Esta arquitectura de referencia muestra una canalización de procesamiento de flujos de datos de un extremo a otro. La canalización ingiere los datos de dos orígenes, correlaciona los registros de los dos flujos de datos y calcula una media acumulada en un intervalo de tiempo. Los resultados se almacenan para su posterior análisis.
 Hay disponible una implementación de referencia de esta arquitectura en GitHub.
Hay disponible una implementación de referencia de esta arquitectura en GitHub.
Architecture

Descargue un archivo Visio de esta arquitectura.
Flujo de trabajo
La arquitectura consta de los siguientes componentes:
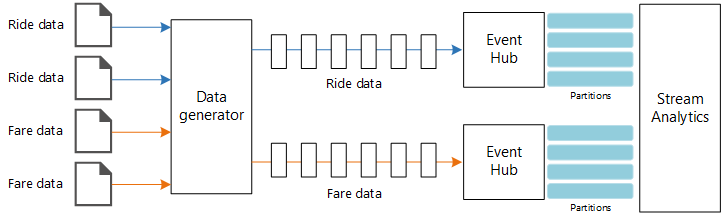
Orígenes de datos. En esta arquitectura, hay dos orígenes de datos que generan flujos de datos en tiempo real. El primer flujo de datos contiene información sobre la carrera y, el segundo, contiene información sobre las tarifas. La arquitectura de referencia incluye un generador de datos simulados que lee un conjunto de archivos estáticos e inserta los datos en Event Hubs. En una aplicación real, los orígenes de datos serían los dispositivos instalados en el taxi.
Azure Event Hubs. Event Hubs es un servicio de ingesta de eventos. Esta arquitectura emplea dos instancias de centro de eventos, uno para cada origen de datos. Cada origen de datos envía un flujo de datos al centro de eventos asociado.
Azure Stream Analytics. Stream Analytics es un motor de procesamiento de eventos. Un trabajo de Stream Analytics lee los flujos de datos desde los dos centros de eventos y realiza el procesamiento de los flujos.
Azure Cosmos DB. La salida del trabajo de Stream Analytics es una serie de registros que se escriben como documentos JSON en una base de datos de documentos de Azure Cosmos DB.
Microsoft Power BI. Power BI es un conjunto de herramientas de análisis de negocios que sirve para analizar datos con el fin de obtener perspectivas empresariales. En esta arquitectura, carga los datos desde Azure Cosmos DB. Esto permite a los usuarios analizar el conjunto completo de los datos históricos que se han recopilado. También podría transmitir los resultados directamente desde Stream Analytics a Power BI para obtener una vista en tiempo real de los datos. Para más información, consulte Streaming en tiempo real en Power BI.
Azure Monitor. Azure Monitor recopila métricas de rendimiento sobre los servicios de Azure implementados en la solución. Puede visualizarlos en un panel para obtener información acerca del estado de la solución.
Detalles del escenario
Escenario: Una empresa de taxi recopila los datos acerca de cada carrera de taxi. En este escenario, se supone que hay dos dispositivos independientes que envían datos. El taxi tienen un medidor que envía la información acerca de cada carrera: duración, distancia y ubicaciones de recogida y destino. Un dispositivo independiente acepta los pagos de clientes y envía los datos sobre las tarifas. La empresa de taxi desea calcular el promedio de propinas por milla conducida, en tiempo real, con el fin de identificar las tendencias.
Posibles casos de uso
Esta solución está optimizada para el sector minorista.
Ingesta de datos
Para simular un origen de datos, esta arquitectura de referencia usa el conjunto de datos New York City Taxi Data[1]. Este conjunto de datos contiene datos acerca de carreras de taxi en la ciudad de Nueva York durante un período de cuatro años (de 2010 a 2013). Contiene dos tipos de registros: datos de carreras y datos de tarifas. Los datos de carreras incluyen la duración del viaje, la distancia de viaje y la ubicación de recogida y destino. Los datos de tarifas incluyen las tarifas, los impuestos y las propinas. Los campos comunes en ambos tipos de registro son la placa y el número de licencia, y el identificador del proveedor. Juntos, estos tres campos identifican un taxi además del conductor. Los datos se almacenan en formato CSV.
[1] Donovan, Brian; Trabajo, Dan (2016): New York City Taxi Trip Data (2010-2013). Universidad de Illinois en Urbana-Champaign. https://doi.org/10.13012/J8PN93H8
El generador de datos es una aplicación de .NET Core que lee los registros y los envía a Azure Event Hubs. El generador envía los datos de carreras en formato JSON y los datos de tarifas en formato CSV.
