Intelligent applications
Applies to: ![]() Azure SQL Database
Azure SQL Database ![]() SQL database in Fabric
SQL database in Fabric
This article provides an overview of using artificial intelligence (AI) options, such as OpenAI and vectors, to build intelligent applications with Azure SQL Database and Fabric SQL database, which shares many of these features of Azure SQL Database.
For samples and examples, please visit the SQL AI Samples repository.
Watch this video in the Azure SQL Database essentials series for a brief overview of building an AI ready application:
Overview
Large language models (LLMs) enable developers to create AI-powered applications with a familiar user experience.
Using LLMs in applications brings greater value and an improved user experience when the models can access the right data, at the right time, from your application's database. This process is known as Retrieval Augmented Generation (RAG) and Azure SQL Database and Fabric SQL database have many features that support this new pattern, making it a great database to build intelligent applications.
The following links provide sample code of various options to build intelligent applications:
| AI Option | Description |
|---|---|
| Azure OpenAI | Generate embeddings for RAG and integrate with any model supported by Azure OpenAI. |
| Vectors | Learn how to store and query vectors the database. |
| Azure AI Search | Use your database together with Azure AI Search to train LLM on your data. |
| Intelligent applications | Learn how to create an end-to-end solution using a common pattern that can be replicated in any scenario. |
| Copilot skills in Azure SQL Database | Learn about the set of AI-assisted experiences designed to streamline the design, operation, optimization, and health of Azure SQL Database-driven applications. |
| Copilot skills in Fabric SQL database | Learn about the set of AI-assisted experiences designed to streamline the design, operation, optimization, and health of Fabric SQL database-driven applications. |
Key concepts for implementing RAG with Azure OpenAI
This section includes key concepts that are critical for implementing RAG with Azure OpenAI in Azure SQL Database or Fabric SQL database.
Retrieval Augmented Generation (RAG)
RAG is a technique that enhances the LLM's ability to produce relevant and informative responses by retrieving additional data from external sources. For example, RAG can query articles or documents that contain domain-specific knowledge related to the user's question or prompt. The LLM can then use this retrieved data as a reference when generating its response. For example, a simple RAG pattern using Azure SQL Database could be:
- Insert data into a table.
- Link Azure SQL Database to Azure AI Search.
- Create an Azure OpenAI GPT4 model and connect it to Azure AI Search.
- Chat and ask questions about your data using the trained Azure OpenAI model from your application and from Azure SQL Database.
The RAG pattern, with prompt engineering, serves the purpose of enhancing response quality by offering more contextual information to the model. RAG enables the model to apply a broader knowledgebase by incorporating relevant external sources into the generation process, resulting in more comprehensive and informed responses. For more information on grounding LLMs, see Grounding LLMs - Microsoft Community Hub.
Prompts and prompt engineering
A prompt refers to specific text or information that serves as an instruction to an LLM, or as contextual data that the LLM can build upon. A prompt can take various forms, such as a question, a statement, or even a code snippet.
Sample prompts that can be used to generate a response from an LLM:
- Instructions: provide directives to the LLM
- Primary content: gives information to the LLM for processing
- Examples: help condition the model to a particular task or process
- Cues: direct the LLM's output in the right direction
- Supporting content: represents supplemental information the LLM can use to generate output
The process of creating good prompts for a scenario is called prompt engineering. For more information about prompts and best practices for prompt engineering, see Azure OpenAI Service.
Tokens
Tokens are small chunks of text generated by splitting the input text into smaller segments. These segments can either be words or groups of characters, varying in length from a single character to an entire word. For instance, the word hamburger would be divided into tokens such as ham, bur, and ger while a short and common word like pear would be considered a single token.
In Azure OpenAI, input text provided to the API is turned into tokens (tokenized). The number of tokens processed in each API request depends on factors such as the length of the input, output, and request parameters. The quantity of tokens being processed also impacts the response time and throughput of the models. There are limits to the number of tokens each model can take in a single request/response from Azure OpenAI. To learn more, see Azure OpenAI Service quotas and limits.
