¿Qué es la arquitectura de medallón de Lakehouse?
La arquitectura de medallón describe una serie de capas de datos que denotan la calidad de los datos almacenados en Lakehouse. Azure Databricks recomienda adoptar un enfoque multicapa para crear una única fuente de verdad para los productos de datos empresariales.
Esta arquitectura garantiza la atomicidad, la coherencia, el aislamiento y la durabilidad a medida que los datos pasan por varias capas de validaciones y transformaciones antes de almacenarse en un diseño optimizado para un análisis eficiente. Los términos bronce (sin procesar), plata (validado) y oro (enriquecido) describen la calidad de los datos en cada una de estas capas.
Arquitectura de Medallion como patrón de diseño de datos
Una arquitectura medallion es un patrón de diseño de datos que se usa para organizar los datos lógicamente. Su objetivo es mejorar de forma incremental y progresiva la estructura y la calidad de los datos a medida que fluye a través de cada capa de la arquitectura (desde las tablas de capa Bronze ⇒ Silver ⇒ Gold). Las arquitecturas de Medallion a veces también se conocen como arquitecturas de varios saltos.
Al avanzar los datos a través de estas capas, las organizaciones pueden mejorar incrementalmente la calidad y la confiabilidad de los datos, lo que hace que sea más adecuado para las aplicaciones de inteligencia empresarial y aprendizaje automático.
Siguiendo la arquitectura de medallion es un procedimiento recomendado, pero no un requisito.
| Pregunta | Bronce | Plata | Oro |
|---|---|---|---|
| ¿Qué ocurre en esta capa? | Ingesta de datos sin procesar | Limpieza y validación de datos | Modelado y agregación dimensionales |
| ¿Quién es el usuario previsto? | - Ingenieros de datos - Operaciones de datos - Equipos de cumplimiento y auditoría |
- Ingenieros de datos - Analistas de datos (use la capa Silver para un conjunto de datos más refinado que todavía conserva información detallada necesaria para el análisis detallado) - Científicos de datos (crear modelos y realizar análisis avanzados) |
- Analistas de negocios y desarrolladores de BI - Científicos de datos e ingenieros de aprendizaje automático (ML) - Ejecutivos y responsables de la toma de decisiones - Equipos operativos |
Arquitectura de medallion de ejemplo
En este ejemplo de una arquitectura de medallón se muestran las capas de bronce, plata y oro para su uso por parte de un equipo de operaciones empresariales. Cada capa se almacena en un esquema diferente del catálogo de operaciones.
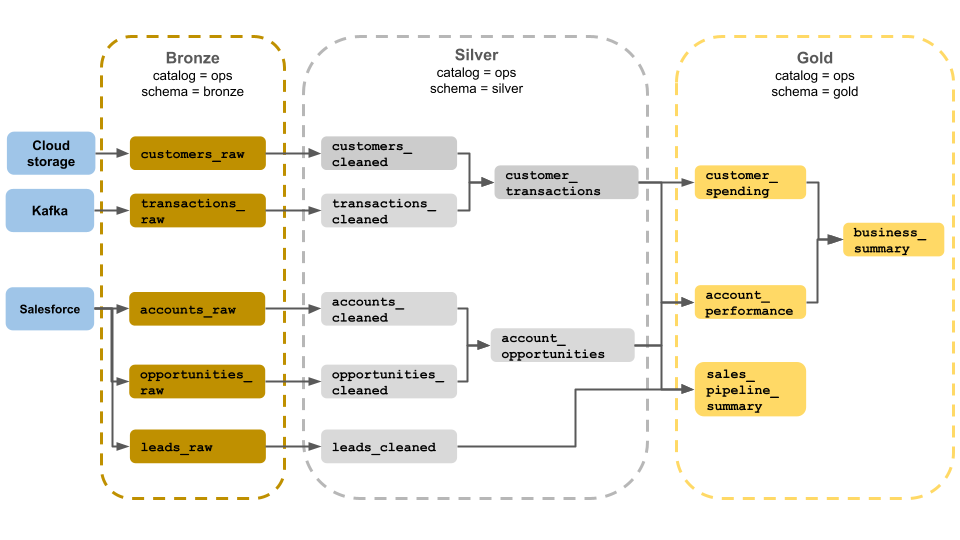
- Capa de bronce (
ops.bronze): ingiere datos sin procesar del almacenamiento en la nube, Kafka y Salesforce. No se realiza ninguna limpieza o validación de datos aquí. - Capa de plata (
ops.silver): la limpieza de datos y la validación se realizan en esta capa.- Los datos sobre clientes y transacciones se limpian quitando valores NULL y colocando registros no válidos. Estos conjuntos de datos se unen a un nuevo conjunto de datos denominado
customer_transactions. Los científicos de datos pueden usar este conjunto de datos para el análisis predictivo. - Del mismo modo, las cuentas y los conjuntos de datos de oportunidades de Salesforce se unen para crear
account_opportunities, que se mejora con la información de la cuenta. - Los
leads_rawdatos se limpian en un conjunto de datos denominadoleads_cleaned.
