Export Dataverse data in Delta Lake format
Use Azure Synapse Link for Dataverse to export your Microsoft Dataverse data to Azure Synapse Analytics in Delta Lake format. Then explore your data and accelerate time to insight. This article provides the following information and shows you how to perform the following tasks:
- Explains Delta Lake and Parquet and why you should export data in this format.
- Export your Dataverse data to your Azure Synapse Analytics workspace in Delta Lake format with the Azure Synapse Link.
- Monitor your Azure Synapse Link and data conversion.
- View your data from Azure Data Lake Storage Gen2.
- View your data from Synapse Workspace.
Important
- If you're upgrading from CSV to Delta Lake with existing custom views, we recommend updating the script to replace all partitioned tables to non_partitioned. Do this by looking for instances of
_partitionedand replace them with an empty string. - For the Dataverse configuration, append-only is enabled by default to export CSV data in
appendonlymode. But the Delta Lake table will have an in-place update structure because the Delta Lake conversion comes with a periodic merge process. - There are no costs incurred with the creation of Spark pools. Charges are only incurred once a Spark job is executed on the target Spark pool and the Spark instance is instantiated on demand. These costs are related to the usage of Azure Synapse workspace Spark and are billed monthly. The cost of conducting Spark computing mainly depends on the time interval for incremental update and the data volumes. More information: Azure Synapse Analytics pricing
- It's important to take these additional costs into consideration when deciding to use this feature as they are not optional and must be paid in order to continue using this feature.
- End of life announced (EOLA) for Azure Synapse Runtime for Apache Spark 3.3 has been announced July 12, 2024. In accordance with the Synapse runtime for Apache Spark lifecycle policy, Azure Synapse runtime for Apache Spark 3.3 will be retired and disabled as of March 31, 2025. After the EOL date, the retired runtimes are unavailable for new Spark pools and existing workflows can't execute. Metadata will temporarily remain in the Synapse workspace. More information: Azure Synapse Runtime for Apache Spark 3.3 (EOSA). To have your Synapse Link for Dataverse with export to Delta Lake format upgrade to Spark 3.4, do an in-place upgrade for your existing profiles. More information: In-place upgrade to Apache Spark 3.4 with Delta Lake 2.4
- Beginning December 25, 2024, only Spark Pool version 3.4 will be supported when initially creating the link.
Note
The Azure Synapse Link status in Power Apps (make.powerapps.com) reflects the Delta Lake conversion state:
Countshows the number of records in the Delta Lake table.Last synchronized onDatetime represents the last successful conversion timestamp.Sync statusis shown as active once the data sync and Delta Lake conversion complete, indicating that the data is ready for consumption.
What is Delta Lake?
Delta Lake is an open-source project that enables building a lakehouse architecture on top of data lakes. Delta Lake provides ACID (atomicity, consistency, isolation, and durability) transactions, scalable metadata handling, and unifies streaming and batch data processing on top of existing data lakes. Azure Synapse Analytics is compatible with Linux Foundation Delta Lake. The current version of Delta Lake included with Azure Synapse has language support for Scala, PySpark, and .NET. More information: What is Delta Lake?. You can also learn more from the Introduction to Delta Tables video.
Apache Parquet is the baseline format for Delta Lake, enabling you to leverage the efficient compression and encoding schemes that are native to the format. Parquet file format uses column-wise compression. It's efficient and saves storage space. Queries that fetch specific column values need not read the entire row data thus improving performance. Therefore, serverless SQL pool needs less time and fewer storage requests to read the data.
Why use Delta Lake?
- Scalability: Delta Lake is built on top of Open-source Apache license, which is designed to meet industry standards for handling large-scale data processing workloads.
- Reliability: Delta Lake provides ACID transactions, ensuring data consistency and reliability even in the face of failures or concurrent access.
- Performance: Delta Lake leverages the columnar storage format of Parquet, providing better compression and encoding techniques, which can lead to improved query performance compared to query CSV files.
- Cost-effective: The Delta Lake file format is a highly compressed data storage technology that offers significant potential storage savings for businesses. This format is specifically designed to optimize data processing and potentially reduce the total amount of data processed or running time required for on-demand computing.
- Data protection compliance: Delta Lake with Azure Synapse Link provides tools and features including soft-delete and hard-delete to comply various data privacy regulations, including General Data Protection Regulation (GDPR).
How Delta Lake works with Azure Synapse Link for Dataverse?
