Εκμάθηση: Εντοπισμός σχέσεων στο σύνολο δεδομένων Synthea, με χρήση σημασιολογικής σύνδεσης
Αυτή η εκμάθηση παρουσιάζει τον τρόπο εντοπισμού σχέσεων στο δημόσιο τη Synthea σύνολο δεδομένων, χρησιμοποιώντας σύνδεση σημασιολογίας.
Όταν εργάζεστε με νέα δεδομένα ή εργάζεστε χωρίς υπάρχον μοντέλο δεδομένων, μπορεί να είναι χρήσιμο να ανακαλύψετε αυτόματα σχέσεις. Αυτός ο εντοπισμός σχέσεων μπορεί να σας βοηθήσει να κάνετε τα εξής:
- κατανόηση του μοντέλου σε υψηλό επίπεδο,
- αποκτήστε περισσότερες πληροφορίες κατά τη διάρκεια της διερευνητικής ανάλυσης δεδομένων,
- επικύρωση ενημερωμένων δεδομένων ή νέων, εισερχόμενων δεδομένων και
- την εκκαθάριση δεδομένων.
Ακόμη και αν οι σχέσεις είναι γνωστές εκ των προτέρων, η αναζήτηση σχέσεων μπορεί να βοηθήσει στην καλύτερη κατανόηση του μοντέλου δεδομένων ή στον προσδιορισμό προβλημάτων ποιότητας δεδομένων.
Σε αυτό το πρόγραμμα εκμάθησης, ξεκινάτε με ένα απλό παράδειγμα γραμμής βάσης, όπου πειραματίζεστε με μόνο τρεις πίνακες, έτσι ώστε να είναι εύκολο να ακολουθήσετε τις συνδέσεις μεταξύ τους. Στη συνέχεια, θα δείτε ένα πιο σύνθετο παράδειγμα με ένα μεγαλύτερο σύνολο πινάκων.
Σε αυτή την εκμάθηση, θα μάθετε πώς μπορείτε να κάνετε τα εξής:
- Χρησιμοποιήστε στοιχεία της βιβλιοθήκης Python της σημασιολογικής σύνδεσης (SemPy) που υποστηρίζουν ενοποίηση με το Power BI και βοηθούν στην αυτοματοποίηση της ανάλυσης δεδομένων. Αυτά τα στοιχεία περιλαμβάνουν:
- FabricDataFrame - μια δομή που μοιάζει με pandas ενισχυμένη με πρόσθετες σημασιολογικές πληροφορίες.
- Συναρτήσεις για την άντληση σημασιολογικών μοντέλων από έναν χώρο εργασίας Fabric στο σημειωματάριό σας.
- Συναρτήσεις που αυτοματοποιούν τον εντοπισμό και την απεικόνιση σχέσεων στα σημασιολογικά μοντέλα σας.
- Αντιμετώπιση προβλημάτων κατά τη διαδικασία εντοπισμού σχέσεων για σημασιολογικά μοντέλα με πολλούς πίνακες και αλληλεξαρτίες.
Προϋποθέσεις
Λάβετε μια συνδρομής Microsoft Fabric . Εναλλακτικά, εγγραφείτε για μια δωρεάν δοκιμαστική έκδοση microsoft Fabric.
Εισέλθετε για να το Microsoft Fabric.
Χρησιμοποιήστε την εναλλαγή εμπειρίας στην κάτω αριστερή πλευρά της αρχικής σελίδας σας για να μεταβείτε σε Fabric.

- Επιλέξτε χώροι εργασίας από το αριστερό παράθυρο περιήγησης για να βρείτε και να επιλέξετε τον χώρο εργασίας σας. Αυτός ο χώρος εργασίας γίνεται ο τρέχων χώρος εργασίας σας.