Vectors
Vectors are ordered arrays of numbers (typically floats) that can represent information about some data. For example, an image can be represented as a vector of pixel values, or a string of text can be represented as a vector or ASCII values. The process to turn data into a vector is called vectorization. For more information, see Vectors.
Embeddings
Embeddings are vectors that represent important features of data. Embeddings are often learned by using a deep learning model, and machine learning and AI models utilize them as features. Embeddings can also capture semantic similarity between similar concepts. For example, in generating an embedding for the words person and human, we would expect their embeddings (vector representation) to be similar in value since the words are also semantically similar.
Azure OpenAI features models to create embeddings from text data. The service breaks text out into tokens and generates embeddings using models pretrained by OpenAI. To learn more, see Creating embeddings with Azure OpenAI.
Vector search
Vector search refers to the process of finding all vectors in a dataset that are semantically similar to a specific query vector. Therefore, a query vector for the word human searches the entire dictionary for semantically similar words, and should find the word person as a close match. This closeness, or distance, is measured using a similarity metric such as cosine similarity. The closer vectors are in similarity, the smaller is the distance between them.
Consider a scenario where you run a query over millions of document to find the most similar documents in your data. You can create embeddings for your data and query documents using Azure OpenAI. Then, you can perform a vector search to find the most similar documents from your dataset. However, performing a vector search across a few examples is trivial. Performing this same search across thousands, or millions, of data points becomes challenging. There are also trade-offs between exhaustive search and approximate nearest neighbor (ANN) search methods including latency, throughput, accuracy, and cost, all of which depends on the requirements of your application.
Vectors in Azure SQL Database can be efficiently stored and queried, as described in the next sections, allowing exact nearest neighbor search with great performance. You don't have to decide between accuracy and speed: you can have both. Storing vector embeddings alongside the data in an integrated solution minimizes the need to manage data synchronization and accelerates your time-to-market for AI application development.
Azure OpenAI
Embedding is the process of representing the real world as data. Text, images, or sounds can be converted into embeddings. Azure OpenAI models are able to transform real-world information into embeddings. The models are available as REST endpoints and thus can be easily consumed from Azure SQL Database using the sp_invoke_external_rest_endpoint system stored procedure:
DECLARE @retval INT, @response NVARCHAR(MAX);
DECLARE @payload NVARCHAR(MAX);
SET @payload = JSON_OBJECT('input': @text);
EXEC @retval = sp_invoke_external_rest_endpoint @url = 'https://<openai-url>/openai/deployments/<model-name>/embeddings?api-version=2023-03-15-preview',
@method = 'POST',
@credential = [https://<openai-url>/openai/deployments/<model-name>],
@payload = @payload,
@response = @response OUTPUT;
SELECT CAST([key] AS INT) AS [vector_value_id],
CAST([value] AS FLOAT) AS [vector_value]
FROM OPENJSON(JSON_QUERY(@response, '$.result.data[0].embedding'));
Using a call to a REST service to get embeddings is just one of the integration options you have when working with SQL Database and OpenAI. You can let any of the available models access data stored in Azure SQL Database to create solutions where your users can interact with the data, such as the following example.
