Introducción: Mejora y limpieza de datos
Este artículo de introducción le guiará a través del uso de un cuaderno Azure Databricks para limpiar y mejorar los datos de nombres de bebés del Estado de Nueva York que se cargaron previamente en una tabla en Unity Catalog mediante el uso de Python, Scala y R. En este artículo, cambiará los nombres de las columnas, cambiará las mayúsculas y escribirá el sexo de cada nombre de bebé de la tabla de datos sin procesar y, a continuación, guardará el DataFrame en una tabla silver. Después, filtre los datos para incluir solo los de 2021, agrupe los datos a nivel estatal y ordene los datos por recuento. Por último, guarde este DataFrame en una tabla gold y visualice los datos en un gráfico de barras. Para más información sobre las tablas de plata y oro, consulte medallion architecture.
Importante
Este artículo de introducción se basa en Introducción: Ingesta e inserción de datos adicionales. Debe completar los pasos descritos en ese artículo para completar este artículo. Para obtener el cuaderno completo para ese artículo de introducción, consulte Ingesta de cuadernos de datos adicionales.
Requisitos
Para completar las tareas de este artículo, debe cumplir los siguientes requisitos:
- El área de trabajo debe tener habilitado para Unity Catalog. Para obtener información sobre cómo empezar a trabajar con Unity Catalog, vea Configuración y administración del Unity Catalog.
- Debe tener el privilegio
WRITE VOLUMEen un volumen, el privilegioUSE SCHEMAen el esquema principal y el privilegioUSE CATALOGen el catálogo principal. - Debe tener permiso para usar un recurso de proceso existente o crear un nuevo recurso de proceso. Consulte Introducción a Azure Databricks o consulte el administrador de Databricks.
Sugerencia
Para obtener un cuaderno completado para este artículo, consulte Limpiar y mejorar los cuadernos de datos.
Paso 1: Crear un nuevo cuaderno
Para crear un cuaderno en el área de trabajo, haga clic en ![]() Nuevo en la barra lateral y a continuación, haga clic en Cuaderno. Se abre un cuaderno en blanco en el área de trabajo.
Nuevo en la barra lateral y a continuación, haga clic en Cuaderno. Se abre un cuaderno en blanco en el área de trabajo.
Para obtener más información sobre cómo crear y administrar cuadernos, consulte Administración de cuadernos.
Paso 2: Definir variables
En este paso, definirá variables para su uso en el cuaderno de ejemplo que cree en este artículo.
Copie y pegue el código siguiente en la celda del nuevo cuaderno vacío. Reemplace
<catalog-name>,<schema-name>y<volume-name>por los nombres de catálogo, esquema y volumen de un volumen de Unity Catalog. De manera opcional, reemplace el valortable_namepor un nombre de la tabla de su elección. Guardará los datos del nombre del bebé en esta tabla más adelante en este artículo.Presione
Shift+Enterpara ejecutar la celda y crear una nueva celda en blanco.Python
catalog = "<catalog_name>" schema = "<schema_name>" table_name = "baby_names" silver_table_name = "baby_names_prepared" gold_table_name = "top_baby_names_2021" path_table = catalog + "." + schema print(path_table) # Show the complete pathScala
val catalog = "<catalog_name>" val schema = "<schema_name>" val tableName = "baby_names" val silverTableName = "baby_names_prepared" val goldTableName = "top_baby_names_2021" val pathTable = s"${catalog}.${schema}" print(pathTable) // Show the complete pathR
catalog <- "<catalog_name>" schema <- "<schema_name>" volume <- "<volume_name>" table_name <- "baby_names" silver_table_name <- "baby_names_prepared" gold_table_name <- "top_baby_names_2021" path_table <- paste(catalog, ".", schema, sep = "") print(path_table) # Show the complete path
Paso 3: Cargar los datos sin procesar en un nuevo DataFrame
En este paso se cargan los datos sin procesar guardados anteriormente en una tabla Delta en un nuevo DataFrame como preparación para la limpieza y mejora de estos datos para su posterior análisis.
Copie y pegue el código siguiente en la celda del nuevo cuaderno vacío.
Python
df_raw = spark.read.table(f"{path_table}.{table_name}") display(df_raw)Scala
val dfRaw = spark.read.table(s"${pathTable}.${tableName}") display(dfRaw)R
# Load the SparkR package that is already preinstalled on the cluster. library(SparkR) df_raw = sql(paste0("SELECT * FROM ", path_table, ".", table_name)) display(df_raw)Presione
Shift+Enterpara ejecutar la celda y, a continuación, vaya a la celda siguiente.
