En este artículo se proporcionan respuestas a algunas de las preguntas más comunes sobre la ejecución de Azure HDInsight.
Creación o eliminación de clústeres de HDInsight
¿Cómo aprovisiono un clúster de HDInsight?
Para revisar los tipos de clústeres de HDInsight y los métodos de aprovisionamiento, consulte Configuración de clústeres en HDInsight con Apache Hadoop, Apache Spark, Apache Kafka, etc.
¿Cómo elimino un clúster de HDInsight existente?
Para más información sobre cómo eliminar un clúster que ya no se usa, consulte Eliminación de un clúster de HDInsight.
Intente dejar al menos de 30 a 60 minutos entre la operación de creación y la de eliminación. De lo contrario, puede producirse un error en la operación con el siguiente mensaje de error:
Conflict (HTTP Status Code: 409) error when attempting to delete a cluster immediately after creation of a cluster. If you encounter this error, wait until the newly created cluster is in operational state before attempting to delete it.
¿Cómo selecciono el número correcto de núcleos o nodos para mi carga de trabajo?
El número adecuado de núcleos y otras opciones de configuración dependen de diversos factores.
Para más información, consulte Planeamiento de la capacidad de los clústeres de HDInsight.
¿Cuáles son los distintos tipos de nodos de un clúster de HDInsight?
¿Cuáles son los procedimientos recomendados para crear clústeres grandes de HDInsight?
- Se recomienda configurar los clústeres de HDInsight con una base de datos de Ambari personalizada para mejorar la escalabilidad del clúster.
- Use Azure Data Lake Storage Gen2 para crear clústeres de HDInsight para aprovechar el mayor ancho de banda y otras características de rendimiento de Azure Data Lake Storage Gen2.
- Los nodos principales deben ser lo suficientemente grandes como para dar cabida a varios servicios maestros que se ejecuten en estos nodos.
- Algunas cargas de trabajo específicas, como Interactive Query, también necesitarán nodos de Zookeeper más grandes. Considere VM con un mínimo de ocho núcleos.
- En el caso de Hive y Spark, use un metastore de Hive externo.
Componentes individuales
¿Puedo instalar más componentes en mi clúster?
Sí. Para instalar más componentes o personalizar la configuración del clúster, use:
Scripts durante la creación o después. Los scripts se invocan a través de la acción de script. Una acción de script es una opción de configuración que se puede usar a partir de los cmdlets de Windows PowerShell de HDInsight, Azure Portal o el SDK de HDInsight para .NET. Esta opción de configuración se puede usar desde Azure Portal, los cmdlets de Windows PowerShell para HDInsight o el SDK de HDInsight para .NET.
Plataforma de aplicaciones HDInsight para instalar aplicaciones.
Para una lista de los componentes admitidos, consulte ¿Cuáles son los componentes y versiones de Apache Hadoop disponibles con HDInsight?.
¿Puedo actualizar los componentes individuales que están preinstalados en el clúster?
Si actualiza los componentes integrados o las aplicaciones que están preinstaladas en el clúster, Microsoft no dará soporte técnico a la configuración resultante. Microsoft no ha probado estas configuraciones del sistema. Intente usar una versión diferente del clúster de HDInsight; puede que ya tenga la versión actualizada del componente preinstalado.
Por ejemplo, no se admite la actualización de Hive como componente individual. HDInsight es un servicio administrado y muchos servicios se integran con el servidor de Ambari y se prueban. La actualización independiente de Hive hace que los archivos binarios indexados de otros componentes cambien, lo que provocará problemas de integración de componentes en el clúster.
¿Se pueden ejecutar Spark y Kafka en el mismo clúster de HDInsight?
No, no es posible ejecutar Apache Kafka y Apache Spark en el mismo clúster de HDInsight. Debe crear clústeres independientes para Kafka y Spark, con el fin de evitar problemas de contención de recursos.
¿Cómo cambio la zona horaria en Ambari?
Abra la interfaz de usuario de Ambari Web en
https://CLUSTERNAME.azurehdinsight.net, donde CLUSTERNAME es el nombre del clúster.En la esquina superior derecha, seleccione admin | Settings (Administrador | Configuración).
