Rendimiento y solución de problemas para la extracción de datos de SAP
Este artículo forma parte de la serie de artículos "Ampliación e innovación de datos de SAP: procedimientos recomendados".
- Identificación de orígenes de datos de SAP
- Elección del mejor conector de SAP
- Rendimiento y solución de problemas para la extracción de datos de SAP
- Seguridad de integración de datos para SAP en Azure
- Arquitectura genérica de integración de datos de SAP
Hay muchas maneras de conectarse al sistema SAP para la integración de datos. En las siguientes secciones se describen las consideraciones y recomendaciones generales y específicas del conector.
Rendimiento
Es importante configurar los valores óptimos para el origen y el destino para que pueda lograr el mejor rendimiento durante la extracción y el procesamiento de datos.
Consideraciones generales
- Asegúrese de que los parámetros de SAP correctos están establecidos para una conexión simultánea máxima.
- Considere la posibilidad de usar el tipo de inicio de sesión de grupo de SAP para mejorar el rendimiento y la distribución de carga.
- Asegúrese de que la máquina virtual del entorno de ejecución de integración autohospedado (SHIR) tenga el tamaño adecuado y tenga una alta disponibilidad.
- Al trabajar con grandes conjuntos de datos, compruebe si el conector que usa proporciona una funcionalidad de creación de particiones. Muchos de los conectores de SAP admiten funcionalidades de creación de particiones y paralelización para acelerar las cargas de datos. Cuando se usa este método, los datos se empaquetan en fragmentos más pequeños que se pueden cargar mediante varios procesos paralelos. Para más información, consulte la documentación específica del conector.
Recomendaciones generales
Use la transacción de SAP RZ12 para modificar los valores de las conexiones simultáneas máximas.
Parámetros de SAP para RFC - RZ12: el siguiente parámetro puede restringir el número de llamadas RFC permitidas para un usuario o una aplicación, por lo que debe asegurarse de que esta restricción no está causando un cuello de botella.
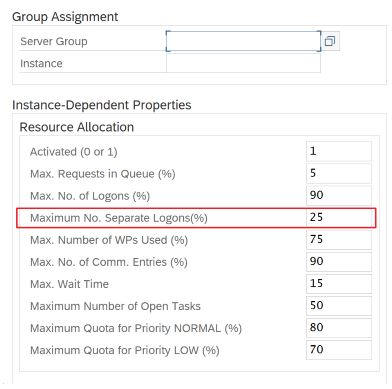
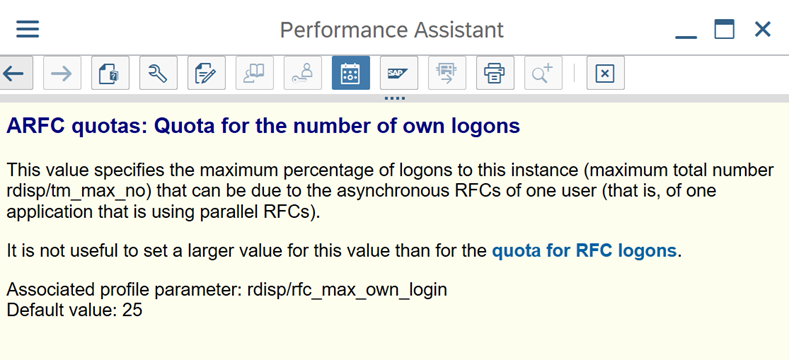
Conexión a SAP mediante el grupo de inicio de sesión: SHIR (entorno de ejecución de integración autohospedado) debe conectarse a SAP mediante un grupo de inicio de sesión de SAP (a través del servidor de mensajes) y no a un servidor de aplicaciones específico para garantizar una distribución de cargas de trabajo en todos los servidores de aplicaciones disponibles.
