Flujos de trabajo de MLOps en Azure Databricks
En este artículo se describe cómo puede usar MLOps en la plataforma Databricks para optimizar el rendimiento y la eficacia a largo plazo de los sistemas de aprendizaje automático (ML). Incluye recomendaciones generales para una arquitectura MLOps y describe un flujo de trabajo generalizado mediante la plataforma Databricks que puede usar como modelo para el proceso de desarrollo a producción de ML. Para ver las modificaciones de este flujo de trabajo para aplicaciones LLMOps, consulte Flujos de trabajo de LLMOps.
Para obtener más información, consulte El gran libro de MLOps.
¿Qué es MLOps?
MLOps es un conjunto de procesos y pasos automatizados para administrar código, datos y modelos para mejorar el rendimiento, la estabilidad y la eficacia a largo plazo de los sistemas de ML. Combina DevOps, DataOps y ModelOps.

Los recursos de ML, como el código, los datos y los modelos, se desarrollan en fases que progresan desde las primeras fases de desarrollo que no tienen limitaciones de acceso estrictas y no se prueban rigurosamente, pasando por una fase de prueba intermedia, hasta una fase de producción final que está estrechamente controlada. La plataforma Databricks permite administrar estos recursos en una sola plataforma con control de acceso unificado. Puede desarrollar aplicaciones de datos y aplicaciones de ML en la misma plataforma, lo que reduce los riesgos y retrasos asociados con el movimiento de datos.
Recomendaciones generales para MLOps
En esta sección se incluyen algunas recomendaciones generales para MLOps en Databricks con vínculos para obtener más información.
Creación de un entorno distinto para cada fase
Un entorno de ejecución es el lugar donde el código crea o consume modelos y datos. Cada entorno de ejecución consta de instancias de proceso, sus entornos de ejecución y bibliotecas, y trabajos automatizados.
Databricks recomienda crear entornos distintos para las distintas fases del código de ML y el desarrollo de modelos con transiciones claramente definidas entre fases. El flujo de trabajo descrito en este artículo sigue este proceso, usando los nombres comunes para las fases:
Otras configuraciones también se pueden usar para satisfacer las necesidades específicas de su organización.
Control de acceso y control de versiones
El control de acceso y el control de versiones son componentes clave de cualquier proceso de operaciones de software. Databricks recomienda lo siguiente:
- Usar Git para el control de versiones. Las canalizaciones y el código deben almacenarse en Git para el control de versiones. Mover la lógica de ML entre fases se puede interpretar entonces como mover código de la rama de desarrollo, a la rama de almacenamiento provisional y a la rama de versión. Use Carpetas de Git de Databricks para integrarse con el proveedor de Git y sincronizar cuadernos y código fuente con áreas de trabajo de Databricks. Databricks también proporciona herramientas adicionales para la integración de Git y el control de versiones; consulte Herramientas de desarrollo local.
- Almacene datos en una arquitectura de almacén de lago mediante tablas Delta. Los datos deben almacenarse en una arquitectura de almacén de lago en la cuenta de nube. Tanto los datos sin procesar como las tablas de características deben almacenarse como tablas Delta con controles de acceso para determinar quién puede leerlos y modificarlos.
- Administrar el desarrollo de modelos con MLflow. Puede usar MLflow para realizar un seguimiento del proceso de desarrollo de modelos y guardar instantáneas de código, parámetros de modelo, métricas y otros metadatos.
- Use modelos en Unity Catalog para administrar el ciclo de vida del modelo. Use modelos en Unity Catalog para administrar el estado de implementación, la gobernanza y el control de versiones del modelo.
Implementación de código, no modelos
En la mayoría de las situaciones, Databricks recomienda que, durante el proceso de desarrollo de ML, promueva código, en lugar de modelos, de un entorno a otro. Mover los recursos del proyecto de esta manera garantiza que todo el código del proceso de desarrollo de ML pasa por los mismos procesos de revisión y pruebas de integración del código. También garantiza que la versión de producción del modelo se entrene en el código de producción. Para tener una explicación más detallada de las opciones y desventajas, consulte Patrones de implementación de modelos.
Flujo de trabajo recomendado de MLOps
En las secciones siguientes se describe un flujo de trabajo típico de MLOps, que abarca cada una de las tres fases: desarrollo, ensayo y producción.
