Comprender y ajustar las unidades de streaming de Stream Analytics
Descripción de la unidad de streaming y el nodo de streaming
Las unidades de streaming (SU) representan los recursos informáticos que se asignan para ejecutar un trabajo de Stream Analytics. Cuanto mayor sea el número de unidades de streaming, más recursos de CPU y memoria se asignarán al trabajo. Esta función le permite centrarse en la lógica de consulta y abstrae la necesidad de administrar el hardware para ejecutar el trabajo de Stream Analytics de manera oportuna.
Azure Stream Analytics admite dos estructuras de unidad de streaming: SU V1 (que quedará en desuso) y SU V2 (recomendada).
El modelo de SU V1 es la oferta original de Azure Stream Analytics (ASA) donde cada 6 SU corresponden a un único nodo de streaming para un trabajo. Los trabajos también se pueden ejecutar con 1 y 3 SU y se corresponden con nodos de streaming fraccionarios. El escalado se produce en incrementos de 6 más allá de 6 trabajos de SU, a 12, 18, 24 y versiones posteriores, agregando más nodos de streaming que proporcionan recursos informáticos distribuidos.
El modelo de SU V2 (recomendado) es una estructura simplificada con precios favorables para los mismos recursos de proceso. En el modelo de SU V2, 1 SU V2 corresponde a un nodo de streaming para el trabajo. 2 SU V2 corresponden a 2, 3 a 3, etc. Los trabajos con 1/3 y 2/3 de SU V2 también están disponibles con un nodo de streaming, pero una fracción de los recursos informáticos. Los trabajos de 1/3 y 2/3 de SU V2 ofrecen una opción rentable para las cargas de trabajo que requieren una escala menor.
La potencia de proceso subyacente para las unidades de streaming V1 y V2 es la siguiente:
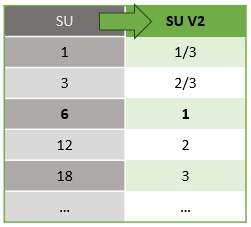
Para obtener información sobre los precios de SU, visite la página de precios de Azure Stream Analytics.
Descripción de las conversiones de unidad de streaming y dónde se aplican
Existe una conversión automática de las unidades de streaming que se produce desde la capa de la API de REST a la interfaz de usuario (Azure Portal y Visual Studio Code). Observará esta conversión también en el Registro de actividad, donde los valores de SU aparecen de forma diferente a los valores de la interfaz de usuario. Este comportamiento es por diseño y el motivo es que los campos de la API de REST están limitados a valores enteros y los trabajos de ASA admiten nodos fraccionarios (1/3 y 2/3 unidades de streaming). La interfaz de usuario de ASA muestra los valores de los nodos 1/3, 2/3, 1, 2, 3... etc., mientras que el back-end (Registros de actividad, capa de la API de REST) muestra los mismos valores multiplicados por 10 como 3, 7, 10, 20, 30 respectivamente.
| Estándar | Estándar V2 (UI) | Estándar V2 (back-end como registros, API de Rest, etc.) |
|---|---|---|
| 1 | 1/3 | 3 |
| 3 | 2/3 | 7 |
| 6 | 1 | 10 |
| 12 | 2 | 20 |
| 18 | 3 | 30 |
| ... | ... | ... |
Esto nos permite transmitir la misma granularidad y eliminar el punto decimal en la capa de API para las SKU V2. Esta conversión es automática y no afecta al rendimiento del trabajo.
Comprender el consumo y la utilización de la memoria
Para lograr un procesamiento de streaming de latencia baja, los trabajos de Azure Stream Analytics realizan todo el procesamiento en memoria. El trabajo de streaming presenta un error cuando se queda sin memoria. Como resultado, en el caso de un trabajo de producción, resulta importante supervisar el uso de recursos de un trabajo de streaming, y debe asegurarse de que hay recursos asignados suficientes para mantener los trabajos en ejecución de manera ininterrumpida.
La métrica de uso del % de SU, que oscila de 0 % al 100 %, describe el consumo de memoria de la carga de trabajo. Para un trabajo de streaming con una superficie mínima, esta métrica suele estar entre el 10 % y el 20 %. Si el porcentaje de uso de SU fuera alto (por encima del 80 %) o si los eventos de entrada quedasen pendientes (incluso con un porcentaje de uso de SU bajo, dado que no muestra el uso de la CPU), puede que la carga de trabajo requiera más recursos informáticos, para lo que sería necesario aumentar el número de unidades de almacenamiento. Se recomienda mantener la métrica de SU por debajo del 80 % y así tener en cuenta las subidas ocasionales. Para reaccionar a mayores cargas de trabajo y aumentar las unidades de streaming, considere la posibilidad de establecer una alerta del 80 % en la métrica de uso de SU. Asimismo, puede usar las métricas de retraso en la marca de agua y de eventos pendientes para ver si esto produce algún impacto.
