Identifying sensitive and security classified information for Australian Government compliance with PSPF
This article provides guidance for Australian Government organizations on the use of Microsoft Purview for identifying sensitive and security classified information. Its purpose is to help such organizations strengthen their approach to data security and their ability to comply with requirements outlined in the Protective Security Policy Framework (PSPF) and Information Security Manual (ISM).
Key to protecting information and securing it from data loss is first understanding what information is. This article explores methods of identifying information across an organizations Microsoft 365 environment. These approaches are often referred to as the know your data aspects of Microsoft Purview. Once identified, the information can then be protected via both sensitivity auto-labeling and Data Loss Prevention(DLP).
Sensitive Information Types
Sensitive information types (SITs) are pattern-based classifiers. They detect sensitive information via regular expressions (RegEx) or keywords.
There are many different types of SITs that are relevant to Australian Government organizations:
- Prebuilt SITS created by Microsoft, several of which align with common Australian data types.
- Custom SITs are created based on organizational requirements.
- Named entity SITs include complex dictionary-based identifiers such as Australian physical addresses.
- Exact Data Match (EDM) SITs are generated based on actual sensitive data.
- Document fingerprint SITs are based on the format of documents rather than their content.
- SITs relevant to network or information security although technically prebuilt SITs, they have special relevance to cyber teams working for Australian Government organizations, and so are worthy of their own category.
Prebuilt Sensitive Information Types
Prebuilt sensitive information types are based on common types of information that customers typically consider sensitive. These can be generic and have global relevance (for example, credit card numbers), or have local relevance (for example, Australian bank account numbers).
Microsoft's complete list of Prebuilt SITs can be found in sensitive information type entity definitions
Australian specific SITs include:
- Australian bank account number
- Australian driver's license number
- Australian passport number
- Australian physical addresses
- Australian tax file number
- Australian business number
- Australian company number
- Australian medical account number
These SITs can be found within the Microsoft Purview Data classification portal under Classifiers > Sensitive info types.
Prebuilt SITs are valuable for organizations starting their Information Protection or Governance Journey as they provide a head start towards the enablement of capabilities like DLP and Auto-labeling. The two easiest ways to make use of these SITs are:
Use of prebuilt SITs via DLP policy templates
Some prebuilt SITs are included in Microsoft created DLP policy templates that align with Australian regulations. The following DLP policy templates that align with Australian requirements are available for use:
- Australia Privacy Act Enhanced
- Australia Financial Data
- PCI Data Security Standard (PCI DSS)
- Australia Personally Identifiable Information (PII) Data
Enablement of DLP policies based on these templates allow for initial monitoring of data loss events, which form a great starting point for organizations introducing Microsoft 365 DLP. Once deployed, these policies provide insight into the extent of an organizations data loss issue and can help to drive decisions on next steps.
Use of these policy templates is further explored in limiting distribution of sensitive information.
Use of prebuilt SITs in sensitivity auto-labeling
If an item is detected to contain an Australian medical account number, one or more medical terms, and a full name, then it could be fair to assume that the item contains personally identifiable medical information and could constitute a health record. Based on this assumption, we can suggest to a user that the item be labeled as 'OFFICIAL: Sensitive Personal Privacy,' or whichever label is most appropriate in your organization for identification and protection of health records.
For more information where this feature can assist Government Organizations meet PSPF compliance, see automatic application of sensitivity labels and client-based auto-labeling scenarios for Australian Government.
Custom Sensitive Information Types
In addition to prebuilt SITs, organizations can create SITs based on their own definitions of sensitive information. Examples of information relevant to Australian Government organizations that could be identified via custom SIT are:
- Protective markings
- Clearance ID or Clearance application ID
- Classifications from other states or territories
- Classifications that shouldn't appear on the platform (for example, TOP SECRET)
- Ministers' briefings or correspondence
- Freedom of Information (FOI) Request Number
- Probity related information
- Terms relating to sensitive systems, projects, or applications
- Paragraph markings
- Trim or Objective record numbers
Custom SITs are made up of a primary identifier, which can be either based on a Regular Expression or keywords, confidence level, and optional supporting elements.