En esta sección se usan los términos "científico de datos" e "ingeniero de ML" como roles arquetípicos; los roles y responsabilidades específicos del flujo de trabajo de MLOps varían según cada equipo y organización.
Fase de desarrollo
El enfoque de la fase de desarrollo es la experimentación. Los científicos de datos desarrollan características y modelos y ejecutan experimentos para optimizar el rendimiento del modelo. La salida del proceso de desarrollo es código de canalización de ML que puede incluir el cálculo de características, el entrenamiento de modelos, la inferencia y la supervisión.

Los siguientes pasos numerados corresponden a los números mostrados en el diagrama.
1. Orígenes de datos
El catálogo de desarrollo representa el entorno de desarrollo en Unity Catalog. Los científicos de datos tienen acceso de lectura y escritura al catálogo de desarrollo a medida que crean tablas de características y datos temporales en el área de trabajo de desarrollo. Los modelos creados en la fase de desarrollo se registran en el catálogo de desarrollo.
Idealmente, los científicos de datos que trabajan en el área de trabajo de desarrollo también tienen acceso de solo lectura a los datos de producción en el catálogo de producción. Permitir que los científicos de datos tengan acceso de lectura a datos de producción, tablas de inferencia y tablas de métricas en el catálogo de producción les permite analizar las predicciones y el rendimiento actuales del modelo de producción. Los científicos de datos también deben poder cargar modelos de producción para experimentación y análisis.
Si no es posible conceder acceso de solo lectura al catálogo de producción, se puede escribir una instantánea de datos de producción en el catálogo de desarrollo para permitir que los científicos de datos desarrollen y evalúen el código del proyecto.
2. Análisis exploratorio de datos (EDA)
Los científicos de datos exploran y analizan los datos en un proceso interactivo e iterativo mediante cuadernos. El objetivo es evaluar si los datos disponibles tienen el potencial para resolver el problema empresarial. En este paso, el científico de datos comienza a identificar los pasos de caracterización y preparación de datos para el entrenamiento de modelos. Este proceso ad hoc no forma parte generalmente de una canalización que se implemente en otros entornos de ejecución.
AutoML acelera este proceso mediante la generación de modelos de línea base para un conjunto de datos. AutoML realiza y registra un conjunto de pruebas y proporciona un cuaderno de Python con el código fuente de cada ejecución de prueba para que pueda revisar, reproducir y modificar el código. AutoML también calcula las estadísticas de resumen del conjunto de datos y guarda esta información en un cuaderno que podrá revisar.
3. Código
El repositorio de código contiene todas las canalizaciones, módulos y otros archivos de proyecto para un proyecto de ML. Los científicos de datos crean canalizaciones nuevas o actualizadas en una rama de desarrollo (“dev”) del repositorio del proyecto. A partir del EDA y las fases iniciales de un proyecto, los científicos de datos deben trabajar en un repositorio para compartir código y realizar un seguimiento de los cambios.
4. Entrenamiento de un modelo (desarrollo)
Los científicos de datos desarrollan la canalización de entrenamiento de modelos en el entorno de desarrollo mediante tablas de los catálogos de desarrollo o producción.
Esta canalización incluye 2 tareas:
Entrenamiento y ajuste. El proceso de entrenamiento registra los parámetros, las métricas y los artefactos del modelo en el servidor de seguimiento de MLflow. Después del entrenamiento y ajuste de hiperparámetros, el artefacto final del modelo se registra en el servidor de seguimiento para registrar un vínculo entre el modelo, los datos de entrada en los que se entrenó y el código usado para su generación.
Evaluación. Evalúe la calidad del modelo realizando pruebas sobre los datos mantenidos. Los resultados de estas pruebas se registran en el servidor de seguimiento de MLflow. El propósito de la evaluación es determinar si el modelo recién desarrollado funciona mejor que el modelo de producción actual. Con los permisos suficientes, cualquier modelo de producción registrado en el catálogo de producción se puede cargar en el área de trabajo de desarrollo y comparar con un modelo recién entrenado.
Si los requisitos de gobernanza de la organización incluyen información adicional sobre el modelo, puede guardarla mediante el seguimiento de MLflow. Los artefactos típicos son descripciones de texto sin formato e interpretaciones de modelos, como los trazados producidos por SHAP. Los requisitos de gobernanza específicos pueden provenir de un responsable de gobernanza de datos o de las partes interesadas del negocio.
