Εκμάθηση: Εκκαθάριση δεδομένων με λειτουργικές εξαρτήσεις
Σε αυτό το πρόγραμμα εκμάθησης, χρησιμοποιείτε λειτουργικές εξαρτήσεις για την εκκαθάριση δεδομένων. Υπάρχει μια λειτουργική εξάρτηση όταν μία στήλη σε ένα μοντέλο σημασιολογίας (ένα σύνολο δεδομένων Power BI) είναι συνάρτηση μιας άλλης στήλης. Για παράδειγμα, μια στήλη
Σε αυτή την εκμάθηση, θα μάθετε πώς μπορείτε να κάνετε τα εξής:
- Εφαρμόστε γνώσεις τομέα σε υποθέσεις τύπων σχετικά με λειτουργικές εξαρτήσεις σε ένα μοντέλο σημασιολογίας.
- Εξοικειωθείτε με τα στοιχεία της βιβλιοθήκης Python της σημασιολογικής σύνδεσης (SemPy) που βοηθούν στην αυτοματοποίηση της ανάλυσης ποιότητας των δεδομένων. Αυτά τα στοιχεία περιλαμβάνουν:
- FabricDataFrame - μια δομή που μοιάζει με pandas ενισχυμένη με πρόσθετες σημασιολογικές πληροφορίες.
- Χρήσιμες συναρτήσεις που αυτοματοποιούν την αξιολόγηση υποθέσεων σχετικά με λειτουργικές εξαρτήσεις και που αναγνωρίζουν παραβιάσεις των σχέσεων στα σημασιολογικά μοντέλα σας.
Προϋποθέσεις
Λάβετε μια συνδρομής Microsoft Fabric . Εναλλακτικά, εγγραφείτε για μια δωρεάν δοκιμαστική έκδοση microsoft Fabric.
Εισέλθετε για να το Microsoft Fabric.
Χρησιμοποιήστε την εναλλαγή εμπειρίας στην κάτω αριστερή πλευρά της αρχικής σελίδας σας για να μεταβείτε σε Fabric.

- Επιλέξτε χώροι εργασίας από το αριστερό παράθυρο περιήγησης για να βρείτε και να επιλέξετε τον χώρο εργασίας σας. Αυτός ο χώρος εργασίας γίνεται ο τρέχων χώρος εργασίας σας.
Ακολουθήστε τις οδηγίες στο σημειωματάριο
Το σημειωματάριο.ipynb του
Για να ανοίξετε το σημειωματάριο που συνοδεύει αυτό το εκπαιδευτικό βοήθημα, ακολουθήστε τις οδηγίες στο Προετοιμασία του συστήματός σας για εκπαιδευτικά βοηθήματα επιστήμης δεδομένων, να εισαγάγετε το σημειωματάριο στον χώρο εργασίας σας.
Εάν προτιμάτε να αντιγράψετε και να επικολλήσετε τον κώδικα από αυτήν τη σελίδα, μπορείτε να δημιουργήσετε ένα νέο σημειωματάριο.
Βεβαιωθείτε ότι επισυνάψετε μια λίμνη στο σημειωματάριο προτού ξεκινήσετε την εκτέλεση κώδικα.
Ρύθμιση του σημειωματάριου
Σε αυτή την ενότητα, ρυθμίζετε ένα περιβάλλον σημειωματάριου με τις απαραίτητες λειτουργικές μονάδες και δεδομένα.