Configuración de las unidades de streaming (SU) de Stream Analytics
Inicie sesión en Azure Portal.
En la lista de recursos, busque el trabajo de Stream Analytics que quiere escalar y ábralo.
En la página del trabajo, en el encabezado Configurar, seleccione Escalar. El número predeterminado de SU es 1 cuando se crea un trabajo.
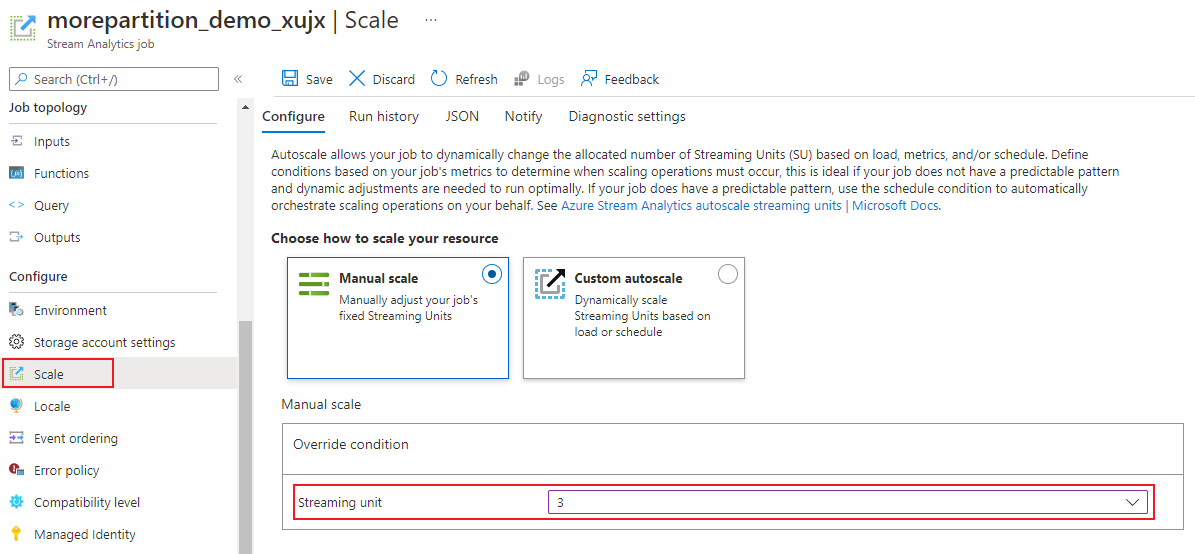
Elija la opción SU en la lista desplegable para establecer las SU del trabajo. Tenga en cuenta que está limitado a un rango de unidades de almacenamiento específico.
Puede cambiar el número de SU asignados a su trabajo mientras se está ejecutando. Es posible que esté restringido a elegir un conjunto de valores de SU cuando el trabajo se ejecute si su trabajo usa una salida sin particiones o tiene una consulta de varios pasos con valores PARTITION BY diferentes.
Supervisión del rendimiento del trabajo
A través del Azure Portal, puede hacer un seguimiento de las métricas relacionadas con el rendimiento de un trabajo. Para más información sobre la definición de métricas, consulte Métricas de trabajos de Azure Stream Analytics. Para más información sobre la supervisión de métricas en el portal, consulte Supervisión del trabajo de Stream Analytics con Azure Portal.