La salida de la canalización de entrenamiento de modelos es un artefacto del modelo de ML almacenado en el servidor de seguimiento de MLflow para el entorno de desarrollo. Si la canalización se ejecuta en el área de trabajo de ensayo o producción, el artefacto del modelo se almacena en el servidor de seguimiento de MLflow para esa área de trabajo.
Una vez completado el entrenamiento del modelo, regístrelo en Unity Catalog. Configure el código de canalización para registrar el modelo en el catálogo correspondiente al entorno en el que se ejecutó la canalización del modelo; en este ejemplo, el catálogo de desarrollo.
Con la arquitectura recomendada, se implementa un flujo de trabajo de Databricks de varias tareas en el que la primera tarea es la canalización de entrenamiento de modelos, seguida de las tareas de validación e implementación de modelos. La tarea de entrenamiento de modelos da como resultado un URI del modelo que puede usar la tarea de validación de modelos. Puede usar valores de tarea para pasar este URI al modelo.
5. Validación e implementación de un modelo (desarrollo)
Además de la canalización de entrenamiento de modelos, otras canalizaciones como las de validación e implementación de modelos se desarrollan en el entorno de desarrollo.
Validación del modelo. La canalización de validación de modelos toma el URI del modelo de la canalización de entrenamiento de modelos, carga el modelo desde Unity Catalog y ejecuta comprobaciones de validación.
Las comprobaciones de validación dependen del contexto. Pueden incluir comprobaciones fundamentales, como confirmar el formato y los metadatos necesarios, y comprobaciones más complejas que podrían requerirse para sectores muy regulados, como comprobaciones de cumplimiento predefinidas, y confirmar el rendimiento del modelo en segmentos de datos seleccionados.
La función principal de la canalización de validación de modelos es determinar si un modelo debe continuar con el paso de implementación. Si el modelo supera las comprobaciones previas a la implementación, se le puede asignar el alias “Challenger” en Unity Catalog. Si se produce un error en las comprobaciones, el proceso finalizará. Puede configurar el flujo de trabajo para notificar a los usuarios un error de validación. Consulta Incorporación de notificaciones en un trabajo.
Implementación del modelo. Normalmente, la canalización de implementación de modelos promueve directamente el modelo “Challenger” recién entrenado al estado “Champion” mediante una actualización de alias, o bien facilita una comparación entre el modelo “Champion” existente” y el nuevo modelo “Challenger”. Esta canalización también puede configurar cualquier infraestructura de inferencia necesaria, como los puntos de conexión de servicio de modelos. Para obtener una descripción detallada de los pasos implicados en la canalización de implementación de modelos, consulte Producción.
6. Confirmación del código
Después de desarrollar código para entrenamiento, validación, implementación y otras canalizaciones, el científico de datos o el ingeniero de ML confirma los cambios de la rama de desarrollo en el control de código fuente.
Fase de ensayo
El objetivo de esta fase es probar el código de canalización de ML para asegurarse de que está listo para producción. Todo el código de canalización de ML se prueba en esta fase, incluido el código para el entrenamiento del modelo, así como las canalizaciones de caracterización, el código de inferencia, etc.
Los ingenieros de ML crean una canalización de CI para implementar las pruebas unitarias y de integración que se ejecutan en esta fase. La salida del proceso de ensayo es una rama de versión que desencadena el sistema de CI/CD para iniciar la fase de producción.