Ακολουθήστε τις οδηγίες στο σημειωματάριο
Το σημειωματάριο.ipynb
Για να ανοίξετε το σημειωματάριο που συνοδεύει αυτό το εκπαιδευτικό βοήθημα, ακολουθήστε τις οδηγίες στο Προετοιμασία του συστήματός σας για εκπαιδευτικά βοηθήματα επιστήμης δεδομένων, να εισαγάγετε το σημειωματάριο στον χώρο εργασίας σας.
Εάν προτιμάτε να αντιγράψετε και να επικολλήσετε τον κώδικα από αυτήν τη σελίδα, μπορείτε να δημιουργήσετε ένα νέο σημειωματάριο.
Βεβαιωθείτε ότι επισυνάψετε μια λίμνη στο σημειωματάριο προτού ξεκινήσετε την εκτέλεση κώδικα.
Ρύθμιση του σημειωματάριου
Σε αυτή την ενότητα, ρυθμίζετε ένα περιβάλλον σημειωματάριου με τις απαραίτητες λειτουργικές μονάδες και δεδομένα.
Εγκαταστήστε
SemPyαπό το PyPI χρησιμοποιώντας τη δυνατότητα εγκατάστασης%pipεντός του σημειωματάριου:%pip install semantic-linkΕκτελέστε τις απαραίτητες εισαγωγές λειτουργικών μονάδων SemPy που θα χρειαστείτε αργότερα:
import pandas as pd from sempy.samples import download_synthea from sempy.relationships import ( find_relationships, list_relationship_violations, plot_relationship_metadata )Εισαγάγετε pandas για την επιβολή μιας επιλογής ρύθμισης παραμέτρων που βοηθά με τη μορφοποίηση εξόδου:
import pandas as pd pd.set_option('display.max_colwidth', None)Τραβήξτε το δείγμα δεδομένων. Για αυτό το εκπαιδευτικό βοήθημα, χρησιμοποιείτε το Synthea σύνολο δεδομένων συνθετικών ιατρικών αρχείων (μικρή έκδοση για λόγους ευκολίας):
download_synthea(which='small')
Εντοπισμός σχέσεων σε ένα μικρό υποσύνολο πινάκων Synthea
Επιλέξτε τρεις πίνακες από ένα μεγαλύτερο σύνολο:
-
patientsκαθορίζει πληροφορίες ασθενών -
encountersκαθορίζει τους ασθενείς που είχαν ιατρικές συναντήσεις (για παράδειγμα, ιατρικό ραντεβού, διαδικασία) -
providersκαθορίζει ποιοι ιατρικοί πάροχοι παρακολούθησαν
Ο
encountersπίνακας επιλύει μια σχέση πολλά-προς-πολλά μεταξύpatientsκαιprovidersκαι μπορεί να περιγραφεί ως μια συσχετισμική οντότητα:patients = pd.read_csv('synthea/csv/patients.csv') providers = pd.read_csv('synthea/csv/providers.csv') encounters = pd.read_csv('synthea/csv/encounters.csv')-
Εύρεση σχέσεων μεταξύ των πινάκων χρησιμοποιώντας τη συνάρτηση
find_relationshipsτου SemPy:suggested_relationships = find_relationships([patients, providers, encounters]) suggested_relationshipsΑπεικονίστε τις σχέσεις DataFrame ως γράφημα, χρησιμοποιώντας τη
plot_relationship_metadataσυνάρτηση του SemPy.plot_relationship_metadata(suggested_relationships)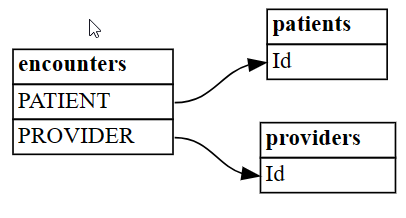
Η συνάρτηση καθορίζει την ιεραρχία σχέσεων από την αριστερή πλευρά προς τα δεξιά, η οποία αντιστοιχεί σε πίνακες "από" και "προς" στο αποτέλεσμα. Με άλλα λόγια, οι ανεξάρτητοι πίνακες "από" στην αριστερή πλευρά χρησιμοποιούν τα εξωτερικά κλειδιά τους για να υποδείίσουν τους πίνακες εξάρτησης "προς" στη δεξιά πλευρά. Κάθε πλαίσιο οντότητας εμφανίζει στήλες που συμμετέχουν είτε στην πλευρά "από" είτε στην πλευρά "προς" μιας σχέσης.