Nota:
El clúster de Spark de flujo de datos y SHIR son eficaces. Muchas actividades internas de copia de SAP, por ejemplo 16, se pueden desencadenar y ejecutar. Pero si el número de conexión simultánea del servidor SAP es pequeño, por ejemplo 8, el rendimiento lee los datos del lado SAP.
Comience con 4 vCPU y 16 GB de máquinas virtuales para SHIR. En los pasos siguientes se muestra la conexión del proceso de trabajo del cuadro de diálogo en SAP con SHIR.
- Compruebe si el cliente usa una máquina física deficiente para configurar e instalar SHIR para ejecutar una copia interna de SAP.
- Vaya al portal de Azure Data Factory y busque el servicio vinculado CDC de SAP relacionado que se usa en el flujo de datos. Compruebe el nombre de SHIR al que se hace referencia.
- Compruebe la configuración de CPU, memoria, red y disco de la máquina física donde está instalado SHIR.
- Compruebe cuántos
diawp.exese ejecutan en la máquina SHIR. Undiawp.exepuede ejecutar una actividad de copia. El número dediawp.exese basa en la configuración de CPU, memoria, red y disco de la máquina.
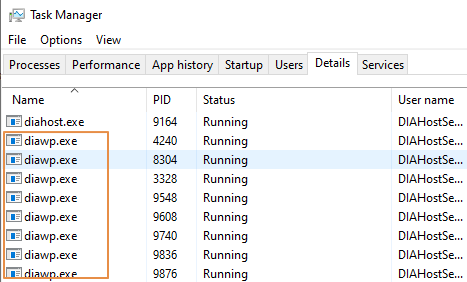
Si desea ejecutar varias particiones en paralelo en SHIR al mismo tiempo, use una máquina virtual eficaz para configurar SHIR. O bien, use el escalado horizontal mediante las características de alta disponibilidad y escalabilidad de SHIR para tener varios nodos. Para más información, consulte Alta disponibilidad y escalabilidad.
Particiones
En la sección siguiente se describe el proceso de creación de particiones para un conector CDC de SAP. El proceso es el mismo para una tabla de SAP y un conector de Open Hub de SAP BW.

El escalado se puede realizar en el entorno de ejecución de integración autohospedado o en Azure IR en función de los requisitos de rendimiento. Revise el consumo de CPU de SHIR para ver las métricas que le ayudarán a decidir el enfoque de escalado. El SHIR se puede escalar vertical u horizontalmente en función de sus necesidades. Se recomienda implementar Azure IR en una SKU inferior. Escale verticalmente para satisfacer los requisitos de rendimiento según se determine mediante pruebas de carga, en lugar de comenzar en el extremo superior innecesariamente.
Nota:
Si alcanza el 70 % de capacidad, escale verticalmente o escale horizontalmente para SHIR.

La creación de particiones es útil para cargas completas iniciales o grandes y normalmente no es necesaria para cargas diferenciales. Si no especifica la partición, de forma predeterminada, 1 "productor" en el sistema SAP (normalmente un proceso por lotes) captura los datos de origen en la cola de datos operativos (ODQ) y SHIR captura los datos de ODQ. De forma predeterminada, SHIR usa cuatro subprocesos para capturar los datos de ODQ, por lo que, en ese momento, hay cuatro procesos de diálogo ocupados en SAP.
La idea de la creación de particiones es dividir un conjunto de datos inicial grande en varios subconjuntos separados más pequeños que son idealmente iguales de tamaño y que se pueden procesar en paralelo. Este método reduce el tiempo necesario para generar los datos de la tabla de origen en ODQ de forma lineal. Este método supone que hay suficientes recursos en el lado de SAP para controlar la carga.
Nota:
- El número de particiones ejecutadas en paralelo está limitado por el número de núcleos de controlador en Azure IR. Actualmente se está llevando a cabo una resolución para esta limitación.
- Cada unidad o paquete de la transacción de SAP ODQMON es un único archivo de la carpeta de almacenamiento provisional.
Consideraciones de diseño al ejecutar las canalizaciones mediante CDC
Compruebe la duración de la fase de SAP.