- Για το Spark 3.4 και νεότερες εκδόσεις, η Σύνδεση σημασιολογίας είναι διαθέσιμη στον προεπιλεγμένο χρόνο εκτέλεσης όταν χρησιμοποιείτε το Fabric και δεν χρειάζεται να την εγκαταστήσετε. Εάν χρησιμοποιείτε το Spark 3.3 ή παρακάτω ή εάν θέλετε να ενημερώσετε την πιο πρόσφατη έκδοση της Σημασιολογικής σύνδεσης, μπορείτε να εκτελέσετε την εντολή:
python %pip install -U semantic-link
Εκτελέστε τις απαραίτητες εισαγωγές λειτουργικών μονάδων που θα χρειαστείτε αργότερα:
import pandas as pd import sempy.fabric as fabric from sempy.fabric import FabricDataFrame from sempy.dependencies import plot_dependency_metadata from sempy.samples import download_syntheaΤραβήξτε το δείγμα δεδομένων. Για αυτό το εκπαιδευτικό βοήθημα, χρησιμοποιείτε το Synthea σύνολο δεδομένων συνθετικών ιατρικών αρχείων (μικρή έκδοση για λόγους ευκολίας):
download_synthea(which='small')
Εξερεύνηση των δεδομένων
Προετοιμάστε ένα
FabricDataFrameμε το περιεχόμενο του αρχείου providers.csv:providers = FabricDataFrame(pd.read_csv("synthea/csv/providers.csv")) providers.head()Ελέγξτε για προβλήματα ποιότητας δεδομένων με τη συνάρτηση
find_dependenciesτου SemPy σχεδιάζοντας ένα γράφημα των αυτόματων λειτουργικών εξαρτήσεων:deps = providers.find_dependencies() plot_dependency_metadata(deps)
Το γράφημα των λειτουργικών εξαρτήσεων δείχνει ότι
IdπροσδιορίζειNAMEκαιORGANIZATION(υποδεικνύονται από τα συμπαγή βέλη), κάτι που αναμένεται, δεδομένου ότιIdείναι μοναδικό:Επιβεβαιώστε ότι
Idείναι μοναδική:providers.Id.is_uniqueΟ κώδικας επιστρέφει
Trueγια να επιβεβαιώσει ότιIdείναι μοναδική.

Ανάλυση των λειτουργικών εξαρτήσεων σε βάθος
Το γράφημα λειτουργικών εξαρτήσεων δείχνει επίσης ότι ORGANIZATION προσδιορίζει ADDRESS και ZIP, όπως αναμένεται. Ωστόσο, μπορεί να περιμένετε ZIP να προσδιορίσετε επίσης CITY, αλλά το διακεκομμένη βέλος υποδεικνύει ότι η εξάρτηση είναι προσεγγισμένη μόνο και δείχνει προς ένα ζήτημα ποιότητας δεδομένων.
Υπάρχουν και άλλες ιδιαιτερότητες στο γράφημα. Για παράδειγμα, NAME δεν προσδιορίζει GENDER, Id, SPECIALITYή ORGANIZATION. Κάθε μία από αυτές τις ιδιαιτερότητες μπορεί να αξίζει να διερευνηθεί.
Ρίξτε μια βαθύτερη ματιά στην κατά προσέγγιση σχέση μεταξύ
ZIPκαιCITY, χρησιμοποιώντας τη συνάρτησηlist_dependency_violationsτου SemPy για να δείτε μια λίστα παραβιάσεων σε μορφή πίνακα:providers.list_dependency_violations('ZIP', 'CITY')Σχεδιάστε ένα γράφημα με τη συνάρτηση
