Migration: Azure Synapse Analytics: Dedizierter SQL-Pool von Fabric
Gilt für:✅ Warehouse in Microsoft Fabric
Dieser Artikel beschreibt die Strategie, Überlegungen und Methoden der Migration von Data Warehousing in Azure Synapse Analytics dedizierten SQL-Pools zu Microsoft Fabric Warehouse.
Migration – Einführung
Als Microsoft Microsoft Fabric vorstellte, eine SaaS-Analyselösung für Unternehmen, die eine umfassende Sammlung von Diensten bietet, darunter Data Factory, Data Engineering, Data Warehousing, Data Science, Echtzeitintelligenz, und Power BI.
In diesem Artikel geht es um die Optionen für die Migration von Schema (DDL), Datenbankcode (DML) und Daten. Microsoft bietet dazu mehrere Möglichkeiten an. Hier besprechen wir jede Option im Detail und geben Tipps, welche dieser Optionen Sie für Ihr Szenario in Betracht ziehen sollten. Dieser Artikel verwendet den TPC-DS-Benchmark zur Veranschaulichung und für Leistungstests. Ihr tatsächliches Ergebnis kann von vielen Faktoren abhängen, darunter die Art der Daten, die Datentypen, die Breite der Tabellen, die Latenzzeit der Datenquelle usw.
Vorbereiten der Migration
Planen Sie Ihr Migrationsprojekt sorgfältig, bevor Sie beginnen, und stellen Sie sicher, dass Ihr Schema, Code und Daten mit Fabric Warehouse kompatibel sind. Es gibt einige Einschränkungen, die Sie berücksichtigen müssen. Quantifizieren Sie den Refactoring-Aufwand für die inkompatiblen Elemente sowie alle anderen Ressourcen, die vor der Migration benötigt werden.
Ein weiteres wichtiges Ziel der Planung besteht darin, Ihren Entwurf anzupassen, um sicherzustellen, dass Ihre Lösung die hohe Abfrageleistung von Fabric Warehouse optimal nutzt. Das Entwerfen von Data Warehouses für die Skalierung umfasst einzigartige Entwurfsmuster, weshalb herkömmliche Ansätze nicht immer optimal sind. Prüfen Sie die Leistungsrichtlinien von Fabric Warehouse, denn obwohl einige Entwurfsanpassungen nach der Migration vorgenommen werden können, sparen Sie Zeit und Mühe, wenn Sie die Änderungen früher im Prozess vornehmen. Die Migration von einer Technologie/Umgebung zu einer anderen ist immer ein großer Aufwand.
Das folgende Diagramm zeigt den Migrationslebenszyklus mit den wichtigsten Säulen, bestehend aus den Säulen Bewerten und Evaluieren, Planen und Entwerfen, Migrieren, Überwachen und Verwalten, Optimieren und Modernisieren mit den zugehörigen Aufgaben in jeder Säule, um eine reibungslose Migration zu planen und vorzubereiten.

Runbook für die Migration
Betrachten Sie die folgenden Aktivitäten als ein Runbook für die Planung Ihrer Migration von Synapse dedizierten SQL-Pools zu Fabric Warehouse.
- Bewerten und evaluieren
- Identifizieren der Ziele und Motivationen. Definieren von klaren, gewünschten Ergebnissen.
- Ermittlung, Bewertung und Baseline der bestehenden Architektur.
- Identifizieren wichtiger Projektbeteiligter und Sponsoren.
- Definieren des Umfangs der zu migrierenden Elemente.
- Klein und einfach anfangen, sich auf mehrere kleine Migrationen vorbereiten.
- Überwachen und Dokumentieren aller Phasen des Prozesses.
- Erstellen einer Bestandsaufnahme der Daten und Prozesse für die Migration
- Definieren von Datenmodelländerungen (falls erforderlich)
- Den Fabric Arbeitsbereich einrichten.
- Was ist Ihr Skillset/Ihre Vorliebe?
- Nehmen Sie wann immer möglich eine Automatisierung vor.
- Verwenden von integrierten Azure-Tools und -Features zum Verringern des Migrationsaufwands.
- Frühzeitige Schulung von Mitarbeitern für die neue Plattform
- Ermitteln Sie den Weiterbildungsbedarf und die entsprechenden Trainings, einschließlich Microsoft Learn.
- Planen und Entwerfen
- Definieren Sie die gewünschte Architektur.
- Wählen Sie die Methode/Tools für die Migration aus, um die folgenden Aufgaben auszuführen:
- Extrahieren von Daten aus der Quelle.
- Schemakonvertierung (DDL), einschließlich Metadaten für Tabellen und Ansichten
- Datenaufnahme, einschließlich historischer Daten.
- Erneutes Erstellen des Datenmodells bei Bedarf anhand der Leistung und Skalierbarkeit der neuen Plattform.
- Migration von Datenbankcode (DML).
- Migrieren oder Umgestalten von gespeicherten Prozeduren und Geschäftsprozessen
- Inventarisieren und extrahieren der Sicherheitsmerkmale und Objektberechtigungen aus der Quelle.
- Entwerfen und planen der Ersetzung/Änderung bestehender ETL/ELT-Prozesse für inkrementelles Laden.