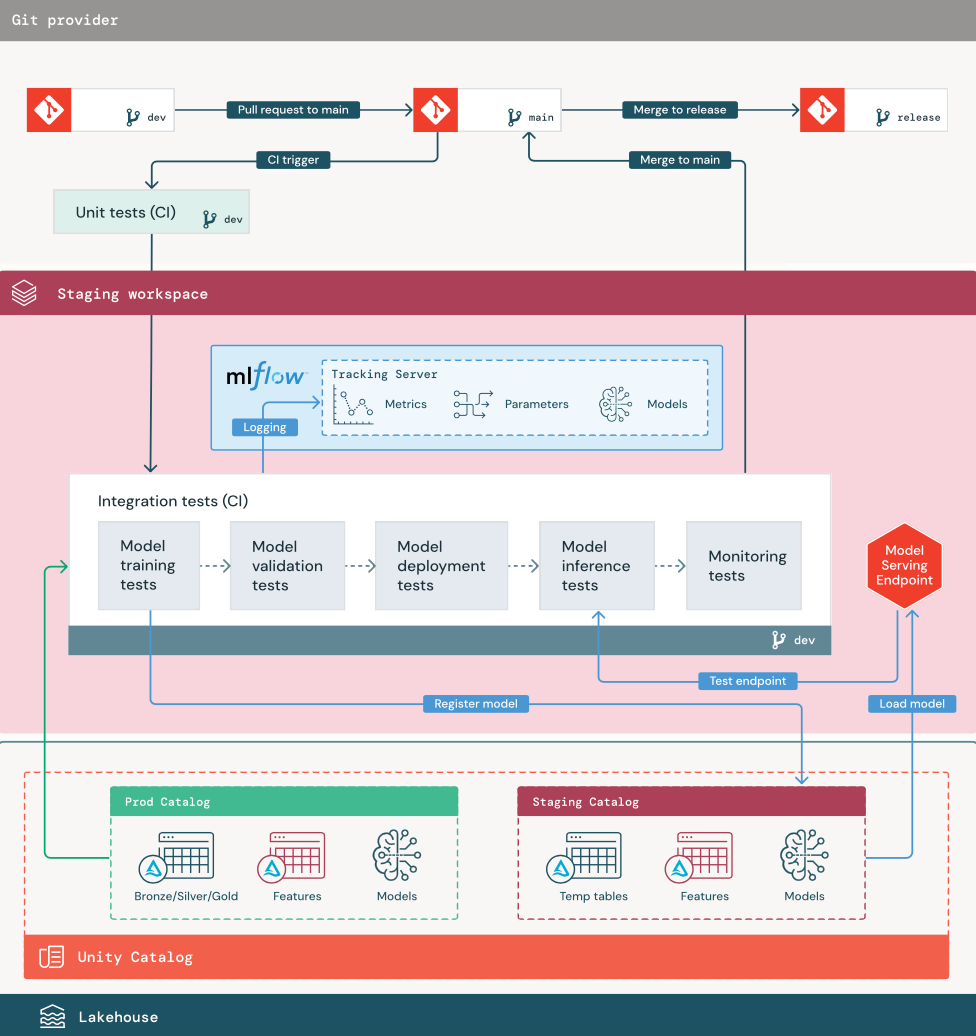
1. data
El entorno de ensayo debe tener su propio catálogo en Unity Catalog para probar canalizaciones de ML y registrar modelos en Unity Catalog. Este catálogo se muestra como catálogo de “ensayo” en el diagrama. Los recursos escritos en este catálogo suelen ser temporales y solo se conservan hasta que se completan las pruebas. El entorno de desarrollo también puede requerir acceso al catálogo de ensayo con fines de depuración.
2. Combinación de código
Los científicos de datos desarrollan la canalización de entrenamiento de modelos en el entorno de desarrollo mediante tablas de los catálogos de desarrollo o producción.
Solicitud de incorporación de cambios. El proceso de implementación comienza cuando se crea una solicitud de cambios en la rama principal del proyecto en el control de código fuente.
Pruebas unitarias (CI). La solicitud de cambios compila automáticamente el código fuente y desencadena pruebas unitarias. Si se produce un error en las pruebas unitarias, se rechaza la solicitud de cambios.
Las pruebas unitarias forman parte del proceso de desarrollo de software y se ejecutan y agregan continuamente al código base durante el desarrollo de cualquier código. La ejecución de pruebas unitarias como parte de una canalización de CI garantiza que los cambios realizados en una rama de desarrollo no interrumpan la funcionalidad existente.
3. Pruebas de integración (CI)
A continuación, en el proceso de CI se ejecutan las pruebas de integración. Las pruebas de integración ejecutan todas las canalizaciones (incluida la caracterización, el entrenamiento del modelo, la inferencia y la supervisión) para asegurarse de que funcionan correctamente juntas. El entorno de ensayo debe coincidir con el entorno de producción lo más razonablemente posible.
