Flujos de trabajo de LLMOps en Azure Databricks
En este artículo se complementan los flujos de trabajo de MLOps en Databricks mediante la adición de información específica de los flujos de trabajo de LLMOps. Para obtener más información, consulte El gran libro de MLOps.
¿Cómo cambia el flujo de trabajo de MLOps para los LLM?
Los LLM son una clase de modelos de procesamiento de lenguaje natural (NLP) que han superado significativamente sus predecesores en tamaño y rendimiento en una variedad de tareas, como la respuesta a preguntas abierta, el resumen y la ejecución de instrucciones.
El desarrollo y la evaluación de los LLM difieren de algunas maneras importantes de los modelos tradicionales de aprendizaje automático. En esta sección se resumen brevemente algunas de las propiedades clave de las VM y las implicaciones de MLOps.
| Propiedades clave de los LLM | Implicaciones para MLOps |
|---|---|
| Los LLM están disponibles en muchos formatos. - Modelos propietarios generales y OSS a los que se accede mediante las API de pago. - Modelos de código abierto estándar que varían de aplicaciones generales a específicas. - Modelos personalizados que se han ajustado para aplicaciones específicas. - Aplicaciones previamente entrenadas personalizadas. |
Proceso de desarrollo: los proyectos suelen desarrollarse de forma incremental, a partir de modelos existentes, de terceros o de código abierto y terminando con modelos personalizados optimizados. |
| Muchas máquinas virtuales toman instrucciones y consultas generales de lenguaje natural como entrada. Esas consultas pueden contener indicaciones cuidadosamente diseñadas para que se cumplan las respuestas deseadas. | Proceso de desarrollo: el diseño de plantillas de texto para consultar los LLM suele ser una parte importante del desarrollo de nuevas canalizaciones LLM. Empaquetado de artefactos de ML: muchas canalizaciones de LLM usan los puntos de conexión de servicio de LLM o LLM existentes. La lógica de aprendizaje automático desarrollada para esas canalizaciones podría centrarse en plantillas de solicitud, agentes o cadenas en lugar del propio modelo. Los artefactos de ML empaquetados y promocionados a producción podrían ser estas canalizaciones, en lugar de modelos. |
| Se pueden proporcionar muchas solicitudes de LLM con ejemplos, contexto u otra información para ayudar a responder a la consulta. | Servicio de infraestructura: al aumentar las consultas LLM con contexto, puede usar herramientas adicionales como bases de datos vectoriales para buscar el contexto pertinente. |
| Las API de terceros proporcionan modelos propietarios y de código abierto. | Gobernanza de API: el uso de la gobernanza de API centralizada proporciona la capacidad de cambiar fácilmente entre proveedores de API. |
| Los LLM son modelos de aprendizaje profundo muy grandes, a menudo van desde gigabytes hasta cientos de gigabytes. | Infraestructura de servicio: los LLM pueden requerir GPU para el servicio de modelos en tiempo real y un almacenamiento rápido para los modelos que deben cargarse dinámicamente. Inconvenientes de costo y rendimiento: dado que los modelos más grandes requieren más cálculo y son más caros de servir, es posible que se requieran técnicas para reducir el tamaño del modelo y el cálculo. |
| Los LLM son difíciles de evaluar mediante las métricas tradicionales de ML, ya que a menudo no hay ninguna respuesta "correcta". | Comentarios humanos: los comentarios humanos son esenciales para evaluar y probar los LLM. Debe incorporar los comentarios de los usuarios directamente en el proceso de MLOps, incluidas las pruebas, la supervisión y el ajuste preciso futuro. |
Semejanzas entre MLOps y LLMOps
Muchos aspectos de los procesos de MLOps no cambian para los LLM. Por ejemplo, las siguientes directrices también se aplican a los LLM:
- Use entornos independientes para el desarrollo, el almacenamiento provisional y la producción.
- Usar Git para el control de versiones.
- Administre el desarrollo de modelos con MLflow y use Modelos en Unity Catalog para administrar el ciclo de vida del modelo.