For more detailed explanation of SITs and their components, see Learn about sensitive information types.
Regular Expressions (RegEx)
Regular expressions are code-based identifiers that can be used to identify patterns of information. For example, if a Freedom of Information (FOI) number was made up of the letters FOI followed by a four-digit year, a hyphen and a further three digits (for example, FOI2023-123), it could be represented in a regular expression of:
[Ff][Oo][Ii]20[01234]\d{1}-\d{3}
To explain this expression:
[Ff][Oo][Ii]matches an upper or lower case letters F, O, and I.20matches the number 20 as the first half of out four digit year.[0123]matches 0, 1, 2 or 3 in the third digit in our four digit year value, which allows us to match FOI numbers from the year 2000 until 2039.-matches a hyphen.\d{3}matches any three digits.
Tip
Copilot is quite adept at generating regular expressions (RegEx). You can use natural language to ask Copilot to generate RegEx for you.
List of keywords or a keyword dictionary
Keyword lists and dictionaries consist of words, terms, or phrases that are likely to be included in the items that you're seeking to identify. cabinet briefing or tender application are terms that could be useful as keywords.
Keywords can be case sensitive or insensitive. Case can be useful in eliminating false positives. For example, lower case official is more likely to be used in general conversation but uppercase OFFICIAL has higher probability of being part of a protective marking.
Keyword dictionaries containing large datasets can also be uploaded via CSV or TXT format. For more information on how uploading a keyword dictionary, see how to create a keyword dictionary.
Confidence level
Some keywords or regular expressions can provide accurate matching without need for refinement. The Freedom of Information (FOI) expression included in the previous example of a value is unlikely to come up in general conversation and when it does appear in correspondence, is likely to match relevant information. However, if we were trying to match an Australian Public Service employee number, which is represented as eight numerical digits, our matching is likely to result in numerous false positives. Confidence level allows us to assign a likelihood that the presence of the keyword or pattern in an item such as an email or document, is actually what we're looking for. More more information on confidence levels, see managing confidence levels.
Primary and supporting elements
Custom SITs also have a concept of primary and supporting elements. The primary element is the key pattern we want to detect in content. Supporting elements can be added to a primary to build a case for occurrence of a value being an accurate match. For example, if attempting to match based on a eight numerical digit employee number, we could use keywords of 'employee number' or Australian Government Number AGS, or Australian Public Service Employee Database APSED as a supporting element to increase confidence that the match is relevant. For more information on how to create primary and supporting elements, see understanding elements.
Character proximity
The final value that we would generally configure in a SIT is character proximity. This is the distance between primary and supporting elements. If we expect the keyword AGS to be near to our eight digit numerical value, then we configure a proximity of 10 characters. If primary and supporting elements aren't likely to appear next to each other, we set the proximity value to be a greater number of characters. For more information on how to create character proximity, see understanding proximity.
SITs to identify protective markings
A valuable way for Australian Government organizations to make use of custom SITs is to identify protective markings. In a Greenfield organization, all items in an environment have a sensitivity label applied to them. However, most government organizations have legacy labeling requiring modernization to Microsoft Purview. SITs are used to identify and apply markings to:
- Marked legacy files
- Marked files generated by external entities
- Email conversations initiated and marked externally
- Emails that have lost their label information (x-headers)
- Emails, which have had their labels incorrectly downgraded
When such a marker is identified, the user is advised of the detection and a label recommendation is provided to them. If they accept the recommendation, then label-based protections apply to the item. These concepts are further discussed in Client-based auto-labeling scenarios for Australian Government.
Classification-based SITs are also useful in DLP. Examples include:
- A user receives information and identifies it as sensitive via its marking but doesn't want to reclassify it as it doesn't translate to a PSPF classification (for example, 'OFFICIAL Sensitive NSW Government'). Constructing a DLP policy to protect the enclosed information based on the marking rather than the applied label means that we can apply a measure of data security to it.
- A user copies text from an email conversation, which includes a protective marking. They paste the information into a Teams chat with an external participant who shouldn't have access to the information. Via a DLP policy applying to the Teams service, the marking can be detected and disclosure prevented.
