Generate aggregate tables
Important
Some or all of this functionality is available as part of a preview release. The content and the functionality are subject to change.
Aggregate tables or aggregated datasets are denormalized datasets that contain aggregated measurement value (for example: CO2e emissions, water utilization, or waste generated) from the environmental, social, and governance (ESG) data model tables for a comprehensive set of dimensions, including reporting period. ESG metrics are computed on top of these aggregate tables.
The capability provides set of prebuilt notebooks you can use to generate these aggregate tables for computing prebuilt and custom metrics. The notebooks contain the computation logic for generating these aggregate tables.
| Aggregate table name | Prebuilt notebook |
|---|---|
| EmissionsAggregate | CreateAggregateForEmissionsMetrics_INTB |
| EmployeeDataAggregate | CreateAggregateForEmployeeMetrics_INTB |
| EmployeeEventsAggregate | CreateAggregateForEmployeeEventMetrics_INTB |
| IncidentDataAggregate | CreateAggregateForIncidentMetrics_INTB |
| NetRevenueAggregate | CreateAggregateForNetRevenueMetrics_INTB |
| PreCalculatedMetricsAggregate | CreateAggregateForPreCalculatedMetrics_INTB |
| ResourceInflowsAggregate | CreateAggregateForResourceInflowMetrics_INTB |
| ResourceOutflowsAggregate | CreateAggregateForResourceOutflowMetrics_INTB |
| SustainabilityContentResourceInflowsAggregate | CreateAggregateForResourceInflowsSustainabilityContentMetrics_INTB |
| SustainabilityContentResourceOutflowsAggregate | CreateAggregateForResourceOutflowsSustainabilityContentMetrics_INTB |
| WasteQuantityAggregate | CreateAggregateForWasteMetrics_INTB |
| WaterStorageAggregate | CreateAggregateForWaterStorageMetrics_INTB |
| WaterUtilizationAggregate | CreateAggregateForWaterUtilizationMetrics_INTB |
Generate aggregate tables
Refer to Prebuilt metrics library to select the metric to compute and figure out the required aggregate table to be generated. Then run the corresponding notebook (from the previous table) separately or run the ExecuteToCreateAggregates_DTPL pipeline by selecting the aggregate table to be generated in the pipeline parameter.
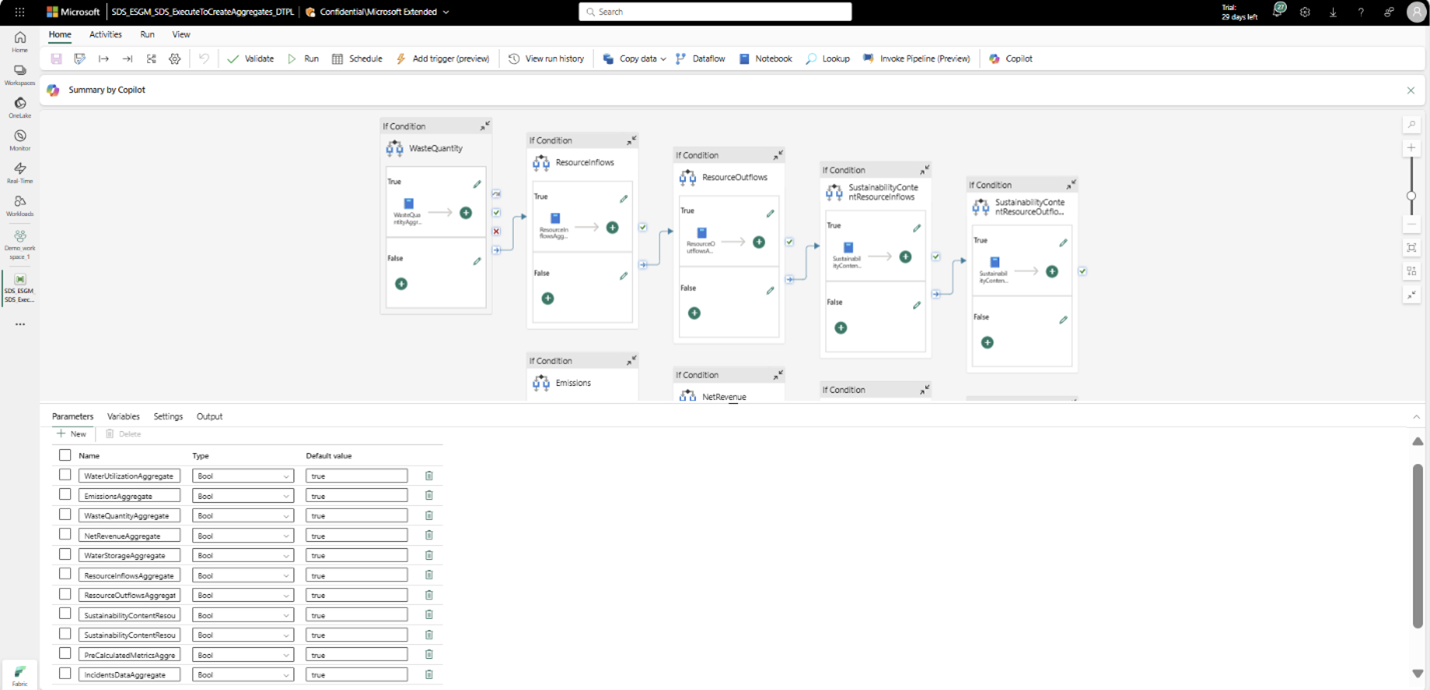
Note
By default the pipeline generates all the aggregate tables since the parameters are set to True. In case you want to generate data for only a specific aggregate table then set the value for all the remaining aggregate tables as false.