Compruebe el rendimiento en tiempo de ejecución en el receptor.
Considere la posibilidad de usar la característica de creación de particiones para mejorar el rendimiento.
Si la duración de SAP a la fase es lenta, considere la posibilidad de cambiar el tamaño de SHIR a especificaciones más altas.
Compruebe si el tiempo de procesamiento del receptor es demasiado lento.
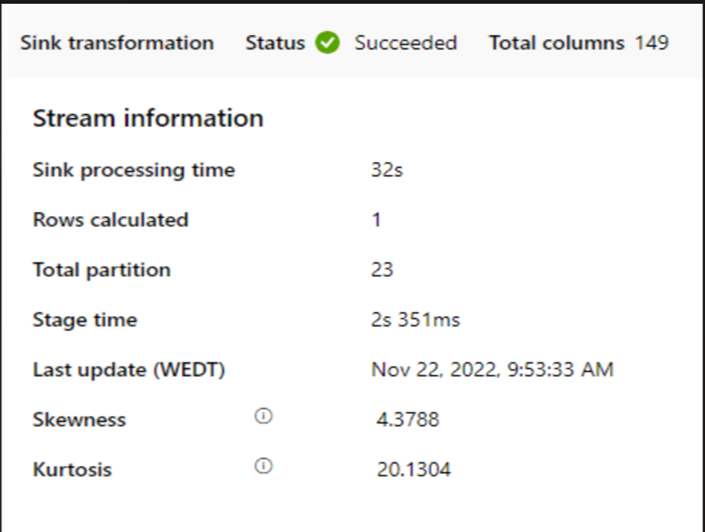
Si se usa un clúster pequeño para ejecutar el flujo de datos de asignación, podría afectar al rendimiento en el receptor. Use un clúster grande, por ejemplo, 16 + 256 núcleos, por lo que el rendimiento lee los datos de la fase y escribe en el receptor.
En el caso de volúmenes de datos grandes, se recomienda crear particiones de la carga para ejecutar trabajos paralelos, pero mantener el número de particiones menores o iguales que el núcleo de Azure IR, también denominado núcleo del clúster de Spark.
Use la pestaña Optimizar para definir las particiones. Puede usar la creación de particiones de origen en el conector CDC.
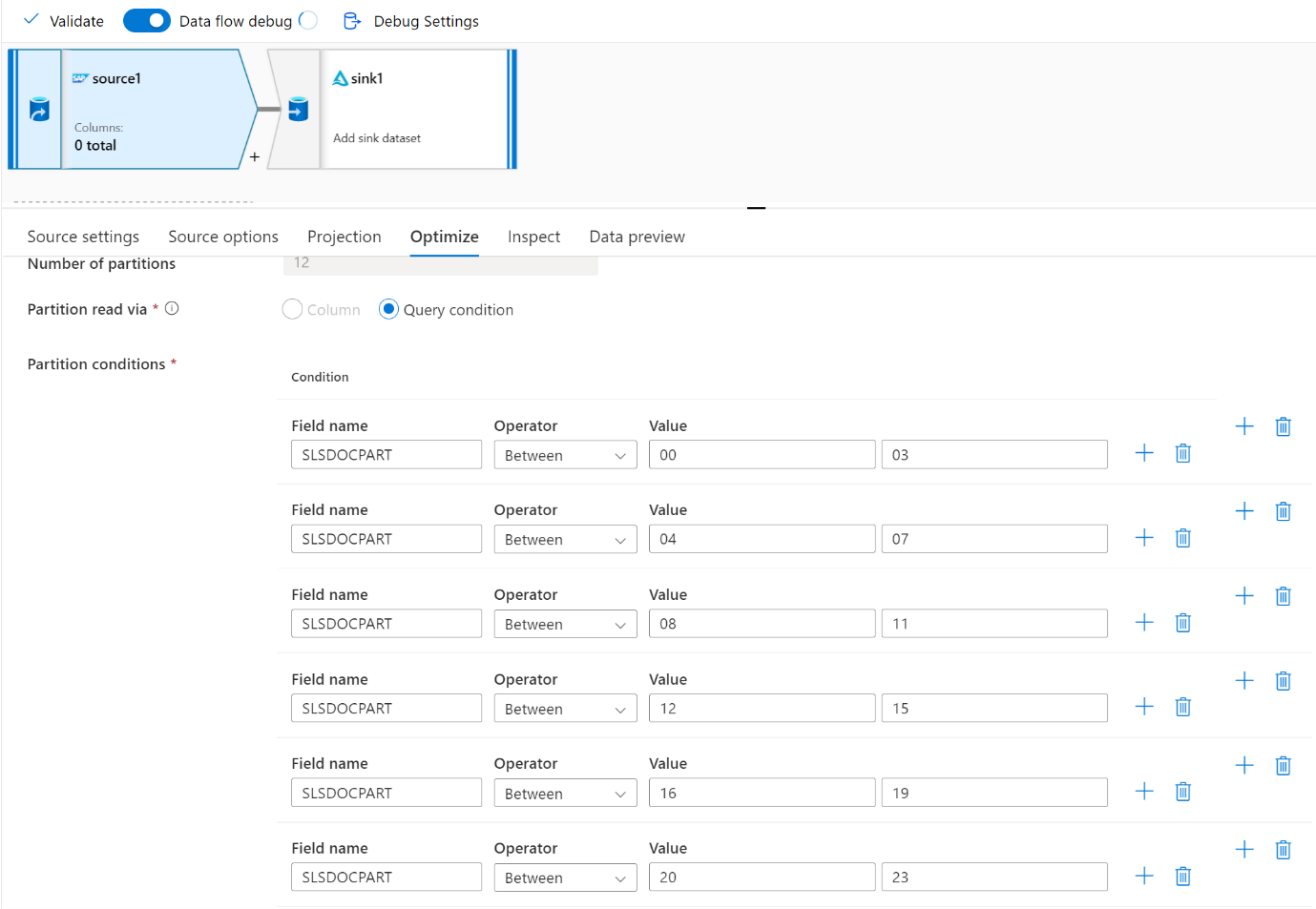
Nota:
- Hay una correlación directa entre el número de particiones con núcleos SHIR y nodos de Azure IR.
- El conector CDC de SAP aparece como el tipo de suscriptor de Odata "Acceso de Odata para el aprovisionamiento de datos operativos" en ODQMON en el sistema SAP.
Consideraciones de diseño al usar un conector table
- Optimice la creación de particiones para mejorar el rendimiento.