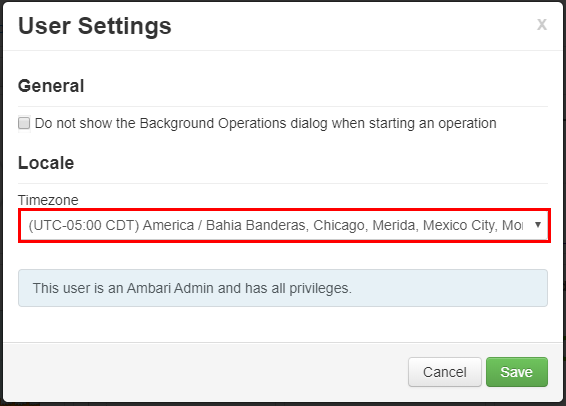
En la ventana Configuración del usuario, seleccione la nueva zona horaria en la lista desplegable Zona horaria y, a continuación, seleccione Guardar.
Tienda de metadatos
¿Cómo puedo migrar desde el metastore existente a Azure SQL Database?
Para migrar de SQL Server a Azure SQL Database, consulte Tutorial: Migración de SQL Server a una base de datos única o agrupada en Azure SQL Database sin conexión mediante DMS.
¿El metastore de Hive se elimina cuando se elimina el clúster?
Depende del tipo de metastore que el clúster tenga configurado para usar.
Si se trata del metastore predeterminado: el metastore predeterminado forma parte del ciclo de vida del clúster. Al eliminar un clúster, también se eliminan la tienda de metadatos y los metadatos correspondientes.
Si se trata de un metastore personalizado: el ciclo de vida del metastore no está asociado al ciclo de vida de un clúster. Por lo tanto, puede crear y eliminar clústeres sin perder los metadatos. Los metadatos, como los esquemas de Hive, se conservan incluso después de eliminar y volver a crear el clúster de HDInsight.
Para más información, consulte Use external metadata stores in Azure HDInsight (Uso de almacenes externos de metadatos en Azure HDInsight).
¿La migración de un metastore de Hive también migra las directivas predeterminadas de la base de datos de Ranger?
No, la definición de la directiva se encuentra en la base de datos de Ranger, por lo que al migrar esta se migra también su directiva.
¿Se puede migrar un metastore de Hive desde un clúster de Enterprise Security Package (ESP) a un clúster que no sea ESP y viceversa?
Sí, puede migrar un metastore de Hive desde un clúster ESP a un clúster que no sea ESP.
¿Cómo puedo calcular el tamaño de una base de datos de metastore de Hive?
El metastore de Hive se utiliza para almacenar los metadatos de los orígenes de datos que usa el servidor de Hive. Los requisitos de tamaño dependen en parte del número y la complejidad de los orígenes de datos de Hive. Estos elementos no se pueden estimar por adelantado. Como se describe en instrucciones de metastore de Hive, puede empezar con un nivel S2. El nivel proporciona 50 DTU y 250 GB de almacenamiento y, si ve un cuello de botella, escale verticalmente la base de datos.
¿Se admite alguna otra base de datos que no sea Azure SQL Database como metastore externo?
No, Microsoft solo admite Azure SQL Database como metastore personalizado externo.
¿Puedo compartir un metastore entre varios clústeres?
Sí, puede compartir un metastore personalizado entre varios clústeres, siempre que usen la misma versión de HDInsight.
Conectividad y redes virtuales
¿Cuáles son las implicaciones de bloquear los puertos 22 y 23 en mi red?
Si bloquea los puertos 22 y 23, no tendrá acceso SSH al clúster. El servicio HDInsight no usa estos puertos.
Para obtener más información, vea los documentos siguientes:
¿Puedo implementar más máquinas virtuales dentro de la misma subred que un clúster de HDInsight?
Sí, puede implementar más máquinas virtuales en la misma subred que un clúster de HDInsight. Se admiten las siguientes configuraciones:
Nodos perimetrales: puede agregar otro nodo perimetral al clúster, tal y como se describe en Uso de nodos perimetrales vacíos en clústeres de Apache Hadoop en HDInsight.
Nodos independientes: puede agregar una máquina virtual independiente a la misma subred y acceder al clúster desde esa máquina virtual mediante el punto de conexión privado
https://<CLUSTERNAME>-int.azurehdinsight.net. Para más información, consulte Control del tráfico de red.
¿Se deben almacenar datos en el disco local de un nodo perimetral?
No, no es una buena idea almacenar datos en un disco local. Si se produce un error en el nodo, se perderán todos los datos almacenados localmente. Se recomienda almacenar los datos en Azure Data Lake Storage Gen2 o en Azure Blob Storage, o mediante el montaje de un recurso compartido de Azure Files para almacenar los datos.
¿Puedo agregar un clúster de HDInsight existente a otra red virtual?