- Parallele ETL/ELT-Prozesse für die neue Umgebung erstellen.
- Einen detaillierten Migrationsplan erstellen.
- Den aktuellen Zustand dem neuen gewünschten Zustand zuordnen.
- Migrieren
- Ausführen von Schema, Daten, Codemigration.
- Extrahieren von Daten aus der Quelle.
- Schemakonvertierung (DDL)
- Datenerfassung
- Migration von Datenbankcode (DML).
- Skalieren Sie bei Bedarf die dedizierten SQL-Poolressourcen vorübergehend, um die Migrationsgeschwindigkeit zu beschleunigen.
- Sicherheit und -Berechtigungen anwenden.
- Migrieren bestehender ETL/ELT-Prozesse für inkrementelles Laden.
- Migrieren oder Umgestalten von ETL/ELT-Prozessen für inkrementelles Laden
- Testen und vergleichen paralleler inkrementelle Ladeprozesse.
- Detailmigrationsplan nach Bedarf anpassen.
- Ausführen von Schema, Daten, Codemigration.
- Überwachen und Steuern
- Parallel ausführen, mit Ihrer Quellumgebung vergleichen.
- Anwendungen, Business Intelligence-Plattformen und Abfragetools testen.
- Erstellen von Benchmarks für die Abfrageleistung und Optimieren derselben
- Überwachen und Verwalten von Kosten, Sicherheit und Leistung.
- Bewertung des Vergleichstests und Governance.
- Parallel ausführen, mit Ihrer Quellumgebung vergleichen.
- Optimieren und Modernisieren
- Wenn das Unternehmen komfortabel ist, übertragen Sie Anwendungen und primäre Berichterstellungsplattformen auf Fabric.
- Skalieren Sie Ressourcen nach oben/unten, da sich die Arbeitsauslastung von Azure Synapse Analytics zu Microsoft Fabric verschiebt.
- Erstellen Sie aus den gewonnenen Erfahrungen eine wiederholbare Vorlage für zukünftige Migrationen. Iterate.
- Identifizieren von Möglichkeiten für Kostenoptimierung, Sicherheit, Skalierbarkeit und operative Exzellenz
- Identifizieren Sie Möglichkeiten, Ihren Datenbestand mit den neuesten Fabric-Funktionen zu modernisieren.
- Wenn das Unternehmen komfortabel ist, übertragen Sie Anwendungen und primäre Berichterstellungsplattformen auf Fabric.
„Lift & Shift“ oder modernisieren?
Unabhängig von Zweck und Umfang der geplanten Migration gibt es im Allgemeinen zwei Typen von Migrationsszenarien: eine unveränderte Migration (Lift and Shift) oder einen phasenweisen Ansatz, der Architektur- und Codeänderungen einbindet.
Lift & Shift
Bei einer Lift- und Schichtmigration wird ein vorhandenes Datenmodell mit geringfügigen Änderungen an dem neuen Fabric Warehouse migriert. Dieser Ansatz minimiert die Risiken und den Zeitaufwand für die Migration, indem er den neuen Aufwand reduziert, der erforderlich ist, um die Vorteile der Migration zu nutzen.
Die Migration per Lift & Shift eignet sich gut für die folgenden Szenarien:
- Sie haben eine bestehende Umgebung mit einer kleinen Anzahl von zu migrierenden Data Marts.
- Sie haben eine vorhandene Umgebung mit Daten, die sich bereits in einem gut gestalteten Stern- oder Schneeflockenschema befinden.
- Sie sind unter Zeit- und Kostendruck, um in Fabric Warehouse zu wechseln.
Zusammenfassend funktioniert dieser Ansatz gut für die Workloads, die mit Ihrer aktuellen dedizierten Synapse SQL-Pools-Umgebung optimiert sind, und erfordert daher keine großen Änderungen in Fabric.
Modernisieren in einem phasenweisen Ansatz mit Architekturänderungen
Wenn ein Legacy-Data Warehouse über einen längeren Zeitraum weiterentwickelt wurde, müssen Sie es möglicherweise umstrukturieren, um die erforderlichen Leistungsstufen beibehalten zu können.
Möglicherweise möchten Sie auch die Architektur neu gestalten, um die neuen Engines und Features zu nutzen, die im Fabric-Arbeitsbereich verfügbar sind.
Unterschiede im Design: Dedizierte SQL-Pools von Synapse und Fabric Warehouse
Betrachten Sie die folgenden Unterschiede zwischen Azure Synapse und Microsoft Fabric Data Warehouse, wobei dedizierte SQL-Pools mit dem Fabric Warehouse verglichen werden.
Überlegungen zu Tabellen
Wenn Sie Tabellen zwischen verschiedenen Umgebungen migrieren, werden normalerweise nur die Rohdaten und die Metadaten physisch migriert. Andere Datenbankelemente aus dem Quellsystem, wie z. B. Indizes, werden in der Regel nicht migriert, weil sie in der neuen Umgebung möglicherweise nicht benötigt oder anders implementiert werden.
Leistungsoptimierungen in der Quellumgebung, wie z. B. Indizes, zeigen an, wo Sie in einer neuen Umgebung Leistungsoptimierungen hinzufügen könnten. Jetzt kümmert sich Fabric automatisch darum.
