Personalizar un modelo con ajuste preciso
Azure OpenAI Service le permite adaptar nuestros modelos a sus conjuntos de datos personales mediante un proceso conocido como ajuste preciso. Este paso de personalización le permite sacar más provecho del servicio al proporcionarle:
- Resultados de mayor calidad que los que puede obtener solo con la ingeniería de una solicitud
- La capacidad de formarse con más ejemplos de los que caben en el límite máximo de contexto de solicitud de un modelo.
- Ahorro de tokens debido a solicitudes más cortas
- Solicitudes de baja latencia, especialmente cuando se usan modelos más pequeños.
A diferencia del aprendizaje en pocos pasos, el ajuste preciso mejora el modelo mediante el entrenamiento en muchos más ejemplos de los que pueden caber en una solicitud, lo que le permite lograr mejores resultados en un gran número de tareas. Dado que el ajuste preciso ajusta los pesos del modelo base para mejorar el rendimiento en la tarea específica, no tendrá que incluir tantos ejemplos o instrucciones en la solicitud. Esto significa que se envía menos texto y se procesan menos tokens en cada llamada API, lo que puede ahorrar costos y mejorar la latencia de las solicitudes.
Usaremos LoRA, o aproximación de rango bajo, para ajustar los modelos de forma que se reduzca su complejidad sin afectar significativamente a su rendimiento. Este método funciona aproximando la matriz de alto rango original a una de rango inferior, por lo que solo se ajusta un subconjunto más pequeño de parámetros importantes durante la fase de entrenamiento supervisado, lo que hace que el modelo sea más fácil de administrar y eficiente. Para los usuarios, esto hace que el entrenamiento sea más rápido y asequible que otras técnicas.
Hay dos experiencias únicas de ajuste preciso en el portal de Azure AI Foundry:
- Vista de hub/proyecto: es compatible con modelos de optimización de múltiples proveedores, incluidos Azure OpenAI, Meta Llama, Microsoft Phi, etc.
- Vista centrada en Azure OpenAI: solo admite la optimización de los modelos de Azure OpenAI, pero tiene compatibilidad con características adicionales como la Integración de vista previa de Weights & Biases (W&B).
Si solo va a ajustar los modelos de Azure OpenAI, se recomienda la experiencia centrada en el ajuste preciso de Azure OpenAI, disponible navegando a https://oai.azure.com.
Requisitos previos
- Lea la guía Cuándo usar el ajuste preciso de Azure OpenAI.
- Suscripción a Azure. cree una de forma gratuita.
- Un recurso de Azure OpenAI que se encuentra en una región que admite el ajuste preciso del modelo de Azure OpenAI. Compruebe la tabla de resumen del modelo y de disponibilidad de regiones para ver la lista de modelos disponibles por región y la funcionalidad admitida. Para obtener más información, consulte Creación de un recurso e implementación de un modelo con Azure OpenAI.
- El ajuste preciso del acceso requiere Colaborador de OpenAI de Cognitive Services.
- Si aún no tiene acceso para ver la cuota e implementar modelos en el portal de Azure AI Foundry, necesitará permisos adicionales.
Modelos
Los modelos siguientes admiten el ajuste preciso:
-
gpt-35-turbo(0613) -
gpt-35-turbo(1106) -
gpt-35-turbo(0125) -
gpt-4(0613)* -
gpt-4o(2024-08-06) -
gpt-4o-mini(18-07-2024)
* El ajuste preciso de este modelo está actualmente en versión preliminar pública.
O bien, puede realizar el ajuste preciso de un modelo previamente ajustado, con el formato base-model.ft-{jobid}.
Consulte la página de modelos para comprobar qué regiones admiten actualmente el ajuste preciso.
Revisión del flujo de trabajo para el Portal de la Fundición de IA de Azure
Dedique un momento a revisar el flujo de trabajo de ajuste para usar el Portal de la Fundición de IA de Azure:
- Prepare los datos de entrenamiento y validación.
- Use el asistente para Creación de modelos personalizados en el portal de Azure AI Foundry para entrenar el modelo personalizado.
- Seleccione un modelo base.
- Elija los datos de entrenamiento.
- Opcionalmente, elija los datos de validación.
- Opcionalmente, configure los parámetros de la tarea para el trabajo de ajuste preciso.
- Revise las opciones y entrene el nuevo modelo personalizado.
- Compruebe el estado del modelo con ajuste preciso personalizado.
- Implemente el modelo personalizado para su uso.
- Use el modelo personalizado.
- Opcionalmente, analice el modelo personalizado para mejorar el rendimiento y ajustarlo.
Preparación de los datos de entrenamiento y validación
El conjunto de datos de validación y los datos de entrenamiento consisten en ejemplos de entrada y salida para el rendimiento del modelo.
Los datos de entrenamiento y validación que usa deben tener formato como documento de líneas JSON (JSONL). En el caso de gpt-35-turbo (todas las versiones), gpt-4, gpt-4o y gpt-4o-mini, el conjunto de datos de ajuste preciso debe tener el formato conversacional que usa la API de finalizaciones de chat.
Si desea un tutorial paso a paso sobre cómo ajustar un modelo gpt-4o-mini (18/7/2024) consulte el Tutorial de ajuste detallado de Azure OpenAI.
Formato de archivo de ejemplo
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who discovered Antarctica?"}, {"role": "assistant", "content": "Some chaps named Fabian Gottlieb von Bellingshausen and Mikhail Lazarev, as if they don't teach that in every school!"}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What is the biggest ocean?"}, {"role": "assistant", "content": "The Pacific Ocean. It's not like it's a small pond or anything."}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What is the largest planet?"}, {"role": "assistant", "content": "It's called Jupiter, you might have heard of it...or not."}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who painted the Mona Lisa?"}, {"role": "assistant", "content": "Oh, some obscure artist named Leonardo da Vinci. Not that he is famous or anything."}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the boiling point of water?"}, {"role": "assistant", "content": "Exciting fact of the day: it's 100 degrees Celsius. Life-changing, isn't it?"}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who wrote 'The Odyssey'?"}, {"role": "assistant", "content": "Oh, just some poet named Homer. Nothing special, really."}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What is the largest mammal?"}, {"role": "assistant", "content": "Blue Whale. Quite a big fish isn't it? Oh wait, it's not a fish!"}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the highest mountain peak?"}, {"role": "assistant", "content": "Everest. Brace yourself, it's not a walk in the park."}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who invented the telephone?"}, {"role": "assistant", "content": "A guy named Alexander Graham Bell. Bet you didn't guess that one!"}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What is the distance from Earth to the Sun?"}, {"role": "assistant", "content": "About 93 million miles. Just a quick drive, really."}]}
Formato de archivo de chat multiturno de Azure OpenAI
También se admiten varios turnos de una conversación en una sola línea del archivo de entrenamiento jsonl. Para omitir el ajuste específico de los mensajes del asistente, agregue el par de valores de clave opcional weight. Actualmente, weight se puede establecer en 0 o 1.
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the capital of France?"}, {"role": "assistant", "content": "Paris", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Paris, as if everyone doesn't know that already.", "weight": 1}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who wrote 'Romeo and Juliet'?"}, {"role": "assistant", "content": "William Shakespeare", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Oh, just some guy named William Shakespeare. Ever heard of him?", "weight": 1}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "How far is the Moon from Earth?"}, {"role": "assistant", "content": "384,400 kilometers", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Around 384,400 kilometers. Give or take a few, like that really matters.", "weight": 1}]}
Finalizaciones de chat con visión
{"messages": [{"role": "user", "content": [{"type": "text", "text": "What's in this image?"}, {"type": "image_url", "image_url": {"url": "https://raw.githubusercontent.com/MicrosoftDocs/azure-ai-docs/main/articles/ai-services/openai/media/how-to/generated-seattle.png"}}]}, {"role": "assistant", "content": "The image appears to be a watercolor painting of a city skyline, featuring tall buildings and a recognizable structure often associated with Seattle, like the Space Needle. The artwork uses soft colors and brushstrokes to create a somewhat abstract and artistic representation of the cityscape."}]}
Además del formato JSONL, los archivos de datos de entrenamiento y validación deben codificarse en UTF-8 e incluir una marca de orden de bytes (BOM). El archivo debe tener un tamaño inferior a 512 MB.
Creación de conjuntos de datos de entrenamiento y validación
Cuantos más ejemplos de entrenamiento tenga, mejor. Los trabajos de ajuste preciso no se llevarán a cabo sin al menos 10 ejemplos de entrenamiento, pero un número tan pequeño no es suficiente para influir notablemente en las respuestas del modelo. Es recomendable proporcionar cientos, o incluso miles, de ejemplos de entrenamiento para llevarlos a cabo correctamente.
En general, al duplicar el tamaño del conjunto de datos se puede producir un aumento lineal de la calidad del modelo. Sin embargo, tenga en cuenta que los ejemplos de baja calidad pueden afectar negativamente al rendimiento. Si entrena el modelo en una gran cantidad de datos internos, sin eliminar primero el conjunto de datos solo para los ejemplos de mayor calidad, podría acabar con un modelo que funciona mucho peor de lo esperado.
Uso del Asistente para crear modelos personalizados
En el Portal de la Fundición de IA de Azure se proporciona el asistente para Crear modelos personalizados, por lo que puede crear y entrenar de forma interactiva un modelo ajustado de forma precisa para el recurso de Azure.
Abra el Portal de la Fundición de IA de Azure en https://oai.azure.com/ e inicie sesión con las credenciales que le permitan acceder al recurso de Azure OpenAI. Durante el flujo de trabajo de inicio de sesión, seleccione el directorio, la suscripción de Azure y el recurso de Azure OpenAI adecuados.
En el portal de Azure AI Foundry, vaya al panel Herramientas> de ajuste precisoy seleccione Ajuste de modelos.

Se abre el Asistente para crear modelos personalizados.
Selección del modelo base
El primer paso para crear un modelo personalizado es elegir un modelo base. El panel Modelo base le permite elegir un modelo base que se utilizará para el modelo personalizado. La elección influye tanto en el rendimiento como en el costo del modelo.
Seleccione un modelo base de la lista desplegable Tipo de modelo base y, a continuación, seleccione Siguiente para continuar.
- O bien, puede realizar el ajuste preciso de un modelo previamente ajustado, con el formato base-model.ft-{jobid}.

Para obtener más información sobre los modelos base que se pueden ajustar, consulte Modelos.
Elección de los datos de entrenamiento
El siguiente paso consiste en elegir los datos de entrenamiento que ya están preparados o cargar nuevos datos de entrenamiento que se usarán al personalizar el modelo. En el panel Datos de entrenamiento se muestran los conjuntos de datos existentes cargados previamente, y también se proporcionan opciones para cargar nuevos datos de entrenamiento.

Si los datos de entrenamiento ya se han cargado en el servicio, seleccione Archivos de conexión de Azure OpenAI.
- Seleccione el archivo en la lista desplegable que se muestra.
Para cargar nuevos datos de entrenamiento, use una de las siguientes opciones:
Seleccione Archivo local para cargar datos de entrenamiento desde un archivo local.
Seleccione blob de Azure u otras ubicaciones web compartidas para importar los datos de entrenamiento desde un blob de Azure u otra ubicación web compartida.
En cuanto a los archivos de datos grandes, le recomendamos que los importe desde el almacén de blobs de Azure. Los archivos grandes pueden volverse inestables cuando se cargan a través de formularios multiparte porque las solicitudes son atómicas y no se pueden volver a intentar o reanudar. Para obtener más información acerca de Azure Blob Storage, consulte ¿Qué es Azure Blob Storage?
Nota:
Los archivos de datos de entrenamiento deben tener el formato JSONL, estar codificados en UTF-8 con una marca de orden de bytes (BOM). El archivo debe tener un tamaño inferior a 512 MB.
Carga de los datos de entrenamiento desde un archivo local
Puede cargar un nuevo conjunto de datos de entrenamiento en el servicio desde un archivo local mediante uno de los métodos siguientes:
Arrastre y coloque el archivo en el área cliente del panel Datos de entrenamiento y, a continuación, seleccione Cargar archivo.
Seleccione Buscar un archivo en el área cliente del panel Datos de entrenamiento, elija el archivo que quiere cargar en el cuadro de diálogo Abrir y, a continuación, seleccione Cargar archivo.
Después de seleccionar y cargar el conjunto de datos de entrenamiento, seleccione Siguiente para continuar.

Importación de datos de entrenamiento desde el almacén de blobs de Azure
Puede importar un conjunto de datos de entrenamiento desde un blob de Azure u otra ubicación web compartida proporcionando el nombre y la ubicación del archivo.
Escriba el nombre de archivo del archivo.
Para la ubicación del archivo, proporcione la dirección URL del blob de Azure, la firma de acceso compartido (SAS) de Azure Storage u otro vínculo a una ubicación web compartida accesible.
Seleccione Importar para importar el conjunto de datos de entrenamiento en el servicio.
Después de seleccionar y cargar el conjunto de datos de entrenamiento, seleccione Siguiente para continuar.

Elección de los datos de validación
En el paso siguiente se proporcionan opciones para configurar el modelo que usará los datos de validación en el proceso de entrenamiento. Si no quiere usar datos de validación, puede elegir Siguiente para continuar a las opciones avanzadas del modelo. De lo contrario, si tiene un conjunto de datos de validación, puede elegir los datos de validación que ya están preparados o cargar nuevos datos de validación preparados para usarlos al personalizar el modelo.
En el panel Datos de validación se muestran los conjuntos de datos de entrenamiento y validación existentes cargados previamente, y se proporcionan opciones según las que puede cargar nuevos datos de validación.

Si los datos de validación ya se han cargado en el servicio, seleccione Elegir conjunto de datos.
- Seleccione el archivo de la lista que se muestra en el panel Datos de validación.
Para cargar nuevos datos de validación, use una de las siguientes opciones:
Seleccione Archivo local para cargar datos de validación desde un archivo local.
Seleccione blob de Azure u otras ubicaciones web compartidas para importar los datos de validación desde un blob de Azure u otra ubicación web compartida.
En cuanto a los archivos de datos grandes, le recomendamos que los importe desde el almacén de blobs de Azure. Los archivos grandes pueden volverse inestables cuando se cargan a través de formularios multiparte porque las solicitudes son atómicas y no se pueden volver a intentar o reanudar.
Nota:
Al igual que los archivos de datos de entrenamiento, los archivos de datos de validación deben tener el formato JSONL, estar codificados en UTF-8 con una marca de orden de bytes (BOM). El archivo debe tener un tamaño inferior a 512 MB.
Carga de los datos de validación desde un archivo local
Puede cargar un nuevo conjunto de datos de validación en el servicio desde un archivo local mediante uno de los métodos siguientes:
Arrastre y coloque el archivo en el área cliente del panel Datos de validación y, a continuación, seleccione Cargar archivo.
Seleccione Buscar un archivo en el área cliente del panel Datos de validación, elija el archivo que quiere cargar en el cuadro de diálogo Abrir y, a continuación, seleccione Cargar archivo.
Después de seleccionar y cargar el conjunto de datos de validación, seleccione Siguiente para continuar.

Importación de datos de validación desde el almacén de blobs de Azure
Puede importar un conjunto de datos de validación desde un blob de Azure u otra ubicación web compartida proporcionando el nombre y la ubicación del archivo.
Escriba el nombre de archivo del archivo.
Para la ubicación del archivo, proporcione la dirección URL del blob de Azure, la firma de acceso compartido (SAS) de Azure Storage u otro vínculo a una ubicación web compartida accesible.
Seleccione Importar para importar el conjunto de datos de entrenamiento en el servicio.
Después de seleccionar y cargar el conjunto de datos de validación, seleccione Siguiente para continuar.