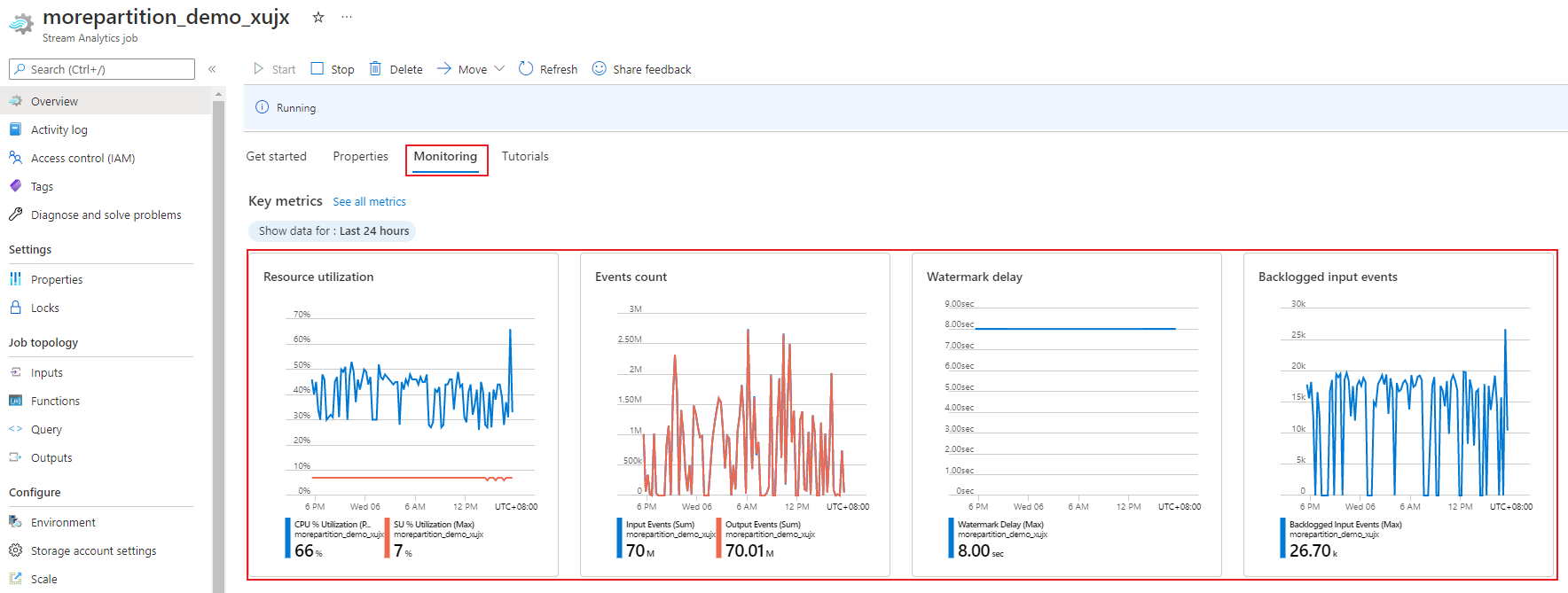
Calcule la capacidad de procesamiento esperada de la carga de trabajo. Si la capacidad de procesamiento es inferior a la esperada, ajuste la partición de entrada, ajuste la consulta y agregue unidades de streaming al trabajo.
¿Cuántas SU son necesarias para un trabajo?
La elección del número de SU necesarias para un trabajo determinado depende de la configuración de particiones de las entradas y de la consulta definida dentro del trabajo. La página Escala le permite establecer el número correcto de SU. Es recomendable asignar más unidades de streaming de las necesarias. El motor de procesamiento de Stream Analytics se optimiza para la latencia y el rendimiento, a costa de asignar memoria adicional.
En general, el procedimiento recomendado es comenzar con 1 SU V2 para consultas que no usen PARTITION BY. Luego, determine el punto favorable mediante un método de prueba y error en el que modifica el número de SU después de pasar las cantidades de datos representativas y examinar la métrica de porcentaje de uso de SU. El número máximo de unidades de streaming que se puede utilizar en un trabajo de Stream Analytics depende del número de pasos de la consulta definida para el trabajo y del número de particiones en cada paso. Puede obtener más información sobre los límites aquí.
Para obtener más información sobre cómo elegir el número correcto de SU, consulte está página: Escalado de trabajos de Azure Stream Analytics para incrementar el rendimiento.
Nota
La elección del número de unidades de streaming que se necesitan para un trabajo en concreto depende de la configuración de particiones para las entradas y de la consulta definida para el trabajo. Puede seleccionar como máximo su cuota en unidades de streaming para un trabajo. Para obtener más información sobre la cuota de suscripción de Azure Stream Analytics, visite Límites de Stream Analytics. Para aumentar las unidades de streaming de sus suscripciones, contacte con Soporte técnico de Microsoft. Los valores válidos para las SU por trabajo son 1/3, 2/3, 1, 2, 3, etc.