T-SQL-Überlegungen
Es gibt mehrere Unterschiede bei der Datenbearbeitungssprache (Data Manipulation Language, DML). Weitere Informationen finden Sie unter T-SQL-Oberflächenbereich in Microsoft Fabric. Erwägen Sie auch eine Codebewertung, wenn Sie Methoden der Migration für den Datenbankcode (DML) auswählen.
Je nach den Paritätsunterschieden zum Zeitpunkt der Migration müssen Sie möglicherweise Teile Ihres T-SQL DML-Codes neu schreiben.
Unterschiede bei der Datentypzuordnung
Es gibt mehrere Datentypunterschiede in Fabric Warehouse. Weitere Informationen finden Sie unter Datentypen in Microsoft Fabric.
Die folgende Tabelle enthält die Zuordnung unterstützter Datentypen aus Synapse dedizierten SQL-Pools zu Fabric Warehouse.
| Synapse dedizierte SQL-Pools | Fabric Warehouse |
|---|---|
| money | dezimal (19,4) |
| smallmoney | dezimal (10,4) |
| smalldatetime | datetime2 |
| datetime | datetime2 |
| NCHAR | char |
| nvarchar | varchar |
| tinyint | smallint |
| BINARY | varbinary |
| datetimeoffset* | datetime2 |
* Datetime2 speichert nicht die zusätzlichen Offsetinformationen für Zeitzonen, die gespeichert sind. Da der Datentyp „datetimeoffset“ derzeit in Fabric Warehouse nicht unterstützt wird, müssen die Zeitzonenoffsetdaten in eine separate Spalte extrahiert werden.
Schema-, Code- und Datenmigrationsmethoden
Überprüfen und identifizieren Sie, welche dieser Optionen zu Ihrem Szenario, Mitarbeiterkompetenzen und den Merkmalen Ihrer Daten passen. Die ausgewählten Optionen hängen von Ihrer Erfahrung, Ihren Vorlieben und den Vorteilen der einzelnen Tools ab. Unser Ziel ist es, weiterhin Migrationstools zu entwickeln, die Reibungsverluste und manuelle Eingriffe reduzieren, um Migrationen nahtlos zu gestalten.
In dieser Tabelle werden Informationen zu Datenschemamethoden (Data Schema, DDL), Datenbankcode (DML) und Datenmigrationsmethoden zusammengefasst. Die einzelnen Szenarien werden später in diesem Artikel in der Spalte Optionen näher erläutert.
| Optionsnummer | Option | Was sie tut | Qualifikation/Einstellung | Szenario |
|---|---|---|---|---|
| 1 | Data Factory | Schemakonvertierung (DDL) Datenextraktion Datenerfassung |
ADF/Pipeline | Vereinfacht alles in einem Schema (DDL) und Datenmigration. Empfohlen für Dimensionstabellen. |
| 2 | Data Factory mit Partition | Schemakonvertierung (DDL) Datenextraktion Datenerfassung |
ADF/Pipeline | Verwenden von Partitionierungsoptionen zum Erhöhen des Lese-/Schreib-Parallelismus mit 10x-Durchsatz im Vergleich zu Option 1, empfohlen für Faktentabellen. |
| 3 | Data Factory mit beschleunigtem Code | Schemakonvertierung (DDL) | ADF/Pipeline | Konvertieren und migrieren Sie zuerst das Schema (DDL), und verwenden Sie dann CETAS zum Extrahieren und COPY/Data Factory, um Daten für eine optimale Gesamtaufnahmeleistung aufzunehmen. |
| 4 | Gespeicherte Prozeduren beschleunigten Code | Schemakonvertierung (DDL) Datenextraktion Codebewertung |
T-SQL | SQL-Benutzer, der IDE verwendet, mit genauerer Kontrolle darüber, an welchen Aufgaben sie arbeiten möchten. Verwenden Sie COPY/Data Factory, um Daten zu erfassen. |
| 5 | Erweiterung „SQL Server-Datenbankprojekt“ für Azure Data Studio | Schemakonvertierung (DDL) Datenextraktion Codebewertung |
SQL-Projekt | SQL-Datenbankprojekt für die Bereitstellung mit der Integration von Option 4. Verwenden Sie COPY oder Data Factory, um Daten zu erfassen. |
| 6 | CREATE EXTERNAL TABLE AS SELECT (CETAS) | Datenextraktion | T-SQL | Kostengünstige und leistungsstarke Datenextraktion in Azure Data Lake Storage (ADLS) Gen2. Verwenden Sie COPY/Data Factory, um Daten zu erfassen. |
| 7 | Migrieren mithilfe von dbt | Schemakonvertierung (DDL) Konvertierung von Datenbankcode (DML) |
dbt | Vorhandene dbt-Benutzer können den dbt Fabric-Adapter verwenden, um ihre DDL und DML zu konvertieren. Anschließend müssen Sie Daten mithilfe anderer Optionen in dieser Tabelle migrieren. |
Auswählen einer Workload für die erste Migration
Wenn Sie entscheiden, wo Sie mit dem dedizierten SQL-Pool Synapse für das Fabric Warehouse-Migrationsprojekt beginnen möchten, wählen Sie einen Workloadbereich aus, in dem Sie folgendes tun können:
- Belegen der Machbarkeit einer Migration zu Fabric Warehouse durch schnelles Bereitstellen der Vorteile der neuen Umgebung. Klein und einfach anfangen, sich auf mehrere kleine Migrationen vorbereiten.