Configuración de los parámetros de la tarea
El asistente Crear modelo personalizado muestra los parámetros para entrenar el modelo con ajuste preciso en el panel Parámetros de tarea. Están disponibles los siguientes parámetros:
| Nombre | Tipo | Descripción |
|---|---|---|
batch_size |
integer | El tamaño del lote a usar para el entrenamiento. El tamaño del lote es el número de ejemplos de entrenamiento usados para entrenar una sola pasada hacia adelante y hacia atrás. En general, hemos comprobado que los tamaños de lote más grandes tienden a funcionar mejor para conjuntos de datos más grandes. El valor predeterminado, así como el valor máximo de esta propiedad, son específicos de un modelo base. Un tamaño de lote mayor significa que los parámetros del modelo se actualizan con menos frecuencia, pero con una varianza menor. |
learning_rate_multiplier |
number | El multiplicador de la tasa de aprendizaje que se usará para el entrenamiento. La tasa de aprendizaje de ajuste es la tasa de aprendizaje original que se usó para el preentrenamiento multiplicada por este valor. Las tasas de aprendizaje más grandes tienden a mejorar con tamaños de lote más grandes. Se recomienda experimentar con valores en el rango de 0,02 a 0,2 para ver qué produce los mejores resultados. Una tasa de aprendizaje más pequeña puede ser útil para evitar el sobreajuste. |
n_epochs |
integer | El número de épocas para entrenar el modelo. Una época se refiere a un ciclo completo a través del conjunto de datos de entrenamiento. |
seed |
integer | La inicialización controla la reproducibilidad del trabajo. Pasar los mismos parámetros de inicialización y trabajo debe generar los mismos resultados, pero puede diferir en raras ocasiones. Si no se especifica un valor de inicialización, se generará uno automáticamente |
Beta |
integer | Parámetro de temperatura para la pérdida de DPO, por lo general, en el intervalo de 0,1 a 0,5. Esto controla cuánta atención se le da al modelo de referencia. Cuanto más pequeño sea el valor de beta, más permitimos que el modelo se desvíe del modelo de referencia. A medida que la versión beta sea más pequeña, se omite el modelo de referencia. |

Seleccione Predeterminado para usar los valores predeterminados del trabajo de ajuste preciso o seleccione Personalizado para mostrar y editar los valores de los hiperparámetros. Cuando se seleccionan los valores predeterminados, determinamos el valor correcto de forma algorítmica en función de los datos de entrenamiento.
Después de configurar las opciones avanzadas, seleccione Siguiente para revisar las opciones y entrenar el modelo ajustado de forma precisa.
Revisión de las opciones y entrenamiento del modelo
El panel Revisar del asistente muestra información sobre las opciones de configuración.

Si está listo para entrenar el modelo, seleccione Inicio del trabajo de entrenamiento para iniciar el trabajo de ajuste preciso y volver al panel Modelos.
Comprobación del estado del modelo personalizado
El panel Modelos muestra información sobre el modelo personalizado en la pestaña Modelos personalizados. La pestaña incluye información sobre el estado y el identificador de trabajo del trabajo de ajuste preciso del modelo personalizado. Una vez completado el trabajo, la pestaña muestra el identificador de archivo del archivo de resultados. Es posible que tenga que seleccionar Actualizar para ver un estado actualizado para el trabajo de entrenamiento de modelos.

Después de haber iniciado un trabajo de ajuste preciso, puede tardar algo de tiempo en completarse. Es posible que el trabajo esté en cola detrás de otros trabajos del sistema. Entrenar el modelo puede tardar minutos u horas, dependiendo del modelo y del tamaño del conjunto de datos.
Estas son algunas de las tareas que puede realizar en el panel Modelos:
Compruebe el estado del trabajo de ajuste preciso del modelo personalizado en la columna Estado de la pestaña Modelos personalizados.
En la columna Nombre del modelo, seleccione el nombre del modelo para ver más información sobre el modelo personalizado. Puede ver el estado del trabajo de ajuste preciso, los resultados de entrenamiento, los eventos de entrenamiento y los hiperparámetros que se han usado en el trabajo.
Seleccione Descargar archivo de entrenamiento para descargar los datos de entrenamiento que usó para el modelo.
Seleccione Descargar resultados para descargar el archivo de resultados adjunto al trabajo de ajuste preciso del modelo y así analizar el modelo personalizado para el entrenamiento y el rendimiento de validación.
Seleccione Actualizar para actualizar la información de la página.
Puntos de control
Cuando finaliza cada época de entrenamiento, se genera un punto de control. Un punto de control es una versión totalmente funcional de un modelo que puede implementarse y usarse como modelo de destino para posteriores trabajos de ajuste. Los puntos de control pueden ser especialmente útiles, ya que pueden proporcionar una instantánea de su modelo antes de que se haya producido el sobreajuste. Cuando finalice un trabajo de ajuste, dispondrá de las tres versiones más recientes del modelo para implementarlas.
Evaluación de seguridad: ajuste fino de GPT-4, GPT-4o y GPT-4o-mini: vista previa pública
GPT-4o, GPT-4o-mini y GPT-4 son nuestros modelos más avanzados que se pueden ajustar a sus necesidades. Al igual que con los modelos de Azure OpenAI generalmente, las funcionalidades avanzadas de los modelos optimizados incluyen mayores desafíos de inteligencia artificial responsables relacionados con contenido dañino, manipulación, comportamiento similar al humano, problemas de privacidad y mucho más. Obtenga más información sobre los riesgos, las funcionalidades y las limitaciones de la Introducción a las prácticas de inteligencia artificial responsable y Nota sobre transparencia. Para ayudar a mitigar los riesgos asociados a modelos avanzados ajustados, hemos implementado pasos de evaluación adicionales para ayudar a detectar y evitar contenido dañino en el entrenamiento y salidas de modelos ajustados. Estos pasos se basan en Microsoft Responsible AI Standard y el filtrado de contenido de Azure OpenAI Service.
- Las evaluaciones se realizan en áreas de trabajo dedicadas, específicas del cliente y privadas;
- Los puntos de conexión de evaluación se encuentran en la misma geografía que el recurso de Azure OpenAI;
- Los datos de entrenamiento no se almacenan en conexión con la realización de evaluaciones; solo se conserva la evaluación final del modelo (que se puede implementar o no se puede implementar);
Los filtros de evaluación de modelos ajustados GPT-4o, GPT-4o-mini y GPT-4 están configurados según umbrales predefinidos y los clientes no pueden modificarlos; no están vinculados a ninguna configuración de filtrado de contenido personalizada que pueda haber creado.
Evaluación de datos
Antes de comenzar el entrenamiento, los datos se evalúan para contenido potencialmente dañino (violencia, sexual, odio y imparcialidad, ver: definiciones de categorías aquí). Si se detecta contenido perjudicial por encima del nivel de gravedad especificado, se producirá un error en el trabajo de entrenamiento y recibirá un mensaje que le informará de las categorías de error.
Mensaje de ejemplo:
The provided training data failed RAI checks for harm types: [hate_fairness, self_harm, violence]. Please fix the data and try again.
Los datos de entrenamiento se evalúan automáticamente dentro del trabajo de importación de datos como parte de proporcionar la funcionalidad de ajuste preciso.
Si se produce un error en el trabajo de ajuste debido a la detección de contenido dañino en los datos de entrenamiento, no se le cobrará.
Evaluación del modelo
Una vez completado el entrenamiento, pero antes de que el modelo optimizado esté disponible para la implementación, el modelo resultante se evalúa para las respuestas potencialmente perjudiciales mediante las métricas de riesgo y seguridad de Azure integradas. Con el mismo enfoque para probar que usamos para los modelos de lenguaje grandes base, nuestra capacidad de evaluación simula una conversación con su modelo ajustado para evaluar el potencial de generar contenido perjudicial, de nuevo usando contenido dañino especificado categorías (violencia, violencia, odio y equidad, autolesiones).
Si se encuentra un modelo para generar una salida que contenga contenido detectado como perjudicial por encima de una tasa aceptable, se le informará de que el modelo no está disponible para la implementación, con información sobre las categorías específicas de daño detectadas:
Mensajes de ejemplo:
This model is unable to be deployed. Model evaluation identified that this fine tuned model scores above acceptable thresholds for [Violence, Self Harm]. Please review your training data set and resubmit the job.

Al igual que con la evaluación de datos, el modelo se evalúa automáticamente dentro del trabajo de ajuste preciso como parte de proporcionar la funcionalidad de ajuste preciso. El servicio registra solo la evaluación resultante (implementable o no implementable). Si se produce un error en la implementación del modelo optimizado debido a la detección de contenido dañino en las salidas del modelo, no se le cobrará por la ejecución de entrenamiento.
Implementación de un modelo ajustado
Cuando el trabajo de ajuste preciso se haya realizado correctamente, puede implementar el modelo personalizado desde el panel Modelos. Debe implementar el modelo personalizado para poder usarlo con las llamadas de finalización.
Importante
Después de implementar un modelo personalizado, si en cualquier momento la implementación permanece inactiva durante más de quince (15) días, la implementación se eliminará automáticamente. La implementación de un modelo personalizado es inactivasi el modelo se ha implementado hace más de quince (15) días y no se han realizado finalizaciones ni llamadas de finalización de chat durante un período continuo de 15 días.
La eliminación de una implementación inactiva no elimina ni afecta al modelo personalizado subyacente, y el modelo personalizado se puede volver a implementar en cualquier momento. Como se describe en Precios de Azure OpenAI Service, cada modelo personalizado (ajustado a sus preferencias) que se implementa incurre en un costo de hospedaje por hora, independientemente de si se realizan finalizaciones o llamadas de finalización de chat al modelo. Para obtener más información sobre cómo planear y administrar los costos con Azure OpenAI, consulte la guía de Planeamiento para administrar los costos Azure OpenAI Service.
Nota:
Solo se permite una implementación para un modelo personalizado. Se muestra un mensaje de error si selecciona un modelo personalizado ya implementado.
Para implementar el modelo personalizado, seleccione el modelo personalizado que se va a implementar y, a continuación, seleccione Implementar modelo.

Se abre el cuadro de diálogo Implementar modelo. En el cuadro de diálogo, escriba el Nombre de la implementación y seleccione Crear para iniciar la implementación del modelo personalizado.

Puede supervisar el progreso de la implementación en el panel Implementaciones en el portal en Azure AI Foundry.
Implementación entre regiones
El ajuste preciso admite la implementación de un modelo ajustado en una región diferente a la de la ubicación en la que originalmente se ha ajustado el modelo. También puede implementar en otra suscripción o región.
Las únicas limitaciones son que la nueva región también debe admitir el ajuste preciso y, al implementar entre suscripciones, la cuenta que genera el token de autorización para la implementación debe tener acceso a las suscripciones de origen y de destino.
La implementación entre suscripciones o regiones se puede realizar a través de Python o REST.
Uso de un modelo personalizado implementado
Cuando su modelo personalizado se implemente, puede usarlo como cualquier otro modelo implementado. Puede utilizar las Área de juegos del Portal de la Fundición de IA de Azure para experimentar con la nueva implementación. Puede seguir usando los mismos parámetros con el modelo personalizado, como temperature y max_tokens, como puede hacer con otros modelos implementados.

Análisis del modelo personalizado
Azure OpenAI asocia un archivo de resultado denominado results.csv a cada trabajo de ajuste preciso una vez completado. Puede usar el archivo de resultados para analizar el rendimiento de entrenamiento y validación del modelo personalizado. El id. del archivo de resultados aparece en cada modelo personalizado en la columna Id. del archivo de resultados del panel Modelos para el Portal de la Fundición de IA de Azure. Puede usar el id. de archivo para identificar y descargar el archivo de resultados desde el panel Archivos de datos del Portal de la Fundición de IA de Azure.
El archivo de resultados es un archivo CSV que contiene una fila de encabezado y una fila para cada paso de entrenamiento que realizó el trabajo de ajuste preciso. El archivo de resultados contiene las columnas siguientes:
| Nombre de la columna | Descripción |
|---|---|
step |
El número del paso de entrenamiento. Un paso de entrenamiento representa un solo paso, hacia delante y hacia atrás, en un lote de datos de entrenamiento. |
train_loss |
La pérdida del lote de entrenamiento. |
train_mean_token_accuracy |
El porcentaje de token del lote de entrenamiento que el modelo predijo correctamente. Por ejemplo, si el tamaño del lote se establece en 3 y los datos contienen finalizaciones de tipo [[1, 2], [0, 5], [4, 2]], este valor se establece en 0,83 (5 de 6) si el modelo predijo [[1, 1], [0, 5], [4, 2]]. |
valid_loss |
La pérdida del lote de validación. |
validation_mean_token_accuracy |
El porcentaje de tokens en el lote de validación que el modelo predijo correctamente. Por ejemplo, si el tamaño del lote se establece en 3 y los datos contienen finalizaciones de tipo [[1, 2], [0, 5], [4, 2]], este valor se establece en 0,83 (5 de 6) si el modelo predijo [[1, 1], [0, 5], [4, 2]]. |
full_valid_loss |
La pérdida de validación calculada al final de cada época. Cuando el entrenamiento va bien, la pérdida debe disminuir. |
full_valid_mean_token_accuracy |
La precisión media válida de los tokens calculada al final de cada época. Cuando el entrenamiento va bien, la precisión del token debe aumentar. |
También puede ver los datos en el archivo results.csv como trazados en el portal de Azure AI Foundry. Seleccione el vínculo del modelo entrenado y verá tres gráficos: pérdida, precisión media del token y precisión del token. Si proporcionó datos de validación, ambos conjuntos de datos aparecerán en el mismo trazado.
Intente disminuir la pérdida con el tiempo y aumentar la precisión. Si ve una divergencia entre los datos de entrenamiento y los de validación, puede indicar que existe un sobreajuste. Pruebe un entrenamiento con menos épocas o un multiplicador de velocidad de aprendizaje más pequeño.
Limpieza de implementaciones, modelos personalizados y archivos de entrenamiento
Cuando haya terminado con su modelo personalizado, puede eliminar la implementación y el modelo. También puede eliminar los archivos de entrenamiento y validación que cargó en el servicio, si es necesario.
Eliminar la implementación de modelo
Importante
Después de implementar un modelo personalizado, si en cualquier momento la implementación permanece inactiva durante más de quince (15) días, la implementación se eliminará automáticamente. La implementación de un modelo personalizado es inactivasi el modelo se ha implementado hace más de quince (15) días y no se han realizado finalizaciones ni llamadas de finalización de chat durante un período continuo de 15 días.
La eliminación de una implementación inactiva no elimina ni afecta al modelo personalizado subyacente, y el modelo personalizado se puede volver a implementar en cualquier momento. Como se describe en Precios de Azure OpenAI Service, cada modelo personalizado (ajustado a sus preferencias) que se implementa incurre en un costo de hospedaje por hora, independientemente de si se realizan finalizaciones o llamadas de finalización de chat al modelo. Para obtener más información sobre cómo planear y administrar los costos con Azure OpenAI, consulte la guía de Planeamiento para administrar los costos Azure OpenAI Service.
Puede eliminar la implementación del modelo personalizado en el panel Implementaciones en el portal Azure AI Foundry. Seleccione la implementación que quiera eliminar y, a continuación, seleccione Eliminar para eliminarla.
Eliminación del modelo personalizado
Puede eliminar un modelo personalizado en el panel Modelos en el portal de Azure AI Foundry. Seleccione el modelo personalizado que quiera eliminar en la pestaña Modelos personalizados y, a continuación, seleccione Eliminar para eliminarlo.
Nota:
No se puede eliminar un modelo personalizado si tiene una implementación existente. Primero debe eliminar la implementación del modelo para poder eliminar el modelo personalizado.
Eliminación de los archivos de entrenamiento
Opcionalmente, puede eliminar los archivos de entrenamiento y validación que ha cargado para el entrenamiento y los archivos de resultados generados durante el entrenamiento, en el panel Administración>Datos e índices del Portal de la Fundición de IA de Azure. Seleccione el archivo que quiera eliminar y, a continuación, seleccione Eliminar para eliminarlo.
Ajuste preciso continuo
Una vez que haya creado un modelo ajustado, es posible que desee seguir refinando el modelo a lo largo del tiempo a través de un ajuste más preciso. El ajuste continuo es el proceso iterativo de seleccionar un modelo ya ajustado como modelo base y ajustarlo más adelante en nuevos conjuntos de ejemplos de entrenamiento.
Para realizar un ajuste preciso en un modelo que ha ajustado previamente, usaría el mismo proceso que se describe en creación de un modelo personalizado pero, en lugar de especificar el nombre de un modelo base genérico, especificaría el modelo ya optimizado. Un modelo personalizado ajustado tendría un aspecto similar a gpt-35-turbo-0613.ft-5fd1918ee65d4cd38a5dcf6835066ed7

También se recomienda incluir el parámetro suffix para facilitar la distinción entre diferentes iteraciones del modelo ajustado.
suffix toma una cadena y se establece para identificar el modelo ajustado. Con la API de Python de OpenAI, se admite una cadena de hasta 18 caracteres que se agregará al nombre del modelo optimizado.