Factores que aumentan el porcentaje de uso de SU
Los elementos de consulta temporal (orientados al tiempo) son el conjunto básico de operadores con estado proporcionados por Stream Analytics. Stream Analytics administra el estado de estas operaciones internamente en nombre de usuario, mediante la administración del consumo de memoria, los puntos de comprobación para la resistencia y la recuperación del estado durante las actualizaciones de servicio. Aunque Stream Analytics administra totalmente los estados, hay muchas prácticas recomendadas que los usuarios deberían tener en cuenta.
Tenga en cuenta que un trabajo con lógica de consulta compleja podría tener un alto porcentaje de utilización de unidades de streaming, incluso cuando no está recibiendo continuamente eventos de entrada. Esto puede suceder después de un repentino aumento de los eventos de entrada y salida. El trabajo puede continuar manteniendo el estado en memoria si la consulta es compleja.
El porcentaje de utilización de unidades de streaming podría caer repentinamente a 0 durante un breve período antes de volver a los niveles esperados. Se produce debido a errores transitorios o actualizaciones iniciadas por el sistema. Aumentar el número de unidades de streaming para un trabajo podría no reducir el porcentaje de utilización de SU si la consulta no es totalmente paralela.
Al comparar el uso durante un período de tiempo, utilice las métricas de velocidad de eventos. Las métricas InputEvents y OutputEvents muestran el número de eventos que se leyeron y procesaron. También hay métricas que indican el número de eventos de error, como los errores de deserialización. Cuando aumenta el número de eventos por unidad de tiempo, el porcentaje de unidades de almacenamiento aumenta en la mayoría de los casos.
Lógica de consulta con estado en elementos temporales
Una funcionalidad única de un trabajo de Azure Stream Analytics es realizar procesamiento con estado, como funciones de análisis temporal, combinaciones temporales y agregados en ventanas. Cada uno de estos operadores conserva información de estado. El tamaño máximo de la ventana para estos elementos de consulta es siete días.
El concepto de ventana temporal aparece en varios elementos de consulta de Stream Analytics:
Agregados en ventanas: GROUP BY de ventanas de saltos de tamaño constante, de salto y deslizantes
Combinaciones temporales: Función JOIN con DATEDIFF
Funciones de análisis temporal: ISFIRST, LAST y LAG con LIMIT DURATION
Los siguientes factores influyen en la memoria utilizada (que forma parte de la métrica de unidades de streaming) por los trabajos de Stream Analytics:
Agregados en ventanas
La memoria utilizada (tamaño de estado) para un agregado en ventanas no siempre es directamente proporcional al tamaño de la ventana. En su lugar, la memoria utilizada es proporcional a la cardinalidad de los datos o el número de grupos de cada ventana temporal.
Por ejemplo, en la consulta siguiente, el número asociado con clusterid es la cardinalidad de la consulta.
SELECT count(*)
FROM input
GROUP BY clusterid, tumblingwindow (minutes, 5)
Para mitigar los problemas causados por una cardinalidad alta en la consulta anterior, puede enviar eventos a Event Hubs particionados por clusterid, y escalar horizontalmente la consulta al permitir que el sistema procese cada partición de entrada por separado mediante PARTITION BY como se muestra en el ejemplo siguiente:
SELECT count(*)
FROM input PARTITION BY PartitionId
GROUP BY PartitionId, clusterid, tumblingwindow (minutes, 5)
Una vez que la consulta está particionada, se extiende por varios nodos. Como resultado, el número de valores clusterid que entra en cada nodo se reduce, lo que disminuye la cardinalidad del grupo por operador.
Las particiones de Event Hubs se deben particionar según la clave de agrupación para evitar la necesidad de un paso de reducción. Para obtener más información, consulte Información general sobre Event Hubs.
Combinaciones temporales
La memoria consumida (tamaño del estado) de una unión temporal es proporcional al número de eventos en el espacio de ondulación temporal de la unión, que es la tasa de entrada del evento multiplicada por el tamaño del espacio de ondulación. En otras palabras, la memoria utilizada por las combinaciones es proporcional al intervalo de tiempo DateDiff multiplicado por la tasa media de los eventos.
La cantidad de eventos no coincidentes en la combinación afecta el uso de memoria de la consulta. La consulta siguiente busca las impresiones de anuncios que generan clics:
SELECT clicks.id
FROM clicks
INNER JOIN impressions ON impressions.id = clicks.id AND DATEDIFF(hour, impressions, clicks) between 0 AND 10.