plot_dependency_violationsαπεικόνισης του SemPy. Αυτό το γράφημα είναι χρήσιμο εάν ο αριθμός των παραβιάσεων είναι μικρός:providers.plot_dependency_violations('ZIP', 'CITY')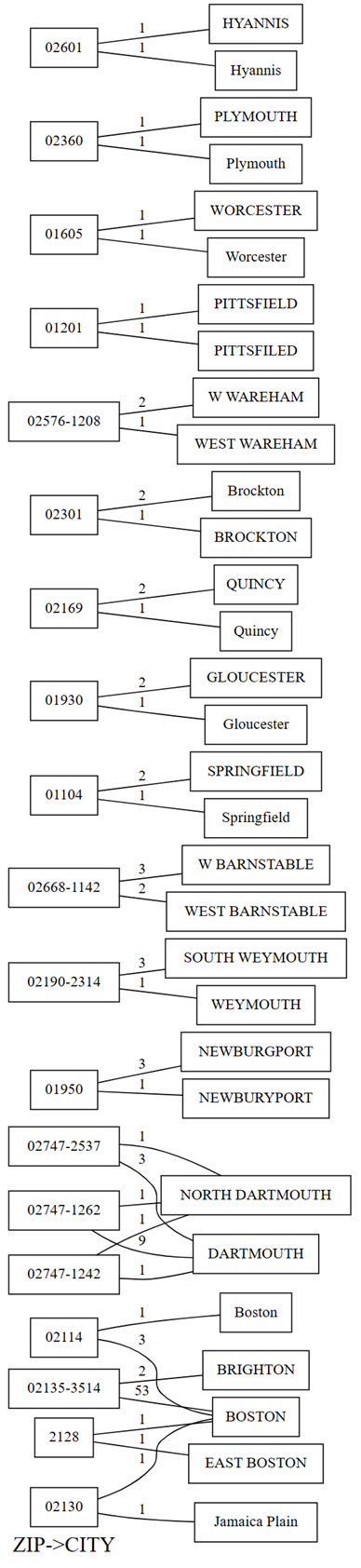
Η σχεδίαση των παραβιάσεων εξάρτησης εμφανίζει τιμές για
ZIPστην αριστερή πλευρά και τιμές γιαCITYστη δεξιά πλευρά. Ένα άκρο συνδέει έναν ταχυδρομικό κώδικα στην αριστερή πλευρά της σχεδίασης με μια πόλη στη δεξιά πλευρά, εάν υπάρχει μια γραμμή που περιέχει αυτές τις δύο τιμές. Τα άκρα επισημαίνονται με το πλήθος αυτών των γραμμών. Για παράδειγμα, υπάρχουν δύο γραμμές με ταχυδρομικό κώδικα 02747-1242, μία γραμμή με την πόλη "NORTH DARTHMOUTH" και η άλλη με την πόλη "DARTHMOUTH", όπως φαίνεται στο προηγούμενο γράφημα και στον παρακάτω κώδικα:Επιβεβαιώστε τις προηγούμενες παρατηρήσεις που κάνατε με τη σχεδίαση των παραβιάσεων εξάρτησης εκτελώντας τον ακόλουθο κώδικα:
providers[providers.ZIP == '02747-1242'].CITY.value_counts()Η σχεδίαση δείχνει επίσης ότι μεταξύ των γραμμών που έχουν
CITYως "DARTHMOUTH", εννέα γραμμές έχουνZIP02747-1262. μία γραμμή έχειZIP02747-1242. και μία γραμμή έχειZIP02747-2537. Επιβεβαιώνει αυτές τις παρατηρήσεις με τον ακόλουθο κώδικα:providers[providers.CITY == 'DARTMOUTH'].ZIP.value_counts()Υπάρχουν άλλοι ταχυδρομικοί κώδικες που σχετίζονται με το "DARTMOUTH", αλλά αυτοί οι ταχυδρομικοί κώδικες δεν εμφανίζονται στο γράφημα των παραβιάσεων εξάρτησης, καθώς δεν υπαινίσσονται προβλήματα ποιότητας δεδομένων. Για παράδειγμα, ο ταχυδρομικός κώδικας "02747-4302" σχετίζεται μοναδικά με το "DARTMOUTH" και δεν εμφανίζεται στο γράφημα παραβιάσεων εξάρτησης. Επιβεβαιώστε εκτελώντας τον ακόλουθο κώδικα:
providers[providers.ZIP == '02747-4302'].CITY.value_counts()
Σύνοψη προβλημάτων ποιότητας δεδομένων που εντοπίστηκαν με το SemPy
Επιστρέφοντας στο γράφημα των παραβιάσεων εξάρτησης, μπορείτε να δείτε ότι υπάρχουν πολλά ενδιαφέροντα ζητήματα ποιότητας δεδομένων σε αυτό το σημασιολογικό μοντέλο:
- Ορισμένα ονόματα πόλεων είναι όλα κεφαλαία. Αυτό το πρόβλημα είναι εύκολο να διορθωθεί χρησιμοποιώντας μεθόδους συμβολοσειράς.
- Ορισμένα ονόματα πόλεων έχουν προσδιοριζόμενα (ή προθέματα), όπως "Βορράς" και "Ανατολή". Για παράδειγμα, ο ταχυδρομικός κώδικας "2128" αντιστοιχίζεται στην τιμή "EAST BOSTON" μία φορά και σε "BOSTON" μία φορά. Ένα παρόμοιο πρόβλημα παρουσιάζεται μεταξύ των "NORTH DARTHMOUTH" και "DARTHMOUTH". Θα μπορούσατε να προσπαθήσετε να αποθέσετε αυτά τα προσδιοριστικό ή να αντιστοιχίστε τους ταχυδρομικούς κώδικες στην πόλη με το πιο συνηθισμένο περιστατικό.