When the notebook or pipeline runs successfully, the aggregate table should be generated and stored in the ComputedESGMetrics lakehouse. If the aggregate table already exists, then it's overwritten.
Note
This step corresponds to the Create aggregate tables activity in the ExecuteComputationForMetrics_DTPL pipeline. The ExecuteToCreateAggregates_DTPL pipeline is invoked as an activity in this pipeline. That means you can also run the Create aggregate tables activity to generate the aggregate tables.
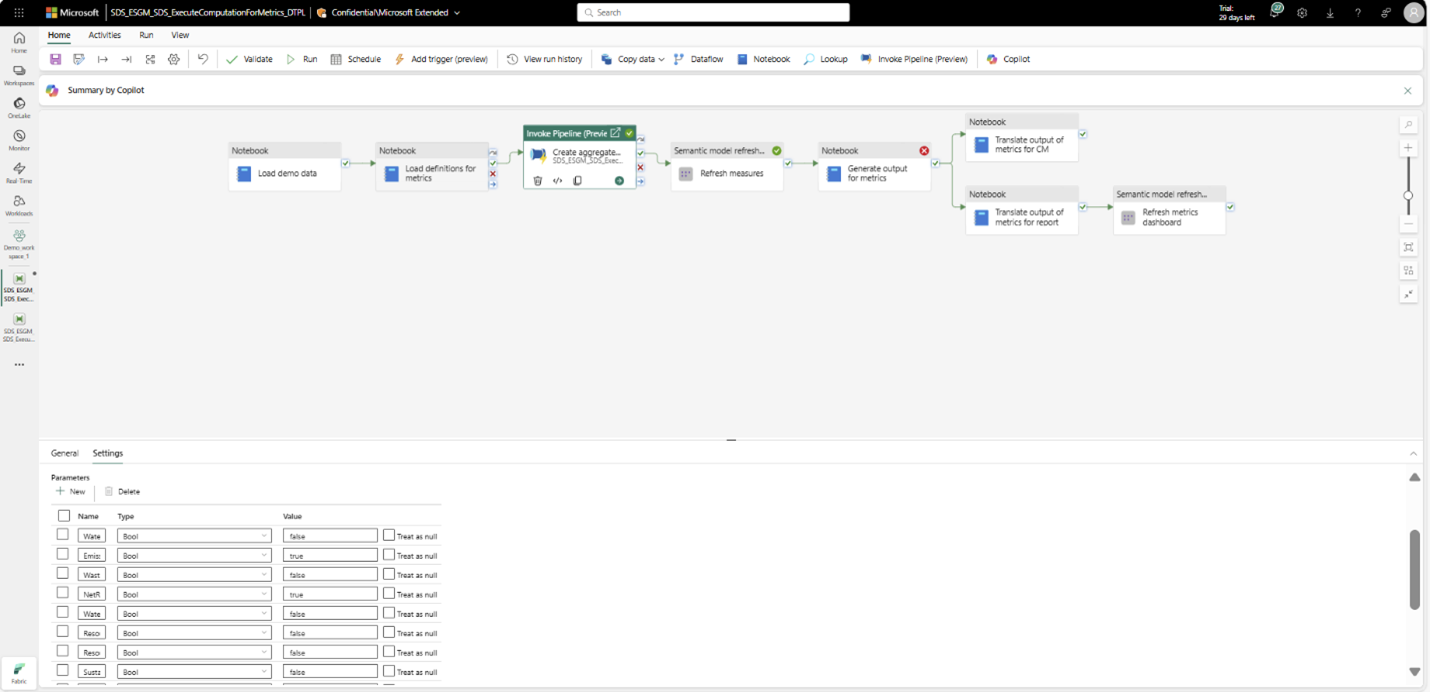
Refresh the measures semantic model (DatasetForMetricsMeasures_DTST) so that the latest aggregate table data is updated in the semantic model.
For the first refresh, you need to authenticate the semantic model by creating a connection. For more information, go to Prerequisites. Next, open the DatasetForMetricsMeasures_DTST semantic model from the workspace page and select Refresh now from the Refresh menu to refresh the semantic model.
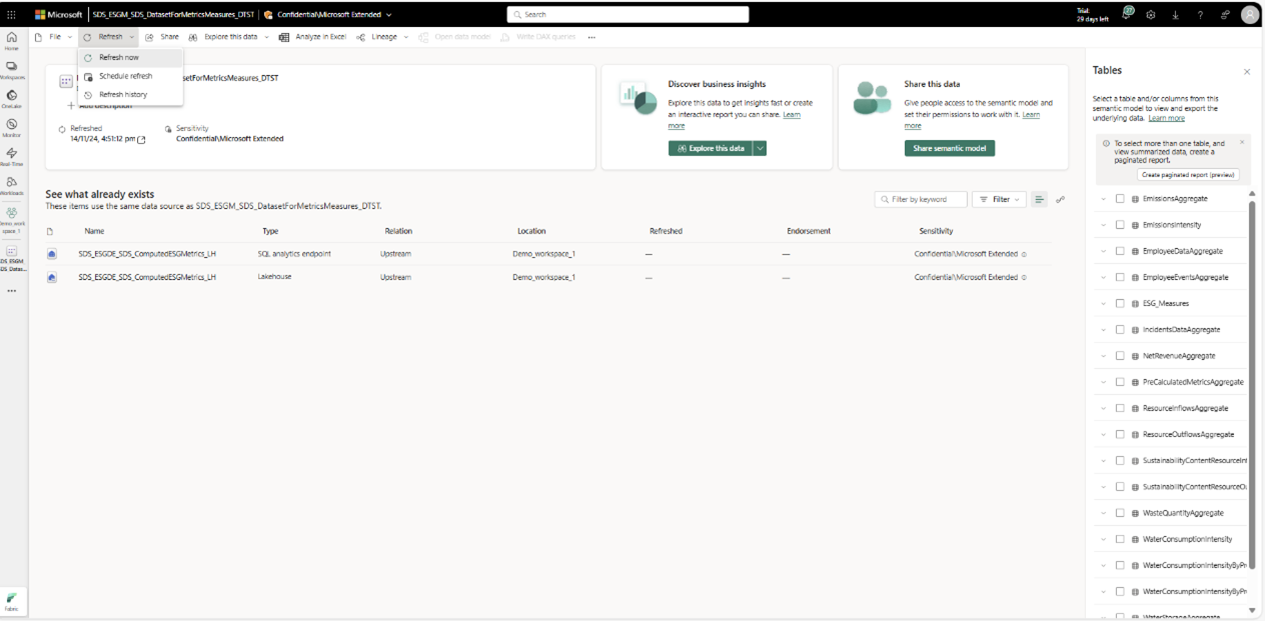
After the refresh completes, you can select Refresh history from the Refresh menu to confirm the status of the refresh. If there are any errors, you can find the error details in the refresh history.