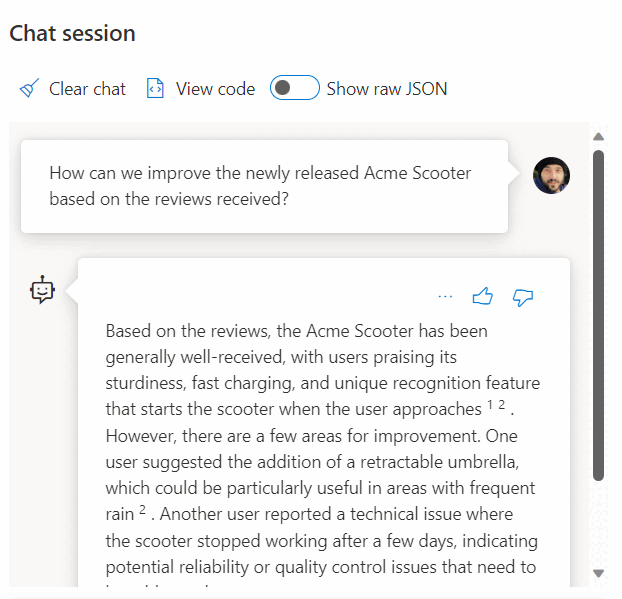
For additional examples on using SQL Database and OpenAI, see the following articles:
- Generate images with Azure OpenAI Service (DALL-E) and Azure SQL Database
- Using OpenAI REST Endpoints with Azure SQL Database
Vectors
Vector data type
In November 2024, the new vector data type was introduced in Azure SQL Database.
The dedicated vector type allows for efficient and optimized storing of vector data, and comes with a set of functions to help developers streamline vector and similarity search implementation. Calculating distance between two vectors can be done in one line of code using the new VECTOR_DISTANCE function. For more information on the vector data type and related functions, see Overview of vectors in the SQL Database Engine.
For example:
CREATE TABLE [dbo].[wikipedia_articles_embeddings_titles_vector]
(
[article_id] [int] NOT NULL,
[embedding] [vector](1536) NOT NULL,
)
GO
SELECT TOP(10)
*
FROM
[dbo].[wikipedia_articles_embeddings_titles_vector]
ORDER BY
VECTOR_DISTANCE('cosine', @my_reference_vector, embedding)
Vectors in older versions of SQL Server
While older versions of SQL Server engine, up to and including SQL Server 2022, doesn't have a native vector type, a vector is nothing more than an ordered tuple, and relational databases are great at managing tuples. You can think of a tuple as the formal term for a row in a table.
Azure SQL Database also supports columnstore indexes and batch mode execution. A vector-based approach is used for batch mode processing, which means that each column in a batch has its own memory location where it's stored as a vector. This allows for faster and more efficient processing of data in batches.
The following example shows how a vector can be stored in SQL Database:
CREATE TABLE [dbo].[wikipedia_articles_embeddings_titles_vector]
(
[article_id] [int] NOT NULL,
[vector_value_id] [int] NOT NULL,
[vector_value] [float] NOT NULL
)
GO
CREATE CLUSTERED COLUMNSTORE INDEX ixc
ON dbo.wikipedia_articles_embeddings_titles_vector
ORDER (article_id);
GO
For an example that uses a common subset of Wikipedia articles with embeddings already generated using OpenAI, see Vector similarity search with Azure SQL Database and OpenAI.
Another option for leveraging Vector Search in Azure SQL database is integration with Azure AI using the integrated vectorization capabilities: Vector Search with Azure SQL Database and Azure AI Search
Azure AI Search
Implement RAG-patterns with Azure SQL Database and Azure AI Search. You can run supported chat models on data stored in Azure SQL Database, without having to train or fine-tune models, thanks to the integration of Azure AI Search with Azure OpenAI and Azure SQL Database. Running models on your data enables you to chat on top of, and analyze, your data with greater accuracy and speed.
- Azure OpenAI on your data
- Retrieval Augmented Generation (RAG) in Azure AI Search
- Vector Search with Azure SQL Database and Azure AI Search
Intelligent applications
Azure SQL Database can be used to build intelligent applications that include AI features, such as recommenders, and Retrieval Augmented Generation (RAG) as the following diagram demonstrates:

For an end-to-end sample to build a AI-enabled application using sessions abstract as a sample dataset, see:
- How I built a session recommender in 1 hour using OpenAI.
- Using Retrieval Augmented Generation to build a conference session assistant
LangChain integration
LangChain is a well-known framework for developing applications powered by language models. For examples that show how LangChain can be used to create a Chatbot on your own data, see:
- Build a chatbot on your own data in 1 hour with Azure SQL, Langchain and Chainlit: Build a chatbot using the RAG pattern on your own data using Langchain for orchestrating LLM calls and Chainlit for the UI.