- Almacene datos en una arquitectura de almacén de lago mediante tablas Delta.
- La infraestructura de CI/CD existente no debe requerir ningún cambio.
- La estructura modular de MLOps sigue siendo la misma, con canalizaciones para caracterización, entrenamiento de modelos, inferencia de modelos, etc.
Diagramas de la arquitectura de referencia
En esta sección se usan dos aplicaciones basadas en LLM para ilustrar algunos de los ajustes de la arquitectura de referencia de MLOps tradicional. Los diagramas muestran la arquitectura de producción para 1) una aplicación de generación aumentada por recuperación (RAG) mediante una API de terceros y 2) una aplicación RAG mediante un modelo ajustado autohospedado. Ambos diagramas muestran una base de datos vectorial opcional: este elemento se puede reemplazar consultando directamente el LLM a través del punto de conexión de servicio del modelo.
RAG con una API de LLM de terceros
En el diagrama se muestra una arquitectura de producción para una aplicación RAG que se conecta a una API de LLM de terceros mediante modelos externos de Databricks.
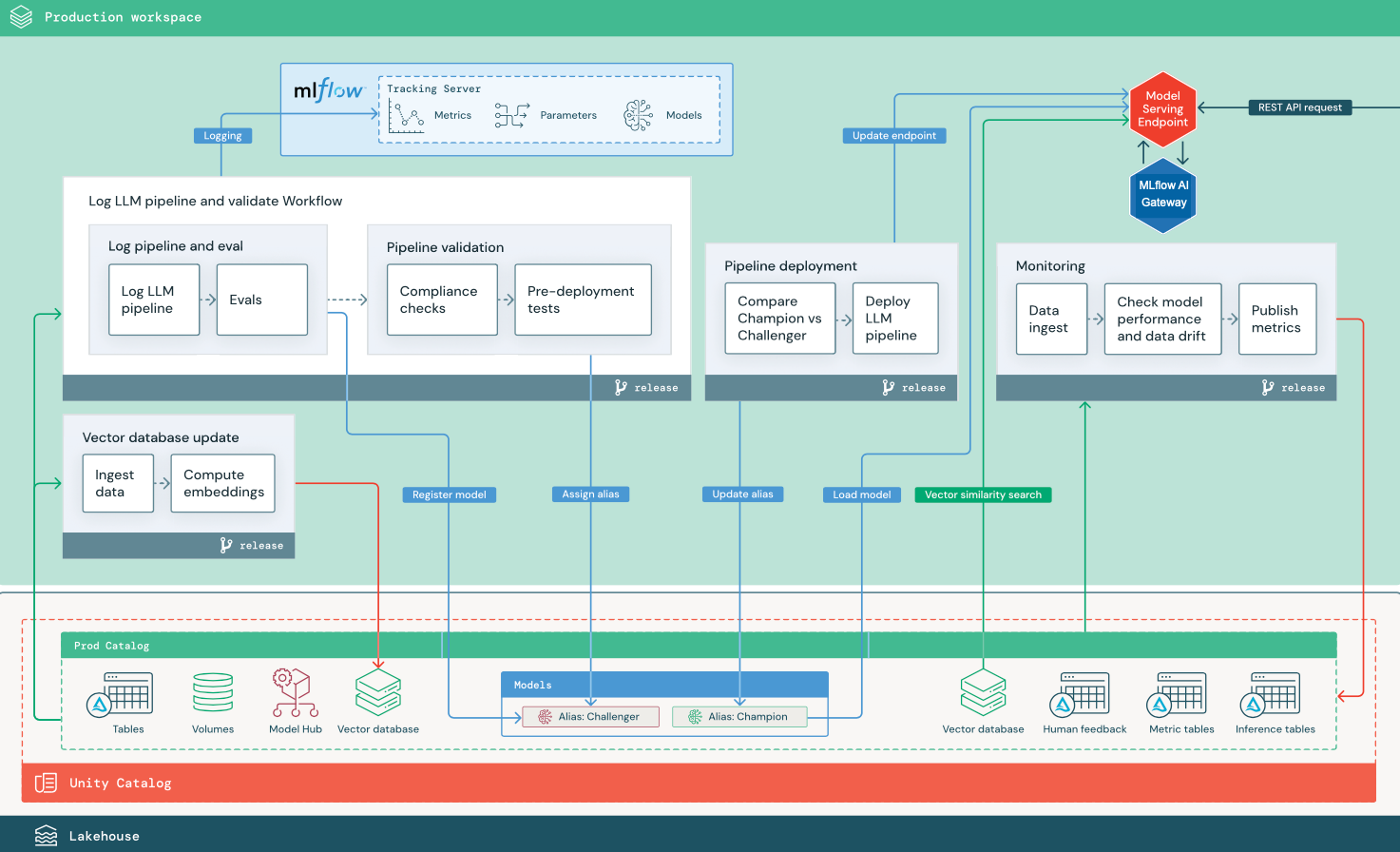
RAG con un modelo de código abierto ajustado
El diagrama muestra una arquitectura de producción para una aplicación RAG que ajusta un modelo de código abierto.
