test" y la asignará al grupo "public" con la condición de directiva astags.attr['type']=='abc' seleccionando todos los permisos de componente de Hive, como select, update, create, drop, alter, index, lock y all.
Ejemplo:
curl -H "Content-Type: application/json" -X POST http://localhost:6080/service/plugins/policies -u admin:admin -d '{"policyType":"0","name":"P100","isEnabled":true,"isAuditEnabled":true,"description":"","resources":{"tag":{"values":["tags-test"],"isRecursive":"","isExcludes":false}},"policyItems":[{"groups":["public"],"conditions":[{"type":"accessed-after-expiry","values":[]},{"type":"tag-expression","values":["tags.attr['type']=='abc'"]}],"accesses":[{"type":"hive:select","isAllowed":true},{"type":"hive:update","isAllowed":true},{"type":"hive:create","isAllowed":true},{"type":"hive:drop","isAllowed":true},{"type":"hive:alter","isAllowed":true},{"type":"hive:index","isAllowed":true},{"type":"hive:lock","isAllowed":true},{"type":"hive:all","isAllowed":true}]}],"denyPolicyItems":[],"allowExceptions":[],"denyExceptions":[],"service":"tagdev"}'Actualización de directiva con condición de directiva:
En el ejemplo siguiente, actualizará la directiva con etiquetas como "tags-test" y la asignará al grupo "public" con la condición de directiva astags.attr['type']=='abc' seleccionando todos los permisos de componente de Hive, como select, update, create, drop, alter, index, lock y all.
Dirección URL de REST: http://<host-name>:6080/service/plugins/policies/<policy-id>
Ejemplo:
curl -H "Content-Type: application/json" -X PUT http://localhost:6080/service/plugins/policies/18 -u admin:admin -d '{"id":18,"guid":"ea78a5ed-07a5-447a-978d-e636b0490a54","isEnabled":true,"createdBy":"Admin","updatedBy":"Admin","createTime":1490802077000,"updateTime":1490802077000,"version":1,"service":"tagdev","name":"P0101","policyType":0,"description":"","resourceSignature":"e5fdb911a25aa7f77af5a9546938d9ed","isAuditEnabled":true,"resources":{"tag":{"values":["tags"],"isExcludes":false,"isRecursive":false}},"policyItems":[{"accesses":[{"type":"hive:select","isAllowed":true},{"type":"hive:update","isAllowed":true},{"type":"hive:create","isAllowed":true},{"type":"hive:drop","isAllowed":true},{"type":"hive:alter","isAllowed":true},{"type":"hive:index","isAllowed":true},{"type":"hive:lock","isAllowed":true},{"type":"hive:all","isAllowed":true}],"users":[],"groups":["public"],"conditions":[{"type":"ip-range","values":["tags.attributes['type']=abc"]}],"delegateAdmin":false}],"denyPolicyItems":[],"allowExceptions":[],"denyExceptions":[],"dataMaskPolicyItems":[],"rowFilterPolicyItems":[]}'Option 2: aplicar cambios de Javascript
Pasos para actualizar el archivo JS:
Busque el archivo PermissionList.js en /usr/hdp/current/ranger-admin.
Busque la definición de la función renderPolicyCondtion (número de línea: 404).
Quite la siguiente línea de esa función, es decir, en la función de presentación (línea 434).
val = _.escape(val);//Line No:460
Después de quitar la línea anterior, la interfaz de usuario de Ranger podrá crear directivas con una condición de directiva que contenga caracteres especiales y la evaluación de la directiva será correcta para la misma directiva.
Integración de HDInsight con ADLS Gen 2: problemas de permisos y directorios de usuario con clústeres ESP 1. Los directorios de inicio para los usuarios no se crean en el nodo principal 1. Una solución alternativa es crearlos manualmente y cambiar la propiedad al UPN del usuario correspondiente. 2. Los permisos en /hdp no están actualmente configurados en 751. Debe establecerse en a. chmod 751 /hdp b. chmod –R 755 /hdp/apps
Desuso
Portal de OMS: se ha eliminado el vínculo de la página de recursos de HDInsight que apuntaba al portal de OMS. Inicialmente, los registros de Azure Monitor usaban su propio portal denominado portal de OMS para administrar su configuración y analizar los datos recopilados. Toda la funcionalidad de este portal se ha movido a Azure Portal, donde continuará desarrollándose. La compatibilidad de HDInsight para el portal de OMS está en desuso. Los clientes podrán usar la integración de registros de Azure Monitor para HDInsight en Azure Portal.
Spark 2.3:versiones de Spark 2.3.0 en desuso
Actualizando
Todas estas características están disponibles en HDInsight 3.6. Para obtener la versión más reciente de Spark, Kafka y R Server (Machine Learning Services), elija la versión de Spark, Kafka, ML Services cuando cree un clúster de HDInsight 3.6. Para obtener la compatibilidad de ADLS, puede elegir el tipo de almacenamiento ADLS como opción. Los clústeres existentes no se actualizarán automáticamente a estas versiones.
Todos los clústeres nuevos creados después de junio de 2018 obtendrán automáticamente las más de 1000 correcciones de errores en todos los proyectos de código abierto. Siga esta guía de procedimientos recomendados en torno a la actualización a una versión más reciente de HDInsight.