No, no puede. La red virtual debe especificarse en el momento del aprovisionamiento. Si no se especifica ninguna red virtual durante el aprovisionamiento, la implementación crea una red interna a la que no se puede acceder desde el exterior. Para más información, consulte Agregar HDInsight a una red virtual existente.
Seguridad y certificados
¿Cuáles son las recomendaciones para la protección contra malware en los clústeres de Azure HDInsight?
Para información sobre la protección contra malware, consulte Microsoft Antimalware para Azure Cloud Services y Virtual Machines.
¿Cómo creo un archivo keytab para un clúster ESP de HDInsight?
Cree un archivo keytab de Kerberos para el nombre de usuario del dominio. Posteriormente, puede usar este archivo para autenticarse en clústeres unidos a un dominio remoto sin necesidad de escribir una contraseña. El nombre de dominio se ha escrito en mayúsculas:
ktutil
ktutil: addent -password -p <username>@<DOMAIN.COM> -k 1 -e aes256-cts-hmac-sha1-96
Password for <username>@<DOMAIN.COM>: <password>
ktutil: wkt <username>.keytab
ktutil: q
¿Cuándo se requiere sal para el cifrado AES256 al crear la tabla de claves?
Si su TenantName y DomainName son diferentes (ejemplo TenantName – bob@CONTOSO.ONMICROSOFT.COM y DomainName – bob@CONTOSOMicrosoft.ONMICROSOFT.COM), deberá agregar un valor SALT usando la opción -s.
¿Cómo determinar el valor SALT adecuado?
- Usar un inicio de sesión de Kerberos interactivo para determinar el valor de sal adecuado para keytab. El inicio de sesión de Kerberos interactivo usa el cifrado más alto de forma predeterminada. Se debe habilitar el seguimiento para observar la sal. A continuación se muestra un inicio de sesión de Kerberos de ejemplo:
$ KRB5_TRAACE=/dev/stdout kinit <username> -V
- Examinar la línea de salida "......".
- Usar este valor de sal al crear la tabla keytab.
ktutil
ktutil: addent -password -p <username>@<DOMAIN.COM> -k 1 -e aes256-cts-hmac-sha1-96 -s <SALTvalue>
Password for <username>@<DOMAIN.COM>: <password>
ktutil: wkt <username>.keytab
ktutil: q
¿Puedo usar un inquilino de Microsoft Entra existente para crear un clúster de HDInsight que tenga el ESP?
Habilite Microsoft Entra Domain Services para poder crear un clúster de HDInsight con ESP. Hadoop de código abierto se basa en Kerberos (en lugar de OAuth) para proporcionar autenticación.
Para unir máquinas virtuales a un dominio, debe tener un controlador de dominio. Microsoft Entra Domain Services es el controlador de dominio administrado y se considera una extensión de Microsoft Entra ID. Microsoft Entra Domain Services proporciona todos los requisitos de Kerberos para crear un clúster de Hadoop seguro de forma administrada. HDInsight como servicio administrado se integra con Microsoft Entra Domain Services para proporcionar seguridad.
¿Puedo usar un certificado autofirmado en una configuración LDAP segura de Microsoft Entra Domain Services y aprovisionar un clúster de ESP?
Se recomienda usar un certificado emitido por una entidad de certificación. Pero el uso de un certificado autofirmado también se admite en ESP. Para más información, consulte:
¿Puedo instalar Data Analytics Studio (DAS) como un clúster ESP?
No, DAS no se admite en clústeres de ESP.
¿Cómo puedo extraer la actividad de inicio de sesión que se muestra en Ranger?
En cuanto a los requisitos de auditoría, Microsoft recomienda habilitar los registros de Azure Monitor, tal como se describe en Uso de los registros de Azure Monitor para supervisar clústeres de HDInsight.
¿Puedo deshabilitar Clamscan en mi clúster?
Clamscan es el software antivirus que se ejecuta en el clúster de HDInsight y se usa en la seguridad de Azure (azsecd) para proteger los clústeres ante los ataques de virus. Microsoft recomienda encarecidamente que los usuarios no realicen ningún cambio en la configuración predeterminada de Clamscan.
Este proceso no interfiere con otros procesos ni les retira ciclos. Siempre se suspenderá ante otro proceso. Los picos de CPU de Clamscan solo deben aparecer cuando el sistema está inactivo.