- Tenga en cuenta el grado de paralelismo de la tabla de SAP.
- Considere un diseño de archivo único para el receptor de destino.
- Realice pruebas comparativas del rendimiento al usar grandes volúmenes de datos.
Recomendaciones de diseño al usar un conector table
Partición: Al crear particiones en el conector de tabla de SAP, este divide una instrucción select subyacente en varias mediante el uso de cláusulas where en un campo adecuado, por ejemplo, un campo con cardinalidad alta. Si su tabla de SAP tiene un gran volumen de datos, habilite las particiones para dividir los datos en particiones más pequeñas. Intente optimizar el número de particiones (parámetro
maxPartitionsNumber) para que las particiones sean lo suficientemente pequeñas como para evitar volcados de memoria en SAP, pero lo suficientemente grande como para acelerar la extracción.Paralelismo: El grado de paralelismo de copia (parámetro
parallelCopies) funciona en conjunto con la creación de particiones e indica al SHIR que realice llamadas RFC paralelas al sistema SAP. Por ejemplo, si establece este parámetro en 4, el servicio genera y ejecuta al mismo tiempo cuatro consultas de acuerdo con la configuración y la opción de partición que ha especificado. Cada consulta recupera una porción de datos de la tabla SAP.Para obtener resultados óptimos, el número de particiones debe ser un múltiplo del grado de paralelismo de copia.