- Ermöglichen Sie Ihren internen technischen Mitarbeitern, Zeit für relevante Erfahrungen mit den Prozessen und Tools zu sammeln, die sie verwenden werden, wenn sie andere Bereiche migrieren.
- Erstellen Sie eine Vorlage für weitere Migrationen, die speziell auf die Synapse-Quellumgebung und die vorhandenen Tools und Prozesse zugeschnitten ist.
Tipp
Führen Sie eine Inventur der zu migrierenden Objekte durch und dokumentieren Sie den Migrationsprozess von Anfang bis Ende, so dass er für andere dedizierte SQL-Pools oder Workloads wiederholt werden kann.
Das Volumen der migrierten Daten in der ersten Migration sollte groß genug sein, um die Möglichkeiten und Vorteile der Fabric Warehouse-Umgebung aufzuzeigen, aber nicht zu groß, damit der Nutzen schnell veranschaulicht werden kann. In der Regel liegt die Größe im Bereich von 1 bis 10 TB.
Migration mit Fabric Data Factory
In diesem Abschnitt werden die Optionen mit Data Factory für die Zielgruppe mit Low-Code/No-Code erläutert, die mit Azure Data Factory und Synapse Pipeline vertraut sind. Diese Option zum Ziehen und Ablegen der Benutzeroberfläche bietet einen einfachen Schritt zum Konvertieren der DDL und zum Migrieren der Daten.
Fabric Data Factory kann die folgenden Aufgaben ausführen:
- Konvertieren des Schemas (DDL) in die Fabric Warehouse-Syntax.
- Erstellen des Schemas (DDL) auf Fabric Warehouse.
- Migrieren der Daten zu Fabric Warehouse.
Option 1. Schema-/Datenmigration – Kopier-Assistent und ForEach-Copy-Aktivität
Diese Methode verwendet den Data Factory Copy-Assistenten, um eine Verbindung mit dem dedizierten SQL-Quellpool herzustellen, die dedizierte DDL-Syntax des SQL-Pools in Fabric zu konvertieren und Daten in Fabric Warehouse zu kopieren. Sie können 1 oder mehr Zieltabellen auswählen (für das TPC-DS-Dataset gibt es 22 Tabellen). Das Programm generiert ForEach, um eine Schleife durch die Liste der in der Benutzeroberfläche ausgewählten Tabellen zu ziehen und 22 parallele Copy-Aktivität-Threads zu erzeugen.
- 22 SELECT-Abfragen (eine für jede ausgewählte Tabelle) wurden generiert und im dedizierten SQL-Pool ausgeführt.
- Stellen Sie sicher, dass Sie über die entsprechende DWU- und Ressourcenklasse verfügen, damit die generierten Abfragen ausgeführt werden können. In diesem Fall benötigen Sie mindestens DWU1000,
staticrc10damit maximal 32 Abfragen 22 übermittelte Abfragen verarbeiten können. - Das direkte Kopieren von Daten aus dem dedizierten SQL-Pool in Fabric Warehouse erfordert einen Stagingprozess. Der Erfassungsprozess umfasst zwei Phasen.
- Die erste Phase besteht aus dem Extrahieren der Daten aus dem dedizierten SQL-Pool in ADLS und wird als „Staging“ bezeichnet.
- Die zweite Phase besteht aus der Erfassung der Daten aus dem Staging in Fabric Warehouse. Der größte Teil der Datenerfassung findet in der Stagingphase statt. Zusammenfassend wirkt sich das Staging auf die Erfassungsleistung aus.
Empfohlene Verwendung
Die Verwendung des Kopier-Assistenten zur Erstellung eines ForEach bietet eine einfache Benutzeroberfläche zur Konvertierung von DDL und zum Einlesen der ausgewählten Tabellen aus dem dedizierten SQL-Pool in Fabric Warehouse in einem Schritt.
Allerdings ist es nicht optimal für den Gesamtdurchsatz. Die Anforderung, Staging zu verwenden, und die Notwendigkeit, Lese- und Schreibvorgänge für den Schritt „Source to Stage“ zu parallelisieren, sind die Hauptfaktoren für die Leistungslatenz. Es wird empfohlen, diese Option nur für Dimensionstabellen zu verwenden.
Option 2. DDL/Datenmigration – Datenpipeline mit Partitionsoption
Um den Durchsatz beim Laden größerer Faktentabellen mit der Datenpipeline von Fabric zu verbessern, wird empfohlen, die Option „Aktivität kopieren“ für jede Faktentabelle mit Partition zu verwenden. Dies bietet die beste Leistung mit Copy-Aktivität.
Sie haben die Möglichkeit, die physische Partitionierung der Quelltabelle zu verwenden, falls verfügbar. Wenn die Tabelle keine physische Partitionierung hat, müssen Sie die Partitionsspalte angeben und Min/Max-Werte liefern, um die dynamische Partitionierung zu verwenden. Im folgenden Screenshot geben die Optionen der Datenpipeline Quelle einen dynamischen Bereich von Partitionen auf der Grundlage der ws_sold_date_sk Spalte an.