Από προεπιλογή, οι σχέσεις δημιουργούνται ως "m:1" (όχι ως "1:m") ή "1:1". Οι σχέσεις "1:1" μπορούν να δημιουργηθούν με έναν ή και τους δύο τρόπους, ανάλογα με το αν η αναλογία των αντιστοιχισμένων τιμών προς όλες τις τιμές υπερβαίνει
coverage_thresholdσε μία ή και στις δύο κατευθύνσεις. Παρακάτω σε αυτή την εκμάθηση, θα καλύψετε τις λιγότερο συχνές σχέσεις "m:m".

Αντιμετώπιση προβλημάτων εντοπισμού σχέσεων
Το παράδειγμα γραμμής βάσης εμφανίζει έναν επιτυχή εντοπισμό σχέσεων σε καθαρές δεδομένα Synthea. Στην πράξη, τα δεδομένα είναι σπάνια καθαρά, γεγονός που αποτρέπει τον επιτυχή εντοπισμό. Υπάρχουν διάφορες τεχνικές που μπορεί να είναι χρήσιμες όταν τα δεδομένα δεν είναι καθαρά.
Αυτή η ενότητα αυτού του προγράμματος εκμάθησης αντιμετωπίζει τον εντοπισμό σχέσεων όταν το μοντέλο σημασιολογίας περιέχει εσφαλμένα δεδομένα.
Ξεκινήστε με τον χειρισμό των αρχικών DataFrames για να λάβετε "βρώμικα" δεδομένα και εκτυπώστε το μέγεθος των βρώμικων δεδομένων.
# create a dirty 'patients' dataframe by dropping some rows using head() and duplicating some rows using concat() patients_dirty = pd.concat([patients.head(1000), patients.head(50)], axis=0) # create a dirty 'providers' dataframe by dropping some rows using head() providers_dirty = providers.head(5000) # the dirty dataframes have fewer records than the clean ones print(len(patients_dirty)) print(len(providers_dirty))Για λόγους σύγκρισης, τα μεγέθη εκτύπωσης των αρχικών πινάκων:
print(len(patients)) print(len(providers))Εύρεση σχέσεων μεταξύ των πινάκων χρησιμοποιώντας τη συνάρτηση
find_relationshipsτου SemPy:find_relationships([patients_dirty, providers_dirty, encounters])Το αποτέλεσμα του κώδικα δείχνει ότι δεν ανιχνεύονται σχέσεις λόγω των σφαλμάτων που εισαγάγατε νωρίτερα για να δημιουργήσετε το "βρώμικο" σημασιολογικό μοντέλο.
Χρήση επικύρωσης
Η επικύρωση είναι το καλύτερο εργαλείο για την αντιμετώπιση προβλημάτων αποτυχιών εντοπισμού σχέσεων καθώς:
- Αναφέρει σαφώς γιατί μια συγκεκριμένη σχέση δεν ακολουθεί τους κανόνες εξωτερικού κλειδιού και, επομένως, δεν μπορεί να εντοπιστεί.
- Εκτελείται γρήγορα με μεγάλα σημασιολογικά μοντέλα καθώς εστιάζει μόνο στις δηλωμένες σχέσεις και δεν εκτελεί αναζήτηση.