Al copiar datos de la tabla SAP en receptores binarios, el recuento paralelo real se ajusta automáticamente en función de la cantidad de memoria disponible en SHIR. Registre el tamaño de la máquina virtual SHIR para cada ciclo de prueba, el grado de paralelismo de copia y el número de particiones. Observe el rendimiento de la máquina virtual SHIR, el rendimiento del sistema SAP de origen y el grado real de paralelismo deseado. Use un proceso iterativo para identificar la configuración óptima y el tamaño ideal para la máquina virtual SHIR. Tenga en cuenta todas las canalizaciones de ingesta que cargan simultáneamente datos de uno o varios sistemas SAP.
Observe el número observado de llamadas RFC a SAP con respecto al grado de paralelismo configurado. Si el número de llamadas RFC a SAP es menor que el grado de paralelismo, compruebe que la máquina virtual SHIR tiene suficiente memoria y recursos de CPU disponibles. Elija una máquina virtual más grande si es necesario. El sistema SAP de origen está configurado para limitar el número de conexiones paralelas. Para más información, consulte la sección Recomendaciones generales de este artículo.
Número de archivos: Al copiar datos en un almacén de datos basado en archivos y el receptor de destino está configurado para ser una carpeta, se generan varios archivos de forma predeterminada. Si establece la propiedad
fileNameen el receptor, los datos se escriben en un único archivo. Se recomienda escribir en una carpeta como varios archivos porque obtiene un mayor rendimiento de escritura en comparación con la escritura en un único archivo.Pruebas comparativas de rendimiento: Se recomienda usar el ejercicio de pruebas comparativas de rendimiento para ingerir grandes cantidades de datos. Este método varía los parámetros, como la creación de particiones, el grado de paralelismo y el número de archivos para determinar la configuración óptima para la arquitectura, el volumen y el tipo de datos especificados. Recopile datos de las pruebas en el siguiente formato.


Solución de problemas
Cuando la extracción del sistema SAP sea lenta o con errores, use los registros de SAP de SM37 y haga que coincidan con las lecturas de Data Factory.
Si solo se desencadena un trabajo por lotes, establezca las particiones de origen de SAP para que tengan una mejora del rendimiento en el flujo de datos de asignación en Data Factory. Para más información, consulte el paso 6 en Propiedades del flujo de datos de asignación.
Si se desencadenan varios trabajos por lotes en el sistema SAP y hay una diferencia significativa entre la hora de inicio de cada trabajo por lotes, cambie el tamaño de Azure IR. Al aumentar el número de nodos de controlador en Azure IR, aumenta el paralelismo de los trabajos por lotes en el lado SAP.
Nota:
El número máximo de nodos de controlador para Azure IR es 16. Cada nodo de controlador solo puede desencadenar un proceso por lotes.
Compruebe los registros en SHIR. Para ver los registros, vaya a MÁQUINA virtual SHIR. Abra la vista de eventos > Aplicaciones y registros de servicio > Conectores > Entorno de ejecución de integración.
Para enviar registros al soporte técnico, vaya a la máquina virtual SHIR. Abra el administrador de la configuración del entorno de ejecución de integración > Diagnóstico > Enviar registros. Esta acción envía los registros de los últimos siete días y proporciona un identificador de informe. Necesita este identificador de informe y RunId de la ejecución. Documente el identificador del informe para futuras referencias.
Al usar el conector CDC de SAP en un escenario de SLT:
Comprobación de que se cumplen los requisitos previos. Los roles son necesarios para el usuario de SAP Landscape Transformation (SLT), por ejemplo, ADFSLTUSER en sistemas OLTP o ECC para que la replicación de SLT funcione. Para obtener más información, consulte ¿Qué autorizaciones y roles son necesarios?.
