Lernprogramm: Entdecken von Beziehungen im Synthea-Dataset mit semantischer Verknüpfung
In diesem Lernprogramm wird veranschaulicht, wie Beziehungen im öffentlichen Synthea Datensatz mithilfe semantischer Verknüpfungen erkannt werden.
Wenn Sie mit neuen Daten arbeiten oder ohne ein vorhandenes Datenmodell arbeiten, kann es hilfreich sein, Beziehungen automatisch zu ermitteln. Diese Beziehungserkennung kann Ihnen dabei helfen:
- Das Modell auf hoher Ebene verstehen,
- Gewinnen Sie mehr Einblicke während der explorativen Datenanalyse.
- Überprüfen aktualisierter Daten oder neuer, eingehender Daten und
- Daten bereinigen
Auch wenn Beziehungen im Voraus bekannt sind, kann eine Suche nach Beziehungen helfen, das Datenmodell besser zu verstehen oder Probleme mit der Datenqualität zu identifizieren.
In diesem Lernprogramm beginnen Sie mit einem einfachen Basisplanbeispiel, in dem Sie mit nur drei Tabellen experimentieren, sodass Verbindungen zwischen ihnen leicht zu verfolgen sind. Anschließend zeigen Sie ein komplexeres Beispiel mit einem größeren Tabellensatz an.
In diesem Lernprogramm erfahren Sie, wie Sie:
- Verwenden Sie Komponenten der Python-Bibliothek des semantischen Links (SemPy), die die Integration in Power BI unterstützen und die Datenanalyse automatisieren. Zu diesen Komponenten gehören:
- FabricDataFrame – eine pandasähnliche Struktur, die mit zusätzlichen semantischen Informationen erweitert wurde.
- Funktionen zum Abrufen von semantischen Modellen aus einem Fabric-Arbeitsbereich in Ihr Notizbuch.
- Funktionen, die die Ermittlung und Visualisierung von Beziehungen in Ihren semantischen Modellen automatisieren.
- Problembehandlung beim Prozess der Beziehungsermittlung für semantische Modelle mit mehreren Tabellen und Abhängigkeiten.
Voraussetzungen
Erwerben Sie ein Microsoft Fabric-Abonnement. Oder registrieren Sie sich für eine kostenlose Microsoft Fabric-Testversion.
Melden Sie sich bei Microsoft Fabrican.
Verwenden Sie den Erfahrungsschalter auf der unteren linken Seite Ihrer Startseite, um zu Fabric zu wechseln.

- Wählen Sie Arbeitsbereiche im linken Navigationsbereich aus, um Ihren Arbeitsbereich zu suchen und auszuwählen. Dieser Arbeitsbereich wird zu Ihrem aktuellen Arbeitsbereich.
Notebook für das Tutorial
In diesem Tutorial wird das Notebook relationships_detection_tutorial.ipynb verwendet.
Zum Öffnen des zugehörigen Notizbuchs für dieses Lernprogramm folgen Sie den Anweisungen in Vorbereiten Ihres Systems für Data Science-Lernprogramme, um das Notizbuch in Ihren Arbeitsbereich zu importieren.
Wenn Sie den Code lieber von dieser Seite kopieren und einfügen möchten, können Sie ein neues Notizbucherstellen.
Fügen Sie unbedingt ein Lakehouse an das Notebook an, bevor Sie mit der Ausführung von Code beginnen.
Einrichten des Notizbuchs
In diesem Abschnitt richten Sie eine Notizbuchumgebung mit den erforderlichen Modulen und Daten ein.
Installieren Sie
SemPyvon PyPI mithilfe der%pipInlineinstallationsfunktion im Notizbuch:%pip install semantic-linkFühren Sie die erforderlichen Importe von SemPy-Modulen durch, die Sie später benötigen:
import pandas as pd from sempy.samples import download_synthea from sempy.relationships import ( find_relationships, list_relationship_violations, plot_relationship_metadata )Importieren Sie pandas, um eine Konfigurationsoption durchzusetzen, die bei der Formatierung der Ausgabe hilft.