Η επικύρωση μπορεί να χρησιμοποιήσει οποιοδήποτε DataFrame με στήλες παρόμοιες με αυτές που δημιουργήθηκαν από find_relationships. Στον παρακάτω κώδικα, το suggested_relationships DataFrame αναφέρεται σε patients αντί για patients_dirty, αλλά μπορείτε να προσθέσετε ψευδώνυμο στα DataFrames με ένα λεξικό:
dirty_tables = {
"patients": patients_dirty,
"providers" : providers_dirty,
"encounters": encounters
}
errors = list_relationship_violations(dirty_tables, suggested_relationships)
errors
Χαλαρώνει τα κριτήρια αναζήτησης
Σε πιο ασαφή σενάρια, μπορείτε να δοκιμάσετε να χαλαρώσετε τα κριτήρια αναζήτησής σας. Αυτή η μέθοδος αυξάνει την πιθανότητα ψευδώς θετικών στοιχείων.
Ορίστε
include_many_to_many=Trueκαι αξιολογήστε εάν βοηθά:find_relationships(dirty_tables, include_many_to_many=True, coverage_threshold=1)Τα αποτελέσματα δείχνουν ότι εντοπίστηκε η σχέση από
encountersσεpatients, αλλά υπάρχουν δύο προβλήματα:- Η σχέση υποδεικνύει μια κατεύθυνση από
patientsέωςencounters, το οποίο είναι ένα αντίστροφο της αναμενόμενης σχέσης. Αυτό συμβαίνει γιατί όλαpatientsέτυχε να καλύπτονται απόencounters(Coverage Fromείναι 1,0), ενώencountersκαλύπτονται μόνο εν μέρει απόpatients(Coverage To= 0,85), δεδομένου ότι λείπουν γραμμές ασθενών. - Υπάρχει μια τυχαία αντιστοίχιση σε μια στήλη
GENDERχαμηλή πληθικότητα, η οποία τυχαίνει να συμφωνεί με το όνομα και την τιμή και στους δύο πίνακες, αλλά δεν είναι μια σχέση ενδιαφέροντος "μ:1". Η χαμηλή πληθικότητα υποδεικνύεται απόUnique Count FromκαιUnique Count Toστήλες.
- Η σχέση υποδεικνύει μια κατεύθυνση από
Επαναλάβετε
find_relationshipsγια να αναζητήσετε μόνο σχέσεις "m:1", αλλά με χαμηλότεροcoverage_threshold=0.5:find_relationships(dirty_tables, include_many_to_many=False, coverage_threshold=0.5)Το αποτέλεσμα εμφανίζει τη σωστή κατεύθυνση των σχέσεων από
encountersέωςproviders. Ωστόσο, η σχέση απόencountersσεpatientsδεν ανιχνεύεται, επειδήpatientsδεν είναι μοναδική, επομένως δεν μπορεί να βρίσκεται στην πλευρά "Ένα" της σχέσης "m:1".Χαλαρώστε τόσο
include_many_to_many=Trueόσο καιcoverage_threshold=0.5:find_relationships(dirty_tables, include_many_to_many=True, coverage_threshold=0.5)Τώρα και οι δύο σχέσεις ενδιαφέροντος είναι ορατές, αλλά υπάρχει πολύ περισσότερος θόρυβος:
- Η αντιστοίχιση χαμηλής πληθικότητας στην
GENDERυπάρχει. - Εμφανίστηκε μια συμφωνία υψηλότερης πληθικότητας "m:m" στον
ORGANIZATION, καθιστώντας προφανές ότιORGANIZATIONείναι πιθανό μια στήλη να μην κανονικοποιείται και στους δύο πίνακες.