- A user incorrectly downgrades a sensitivity label on an email conversation (either maliciously, or by user-error). As the protective markings were applied to the email previously are visible in the email's body, Microsoft Purview detects that the current and previous markings are misaligned. Depending on configuration, the action logs the event, warn the user, or block the email.
- A marked email is sent to an external recipient who is making use of a nonenterprise email platform or client. The platform or client removes the email's metadata (x-headers) which causes the external recipient's reply email to not have a sensitivity label applied when it arrives to the organization's user mailbox. Detecting the previous marking via a SIT allows the reapplication of the label transparently or recommend that the user reapplies the label on their next reply.
In each of these scenarios, classification-based SITs could be used to detect applied protective markings and mitigate the potential data breach.
Example SIT syntax to detect protective markings
The following regular expressions could be used in custom SITs to identify protective markings.
Important
Creation of SITs to identify protective markings assists in PSPF compliance. Classification-based SITs are also be used in DLP and auto-labeling scenarios.
| SIT name | Regular expression |
|---|---|
| UNOFFICIAL Regex1 | UNOFFICIAL |
| OFFICIAL Regex1,2 | (?<!UN)OFFICIAL |
| OFFICIAL Sensitive Regex1,3,4,5 | OFFICIAL[:- ]\s?Sensitive(?!(?:\s\|\/\/\|\s\/\/\s)[Pp]ersonal[- ][Pp]rivacy)(?!(?:\s\|\/\/\|\s\/\/\s)[Ll]egislative[- ][Ss]ecrecy)(?!(?:\s\|\/\/\|\s\/\/\s)[Ll]egal[- ][Pp]rivilege)(?!(?:\s\|\/\/\|\s\/\/\s)NATIONAL[ -]CABINET) |
| OFFICIAL Sensitive Personal Privacy Regex1,4,5 | OFFICIAL[:- ]\s?Sensitive(?:\s\|\/\/\|\s\/\/\s\|,\sACCESS=)Personal[ -]Privacy |
| OFFICIAL Sensitive Legal Privilege Regex1,4,5 | OFFICIAL[:- ]\s?Sensitive(?:\s\|\/\/\|\s\/\/\s\|,\sACCESS=)Legal[ -]Privilege |
| OFFICIAL Sensitive Legislative Secrecy Regex1,4,5 | OFFICIAL[:- ]\s?Sensitive(?:\s\|\/\/\|\s\/\/\s\|,\sACCESS=)Legislative[ -]Secrecy |
| OFFICIAL Sensitive NATIONAL CABINET Regex1,4,5 | OFFICIAL[:- ]\s?Sensitive(?:\s\|\/\/\|\s\/\/\s\|,\sCAVEAT=SH:)NATIONAL[ -]CABINET |
| PROTECTED Regex1,3,5 | PROTECTED(?!,\sACCESS=)(?!(?:\s\|\/\/\|\s\/\/\s)[Pp]ersonal[- ][Pp]rivacy)(?!(?:\s\|\/\/\|\s\/\/\s)[Ll]egislative[- ][Ss]ecrecy)(?!(?:\s\|\/\/\|\s\/\/\s)[Ll]egal[- ][Pp]rivilege)(?!(?:\s\|\/\/\|\s\/\/\s)NATIONAL[ -]CABINET)(?!(?:\s\|\/\/\|\s\/\/\s)CABINET) |
| PROTECTED Personal Privacy Regex1,5 | PROTECTED(?:\s\|\/\/\|\s\/\/\s\|,\sACCESS=)Personal[ -]Privacy |
| PROTECTED Legal Privilege Regex1,5 | PROTECTED(?:\s\|\/\/\|\s\/\/\s\|,\sACCESS=)Legal[ -]Privilege |
| PROTECTED Legislative Secrecy Regex1,5 | PROTECTED(?:\s\|\/\/\|\s\/\/\s\|,\sACCESS=)Legislative[ -]Secrecy |
| PROTECTED NATIONAL CABINET Regex1,5 | PROTECTED(?:\s\|\/\/\|\s\/\/\s\|,\sCAVEAT=SH:)NATIONAL[ -]CABINET |
| PROTECTED CABINET Regex1,5 | PROTECTED(?:\s\|\/\/\|\s\/\/\s\|,\sCAVEAT=SH:)CABINET |
When evaluating the previous SIT examples, note the following expression logic:
- 1 These expressions match markings applied to both documents (for example, OFFICIAL: Sensitive NATIONAL CABINET) and email (for example, '[SEC=OFFICIAL:Sensitive, CAVEAT=NATIONAL-CABINET]').