Si se producen errores en un escenario de SLT, consulte las recomendaciones para el análisis. Aísle y pruebe primero el escenario dentro de la solución de SAP. Por ejemplo, pruébelo fuera de Data Factory mediante la ejecución del programa de prueba proporcionado por SAP
RODPS_REPL_TESTen SE38. Si el problema está en el lado de SAP, obtendrá el mismo error al usar el informe. Puede analizar la extracción de datos en SAP mediante el código de transacciónODQMON.Si la replicación funciona al usar este informe de prueba, pero no con Data Factory, póngase en contacto con el soporte técnico de Azure o Data Factory.
En el ejemplo siguiente se muestra un informe para
RODPS_REPL_TESTen SE38: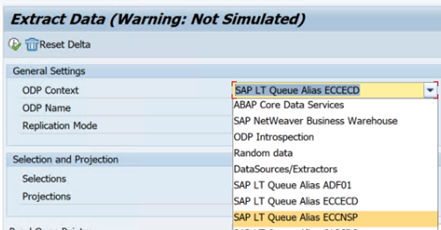
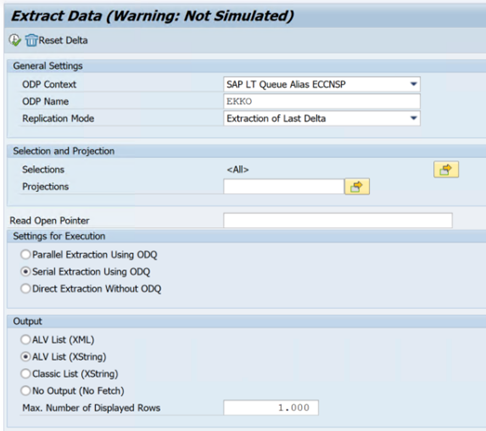

En el ejemplo siguiente se muestra el código
ODQMONde la transacción: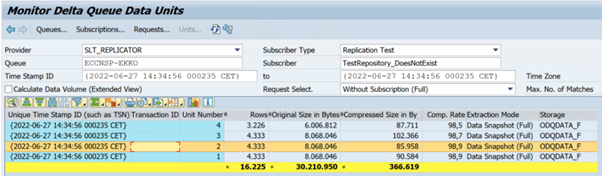
Cuando el servicio vinculado de Data Factory se conecta al sistema SLT, no muestra los identificadores de transferencia masiva de SLT al actualizar el campo Contexto.
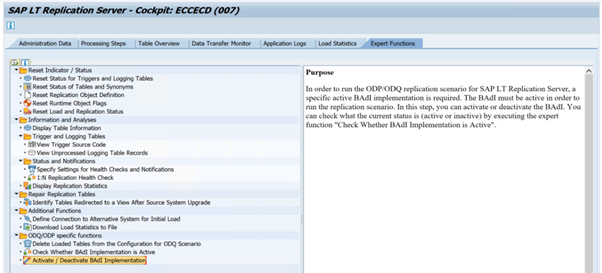
Para ejecutar el escenario de replicación de ODP/ODQ para el servidor de replicación de SAP LT, active la siguiente implementación del complemento empresarial (BAdI).
BAdI:
BADI_ODQ_QUEUE_MODELImplementación de mejoras:
ODQ_ENH_SLT_REPLICATIONEn la transacción LTRC, vaya a la pestaña Función experta y seleccione Activar o desactivar la implementación de BAdI para activar la implementación.
Seleccione Sí.
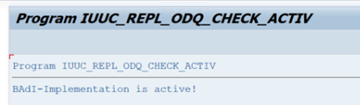
En la carpeta de funciones específicas de ODQ/ODP, seleccione Comprobar si la implementación de BAdI está activa.

El cuadro de diálogo muestra la actividad del programa.