- Η αντιστοίχιση χαμηλής πληθικότητας στην
Αντιστοίχιση ονομάτων στηλών
Από προεπιλογή, το SemPy θεωρεί ότι συμφωνεί μόνο με χαρακτηριστικά που εμφανίζουν ομοιότητα ονόματος, εκμεταλλευόμενοι το γεγονός ότι οι σχεδιαστές βάσεων δεδομένων συνήθως ονομάζουν τις σχετικές στήλες με τον ίδιο τρόπο. Αυτή η συμπεριφορά βοηθά στην αποφυγή ψευδών σχέσεων, οι οποίες εμφανίζονται συχνότερα με ακέραια κλειδιά χαμηλής πληθικότητας. Για παράδειγμα, εάν υπάρχουν 1,2,3,...,10 κατηγορίες προϊόντων και 1,2,3,...,10 κωδικό κατάστασης παραγγελίας, θα συγχέονται μεταξύ τους όταν εξετάζουν μόνο αντιστοιχίσεις τιμών χωρίς να λαμβάνονται υπόψη τα ονόματα στηλών. Οι ψευδείς σχέσεις δεν πρέπει να αποτελούν πρόβλημα με κλειδιά τύπου GUID.
Η SemPy εξετάζει μια ομοιότητα μεταξύ των ονομάτων στηλών και των ονομάτων πινάκων. Η αντιστοίχιση είναι κατά προσέγγιση και δεν κάνει διάκριση πεζών-κεφαλαίων. Αγνοεί τις δευτερεύουσες συμβολοσειρές "decorator" που χρησιμοποιούνται συχνότερα, όπως "id", "code", "name", "key", "pk", "fk". Κατά συνέπεια, οι πιο τυπικές περιπτώσεις αντιστοίχισης είναι οι εξής:
- ένα χαρακτηριστικό που ονομάζεται "στήλη" στην οντότητα "foo" συμφωνεί με ένα χαρακτηριστικό που ονομάζεται "στήλη" (επίσης "COLUMN" ή "Column") στην οντότητα "bar".
- ένα χαρακτηριστικό που ονομάζεται "στήλη" στην οντότητα "foo" συμφωνεί με ένα χαρακτηριστικό που ονομάζεται "column_id" στο "bar".
- ένα χαρακτηριστικό που ονομάζεται "ράβδος" στην οντότητα "foo" συμφωνεί με ένα χαρακτηριστικό που ονομάζεται "κώδικας" στη "γραμμή".
Αντιστοιχίζοντας πρώτα τα ονόματα στηλών, ο εντοπισμός εκτελείται ταχύτερα.
Ταιριάξτε τα ονόματα των στηλών:
- Για να κατανοήσετε ποιες στήλες επιλέγονται για περαιτέρω αξιολόγηση, χρησιμοποιήστε την επιλογή
verbose=2(verbose=1παραθέτει μόνο τις οντότητες που υποβάλλονται σε επεξεργασία). - Η παράμετρος
name_similarity_thresholdκαθορίζει τον τρόπο σύγκρισης των στηλών. Το όριο 1 υποδεικνύει ότι σας ενδιαφέρουν 100% αγώνας μόνο.
find_relationships(dirty_tables, verbose=2, name_similarity_threshold=1.0);Αν εκτελείται στα 100% ομοιότητα δεν λαμβάνει υπόψη τις μικρές διαφορές μεταξύ των ονομάτων. Στο παράδειγμά σας, οι πίνακες έχουν μια μορφή πληθυντικού με επίθημα "s", το οποίο δεν έχει ως αποτέλεσμα ακριβή συμφωνία. Αυτό αντιμετωπίζεται καλά με την προεπιλεγμένη
name_similarity_threshold=0.8.- Για να κατανοήσετε ποιες στήλες επιλέγονται για περαιτέρω αξιολόγηση, χρησιμοποιήστε την επιλογή
Επαναλάβετε την εκτέλεση με την προεπιλεγμένη
name_similarity_threshold=0.8:find_relationships(dirty_tables, verbose=2, name_similarity_threshold=0.8);Παρατηρήστε ότι το αναγνωριστικό για τη μορφή πληθυντικού
patientsσυγκρίνεται τώρα με τον ενικόpatientχωρίς να προστίθεται πάρα πολλές άλλες ψευδείς συγκρίσεις στον χρόνο εκτέλεσης.Επαναλάβετε την εκτέλεση με την προεπιλεγμένη
name_similarity_threshold=0:find_relationships(dirty_tables, verbose=2, name_similarity_threshold=0);Η αλλαγή
name_similarity_thresholdσε 0 είναι το άλλο άκρο και υποδεικνύει ότι θέλετε να συγκρίνετε όλες τις στήλες. Αυτό είναι σπανίως απαραίτητο και έχει ως αποτέλεσμα αυξημένο χρόνο εκτέλεσης και ψευδείς αντιστοιχίες που πρέπει να εξεταστούν. Παρατηρήστε τον αριθμό συγκρίσεων στην λεπτομερή έξοδο.