Event Hubs usa particiones para segmentar los datos. Las particiones permiten a los consumidores leer cada partición en paralelo. Cuando se envían datos a Event Hubs, puede especificar explícitamente la clave de partición. En caso contrario, los registros se asignan a las particiones en modo round-robin.
En este escenario en particular, los datos de carreras y los datos de tarifas deben terminar con el mismo identificador de partición para un taxi determinado. Esto permite a Stream Analytics aplicar un cierto paralelismo cuando se establece una correlación entre los dos flujos. Un registro en la partición n de los datos de carreras coincidirá con un registro en la partición de datos n de los datos de tarifas.
En el generador de datos, el modelo de datos común para ambos tipos de registro tiene una propiedad PartitionKey que es la concatenación de Medallion, HackLicense y VendorId.
public abstract class TaxiData
{
public TaxiData()
{
}
[JsonProperty]
public long Medallion { get; set; }
[JsonProperty]
public long HackLicense { get; set; }
[JsonProperty]
public string VendorId { get; set; }
[JsonProperty]
public DateTimeOffset PickupTime { get; set; }
[JsonIgnore]
public string PartitionKey
{
get => $"{Medallion}_{HackLicense}_{VendorId}";
}
Esta propiedad se utiliza para proporcionar una clave de partición explícita cuando se realizan envíos a Event Hubs:
using (var client = pool.GetObject())
{
return client.Value.SendAsync(new EventData(Encoding.UTF8.GetBytes(
t.GetData(dataFormat))), t.PartitionKey);
}
Procesamiento de flujos
El trabajo de procesamiento de flujos se define mediante una consulta SQL con diferentes pasos. Los dos primeros pasos simplemente seleccionan los registros de los dos flujos de entrada.
WITH
Step1 AS (
SELECT PartitionId,
TRY_CAST(Medallion AS nvarchar(max)) AS Medallion,
TRY_CAST(HackLicense AS nvarchar(max)) AS HackLicense,
VendorId,
TRY_CAST(PickupTime AS datetime) AS PickupTime,
TripDistanceInMiles
FROM [TaxiRide] PARTITION BY PartitionId
),
Step2 AS (
SELECT PartitionId,
medallion AS Medallion,
hack_license AS HackLicense,
vendor_id AS VendorId,
TRY_CAST(pickup_datetime AS datetime) AS PickupTime,
tip_amount AS TipAmount
FROM [TaxiFare] PARTITION BY PartitionId
),
El paso siguiente combina los dos flujos de entrada para seleccionar los registros coincidentes de cada flujo.
Step3 AS (
SELECT tr.TripDistanceInMiles,
tf.TipAmount
FROM [Step1] tr
PARTITION BY PartitionId
JOIN [Step2] tf PARTITION BY PartitionId
ON tr.PartitionId = tf.PartitionId
AND tr.PickupTime = tf.PickupTime
AND DATEDIFF(minute, tr, tf) BETWEEN 0 AND 15
)
Esta consulta combina los registros en un conjunto de campos que identifican los registros coincidentes de forma única (PartitionId y PickupTime).
Nota
Queremos que los flujos TaxiRide y TaxiFare se unan mediante la combinación única de Medallion, HackLicense, VendorId y PickupTime. En este caso, PartitionId cubre los campos Medallion, HackLicense y VendorId, pero no debe considerarse el caso general.
En Stream Analytics, las combinaciones son temporales, lo que significa que los registros se combinan dentro de un intervalo de tiempo determinado. De caso contrario, el trabajo podría tener que esperar indefinidamente a una coincidencia. La función DATEDIFF especifica la separación máxima en el tiempo de dos registros coincidentes para considerarlo una coincidencia.
El último paso del trabajo calcula la media de propinas por milla, agrupada por una ventana de salto de 5 minutos.
SELECT System.Timestamp AS WindowTime,
SUM(tr.TipAmount) / SUM(tr.TripDistanceInMiles) AS AverageTipPerMile
INTO [TaxiDrain]
FROM [Step3] tr
GROUP BY HoppingWindow(Duration(minute, 5), Hop(minute, 1))
Stream Analytics proporciona varias funciones de intervalos de tiempo. Una ventana de salto avanza en el tiempo un período fijo; en este caso, 1 minuto por salto. El objetivo es calcular una media móvil en los últimos cinco minutos.