Restablezca las suscripciones. Para empezar con una extracción nueva o detener los datos de replicación, quite la suscripción en ODQMON. Esta acción también quita las entradas de LTRC. Después de restablecer la suscripción, puede tardar un par de minutos antes de ver el efecto en LTRC. Programar trabajos de limpieza de aprovisionamiento de datos operativos (ODP) para mantener limpias las colas delta, por ejemplo
ODQ_CLEANUP_CLIENT_004CDS_VIEW (transacción DHCDCMON). A partir de S/4HANA 1909, SAP replica datos de vistas de CDS que usan desencadenadores basados en datos en lugar de columnas de fecha. El concepto es similar a SLT, pero en lugar de usar la transacción LTRC para supervisarlo, se usa la transacción DHCDCMON.
Solución de problemas SLT
El servidor de replicación de SLT proporciona replicación de datos en tiempo real desde orígenes de SAP u orígenes que no son de SAP a destinos de SAP o destinos que no son de SAP. Hay tres tipos de conjuntos de herramientas para supervisar la extracción de SLT a Azure.
- ODQMON es la herramienta de supervisión general para la extracción de datos. Inicie el análisis con ODQMON para realizar un seguimiento de las incoherencias de datos, el análisis de rendimiento inicial y las solicitudes de suscripción y extracción abiertas.
- LTRC es la transacción que se va a usar para comprobar el análisis de rendimiento. Resulta útil si tiene problemas de replicación de datos desde el sistema de origen a ODP porque puede supervisar el flujo de datos y buscar incoherencias.
- SM37 proporciona una supervisión detallada de cada paso de extracción de SLT.
El mantenimiento normal debe realizarse con ODQMON, donde puede administrar la suscripción directamente y no debe usar LTRC para lo mismo.
Es posible que encuentre problemas al extraer datos de SLT, como:
La extracción no se ejecuta. Compruebe si la conexión CDC de SAP creó una conexión en ODQMON y compruebe si la suscripción existe.
Incoherencias de datos. Compruebe ODQMON para ver la solicitud individual de datos y confirme que puede ver los datos allí. Si puede ver los datos en ODQMON, pero no en Azure Synapse o Data Factory, la investigación debe producirse en el lado de Azure. Si no puede ver los datos en ODQMON, realice un análisis del marco SLT mediante LTRC.
Problemas de rendimiento. La extracción de datos es un enfoque de dos pasos. En primer lugar, SLT lee los datos del sistema de origen y los transfiere a ODP. En segundo lugar, el conector CDC de SAP recoge los datos de ODP y los transfiere al almacén de datos elegido. La transacción LTRC le permite analizar la primera parte del proceso de extracción. Para analizar la extracción de datos de ODP a Azure, use las herramientas de supervisión de ODQMON y Data Factory o Synapse.
Nota
Para obtener más información, vea estos recursos:
Rendimiento de SLT
En el modo de carga inicial (ODPSLT), hay tres pasos para extraer datos de SLT en ODP:
- Cree objetos de migración. Este proceso solo tarda un par de segundos.
- Acceda al cálculo del plan que divide la tabla de origen en fragmentos más pequeños. Este paso depende del modo de carga inicial que seleccione durante la configuración de SLT y el tamaño de la tabla. Se recomienda la opción optimizada para recursos.
- La carga de datos transfiere los datos del sistema de origen a ODP.
Cada paso se controla mediante los trabajos en segundo plano. Puede usar las transacciones SM37 y LTRC para supervisar la duración. Si el sistema está sobreutilizado, es posible que los trabajos en segundo plano se inicien más adelante porque no hay suficientes procesos de trabajo por lotes libres. Cuando las tareas están inactivas, el rendimiento se ve afectado.
Si el cálculo del plan de acceso tarda mucho tiempo y el modo de carga inicial se establece en "optimizado para el rendimiento", cámbielo a "optimizado para recursos" y vuelva a ejecutar la extracción. Si la carga de datos tarda mucho tiempo, aumente el número de subprocesos paralelos en la configuración.
Si usa una arquitectura independiente para la replicación de SLT (servidor de replicación SLT dedicado), el rendimiento de red entre el sistema de origen y el servidor de replicación podría afectar al rendimiento de extracción.