Requisitos previos
- Lea la guía Cuándo usar el ajuste preciso de Azure OpenAI.
- Suscripción a Azure. cree una de forma gratuita.
- Un recurso de Azure OpenAI. Para obtener más información, consulte Creación de un recurso e implementación de un modelo con Azure OpenAI.
- Las siguientes bibliotecas de Python:
os,json,requests,openai. - La biblioteca de OpenAI Python debe tener al menos la versión 0.28.1.
- El ajuste preciso del acceso requiere Colaborador de OpenAI de Cognitive Services.
- Si aún no tiene acceso para ver la cuota e implementar modelos en el portal de Azure AI Foundry, necesitará permisos adicionales.
Modelos
Los modelos siguientes admiten el ajuste preciso:
-
gpt-35-turbo(0613) -
gpt-35-turbo(1106) -
gpt-35-turbo(0125) -
gpt-4(0613)* -
gpt-4o(2024-08-06) -
gpt-4o-mini(18-07-2024)
* El ajuste preciso de este modelo está actualmente en versión preliminar pública.
O bien, puede ajustar un modelo previamente ajustado, con el formato base-model.ft-{jobid}.
Consulte la página de modelos para comprobar qué regiones admiten actualmente el ajuste preciso.
Revisión del flujo de trabajo del SDK de Python
Dedique un momento a revisar el flujo de trabajo de ajuste preciso para usar el SDK de Python con Azure OpenAI:
- Prepare los datos de entrenamiento y validación.
- Seleccione un modelo base.
- Cargue los datos de entrenamiento.
- Entrene el nuevo modelo personalizado.
- Compruebe el estado del modelo personalizado.
- Implemente el modelo personalizado para usarlo.
- Use el modelo personalizado.
- Opcionalmente, analice el modelo personalizado para mejorar el rendimiento y ajustarlo.
Preparación de los datos de entrenamiento y validación
El conjunto de datos de validación y los datos de entrenamiento consisten en ejemplos de entrada y salida para el rendimiento del modelo.
Los datos de entrenamiento y validación que usa deben tener formato como documento de líneas JSON (JSONL). Para gpt-35-turbo-0613, el conjunto de datos de ajuste preciso debe tener el formato conversacional que usa la API de finalizaciones de chat.
Si desea un tutorial detallado del ajuste preciso de un modelo gpt-35-turbo-0613, consulte el tutorial de ajuste preciso de Azure OpenAI
Formato de archivo de ejemplo
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who discovered Antarctica?"}, {"role": "assistant", "content": "Some chaps named Fabian Gottlieb von Bellingshausen and Mikhail Lazarev, as if they don't teach that in every school!"}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What is the biggest ocean?"}, {"role": "assistant", "content": "The Pacific Ocean. It's not like it's a small pond or anything."}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What is the largest planet?"}, {"role": "assistant", "content": "It's called Jupiter, you might have heard of it...or not."}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who painted the Mona Lisa?"}, {"role": "assistant", "content": "Oh, some obscure artist named Leonardo da Vinci. Not that he is famous or anything."}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the boiling point of water?"}, {"role": "assistant", "content": "Exciting fact of the day: it's 100 degrees Celsius. Life-changing, isn't it?"}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who wrote 'The Odyssey'?"}, {"role": "assistant", "content": "Oh, just some poet named Homer. Nothing special, really."}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What is the largest mammal?"}, {"role": "assistant", "content": "Blue Whale. Quite a big fish isn't it? Oh wait, it's not a fish!"}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the highest mountain peak?"}, {"role": "assistant", "content": "Everest. Brace yourself, it's not a walk in the park."}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who invented the telephone?"}, {"role": "assistant", "content": "A guy named Alexander Graham Bell. Bet you didn't guess that one!"}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What is the distance from Earth to the Sun?"}, {"role": "assistant", "content": "About 93 million miles. Just a quick drive, really."}]}
Formato de archivo de chat de varios turnos
También se admiten varios turnos de una conversación en una sola línea del archivo de entrenamiento jsonl. Para omitir el ajuste específico de los mensajes del asistente, agregue el par de valores de clave opcional weight. Actualmente, weight se puede establecer en 0 o 1.
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the capital of France?"}, {"role": "assistant", "content": "Paris", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Paris, as if everyone doesn't know that already.", "weight": 1}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who wrote 'Romeo and Juliet'?"}, {"role": "assistant", "content": "William Shakespeare", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Oh, just some guy named William Shakespeare. Ever heard of him?", "weight": 1}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "How far is the Moon from Earth?"}, {"role": "assistant", "content": "384,400 kilometers", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Around 384,400 kilometers. Give or take a few, like that really matters.", "weight": 1}]}
Finalizaciones de chat con visión
{"messages": [{"role": "user", "content": [{"type": "text", "text": "What's in this image?"}, {"type": "image_url", "image_url": {"url": "https://raw.githubusercontent.com/MicrosoftDocs/azure-ai-docs/main/articles/ai-services/openai/media/how-to/generated-seattle.png"}}]}, {"role": "assistant", "content": "The image appears to be a watercolor painting of a city skyline, featuring tall buildings and a recognizable structure often associated with Seattle, like the Space Needle. The artwork uses soft colors and brushstrokes to create a somewhat abstract and artistic representation of the cityscape."}]}
Además del formato JSONL, los archivos de datos de entrenamiento y validación deben codificarse en UTF-8 e incluir una marca de orden de bytes (BOM). El archivo debe tener un tamaño inferior a 512 MB.
Creación de conjuntos de datos de entrenamiento y validación
Cuantos más ejemplos de entrenamiento tenga, mejor. Los trabajos de ajuste fino no continuarán sin al menos 10 ejemplos de entrenamiento, pero un número tan pequeño no es suficiente para influir notablemente en las respuestas del modelo. Es recomendable proporcionar cientos, o incluso miles, de ejemplos de entrenamiento para llevarlos a cabo correctamente.
En general, al duplicar el tamaño del conjunto de datos se puede producir un aumento lineal de la calidad del modelo. Sin embargo, tenga en cuenta que los ejemplos de baja calidad pueden afectar negativamente al rendimiento. Si entrena el modelo en una gran cantidad de datos internos, sin eliminar primero el conjunto de datos solo para los ejemplos de mayor calidad, podría acabar con un modelo que funciona mucho peor de lo esperado.
Carga de los datos de aprendizaje
El siguiente paso consiste en elegir los datos de entrenamiento que ya están preparados o cargar nuevos datos de entrenamiento que se usarán al personalizar el modelo. Cuando haya preparado los datos de entrenamiento, puede cargar los archivos en el servicio. Hay dos maneras de cargar los datos de entrenamiento:
En cuanto a los archivos de datos grandes, le recomendamos que los importe desde el almacén de blobs de Azure. Los archivos grandes pueden volverse inestables cuando se cargan a través de formularios multiparte porque las solicitudes son atómicas y no se pueden volver a intentar o reanudar. Para obtener más información acerca de Azure Blob Storage, consulte ¿Qué es Azure Blob Storage?
Nota:
Los archivos de datos de entrenamiento deben tener el formato JSONL, estar codificados en UTF-8 con una marca de orden de bytes (BOM). El archivo debe tener un tamaño inferior a 512 MB.
En el siguiente ejemplo de Python se cargan archivos de entrenamiento y validación locales mediante el SDK de Python y se recuperan los identificadores de archivo devueltos.
# Upload fine-tuning files
import os
from openai import AzureOpenAI
client = AzureOpenAI(
azure_endpoint = os.getenv("AZURE_OPENAI_ENDPOINT"),
api_key=os.getenv("AZURE_OPENAI_API_KEY"),
api_version="2024-05-01-preview" # This API version or later is required to access seed/events/checkpoint capabilities
)
training_file_name = 'training_set.jsonl'
validation_file_name = 'validation_set.jsonl'
# Upload the training and validation dataset files to Azure OpenAI with the SDK.
training_response = client.files.create(
file=open(training_file_name, "rb"), purpose="fine-tune"
)
training_file_id = training_response.id
validation_response = client.files.create(
file=open(validation_file_name, "rb"), purpose="fine-tune"
)
validation_file_id = validation_response.id
print("Training file ID:", training_file_id)
print("Validation file ID:", validation_file_id)
Creación de un modelo personalizado
Después de cargar los archivos de entrenamiento y validación, ya estará listo para iniciar el trabajo de ajuste preciso.
El siguiente código de Python muestra un ejemplo de cómo crear un nuevo trabajo de ajuste preciso con el SDK de Python:
En este ejemplo también se pasa el parámetro de inicialización. La inicialización controla la reproducibilidad del trabajo. Pasar los mismos parámetros de inicialización y trabajo debe generar los mismos resultados, pero puede diferir en raras ocasiones. Si no se especifica un valor de inicialización, se generará uno automáticamente.
response = client.fine_tuning.jobs.create(
training_file=training_file_id,
validation_file=validation_file_id,
model="gpt-35-turbo-0613", # Enter base model name. Note that in Azure OpenAI the model name contains dashes and cannot contain dot/period characters.
seed = 105 # seed parameter controls reproducibility of the fine-tuning job. If no seed is specified one will be generated automatically.
)
job_id = response.id
# You can use the job ID to monitor the status of the fine-tuning job.
# The fine-tuning job will take some time to start and complete.
print("Job ID:", response.id)
print("Status:", response.id)
print(response.model_dump_json(indent=2))
También puede pasar parámetros opcionales adicionales, como hiperparámetros, para tomar un mayor control del proceso de ajuste preciso. Para el entrenamiento inicial, se recomienda usar los valores predeterminados automáticos que están presentes sin especificar estos parámetros.
Los hiperparámetros admitidos actualmente para el ajuste preciso son:
| Nombre | Tipo | Descripción |
|---|---|---|
batch_size |
integer | El tamaño del lote a usar para el entrenamiento. El tamaño del lote es el número de ejemplos de entrenamiento usados para entrenar una sola pasada hacia adelante y hacia atrás. En general, hemos comprobado que los tamaños de lote más grandes tienden a funcionar mejor para conjuntos de datos más grandes. El valor predeterminado, así como el valor máximo de esta propiedad, son específicos de un modelo base. Un tamaño de lote mayor significa que los parámetros del modelo se actualizan con menos frecuencia, pero con una varianza menor. |
learning_rate_multiplier |
number | El multiplicador de la tasa de aprendizaje que se usará para el entrenamiento. La tasa de aprendizaje de ajuste es la tasa de aprendizaje original que se usó para el preentrenamiento multiplicada por este valor. Las tasas de aprendizaje más grandes tienden a mejorar con tamaños de lote más grandes. Se recomienda experimentar con valores en el rango de 0,02 a 0,2 para ver qué produce los mejores resultados. Una velocidad de aprendizaje más pequeña puede ser útil para evitar el sobreajuste. |
n_epochs |
integer | El número de épocas para entrenar el modelo. Una época se refiere a un ciclo completo a través del conjunto de datos de entrenamiento. |
seed |
integer | La inicialización controla la reproducibilidad del trabajo. Pasar los mismos parámetros de inicialización y trabajo debe generar los mismos resultados, pero puede diferir en raras ocasiones. Si no se especifica un valor de inicialización, se generará uno automáticamente. |
Para establecer hiperparámetros personalizados con la versión 1.x de la API de Python de OpenAI:
from openai import AzureOpenAI
client = AzureOpenAI(
azure_endpoint = os.getenv("AZURE_OPENAI_ENDPOINT"),
api_key=os.getenv("AZURE_OPENAI_API_KEY"),
api_version="2024-02-01" # This API version or later is required
)
client.fine_tuning.jobs.create(
training_file="file-abc123",
model="gpt-35-turbo-0613", # Enter base model name. Note that in Azure OpenAI the model name contains dashes and cannot contain dot/period characters.
hyperparameters={
"n_epochs":2
}
)
Comprobación del estado del trabajo de ajuste preciso
response = client.fine_tuning.jobs.retrieve(job_id)
print("Job ID:", response.id)
print("Status:", response.status)
print(response.model_dump_json(indent=2))
Enumeración de eventos de ajuste preciso
Para examinar los eventos individuales de ajuste que se generaron durante el entrenamiento:
Es posible que tenga que actualizar la biblioteca cliente de OpenAI a la versión más reciente con pip install openai --upgrade para ejecutar este comando.
response = client.fine_tuning.jobs.list_events(fine_tuning_job_id=job_id, limit=10)
print(response.model_dump_json(indent=2))
Puntos de control
Cuando finaliza cada época de entrenamiento, se genera un punto de control. Un punto de control es una versión totalmente funcional de un modelo que puede implementarse y usarse como modelo de destino para posteriores trabajos de ajuste. Los puntos de control pueden ser especialmente útiles, ya que pueden proporcionar una instantánea de su modelo antes de que se haya producido el sobreajuste. Cuando finalice un trabajo de ajuste, dispondrá de las tres versiones más recientes del modelo para implementarlas. La última época estará representada por su modelo ajustado, las dos épocas anteriores estarán disponibles como puntos de control.
Puede ejecutar el comando para listar puntos de control para recuperar la lista de puntos de control asociados a un trabajo de ajuste individual:
Es posible que tenga que actualizar la biblioteca cliente de OpenAI a la versión más reciente con pip install openai --upgrade para ejecutar este comando.
response = client.fine_tuning.jobs.list_events(fine_tuning_job_id=job_id, limit=10)
print(response.model_dump_json(indent=2))
Evaluación de seguridad GPT-4, GPT-4o, GPT-4o-mini ajuste - versión preliminar pública
GPT-4o, GPT-4o-mini y GPT-4 son nuestros modelos más avanzados que se pueden ajustar a sus necesidades. Al igual que con los modelos de Azure OpenAI generalmente, las funcionalidades avanzadas de los modelos optimizados incluyen mayores desafíos de inteligencia artificial responsables relacionados con contenido dañino, manipulación, comportamiento similar al humano, problemas de privacidad y mucho más. Obtenga más información sobre los riesgos, las funcionalidades y las limitaciones de la Introducción a las prácticas de inteligencia artificial responsable y Nota sobre transparencia. Para ayudar a mitigar los riesgos asociados a modelos avanzados ajustados, hemos implementado pasos de evaluación adicionales para ayudar a detectar y evitar contenido dañino en el entrenamiento y salidas de modelos ajustados. Estos pasos se basan en Microsoft Responsible AI Standard y el filtrado de contenido de Azure OpenAI Service.
- Las evaluaciones se realizan en áreas de trabajo dedicadas, específicas del cliente y privadas;
- Los puntos de conexión de evaluación se encuentran en la misma geografía que el recurso de Azure OpenAI;
- Los datos de entrenamiento no se almacenan en conexión con la realización de evaluaciones; solo se conserva la evaluación final del modelo (que se puede implementar o no se puede implementar);
Los filtros de evaluación de modelos ajustados GPT-4o, GPT-4o-mini y GPT-4 están configurados según umbrales predefinidos y los clientes no pueden modificarlos; no están vinculados a ninguna configuración de filtrado de contenido personalizada que pueda haber creado.
Evaluación de datos
Antes de comenzar el entrenamiento, los datos se evalúan para contenido potencialmente dañino (violencia, sexual, odio y imparcialidad, ver: definiciones de categorías aquí). Si se detecta contenido perjudicial por encima del nivel de gravedad especificado, se producirá un error en el trabajo de entrenamiento y recibirá un mensaje que le informará de las categorías de error.
Mensaje de ejemplo:
The provided training data failed RAI checks for harm types: [hate_fairness, self_harm, violence]. Please fix the data and try again.
Los datos de entrenamiento se evalúan automáticamente dentro del trabajo de importación de datos como parte de proporcionar la funcionalidad de ajuste preciso.
Si se produce un error en el trabajo de ajuste debido a la detección de contenido dañino en los datos de entrenamiento, no se le cobrará.
Evaluación del modelo
Una vez completado el entrenamiento, pero antes de que el modelo optimizado esté disponible para la implementación, el modelo resultante se evalúa para las respuestas potencialmente perjudiciales mediante las métricas de riesgo y seguridad de Azure integradas. Con el mismo enfoque para probar que usamos para los modelos de lenguaje grandes base, nuestra capacidad de evaluación simula una conversación con su modelo ajustado para evaluar el potencial de generar contenido perjudicial, de nuevo usando contenido dañino especificado categorías (violencia, violencia, odio y equidad, autolesiones).