This step corresponds to the Refresh measures activity in the ExecuteComputationForMetrics_DTPL pipeline. You can also run this activity to refresh the semantic model.
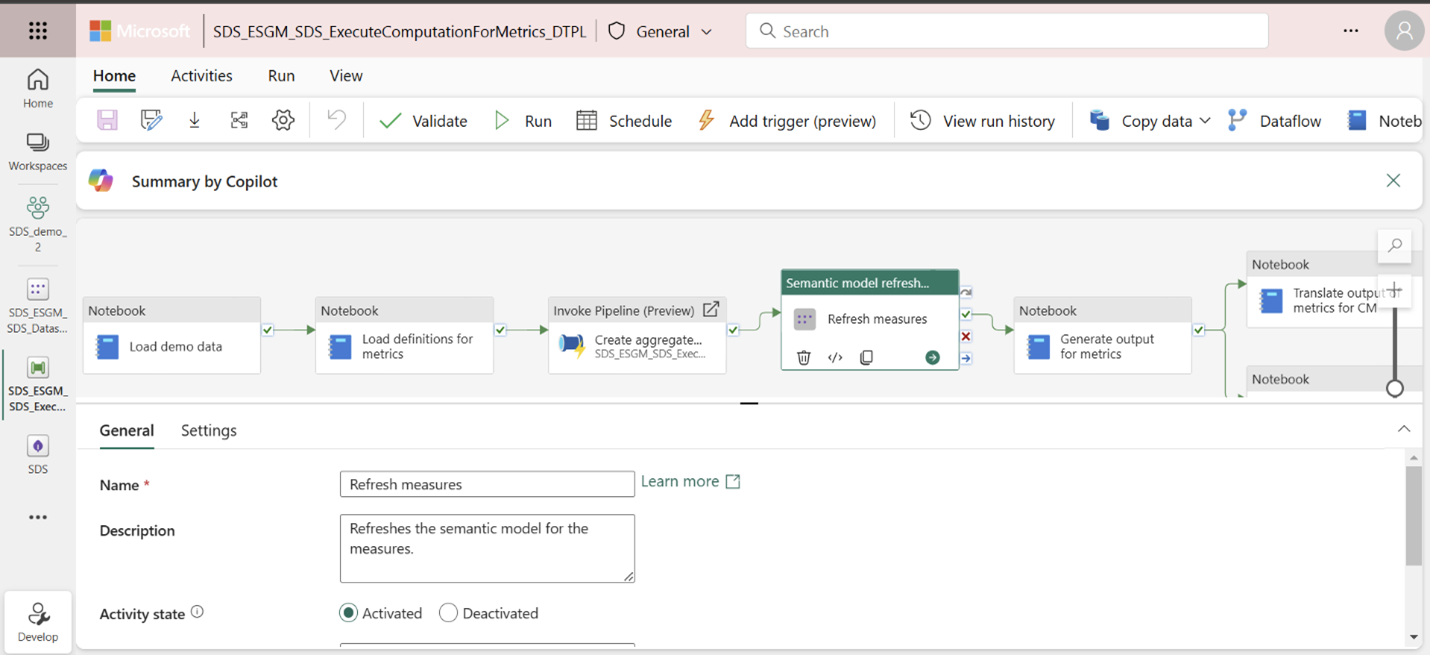
If this is your first time running the pipeline, you also need to set up a connection for the pipeline Refresh measures activity. For more details about this step, refer to the prerequisites mentioned in Explore with demo data.




After these steps run successfully, the aggregate table should appear under tables in ComputedESGMetrics_LH, and the semantic model should contain the updated data.