Σύνοψη των συμβουλών αντιμετώπισης προβλημάτων
- Ξεκινήστε από την ακριβή συμφωνία για σχέσεις "m:1" (δηλαδή, την προεπιλεγμένη
include_many_to_many=Falseκαιcoverage_threshold=1.0). Συνήθως αυτό είναι που θέλετε. - Χρησιμοποιήστε μια στενή εστίαση σε μικρότερα υποσύνολα πινάκων.
- Χρησιμοποιήστε την επικύρωση για να εντοπίσετε προβλήματα ποιότητας δεδομένων.
- Χρησιμοποιήστε
verbose=2εάν θέλετε να κατανοήσετε ποιες στήλες λαμβάνονται υπόψη για σχέση. Αυτό μπορεί να οδηγήσει σε μεγάλη ποσότητα εξόδου. - Να γνωρίζετε τις αντιδικίες των ορισμάτων αναζήτησης.
include_many_to_many=Trueκαιcoverage_threshold<1.0μπορεί να παράγουν ψευδείς σχέσεις που μπορεί να είναι πιο δύσκολο να αναλυθούν και θα χρειαστεί να φιλτραριστούν.
Εντοπισμός σχέσεων στο πλήρες σύνολο δεδομένων Synthea
Το απλό παράδειγμα γραμμής βάσης ήταν ένα εύχρηστο εργαλείο εκμάθησης και αντιμετώπισης προβλημάτων. Στην πράξη, μπορείτε να ξεκινήσετε από ένα σημασιολογικό μοντέλο, όπως το πλήρες Synthea σύνολο δεδομένων, το οποίο έχει πολύ περισσότερους πίνακες. Εξερευνήστε την πλήρη synthea σύνολο δεδομένων ως εξής.
Ανάγνωση όλων των αρχείων από τον κατάλογο synthea/csv του
: all_tables = { "allergies": pd.read_csv('synthea/csv/allergies.csv'), "careplans": pd.read_csv('synthea/csv/careplans.csv'), "conditions": pd.read_csv('synthea/csv/conditions.csv'), "devices": pd.read_csv('synthea/csv/devices.csv'), "encounters": pd.read_csv('synthea/csv/encounters.csv'), "imaging_studies": pd.read_csv('synthea/csv/imaging_studies.csv'), "immunizations": pd.read_csv('synthea/csv/immunizations.csv'), "medications": pd.read_csv('synthea/csv/medications.csv'), "observations": pd.read_csv('synthea/csv/observations.csv'), "organizations": pd.read_csv('synthea/csv/organizations.csv'), "patients": pd.read_csv('synthea/csv/patients.csv'), "payer_transitions": pd.read_csv('synthea/csv/payer_transitions.csv'), "payers": pd.read_csv('synthea/csv/payers.csv'), "procedures": pd.read_csv('synthea/csv/procedures.csv'), "providers": pd.read_csv('synthea/csv/providers.csv'), "supplies": pd.read_csv('synthea/csv/supplies.csv'), }Εύρεση σχέσεων μεταξύ των πινάκων, χρησιμοποιώντας τη συνάρτηση