- Los datos sobre clientes y transacciones se limpian quitando valores NULL y colocando registros no válidos. Estos conjuntos de datos se unen a un nuevo conjunto de datos denominado
- Capa dorada (
ops.gold): esta capa está diseñada para usuarios empresariales. Contiene menos conjuntos de datos que plata y oro.customer_spending: promedio y gasto total para cada cliente.account_performance: rendimiento diario de cada cuenta.sales_pipeline_summary: información sobre la canalización de ventas de un extremo a otro.business_summary: información altamente agregada para el personal ejecutivo.
Ingesta de datos sin procesar en la capa de bronce
La capa de bronce contiene datos sin procesar y no validados. Los datos ingeridos en la capa de bronce suelen tener las siguientes características:
- Contiene y mantiene el estado sin procesar del origen de datos en sus formatos originales.
- Se anexan de manera incremental y aumentan con el tiempo.
- Está pensado para su consumo por cargas de trabajo que enriquecen los datos de las tablas silver, no para el acceso de analistas y científicos de datos.
- Actúa como fuente única de verdad, conservando la fidelidad de los datos.
- Permite volver a procesar y auditar conservando todos los datos históricos.
- Puede ser cualquier combinación de transacciones por lotes y streaming de orígenes, incluido el almacenamiento de objetos en la nube (por ejemplo, S3, GCS, ADLS), buses de mensajes (por ejemplo, Kafka, Kinesis, etc.) y sistemas federados (por ejemplo, Lakehouse Federation).
Limitar la limpieza o validación de datos
La validación mínima de datos se realiza en la capa de bronce. Para garantizar la eliminación de datos, Azure Databricks recomienda almacenar la mayoría de los campos como cadena, VARIANT o binario para protegerse frente a cambios de esquema inesperados. Se pueden agregar columnas de metadatos, como la procedencia o el origen de los datos (por ejemplo, _metadata.file_name ).
Validación y eliminación de datos duplicados en la capa de plata
La limpieza y validación de datos se realizan en la capa de plata.
Crear mesas de plata a partir de la capa de bronce
Para crear la capa de plata, lea datos de una o varias tablas de bronce o plata y escriba datos en tablas silver.
Azure Databricks no recomienda escribir en tablas silver directamente desde la ingesta. Si escribe directamente desde la ingesta, introducirá errores debido a cambios de esquema o registros dañados en orígenes de datos. Suponiendo que todos los orígenes son de solo anexión, configure la mayoría de las lecturas de bronce como lecturas de streaming. Las lecturas por lotes deben reservarse para conjuntos de datos pequeños (por ejemplo, tablas dimensionales pequeñas).
La capa silver representa versiones validadas, limpiadas y enriquecidas de los datos. La capa de plata:
- Siempre debe incluir al menos una representación validada y no agregada de cada registro. Si las representaciones agregadas impulsan muchas cargas de trabajo de bajada, esas representaciones podrían estar en la capa de plata, pero normalmente se encuentran en la capa dorada.
- Es donde se realizan limpieza, desduplicación y normalización de datos.
- Mejora la calidad de los datos mediante la corrección de errores e incoherencias.
- Estructura los datos en un formato más consumible para el procesamiento de bajada.
Aplicación de la calidad de los datos
Las siguientes operaciones se realizan en tablas silver:
- Cumplimiento de esquemas
- Control de valores NULL y que faltan
- Desduplicación de datos
- Resolución de problemas de datos desordenados y de llegada tardía
- Comprobaciones y cumplimiento de la calidad de los datos
- Evolución del esquema
- Conversión de tipos
- Combinaciones
Inicio del modelado de datos
Es habitual empezar a realizar el modelado de datos en la capa de plata, incluida la elección de cómo representar datos altamente anidados o semiestructurados:
- Use el
VARIANTtipo de datos. - Use
JSONcadenas. - Cree estructuras, asignaciones y matrices.