import pandas as pd pd.set_option('display.max_colwidth', None)Rufen Sie die Beispieldaten ab. In diesem Tutorial verwenden Sie das Synthea-Dataset mit synthetischen medizinischen Datensätzen (zur Einfachheit eine Version mit geringem Umfang):
download_synthea(which='small')
Erkennen von Beziehungen in einer kleinen Teilmenge von Synthea Tabellen
Wählen Sie drei Tabellen aus einem größeren Satz aus:
patientsgibt Patienteninformationen anencountersgibt die Patienten an, die medizinische Begegnungen hatten (z. B. einen medizinischen Termin, Verfahren)providersgibt an, welche medizinischen Anbieter den Patienten beigewohnt haben
Die
encounters-Tabelle löst eine m:n-Beziehung zwischenpatientsundprovidersauf und kann als assoziative Entität beschrieben werden:patients = pd.read_csv('synthea/csv/patients.csv') providers = pd.read_csv('synthea/csv/providers.csv') encounters = pd.read_csv('synthea/csv/encounters.csv')Suchen von Beziehungen zwischen den Tabellen mithilfe der
find_relationships-Funktion von SemPy:suggested_relationships = find_relationships([patients, providers, encounters]) suggested_relationshipsVisualisieren Sie die Beziehungen von DataFrame als Diagramm, indem Sie die
plot_relationship_metadata-Funktion von SemPy verwenden.plot_relationship_metadata(suggested_relationships)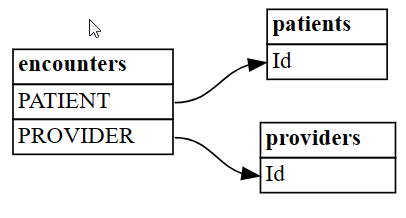
Die Funktion legt die Beziehungshierarchie von der linken Seite zur rechten Seite dar, die den Tabellen "von" und "zu" in der Ausgabe entspricht. Mit anderen Worten: Die unabhängigen From-Tabellen auf der linken Seite verwenden ihre Fremdschlüssel, um auf ihre To-Abhängigkeitstabellen auf der rechten Seite zu verweisen. Jedes Entitätsfeld zeigt Spalten an, die entweder an der From- oder To-Seite an einer Beziehung teilhaben.
Standardmäßig werden Beziehungen als "m:1" (nicht als "1:m") oder "1:1" generiert. Die Beziehungen "1:1" können auf eine oder beide Arten generiert werden, je nachdem, ob das Verhältnis der zugeordneten Werte zu allen Werten
coverage_thresholdin nur einer oder beiden Richtungen überschreitet. Später in diesem Lernprogramm behandeln Sie den weniger häufigen Fall von "m:m"-Beziehungen.

Behandeln von Problemen bei der Beziehungserkennung
Das Basisplanbeispiel zeigt eine erfolgreiche Erkennung von Beziehungen bei sauberen Synthea- Daten. In der Praxis sind die Daten selten sauber, was eine erfolgreiche Erkennung verhindert. Es gibt mehrere Techniken, die nützlich sein können, wenn die Daten nicht sauber sind.
In diesem Abschnitt dieses Lernprogramms wird die Beziehungserkennung behandelt, wenn das semantische Modell schmutzige Daten enthält.
Bearbeiten Sie zunächst die ursprünglichen DataFrames, um "schmutzige" Daten abzurufen, und drucken Sie die Größe der geänderten Daten.
# create a dirty 'patients' dataframe by dropping some rows using head() and duplicating some rows using concat() patients_dirty = pd.concat([patients.head(1000), patients.head(50)], axis=0) # create a dirty 'providers' dataframe by dropping some rows using head() providers_dirty = providers.head(5000) # the dirty dataframes have fewer records than the clean ones print(len(patients_dirty)) print(len(providers_dirty))Zum Vergleich: Druckgrößen der ursprünglichen Tabellen:
print(len(patients)) print(len(providers))Suchen von Beziehungen zwischen den Tabellen mithilfe der
find_relationships-Funktion von SemPy:find_relationships([patients_dirty, providers_dirty, encounters])Die Ausgabe des Codes zeigt, dass wegen der zuvor eingeführten Fehler keine Beziehungen erkannt werden und dadurch ein 'schmutziges' semantisches Modell erzeugt wird.
Validierung verwenden
Die Überprüfung ist das beste Tool für die Problembehandlung von Fehlern bei der Beziehungserkennung, da:
- Es meldet eindeutig, warum eine bestimmte Beziehung nicht den Regeln des Fremdschlüssels folgt und daher nicht erkannt werden kann.
- Sie wird schnell mit großen semantischen Modellen ausgeführt, da sie sich nur auf die deklarierten Beziehungen konzentriert und keine Suche durchführt.