Paso 4: Limpiar y mejorar los datos sin procesar y guardar
En este paso, se cambia el nombre de la columna Year, se cambian los datos de la columna First_Name a mayúsculas iniciales y se actualizan los valores de la columna Sex a la ortografía del sexo y, a continuación, se guarda DataFrame en una nueva tabla.
Copie y pegue el código siguiente en una celda de cuaderno vacía.
Python
from pyspark.sql.functions import col, initcap, when # Rename "Year" column to "Year_Of_Birth" df_rename_year = df_raw.withColumnRenamed("Year", "Year_Of_Birth") # Change the case of "First_Name" column to initcap df_init_caps = df_rename_year.withColumn("First_Name", initcap(col("First_Name").cast("string"))) # Update column values from "M" to "male" and "F" to "female" df_baby_names_sex = df_init_caps.withColumn( "Sex", when(col("Sex") == "M", "Male") .when(col("Sex") == "F", "Female") ) # display display(df_baby_names_sex) # Save DataFrame to table df_baby_names_sex.write.mode("overwrite").saveAsTable(f"{path_table}.{silver_table_name}")Scala
import org.apache.spark.sql.functions.{col, initcap, when} // Rename "Year" column to "Year_Of_Birth" val dfRenameYear = dfRaw.withColumnRenamed("Year", "Year_Of_Birth") // Change the case of "First_Name" data to initial caps val dfNameInitCaps = dfRenameYear.withColumn("First_Name", initcap(col("First_Name").cast("string"))) // Update column values from "M" to "Male" and "F" to "Female" val dfBabyNamesSex = dfNameInitCaps.withColumn("Sex", when(col("Sex") equalTo "M", "Male") .when(col("Sex") equalTo "F", "Female")) // Display the data display(dfBabyNamesSex) // Save DataFrame to a table dfBabyNamesSex.write.mode("overwrite").saveAsTable(s"${pathTable}.${silverTableName}")R
# Rename "Year" column to "Year_Of_Birth" df_rename_year <- withColumnRenamed(df_raw, "Year", "Year_Of_Birth") # Change the case of "First_Name" data to initial caps df_init_caps <- withColumn(df_rename_year, "First_Name", initcap(df_rename_year$First_Name)) # Update column values from "M" to "Male" and "F" to "Female" df_baby_names_sex <- withColumn(df_init_caps, "Sex", ifelse(df_init_caps$Sex == "M", "Male", ifelse(df_init_caps$Sex == "F", "Female", df_init_caps$Sex))) # Display the data display(df_baby_names_sex) # Save DataFrame to a table saveAsTable(df_baby_names_sex, paste(path_table, ".", silver_table_name), mode = "overwrite")Presione
Shift+Enterpara ejecutar la celda y, a continuación, vaya a la celda siguiente.
Paso 5: Agrupar y visualizar datos
En este paso, se filtran los datos solo al año 2021, se agrupan los datos por sexo y nombre, se agregan por recuento y se ordenan por recuento. A continuación, guarde el DataFrame en una tabla y visualice los datos en un gráfico de barras.
Copie y pegue el código siguiente en una celda de cuaderno vacía.
Python
from pyspark.sql.functions import expr, sum, desc from pyspark.sql import Window # Count of names for entire state of New York by sex df_baby_names_2021_grouped=(df_baby_names_sex .filter(expr("Year_Of_Birth == 2021")) .groupBy("Sex", "First_Name") .agg(sum("Count").alias("Total_Count")) .sort(desc("Total_Count"))) # Display data display(df_baby_names_2021_grouped) # Save DataFrame to a table df_baby_names_2021_grouped.write.mode("overwrite").saveAsTable(f"{path_table}.{gold_table_name}")Scala
import org.apache.spark.sql.functions.{expr, sum, desc} import org.apache.spark.sql.expressions.Window // Count of male and female names for entire state of New York by sex val dfBabyNames2021Grouped = dfBabyNamesSex .filter(expr("Year_Of_Birth == 2021")) .groupBy("Sex", "First_Name") .agg(sum("Count").alias("Total_Count")) .sort(desc("Total_Count")) // Display data display(dfBabyNames2021Grouped) // Save DataFrame to a table dfBabyNames2021Grouped.write.mode("overwrite").saveAsTable(s"${pathTable}.${goldTableName}")R
# Filter to only 2021 data df_baby_names_2021 <- filter(df_baby_names_sex, df_baby_names_sex$Year_Of_Birth == 2021) # Count of names for entire state of New York by sex df_baby_names_grouped <- agg( groupBy(df_baby_names_2021, df_baby_names_2021$Sex, df_baby_names_2021$First_Name), Total_Count = sum(df_baby_names_2021$Count) ) # Display data display(arrange(select(df_baby_names_grouped, df_baby_names_grouped$Sex, df_baby_names_grouped$First_Name, df_baby_names_grouped$Total_Count), desc(df_baby_names_grouped$Total_Count))) # Save DataFrame to a table saveAsTable(df_baby_names_2021_grouped, paste(path_table, ".", gold_table_name), mode = "overwrite")Presione
Ctrl+Enterpara ejecutar la celda.-
- Junto a la pestaña Tabla, haga clic + y, a continuación, haga clic en Visualización.