Si va a implementar una aplicación de ML con inferencia en tiempo real, debe crear y probar la infraestructura de servicio en el entorno de ensayo. Esto implica desencadenar la canalización de implementación de modelos, que crea un punto de conexión de servicio en el entorno de ensayo y carga un modelo.
Para reducir el tiempo necesario para ejecutar pruebas de integración, se puede buscar un equilibrio entre la fidelidad de las pruebas y la velocidad o el costo en algunos pasos. Por ejemplo, si los modelos son costosos o tardan mucho tiempo en entrenar, puede usar pequeños subconjuntos de datos o ejecutar menos iteraciones de entrenamiento. Para el servicio de modelos, en función de los requisitos de producción, puede realizar pruebas de carga a escala completa en pruebas de integración, o simplemente probar trabajos por lotes pequeños o solicitudes a un punto de conexión temporal.
4. Combinación con la rama de ensayo
Si se superan todas las pruebas, el nuevo código se combina en la rama principal del proyecto. Si se produce un error en las pruebas, el sistema de CI/CD debe notificarlo a los usuarios y publicar los resultados en la solicitud de cambios.
Puede programar pruebas de integración periódicas en la rama principal. Esta es una buena idea si la rama se actualiza con frecuencia con solicitudes de cambios simultáneas de varios usuarios.
5. Creación de una rama de versión
Una vez superadas las pruebas de CI y combinada la rama de desarrollo en la rama principal, el ingeniero de ML crea una rama de versión, que desencadena el sistema de CI/CD para actualizar los trabajos de producción.
Fase de producción
Los ingenieros de ML poseen el entorno de producción, donde se implementan y ejecutan las canalizaciones de ML. Estas canalizaciones desencadenan el entrenamiento de modelos, validan e implementan nuevas versiones del modelo, publican predicciones en tablas o aplicaciones de bajada y supervisan todo el proceso para evitar la degradación del rendimiento y la inestabilidad.
Normalmente, los científicos de datos no tienen acceso de escritura o proceso en el entorno de producción. Sin embargo, es importante que tengan visibilidad sobre los resultados de las pruebas, los registros, los artefactos del modelo, el estado de la canalización de producción y las tablas de supervisión. Esta visibilidad les permite identificar y diagnosticar problemas en producción, además de comparar el rendimiento de nuevos modelos con modelos actualmente en producción. Puede conceder a los científicos de datos acceso de solo lectura a los recursos del catálogo de producción para estos fines.