Die Überprüfung kann jeden DataFrame mit Spalten verwenden, die dem von find_relationshipsgenerierten Datenmodell ähneln. Im folgenden Code bezieht sich der suggested_relationships DataFrame auf patients und nicht auf patients_dirty, Sie können jedoch die DataFrames mit einem Wörterbuch aliasen:
dirty_tables = {
"patients": patients_dirty,
"providers" : providers_dirty,
"encounters": encounters
}
errors = list_relationship_violations(dirty_tables, suggested_relationships)
errors
Lockerung der Suchkriterien
In komplizierteren Szenarien können Sie versuchen, Ihre Suchkriterien zu lockern. Diese Methode erhöht die Möglichkeit falsch positiver Ergebnisse.
Legen Sie
include_many_to_many=Truefest, und bewerten Sie, ob dies hilft:find_relationships(dirty_tables, include_many_to_many=True, coverage_threshold=1)Die Ergebnisse zeigen, dass die Beziehung von
encounterszupatientserkannt wurde, aber es gibt zwei Probleme:- Die Beziehung gibt eine Richtung von
patientszuencountersan, was eine Umkehrung der erwarteten Beziehung ist. Dies liegt daran, dass allepatientszufällig vonencountersabgedeckt wurden (Coverage Fromist 1,0), währendencountersnur teilweise vonpatients(Coverage To= 0,85) abgedeckt sind, da Zeilen von Patienten fehlen. - Es gibt eine versehentliche Übereinstimmung in einer
GENDER-Spalte mit niedriger Kardinalität, die nach Name und Wert in beiden Tabellen übereinstimmt, allerdings handelt es sich nicht um eine m:1-Beziehung von Interesse. Die niedrige Kardinalität wird durch die SpaltenUnique Count FromundUnique Count Toangegeben.
- Die Beziehung gibt eine Richtung von
Führen Sie den Vorgang
find_relationshipserneut aus, um nur nach m:1-Beziehungen zu suchen, aber mit einem niedrigeren Wert (coverage_threshold=0.5):find_relationships(dirty_tables, include_many_to_many=False, coverage_threshold=0.5)Das Ergebnis zeigt die richtige Richtung der Beziehungen von
encounterszuproviders. Die Beziehung vonencounterszupatientswird jedoch nicht erkannt, dapatientsnicht eindeutig ist, sodass sie sich nicht auf der 1-Seite der "m:1"-Beziehung befinden kann.Lösen Sie sowohl
include_many_to_many=Trueals auchcoverage_threshold=0.5:find_relationships(dirty_tables, include_many_to_many=True, coverage_threshold=0.5)Jetzt sind beide Interessenbeziehungen sichtbar, aber es gibt viel mehr Rauschen:
- Die Übereinstimmung mit niedriger Kardinalität bei
GENDERist vorhanden. - Eine m:m-Übereinstimmung mit höherer Kardinalität wurde für
ORGANIZATIONangezeigt, wodurch deutlich wird, dass dieORGANIZATION-Spalte wahrscheinlich für beide Tabellen denormalisiert ist.
- Die Übereinstimmung mit niedriger Kardinalität bei
Spaltennamen abgleichen
SemPy betrachtet standardmäßig nur Attribute, die eine Namensähnlichkeit aufweisen, und nutzt dabei die Tatsache, dass Datenbankdesigner in der Regel verwandte Spalten auf die gleiche Weise benennen. Dieses Verhalten trägt dazu bei, falsche Beziehungen zu vermeiden, die am häufigsten mit ganzzahligen Schlüsseln niedriger Kardinalität auftreten. Wenn z. B. 1,2,3,...,10 Produktkategorien und 1,2,3,...,10 Bestellstatuscode vorhanden sind, werden sie miteinander verwechselt, wenn nur Wertezuordnungen betrachtet werden, ohne Spaltennamen zu berücksichtigen. Falsche Beziehungen sollten mit GUID-ähnlichen Schlüsseln kein Problem sein.
SemPy betrachtet eine Ähnlichkeit zwischen Spaltennamen und Tabellennamen. Der Abgleich ist approximativ, und die Groß-/Kleinschreibung wird nicht beachtet. Es ignoriert die am häufigsten gefundenen "Decorator"-Teilzeichenfolgen wie "id", "code", "name", "key", "pk", "fk". Daher sind dies die häufigsten Übereinstimmungsfälle:
- Ein Attribut namens „column“ in der Entität „foo“ stimmt mit einem Attribut namens „column“ (auch „COLUMN“ oder „Column“) in der Entität „bar“ überein.