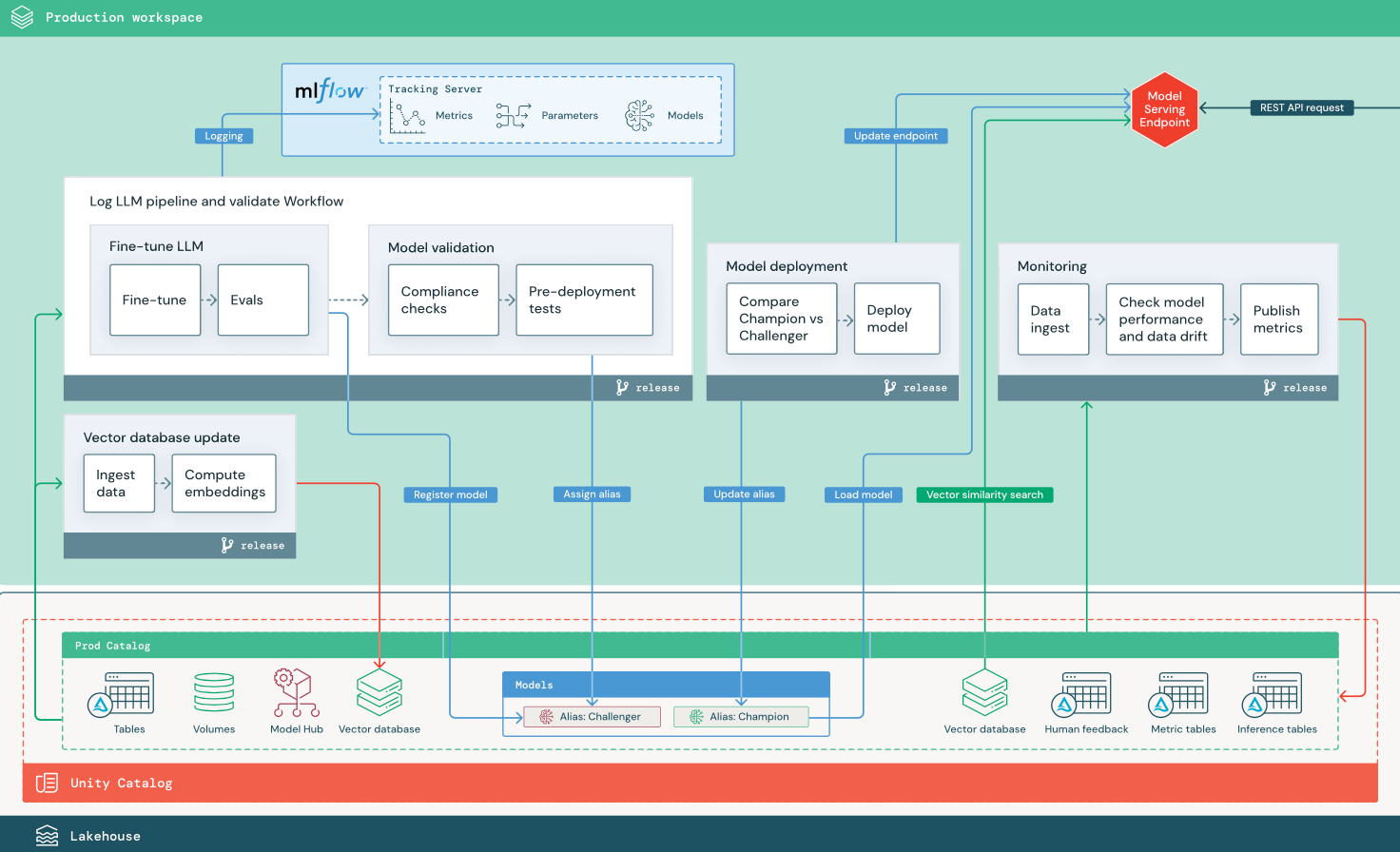
Cambios de LLMOps en la arquitectura de producción de MLOps
En esta sección se resaltan los cambios principales en la arquitectura de referencia de MLOps para aplicaciones LLMOps.