- 2 The negative lookbehind in OFFICIAL Regex (
(?<!UN)) prevents UNOFFICIAL items from being matched as OFFICIAL. - 3 OFFICIAL Sensitive Regex and PROTECTED Regex use negative lookaheads (
(?!)) to ensure that an Information Management Markers (IMM) or caveat isn't applied after the security classification. This helps to prevent items with IMMs or caveats from being identified as the non-IMM or caveat version of the classification. - 4 The use of
[:\- ]in OFFICIAL: Sensitive is intended to allow for flexibility in this marking's format and is important due to the use of colon characters in x-headers. - 5
(?:\s\|\/\/\|\s\/\/\s)is used to identify space between marking components and allows for either single space, double space, double forward slash or double forward slash with spaces. This is intended to allow for the different interpretations of PSPF marking format that exists between Australian Government organizations.
Named entity sensitive information types
Named entity SITs are complex dictionary and pattern-based identifiers created by Microsoft, which can be used to detect information like:
- People's names
- Physical addresses
- Medical terms and conditions
Named entity SITs can be used in isolation but can also be valuable as supporting elements. For example, a medical term existing within an email may not be useful as an indication that the item contains sensitive information. However, a medical term when paired with a value that might indicate a client or patient number and a first and family name, would provide a strong indication that the item is sensitive.
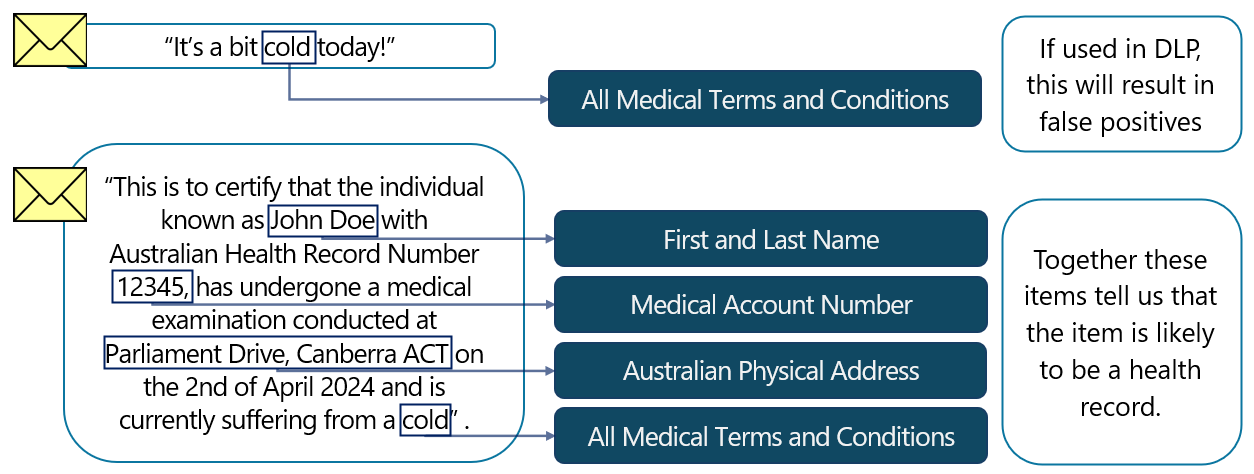
Named entity SITs can be paired with custom SITs, used as supporting elements, or even included with other SITs in DLP policies.
For more information on named entity SITs, see learn about named entities.