- Ein Attribut namens "column" in der Entität "foo" stimmt mit einem Attribut namens "column_id" in "bar" überein.
- ein Attribut namens 'bar' in der Entität 'foo' stimmt mit einem Attribut namens 'code' in 'bar' überein.
Durch den ersten Abgleich von Spaltennamen wird die Erkennung schneller ausgeführt.
Gleichen Sie die Spaltennamen ab:
- Um zu verstehen, welche Spalten zur weiteren Auswertung ausgewählt werden, verwenden Sie die Option
verbose=2(verbose=1listet nur die entitäten auf, die verarbeitet werden). - Der parameter
name_similarity_thresholdbestimmt, wie Spalten verglichen werden. Der Grenzwert „1“ gibt an, dass Sie nur an Übereinstimmungen in Höhe von 100 Prozent interessiert sind.
find_relationships(dirty_tables, verbose=2, name_similarity_threshold=1.0);Die Ausführung bei einer Ähnlichkeit von 100 Prozent lässt keine geringen Unterschiede zwischen Namen zu. In Ihrem Beispiel weisen die Tabellen eine Pluralform mit dem Suffix "s" auf, was zu keiner exakten Übereinstimmung führt. Diese Situationen werden gut mit der Standardeinstellung
name_similarity_threshold=0.8behandelt.- Um zu verstehen, welche Spalten zur weiteren Auswertung ausgewählt werden, verwenden Sie die Option
Führen Sie mit der Standardeinstellung
name_similarity_threshold=0.8erneut aus:find_relationships(dirty_tables, verbose=2, name_similarity_threshold=0.8);Beachten Sie, dass die ID für die Pluralform
patientsjetzt mit dem Singularpatientverglichen wird, ohne allzu viele andere überflüssige Vergleiche zur Ausführungszeit hinzuzufügen.Führen Sie mit der Standardeinstellung
name_similarity_threshold=0erneut aus:find_relationships(dirty_tables, verbose=2, name_similarity_threshold=0);Das Ändern
name_similarity_thresholdauf 0 ist das andere Extrem, und es zeigt an, dass Sie alle Spalten vergleichen möchten. Dies ist selten notwendig und führt zu erhöhter Ausführungszeit und falschen Übereinstimmungen, die überprüft werden müssen. Beobachten Sie die Anzahl der Vergleiche in der ausführlichen Ausgabe.
Zusammenfassung der Tipps zur Problembehandlung
- Beginnen Sie mit der exakten Übereinstimmung für m:1-Beziehungen (also mit den Standardwerten
include_many_to_many=Falseundcoverage_threshold=1.0). Dies ist in der Regel das, was Sie wollen. - Verwenden Sie einen schmalen Fokus auf kleineren Teilmengen von Tabellen.
- Verwenden Sie die Überprüfung, um Probleme mit der Datenqualität zu erkennen.
- Verwenden Sie
verbose=2, wenn Sie verstehen möchten, welche Spalten für die Beziehung berücksichtigt werden. Dies kann zu einer großen Menge an Output führen. - Achten Sie auf Kompromisse bei Suchargumenten.
include_many_to_many=Trueundcoverage_threshold<1.0können scheinbare Beziehungen erzeugen, die schwieriger zu analysieren sind und gefiltert werden müssen.
Erkennen von Beziehungen im vollständigen Synthea--Datensatz
Das einfache Basisplanbeispiel war ein praktisches Lern- und Problembehandlungstool. In der Praxis können Sie mit einem semantischen Modell wie dem vollständigen Synthea Dataset beginnen, das viel mehr Tabellen enthält. Erkunden Sie den vollständigen synthea Datensatz wie folgt.