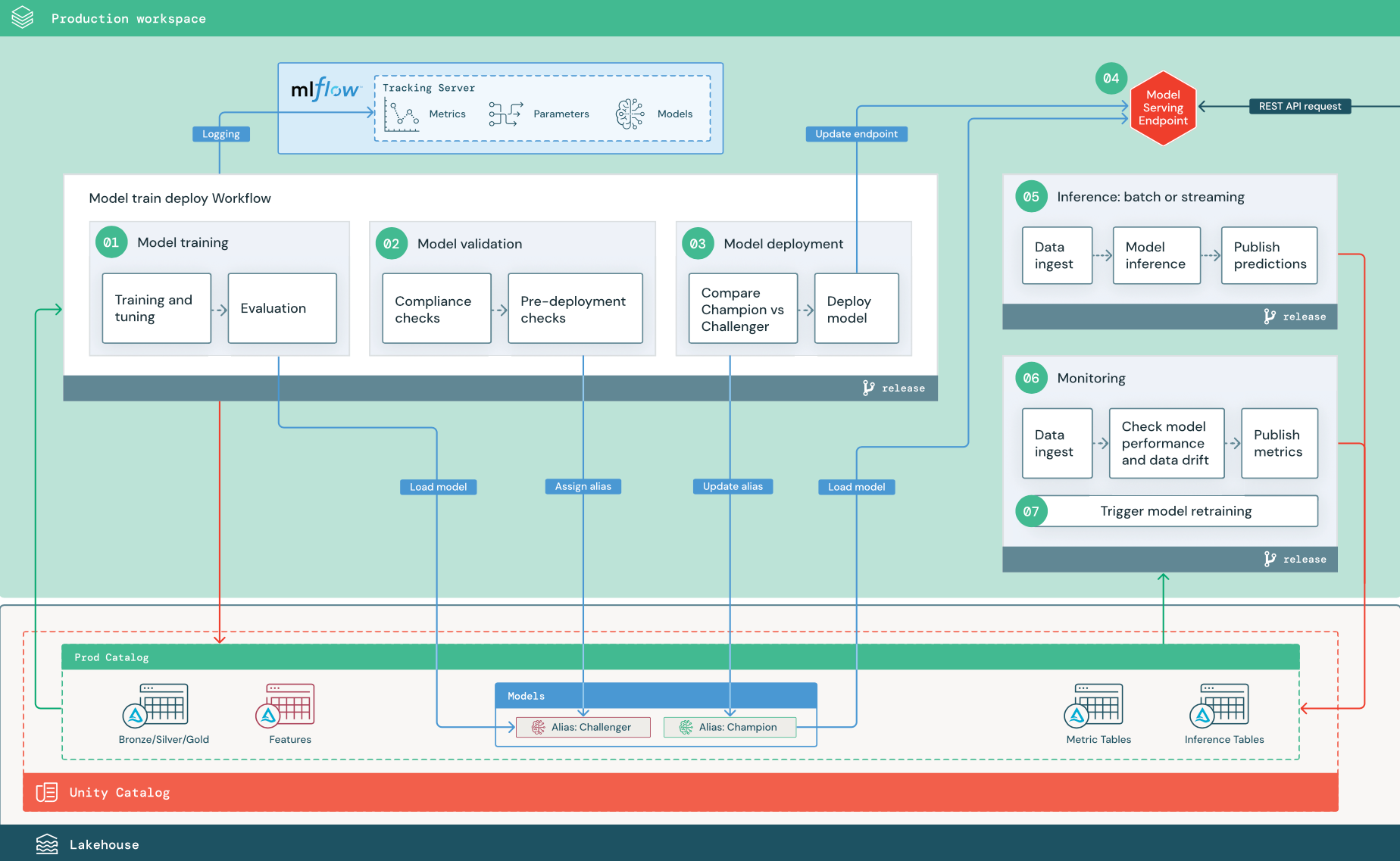
Los siguientes pasos numerados corresponden a los números mostrados en el diagrama.
1. Entrenamiento de un modelo
Esta canalización se puede desencadenar mediante cambios en el código o mediante trabajos de reentrenamiento automatizados. En este paso, se usan tablas del catálogo de producción para los pasos siguientes.
Entrenamiento y ajuste. Durante el proceso de entrenamiento, los registros se registran en el servidor de seguimiento de MLflow del entorno de producción. Estos registros incluyen métricas, parámetros y etiquetas del modelo y el propio modelo. Si usa tablas de características, el modelo se registra en MLflow mediante el cliente del Almacén de características de Databricks, que empaqueta el modelo con información de búsqueda de características que se usa en el momento de la inferencia.
Durante el desarrollo, los científicos de datos pueden probar muchos algoritmos e hiperparámetros. En el código de entrenamiento de producción, es habitual tener en cuenta solo las opciones de alto rendimiento. Limitar el ajuste de esta manera ahorra tiempo y puede reducir la varianza del ajuste en el reentrenamiento automatizado.
Si los científicos de datos tienen acceso de solo lectura al catálogo de producción, es posible que puedan determinar el conjunto óptimo de hiperparámetros para un modelo. En este caso, la canalización de entrenamiento de modelos implementada en producción se puede ejecutar mediante el conjunto seleccionado de hiperparámetros, que normalmente se incluye en la canalización como archivo de configuración.
Evaluación. La calidad del modelo se evalúa realizando pruebas sobre datos de producción mantenidos. Los resultados de estas pruebas se registran en el servidor de seguimiento de MLflow. En este paso se usan las métricas de evaluación especificadas por los científicos de datos en la fase de desarrollo. Estas métricas pueden incluir código personalizado.
Registro del modelo. Una vez completado el entrenamiento del modelo, el artefacto del modelo se guarda como versión del modelo registrada en la ruta de acceso del modelo especificada en el catálogo de producción en Unity Catalog. La tarea de entrenamiento de modelos da como resultado un URI del modelo que puede usar la tarea de validación de modelos. Puede usar valores de tarea para pasar este URI al modelo.
