Εκμάθηση: Εντοπισμός σχέσεων σε ένα μοντέλο σημασιολογίας, με χρήση σημασιολογικής σύνδεσης
Αυτή η εκμάθηση παρουσιάζει τον τρόπο αλληλεπίδρασης με το Power BI από ένα σημειωματάριο Jupyter και τον εντοπισμό σχέσεων μεταξύ πινάκων με τη βοήθεια της βιβλιοθήκης SemPy.
Σε αυτή την εκμάθηση, θα μάθετε πώς μπορείτε να κάνετε τα εξής:
- Ανακαλύψτε σχέσεις σε ένα σημασιολογικό μοντέλο (σύνολο δεδομένων Power BI), χρησιμοποιώντας τη βιβλιοθήκη Python της σημασιολογικής σύνδεσης (SemPy).
- Χρησιμοποιήστε στοιχεία του SemPy που υποστηρίζουν ενοποίηση με το Power BI και βοηθούν στην αυτοματοποίηση της ανάλυσης ποιότητας των δεδομένων. Αυτά τα στοιχεία περιλαμβάνουν:
- FabricDataFrame - μια δομή που μοιάζει με pandas ενισχυμένη με πρόσθετες σημασιολογικές πληροφορίες.
- Συναρτήσεις για την άντληση σημασιολογικών μοντέλων από έναν χώρο εργασίας Fabric στο σημειωματάριό σας.
- Συναρτήσεις που αυτοματοποιούν την αξιολόγηση υποθέσεων σχετικά με λειτουργικές εξαρτήσεις και που εντοπίζουν παραβιάσεις σχέσεων στα σημασιολογικά μοντέλα σας.
Προϋποθέσεις
Λάβετε μια συνδρομής Microsoft Fabric . Εναλλακτικά, εγγραφείτε για μια δωρεάν δοκιμαστική έκδοση microsoft Fabric.
Εισέλθετε για να το Microsoft Fabric.
Χρησιμοποιήστε την εναλλαγή εμπειρίας στην κάτω αριστερή πλευρά της αρχικής σελίδας σας για να μεταβείτε σε Fabric.

Επιλέξτε χώροι εργασίας από το αριστερό παράθυρο περιήγησης για να βρείτε και να επιλέξετε τον χώρο εργασίας σας. Αυτός ο χώρος εργασίας γίνεται ο τρέχων χώρος εργασίας σας.
Κάντε λήψη του Customer Profitability Sample.pbix και Customer Profitability Sample (auto).pbix σημασιολογικά μοντέλα από δείγματα υφάσματος αποθετήριο GitHub και στείλτε τα στον χώρο εργασίας σας.
Ακολουθήστε τις οδηγίες στο σημειωματάριο
Το σημειωματάριο
Για να ανοίξετε το σημειωματάριο που συνοδεύει αυτό το εκπαιδευτικό βοήθημα, ακολουθήστε τις οδηγίες στο Προετοιμασία του συστήματός σας για εκπαιδευτικά βοηθήματα επιστήμης δεδομένων, να εισαγάγετε το σημειωματάριο στον χώρο εργασίας σας.
Εάν προτιμάτε να αντιγράψετε και να επικολλήσετε τον κώδικα από αυτήν τη σελίδα, μπορείτε να δημιουργήσετε ένα νέο σημειωματάριο.
Βεβαιωθείτε ότι επισυνάψετε μια λίμνη στο σημειωματάριο προτού ξεκινήσετε την εκτέλεση κώδικα.
Ρύθμιση του σημειωματάριου
Σε αυτή την ενότητα, ρυθμίζετε ένα περιβάλλον σημειωματάριου με τις απαραίτητες λειτουργικές μονάδες και δεδομένα.
Εγκαταστήστε
SemPyαπό το PyPI χρησιμοποιώντας τη δυνατότητα εγκατάστασης%pipεντός του σημειωματάριου:%pip install semantic-linkΕκτελέστε τις απαραίτητες εισαγωγές λειτουργικών μονάδων SemPy που θα χρειαστείτε αργότερα:
import sempy.fabric as fabric from sempy.relationships import plot_relationship_metadata from sempy.relationships import find_relationships from sempy.fabric import list_relationship_violationsΕισαγάγετε pandas για την επιβολή μιας επιλογής ρύθμισης παραμέτρων που βοηθά με τη μορφοποίηση εξόδου:
import pandas as pd pd.set_option('display.max_colwidth', None)
Εξερεύνηση σημασιολογικών μοντέλων
Αυτό το εκπαιδευτικό βοήθημα χρησιμοποιεί ένα τυπικό δείγμα σημασιολογικού μοντέλου δείγμα κερδοφορίας πελάτη.pbix. Για μια περιγραφή του μοντέλου σημασιολογίας, ανατρέξτε στο θέμα δείγμα κερδοφορίας πελάτη για το Power BI.