Si se encuentra un modelo para generar una salida que contenga contenido detectado como perjudicial por encima de una tasa aceptable, se le informará de que el modelo no está disponible para la implementación, con información sobre las categorías específicas de daño detectadas:
Mensajes de ejemplo:
This model is unable to be deployed. Model evaluation identified that this fine tuned model scores above acceptable thresholds for [Violence, Self Harm]. Please review your training data set and resubmit the job.
Al igual que con la evaluación de datos, el modelo se evalúa automáticamente dentro del trabajo de ajuste preciso como parte de proporcionar la funcionalidad de ajuste preciso. El servicio registra solo la evaluación resultante (implementable o no implementable). Si se produce un error en la implementación del modelo optimizado debido a la detección de contenido dañino en las salidas del modelo, no se le cobrará por la ejecución de entrenamiento.
Implementación de un modelo ajustado
Cuando el trabajo de ajuste se realiza correctamente, el valor de la variable fine_tuned_model en el cuerpo de la respuesta se establece en el nombre del modelo personalizado. Ya tiene el modelo disponible para la detección de elementos en la API de modelos de lista. Sin embargo, no puede emitir llamadas de finalización al modelo personalizado hasta que implemente este. Debe implementar el modelo personalizado para poder usarlo con las llamadas de finalización.
Importante
Después de implementar un modelo personalizado, si en cualquier momento la implementación permanece inactiva durante más de quince (15) días, la implementación se eliminará automáticamente. La implementación de un modelo personalizado es inactivasi el modelo se ha implementado hace más de quince (15) días y no se han realizado finalizaciones ni llamadas de finalización de chat durante un período continuo de 15 días.
La eliminación de una implementación inactiva no elimina ni afecta al modelo personalizado subyacente, y el modelo personalizado se puede volver a implementar en cualquier momento. Como se describe en Precios de Azure OpenAI Service, cada modelo personalizado (ajustado a sus preferencias) que se implementa incurre en un costo de hospedaje por hora, independientemente de si se realizan finalizaciones o llamadas de finalización de chat al modelo. Para obtener más información sobre cómo planear y administrar los costos con Azure OpenAI, consulte la guía de Planeamiento para administrar los costos Azure OpenAI Service.
También puede utilizar Azure AI Foundry o CLI de Azure para implementar su modelo personalizado.
Nota:
Solo se permite una implementación para un modelo personalizado. Se produce un error si selecciona un modelo personalizado ya implementado.
A diferencia de los comandos de SDK anteriores, la implementación debe realizarse mediante la API del plano de control que requiere una autorización independiente, una ruta de acceso de API diferente y otra versión de API.
| variable | Definición |
|---|---|
| token | Hay varias maneras de generar un token de autorización. El método más sencillo para las pruebas iniciales es iniciar Cloud Shell desde Azure Portal. A continuación, ejecute az account get-access-token. Puede usar este token como token de autorización temporal para las pruebas de API. Se recomienda su almacenamiento en una nueva variable de entorno. |
| subscription | Identificador de suscripción para el recurso de Azure OpenAI asociado. |
| resource_group | Nombre del grupo de recursos para el recurso de Azure OpenAI. |
| resource_name | El nombre del recurso de Azure OpenAI. |
| model_deployment_name | Nombre personalizado para la nueva implementación de modelos con ajuste preciso. Este es el nombre al que se hará referencia en el código al efectuar llamadas de finalización de chat. |
| fine_tuned_model | Recupere este valor de los resultados del trabajo de ajuste preciso del paso anterior. Tendrá el siguiente aspecto: gpt-35-turbo-0613.ft-b044a9d3cf9c4228b5d393567f693b83. Tendrá que agregar ese valor al archivo JSON deploy_data. Como alternativa, también puede implementar un punto de control, pasando el id. del punto de control que aparecerá en el formato ftchkpt-e559c011ecc04fc68eaa339d8227d02d |
import json
import os
import requests
token= os.getenv("<TOKEN>")
subscription = "<YOUR_SUBSCRIPTION_ID>"
resource_group = "<YOUR_RESOURCE_GROUP_NAME>"
resource_name = "<YOUR_AZURE_OPENAI_RESOURCE_NAME>"
model_deployment_name ="gpt-35-turbo-ft" # custom deployment name that you will use to reference the model when making inference calls.
deploy_params = {'api-version': "2023-05-01"}
deploy_headers = {'Authorization': 'Bearer {}'.format(token), 'Content-Type': 'application/json'}
deploy_data = {
"sku": {"name": "standard", "capacity": 1},
"properties": {
"model": {
"format": "OpenAI",
"name": <"fine_tuned_model">, #retrieve this value from the previous call, it will look like gpt-35-turbo-0613.ft-b044a9d3cf9c4228b5d393567f693b83
"version": "1"
}
}
}
deploy_data = json.dumps(deploy_data)
request_url = f'https://management.azure.com/subscriptions/{subscription}/resourceGroups/{resource_group}/providers/Microsoft.CognitiveServices/accounts/{resource_name}/deployments/{model_deployment_name}'
print('Creating a new deployment...')
r = requests.put(request_url, params=deploy_params, headers=deploy_headers, data=deploy_data)
print(r)
print(r.reason)
print(r.json())
Implementación entre regiones
El ajuste preciso admite la implementación de un modelo ajustado en una región diferente a la de la ubicación en la que originalmente se ha ajustado el modelo. También puede implementar en otra suscripción o región.
Las únicas limitaciones son que la nueva región también debe admitir el ajuste preciso y, al implementar entre suscripciones, la cuenta que genera el token de autorización para la implementación debe tener acceso a las suscripciones de origen y de destino.
A continuación se muestra un ejemplo de implementación de un modelo que se ha ajustado en una suscripción o de una región a otra.
import json
import os
import requests
token= os.getenv("<TOKEN>")
subscription = "<DESTINATION_SUBSCRIPTION_ID>"
resource_group = "<DESTINATION_RESOURCE_GROUP_NAME>"
resource_name = "<DESTINATION_AZURE_OPENAI_RESOURCE_NAME>"
source_subscription = "<SOURCE_SUBSCRIPTION_ID>"
source_resource_group = "<SOURCE_RESOURCE_GROUP>"
source_resource = "<SOURCE_RESOURCE>"
source = f'/subscriptions/{source_subscription}/resourceGroups/{source_resource_group}/providers/Microsoft.CognitiveServices/accounts/{source_resource}'
model_deployment_name ="gpt-35-turbo-ft" # custom deployment name that you will use to reference the model when making inference calls.
deploy_params = {'api-version': "2023-05-01"}
deploy_headers = {'Authorization': 'Bearer {}'.format(token), 'Content-Type': 'application/json'}
deploy_data = {
"sku": {"name": "standard", "capacity": 1},
"properties": {
"model": {
"format": "OpenAI",
"name": <"FINE_TUNED_MODEL_NAME">, # This value will look like gpt-35-turbo-0613.ft-0ab3f80e4f2242929258fff45b56a9ce
"version": "1",
"source": source
}
}
}
deploy_data = json.dumps(deploy_data)
request_url = f'https://management.azure.com/subscriptions/{subscription}/resourceGroups/{resource_group}/providers/Microsoft.CognitiveServices/accounts/{resource_name}/deployments/{model_deployment_name}'
print('Creating a new deployment...')
r = requests.put(request_url, params=deploy_params, headers=deploy_headers, data=deploy_data)
print(r)
print(r.reason)
print(r.json())
Para realizar la implementación entre la misma suscripción, pero distintas regiones, solo tendría que tener grupos de recursos y suscripciones son idénticos para las variables de origen y destino, y solo los nombres de recursos de origen y destino tendrían que ser únicos.
Implementación entre inquilinos
La cuenta que se usa para generar tokens de acceso con az account get-access-token --tenant debe tener permisos de colaborador de OpenAI de Cognitive Services para los recursos de Azure OpenAI de origen y destino. Deberá generar dos tokens diferentes, uno para el inquilino de origen y otro para el inquilino de destino.
import requests
subscription = "DESTINATION-SUBSCRIPTION-ID"
resource_group = "DESTINATION-RESOURCE-GROUP"
resource_name = "DESTINATION-AZURE-OPENAI-RESOURCE-NAME"
model_deployment_name = "DESTINATION-MODEL-DEPLOYMENT-NAME"
fine_tuned_model = "gpt-4o-mini-2024-07-18.ft-f8838e7c6d4a4cbe882a002815758510" #source fine-tuned model id example id provided
source_subscription_id = "SOURCE-SUBSCRIPTION-ID"
source_resource_group = "SOURCE-RESOURCE-GROUP"
source_account = "SOURCE-AZURE-OPENAI-RESOURCE-NAME"
dest_token = "DESTINATION-ACCESS-TOKEN" # az account get-access-token --tenant DESTINATION-TENANT-ID
source_token = "SOURCE-ACCESS-TOKEN" # az account get-access-token --tenant SOURCE-TENANT-ID
headers = {
"Authorization": f"Bearer {dest_token}",
"x-ms-authorization-auxiliary": f"Bearer {source_token}",
"Content-Type": "application/json"
}
url = f"https://management.azure.com/subscriptions/{subscription}/resourceGroups/{resource_group}/providers/Microsoft.CognitiveServices/accounts/{resource_name}/deployments/{model_deployment_name}?api-version=2024-10-01"
payload = {
"sku": {
"name": "standard",
"capacity": 1
},
"properties": {
"model": {
"format": "OpenAI",
"name": fine_tuned_model,
"version": "1",
"sourceAccount": f"/subscriptions/{source_subscription_id}/resourceGroups/{source_resource_group}/providers/Microsoft.CognitiveServices/accounts/{source_account}"
}
}
}
response = requests.put(url, headers=headers, json=payload)
# Check response
print(f"Status Code: {response.status_code}")
print(f"Response: {response.json()}")
Implementación de un modelo con la CLI de Azure
En el siguiente ejemplo se muestra cómo usar la CLI de Azure para implementar el modelo personalizado. Con la CLI de Azure, debe especificar un nombre para la implementación del modelo personalizado. Para obtener más información sobre cómo usar la CLI de Azure para implementar modelos personalizados, consulte az cognitiveservices account deployment.
Para ejecutar este comando de la CLI de Azure en una ventana de la consola, debe reemplazar los siguientes <marcadores de posición> por los valores correspondientes para el modelo personalizado:
| Marcador de posición | Valor |
|---|---|
| <YOUR_AZURE_SUBSCRIPTION> | El nombre o id. de la suscripción de Azure. |
| <YOUR_RESOURCE_GROUP> | El nombre del grupo de recursos de Azure. |
| <YOUR_RESOURCE_NAME> | El nombre del recurso de Azure OpenAI. |
| <YOUR_DEPLOYMENT_NAME> | El nombre que quiere usar para la implementación del modelo. |
| <YOUR_FINE_TUNED_MODEL_ID> | El nombre del modelo personalizado. |
az cognitiveservices account deployment create
--resource-group <YOUR_RESOURCE_GROUP>
--name <YOUR_RESOURCE_NAME>
--deployment-name <YOUR_DEPLOYMENT_NAME>
--model-name <YOUR_FINE_TUNED_MODEL_ID>
--model-version "1"
--model-format OpenAI
--sku-capacity "1"
--sku-name "Standard"
Uso de un modelo personalizado implementado
Cuando su modelo personalizado se implemente, puede usarlo como cualquier otro modelo implementado. Puede usar el área de juegos de chat en Fundición de IA de Azure para experimentar con la nueva implementación. Puede seguir usando los mismos parámetros con el modelo personalizado, como temperature y max_tokens, como puede hacer con otros modelos implementados.
import os
from openai import AzureOpenAI
client = AzureOpenAI(
azure_endpoint = os.getenv("AZURE_OPENAI_ENDPOINT"),
api_key=os.getenv("AZURE_OPENAI_API_KEY"),
api_version="2024-02-01"
)
response = client.chat.completions.create(
model="gpt-35-turbo-ft", # model = "Custom deployment name you chose for your fine-tuning model"
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Does Azure OpenAI support customer managed keys?"},
{"role": "assistant", "content": "Yes, customer managed keys are supported by Azure OpenAI."},
{"role": "user", "content": "Do other Azure AI services support this too?"}
]
)
print(response.choices[0].message.content)
Análisis del modelo personalizado
Azure OpenAI asocia un archivo de resultado denominado results.csv a cada trabajo de ajuste preciso una vez completado. Puede usar el archivo de resultados para analizar el rendimiento de entrenamiento y validación del modelo personalizado. El id. del archivo de resultados se muestra para cada modelo personalizado; igualmente, puede usar el SDK de Python para recuperar el id. de archivo y descargar el archivo de resultados para su análisis.
En el siguiente ejemplo de Python se recupera el id. del primer archivo de resultados adjunto al trabajo de ajuste preciso del modelo personalizado y, a continuación, se usa el SDK de Python para descargar el archivo en el directorio de trabajo para su análisis.
# Retrieve the file ID of the first result file from the fine-tuning job
# for the customized model.
response = client.fine_tuning.jobs.retrieve(job_id)
if response.status == 'succeeded':
result_file_id = response.result_files[0]
retrieve = client.files.retrieve(result_file_id)
# Download the result file.
print(f'Downloading result file: {result_file_id}')
with open(retrieve.filename, "wb") as file:
result = client.files.content(result_file_id).read()
file.write(result)
El archivo de resultados es un archivo CSV que contiene una fila de encabezado y una fila para cada paso de entrenamiento que realizó el trabajo de ajuste preciso. El archivo de resultados contiene las columnas siguientes:
| Nombre de la columna | Descripción |
|---|---|
step |
El número del paso de entrenamiento. Un paso de entrenamiento representa un solo paso, hacia delante y hacia atrás, en un lote de datos de entrenamiento. |
train_loss |
La pérdida del lote de entrenamiento. |
train_mean_token_accuracy |
El porcentaje de token del lote de entrenamiento que el modelo predijo correctamente. Por ejemplo, si el tamaño del lote se establece en 3 y los datos contienen finalizaciones de tipo [[1, 2], [0, 5], [4, 2]], este valor se establece en 0,83 (5 de 6) si el modelo predijo [[1, 1], [0, 5], [4, 2]]. |
valid_loss |
La pérdida del lote de validación. |
validation_mean_token_accuracy |
El porcentaje de tokens en el lote de validación que el modelo predijo correctamente. Por ejemplo, si el tamaño del lote se establece en 3 y los datos contienen finalizaciones de tipo [[1, 2], [0, 5], [4, 2]], este valor se establece en 0,83 (5 de 6) si el modelo predijo [[1, 1], [0, 5], [4, 2]]. |
full_valid_loss |
La pérdida de validación calculada al final de cada época. Cuando el entrenamiento va bien, la pérdida debe disminuir. |
full_valid_mean_token_accuracy |
La precisión media válida de los tokens calculada al final de cada época. Cuando el entrenamiento va bien, la precisión del token debe aumentar. |
También puede ver los datos en el archivo results.csv como trazados en el portal de Azure AI Foundry. Seleccione el vínculo del modelo entrenado y verá tres gráficos: pérdida, precisión media del token y precisión del token. Si proporcionó datos de validación, ambos conjuntos de datos aparecerán en el mismo trazado.
Intente disminuir la pérdida con el tiempo y aumentar la precisión. Si ve una divergencia entre los datos de entrenamiento y validación que pueden indicar que está sobreajustando. Pruebe un entrenamiento con menos épocas o un multiplicador de velocidad de aprendizaje más pequeño.
Limpieza de implementaciones, modelos personalizados y archivos de entrenamiento
Cuando haya terminado con su modelo personalizado, puede eliminar la implementación y el modelo. También puede eliminar los archivos de entrenamiento y validación que cargó en el servicio, si es necesario.
Eliminar la implementación de modelo
Importante
Después de implementar un modelo personalizado, si en cualquier momento la implementación permanece inactiva durante más de quince (15) días, la implementación se eliminará automáticamente. La implementación de un modelo personalizado es inactivasi el modelo se ha implementado hace más de quince (15) días y no se han realizado finalizaciones ni llamadas de finalización de chat durante un período continuo de 15 días.
La eliminación de una implementación inactiva no elimina ni afecta al modelo personalizado subyacente, y el modelo personalizado se puede volver a implementar en cualquier momento. Como se describe en Precios de Azure OpenAI Service, cada modelo personalizado (ajustado a sus preferencias) que se implementa incurre en un costo de hospedaje por hora, independientemente de si se realizan finalizaciones o llamadas de finalización de chat al modelo. Para obtener más información sobre cómo planear y administrar los costos con Azure OpenAI, consulte la guía de Planeamiento para administrar los costos Azure OpenAI Service.
Puede usar varios métodos para eliminar la implementación del modelo personalizado:
Eliminación de un modelo personalizado
Del mismo modo, puede usar varios métodos para eliminar el modelo personalizado:
Nota:
No se puede eliminar un modelo personalizado si tiene una implementación existente. Primero debe eliminar la implementación del modelo para poder eliminar el modelo personalizado.
Eliminación de los archivos de entrenamiento
Opcionalmente, puede eliminar los archivos de entrenamiento y validación que cargó para el entrenamiento y los archivos de resultados que se crearon durante el entrenamiento, desde su suscripción a Azure OpenAI. Puede usar los métodos siguientes para eliminar los archivos de entrenamiento, validación y resultado:
- Azure AI Foundry
- Las API REST
- SDK de Python