Alle Dateien aus dem synthea/csv Verzeichnis lesen:
all_tables = { "allergies": pd.read_csv('synthea/csv/allergies.csv'), "careplans": pd.read_csv('synthea/csv/careplans.csv'), "conditions": pd.read_csv('synthea/csv/conditions.csv'), "devices": pd.read_csv('synthea/csv/devices.csv'), "encounters": pd.read_csv('synthea/csv/encounters.csv'), "imaging_studies": pd.read_csv('synthea/csv/imaging_studies.csv'), "immunizations": pd.read_csv('synthea/csv/immunizations.csv'), "medications": pd.read_csv('synthea/csv/medications.csv'), "observations": pd.read_csv('synthea/csv/observations.csv'), "organizations": pd.read_csv('synthea/csv/organizations.csv'), "patients": pd.read_csv('synthea/csv/patients.csv'), "payer_transitions": pd.read_csv('synthea/csv/payer_transitions.csv'), "payers": pd.read_csv('synthea/csv/payers.csv'), "procedures": pd.read_csv('synthea/csv/procedures.csv'), "providers": pd.read_csv('synthea/csv/providers.csv'), "supplies": pd.read_csv('synthea/csv/supplies.csv'), }Suchen von Beziehungen zwischen den Tabellen mithilfe der
find_relationships-Funktion von SemPy:suggested_relationships = find_relationships(all_tables) suggested_relationshipsVisualisieren von Beziehungen:
plot_relationship_metadata(suggested_relationships)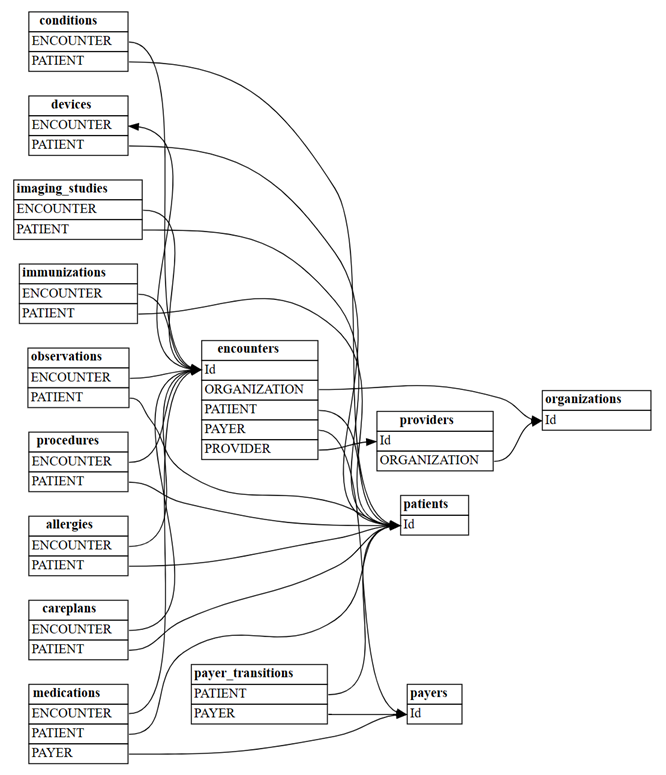
Zählen Sie, wie viele neue "m:m"-Beziehungen mit
include_many_to_many=Trueentdeckt werden. Diese Beziehungen sind zusätzlich zu den zuvor gezeigten "m:1"-Beziehungen; Daher müssen Sie nachmultiplicityfiltern:suggested_relationships = find_relationships(all_tables, coverage_threshold=1.0, include_many_to_many=True) suggested_relationships[suggested_relationships['Multiplicity']=='m:m']Sie können die Beziehungsdaten nach verschiedenen Spalten sortieren, um ein tieferes Verständnis ihrer Art zu erhalten. Sie können z. B. die Ausgabe nach
Row Count FromundRow Count Tosortieren, wodurch die größten Tabellen identifiziert werden können.suggested_relationships.sort_values(['Row Count From', 'Row Count To'], ascending=False)In einem anderen semantischen Modell wäre es vielleicht wichtig, sich auf die Anzahl der Nullen
Null Count FromoderCoverage Tozu konzentrieren.Diese Analyse kann Ihnen helfen zu verstehen, ob eine der Beziehungen ungültig sein könnte, und wenn Sie sie aus der Liste der Kandidaten entfernen müssen.

Verwandte Inhalte
Schauen Sie sich weitere Lernprogramme für semantischen Link / SemPy an:
- Lernprogramm: Bereinigen von Daten mit funktionalen Abhängigkeiten
- Lernprogramm: Analysieren funktionaler Abhängigkeiten in einem Beispielsemantikmodell
- Lernprogramm: Entdecken von Beziehungen in einem Semantikmodell mithilfe von semantischen Verknüpfungen
- Lernprogramm: Extrahieren und Berechnen von Power BI-Measures aus einem Jupyter-Notizbuch