Χρησιμοποιήστε τη συνάρτηση
list_datasetsτου SemPy για να εξερευνήσετε σημασιολογικά μοντέλα στον τρέχοντα χώρο εργασίας σας:fabric.list_datasets()
Για το υπόλοιπο αυτού του σημειωματάριου χρησιμοποιείτε δύο εκδόσεις του σημασιολογικού μοντέλου δείγματος κερδοφορίας πελάτη:
- δείγμα κερδοφορίας πελάτη: το σημασιολογικό μοντέλο όπως προέρχεται από δείγματα Power BI με προκαθορισμένες σχέσεις πινάκων
- Δείγμα κερδοφορίας πελάτη (αυτόματο): τα ίδια δεδομένα, αλλά οι σχέσεις περιορίζονται σε εκείνες που θα έκανε αυτόματο εντοπισμό το Power BI.
Εξαγωγή δείγματος σημασιολογικού μοντέλου με το προκαθορισμένο σημασιολογικό μοντέλο του
Οι σχέσεις φόρτωσης που έχουν προκαθοριστεί και αποθηκευτεί στο Δείγμα κερδοφορίας πελάτη σημασιολογικό μοντέλο, χρησιμοποιώντας τη συνάρτηση
list_relationshipsτου SemPy. Αυτή η συνάρτηση παραθέτει από το Μοντέλο αντικειμένου σε μορφή πίνακα:dataset = "Customer Profitability Sample" relationships = fabric.list_relationships(dataset) relationshipsΑπεικονίστε το
relationshipsDataFrame ως γράφημα, χρησιμοποιώντας τη συνάρτησηplot_relationship_metadataτου SemPy:plot_relationship_metadata(relationships)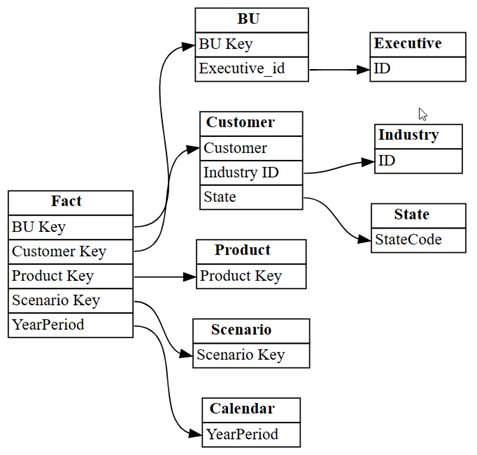

Αυτό το γράφημα δείχνει την "αλήθεια του εδάφους" για τις σχέσεις μεταξύ πινάκων σε αυτό το σημασιολογικό μοντέλο, καθώς αντικατοπτρίζει τον τρόπο με τον οποίο ορίστηκαν στο Power BI από έναν ειδικό επί του θέματος.
Συμπλήρωση ανακάλυψης σχέσεων
Εάν ξεκινήσατε με σχέσεις που ανιχνεύονται αυτόματα από το Power BI, θα έχετε ένα μικρότερο σύνολο.
Απεικονίστε τις σχέσεις που το Power BI ανιχνεύθηκε αυτόματα στο μοντέλο σημασιολογίας:
dataset = "Customer Profitability Sample (auto)" autodetected = fabric.list_relationships(dataset) plot_relationship_metadata(autodetected)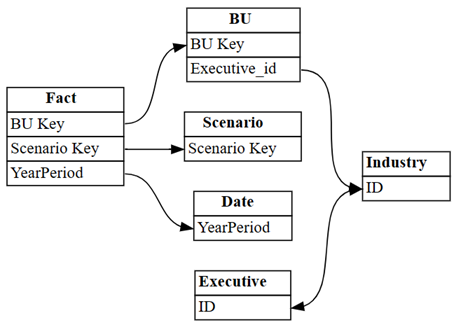
Η αυτόματη εντοπισμός του Power BI έχασε πολλές σχέσεις. Επιπλέον, δύο από τις σχέσεις που ανιχνεύονται αυτόματα είναι σημαντιολογικά λανθασμένες:
-
Executive[ID]->Industry[ID] -
BU[Executive_id]->Industry[ID]
-
Εκτυπώστε τις σχέσεις ως πίνακα:
autodetectedΟι λανθασμένες σχέσεις με τον
Industryπίνακα εμφανίζονται σε γραμμές με ευρετήριο 3 και 4. Χρησιμοποιήστε αυτές τις πληροφορίες για να καταργήσετε αυτές τις γραμμές.Απορρίψτε τις σχέσεις που έχουν προσδιοριστεί εσφαλμένα.
autodetected.drop(index=[3,4], inplace=True) autodetectedΤώρα έχετε σωστές, αλλά ελλιπείς σχέσεις.