When setting up an Azure Synapse Link for Dataverse, you can enable the export to Delta Lake feature and connect with a Synapse workspace and Spark pool. Azure Synapse Link exports the selected Dataverse tables in CSV format at designated time intervals, processing them through a Delta Lake conversion Spark job. Upon the completion of this conversion process, CSV data is cleaned up for storage saving. Additionally, a series of maintenance jobs are scheduled to run on a daily basis, automatically performing compaction and vacuuming processes to merge and clean up data files to further optimize storage and improve query performance.
Prerequisites
- Dataverse: You must have the Dataverse system administrator security role. Additionally, tables you want to export via Azure Synapse Link must have the Track changes property enabled. More information: Advanced options
- Azure Data Lake Storage Gen2: You must have an Azure Data Lake Storage Gen2 account and Owner and Storage Blob Data Contributor role access. Your storage account must enable Hierarchical namespace and public network access for both initial setup and delta sync. Allow storage account key access is required only for the initial setup.
- Synapse workspace: You must have a Synapse workspace and Owner role in access control(IAM) and the Synapse Administrator role access within the Synapse Studio. The Synapse workspace must be in the same region as your Azure Data Lake Storage Gen2 account. The storage account must be added as a linked service within the Synapse Studio. To create a Synapse workspace, go to Creating a Synapse workspace.
- An Apache Spark pool in the connected Azure Synapse workspace with Apache Spark Version 3.4 using this recommended Spark Pool configuration. For information about how to create a Spark Pool, go to Create new Apache Spark pool.
- The Microsoft Dynamics 365 minimum version requirement to use this feature is 9.2.22082. More information: Opt in to early access updates
Recommended Spark Pool configuration
This configuration can be considered a bootstrap step for average use cases.
- Node size: small (4 vCores / 32 GB)
- Autoscale: Enabled
- Number of nodes: 5 to 10
- Automatic pausing: Enabled
- Number of minutes idle: 5
- Apache Spark: 3.4
- Dynamically allocate executors: Enabled
- Default number of executors: 1 to 9
Important
Use the Spark pool exclusively for Delta Lake conversation operation with Synapse Link for Dataverse. For optimal reliability and performance, avoid running other Spark jobs using the same Spark pool.
Connect Dataverse to Synapse workspace and export data in Delta Lake format
Sign into Power Apps and select the environment you want.
On the left navigation pane, select Azure Synapse Link. If the item isn’t in the side panel pane, select …More and then select the item you want.
On the command bar, select + New link