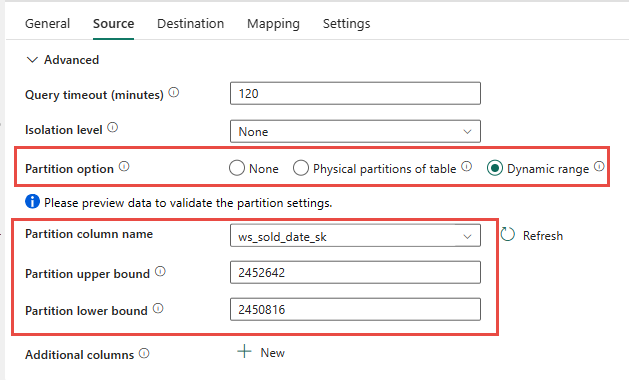
Während die Verwendung der Partition den Durchsatz mit der Stagingphase erhöhen kann, gibt es Überlegungen, die entsprechenden Anpassungen vorzunehmen:
- Abhängig von Ihrem Partitionsbereich werden möglicherweise alle Parallelitätsslots verwendet, da mehr als 128 Abfragen auf dem dedizierten SQL-Pool erstellt werden können.
- Sie müssen auf ein Minimum von DWU6000 skalieren, damit alle Abfragen ausgeführt werden können.
- Beispielsweise wurden für die TPC-DS-Tabelle
web_sales163 Abfragen an den dedizierten SQL-Pool übermittelt. Bei DWU6000 wurden 128 Abfragen ausgeführt, während 35 Abfragen in die Warteschlange gestellt wurden. - Dynamische Partition wählt automatisch die Bereichspartition aus. In diesem Fall wird ein 11-tägiger Bereich für jede SELECT-Abfrage an den dedizierten SQL-Pool übermittelt. Beispiel:
WHERE [ws_sold_date_sk] > '2451069' AND [ws_sold_date_sk] <= '2451080') ... WHERE [ws_sold_date_sk] > '2451333' AND [ws_sold_date_sk] <= '2451344')
Empfohlene Verwendung
Für Faktentabellen empfehlen wir die Verwendung von Data Factory mit Partitionierungsoption, um den Durchsatz zu erhöhen.
Die erhöhten parallelisierten Lesevorgänge erfordern jedoch einen dedizierten SQL-Pool, um eine Skalierung auf eine höhere DWU zu ermöglichen, damit die Extraktabfragen ausgeführt werden können. Durch die Partitionierung wird die Rate im Vergleich zur Option ohne Partitionierung um das 10-fache verbessert. Sie könnten die DWU erhöhen, um zusätzlichen Durchsatz über Computeressourcen zu erhalten, aber der dedizierte SQL-Pool lässt maximal 128 aktive Abfragen zu.
Hinweis
Weitere Informationen zur Zuordnung von Synapse-DWU zu Fabric finden Sie im Blog: Zuordnen von Azure Synapse zugeteilten SQL-Pools zu Fabric Data Warehouse-Compute.
Option 3. DDL-Migration – Kopier-Assistent forEach Copy-Aktivität
Die beiden vorherigen Optionen sind gute Möglichkeiten zur Datenmigration für kleinere Datenbanken. Wenn Sie jedoch einen höheren Durchsatz benötigen, empfehlen wir eine alternative Option:
- Extrahieren Sie die Daten aus dem dedizierten SQL-Pool in ADLS und verringern Sie so den Aufwand für die Stage Leistung.
- Verwenden Sie entweder Data Factory oder den Befehl COPY, um die Daten in Fabric Warehouse zu erfassen.
Empfohlene Verwendung
Sie können weiterhin Data Factory verwenden, um Ihr Schema (DDL) zu konvertieren. Mit dem Kopier-Assistenten können Sie die bestimmte Tabelle oder Alle Tabellenauswählen. Dadurch werden das Schema und die Daten in einem Schritt migriert. Dabei wird das Schema ohne Zeilen extrahiert, indem die falsche Bedingung TOP 0 in der Abfrageanweisung verwendet wird.
Im folgenden Codebeispiel wird die Schemamigration (DDL) mit Data Factory behandelt.
Codebeispiel: Schemamigration (DDL) mit Data Factory
Sie können Fabric Data Pipelines verwenden, um Ihre DDL (Schemata) für Tabellenobjekte aus einer beliebigen Azure SQL-Datenbank oder einem dedizierten SQL-Pool einfach zu migrieren. Diese Datenpipeline migriert das Schema (DDL) für die dedizierten SQL-Pool-Tabellen der Quelle zu Fabric Warehouse.