2. Validación de un modelo
Esta canalización usa el URI del modelo del paso 1 y carga el modelo desde Unity Catalog. A continuación, ejecuta una serie de comprobaciones de validación. Estas comprobaciones dependen de su organización y caso de uso, y pueden incluir elementos como validaciones de metadatos y formato básicas, evaluaciones de rendimiento de segmentos de datos seleccionados y cumplimiento de requisitos de la organización, como comprobaciones de cumplimiento de etiquetas o documentación.
Si el modelo supera correctamente todas las comprobaciones de validación, puede asignar el alias “Challenger” a la versión del modelo en Unity Catalog. Si el modelo no supera todas las comprobaciones de validación, el proceso se cierra y los usuarios pueden recibir notificaciones automáticas. Puede usar etiquetas para agregar atributos de clave-valor en función del resultado de estas comprobaciones de validación. Por ejemplo, podría crear una etiqueta “model_validation_status” y establecer el valor en “PENDIENTE” a medida que se ejecuten las pruebas y, a continuación, actualizarlo a “SUPERADA” o “NO SUPERADA” cuando se complete la canalización.
Dado que el modelo está registrado en Unity Catalog, los científicos de datos que trabajan en el entorno de desarrollo pueden cargar esta versión del modelo desde el catálogo de producción para investigar si el modelo produce un error en la validación. Independientemente del resultado, los resultados se registran en el modelo registrado en el catálogo de producción mediante anotaciones en la versión del modelo.
3. Implementación de un modelo
Al igual que la canalización de validación, la canalización de implementación de modelos depende de su organización y caso de uso. En esta sección se supone que ha asignado al modelo recién validado el alias “Challenger” y que se ha asignado el alias “Champion” al modelo de producción existente. El primer paso antes de implementar el nuevo modelo es confirmar que funciona al menos igual de bien que el modelo de producción actual.
Compare el modelo “CHALLENGER” con el modelo “CHAMPION”. Puede realizar esta comparación sin conexión o en línea. Una comparación sin conexión evalúa ambos modelos en un conjunto de datos mantenido y realiza un seguimiento de los resultados mediante el servidor de seguimiento de MLflow. Para el servicio de modelos en tiempo real, es posible que desee realizar comparaciones en línea de larga duración, como pruebas A/B o un lanzamiento gradual del nuevo modelo. Si la versión del modelo “Challenger” funciona mejor en la comparación, sustituye el alias “Champion” actual.
El servicio de modelos de Mosaic AI y la supervisión de Databricks Lakehouse permiten recopilar y supervisar automáticamente tablas de inferencia que contienen datos de solicitud y respuesta para un punto de conexión.
Si no existe ningún modelo “Champion”, puede comparar el modelo “Challenger” con una heurística empresarial u otro umbral como base de referencia.
El proceso descrito aquí está totalmente automatizado. Si se requieren pasos de aprobación manuales, puede configurarlos mediante notificaciones de flujo de trabajo o devoluciones de llamada de CI/CD desde la canalización de implementación de modelos.
Implementar modelo. Las canalizaciones de inferencia por lotes o de streaming se pueden configurar para usar el modelo con el alias “Champion”. Para los casos de uso en tiempo real, debe configurar la infraestructura para implementar el modelo como punto de conexión de la API REST. Puede crear y administrar este punto de conexión mediante servicio de modelos de Mosaic AI. Si un punto de conexión ya está en uso para el modelo actual, puede actualizar el punto de conexión con el nuevo modelo. Servicio de modelos de Mosaic AI ejecuta una actualización sin tiempo de inactividad manteniendo la configuración existente en ejecución hasta que la nueva esté lista.
4. Servicio de modelos
Al configurar un punto de conexión del servicio de modelos, se especifica el nombre del modelo en Unity Catalog y la versión que se va a servir. Si la versión del modelo se ha entrenado mediante características de tablas en Unity Catalog, el modelo almacena las dependencias para las características y funciones. El servicio de modelos usa automáticamente este gráfico de dependencias para buscar características de las tiendas en línea adecuadas en el momento de la inferencia. Este enfoque también se puede usar para aplicar funciones para el preprocesamiento de datos o para calcular características a petición durante la puntuación del modelo.
Puede crear un único punto de conexión con varios modelos y especificar la división del tráfico del punto de conexión entre esos modelos, lo que le permite realizar comparaciones en línea entre “Champion” y “Challenger”.