En los escenarios en los que debe controlar la programación, puede seguir estos pasos:
Deshabilite la ejecución automática con el siguiente comando:
sudo
usr/local/bin/azsecd config -s clamav -d Disabledsudo service azsecd restartAgregue un trabajo Cron que ejecute este comando como raíz:
/usr/local/bin/azsecd manual -s clamav
Para más información sobre la configuración y ejecución de un trabajo Cron, consulte How do I set up a Cron job? (¿Cómo configuro un trabajo Cron?).
¿Por qué LLAP está disponible en los clústeres de Spark para ESP?
LLAP está habilitado por razones de seguridad (Apache Ranger), no de rendimiento. Use máquinas virtuales con nodos de mayor tamaño para integrar el uso de recursos de LLAP (por ejemplo, D13V2 como mínimo).
¿Cómo puedo agregar grupos adicionales de Microsoft Entra después de crear un clúster de ESP?
Hay dos formas de hacerlo: 1. Puede volver a crear el clúster y agregar el grupo adicional en el momento de la creación del clúster. Si usa la sincronización con ámbito en Microsoft Entra Domain Services, asegúrese de que el grupo B se incluye en la sincronización con ámbito.
2\. Agregue el grupo como un subgrupo anidado del grupo anterior que se usó para crear el clúster de ESP. Por ejemplo, si creó un clúster de ESP con el grupo A, puede agregar más adelante al grupo B como un subgrupo anidado de A y, después de aproximadamente una hora, se sincronizará y estará disponible en el clúster automáticamente.
Storage
¿Puedo agregar Azure Data Lake Storage Gen2 a un clúster de HDInsight existente como una cuenta de almacenamiento adicional?
No, actualmente no es posible agregar una cuenta de almacenamiento de Azure Data Lake Storage Gen2 a un clúster con almacenamiento de blobs como almacenamiento principal. Para más información, consulte Comparación de las opciones de almacenamiento.
¿Cómo puedo encontrar la entidad de servicio vinculada actualmente para una cuenta de Data Lake Storage?
Puede buscar la configuración en el acceso a Data Lake Storage Gen1 en las propiedades del clúster de Azure Portal. Para más información, consulte Comprobación de la configuración del clúster.
¿Cómo puedo calcular el uso de cuentas de almacenamiento y contenedores de blobs para mis clústeres de HDInsight?
Realice alguna de las siguientes acciones:
Busque el tamaño de la carpeta /user/hive/.Trash/ en el clúster de HDInsight, con la siguiente línea de comandos:
hdfs dfs -du -h /user/hive/.Trash/
¿Cómo puedo configurar la auditoría para mi cuenta de almacenamiento de blobs?
Para auditar cuentas de almacenamiento de blobs, configure la supervisión mediante el procedimiento que se encuentra en Supervisión de una cuenta de almacenamiento en Azure Portal. Un registro de auditoría de HDFS solo proporciona información de auditoría para el sistema de archivos HDFS local (hdfs://mycluster). No incluye las operaciones que se realizan en el almacenamiento remoto.
¿Cómo puedo transferir archivos entre un contenedor de blobs y un nodo principal de HDInsight?
Ejecute un script similar al siguiente script de shell en el nodo principal:
for i in cat filenames.txt
do
hadoop fs -get $i <local destination>
done
Nota
El archivo filenames.txt incluirá la ruta de acceso absoluta de los archivos de los contenedores de blobs.
¿Hay algún complemento de Ranger para el almacenamiento?
Actualmente no existe ningún complemento de Ranger para el almacenamiento de blobs y Azure Data Lake Storage Gen1 o Gen2. En el caso de los clústeres de ESP, debe usar Azure Data Lake Storage. Puede establecer al menos los permisos específicos de forma manual en el nivel del sistema de archivos mediante las herramientas de HDFS. Además, al usar Azure Data Lake Storage, los clústeres de ESP realizarán parte del control de acceso del sistema de archivos mediante Microsoft Entra ID en el nivel de clúster.
Puede asignar directivas de acceso a los datos a los grupos de seguridad de los usuarios mediante el Explorador de Azure Storage. Para más información, consulte:
¿Puedo aumentar el almacenamiento de HDFS en un clúster sin aumentar el tamaño del disco de los nodos de trabajo?
No. No, no puede aumentar el tamaño del disco de ningún nodo de trabajo. Por lo tanto, la única manera de aumentar el tamaño del disco es quitar el clúster y volver a crearlo con mayores máquinas virtuales de trabajo. No utilice HDFS para almacenar los datos de HDInsight, ya que estos se eliminan si elimina el clúster. En su lugar, almacene los datos en Azure. El escalado vertical del clúster también puede agregar más capacidad al clúster de HDInsight.