En la arquitectura que se muestra a continuación, solo se guardan los resultados del trabajo de Stream Analytics en Azure Cosmos DB. En un escenario de macrodatos, considere la posibilidad de usar también Event Hubs Capture para guardar los datos de eventos sin procesar en Azure Blob Storage. Mantener los datos sin procesar le permitirá ejecutar consultas por lotes en los datos históricos en el futuro, con el fin de obtener información nueva a partir de los datos.
Consideraciones
Estas consideraciones implementan los pilares del marco de buena arquitectura de Azure, que es un conjunto de principios guía que se pueden usar para mejorar la calidad de una carga de trabajo. Para más información, consulte Marco de buena arquitectura de Microsoft Azure.
Optimización de costos
La optimización de costos consiste en examinar formas de reducir los gastos innecesarios y mejorar las eficiencias operativas. Para obtener más información, consulte Lista de comprobación de revisión de diseño para la optimización de costos.
Puede usar la calculadora de precios de Azure para calcular los costos. Estas son algunas consideraciones sobre los servicios que se usan en esta arquitectura de referencia.
Azure Stream Analytics
Los precios de Azure Stream Analytics se basan en el número de unidades de streaming (0,11 $/hora) necesarias para procesar los datos en el servicio.
Stream Analytics puede ser costoso si no está procesando los datos en tiempo real o pequeñas cantidades de datos. En esos casos de uso, considere la posibilidad de usar Azure Functions o Logic Apps para trasladar datos de Azure Event Hubs a un almacén de datos.
Azure Event Hubs y Azure Cosmos DB
Para obtener información sobre los costos de Azure Event Hubs y Azure Cosmos DB, consulte las consideraciones de costos en la arquitectura de referencia de Procesamiento de flujos con Azure Databricks.
Excelencia operativa
La excelencia operativa abarca los procesos de operaciones que implementan una aplicación y lo mantienen en ejecución en producción. Para obtener más información, vea Lista de comprobación de revisión de diseño para la excelencia operativa.
Supervisión
Con cualquier solución de procesamiento de flujos, es importante supervisar el rendimiento y el estado del sistema. Azure Monitor recopila métricas y registros de diagnóstico para los servicios de Azure que se utilizan en la arquitectura. Azure Monitor se integra en la plataforma de Azure y no requiere ningún código adicional en la aplicación.
Cualquiera de las siguientes señales de advertencia indica que debe escalar horizontalmente el recurso de Azure correspondiente:
- Event Hubs limita las solicitudes o está cerca de la cuota diaria de mensajes.
- El trabajo de Stream Analytics utiliza sistemáticamente más del 80 % de las unidades de streaming (SU) asignadas.
- Azure Cosmos DB comienza a limitar las solicitudes.
La arquitectura de referencia incluye un panel personalizado, que se implementa en Azure Portal. Después de implementar la arquitectura, abra Azure Portal y seleccione TaxiRidesDashboard en la lista de paneles para ver el panel. Para más información sobre cómo crear e implementar paneles personalizados en Azure Portal, consulte Creación mediante programación de paneles de Azure.
La siguiente imagen muestra el panel después de que el trabajo de Stream Analytics se ejecutara durante una hora aproximadamente.
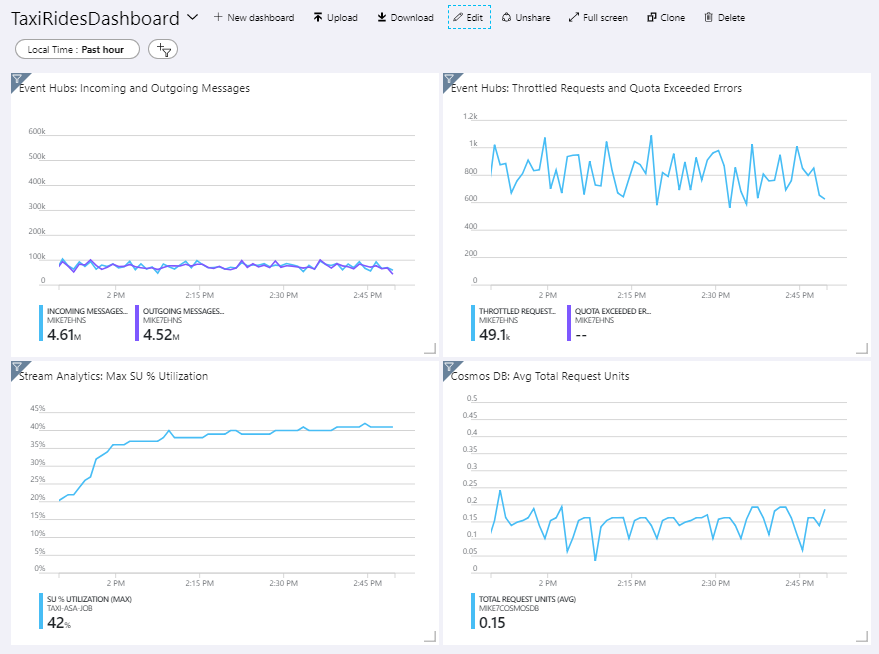
El panel de la parte inferior izquierda muestra que el consumo de unidades de streaming para el trabajo de Stream Analytics aumenta durante los primeros 15 minutos y después se nivela. Este es un patrón típico mientras el trabajo alcanza un estado estable.