5. Inferencia: procesamiento por lotes o streaming
La canalización de inferencia lee los datos más recientes del catálogo de producción, ejecuta funciones para calcular características a petición, carga el modelo “Champion”, puntúa los datos y devuelve predicciones. La inferencia por lotes o streaming suele ser la opción más rentable para casos de uso de mayor rendimiento y mayor latencia. Para escenarios en los que se requieren predicciones de baja latencia, pero estas se pueden calcular sin conexión, estas predicciones por lotes se pueden publicar en un almacén de clave-valor en línea, como DynamoDB o Cosmos DB.
El alias del modelo registrado en Unity Catalog le hace referencia. La canalización de inferencia está configurada para cargar y aplicar la versión del modelo “Champion”. Si la versión "Champion" se actualiza a una nueva versión del modelo, la canalización de inferencia usa automáticamente la nueva versión para su siguiente ejecución. De este modo, el paso de implementación de modelos está desacoplado de las canalizaciones de inferencia.
Normalmente, los trabajos por lotes publican predicciones en tablas del catálogo de producción, en archivos planos o a través de una conexión JDBC. Los trabajos de streaming suelen publicar predicciones en tablas de Unity Catalog o en colas de mensajes como Apache Kafka.
6. Supervisión de Lakehouse
La supervisión de Lakehouse supervisa propiedades estadísticas como, por ejemplo, el desfase de datos y el rendimiento del modelo, de los datos de entrada y las predicciones de modelos. Puede crear alertas basadas en estas métricas o publicarlas en paneles.
- Ingesta de datos. Esta canalización lee los registros de la inferencia por lotes, de streaming o en línea.
- Comprobación de la precisión y el desfase de datos. La canalización calcula métricas sobre los datos de entrada, las predicciones del modelo y el rendimiento de la infraestructura. Los científicos de datos especifican datos y métricas de modelo durante el desarrollo y los ingenieros de ML especifican métricas de infraestructura. También puede definir métricas personalizadas con la supervisión de Lakehouse.
- Publique métricas y configure alertas. La canalización escribe en tablas del catálogo de producción para el análisis y la creación de informes. Debe configurar estas tablas para que sean legibles desde el entorno de desarrollo de modo que los científicos de datos tengan acceso para su análisis. Puede usar Databricks SQL para crear paneles de supervisión para realizar un seguimiento del rendimiento del modelo y configurar el trabajo de supervisión o la herramienta de panel para emitir una notificación cuando una métrica supere un umbral especificado.
- Desencadene el reentrenamiento del modelo. Cuando las métricas de supervisión indican problemas de rendimiento o cambios en los datos de entrada, es posible que el científico de datos tenga que desarrollar una nueva versión del modelo. Puede configurar alertas SQL para notificar a los científicos de datos cuando esto ocurra.
7. Reentrenamiento
Esta arquitectura admite el reentrenamiento automático mediante la misma canalización de entrenamiento de modelos anterior. Databricks recomienda comenzar con un reentrenamiento programado y periódico, y migrar a un reentrenamiento desencadenado cuando sea necesario.
- Programado. Si hay disponibles nuevos datos periódicamente, puede crear un trabajo programado para ejecutar el código de entrenamiento del modelo sobre los datos disponibles más recientes. Consulte Automatización de trabajos con programaciones y desencadenadores
- Desencadenado. Si la canalización de supervisión puede identificar problemas de rendimiento del modelo y enviar alertas, también puede desencadenar el reentrenamiento. Por ejemplo, si la distribución de los datos entrantes cambia significativamente o el rendimiento del modelo empeora, el reentrenamiento y la reimplementación automáticos pueden mejorar el rendimiento del modelo con una intervención humana mínima. Esto se puede lograr mediante una alerta SQL para comprobar si una métrica es anómala (por ejemplo, comprobar el desfase o la calidad del modelo en relación con un umbral). La alerta se puede configurar para usar un destino de webhook, que posteriormente puede desencadenar el flujo de trabajo de entrenamiento.
Si la canalización de reentrenamiento u otras canalizaciones presentan problemas de rendimiento, es posible que el científico de datos tenga que volver al entorno de desarrollo a modo de prueba adicional para solucionar los problemas.