En este ejemplo, es posible que se muestren muchos anuncios, pero que pocas personas hagan clic en ellos, por lo que es necesario mantener todos los eventos en la ventana de tiempo. La memoria consumida es proporcional al tamaño de ventana y la tasa de eventos.
Para corregir este comportamiento, envíe eventos a Event Hubs particionados por las claves de combinación (identificador en este caso) y escale horizontalmente la consulta al permitir que el sistema procese cada partición de entrada por separado mediante PARTITION BY como se muestra:
SELECT clicks.id
FROM clicks PARTITION BY PartitionId
INNER JOIN impressions PARTITION BY PartitionId
ON impression.PartitionId = clicks.PartitionId AND impressions.id = clicks.id AND DATEDIFF(hour, impressions, clicks) between 0 AND 10
Una vez que la consulta está particionada, se extiende por varios nodos. Como resultado, el número de eventos que entra en cada nodo se reduce, lo que disminuye el tamaño del estado que se conserva en la ventana de la combinación.
Funciones de análisis temporal
La memoria consumida (tamaño del estado) de una función de análisis temporal es proporcional a la tasa de eventos multiplicada por la duración. La memoria utilizada por las funciones analíticas no es proporcional al tamaño de la ventana, sino más bien a la cantidad de particiones de cada ventana temporal.
La solución es similar a la combinación temporal. Puede escalar horizontalmente la consulta con PARTITION BY.
Búfer desordenado
El usuario puede configurar el tamaño de búfer desordenado en el panel de configuración de la ordenación de eventos. El búfer se usa para contener entradas para la duración de la ventana y para reordenarlas. El tamaño del búfer es proporcional a la tasa de entrada de eventos multiplicada por el tamaño de la ventana desordenada. El tamaño predeterminado de la ventana es 0.
Para corregir el desbordamiento del búfer desordenado, escale la consulta horizontalmente con PARTITION BY. Una vez que la consulta está particionada, se extiende por varios nodos. Como resultado, el número de eventos que entra en cada nodo se reduce, lo que disminuye el número de eventos en cada búfer de reordenación.
Número de particiones de entrada
Cada partición de entrada de una entrada del trabajo tiene un búfer. Mientras más grande sea la cantidad de particiones de entrada, más recursos consume el trabajo. Para cada unidad de streaming, Azure Stream Analytics puede procesar aproximadamente 7 MB/s de entrada. Por lo tanto, es posible mejorarlo haciendo coincidir el número de unidades de streaming de Stream Analytics con el número de particiones de Event Hub.
Normalmente, un trabajo configurado con 1/3 de la unidad de streaming es suficiente para un centro de eventos con dos particiones (que es el valor mínimo para el centro de eventos). Si Event Hub tiene más particiones, el trabajo de Stream Analytics consume más recursos, pero no consume necesariamente el rendimiento adicional que proporciona Event Hubs.
En el caso de un trabajo de unidades de streaming 1 V2, podría necesitar 4 u 8 particiones del centro de eventos. Sin embargo, evite demasiadas particiones innecesarias, porque provoca un uso de recursos excesivo. Por ejemplo, un Event Hub con 16 particiones o más en un trabajo de Stream Analytics que tiene 1 unidad de streaming.
Datos de referencia
Los datos de referencia en ASA se cargan en la memoria para poder realizar una búsqueda rápida. Con la implementación actual, cada operación de combinación con datos de referencia conserva una copia de estos datos en la memoria, incluso si se combina varias veces con los mismos datos de referencia. Para consultas con PARTITION BY, cada partición tiene una copia de los datos de referencia, por lo que las particiones están completamente desacopladas. Con el efecto multiplicador, el uso de la memoria puede aumentar muchísimo rápidamente si combina con datos de referencia varias veces con varias particiones.
Uso de las funciones UDF
Al agregar una función UDF, Azure Stream Analytics carga el tiempo de ejecución de JavaScript en la memoria, lo que afecta al SU%.
Pasos siguientes
- Creación de consultas que se pueden paralelizar en Azure Stream Analytics
- Escalar los trabajos de Azure Stream Analytics para incrementar el rendimiento
- Métricas de trabajo de Stream Analytics
- Dimensiones de métricas de trabajo de Azure Stream Analytics
- Supervisión del trabajo de Stream Analytics con Azure Portal
- Analizar el rendimiento del trabajo de Stream Analytics con dimensiones métricas
- Descripción y ajuste de las unidades de streaming