Nodos perimetrales
¿Puedo agregar un nodo perimetral una vez creado el clúster?
¿Cómo puedo conectarme a un nodo perimetral?
Después de crear un nodo perimetral, puede conectarse a él mediante SSH en el puerto 22. Puede encontrar el nombre del nodo perimetral en el portal del clúster. Los nombres normalmente terminan por -ed.
¿Por qué los scripts persistentes no se ejecutan automáticamente en los nodos perimetrales recién creados?
Los scripts persistentes se usan para personalizar nuevos nodos de trabajo agregados al clúster mediante operaciones de escalado. Los scripts persistentes no se aplican a los nodos perimetrales.
API DE REST
¿Cuáles son las llamadas de la API REST para extraer una vista de consulta de Tez del clúster?
Puede usar los siguientes puntos de conexión REST para extraer la información necesaria en formato JSON. Use los encabezados de autenticación básica para realizar las solicitudes.
-
Tez Query View: https://<nombre del clúster>.azurehdinsight.net/ws/v1/timeline/HIVE_QUERY_ID/ -
Tez Dag View: https://<nombre del clúster>.azurehdinsight.net/ws/v1/timeline/TEZ_DAG_ID/
¿Cómo se recuperan los detalles de configuración del clúster de HDI mediante un usuario de Microsoft Entra?
Para negociar los tokens de autenticación adecuados con el usuario de Microsoft Entra, vaya a través de la puerta de enlace mediante el siguiente formato:
- https://
<cluster dnsname>.azurehdinsight.net/api/v1/clusters/testclusterdem/stack_versions/1/repository_versions/1
Cómo usar la API RESTful de Ambari para supervisar el rendimiento de YARN
Si llama al comando Curl en la misma red virtual o en una red virtual emparejada, el comando es:
curl -u <cluster login username> -sS -G
http://<headnodehost>:8080/api/v1/clusters/<ClusterName>/services/YARN/components/NODEMANAGER?fields=metrics/cpu
Si llama al comando desde fuera de la red virtual o desde una red virtual no emparejada, el formato de comando es:
Para un clúster que no sea ESP:
curl -u <cluster login username> -sS -G https://<ClusterName>.azurehdinsight.net/api/v1/clusters/<ClusterName>/services/YARN/components/NODEMANAGER?fields=metrics/cpuPara un clúster de ESP:
curl -u <cluster login username>-sS -G https://<ClusterName>.azurehdinsight.net/api/v1/clusters/<ClusterName>/services/YARN/components/NODEMANAGER?fields=metrics/cpu
Nota:
Curl le pide una contraseña. Debe escribir una contraseña válida para el nombre de usuario de inicio de sesión del clúster.
Facturación
¿Cuánto cuesta implementar un clúster de HDInsight?
Para más información sobre los precios y las preguntas más frecuentes relacionadas con la facturación, consulte la página Precios de Azure HDInsight.
¿Cuándo se inicia y se detiene la facturación de HDInsight?
La facturación del clúster de HDInsight se inicia una vez creado el clúster y solo se detiene cuando se elimina. La facturación se prorratea por minuto.
¿Cómo cancelo mi suscripción?
Para información sobre cómo cancelar la suscripción, consulte Cancelación de su suscripción de Azure.
En el caso de las suscripciones de pago por uso, ¿qué ocurre después de cancelar mi suscripción?
Para información sobre la suscripción después de su cancelación, consulte ¿Qué ocurre después de cancelar la suscripción?
Hive
¿Por qué aparece la versión de Hive como 1.2.1000 en lugar de 2.1 en la interfaz de usuario de Ambari, a pesar de ejecutar un clúster de HDInsight 3.6?
Aunque solo aparece 1.2 en la interfaz de usuario de Ambari, HDInsight 3.6 contiene Hive 1.2 y Hive 2.1.
Otras preguntas más frecuentes
¿Qué ofrece HDInsight en cuanto a las capacidades de procesamiento de flujos en tiempo real?
Para información sobre las capacidades de integración del procesamiento de flujos, consulte Selección de una tecnología de procesamiento de flujos en Azure.
¿Hay alguna manera de terminar de forma dinámica el nodo principal del clúster cuando este está inactivo durante un período específico?
No se puede hacer esta acción con los clústeres de HDInsight. Puede usar Azure Data Factory para estos escenarios.
¿Qué ofertas de cumplimiento ofrece HDInsight?
Para más información sobre el cumplimiento, consulte el Centro de confianza de Microsoft.