Exact data match sensitive information types
Exact Data Match (EDM) SITs are generated based on actual data. Numeric values, such as numeric customer IDs, are difficult to match via standard SITs due to clashes with other numerical values like phone numbers. Supporting elements improve matching help reducing false positives.
Exact Data Match helps Australian Government organizations who have systems, which contain data relating to employees, customers, or citizens for accurately identifying this information.
For more information to implement EDM SITs, see learn about exact data match based sensitive information types.
Document fingerprinting
Document Fingerprinting is an information identification technique that, rather than looking for values contained in an item, instead looks at the item's format and structure. Essentially, this allows us to convert a standard form into a sensitive information type that can be used to identify information.
Government organizations can use document fingerprinting method of content identification to identify items that have been generated via a workflow or forms submitted by other organizations or members of the public.
For information on implementing document fingerprinting, see document fingerprinting.
Network or security-related sensitive information types
There are numerous uses for SITs beyond identification of security classified or otherwise sensitive information. One such use is detection of credentials. Prebuilt SITs are provided for the following credential types:
- User sign in credentials
- Microsoft Entra ID client access tokens
- Azure Batch shared access keys
- Azure Storage account shared access signatures
- Client secret / API keys
These prebuilt SITs are used independently and are also bundled into a SIT called All credentials. The all credentials SIT is useful for cyber teams who use it in:
- DLP policies to identify and prevent lateral movement by malicious users or external attackers.
- Auto-labeling policies, to apply encryption to items that shouldn't contain credentials, locking users out of files and allowing remediation actions to commence.
- DLP policies to prevent users from sharing their credentials with other users against organization policies.
- To highlight items stored in SharePoint or Exchange locations, which are inappropriately retaining credential information.
Prebuilt SITs also exist for network addresses (both IPv4 and IPv6) and are useful for securing items containing network information, or preventing users from sharing IP addresses via email, Teams chat or channel messages.
Trainable Classifiers
Trainable classifiers are machine learning models that can be trained to recognize sensitive information. As with SITs, Microsoft provides pretrained classifiers. An extract of pretrained classifiers that are relevant to Australian Government organizations are listed in the following table:
| Classifier Category | Example Trainable Classifiers |
|---|---|
| Financial | Bank statements, budget, financial audit reports, financial statements, tax, statement of accounts, Budget Estimates (BE), Business Activity Statement (BAS). |
| Business | Operating procedures, non-disclosure agreements, procurement, project code words, Senate Estimates (SE), Questions on Notice (QoNs). |
| Human resources | Resumes, employee disciplinary action files, employment agreement, Australian Government Security Vetting Agency (AGSVA) clearances, Higher Education Loan Program (HELP), military ID, Foreign Work Authorization (FWA). |
| Medical | Healthcare, medical forms, MyHealth Record. |
| Legal | Legal affairs, agreements, license agreements. |
| Technical | Software development files, project documents, network design files. |
| Behavioral | offensive language, profanity, threat, targeted harassment, discrimination, regulatory collusion, customer complaint. |
Some examples of how Government organizations could use these prebuilt classifiers include:
- Business rules might dictate that some items in the HR category, such as resumes, should be marked as 'OFFICIAL: Sensitive Personal Privacy' due to them containing sensitive personal information. For these items, a label recommendation could be configured via client-based auto-labeling.
- Network design files, particularly for secure networks, should be treated carefully to avoid compromise. These could be worthy of either a PROTECTED label, or at the least, DLP policies preventing from unauthorized disclosure to unauthorized users.
- Behavioral classifiers are interesting and although they might not have a direct correlation with protective markings or DLP requirements, they can still have high business value. For example, HR teams could be notified of occurrences of harassment and/or provided with the ability to screen flagged correspondence via Communications Compliance.
Organizations can also train their own classifiers. Classifiers can be trained providing them with sets of positive and negative samples. The classifier processes the samples and builds a prediction model. Once training is complete, classifiers can be used for the application of sensitivity labels, communications compliance policies, and retention labeling policies. The use of classifiers in DLP policies is available in preview.
For more information on trainable classifiers, see learn about trainable classifiers.