- Υπάρχουν τυπογραφικά λάθη σε ορισμένες πόλεις, όπως "PITTSFIELD" εναντίον "PITTSFILED" και "NEWBURGPORT vs. "NEWBURYPORT". Για το "NEWBURGPORT", αυτό το τυπογραφικό λάθος μπορεί να διορθωθεί χρησιμοποιώντας την πιο συνηθισμένη εμφάνιση. Για το "PITTSFIELD", η ύπαρξη μόνο μίας εμφάνισης το καθένα καθιστά πολύ πιο δύσκολο για την αυτόματη αποσαφήνιση χωρίς εξωτερικές γνώσεις ή τη χρήση ενός μοντέλου γλώσσας.
- Ορισμένες φορές, προθήματα όπως "Δύση" συντομογραφούνται σε ένα μόνο γράμμα "W". Αυτό το ζήτημα μπορεί πιθανώς να διορθωθεί με μια απλή αντικατάσταση, εάν όλες οι εμφανίσεις του "W" ισχύει για "West".
- Ο ταχυδρομικός κώδικας "02130" αντιστοιχεί μία φορά στη "ΒΟΣΤΟΝΗ" και στο "Τζαμάικα Plain" μία φορά. Αυτό το πρόβλημα δεν είναι εύκολο να διορθωθεί, αλλά αν υπήρχαν περισσότερα δεδομένα, η αντιστοίχιση στην πιο συνηθισμένη εμφάνιση θα μπορούσε να αποτελέσει μια πιθανή λύση.
Εκκαθάριση των δεδομένων
Διορθώστε τα ζητήματα κεφαλαιοποίησης αλλάζοντας όλα τα κεφαλαία σε κεφαλαία σε κεφαλαία:
providers['CITY'] = providers.CITY.str.title()Εκτελέστε ξανά τον εντοπισμό παραβίασης για να δείτε ότι ορισμένες από τις ασάφειες έχουν χαθεί (ο αριθμός των παραβιάσεων είναι μικρότερος):
providers.list_dependency_violations('ZIP', 'CITY')Σε αυτό το σημείο, θα μπορούσατε να περιορίσετε τα δεδομένα σας πιο μη αυτόματα, αλλά μια πιθανή εργασία εκκαθάρισης δεδομένων είναι η κατάργηση γραμμών που παραβιάζουν τους λειτουργικούς περιορισμούς μεταξύ των στηλών στα δεδομένα, χρησιμοποιώντας τη συνάρτηση
drop_dependency_violationsτου SemPy.Για κάθε τιμή της αιτιοκρατικής μεταβλητής,
drop_dependency_violationsλειτουργεί επιλέγοντας την πιο κοινή τιμή της εξαρτώμενης μεταβλητής και απορρίπτοντας όλες τις γραμμές με άλλες τιμές. Θα πρέπει να εφαρμόσετε αυτή τη λειτουργία μόνο εάν είστε βέβαιοι ότι αυτή η στατιστική ευρετική θα οδηγούσε στα σωστά αποτελέσματα για τα δεδομένα σας. Διαφορετικά, θα πρέπει να συντάξετε τον δικό σας κώδικα για να χειρίζεστε τις παραβιάσεις που εντοπίστηκαν, ανάλογα με τις ανάγκες.Εκτελέστε τη συνάρτηση
drop_dependency_violationsστις στήλεςZIPκαιCITY:providers_clean = providers.drop_dependency_violations('ZIP', 'CITY')Παράθεση τυχόν παραβιάσεων εξάρτησης μεταξύ
ZIPκαιCITY:providers_clean.list_dependency_violations('ZIP', 'CITY')Ο κώδικας επιστρέφει μια κενή λίστα για να υποδείξει ότι δεν υπάρχουν άλλες παραβιάσεις του λειτουργικού περιορισμού CITY -> ZIP.
Σχετικό περιεχόμενο
Δείτε άλλα προγράμματα εκμάθησης για τη σημασιολογική σύνδεση / SemPy:
- Εκμάθηση : Ανάλυση λειτουργικών εξαρτήσεων σε ένα δείγμα μοντέλου σημασιολογίας
- Εκμάθηση : Εξαγωγή και υπολογισμός μετρήσεων Power BI από ένα σημειωματάριο Jupyter
- Εκμάθηση : Εντοπισμός σχέσεων σε ένα μοντέλο σημασιολογίας, χρησιμοποιώντας σημασιολογική σύνδεση
- Εκμάθηση : Εντοπισμός σχέσεων στο σύνολο δεδομένων Synthea, με χρήση σύνδεσης σημασιολογίας
- Εκμάθηση : Επικύρωση δεδομένων με χρήση των SemPy και Μεγάλων προσδοκιών (GX)