Tenga en cuenta que Event Hubs limita las solicitudes, tal y como se muestra en el panel superior derecho. Un solicitud limitada de vez en cuanto no es un problema, porque el SDK de cliente de Event Hubs realiza reintentos automáticamente cuando recibe un error de limitación. Sin embargo, si se producen errores de limitación sistemáticamente, significa que el centro de eventos necesita más unidades de procesamiento. El gráfico siguiente muestra una ejecución de prueba con la característica de inflado automático de Event Hubs, que escala horizontalmente las unidades de procesamiento automáticamente cuando es necesario.
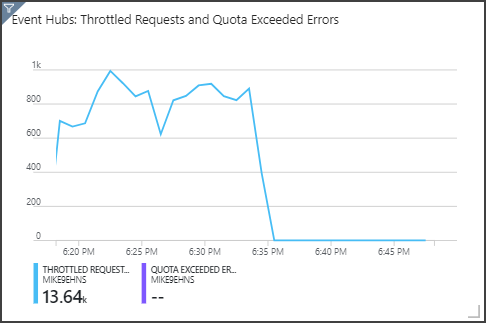
El inflado automático se habilitó en la marca de 06:35 aproximadamente. Puede ver la caída de solicitudes limitadas, porque Event Hubs escaló automáticamente a 3 unidades de procesamiento.
Curiosamente, esto tuvo el efecto secundario de aumentar el uso de las unidades de streaming en el trabajo de Stream Analytics. Con la limitación, Event Hubs redujo artificialmente la tasa de ingesta del trabajo de Stream Analytics. Es bastante habitual que, al resolver un cuello de botella de rendimiento, se produzca otro. En este caso, asignar unidades de streaming adicionales para el trabajo de Stream Analytics resolvió el problema.
DevOps
Cree grupos de recursos independientes para entornos de producción, desarrollo y pruebas. Los grupos de recursos independientes facilitan la administración de implementaciones, la eliminación de implementaciones de prueba y la asignación de derechos de acceso.
Use la plantilla de Azure Resource Manager para implementar los recursos de Azure según el proceso de infraestructura como código (IaC). Con las plantillas, es más fácil automatizar las implementaciones mediante Azure DevOps Services u otras soluciones de CI/CD.
Coloque cada carga de trabajo en una plantilla de implementación independiente y almacene los recursos en los sistemas de control de código fuente. Puede implementar las plantillas en conjunto o por separado como parte de un proceso de CI/CD, lo que facilita el proceso de automatización.
En esta arquitectura, Azure Event Hubs, Log Analytics y Azure Cosmos DB se identifican como una sola carga de trabajo. Estos recursos se incluyen en una sola plantilla de Resource Manager.
Considere la posibilidad de almacenar provisionalmente las cargas de trabajo. Realice la implementación en varias fases y ejecute comprobaciones de validación en cada fase antes de pasar a la siguiente fase. De este modo, puede enviar actualizaciones a los entornos de producción de una manera muy controlada y minimizar los problemas de implementación imprevistos.
Considere la posibilidad de usar Azure Monitor para analizar el rendimiento de la canalización de procesamiento de flujos. Para obtener más información, consulte Supervisión de Azure Databricks.
Para más información, consulte el fundamento de excelencia operativa en Microsoft Azure Well-Architected Framework.
Eficiencia del rendimiento
La eficiencia del rendimiento es la capacidad de la carga de trabajo para escalar a fin de satisfacer las demandas que los usuarios ponen en ella de forma eficaz. Para obtener más información, vea Lista de comprobación de revisión de diseño para la eficiencia del rendimiento.