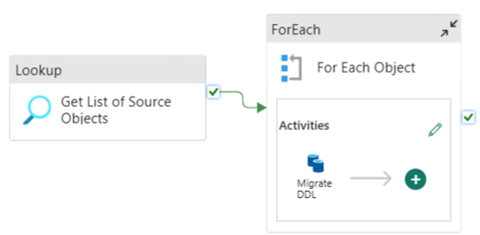
Pipelineentwurf: Parameter
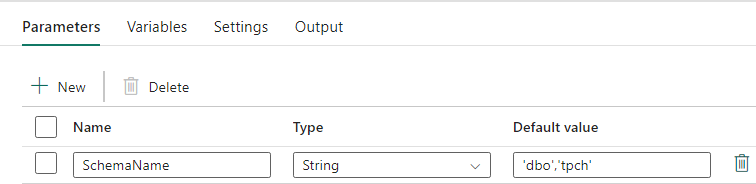
Diese Daten-Pipeline akzeptiert einen Parameter SchemaName, mit dem Sie angeben können, welche Schemata migriert werden sollen. Das dbo Schema ist die Standardeinstellung.
Geben Sie in das Feld Standardwert eine durch Komma getrennte Liste von Tabellenschemata ein, die angibt, welche Schemata migriert werden sollen: 'dbo','tpch' um zwei Schemata bereitzustellen, dbo und tpch.
Pipelineentwurf: Lookup-Aktivität
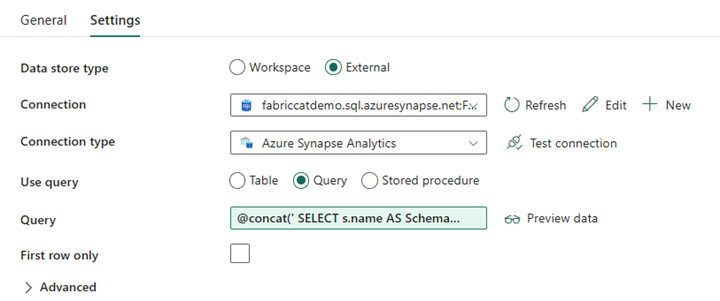
Erstellen Sie eine Lookup-Aktivität, und legen Sie die Verbindung so fest, dass sie auf Ihre Quelldatenbank verweist.
Auf der Registerkarte Einstellungen:
Setzen Sie den Datenspeichertyp auf Extern.
Die Verbindung ist Ihr dedizierter SQL-Pool in Azure Synapse. Verbindungstyp ist Azure Synapse Analytics.
Verwendungsabfrage ist auf Abfrage festgelegt.
Das Feld Abfrage muss mit Hilfe eines dynamischen Ausdrucks erstellt werden, damit der Parameter SchemaName in einer Abfrage verwendet werden kann, die eine Liste von Zielquelltabellen zurückgibt. Wählen Sie Abfrage und dann Dynamischen Inhalt hinzufügen aus.
Dieser Ausdruck innerhalb der Lookup-Aktivität generiert eine SQL-Anweisung zur Abfrage der Systemansichten, um eine Liste von Schemas und Tabellen abzurufen. Verweist auf den SchemaName-Parameter, um das Filtern nach SQL-Schemas zu ermöglichen. Die Ausgabe ist ein Array von SQL-Schema und Tabellen, die als Eingabe in die ForEach-Aktivität verwendet werden.
Verwenden Sie den folgenden Code, um eine Liste aller Benutzertabellen mit ihrem Schemanamen zurückzugeben.
@concat(' SELECT s.name AS SchemaName, t.name AS TableName FROM sys.tables AS t INNER JOIN sys.schemas AS s ON t.type = ''U'' AND s.schema_id = t.schema_id AND s.name in (',coalesce(pipeline().parameters.SchemaName, 'dbo'),') ')
Pipelineentwurf: ForEach-Schleife
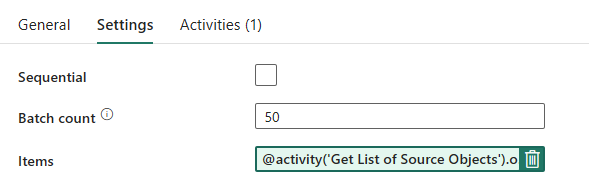
Konfigurieren Sie für die ForEach-Schleife die folgenden Optionen auf der Registerkarte Einstellungen:
- Deaktivieren Sie Sequenziell, damit mehrere Iterationen gleichzeitig ausgeführt werden können.
- Setzen Sie Batch-Anzahl auf
50, um die maximale Anzahl der gleichzeitigen Iterationen zu begrenzen. - Das Feld „Elemente“ muss dynamischen Inhalt verwenden, um auf die Ausgabe der Lookup-Aktivität zu verweisen. Verwenden Sie den folgenden Codeausschnitt:
@activity('Get List of Source Objects').output.value
Pipelineentwurf: Copy-Aktivität in der ForEach-Schleife
Fügen Sie in der ForEach-Aktivität eine Copy-Aktivität hinzu. Diese Methode verwendet die Dynamic Expression Language innerhalb von Data Pipelines, um ein SELECT TOP 0 * FROM <TABLE> Schema ohne Daten in ein Fabric Warehouse zu migrieren.
Auf der Registerkarte Quelle:
- Setzen Sie den Datenspeichertyp auf Extern.
- Die Verbindung ist Ihr dedizierter SQL-Pool in Azure Synapse. Verbindungstyp ist Azure Synapse Analytics.
- Setzen Sie Abfrage verwenden auf Abfrage.