- Building your own DB Copilot for Azure SQL with Azure OpenAI GPT-4: Build a copilot-like experience to query your databases using natural language.
Semantic Kernel integration
Semantic Kernel is an open-source SDK that lets you easily build agents that can call your existing code. As a highly extensible SDK, you can use Semantic Kernel with models from OpenAI, Azure OpenAI, Hugging Face, and more! By combining your existing C#, Python, and Java code with these models, you can build agents that answer questions and automate processes.
- The ultimate chatbot?: Build a chatbot on your own data using both NL2SQL and RAG patterns for the ultimate user experience.
- OpenAI Embeddings Sample: An example that shows how to use Semantic Kernel and Kernel Memory to work with embeddings in a .NET application using SQL Server as Vector Database.
- Semantic Kernel & Kernel Memory - SQL Connector - Provides a connection to a SQL database for the Semantic Kernel for the memories.
Microsoft Copilot skills in Azure SQL Database
Microsoft Copilot skills in Azure SQL Database (preview) is a set of AI-assisted experiences designed to streamline the design, operation, optimization, and health of Azure SQL Database-driven applications. Copilot can improve productivity by offering natural language to SQL conversion and self-help for database administration.
Copilot provides relevant answers to user questions, simplifying database management by leveraging database context, documentation, dynamic management views, Query Store, and other knowledge sources. For example:
- Database administrators can independently manage databases and resolve issues, or learn more about the performance and capabilities of your database.
- Developers can ask questions about their data as they would in text or conversation to generate a T-SQL query. Developers can also learn to write queries faster through detailed explanations of the generated query.
Note
Microsoft Copilot skills in Azure SQL Database are currently in preview for a limited number of early adopters. To sign up for this program, visit Request Access to Copilot in Azure SQL Database: Preview.
The preview of Copilot for Azure SQL Database includes two Azure portal experiences:
| Portal location | Experiences |
|---|---|
| Azure portal Query Editor | Natural language to SQL: This experience within the Azure portal query editor for Azure SQL Database translates natural language queries into SQL, making database interactions more intuitive. For a tutorial and examples of natural language to SQL capabilities, see Natural language to SQL in the Azure portal Query editor (preview). |
| Microsoft Copilot for Azure | Azure Copilot integration: This experience adds Azure SQL skills into Microsoft Copilot for Azure, providing customers with self-guided assistance, empowering them to manage their databases and solve issues independently. |
For more information, see Frequently asked questions about Microsoft Copilot skills in Azure SQL Database (preview).
Microsoft Copilot skills in Fabric SQL database (preview)
Copilot for SQL database in Microsoft Fabric (preview) includes integrated AI assistance with the following features:
Code completion: Start writing T-SQL in the SQL query editor and Copilot will automatically generate a code suggestion to help complete your query. The Tab key accepts the code suggestion or keeps typing to ignore the suggestion.
Quick actions: In the ribbon of the SQL query editor, the Fix and Explain options are quick actions. Highlight a SQL query of your choice and select one of the quick action buttons to perform the selected action on your query.
Fix: Copilot can fix errors in your code as error messages arise. Error scenarios can include incorrect/unsupported T-SQL code, wrong spellings, and more. Copilot will also provide comments that explain the changes and suggest SQL best practices.
Explain: Copilot can provide natural language explanations of your SQL query and database schema in comments format.
Chat pane: Use the chat pane to ask questions to Copilot through natural language. Copilot responds with a generated SQL query or natural language based on the question asked.
Natural Language to SQL: Generate T-SQL code from plain text requests, and get suggestions of questions to ask to accelerate your workflow.
Document-based Q&A: Ask Copilot questions about general SQL database capabilities, and it responds in natural language. Copilot also helps find documentation related to your request.
Copilot for SQL database utilizes table and view names, column names, primary key, and foreign key metadata to generate T-SQL code. Copilot for SQL database does not use data in tables to generate T-SQL suggestions.