En el siguiente ejemplo de Python se usa el SDK de Python para eliminar los archivos de entrenamiento, validación y resultado del modelo personalizado:
print('Checking for existing uploaded files.')
results = []
# Get the complete list of uploaded files in our subscription.
files = openai.File.list().data
print(f'Found {len(files)} total uploaded files in the subscription.')
# Enumerate all uploaded files, extracting the file IDs for the
# files with file names that match your training dataset file and
# validation dataset file names.
for item in files:
if item["filename"] in [training_file_name, validation_file_name, result_file_name]:
results.append(item["id"])
print(f'Found {len(results)} already uploaded files that match our files')
# Enumerate the file IDs for our files and delete each file.
print(f'Deleting already uploaded files.')
for id in results:
openai.File.delete(sid = id)
Ajuste preciso continuo
Una vez que haya creado un modelo ajustado, es posible que quiera seguir refinando el modelo a lo largo del tiempo a través de un ajuste más preciso. El ajuste continuo es el proceso iterativo de seleccionar un modelo ya ajustado como modelo base y ajustarlo más adelante en nuevos conjuntos de ejemplos de entrenamiento.
Para realizar un ajuste preciso en un modelo que ha ajustado previamente, usaría el mismo proceso que se describe en creación de un modelo personalizado pero, en lugar de especificar el nombre de un modelo base genérico, especificaría el identificador del modelo ya optimizado. El identificador del modelo ajustado es similar a gpt-35-turbo-0613.ft-5fd1918ee65d4cd38a5dcf6835066ed7
from openai import AzureOpenAI
client = AzureOpenAI(
azure_endpoint = os.getenv("AZURE_OPENAI_ENDPOINT"),
api_key=os.getenv("AZURE_OPENAI_API_KEY"),
api_version="2024-02-01"
)
response = client.fine_tuning.jobs.create(
training_file=training_file_id,
validation_file=validation_file_id,
model="gpt-35-turbo-0613.ft-5fd1918ee65d4cd38a5dcf6835066ed7" # Enter base model name. Note that in Azure OpenAI the model name contains dashes and cannot contain dot/period characters.
)
job_id = response.id
# You can use the job ID to monitor the status of the fine-tuning job.
# The fine-tuning job will take some time to start and complete.
print("Job ID:", response.id)
print("Status:", response.id)
print(response.model_dump_json(indent=2))
También se recomienda incluir el parámetro suffix para facilitar la distinción entre diferentes iteraciones del modelo ajustado.
suffix toma una cadena y se establece para identificar el modelo ajustado. Con la API de Python de OpenAI, se admite una cadena de hasta 18 caracteres que se agregará al nombre del modelo optimizado.
Si no está seguro del id. del modelo optimizado existente, esta información se puede encontrar en la página Modelosde Azure AI Foundry, o puede generar una lista de modelos para un recurso de Azure OpenAI determinado mediante la API de REST.
Requisitos previos
- Lea la guía Cuándo usar el ajuste preciso de Azure OpenAI.
- Suscripción a Azure. cree una de forma gratuita.
- Un recurso de Azure OpenAI. Para obtener más información, consulte Creación de un recurso e implementación de un modelo con Azure OpenAI.
- El ajuste preciso del acceso requiere Colaborador de OpenAI de Cognitive Services.
- Si aún no tiene acceso para ver la cuota e implementar modelos en el portal de Azure AI Foundry, necesitará permisos adicionales.
Modelos
Los modelos siguientes admiten el ajuste preciso:
-
gpt-35-turbo(0613) -
gpt-35-turbo(1106) -
gpt-35-turbo(0125) -
gpt-4(0613)* -
gpt-4o(2024-08-06) -
gpt-4o-mini(18-07-2024)
* El ajuste preciso de este modelo está actualmente en versión preliminar pública.
O bien, puede realizar el ajuste preciso de un modelo previamente ajustado, con el formato base-model.ft-{jobid}.
Consulte la página de modelos para comprobar qué regiones admiten actualmente el ajuste preciso.
Revisión del flujo de trabajo de la API REST
Dedique un momento a revisar el flujo de trabajo de ajuste preciso para usar las API REST y Python con Azure OpenAI:
- Prepare los datos de entrenamiento y validación.
- Seleccione un modelo base.
- Cargue los datos de entrenamiento.
- Entrene el nuevo modelo personalizado.
- Compruebe el estado del modelo personalizado.
- Implemente el modelo personalizado para usarlo.
- Use el modelo personalizado.
- Opcionalmente, analice el modelo personalizado para mejorar el rendimiento y ajustarlo.
Preparación de los datos de entrenamiento y validación
El conjunto de datos de validación y los datos de entrenamiento consisten en ejemplos de entrada y salida para el rendimiento del modelo.
Los datos de entrenamiento y validación que usa deben tener formato como documento de líneas JSON (JSONL). Para gpt-35-turbo-0613 y otros modelos relacionados, el conjunto de datos de ajuste preciso debe tener el formato conversacional que usa la API de finalizaciones de chat.
Si desea un tutorial detallado del ajuste preciso de un modelo gpt-35-turbo-0613, consulte el tutorial de ajuste preciso de Azure OpenAI.
Formato de archivo de ejemplo
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who discovered Antarctica?"}, {"role": "assistant", "content": "Some chaps named Fabian Gottlieb von Bellingshausen and Mikhail Lazarev, as if they don't teach that in every school!"}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What is the biggest ocean?"}, {"role": "assistant", "content": "The Pacific Ocean. It's not like it's a small pond or anything."}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What is the largest planet?"}, {"role": "assistant", "content": "It's called Jupiter, you might have heard of it...or not."}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who painted the Mona Lisa?"}, {"role": "assistant", "content": "Oh, some obscure artist named Leonardo da Vinci. Not that he is famous or anything."}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the boiling point of water?"}, {"role": "assistant", "content": "Exciting fact of the day: it's 100 degrees Celsius. Life-changing, isn't it?"}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who wrote 'The Odyssey'?"}, {"role": "assistant", "content": "Oh, just some poet named Homer. Nothing special, really."}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What is the largest mammal?"}, {"role": "assistant", "content": "Blue Whale. Quite a big fish isn't it? Oh wait, it's not a fish!"}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the highest mountain peak?"}, {"role": "assistant", "content": "Everest. Brace yourself, it's not a walk in the park."}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who invented the telephone?"}, {"role": "assistant", "content": "A guy named Alexander Graham Bell. Bet you didn't guess that one!"}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What is the distance from Earth to the Sun?"}, {"role": "assistant", "content": "About 93 million miles. Just a quick drive, really."}]}
Formato de archivo de chat de varios turnos
También se admiten varios turnos de una conversación en una sola línea del archivo de entrenamiento jsonl. Para omitir el ajuste específico de los mensajes del asistente, agregue el par de valores de clave opcional weight. Actualmente, weight se puede establecer en 0 o 1.
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the capital of France?"}, {"role": "assistant", "content": "Paris", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Paris, as if everyone doesn't know that already.", "weight": 1}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who wrote 'Romeo and Juliet'?"}, {"role": "assistant", "content": "William Shakespeare", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Oh, just some guy named William Shakespeare. Ever heard of him?", "weight": 1}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "How far is the Moon from Earth?"}, {"role": "assistant", "content": "384,400 kilometers", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Around 384,400 kilometers. Give or take a few, like that really matters.", "weight": 1}]}
Finalizaciones de chat con visión
{"messages": [{"role": "user", "content": [{"type": "text", "text": "What's in this image?"}, {"type": "image_url", "image_url": {"url": "https://raw.githubusercontent.com/MicrosoftDocs/azure-ai-docs/main/articles/ai-services/openai/media/how-to/generated-seattle.png"}}]}, {"role": "assistant", "content": "The image appears to be a watercolor painting of a city skyline, featuring tall buildings and a recognizable structure often associated with Seattle, like the Space Needle. The artwork uses soft colors and brushstrokes to create a somewhat abstract and artistic representation of the cityscape."}]}
Además del formato JSONL, los archivos de datos de entrenamiento y validación deben codificarse en UTF-8 e incluir una marca de orden de bytes (BOM). El archivo debe tener un tamaño inferior a 512 MB.
Creación de conjuntos de datos de entrenamiento y validación
Cuantos más ejemplos de entrenamiento tenga, mejor. Los trabajos de ajuste fino no continuarán sin al menos 10 ejemplos de entrenamiento, pero un número tan pequeño no es suficiente para influir notablemente en las respuestas del modelo. Es recomendable proporcionar cientos, o incluso miles, de ejemplos de entrenamiento para llevarlos a cabo correctamente.
En general, al duplicar el tamaño del conjunto de datos se puede producir un aumento lineal de la calidad del modelo. Sin embargo, tenga en cuenta que los ejemplos de baja calidad pueden afectar negativamente al rendimiento. Si entrena el modelo en una gran cantidad de datos internos, sin eliminar primero el conjunto de datos solo para los ejemplos de mayor calidad, podría acabar con un modelo que funciona mucho peor de lo esperado.
Selección del modelo base
El primer paso para crear un modelo personalizado es elegir un modelo base. El panel Modelo base le permite elegir un modelo base que se utilizará para el modelo personalizado. La elección influye tanto en el rendimiento como en el costo del modelo.
Seleccione un modelo base de la lista desplegable Tipo de modelo base y, a continuación, seleccione Siguiente para continuar.
O bien, puede realizar el ajuste preciso de un modelo previamente ajustado, con el formato base-model.ft-{jobid}.
Para obtener más información sobre los modelos base que se pueden ajustar, consulte Modelos.
Carga de los datos de aprendizaje
El siguiente paso consiste en elegir los datos de entrenamiento que ya están preparados o cargar nuevos datos de entrenamiento que se usarán al realizar el ajuste preciso del modelo. Cuando haya preparado los datos de entrenamiento, puede cargar los archivos en el servicio. Hay dos maneras de cargar los datos de entrenamiento:
En cuanto a los archivos de datos grandes, le recomendamos que los importe desde el almacén de blobs de Azure. Los archivos grandes pueden volverse inestables cuando se cargan a través de formularios multiparte porque las solicitudes son atómicas y no se pueden volver a intentar o reanudar. Para obtener más información acerca de Azure Blob Storage, consulte ¿Qué es Azure Blob Storage?
Nota:
Los archivos de datos de entrenamiento deben tener el formato JSONL, estar codificados en UTF-8 con una marca de orden de bytes (BOM). El archivo debe tener un tamaño inferior a 512 MB.
Cargar datos de entrenamiento
curl -X POST $AZURE_OPENAI_ENDPOINT/openai/files?api-version=2023-12-01-preview \
-H "Content-Type: multipart/form-data" \
-H "api-key: $AZURE_OPENAI_API_KEY" \
-F "purpose=fine-tune" \
-F "file=@C:\\fine-tuning\\training_set.jsonl;type=application/json"
Cargar datos de validación
curl -X POST $AZURE_OPENAI_ENDPOINT/openai/files?api-version=2023-12-01-preview \
-H "Content-Type: multipart/form-data" \
-H "api-key: $AZURE_OPENAI_API_KEY" \
-F "purpose=fine-tune" \
-F "file=@C:\\fine-tuning\\validation_set.jsonl;type=application/json"
Creación de un modelo personalizado
Después de cargar los archivos de entrenamiento y validación, ya estará listo para iniciar el trabajo de ajuste preciso. El siguiente código muestra un ejemplo de cómo crear un nuevo trabajo de ajuste preciso con la API de REST.
En este ejemplo también se pasa el parámetro de inicialización. La inicialización controla la reproducibilidad del trabajo. Pasar los mismos parámetros de inicialización y trabajo debe generar los mismos resultados, pero puede diferir en raras ocasiones. Si no se especifica un valor de inicialización, se generará uno automáticamente.
curl -X POST $AZURE_OPENAI_ENDPOINT/openai/fine_tuning/jobs?api-version=2024-05-01-preview \
-H "Content-Type: application/json" \
-H "api-key: $AZURE_OPENAI_API_KEY" \
-d '{
"model": "gpt-35-turbo-0613",
"training_file": "<TRAINING_FILE_ID>",
"validation_file": "<VALIDATION_FILE_ID>",
"seed": 105
}'
También puede pasar parámetros opcionales adicionales, como hiperparámetros, para tomar un mayor control del proceso de ajuste preciso. Para el entrenamiento inicial, se recomienda usar los valores predeterminados automáticos que están presentes sin especificar estos parámetros.
Los hiperparámetros admitidos actualmente para el ajuste preciso son:
| Nombre | Tipo | Descripción |
|---|---|---|
batch_size |
integer | El tamaño del lote a usar para el entrenamiento. El tamaño del lote es el número de ejemplos de entrenamiento usados para entrenar una sola pasada hacia adelante y hacia atrás. En general, hemos comprobado que los tamaños de lote más grandes tienden a funcionar mejor para conjuntos de datos más grandes. El valor predeterminado, así como el valor máximo de esta propiedad, son específicos de un modelo base. Un tamaño de lote mayor significa que los parámetros del modelo se actualizan con menos frecuencia, pero con una varianza menor. |
learning_rate_multiplier |
number | El multiplicador de la tasa de aprendizaje que se usará para el entrenamiento. La tasa de aprendizaje de ajuste es la tasa de aprendizaje original que se usó para el preentrenamiento multiplicada por este valor. Las tasas de aprendizaje más grandes tienden a mejorar con tamaños de lote más grandes. Se recomienda experimentar con valores en el rango de 0,02 a 0,2 para ver qué produce los mejores resultados. Una velocidad de aprendizaje más pequeña puede ser útil para evitar el sobreajuste. |
n_epochs |
integer | El número de épocas para entrenar el modelo. Una época se refiere a un ciclo completo a través del conjunto de datos de entrenamiento. |
seed |
integer | La inicialización controla la reproducibilidad del trabajo. Pasar los mismos parámetros de inicialización y trabajo debe generar los mismos resultados, pero puede diferir en raras ocasiones. Si no se especifica un valor de inicialización, se generará uno automáticamente. |
Compruebe el estado del modelo personalizado
Después de haber iniciado un trabajo de ajuste preciso, puede tardar algo de tiempo en completarse. Es posible que el trabajo esté en cola detrás de otros trabajos del sistema. Entrenar el modelo puede tardar minutos u horas, dependiendo del modelo y del tamaño del conjunto de datos. En el siguiente ejemplo se usa la API REST para comprobar el estado del trabajo de ajuste preciso. En el ejemplo se recupera información sobre el trabajo mediante el id. de trabajo devuelto del ejemplo anterior:
curl -X GET $AZURE_OPENAI_ENDPOINT/openai/fine_tuning/jobs/<YOUR-JOB-ID>?api-version=2024-05-01-preview \
-H "api-key: $AZURE_OPENAI_API_KEY"
Enumeración de eventos de ajuste preciso
Para examinar los eventos individuales de ajuste que se generaron durante el entrenamiento:
curl -X POST $AZURE_OPENAI_ENDPOINT/openai/fine_tuning/jobs/{fine_tuning_job_id}/events?api-version=2024-05-01-preview \
-H "Content-Type: application/json" \
-H "api-key: $AZURE_OPENAI_API_KEY"
Puntos de control
Cuando finaliza cada época de entrenamiento, se genera un punto de control. Un punto de control es una versión totalmente funcional de un modelo que puede implementarse y usarse como modelo de destino para posteriores trabajos de ajuste. Los puntos de control pueden ser especialmente útiles, ya que pueden proporcionar una instantánea de su modelo antes de que se haya producido el sobreajuste. Cuando finalice un trabajo de ajuste, dispondrá de las tres versiones más recientes del modelo para implementarlas. La última época estará representada por su modelo ajustado, las dos épocas anteriores estarán disponibles como puntos de control.
Puede ejecutar el comando para listar puntos de control para recuperar la lista de puntos de control asociados a un trabajo de ajuste individual:
curl -X POST $AZURE_OPENAI_ENDPOINT/openai/fine_tuning/jobs/{fine_tuning_job_id}/checkpoints?api-version=2024-05-01-preview \
-H "Content-Type: application/json" \
-H "api-key: $AZURE_OPENAI_API_KEY"
Evaluación de seguridad GPT-4, GPT-4o, GPT-4o-mini ajuste - versión preliminar pública
GPT-4o, GPT-4o-mini y GPT-4 son nuestros modelos más avanzados que se pueden ajustar a sus necesidades. Al igual que con los modelos de Azure OpenAI generalmente, las funcionalidades avanzadas de los modelos optimizados incluyen mayores desafíos de inteligencia artificial responsables relacionados con contenido dañino, manipulación, comportamiento similar al humano, problemas de privacidad y mucho más. Obtenga más información sobre los riesgos, las funcionalidades y las limitaciones de la Introducción a las prácticas de inteligencia artificial responsable y Nota sobre transparencia. Para ayudar a mitigar los riesgos asociados a modelos avanzados ajustados, hemos implementado pasos de evaluación adicionales para ayudar a detectar y evitar contenido dañino en el entrenamiento y salidas de modelos ajustados. Estos pasos se basan en Microsoft Responsible AI Standard y el filtrado de contenido de Azure OpenAI Service.
- Las evaluaciones se realizan en áreas de trabajo dedicadas, específicas del cliente y privadas;
- Los puntos de conexión de evaluación se encuentran en la misma geografía que el recurso de Azure OpenAI;
- Los datos de entrenamiento no se almacenan en conexión con la realización de evaluaciones; solo se conserva la evaluación final del modelo (que se puede implementar o no se puede implementar);
Los filtros de evaluación de modelos ajustados GPT-4o, GPT-4o-mini y GPT-4 están configurados según umbrales predefinidos y los clientes no pueden modificarlos; no están vinculados a ninguna configuración de filtrado de contenido personalizada que pueda haber creado.
Evaluación de datos
Antes de comenzar el entrenamiento, los datos se evalúan para contenido potencialmente dañino (violencia, sexual, odio y imparcialidad, ver: definiciones de categorías aquí). Si se detecta contenido perjudicial por encima del nivel de gravedad especificado, se producirá un error en el trabajo de entrenamiento y recibirá un mensaje que le informará de las categorías de error.
Mensaje de ejemplo:
The provided training data failed RAI checks for harm types: [hate_fairness, self_harm, violence]. Please fix the data and try again.
Los datos de entrenamiento se evalúan automáticamente dentro del trabajo de importación de datos como parte de proporcionar la funcionalidad de ajuste preciso.
Si se produce un error en el trabajo de ajuste debido a la detección de contenido dañino en los datos de entrenamiento, no se le cobrará.
Evaluación del modelo
Una vez completado el entrenamiento, pero antes de que el modelo optimizado esté disponible para la implementación, el modelo resultante se evalúa para las respuestas potencialmente perjudiciales mediante las métricas de riesgo y seguridad de Azure integradas. Con el mismo enfoque para probar que usamos para los modelos de lenguaje grandes base, nuestra capacidad de evaluación simula una conversación con su modelo ajustado para evaluar el potencial de generar contenido perjudicial, de nuevo usando contenido dañino especificado categorías (violencia, violencia, odio y equidad, autolesiones).
Si se encuentra un modelo para generar una salida que contenga contenido detectado como perjudicial por encima de una tasa aceptable, se le informará de que el modelo no está disponible para la implementación, con información sobre las categorías específicas de daño detectadas:
Mensajes de ejemplo:
This model is unable to be deployed. Model evaluation identified that this fine tuned model scores above acceptable thresholds for [Violence, Self Harm]. Please review your training data set and resubmit the job.
Al igual que con la evaluación de datos, el modelo se evalúa automáticamente dentro del trabajo de ajuste preciso como parte de proporcionar la funcionalidad de ajuste preciso. El servicio registra solo la evaluación resultante (implementable o no implementable). Si se produce un error en la implementación del modelo optimizado debido a la detección de contenido dañino en las salidas del modelo, no se le cobrará por la ejecución de entrenamiento.
Implementación de un modelo ajustado
Importante
Después de implementar un modelo personalizado, si en cualquier momento la implementación permanece inactiva durante más de quince (15) días, la implementación se eliminará automáticamente. La implementación de un modelo personalizado es inactivasi el modelo se ha implementado hace más de quince (15) días y no se han realizado finalizaciones ni llamadas de finalización de chat durante un período continuo de 15 días.
La eliminación de una implementación inactiva no elimina ni afecta al modelo personalizado subyacente, y el modelo personalizado se puede volver a implementar en cualquier momento. Como se describe en Precios de Azure OpenAI Service, cada modelo personalizado (ajustado a sus preferencias) que se implementa incurre en un costo de hospedaje por hora, independientemente de si se realizan finalizaciones o llamadas de finalización de chat al modelo. Para obtener más información sobre cómo planear y administrar los costos con Azure OpenAI, consulte la guía de Planeamiento para administrar los costos Azure OpenAI Service.
En el siguiente ejemplo de Python se muestra cómo usar la API de REST para crear una implementación de modelos para el modelo personalizado. La API de REST genera un nombre para la implementación del modelo personalizado.
| variable | Definición |
|---|---|
| token | Hay varias maneras de generar un token de autorización. El método más sencillo para las pruebas iniciales es iniciar Cloud Shell desde Azure Portal. A continuación, ejecute az account get-access-token. Puede usar este token como token de autorización temporal para las pruebas de API. Se recomienda su almacenamiento en una nueva variable de entorno. |
| subscription | Identificador de suscripción para el recurso de Azure OpenAI asociado. |
| resource_group | Nombre del grupo de recursos para el recurso de Azure OpenAI. |
| resource_name | El nombre del recurso de Azure OpenAI. |
| model_deployment_name | Nombre personalizado para la nueva implementación de modelos con ajuste preciso. Este es el nombre al que se hará referencia en el código al efectuar llamadas de finalización de chat. |
| fine_tuned_model | Recupere este valor de los resultados del trabajo de ajuste preciso del paso anterior. Tendrá el siguiente aspecto: gpt-35-turbo-0613.ft-b044a9d3cf9c4228b5d393567f693b83. Tendrá que agregar ese valor al archivo JSON deploy_data. Como alternativa, también puede implementar un punto de control, pasando el id. del punto de control que aparecerá en el formato ftchkpt-e559c011ecc04fc68eaa339d8227d02d |
curl -X POST "https://management.azure.com/subscriptions/<SUBSCRIPTION>/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.CognitiveServices/accounts/<RESOURCE_NAME>/deployments/<MODEL_DEPLOYMENT_NAME>api-version=2023-05-01" \
-H "Authorization: Bearer <TOKEN>" \
-H "Content-Type: application/json" \
-d '{
"sku": {"name": "standard", "capacity": 1},
"properties": {
"model": {
"format": "OpenAI",
"name": "<FINE_TUNED_MODEL>",
"version": "1"
}
}
}'
Implementación entre regiones
El ajuste preciso admite la implementación de un modelo ajustado en una región diferente a la de la ubicación en la que originalmente se ha ajustado el modelo. También puede implementar en otra suscripción o región.
Las únicas limitaciones son que la nueva región también debe admitir el ajuste preciso y, al implementar entre suscripciones, la cuenta que genera el token de autorización para la implementación debe tener acceso a las suscripciones de origen y de destino.
A continuación se muestra un ejemplo de implementación de un modelo que se ha ajustado en una suscripción o de una región a otra.
curl -X PUT "https://management.azure.com/subscriptions/<SUBSCRIPTION>/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.CognitiveServices/accounts/<RESOURCE_NAME>/deployments/<MODEL_DEPLOYMENT_NAME>api-version=2023-05-01" \
-H "Authorization: Bearer <TOKEN>" \
-H "Content-Type: application/json" \
-d '{
"sku": {"name": "standard", "capacity": 1},
"properties": {
"model": {
"format": "OpenAI",
"name": "<FINE_TUNED_MODEL>",
"version": "1",
"source": "/subscriptions/{sourceSubscriptionID}/resourceGroups/{sourceResourceGroupName}/providers/Microsoft.CognitiveServices/accounts/{sourceAccount}"
}
}
}'
Para realizar la implementación entre la misma suscripción, pero distintas regiones, solo tendría que tener grupos de recursos y suscripciones son idénticos para las variables de origen y destino, y solo los nombres de recursos de origen y destino tendrían que ser únicos.
Implementación entre inquilinos
La cuenta que se usa para generar tokens de acceso con az account get-access-token --tenant debe tener permisos de colaborador de OpenAI de Cognitive Services para los recursos de Azure OpenAI de origen y destino. Deberá generar dos tokens diferentes, uno para el inquilino de origen y otro para el inquilino de destino.
curl -X PUT "https://management.azure.com/subscriptions/<SUBSCRIPTION>/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.CognitiveServices/accounts/<RESOURCE_NAME>/deployments/<MODEL_DEPLOYMENT_NAME>?api-version=2024-10-01" \
-H "Authorization: Bearer <DESTINATION TOKEN>" \
-H "x-ms-authorization-auxiliary: Bearer <SOURCE TOKEN>" \
-H "Content-Type: application/json" \
-d '{
"sku": {"name": "standard", "capacity": 1},
"properties": {
"model": {
"format": "OpenAI",
"name": "<FINE_TUNED_MODEL>",
"version": "1",
"sourceAccount": "/subscriptions/{sourceSubscriptionID}/resourceGroups/{sourceResourceGroupName}/providers/Microsoft.CognitiveServices/accounts/{sourceAccount}"
}
}
}'
Implementación de un modelo con la CLI de Azure
En el siguiente ejemplo se muestra cómo usar la CLI de Azure para implementar el modelo personalizado. Con la CLI de Azure, debe especificar un nombre para la implementación del modelo personalizado. Para obtener más información sobre cómo usar la CLI de Azure para implementar modelos personalizados, consulte az cognitiveservices account deployment.
Para ejecutar este comando de la CLI de Azure en una ventana de la consola, debe reemplazar los siguientes <marcadores de posición> por los valores correspondientes para el modelo personalizado:
| Marcador de posición | Valor |
|---|---|
| <YOUR_AZURE_SUBSCRIPTION> | El nombre o id. de la suscripción de Azure. |
| <YOUR_RESOURCE_GROUP> | El nombre del grupo de recursos de Azure. |
| <YOUR_RESOURCE_NAME> | El nombre del recurso de Azure OpenAI. |
| <YOUR_DEPLOYMENT_NAME> | El nombre que quiere usar para la implementación del modelo. |
| <YOUR_FINE_TUNED_MODEL_ID> | El nombre del modelo personalizado. |
az cognitiveservices account deployment create
--resource-group <YOUR_RESOURCE_GROUP>
--name <YOUR_RESOURCE_NAME>
--deployment-name <YOUR_DEPLOYMENT_NAME>
--model-name <YOUR_FINE_TUNED_MODEL_ID>
--model-version "1"
--model-format OpenAI
--sku-capacity "1"
--sku-name "Standard"
Uso de un modelo personalizado implementado
Cuando su modelo personalizado se implemente, puede usarlo como cualquier otro modelo implementado. Puede usar las áreas de juegos de chat en Fundición de IA de Azure para experimentar con la nueva implementación. Puede seguir usando los mismos parámetros con el modelo personalizado, como temperature y max_tokens, como puede hacer con otros modelos implementados.
curl $AZURE_OPENAI_ENDPOINT/openai/deployments/<deployment_name>/chat/completions?api-version=2023-05-15 \
-H "Content-Type: application/json" \
-H "api-key: $AZURE_OPENAI_API_KEY" \
-d '{"messages":[{"role": "system", "content": "You are a helpful assistant."},{"role": "user", "content": "Does Azure OpenAI support customer managed keys?"},{"role": "assistant", "content": "Yes, customer managed keys are supported by Azure OpenAI."},{"role": "user", "content": "Do other Azure AI services support this too?"}]}'
Análisis del modelo personalizado
Azure OpenAI asocia un archivo de resultado denominado results.csv a cada trabajo de ajuste preciso una vez completado. Puede usar el archivo de resultados para analizar el rendimiento de entrenamiento y validación del modelo personalizado. El id. del archivo de resultados se muestra para cada modelo personalizado; igualmente, puede usar la API de REST para recuperar el id. de archivo y descargar el archivo de resultados para su análisis.
En el siguiente ejemplo de Python se usa la API de REST para recuperar el id. del primer archivo de resultados adjunto al trabajo de ajuste preciso del modelo personalizado y, a continuación, se descarga el archivo en el directorio de trabajo para su análisis.
curl -X GET "$AZURE_OPENAI_ENDPOINT/openai/fine_tuning/jobs/<JOB_ID>?api-version=2023-12-01-preview" \
-H "api-key: $AZURE_OPENAI_API_KEY")
curl -X GET "$AZURE_OPENAI_ENDPOINT/openai/files/<RESULT_FILE_ID>/content?api-version=2023-12-01-preview" \
-H "api-key: $AZURE_OPENAI_API_KEY" > <RESULT_FILENAME>
El archivo de resultados es un archivo CSV que contiene una fila de encabezado y una fila para cada paso de entrenamiento que realizó el trabajo de ajuste preciso. El archivo de resultados contiene las columnas siguientes:
| Nombre de la columna | Descripción |
|---|---|
step |
El número del paso de entrenamiento. Un paso de entrenamiento representa un solo paso, hacia delante y hacia atrás, en un lote de datos de entrenamiento. |
train_loss |
La pérdida del lote de entrenamiento. |
train_mean_token_accuracy |
El porcentaje de token del lote de entrenamiento que el modelo predijo correctamente. Por ejemplo, si el tamaño del lote se establece en 3 y los datos contienen finalizaciones de tipo [[1, 2], [0, 5], [4, 2]], este valor se establece en 0,83 (5 de 6) si el modelo predijo [[1, 1], [0, 5], [4, 2]]. |
valid_loss |
La pérdida del lote de validación. |
validation_mean_token_accuracy |
El porcentaje de tokens en el lote de validación que el modelo predijo correctamente. Por ejemplo, si el tamaño del lote se establece en 3 y los datos contienen finalizaciones de tipo [[1, 2], [0, 5], [4, 2]], este valor se establece en 0,83 (5 de 6) si el modelo predijo [[1, 1], [0, 5], [4, 2]]. |
full_valid_loss |
La pérdida de validación calculada al final de cada época. Cuando el entrenamiento va bien, la pérdida debe disminuir. |
full_valid_mean_token_accuracy |
La precisión media válida de los tokens calculada al final de cada época. Cuando el entrenamiento va bien, la precisión del token debe aumentar. |
También puede ver los datos en el archivo results.csv como trazados en el portal de Azure AI Foundry. Seleccione el vínculo del modelo entrenado y verá tres gráficos: pérdida, precisión media del token y precisión del token. Si proporcionó datos de validación, ambos conjuntos de datos aparecerán en el mismo trazado.
Intente disminuir la pérdida con el tiempo y aumentar la precisión. Si ve una divergencia entre los datos de entrenamiento y validación que pueden indicar que está sobreajustando. Pruebe un entrenamiento con menos épocas o un multiplicador de velocidad de aprendizaje más pequeño.
Limpieza de implementaciones, modelos personalizados y archivos de entrenamiento
Cuando haya terminado con su modelo personalizado, puede eliminar la implementación y el modelo. También puede eliminar los archivos de entrenamiento y validación que cargó en el servicio, si es necesario.
Eliminar la implementación de modelo
Puede usar varios métodos para eliminar la implementación del modelo personalizado:
Eliminación de un modelo personalizado
Del mismo modo, puede usar varios métodos para eliminar el modelo personalizado:
Nota:
No se puede eliminar un modelo personalizado si tiene una implementación existente. Primero debe eliminar la implementación del modelo para poder eliminar el modelo personalizado.
Eliminación de los archivos de entrenamiento
Opcionalmente, puede eliminar los archivos de entrenamiento y validación que cargó para el entrenamiento y los archivos de resultados que se crearon durante el entrenamiento, desde su suscripción a Azure OpenAI. Puede usar los métodos siguientes para eliminar los archivos de entrenamiento, validación y resultado:
Ajuste preciso continuo
Una vez que haya creado un modelo ajustado, es posible que quiera seguir refinando el modelo a lo largo del tiempo a través de un ajuste más preciso. El ajuste continuo es el proceso iterativo de seleccionar un modelo ya ajustado como modelo base y ajustarlo más adelante en nuevos conjuntos de ejemplos de entrenamiento.
Para realizar un ajuste preciso en un modelo que ha ajustado previamente, usaría el mismo proceso que se describe en creación de un modelo personalizado pero, en lugar de especificar el nombre de un modelo base genérico, especificaría el identificador del modelo ya optimizado. El identificador del modelo ajustado es similar a gpt-35-turbo-0613.ft-5fd1918ee65d4cd38a5dcf6835066ed7
curl -X POST $AZURE_OPENAI_ENDPOINT/openai/fine_tuning/jobs?api-version=2023-12-01-preview \
-H "Content-Type: application/json" \
-H "api-key: $AZURE_OPENAI_API_KEY" \
-d '{
"model": "gpt-35-turbo-0613.ft-5fd1918ee65d4cd38a5dcf6835066ed7",
"training_file": "<TRAINING_FILE_ID>",
"validation_file": "<VALIDATION_FILE_ID>",
"suffix": "<additional text used to help identify fine-tuned models>"
}'
También se recomienda incluir el parámetro suffix para facilitar la distinción entre diferentes iteraciones del modelo ajustado.
suffix toma una cadena y se establece para identificar el modelo ajustado. El sufijo puede contener hasta 40 caracteres (a-z, A-Z, 0-9 y _) que se agregarán al nombre del modelo ajustado.
Si no está seguro del identificador del modelo optimizado, esta información se puede encontrar en la página Modelos de Azure AI Foundry, o puede generar una lista de modelos para un recurso de Azure OpenAI determinado mediante la API de REST.
Otros tipos de implementación
El ajuste preciso de Azure OpenAI admite implementaciones estándar globales en Este de EE. UU. 2, Centro-norte de EE. UU. y Centro de Suecia para:
gpt-4o-mini-2024-07-18gpt-4o-2024-08-06
Además, admite administrado aprovisionado regional en centro-norte de EE. UU. y Oeste de Suiza para:
gpt-4o-mini-2024-07-18gpt-4o-2024-08-06
Estándar global (versión preliminar)
Las implementaciones con ajuste preciso de estándar global ofrecen ahorros en costos, pero los pesos de los modelo personalizados podrían almacenarse, de manera temporal, fuera de la geografía del recurso de Azure OpenAI.

Actualmente, las implementaciones con ajuste preciso de estándar global no admiten salidas estructuradas ni de visión.
Administrado aprovisionado (versión preliminar)
Las implementaciones administradas aprovisionadas ajustadas ofrecen rendimiento predecible para implementaciones ajustadas. Como parte de la versión preliminar pública, las implementaciones administradas aprovisionadas se pueden crear de forma regional a través del plano de datos API de REST versión 2024-10-01 o posterior. Vea ejemplos a continuación.
Actualmente, las implementaciones ajustadas administradas aprovisionadas no admiten salidas estructuradas ni de visión.
Creación de una implementación administrada aprovisionada
Para crear una nueva implementación, realice una llamada HTTP PUT a través de las implementaciones: creación o actualización de la API de REST. El enfoque es similar a realizar una implementación entre regiones con las siguientes excepciones:
- Debe proporcionar un nombre de SKU de
ProvisionedStandard. - La capacidad debe declararse en PTUs.
- La
api-versiondebe ser2024-10-01o posterior. - El método HTTP debe ser
PUT.
Por ejemplo, para implementar un modelo gpt-4o-mini:
curl -X PUT "https://management.azure.com/subscriptions/<SUBSCRIPTION>/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.CognitiveServices/accounts/<RESOURCE_NAME>/deployments/<MODEL_DEPLOYMENT_NAME>api-version=2024-10-01" \
-H "Authorization: Bearer <TOKEN>" \
-H "Content-Type: application/json" \
-d '{
"sku": {"name": "ProvisionedStandard", "capacity": 25},
"properties": {
"model": {
"format": "OpenAI",
"name": "gpt-4omini-ft-model-name",
"version": "1",
"source": "/subscriptions/00000000-0000-0000-0000-000000000000/resourceGroups/{SourceResourceGroupName}/providers/Microsoft.CognitiveServices/accounts/{SourceAOAIAccountName}"
}
}
}'
Escalado de un modelo ajustado en Administrado aprovisionado
Para escalar una implementación administrada de aprovisionamiento ajustada para aumentar o reducir la capacidad de PTU, realice la misma llamada a la API de REST PUT que hizo al crear la implementación y proporcione un valor capacity actualizado para el sku. Tenga en cuenta que las implementaciones aprovisionadas deben escalar incrementos mínimos.
Por ejemplo, para escalar el modelo implementado en la sección anterior de 25 a 40 PTU, realice otra llamada PUT y aumente la capacidad:
curl -X PUT "https://management.azure.com/subscriptions/<SUBSCRIPTION>/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.CognitiveServices/accounts/<RESOURCE_NAME>/deployments/<MODEL_DEPLOYMENT_NAME>api-version=2024-10-01" \
-H "Authorization: Bearer <TOKEN>" \
-H "Content-Type: application/json" \
-d '{
"sku": {"name": "ProvisionedStandard", "capacity": 40},
"properties": {
"model": {
"format": "OpenAI",
"name": "gpt-4omini-ft-model-name",
"version": "1",
"source": "/subscriptions/00000000-0000-0000-0000-000000000000/resourceGroups/{SourceResourceGroupName}/providers/Microsoft.CognitiveServices/accounts/{SourceAOAIAccountName}"
}
}
}'
Eliminación de una implementación administrada aprovisionada
Para eliminar una implementación, use [Implementaciones: eliminar API de REST(/rest/api/aiservices/accountmanagement/deployments/delete?view=rest-aiservices-accountmanagement-2024-10-01&tabs=HTTP&preserve-view=true) y envíe un DELETE de HTTP al recurso de implementación. Al igual que con la creación de implementaciones, debe incluir los parámetros siguientes:
- Identificador de suscripción de Azure
- Nombre del grupo de recursos de Azure
- El nombre del recurso de Azure OpenAI
- El nombre de la implementación de PTU que se eliminará
Por ejemplo, para eliminar el modelo creado y modificado en las secciones anteriores:
curl -X DELETE "https://management.azure.com/subscriptions/<SUBSCRIPTION>/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.CognitiveServices/accounts/<RESOURCE_NAME>/deployments/<MODEL_DEPLOYMENT_NAME>api-version=2024-10-01" \
-H "Authorization: Bearer <TOKEN>"
Optimización de visión
La optimización también es posible con las imágenes de sus archivos JSONL. De la misma manera que puede enviar una o varias imágenes a las finalizaciones de chat, puede incluir esos mismos tipos de mensajes en sus datos de entrenamiento. Las imágenes pueden proporcionarse como direcciones URL de acceso público o como URI de datos que contengan imágenes codificadas en base64.
Requisitos del conjunto de datos de imagen
- El archivo de entrenamiento puede contener un máximo de 50 000 ejemplos que contengan imágenes (sin incluir los ejemplos de texto).
- Cada ejemplo puede tener como máximo 64 imágenes.
- Cada imagen puede tener como máximo 10 MB.
Format
Las imágenes deben ser:
- JPEG
- PNG
- WEBP
Las imágenes deben estar en el modo de imagen RGB o RGBA.
No se pueden incluir imágenes como salida de mensajes con el rol de asistente.
Directiva de moderación de contenido
Examinamos sus imágenes antes del entrenamiento para asegurarnos de que cumplen nuestra Nota sobre transparencia de la política de uso. Esto puede introducir latencia en la validación de archivos antes de comenzar el ajuste.
Las imágenes que contienen lo siguiente se excluirán del conjunto de datos y no se usarán para el entrenamiento:
- People (Personas)
- Caras
- CAPTCHA
Importante
Para el proceso de filtrado de caras de optimización de visión: revisamos las caras/personas para omitir esas imágenes del entrenamiento del modelo. La capacidad de filtrado usa la detección de caras SIN identificación facial, lo que significa que no creamos plantillas faciales ni medimos la geometría facial específica, y la tecnología utilizada para filtrar rostros es incapaz de identificar de forma exclusiva a los individuos. Para más información sobre los datos y la privacidad para la cara, consulte Datos y privacidad para Face: servicios de Azure AI | Microsoft Learn.
Almacenamiento en caché de mensajes
El ajuste preciso de Azure OpenAI admite el almacenamiento en caché de indicaciones con modelos seleccionados. El almacenamiento en caché de mensajes permite reducir la latencia general de las solicitudes y el costo de los mensajes más largos que tienen contenido idéntico al principio del mensaje. Para más información sobre el almacenamiento en caché de indicaciones, consulte introducción al almacenamiento en caché de indicaciones.
Optimización directa de preferencias (DPO, por sus siglas en inglés) (versión preliminar)
La optimización directa de preferencias (DPO) es una técnica de alineación para los modelos de lenguaje de gran tamaño, que se usa para ajustar los pesos del modelo en función de las preferencias humanas. Difiere del aprendizaje por refuerzo a partir de la retroalimentación humana (RLHF, por sus siglas en inglés) en que no requiere ajustar un modelo de recompensas y usa preferencias de datos binarios más simples para el entrenamiento. Tiene un peso más ligero a nivel computacional y es más rápida que la RLHF, a la vez, es igual de eficaz en la alineación.
¿Por qué es útil la DPO?
La DPO es especialmente útil en escenarios en los que no hay una respuesta correcta absoluta, y en aquellos en que los elementos subjetivos como el tono, estilo o preferencias de contenido específicas son importantes. Este enfoque también permite que el modelo aprenda de ejemplos positivos (lo que se considera correcto o ideal) y ejemplos negativos (lo que es menos deseado o incorrecto).
Se cree que la DPO es una técnica que facilitará a los clientes la generación de conjuntos de datos de entrenamiento de alta calidad. Aunque muchos clientes tienen dificultades para generar suficientes conjuntos de datos de gran tamaño para el ajuste preciso supervisado, a menudo tienen datos de preferencia ya recopilados en función de los registros de usuario, las pruebas A/B o los trabajos de anotación manual más pequeños.
Formato de conjunto de datos de optimización directa de preferencias
Los archivos de optimización directa de preferencias tienen un formato diferente al del ajuste preciso supervisado. Los clientes proporcionan una "conversación" que contiene el mensaje del sistema y el mensaje de usuario inicial y, a continuación, "finalizaciones" con datos de preferencias emparejados. Los usuarios solo pueden proporcionar dos finalizaciones.
Tres campos de nivel superior: input, preferred_output y non_preferred_output
- Cada elemento del preferred_output/non_preferred_output debe contener al menos un mensaje de asistente
- Cada elemento del preferred_output/non_preferred_output solo puede tener roles en (asistente, herramienta)
{
"input": {
"messages": {"role": "system", "content": ...},
"tools": [...],
"parallel_tool_calls": true
},
"preferred_output": [{"role": "assistant", "content": ...}],
"non_preferred_output": [{"role": "assistant", "content": ...}]
}
Los conjuntos de datos de entrenamiento deben estar en formato jsonl:
{{"input": {"messages": [{"role": "system", "content": "You are a chatbot assistant. Given a user question with multiple choice answers, provide the correct answer."}, {"role": "user", "content": "Question: Janette conducts an investigation to see which foods make her feel more fatigued. She eats one of four different foods each day at the same time for four days and then records how she feels. She asks her friend Carmen to do the same investigation to see if she gets similar results. Which would make the investigation most difficult to replicate? Answer choices: A: measuring the amount of fatigue, B: making sure the same foods are eaten, C: recording observations in the same chart, D: making sure the foods are at the same temperature"}]}, "preferred_output": [{"role": "assistant", "content": "A: Measuring The Amount Of Fatigue"}], "non_preferred_output": [{"role": "assistant", "content": "D: making sure the foods are at the same temperature"}]}
}
Compatibilidad con el modelo de optimización directa de preferencias
-
gpt-4o-2024-08-06admite la optimización de preferencias directas en sus respectivas regiones de ajuste preciso. La disponibilidad de la región más reciente se actualiza en la página de modelos
Los usuarios pueden usar el ajuste preciso de preferencias con los modelos base y con los modelos en los que ya se haya usado el ajuste preciso de manera correcta por medio del ajuste preciso supervisado, siempre que pertenezcan a un modelo o versión compatibles.
¿Cómo usar el ajuste preciso para la optimización de preferencias directas?
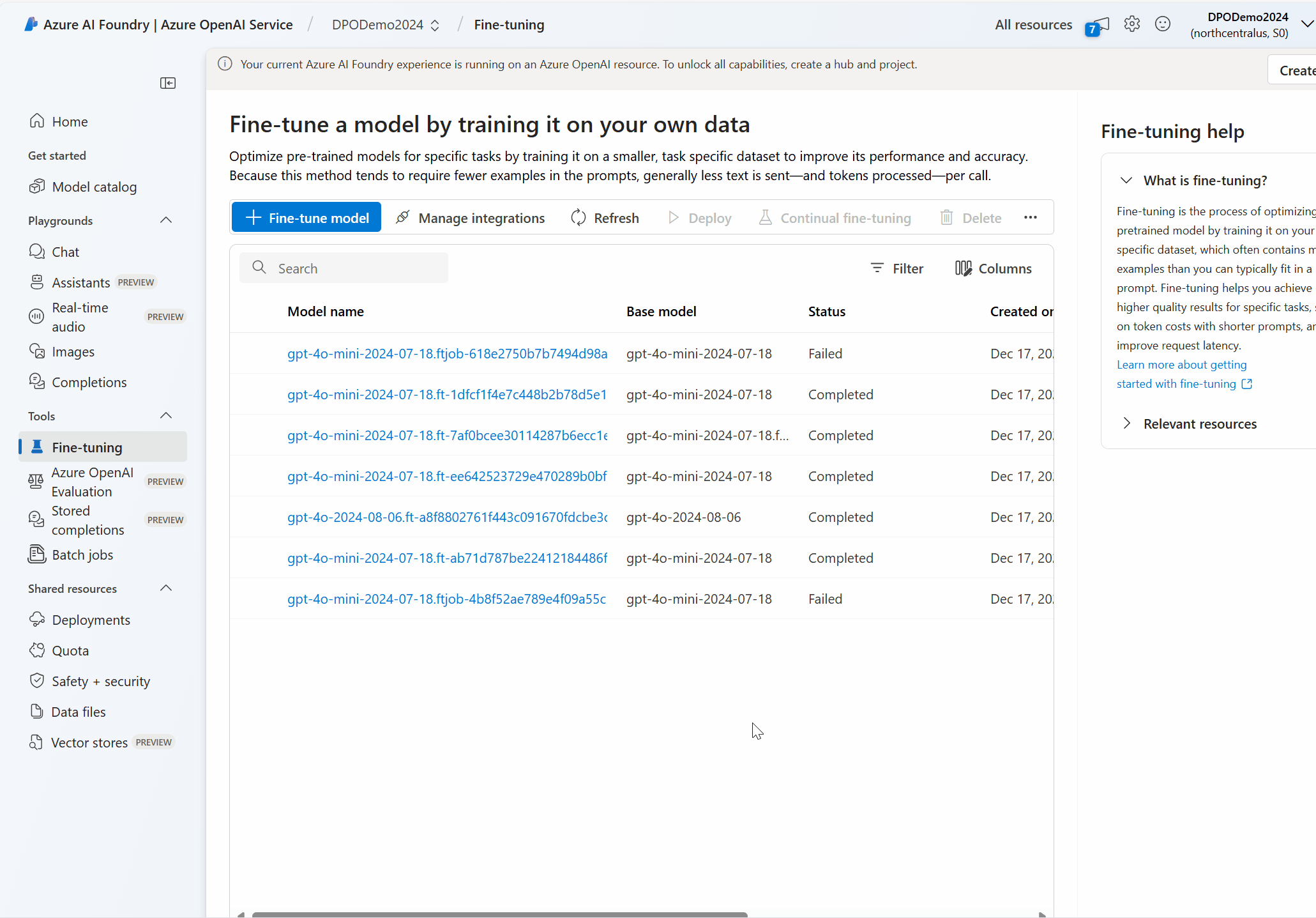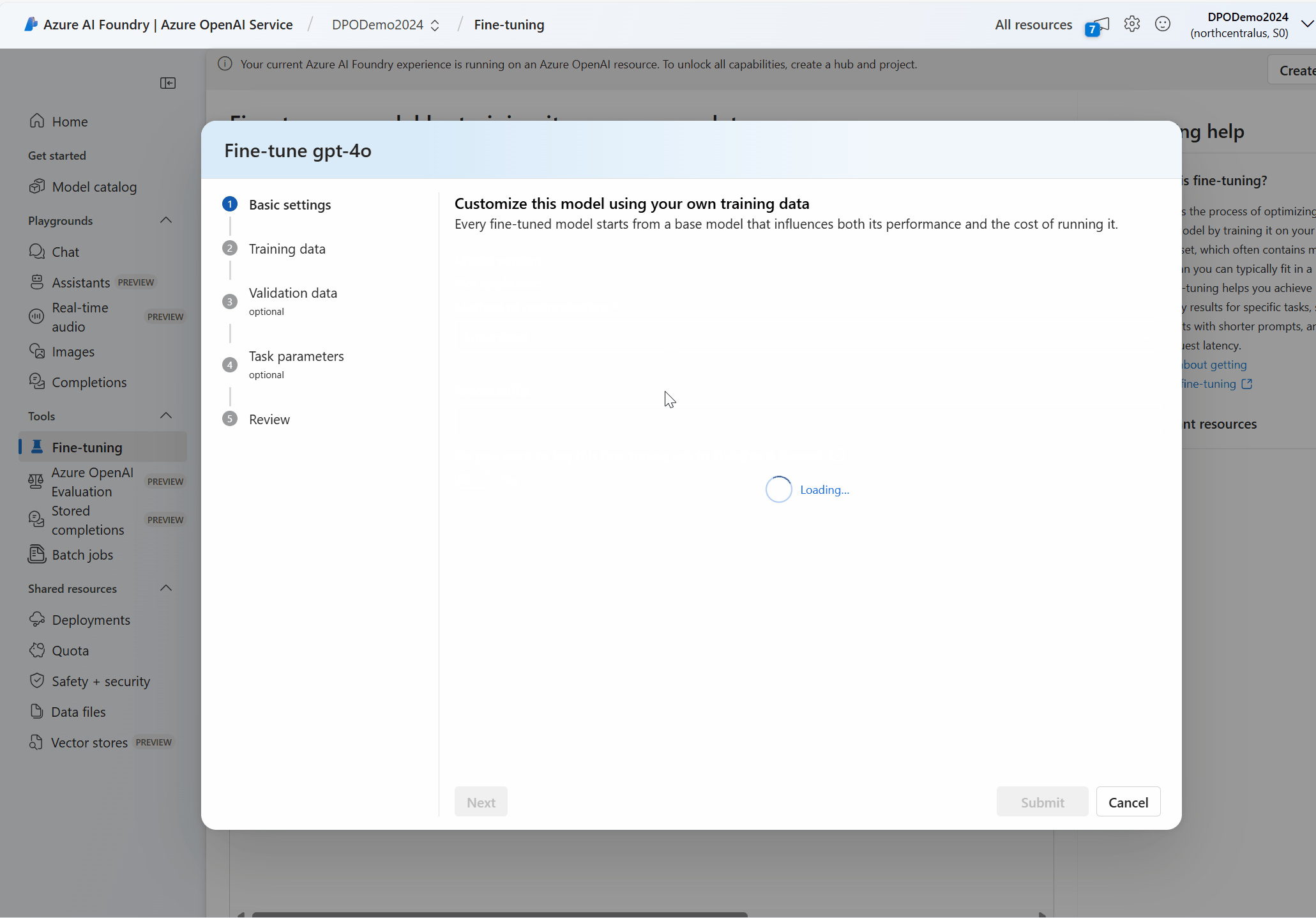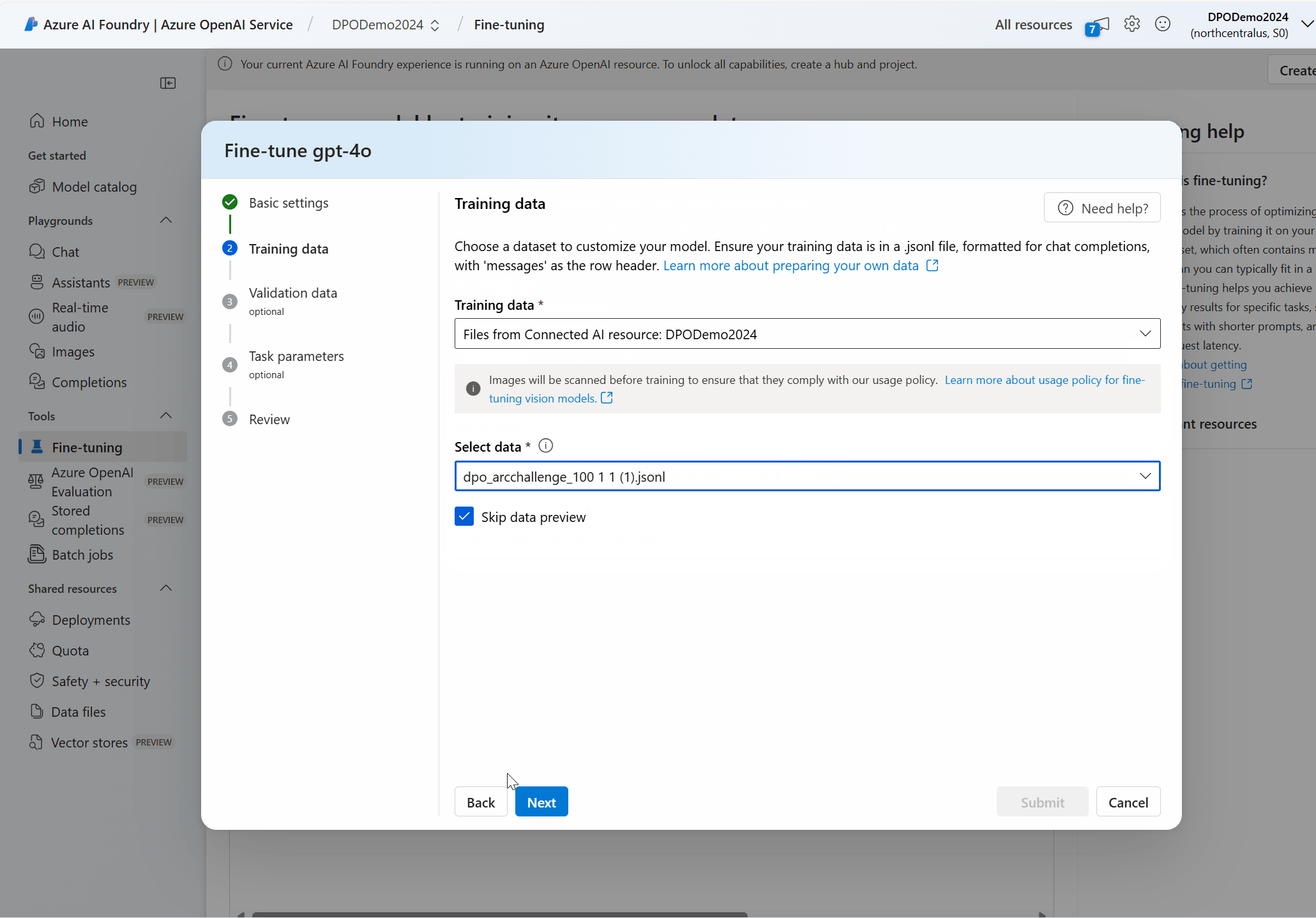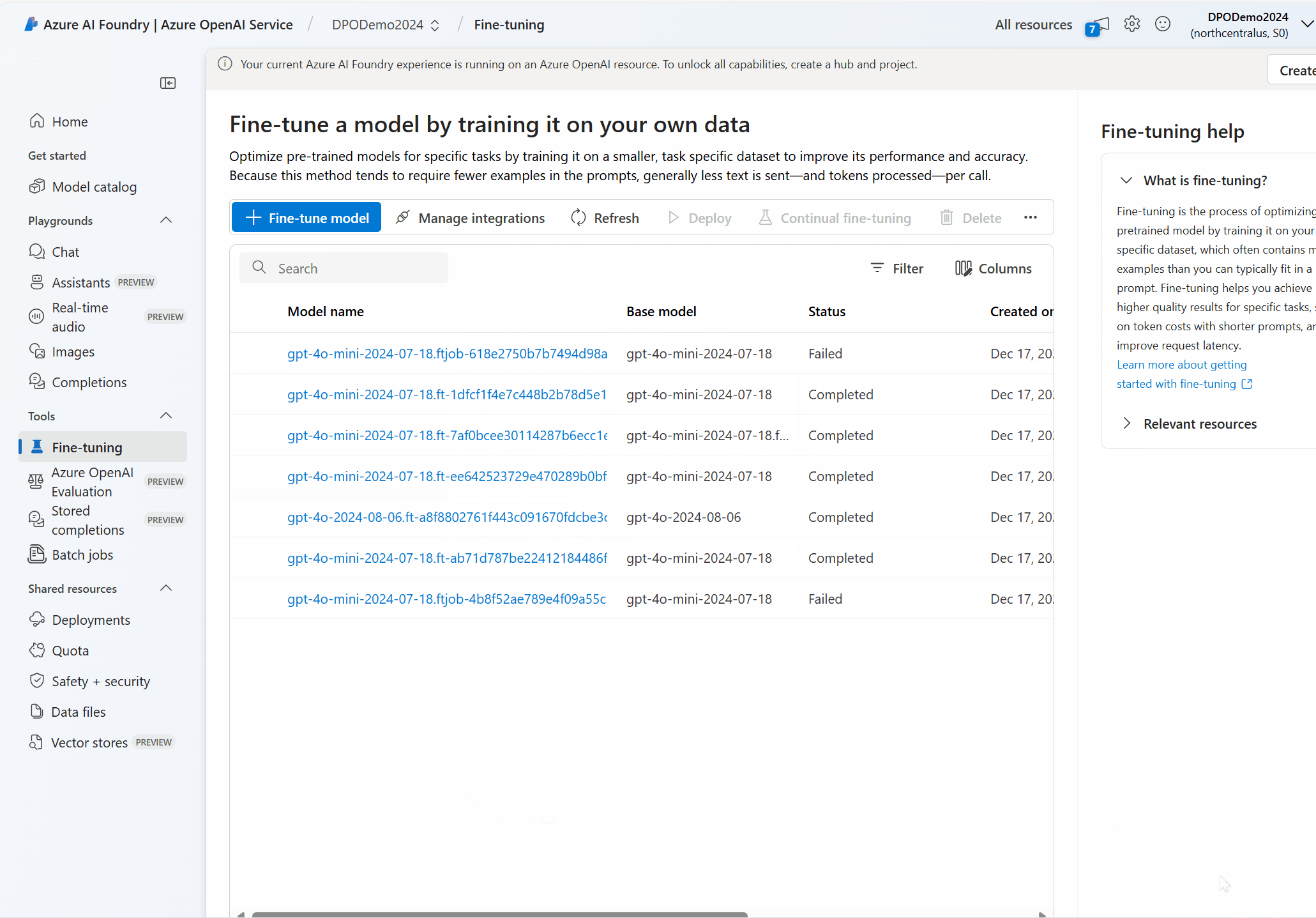
- Prepare los conjuntos de datos
jsonlen el formato de preferencia. - Seleccione el modelo y, a continuación, seleccione el método de personalización Optimización directa de preferencias.
- Carga de conjuntos de datos: entrenamiento y validación. Revise la vista previa según sea necesario.
- Seleccione los hiperparámetros; se recomiendan los valores predeterminados para la experimentación inicial.
- Revise las selecciones y cree un trabajo de ajuste preciso.
Solución de problemas
¿Cómo se habilita el ajuste preciso?
Para acceder correctamente al ajuste preciso, necesita Colaborador de OpenAI de Cognitive Services asignado. Incluso alguien con permisos de administrador de servicios de alto nivel necesitaría esta cuenta establecida explícitamente para acceder al ajuste preciso. Para más información, consulte las instrucciones de control de acceso basado en rol.
¿Por qué se produjo un error en la carga?
Si se produce un error en la carga de archivos en el Portal de la Fundición de IA de Azure, puede ver el mensaje de error en Archivos de datos. Mantenga el mouse sobre la zona que pone "error" (en la columna de estado) y aparecerá una explicación del error.