- Fügen Sie im Feld Abfrage die dynamische Inhaltsabfrage ein und verwenden Sie diesen Ausdruck, der keine Zeilen, sondern nur das Tabellenschema zurückgibt:
@concat('SELECT TOP 0 * FROM ',item().SchemaName,'.',item().TableName)

Gehen Sie in der Registerkarte Ziel folgendermaßen vor:
- Setzen Sie den Datenspeichertyp auf Arbeitsbereich.
- Der Datenspeichertyp des Arbeitsbereichs ist Data Warehouse und das Data Warehouse ist auf das Fabric Warehouse eingestellt.
- Das Schema und der Tabellenname der Zieltabelle werden mithilfe dynamischer Inhalte definiert.
- Das Schema bezieht sich auf das Feld der aktuellen Iteration, SchemaName mit dem Codeschnipsel:
@item().SchemaName - Die Tabelle verweist auf TableName mit dem Codeschnipsel:
@item().TableName
- Das Schema bezieht sich auf das Feld der aktuellen Iteration, SchemaName mit dem Codeschnipsel:

Pipelineentwurf: Senke
Für Sink zeigen Sie auf Ihr Warehouse und verweisen auf das Quellschema und den Tabellennamen.
Nachdem Sie diese Pipeline ausgeführt haben, wird Ihr Data Warehouse mit jeder Tabelle in Ihrer Quelle mit dem richtigen Schema aufgefüllt.
Migration mit gespeicherten Prozeduren im dedizierten SQL-Pool von Synapse
Diese Option verwendet gespeicherte Prozeduren zum Ausführen der Fabric-Migration.
Sie können die Codebeispiele bei der Microsoft/Fabric-Migration auf GitHub.comabrufen. Dieser Code wird als Open Source freigegeben. Sie können also zur Zusammenarbeit beitragen und der Community helfen.
Was die gespeicherten Prozeduren für die Migration tun können:
- Konvertieren des Schemas (DDL) in die Fabric Warehouse-Syntax.
- Erstellen des Schemas (DDL) auf Fabric Warehouse.
- Extrahieren Sie Daten aus dem dedizierten SQL-Pool von Synapse in ADLS.
- Nicht unterstützte Fabric-Syntax für T-SQL-Codes (gespeicherte Prozeduren, Funktionen, Ansichten) markieren.
Empfohlene Verwendung
Dies ist eine großartige Option für diejenigen, die:
- Mit T-SQL vertraut sind.
- Eine integrierte Entwicklungsumgebung wie das SQL Server Management Studio (SSMS) verwenden möchten.
- Mehr Kontrolle darüber haben möchten, welche Aufgaben sie bearbeiten möchten.
Sie können die spezifische gespeicherte Prozedur für die Schemakonvertierung (DDL), den Datenextrakt oder die T-SQL-Codebewertung ausführen.
Für die Datenmigration müssen Sie entweder COPY INTO oder Data Factory verwenden, um die Daten in Fabric Warehouse zu erfassen.
Migration mit SQL-Datenbankprojekten
Microsoft Fabric Data Warehouse wird jetzt in der SQL-Datenbankprojekterweiterung unterstützt, die in Azure Data Studio und Visual Studio Code verfügbar ist.
Diese Erweiterung ist in Azure Data Studio und Visual Studio Code verfügbar. Dieses Feature ermöglicht Funktionen für Quellcodeverwaltung, Datenbanktests und Schemaüberprüfung.
Weitere Informationen zur Quellcodeverwaltung für Lagerorte in Microsoft Fabric, einschließlich Git-Integrations- und Bereitstellungspipelinen, finden Sie unter Quellcodeverwaltung mit Warehouse.
Empfohlene Verwendung
Dies ist eine gute Option für diejenigen, die SQL-Datenbankprojekt für die Bereitstellung verwenden möchten. Diese Option integrierte im Wesentlichen die gespeicherten Fabric-Prozeduren in das SQL-Datenbankprojekt, um eine nahtlose Migrationserfahrung zu ermöglichen.
Ein SQL-Datenbankprojekt kann:
- Konvertieren des Schemas (DDL) in die Fabric Warehouse-Syntax.
- Erstellen des Schemas (DDL) auf Fabric Warehouse.
- Extrahieren Sie Daten aus dem dedizierten SQL-Pool von Synapse in ADLS.
- Nicht unterstützte Syntax für T-SQL-Codes (gespeicherte Prozeduren, Funktionen, Ansichten) markieren.
Für die Datenmigration müssen Sie entweder COPY INTO oder Data Factory verwenden, um die Daten in Fabric Warehouse zu erfassen.
Um die Unterstützung von Azure Data Studio für Microsoft Fabric zu erweitern, hat das Microsoft Fabric CAT-Team eine Reihe von PowerShell-Skripten zur Verfügung gestellt, die die Extraktion, Erstellung und Bereitstellung von Schema (DDL) und Datenbankcode (DML) über ein SQL-Datenbankprojekt ermöglichen. Eine exemplarische Vorgehensweise zur Verwendung des SQL-Datenbankprojekts mit unseren hilfreichen PowerShell-Skripts finden Sie unter microsoft/fabric-migration zu GitHub.com.
Weitere Informationen zu den SQL-Datenbankprojekten finden Sie unter Erste Schritte mit der Erweiterung für SQL-Datenbankprojekte und Erstellen und Veröffentlichen eines Projekts.
