CMS-Anspruchsdatentransformationen (Vorschauversion) in Datenlösungen für das Gesundheitswesen verwenden
[Dieser Artikel ist Teil der Dokumentation zur Vorabversion und kann geändert werden.]
Mit CMS-Anspruchsdatentransformationen (Vorschauversion) können Sie Anspruchsdaten im CMS-(Centers for Medicare & Medicaid Services)-CCLF(Claim and Claim Line Feed)-Format erfassen, speichern und analysieren. Weitere Informationen zu dieser Funktion sowie zur Bereitstellung und Konfiguration finden Sie unter:
- Übersicht über CMS-Anspruchsdatentransformationen (Vorschauversion)
- CMS-Anspruchsdatentransformationen bereitstellen und konfigurieren (Vorschauversion)
Grundlegendes zum Transformationsmechanismus
Die Pipeline für die Transformation von Anspruchsdaten erfasst Anspruchsdateien entweder in nativem oder komprimiertem Format im Lakehouse. Die End-to-End-Transformation folgt diesen allgemeinen aufeinanderfolgenden Schritten:
- Transformieren der Anspruchsdateien in OneLake
- Organisieren der Anspruchsdateien in OneLake
- Extrahieren der Anspruchsdaten in das Bronze-Lakehouse
- Konvertieren von Anspruchsdaten in FHIR-NDJSON-Dateien
- Transformieren von Anspruchsdaten in vereinfachte FHIR-Tabellen im Bronze-Lakehouse
- Transformieren von Anspruchsdaten in relationale FHIR-Tabellen im Silver-Lakehouse
Ausführen der Pipeline der Anspruchsdatentransformationen
Stellen Sie sicher, dass Sie die Schritte unter Einrichten von Anspruchsbeispieldaten ausführen, bevor Sie die Pipeline für Anspruchsdatentransformationen ausführen.
Um die Anspruchsdaten vom Bronze-Lakehouse in das Silver-Lakehouse zu transformieren, öffnen Sie die healthcare#_msft_clinical_claims_cclf_data_transformation-Datenpipeline, und wählen Sie Ausführen aus.
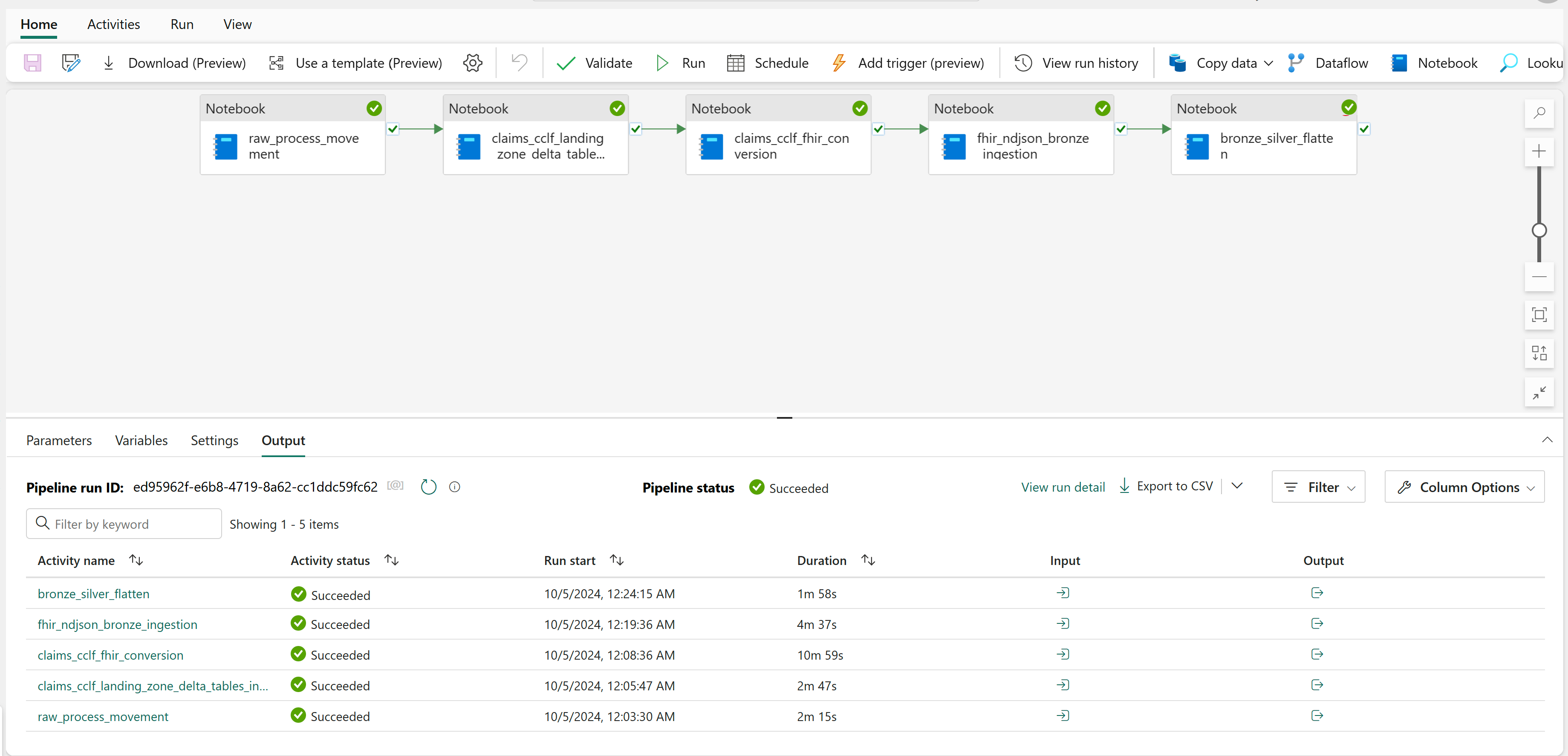
Nachdem die Pipeline erfolgreich ausgeführt wurde, öffnen Sie die Tabelle ExplanationOfBenefit im Silver-Lakehouse, um die transformierten Daten anzuzeigen.
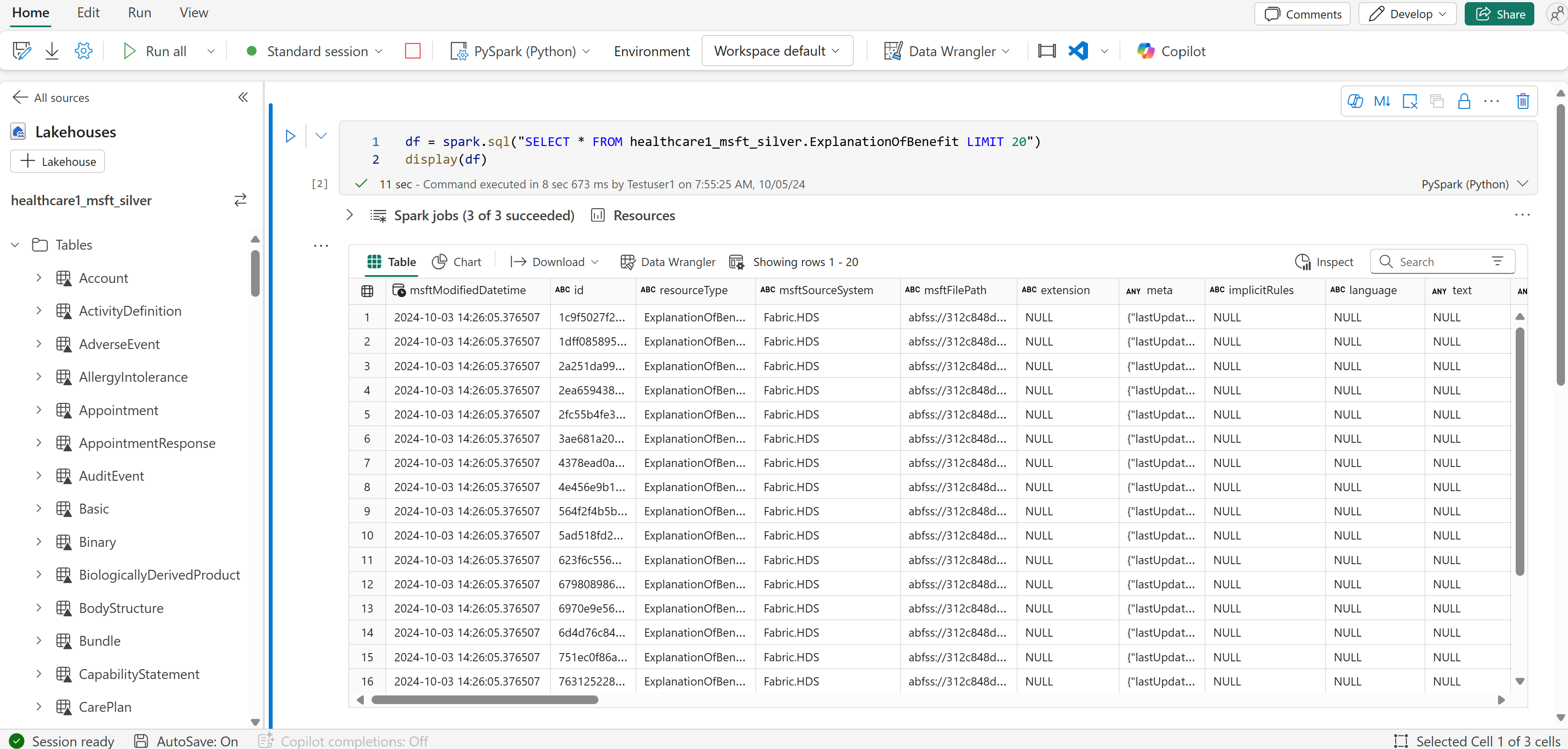


Überlegungen zur Nutzung
Lesen Sie diese wichtigen Punkte, bevor Sie die CMS-Funktion für Anspruchsdatentransformationen (Vorschauversion) verwenden.
Spark-Version
Die Notebooks sind standardmäßig für die Ausführung mit der Spark-Laufzeitversion 1.2 (Spark 3.4, Delta 2.4) vorkonfiguriert. Stellen Sie sicher, dass Sie diese Einstellung auf Umgebungsebene beibehalten. Weiteren Informationen finden Sie unter Spark-Laufzeitversion im Fabric-Arbeitsbereich zurücksetzen.
Dateierweiterung
Die hochgeladenen CCLF-Dateien müssen dem Erweiterungsformat folgen: *.T1000001 zu *.T1000009. Dateien mit falschen Erweiterungen werden in den Ordner Fehlgeschlagen im Bronze-Lakehouse verschoben.
Länge des Datensatzes
Eine Nichtübereinstimmung der Datensatzlänge in CCLF-Dateien tritt auf, wenn ein oder mehrere Datensätze vom erforderlichen Format mit fester Länge abweichen. Diese Diskrepanz kann zu einer falschen Datenausrichtung, einer unvollständigen Datenerfassung oder zu Verarbeitungsfehlern führen. Dateien mit Datensätzen, die die erwartete Länge nicht erreichen, werden in den Ordner Fehlgeschlagen im Bronze-Lakehouse verschoben.