Select Connect to your Azure Synapse Analytics workspace, and then select the Subscription, Resource group, and Workspace name.
Select Use Spark pool for processing, and then select the precreated Spark pool and Storage account.
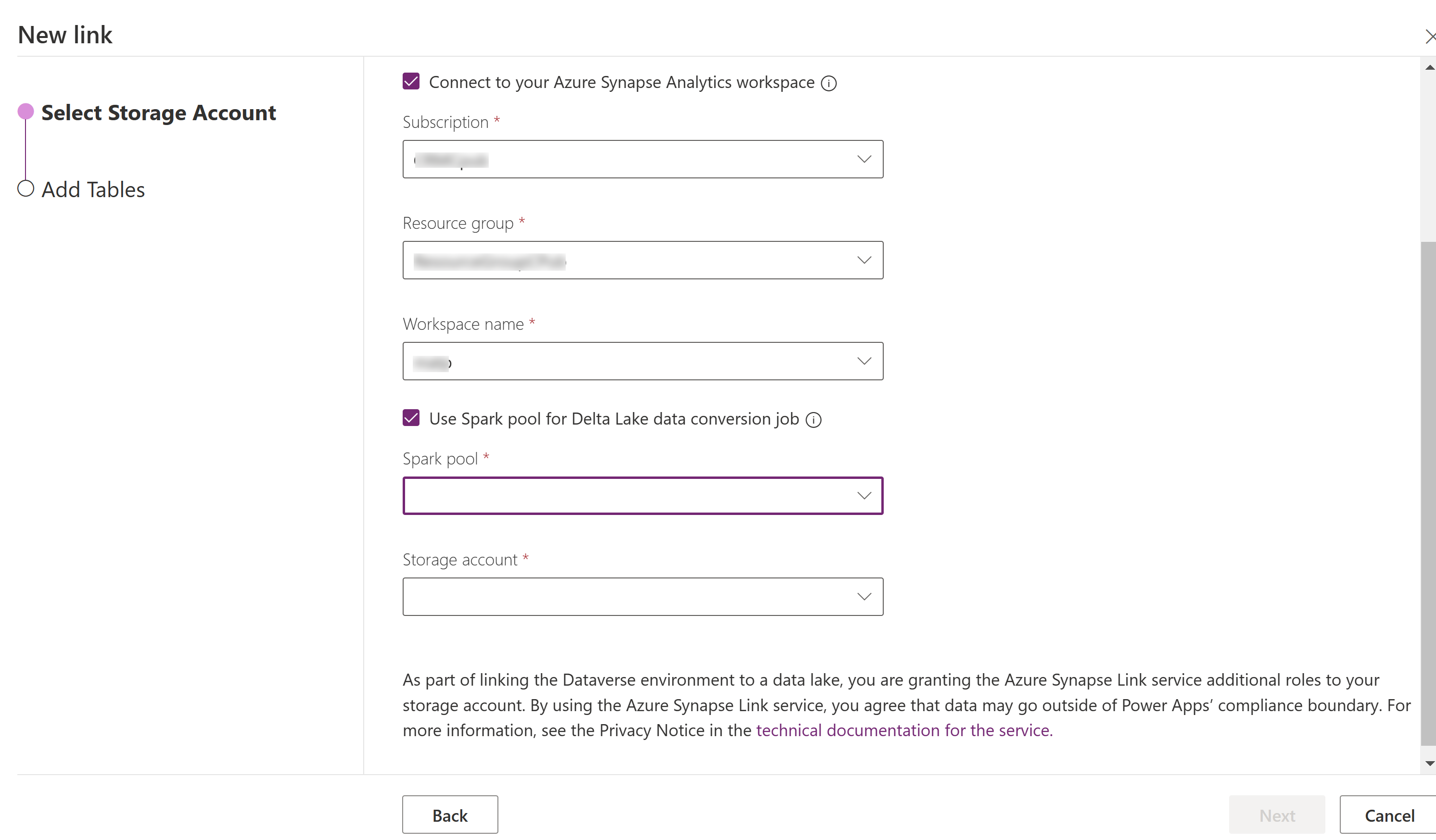
Select Next.
Add the tables you want to export, and then select Advanced.
Optionally, select Show advanced configuration settings and enter the time interval, in minutes, for how often the incremental updates should be captured.
Select Save.
Monitor your Azure Synapse Link and data conversion
- Select the Azure Synapse Link you want, and then select Go to Azure Synapse Analytics workspace on the command bar.
- Select Monitor > Apache Spark applications. More information: Use Synapse Studio to monitor your Apache Spark applications
View your data from Synapse workspace
- Select the Azure Synapse Link you want, and then select Go to Azure Synapse Analytics workspace on the command bar.
- Expand Lake Databases on the left pane, select dataverse-environmentNameorganizationUniqueName, and then expand Tables. All Parquet tables are listed and available for analysis with the naming convention DataverseTableName. (Non_partitioned Table).
Note
Don't use tables with the naming convention _partitioned. When you choose Delta parquet as the format, tables with the _partition naming convention are used as staging tables and removed after they're used by the system.
View your data from Azure Data Lake Storage Gen2
- Select the Azure Synapse Link you want, and then select Go to Azure data lake on the command bar.
- Select the Containers under Data Storage.
- Select *dataverse- *environmentName-organizationUniqueName. All parquet files are stored in the deltalake folder.
In place upgrade to Apache Spark 3.4 with Delta Lake 2.4
Prerequisites
- You must have an existing Azure Synapse Link for Dataverse Delta Lake profile running with a Synapse Spark version 3.3.
- You must create a new Synapse Spark pool with Spark version 3.4, using the same or higher nodes hardware configuration within the same Synapse workspace. For information about how to create a Spark Pool, go to Create new Apache Spark pool. This Spark pool should be created independent of the current 3.3 pool.
In-place upgrade to Spark 3.4:
- Sign in to Power Apps and select your preferred environment.
- On the left navigation pane, select Azure Synapse Link. If the item isn’t in the left navigation pane, select …More and then select the item you want.
- Open the Azure Synapse Link profile, and then select Upgrade to Apache Spark 3.4 with Delta Lake 2.4.
- Select the available Spark pool from the list, and select then Update.
Note
The Spark pool upgrade occurs only when a new Delta Lake conversion Spark job is triggered. Ensure you have at least one data change after selecting Update.