Para replicación:
- Asegúrese de que tiene suficientes trabajos de transferencia de datos que no están reservados para la carga inicial.
- Compruebe que no tiene un registro de tabla de registro sin procesar en las estadísticas de carga.
- Asegúrese de que la opción de replicación está establecida en tiempo real.
La configuración avanzada de replicación está disponible en LTRS. Para más información, consulte la guía para la solución de problemas de SLT.
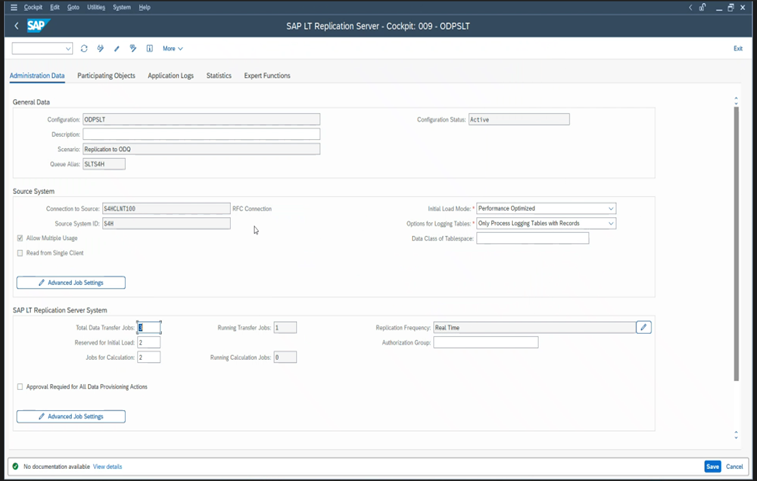
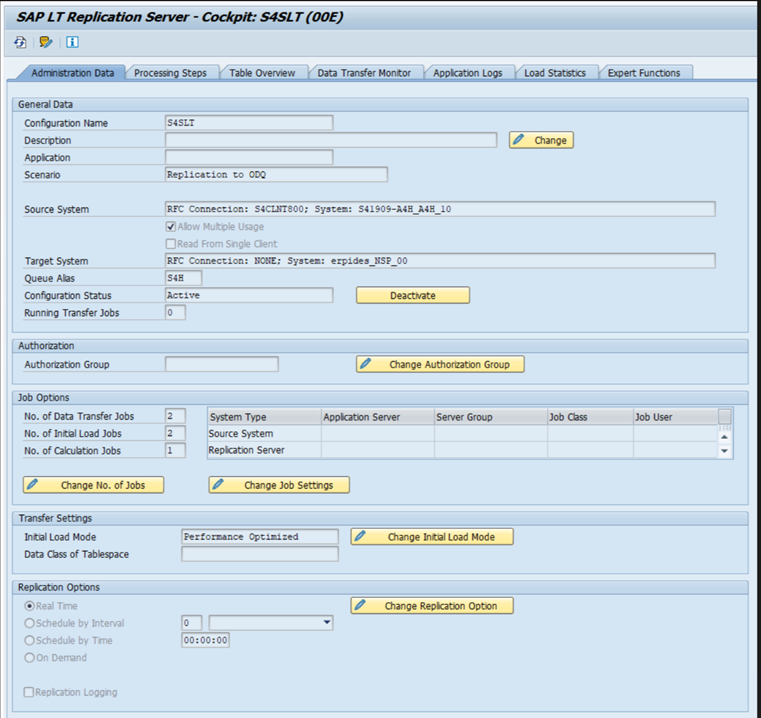
Las distintas versiones de SAP tienen diferentes interfaces de usuario LTRC. En las capturas de pantalla siguientes se muestra la misma página para dos versiones diferentes.
SAP S/4HANA:
SAP ECC:


Monitor
Para obtener información sobre la supervisión de la extracción de datos de SAP, consulte estos recursos: