Implementieren der Medallion Lakehouse-Architektur in Microsoft Fabric
In diesem Artikel wird die Medallion Lake-Architektur vorgestellt, und es wird beschrieben, wie Sie ein Lakehouse in Microsoft Fabric implementieren können. Er richtet sich an mehrere Zielgruppen:
- Technische Fachkräfte für Daten: Technische Mitarbeiter, die Infrastrukturen und Systeme entwerfen, erstellen und verwalten, die es ihren Organisationen ermöglichen, große Datenmengen zu sammeln, zu speichern, zu verarbeiten und zu analysieren.
- Center of Excellence, IT und BI-Team: Die Teams, die für die Überwachung von Analysen in der gesamten Organisation verantwortlich sind.
- Fabric-Administrator*innen: Administrator*innen, die für die Überwachung von Fabric in der Organisation verantwortlich sind
Die Medallion Lakehouse-Architektur, allgemein bekannt als Medallion-Architektur, ist ein Designmuster, das von Organisationen verwendet wird, um Daten in einem Lakehouse logisch zu organisieren. Es ist der empfohlene Entwurfsansatz für Fabric.
Die Medallion-Architektur besteht aus drei unterschiedlichen Ebenen – oder Zonen. Jede Ebene gibt die Qualität der im Lakehouse gespeicherten Daten an, wobei höhere Ebenen eine höhere Qualität darstellen. Dieser Ansatz mit mehreren Ebenen hilft Ihnen, eine einzelne Wahrheitsinstanz für Unternehmensdatenprodukte zu erstellen.
Wichtig ist, dass die Medallion-Architektur den Unteilbarkeit, Konsistenz, Isolation und Haltbarkeit (ACID)-Satz von Eigenschaften garantiert, wenn die Daten die Ebenen durchlaufen. Beginnend mit Rohdaten bereitet eine Reihe von Validierungen und Transformationen Daten vor, die für effiziente Analysen optimiert sind. Es gibt drei Medallion-Ebenen: Bronze (roh), Silber (validiert) und Gold (angereichert).
Weitere Informationen finden Sie unter Was ist die Medallion Lakehouse-Architektur?.
OneLake und Lakehouse in Fabric
Die Basis eines modernen Data Warehouse ist ein Data Lake. Microsoft OneLake ist ein einziger, einheitlicher, logischer Data Lake für Ihre gesamte Organisation. Es wird automatisch mit jedem Fabric-Mandanten bereitgestellt und ist als zentraler Ort für alle Ihre Analysedaten konzipiert.
Sie können OneLake für Folgendes verwenden:
- Entfernen von Silos und Reduzieren des Verwaltungsaufwands. Alle Organisationsdaten werden in einer Data Lake-Ressource gespeichert, verwaltet und gesichert. Da OneLake mit Ihrem Fabric-Mandanten bereitgestellt wird, gibt es keine weiteren Ressourcen zum Bereitstellen oder Verwalten.
- Verringern der Datenverschiebung und -duplizierung. Das Ziel von OneLake besteht darin, nur eine Kopie von Daten zu speichern. Weniger Kopien von Daten führen zu weniger Datenverschiebungen, was zu Effizienzgewinnen und einer Verringerung der Komplexität führt. Bei Bedarf können Sie eine Verknüpfung erstellen, um auf in anderen Speicherorten gespeicherte Daten zu verweisen, anstatt sie in OneLake zu kopieren.
- Verwenden mit mehreren Analyse-Engines. Die Daten in OneLake werden in einem offenen Format gespeichert. Auf diese Weise können die Daten von verschiedenen Analyse-Engines abgefragt werden, einschließlich Analysis Services (verwendet von Power BI), T-SQL und Apache Spark. Andere Nicht-Fabric-Anwendungen können APIs und SDKs verwenden, um auch auf OneLake zuzugreifen.
Weitere Informationen finden Sie unter OneLake, das OneDrive für Daten.
Um Daten in OneLake zu speichern, erstellen Sie ein Lakehouse in Fabric. Ein Lakehouse ist eine Datenarchitekturplattform zum Speichern, Verwalten und Analysieren strukturierter und unstrukturierter Daten an einem einzelnen Speicherort. Es lässt sich problemlos auf große Datenmengen aller Dateitypen und -größen skalieren, und da die Daten an einem einzigen Ort gespeichert werden, können sie problemlos im gesamten Unternehmen gemeinsam genutzt werden.
Jedes Lakehouse verfügt über einen integrierten SQL-Analyseendpunkt, der Data Warehouse-Funktionen freischaltet, ohne dass Sie Daten verschieben müssen. Das bedeutet, dass Sie Ihre Daten im Lakehouse mithilfe von SQL-Abfragen und ohne spezielle Einrichtung abfragen können.
Weitere Informationen finden Sie unter Was ist ein Lakehouse in Microsoft Fabric?.
Tabellen und Dateien
Wenn Sie ein Lakehouse in Fabric erstellen, werden für Tabellen und Daten automatisch zwei physische Speicherorte bereitgestellt.
- Tabellen ist ein verwalteter Bereich zum Hosten von Tabellen aller Formate in Apache Spark (CSV, Parquet oder Delta). Alle Tabellen, ob automatisch oder explizit erstellt, werden als Tabellen im Lakehouse erkannt. Außerdem werden alle Delta-Tabellen, bei denen es sich um Datendateien mit einem dateibasierten Transaktionsprotokoll handelt, auch als Tabellen erkannt.
- Dateien ist ein nicht verwalteter Bereich zum Speichern von Daten in einem beliebigen Dateiformat. Alle in diesem Bereich gespeicherten Delta-Dateien werden nicht automatisch als Tabellen erkannt. Wenn Sie eine Tabelle über einen Delta Lake-Ordner im nicht verwalteten Bereich erstellen möchten, müssen Sie explizit eine Verknüpfung oder eine externe Tabelle mit einem Speicherort erstellen, der auf den nicht verwalteten Ordner zeigt, der die Delta Lake-Dateien in Apache Spark enthält.
Der Hauptunterschied zwischen dem verwalteten Bereich (Tabellen) und dem nicht verwalteten Bereich (Dateien) ist der automatische Ermittlungs- und Registrierungsprozess für Tabellen. Dieser Vorgang wird nur für alle Ordner ausgeführt, die im verwalteten Bereich erstellt wurden, nicht aber im nicht verwalteten Bereich.
In Microsoft Fabric bietet der Lakehouse-Explorer eine einheitliche grafische Darstellung des gesamten Lakehouse, damit Benutzer navigieren, auf ihre Daten zugreifen und sie aktualisieren können.
Weitere Informationen zur automatischen Tabellenermittlung finden Sie unter Automatische Tabellenermittlung und -registrierung.
Delta Lake-Storage
Delta Lake ist eine optimierte Speicherebene, die die Grundlage für die Speicherung von Daten und Tabellen bildet. Es unterstützt ACID-Transaktionen für Big Data-Workloads, und aus diesem Grund ist es das Standardspeicherformat in einem Fabric Lakehouse.
Wichtig ist, dass Delta Lake Zuverlässigkeit, Sicherheit und Leistung im Lakehouse sowohl für Streaming- als auch Batchvorgänge bietet. Intern speichert es Daten jedoch im Parquet-Dateiformat, es verwaltet auch Transaktionsprotokolle und Statistiken, die Features und Leistungsverbesserungen über das Standard-Parquet-Format bieten.
Das Delta Lake-Format über generische Dateiformate bietet die folgenden Hauptvorteile.
- Unterstützung für ACID-Eigenschaften und insbesondere Dauerhaftigkeit zur Verhinderung von Datenbeschädigungen.
- Schnelleres Lesen von Abfragen.
- Erhöhte Datenaktualität.
- Unterstützung für Batch- und Streamingworkloads.
- Unterstützung für Datenrollback mithilfe von Delta Lake-Zeitreise.
- Verbesserte Einhaltung gesetzlicher Vorschriften und Überwachung mithilfe des Delta Lake-Tabellenverlaufs.
Fabric standardisiert das Speicherdateiformat mit Delta Lake, und standardmäßig erstellt jede Workload-Engine in Fabric Delta-Tabellen, wenn Sie Daten in eine neue Tabelle schreiben. Weitere Informationen finden Sie unter Lakehouse- und Delta Lake-Tabellen.
Medallion-Architektur in Fabric
Das Ziel der Medaillon-Architektur ist es, die Struktur und Qualität der Daten schrittweise und progressiv zu verbessern, während sie die einzelnen Phasen durchlaufen.
Die Medallion-Architektur besteht aus drei unterschiedlichen Ebenen (oder Zonen).
- Bronze: Auch bekannt als rohe Zone; diese erste Ebene speichert Quelldaten im ursprünglichen Format. Die Daten in dieser Ebene sind in der Regel nur angefügt und unveränderlich.
- Silber: Auch bekannt als angereicherte Zone; diese Ebene speichert Datenquellen aus der Bronzeebene. Die Rohdaten wurden bereinigt und standardisiert und sind jetzt als Tabellen (Zeilen und Spalten) strukturiert. Sie können auch in andere Daten integriert werden, um eine Unternehmensansicht aller Geschäftseinheiten wie Kunde, Produkt und andere bereitzustellen.
- Gold: Auch bekannt als kuratierte Zone; diese letzte Ebene speichert Datenquellen aus der Silberebene. Die Daten werden so optimiert, dass sie bestimmte nachgelagerte Geschäfts- und Analyseanforderungen erfüllen. Tabellen entsprechen in der Regel dem Sternschemadesign, das die Entwicklung von Datenmodellen unterstützt, die für Leistung und Benutzerfreundlichkeit optimiert sind.
Wichtig
Da ein Fabric Lakehouse eine einzelne Zone darstellt, erstellen Sie für jede der drei Zonen ein Lakehouse.
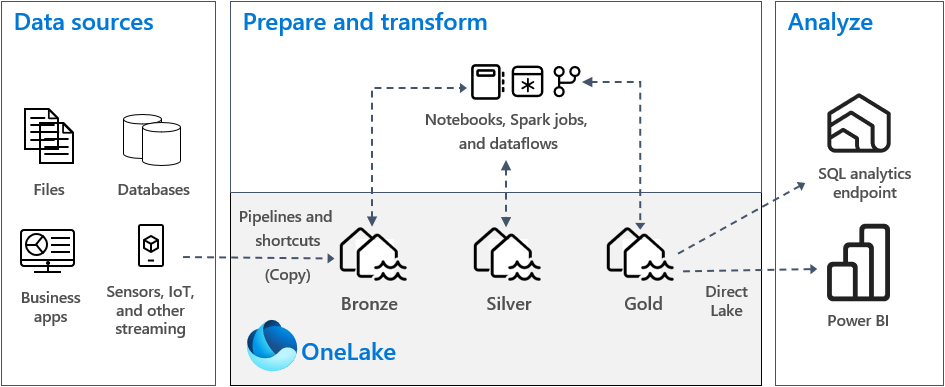
In einer typischen Medallion-Architekturimplementierung in Fabric speichert die Bronzezone die Daten im gleichen Format wie die Datenquelle. Wenn es sich bei der Datenquelle um eine relationale Datenbank handelt, sind Delta-Tabellen eine gute Wahl. Die Silber- und Goldzonen enthalten Delta-Tabellen.
Tipp
Um zu erfahren, wie Sie ein Lakehouse erstellen, arbeiten Sie das Tutorial Umfassendes Lakehouse-Szenario durch.
Leitfaden für Fabric-Lakehouse
Dieser Abschnitt enthält Anleitungen zur Implementierung Ihres Fabric Lakehouse mithilfe der Medallion-Architektur.
Bereitstellungsmodell
Um die Medallion-Architektur in Fabric zu implementieren, können Sie entweder Lakehouses (eins für jede Zone), ein Data Warehouse oder eine Kombination aus beiden verwenden. Ihre Entscheidung sollte auf Ihren Vorlieben und der Expertise Ihres Teams basieren. Denken Sie daran, dass Fabric Ihnen Flexibilität bietet: Sie können verschiedene Analysemodule verwenden, die an einer Kopie Ihrer Daten in OneLake arbeiten.
Diese zwei Muster müssen berücksichtigt werden.
- Muster 1: Erstellen jeder Zone als Lakehouse. In diesem Fall greifen Geschäftsbenutzer mithilfe des SQL-Analyseendpunkts auf Daten zu.
- Muster 2: Erstellen der Bronze- und Silberzonen als Lakehouses und der Goldzone als Data Warehouse. In diesem Fall greifen Geschäftsbenutzer mithilfe des Data Warehouse-Endpunkts auf Daten zu.
Während Sie alle Lakehouses in einem einzigen Fabric-Arbeitsbereich erstellen können, empfehlen wir Ihnen, jedes Lakehouse in einem eigenen, separaten Fabric-Arbeitsbereich zu erstellen. Dieser Ansatz bietet Ihnen mehr Kontrolle und bessere Governance auf Zonenebene.
Für die Bronzezone wird empfohlen, die Daten im originalen Format zu speichern oder Parquet oder Delta Lake zu verwenden. Behalten Sie die Daten nach Möglichkeit im ursprünglichen Format bei. Wenn die Quelldaten aus OneLake, Azure Data Lake Store Gen2 (ADLS Gen2), Amazon S3 oder Google stammen, erstellen Sie eine Verknüpfung in der Bronzezone, anstatt die Daten zu kopieren.
Für die Silber- und Goldzonen wird empfohlen, Delta-Tabellen aufgrund der zusätzlichen Funktionen und Leistungsverbesserungen zu verwenden, die sie bieten. Fabric standardisiert das Delta Lake-Format, und standardmäßig schreibt jedes Modul in Fabric Daten in diesem Format. Darüber hinaus verwenden diese Engines die Optimierung der V-Reihenfolgen-Schreibzeit für das Parquet-Dateiformat. Diese Optimierung ermöglicht extrem schnelle Lesevorgänge von Fabric-Computemodulen wie Power BI, SQL, Apache Spark und anderen. Weitere Informationen finden Sie unter Delta Lake-Tabellenoptimierung und V-Reihenfolge.
Heute sehen sich Organisationen einem massiven Datenwachstum gegenüber und einer zunehmenden Notwendigkeit, diese Daten auf logische Weise zu organisieren und zu verwalten und gleichzeitig eine gezieltere und effizientere Nutzung und Governance zu ermöglichen. Dies kann dazu führen, dass Sie eine dezentrale oder Verbunddatenorganisation mit Governance einrichten und verwalten.
Um dieses Ziel zu erreichen, sollten Sie eine Datengitterarchitektur implementieren. Datengitter ist ein Architekturmuster, das sich auf das Erstellen von Datendomänen konzentriert, die Daten als Produkt anbieten.
In Fabric können Sie eine Datengitterarchitektur für Ihre Datenstruktur erstellen, indem Sie Datendomänen erstellen. Sie können beispielsweise Domänen erstellen, die Ihren Geschäftsdomänen zugeordnet sind, z. B. Marketing, Vertrieb, Bestand, Personalwesen und andere. Anschließend können Sie die Medallion-Architektur implementieren, indem Sie Datenzonen innerhalb jeder Ihrer Domänen einrichten.
Weitere Informationen zu Domänen finden Sie unter Domänen.
Grundlegendes zur Datenspeicherung von Delta-Tabellen
In diesem Abschnitt werden weitere Leitthemen zum Implementieren einer Medallion Lakehouse-Architektur in Fabric beschrieben.
Dateigröße
Im Allgemeinen wird eine Big Data-Plattform besser ausgeführt, wenn sie über eine kleine Anzahl großer Dateien und nicht über eine große Anzahl kleiner Dateien verfügt. Das liegt daran, dass Leistungsbeeinträchtigungen auftreten, wenn die Compute-Engine viele Metadaten- und Dateivorgänge verwalten muss. Für eine bessere Abfrageleistung empfehlen wir, dass Sie auf Datendateien abzielen, die ungefähr 1 GB groß sind.
Delta Lake verfügt über ein Feature namens Prädiktive Optimierung. Durch die prädiktive Optimierung entfällt die Notwendigkeit, Wartungsvorgänge für Deltatabellen manuell zu verwalten. Wenn dieses Feature aktiviert ist, identifiziert Delta Lake automatisch Tabellen, die von Wartungsvorgängen profitieren würden, und optimiert dann ihren Speicher. Es kann viele kleinere Dateien transparent in große Dateien zusammenfügen, ohne Auswirkungen auf andere Leser und Schreiber der Daten. Obwohl dieses Feature Teil Ihrer operativen Exzellenz und Ihrer Datenvorbereitung sein sollte, kann Fabric diese Datendateien auch während des Schreibens von Daten optimieren. Weitere Informationen finden Sie unter Prädiktive Optimierung für Delta Lake.
Historische Aufbewahrung
Standardmäßig behält Delta Lake eine Historie aller vorgenommenen Änderungen bei. Dies bedeutet, dass die Größe der historischen Metadaten im Laufe der Zeit wächst. Basierend auf Ihren geschäftlichen Anforderungen sollten Sie historische Daten nur für einen bestimmten Zeitraum aufbewahren, um Ihre Speicherkosten zu reduzieren. Erwägen Sie, historische Daten nur für den letzten Monat oder einen anderen geeigneten Zeitraum aufzubewahren.
Sie können ältere historische Daten aus einer Delta-Tabelle entfernen, indem Sie denVACUUM-Befehl verwenden. Beachten Sie jedoch, dass Sie historische Daten der letzten sieben Tage nicht löschen können, um die Konsistenz in den Daten beizubehalten. Die Standardanzahl von Tagen wird durch die Tabelleneigenschaft delta.deletedFileRetentionDuration = "interval <interval>" gesteuert. Sie bestimmt den Zeitraum, in dem eine Datei gelöscht werden muss, bevor sie als Kandidat für einen Vakuumvorgang betrachtet werden kann.
Tabellenpartitionen
Wenn Sie Daten in den jeweiligen Zonen speichern, wird empfohlen, bei Bedarf eine partitionierte Ordnerstruktur zu verwenden. Diese Technik trägt dazu bei, die Datenverwaltung und Abfrageleistung zu verbessern. Im Allgemeinen führt die Partitionierung von Daten in einer Ordnerstruktur zu einer schnelleren Suche nach bestimmten Dateneinträgen dank der Beschneidung/Beseitigung von Partitionen.
In der Regel fügen Sie Daten an die Zieltabelle an, wenn neue Daten eintreffen. In einigen Fällen können Sie jedoch Daten zusammenführen, da Sie vorhandene Daten gleichzeitig aktualisieren müssen. In diesem Fall können Sie einen Upsert-Vorgang ausführen, indem Sie den MERGE-Befehl verwenden. Wenn die Zieltabelle partitioniert ist, müssen Sie unbedingt einen Partitionsfilter verwenden, um den Vorgang zu beschleunigen. Auf diese Weise kann das Modul Partitionen ausschließen, die keine Aktualisierung erfordern.
Datenzugriff
Schließlich sollten Sie planen und steuern, wer Zugriff auf bestimmte Daten im Lakehouse benötigt. Sie sollten auch die verschiedenen Transaktionsmuster verstehen, die sie beim Zugriff auf diese Daten verwenden werden. Anschließend können Sie das richtige Tabellenpartitionsschema und die Datenkollokation mit Delta Lake Z-Reihenfolge-Indizes definieren.
Zugehöriger Inhalt
Weitere Informationen zur Implementierung eines Fabric Lakehouse finden Sie in den folgenden Ressourcen.
- Tutorial: Umfassendes Lakehouse-Szenario
- Lakehouse- und Delta Lake-Tabellen
- Microsoft Fabric-Entscheidungsleitfaden: Auswählen eines Datenspeichers
- Delta Lake-Tabellenoptimierung und V-Reihenfolge
- Die Notwendigkeit, das Schreiben auf Apache Spark zu optimieren
- Fragen? Versuchen Sie, die Fabric-Community zu fragen.
- Vorschläge? Tragen Sie Ideen bei, um Fabric zu verbessern.