Mi modelo con ajuste preciso no parece haber mejorado
Mensaje de sistema que falta: tiene que proporcionar un mensaje de sistema cuando realice un ajuste preciso; posiblemente querrá proporcionar ese mismo mensaje de sistema cuando use el modelo con ajuste preciso. Si proporciona un mensaje de sistema diferente, es posible que vea resultados diferentes a aquellos para los que realizó el ajuste.
Datos insuficientes: mientras que 10 es el mínimo para que se ejecute la canalización, necesita cientos de puntos de datos, o incluso miles, para enseñar al modelo una nueva aptitud. Con muy pocos puntos de datos se corre el riesgo de un sobreajuste y una generalización deficiente. El modelo con ajuste preciso puede funcionar bien en los datos de entrenamiento pero de manera deficiente en otros datos porque ha memorizado los ejemplos de entrenamiento en lugar de los patrones de aprendizaje. Para obtener los mejores resultados, planee preparar un conjunto de datos con cientos o miles de puntos de datos.
Datos incorrectos: un conjunto de datos mal mantenido o no representativo producirá un modelo de baja calidad. El modelo puede aprender patrones inexactos o sesgados del conjunto de datos. Por ejemplo, si está entrenando un bot de chat para el servicio al cliente, pero solo proporciona datos de entrenamiento para un escenario (por ejemplo, devoluciones de artículos), no sabrá cómo responder en otros escenarios. O, si los datos de entrenamiento son incorrectos (contiene respuestas incorrectas), el modelo aprenderá a proporcionar resultados incorrectos.
Optimización con visión
Qué hacer si se omiten las imágenes
Las imágenes se pueden omitir por los siguientes motivos:
- contienen CAPTCHA
- contienen personas
- contienen caras
Quite la imagen. Por ahora, no podemos optimizar los modelos con imágenes que contengan estas entidades.
Problemas comunes
| Problema | Motivo o solución |
|---|---|
| Imágenes omitidas | Las imágenes se pueden omitir por las siguientes razones: contienen CAPTCHA, personas o caras. Quite la imagen. Por ahora, no podemos optimizar los modelos con imágenes que contengan estas entidades. |
| Dirección URL inaccesible | Compruebe que la dirección URL de la imagen es accesible públicamente. |
| Imagen demasiado grande | Compruebe que las imágenes se encuentran dentro de nuestros límites de tamaño del conjunto de datos. |
| Formato de imagen no válido | Compruebe que las imágenes se encuentran dentro del formato del conjunto de datos. |
Cómo cargar archivos grandes
Los archivos de entrenamiento podrían ser bastante grandes. Puede cargar archivos de hasta 8 GB en varias partes usando la API de Uploads, a diferencia de la API de Files, que solo permite cargar archivos de hasta 512 MB.
Reducción del costo de entrenamiento
Si establece el parámetro de detalle de una imagen en bajo, la imagen se redimensiona a 512 por 512 píxeles y solo se representa con 85 tokens independientemente de su tamaño. Esto reducirá el costo del entrenamiento.
{
"type": "image_url",
"image_url": {
"url": "https://raw.githubusercontent.com/MicrosoftDocs/azure-ai-docs/main/articles/ai-services/openai/media/how-to/generated-seattle.png",
"detail": "low"
}
}
Otras consideraciones para la optimización de la visión
Para controlar la fidelidad de la comprensión de la imagen, establezca el parámetro de detalle de image_url en low, high o auto para cada imagen. Esto también afectará al número de tokens por imagen que el modelo ve durante el tiempo de entrenamiento y afectará al costo del entrenamiento.
Pasos siguientes
- Explore las funcionalidades de ajuste preciso en el tutorial de ajuste preciso de Azure OpenAI.
- Revisión de la disponibilidad regional del modelo con ajuste preciso
- Más información sobre Cuotas de Azure OpenAI