Απεικονίστε αυτές τις ελλιπείς σχέσεις, χρησιμοποιώντας
plot_relationship_metadata:plot_relationship_metadata(autodetected)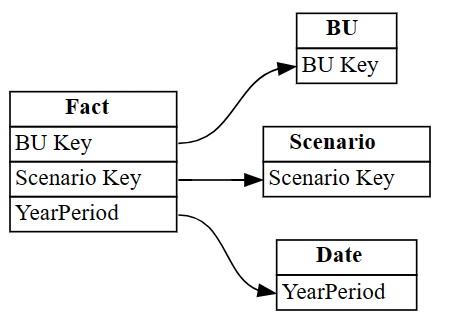
Φορτώστε όλους τους πίνακες από το μοντέλο σημασιολογίας, χρησιμοποιώντας τις συναρτήσεις
list_tablesκαιread_tableτου SemPy:tables = {table: fabric.read_table(dataset, table) for table in fabric.list_tables(dataset)['Name']} tables.keys()Βρείτε σχέσεις μεταξύ πινάκων, χρησιμοποιώντας
find_relationshipsκαι εξετάστε την έξοδο αρχείου καταγραφής για να λάβετε ορισμένες πληροφορίες σχετικά με τον τρόπο λειτουργίας αυτής της συνάρτησης:suggested_relationships_all = find_relationships( tables, name_similarity_threshold=0.7, coverage_threshold=0.7, verbose=2 )Απεικόνιση σχέσεων που ανακαλύφθηκαν πρόσφατα:
plot_relationship_metadata(suggested_relationships_all)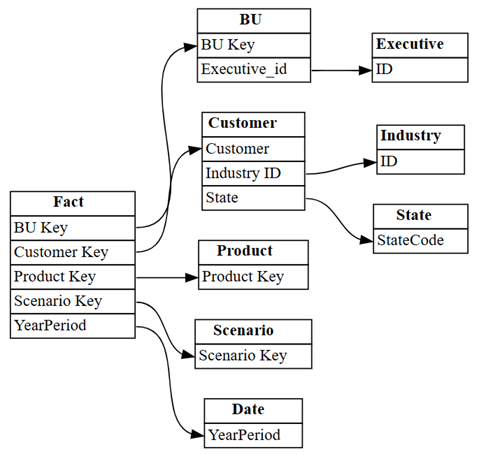
Το SemPy μπόρεσε να εντοπίσει όλες τις σχέσεις.
Χρησιμοποιήστε την παράμετρο
excludeγια να περιορίσετε την αναζήτηση σε πρόσθετες σχέσεις που δεν αναγνωρίστηκαν προηγουμένως:additional_relationships = find_relationships( tables, exclude=autodetected, name_similarity_threshold=0.7, coverage_threshold=0.7 ) additional_relationships



Επικύρωση των σχέσεων
Πρώτα, φορτώστε τα δεδομένα από το δείγμα κερδοφορίας πελάτη σημασιολογικό μοντέλο:
dataset = "Customer Profitability Sample" tables = {table: fabric.read_table(dataset, table) for table in fabric.list_tables(dataset)['Name']} tables.keys()Ελέγξτε για επικάλυψη των τιμών πρωτεύοντος και εξωτερικού κλειδιού χρησιμοποιώντας τη συνάρτηση
list_relationship_violations. Παρέχετε την έξοδο της συνάρτησηςlist_relationshipsως είσοδο γιαlist_relationship_violations:list_relationship_violations(tables, fabric.list_relationships(dataset))Οι παραβιάσεις των σχέσεων παρέχουν ορισμένες ενδιαφέρουσες πληροφορίες. Για παράδειγμα, μία από τις επτά τιμές σε
Fact[Product Key]δεν υπάρχει στοProduct[Product Key]και αυτό το κλειδί που λείπει είναι50.
Η διερευνητική ανάλυση δεδομένων είναι μια συναρπαστική διαδικασία, το ίδιο και η εκκαθάριση δεδομένων. Πάντα υπάρχει κάτι που κρύβεται από τα δεδομένα, ανάλογα με το πώς τα βλέπετε, τι θέλετε να ρωτήσετε και ούτω καθεξής. Η Σύνδεση σημασιολογίας σάς παρέχει νέα εργαλεία που μπορείτε να χρησιμοποιήσετε για να επιτύχετε περισσότερα με τα δεδομένα σας.
Σχετικό περιεχόμενο
Δείτε άλλα προγράμματα εκμάθησης για τη σημασιολογική σύνδεση / SemPy:
- Εκμάθηση : Καθαρισμός δεδομένων με λειτουργικές εξαρτήσεις
- Εκμάθηση : Ανάλυση λειτουργικών εξαρτήσεων σε ένα δείγμα μοντέλου σημασιολογίας
- Εκμάθηση : Εξαγωγή και υπολογισμός μετρήσεων Power BI από ένα σημειωματάριο Jupyter
- Εκμάθηση : Εντοπισμός σχέσεων στο σύνολο δεδομένων Synthea, με χρήση σύνδεσης σημασιολογίας
- Εκμάθηση : Επικύρωση δεδομένων με χρήση των SemPy και Μεγάλων προσδοκιών (GX)