- Aplanar el esquema o normalizar los datos en varias tablas.
Impulsar el análisis con la capa de oro
La capa dorada representa vistas muy refinadas de los datos que impulsan el análisis, los paneles, el aprendizaje automático y las aplicaciones de bajada. Los datos de capa gold suelen agregarse y filtrarse por períodos de tiempo específicos o regiones geográficas. Contiene conjuntos de datos semánticamente significativos que se asignan a las funciones y necesidades empresariales.
La capa dorada:
- Consta de datos agregados adaptados para análisis e informes.
- Se alinea con la lógica de negocios y los requisitos.
- Está optimizado para el rendimiento en consultas y paneles.
Alineación con la lógica de negocios y los requisitos
La capa dorada es donde modelará los datos para informes y análisis mediante un modelo dimensional mediante el establecimiento de relaciones y la definición de medidas. Los analistas con acceso a datos en oro deben ser capaces de encontrar datos específicos del dominio y responder preguntas.
Dado que la capa gold modela un dominio empresarial, algunos clientes crean varias capas de oro para satisfacer diferentes necesidades empresariales, como RR. HH., finanzas y TI.
Creación de agregados adaptados para análisis e informes
A menudo, las organizaciones necesitan crear funciones de agregado para medidas como promedios, recuentos, máximos y mínimos. Por ejemplo, si su negocio necesita responder a preguntas sobre las ventas semanales totales, podría crear una vista materializada denominada weekly_sales que preagrega estos datos para que los analistas y otros no necesiten volver a crear vistas materializadas usadas con frecuencia.
CREATE OR REPLACE MATERIALIZED VIEW weekly_sales AS
SELECT week,
prod_id,
region,
SUM(units) AS total_units,
SUM(units * rate) AS total_sales
FROM orders
GROUP BY week, prod_id, region
Optimización del rendimiento en consultas y paneles
Optimizar las tablas de capas doradas para el rendimiento es un procedimiento recomendado porque estos conjuntos de datos se consultan con frecuencia. Normalmente se accede a grandes cantidades de datos históricos en la capa de sliver y no se materializan en la capa dorada.
Controlar los costos ajustando la frecuencia de ingesta de datos
Controle los costos mediante la determinación de la frecuencia con la que se ingieren datos.
| Frecuencia de ingesta de datos | Costos | Latencia | Ejemplos declarativos | Ejemplos de procedimientos |
|---|---|---|---|---|
| Ingesta incremental continua | Mayor | Menor | - Tabla de streaming mediante spark.readStream para ingerir desde el almacenamiento en la nube o el bus de mensajes.- La canalización delta Live Tables que actualiza esta tabla de streaming se ejecuta continuamente. - Código de streaming estructurado mediante spark.readStream en un cuaderno para ingerir desde el almacenamiento en la nube o el bus de mensajes en una tabla Delta.- El cuaderno se orquesta mediante un trabajo de Azure Databricks con un desencadenador de trabajo continuo. |
|
| Ingesta incremental desencadenada | Menor | Mayor | - Streaming Table ingesting from cloud storage or message bus using spark.readStream.- La canalización que actualiza esta tabla de streaming se desencadena mediante el desencadenador programado del trabajo o un desencadenador de llegada de archivos. - Código de streaming estructurado en un cuaderno con un Trigger.Available desencadenador.- Este cuaderno se desencadena mediante el desencadenador programado del trabajo o un desencadenador de llegada de archivos. |
|
| Ingesta por lotes con ingesta incremental manual | Menor | Más alto, debido a ejecuciones poco frecuentes. | - Ingesta de tablas de streaming desde el almacenamiento en la nube mediante spark.read.- No usa Structured Streaming. En su lugar, use primitivos como la sobrescritura de particiones para actualizar una partición completa a la vez. - Requiere una arquitectura ascendente extensa para configurar el procesamiento incremental, lo que permite un costo similar al de lecturas y escrituras de Structured Streaming. - También requiere la creación de particiones de datos de origen por un datetime campo y, a continuación, procesar todos los registros de esa partición en el destino. |