Centro de modelos
Las aplicaciones de LLM suelen usar modelos existentes y entrenados previamente seleccionados desde un centro de modelos interno o externo. El modelo se puede usar tal como está o ajustado.
Databricks incluye una selección de modelos de base de alta calidad y entrenados previamente en el catálogo de Unity y en Databricks Marketplace. Puede usar estos modelos entrenados previamente para acceder a las funcionalidades de inteligencia artificial de última generación, lo que le ahorra tiempo y gastos de creación de sus propios modelos personalizados. Para más información, consulte Modelos entrenados previamente en Unity Catalog y Marketplace.
Base de datos vectorial
Algunas aplicaciones de LLM usan bases de datos vectoriales para búsquedas de similitud rápidas, por ejemplo, para proporcionar conocimientos de contexto o dominio en consultas LLM. Databricks proporciona una funcionalidad de búsqueda vectorial integrada que le permite usar cualquier tabla Delta en el Catálogo de Unity como una base de datos vectorial. El índice de búsqueda vectorial se sincroniza automáticamente con la tabla Delta. Para obtener más información, consulte Búsqueda de vectores.
Puede crear un artefacto de modelo que encapsula la lógica para recuperar información de una base de datos vectorial y proporcionar los datos devueltos como contexto al LLM. A continuación, puede registrar el modelo mediante el tipo MLflow LangChain o PyFunc.
Ajuste de LLM
Dado que los modelos LLM son costosos y lentos de crear desde cero, las aplicaciones de LLM suelen ajustar un modelo existente para mejorar su rendimiento en un escenario determinado. En la arquitectura de referencia, la optimización y la implementación del modelo se representan como distintos trabajos de Databricks. Validar un modelo ajustado antes de implementar suele ser un proceso manual.
Databricks proporciona el ajuste fino de Foundation Model, que permite usar sus propios datos para personalizar un LLM existente para optimizar su rendimiento para su aplicación específica. Para obtener más información, consulte Ajuste fino de Foundation Model.
Servicio de modelos
En el RAG mediante un escenario de API de terceros, un cambio arquitectónico importante es que la canalización de LLM realiza llamadas API externas, desde el punto de conexión de servicio de modelos a las API de LLM internas o de terceros. Esto agrega complejidad, latencia potencial y administración de credenciales adicionales.
Databricks proporciona Mosaic AI Model Serving, que proporciona una interfaz unificada para implementar, controlar y consultar modelos de IA. Para obtener más información, consulte Mosaic AI Model Serving.
Comentarios humanos en la supervisión y evaluación
Los bucles de comentarios humanos son esenciales en la mayoría de las aplicaciones de LLM. Los comentarios humanos deben administrarse como otros datos, idealmente incorporados a la supervisión en función del streaming casi en tiempo real.
La aplicación de revisión de Mosaic AI Agent Framework le ayuda a recopilar comentarios de los revisores humanos. Para obtener más detalles, consulte Obtención de comentarios sobre la calidad de una aplicación de agente.