Using identified sensitive information
Once information is identified via either SIT or classifier (via the know your data aspects of Microsoft Purview), we can use this knowledge to help us in our completion of the other three pillars of Microsoft 365 information management, namely:
- Protect your data,
- Prevent data loss, and
- Govern your data.
The following table provides benefits and examples of how knowledge of an item containing sensitive information could assist with the management of the information across the Microsoft 365 platform:
| Capability | Example of use |
|---|---|
| Data Loss Prevention | Assists management by reducing risks of data spill. |
| Sensitivity labeling | Recommends applying appropriate sensitivity label. Once labeled, label-related protections apply to the information. |
| Retention labeling | Automatically applies a retention label, enabling archive or records management requirements to be met. |
| Content Explorer | View where items containing sensitive information reside across Microsoft 365 services, including SharePoint, Teams, OneDrive, and Exchange. |
| Insider Risk Management | Monitor for user activity around sensitive information, establish a user risk level based on behavior, and escalate suspicious behavior to relevant teams. |
| Communication Compliance | Screen high risk correspondence, including any chat or email containing sensitive or suspicious content. Communication compliance can help with ensuring that probity obligations are met by the Australian Government. |
| Microsoft Priva | Detect the storage of sensitive information, including personal data in locations like OneDrive, and guide users around correct storage of information. |
| eDiscovery | Surface sensitive information as part of HR or FOI processes and apply holds to information that could be part of an active request or investigation. |
Content Explorer
Microsoft 365 content explorer enables your compliance, security, and privacy officers to get a quick but comprehensive insight into where sensitive information resides within a Microsoft 365 environment. This tool allows authorized users to browse locations and items by information type. The service indexes and surfaces items residing in Exchange, OneDrive, and SharePoint. Items located within Teams underlying SharePoint team sites are also visible.
Via this tool we can select a sensitive information type or sensitivity label, view the number of items that align with it across each of the Microsoft 365 services:
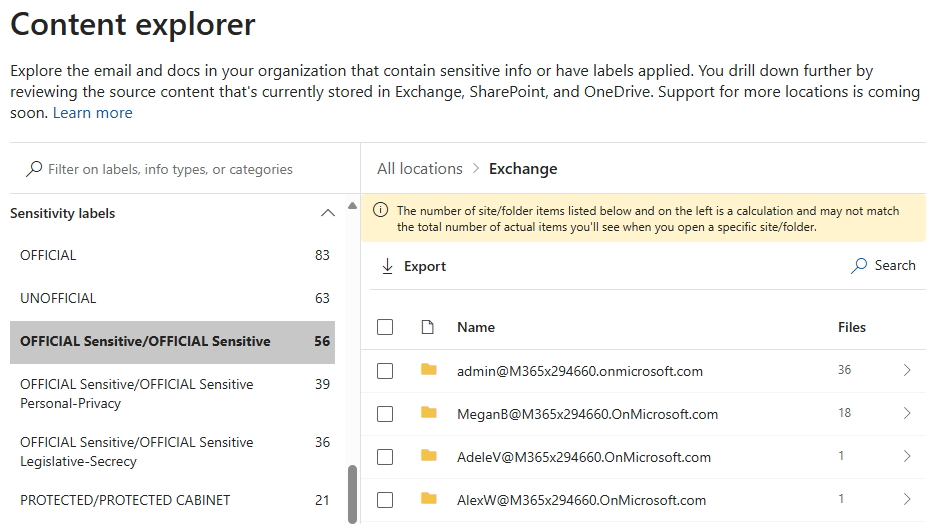
Content explorer can provide valuable insight into the locations where security classified or otherwise sensitive items reside across an environment. Such a consolidated view into the location of information is unlikely to be possible via on-premises systems.
For organizations who include labels that aren't permitted within the organization's account (for example, SECRET or TOP SECRET) along with associated auto-labeling policies to apply the labels, then content explorer can find information that shouldn't be stored on the platform. As content explorer can also surface SITs, a similar approach could be achieved via SITs to identify protective markings.
For more information on Content Explorer, see Get started with content explorer.