En el editor de visualización, haga clic en Tipo de visualización y compruebe que está seleccionado barra.
En la columna X, seleccione
First_Name.Haga clic en Agregar columna en columnas Y y, a continuación, seleccione Total_Count.
En Agrupar por, seleccione Sexo.
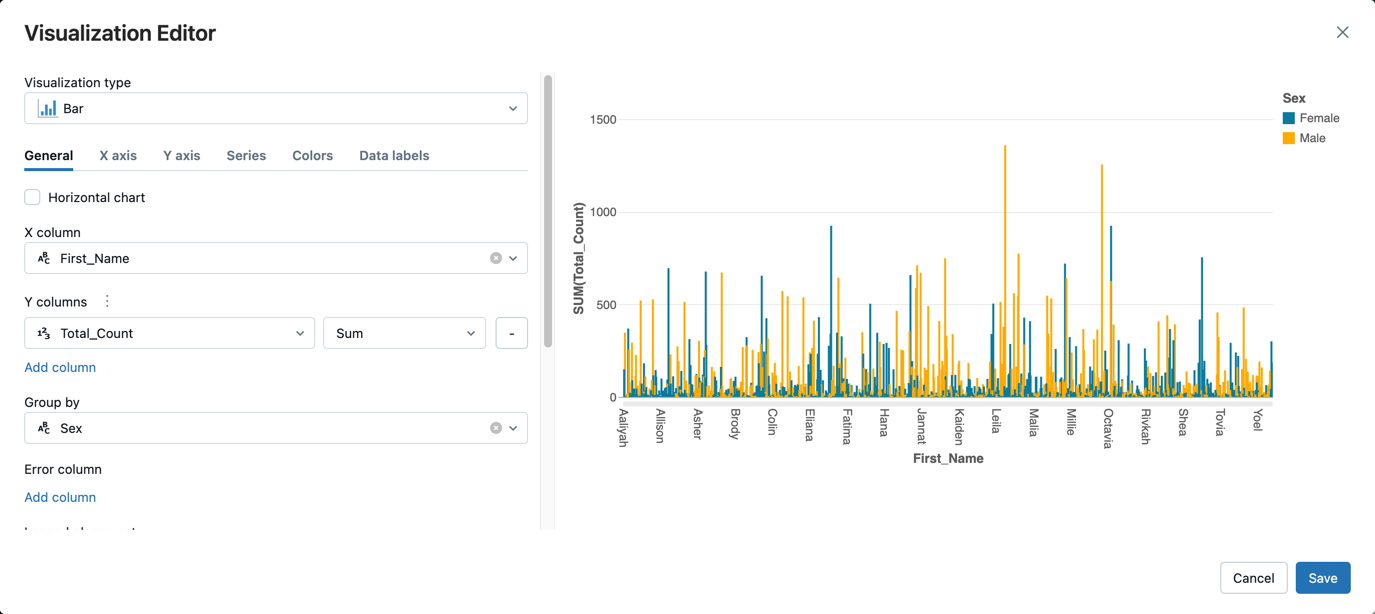
Haga clic en Save(Guardar).
Limpiar y mejorar cuadernos de datos
Use uno de los siguientes cuadernos para realizar los pasos descritos en este artículo. Reemplace <catalog-name>, <schema-name> y <volume-name> por los nombres de catálogo, esquema y volumen de un volumen de Unity Catalog. De manera opcional, reemplace el valor table_name por un nombre de la tabla de su elección.