Event Hubs
La capacidad de procesamiento de Event Hubs se mide en unidades de procesamiento. Para escalar un centro de eventos automáticamente, puede habilitar el inflado automático, que permite escalar las unidades de procesamiento en función del tráfico, hasta un máximo configurado.
Stream Analytics
Para Stream Analytics, los recursos de proceso que se asignan a un trabajo se miden en unidades de streaming. Los trabajos de Stream Analytics escalan mejor si el trabajo se puede ejecutar en paralelo. De este modo, Stream Analytics puede distribuir el trabajo entre varios nodos de proceso.
Para los datos de entrada de Event Hubs, utilice la palabra clave PARTITION BY para dividir el trabajo de Stream Analytics en particiones. Los datos se dividirán en subconjuntos en función de las particiones de Event Hubs.
Las funciones de intervalos de tiempo y las combinaciones temporales requieren unidades de streaming adicionales. Cuando sea posible, use PARTITION BY para que cada partición se procese por separado. Para más información, consulte Descripción y ajuste de las unidades de streaming.
Si no es posible ejecutar todo el trabajo de Stream Analytics en paralelo, intente dividirlo en varios pasos, empezando con uno o varios pasos en paralelo. De este modo, los primeros pasos que pueden ejecutar en paralelo. Por ejemplo, en esta arquitectura de referencia:
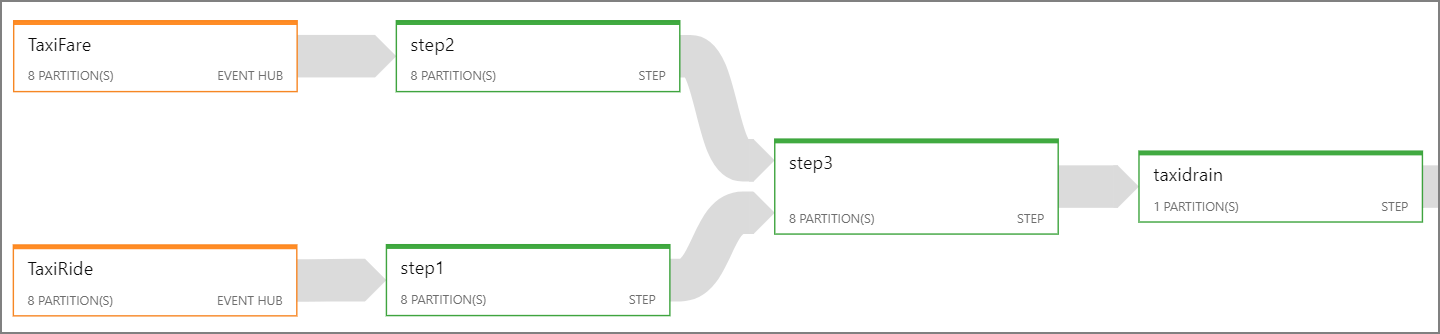
- Los pasos 1 y 2 son instrucciones
SELECTsimples que seleccionan registros dentro de una sola partición. - El paso 3 realiza una combinación con particiones en los dos flujos de entrada. Este paso aprovecha del hecho de que los registros que coinciden comparten la misma clave de partición y, por lo tanto, garantiza que tendrán el mismo identificador de partición en cada flujo de entrada.
- El paso 4 realiza la agregación en todas las particiones. Este paso no se puede ejecutar en paralelo.
Use el diagrama de trabajo de Stream Analytics para ver cuántas particiones se asignan a cada paso del trabajo. El siguiente diagrama muestra el diagrama de trabajo de esta arquitectura de referencia:
Azure Cosmos DB
La capacidad de procesamiento de Azure Cosmos DB se mide en unidades de solicitud (RU). Para escalar un contenedor de Azure Cosmos DB más allá de 10 000 RU, debe especificar una clave de partición al crear el contenedor, e incluir la clave de partición en todos los documentos.
En esta arquitectura de referencia, se crean nuevos documentos solo una vez por minuto (el intervalo de la ventana salto), por lo que los requisitos de procesamiento son bastante bajos. Por ese motivo, no es necesario asignar una clave de partición en este escenario.
Implementación de este escenario
Para la implementación y la ejecución de la implementación de referencia, siga los pasos del archivo Léame de GitHub.
Recursos relacionados
- procesamiento de Stream con Azure Databricks
- procesamiento de flujos con de datos de código abierto