find_relationshipsτου SemPy:suggested_relationships = find_relationships(all_tables) suggested_relationshipsΑπεικόνιση σχέσεων:
plot_relationship_metadata(suggested_relationships)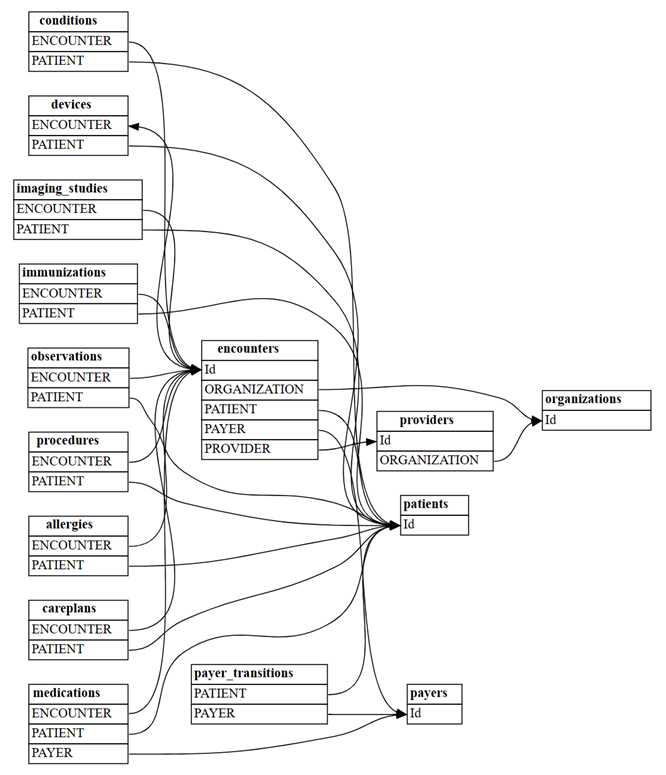
Μετρήστε πόσες νέες σχέσεις "m:m" θα εντοπιστούν με
include_many_to_many=True. Αυτές οι σχέσεις είναι επιπλέον των σχέσεων που εμφανίζονται προηγουμένως "m:1". Επομένως, πρέπει να φιλτράρετε με βάσηmultiplicity:suggested_relationships = find_relationships(all_tables, coverage_threshold=1.0, include_many_to_many=True) suggested_relationships[suggested_relationships['Multiplicity']=='m:m']Μπορείτε να ταξινομήσετε τα δεδομένα σχέσης κατά διάφορες στήλες για να κατανοήσετε βαθύτερα τη φύση τους. Για παράδειγμα, μπορείτε να επιλέξετε να παραγγείλετε την έξοδο κατά
Row Count FromκαιRow Count To, που βοηθούν στον προσδιορισμό των μεγαλύτερων πινάκων.suggested_relationships.sort_values(['Row Count From', 'Row Count To'], ascending=False)Σε ένα διαφορετικό μοντέλο σημασιολογίας, ίσως θα ήταν σημαντικό να εστιάσετε στον αριθμό των null
Null Count FromήCoverage To.Αυτή η ανάλυση μπορεί να σας βοηθήσει να κατανοήσετε εάν οποιαδήποτε από τις σχέσεις μπορεί να μην είναι έγκυρη και εάν χρειάζεται να τις καταργήσετε από τη λίστα υποψηφίων.

Σχετικό περιεχόμενο
Δείτε άλλα προγράμματα εκμάθησης για τη σημασιολογική σύνδεση / SemPy:
- Εκμάθηση : Καθαρισμός δεδομένων με λειτουργικές εξαρτήσεις
- Εκμάθηση : Ανάλυση λειτουργικών εξαρτήσεων σε ένα δείγμα μοντέλου σημασιολογίας
- Εκμάθηση : Εντοπισμός σχέσεων σε ένα μοντέλο σημασιολογίας, χρησιμοποιώντας σημασιολογική σύνδεση
- Εκμάθηση : Εξαγωγή και υπολογισμός μετρήσεων Power BI από ένα σημειωματάριο Jupyter