Migration von Daten mit CETAS
Der Befehl T-SQL CREATE EXTERNAL TABLE AS SELECT (CETAS) bietet die kostengünstigste und optimale Methode zum Extrahieren von Daten aus Synapse dedizierten SQL-Pools in Azure Data Lake Storage (ADLS) Gen2.
Was CETAS tun kann:
- Daten nach ADLS extrahieren.
- Diese Option erfordert, dass Benutzer das Schema (DDL) in Fabric Warehouse erstellen, bevor die Daten erfasst werden. Berücksichtigen Sie die Optionen in diesem Artikel zum Migrieren des Schemas (DDL).
Die Vorteile dieser Option sind:
- Für den dedizierten SQL-Pool von Synapse wird nur eine einzelne Abfrage pro Tabelle übermittelt. Dadurch werden nicht alle Parallelitätsslots verwendet, sodass gleichzeitige ETL/Abfragen der Kundenproduktion nicht blockiert werden.
- Die Skalierung auf DWU6000 ist nicht erforderlich, da nur ein einzelner Parallelitätsslot für jede Tabelle verwendet wird, sodass Kunden niedrigere DWUs verwenden können.
- Der Extrakt wird parallel auf allen Serverknoten ausgeführt, und das ist der Schlüssel zur Verbesserung der Leistung.
Empfohlene Verwendung
Verwenden Sie CETAS, um die Daten als Parquet-Dateien in ADLS zu extrahieren. Parquet-Dateien bieten den Vorteil einer effizienten Datenspeicherung mit spaltenweiser Komprimierung, die weniger Bandbreite für die Übertragung über das Netzwerk benötigt. Da Fabric die Daten im Delta-Parket-Format gespeichert hat, ist die Datenaufnahme im Vergleich zum Textdateiformat außerdem 2,5 Mal schneller, da während der Aufnahme keine Konvertierung in das Delta-Format erforderlich ist.
So erhöhen Sie den CETAS-Durchsatz:
- Fügen Sie parallele CETAS Vorgänge hinzu, was die Nutzung von Parallelitätsslots erhöht, aber einen höheren Durchsatz ermöglicht.
- Skalierung der DWU auf dem dedizierten SQL-Pool von Synapse.
Migration über dbt
In diesem Abschnitt erfahren Sie mehr über die dbt-Option für Kunden, die dbt bereits in ihrer aktuellen dedizierten Synapse-SQL-Pool-Umgebung verwenden.
Was dbt tun kann:
- Konvertieren des Schemas (DDL) in die Fabric Warehouse-Syntax.
- Erstellen des Schemas (DDL) auf Fabric Warehouse.
- Konvertieren von Datenbankcode (DML) in Fabric-Syntax.
Das dbt-Framework generiert automatisch DDL- und DML-Skripts (SQL-Skripts) mit jeder Ausführung. Bei Modelldateien, die in SELECT-Anweisungen formuliert sind, kann die DDL/DML durch Ändern des Profils (Zeichenfolge) und des Adaptertyps sofort auf jede Zielplattform übertragen werden.
Empfohlene Verwendung
Das dbt-Framework ist ein Code-first-Ansatz. Die Daten müssen mithilfe der in diesem Dokument aufgeführten Optionen wie CETAS oder COPY/Data Factorymigriert werden.
Der dbt-Adapter für Microsoft Fabric Data Warehouse ermöglicht es, bestehende dbt-Projekte, die auf andere Plattformen wie dedizierte SQL-Pools in Synapse, Snowflake, Databricks, Google Big Query oder Amazon Redshift ausgerichtet waren, mit einer einfachen Konfigurationsänderung auf ein Fabric Warehouse zu migrieren.
Erste Schritte mit einem dbt-Projekt für Fabric Warehouse finden Sie im Tutorial: Einrichten von dbt für Fabric Data Warehouse. Dieses Dokument enthält auch eine Option für den Wechsel zwischen verschiedenen Warehouses/Plattformen.
Datenerfassung in Fabric Warehouse
Für die Erfassung in Fabric Warehouse verwenden Sie COPY INTO oder Fabric Data Factory, je nachdem, was Sie bevorzugen. Beide Methoden sind die empfohlenen und leistungsstärksten Optionen, da sie über einen entsprechenden Leistungsdurchsatz verfügen. Voraussetzung ist, dass die Dateien bereits in Azure Data Lake Storage (ADLS) Gen2 extrahiert werden.
Beachten Sie mehrere Faktoren, damit Sie Ihren Prozess für maximale Leistung entwerfen können:
- Mit Fabric gibt es keinen Ressourceninhalt beim gleichzeitigen Laden mehrerer Tabellen von ADLS in Fabric Warehouse. Daher gibt es keine Leistungsbeeinträchtigung beim Laden paralleler Threads. Der maximale Erfassungsdurchsatz wird nur durch die Computeleistung Ihrer Fabric-Kapazität begrenzt.
- Die Fabric-Workload-Verwaltung bietet eine Trennung der für Last und Abfragen zugewiesenen Ressourcen. Es gibt keine Ressourcenkonflikte, wenn Abfragen und das Laden von Daten gleichzeitig ausgeführt werden.