Lernprogramm: Bereinigen von Daten mit funktionalen Abhängigkeiten
In diesem Lernprogramm verwenden Sie funktionale Abhängigkeiten für die Datenreinigung. Eine funktionale Abhängigkeit ist vorhanden, wenn eine Spalte in einem semantischen Modell (ein Power BI-Dataset) eine Funktion einer anderen Spalte ist. Beispielsweise kann eine Postleitzahl Spalte die Werte in einer Stadt Spalte bestimmen. Eine funktionale Abhängigkeit zeigt sich als eine Eins-zu-viele-Beziehung zwischen den Werten in zwei oder mehr Spalten in einem DataFrame. In diesem Lernprogramm wird das Synthea-Dataset verwendet, um zu zeigen, wie funktionale Beziehungen helfen können, Probleme mit der Datenqualität zu erkennen.
In diesem Lernprogramm erfahren Sie, wie Sie:
- Wenden Sie Domänenwissen an, um Hypothesen zu funktionalen Abhängigkeiten in einem semantischen Modell zu formulieren.
- Machen Sie sich mit den Komponenten der Python-Bibliothek von Semantic Link (SemPy) vertraut, die bei der Automatisierung der Datenqualitätsanalyse helfen. Zu diesen Komponenten gehören:
- FabricDataFrame – eine pandasähnliche Struktur, die mit zusätzlichen semantischen Informationen erweitert wurde.
- Nützliche Funktionen, die die Auswertung von Hypothesen zu funktionsbezogenen Abhängigkeiten automatisieren und Verstöße gegen Beziehungen in Ihren semantischen Modellen identifizieren.
Voraussetzungen
Abonnieren Sie ein Microsoft Fabric-Abonnement. Oder registrieren Sie sich für eine kostenlose Microsoft Fabric-Testversion.
Melden Sie sich bei Microsoft Fabrican.
Verwenden Sie den Erfahrungsschalter auf der unteren linken Seite Ihrer Startseite, um zu Fabric zu wechseln.

- Wählen Sie Arbeitsbereiche im linken Navigationsbereich aus, um Ihren Arbeitsbereich zu suchen und auszuwählen. Dieser Arbeitsbereich wird zu Ihrem aktuellen Arbeitsbereich.
Durchführung im Notebook
Das Notebook data_cleaning_functional_dependencies_tutorial.ipynb ist diesem Tutorial beigefügt.
Zum Öffnen des zugehörigen Notizbuchs für dieses Lernprogramm folgen Sie den Anweisungen in Vorbereiten Ihres Systems für Data Science-Lernprogramme, um das Notizbuch in Ihren Arbeitsbereich zu importieren.
Wenn Sie den Code lieber von dieser Seite kopieren und einfügen möchten, können Sie ein neues Notizbucherstellen.
Fügen Sie ein Lakehouse an das Notebook an, bevor Sie mit der Ausführung von Code beginnen.
Einrichten des Notizbuchs
In diesem Abschnitt richten Sie eine Notizbuchumgebung mit den erforderlichen Modulen und Daten ein.
- Für Spark 3.4 und höher ist der semantische Link bei Verwendung von Fabric in der Standardlaufzeit verfügbar und muss nicht installiert werden. Wenn Sie Spark 3.3 oder darunter verwenden oder auf die neueste Version von Semantic Link aktualisieren möchten, können Sie den Befehl ausführen:
python %pip install -U semantic-link
Führen Sie die erforderlichen Importe von Modulen aus, die Sie später benötigen:
import pandas as pd import sempy.fabric as fabric from sempy.fabric import FabricDataFrame from sempy.dependencies import plot_dependency_metadata from sempy.samples import download_syntheaRufen Sie die Beispieldaten ab. In diesem Tutorial verwenden Sie das Synthea-Dataset mit synthetischen medizinischen Datensätzen (zur Einfachheit eine Version mit geringem Umfang):
download_synthea(which='small')
Erkunden der Daten
Initialisieren Sie einen
FabricDataFrame-Element mit dem Inhalt der Datei providers.csv:providers = FabricDataFrame(pd.read_csv("synthea/csv/providers.csv")) providers.head()Überprüfen Sie auf Datenqualitätsprobleme mit der
find_dependenciesFunktion von SemPy, indem Sie ein Diagramm der automatisch erkannten funktionsbezogenen Abhängigkeiten darstellen:deps = providers.find_dependencies() plot_dependency_metadata(deps)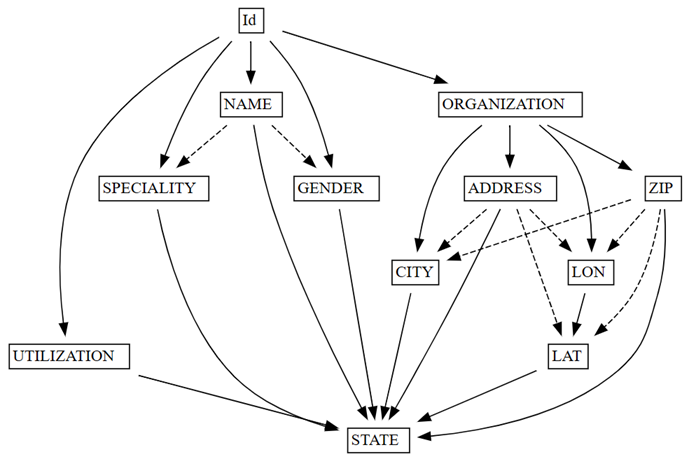
Das Diagramm der funktionalen Abhängigkeiten zeigt, dass
IdNAMEundORGANIZATIONbestimmt (angezeigt durch die durchgezogenen Pfeile), was zu erwarten ist, daIdeindeutig ist.Vergewissern Sie sich, dass
Ideindeutig ist:providers.Id.is_uniqueDer Code gibt
Truezurück, um zu bestätigen, dassIdeindeutig ist.

Analysieren funktionaler Abhängigkeiten im Detail
Das Diagramm mit funktionalen Abhängigkeiten zeigt auch, dass ORGANIZATIONADDRESS und ZIPwie erwartet bestimmt. Möglicherweise erwarten Sie jedoch, dass ZIP auch CITYbestimmen, aber der gestrichelte Pfeil weist darauf hin, dass die Abhängigkeit nur ungefähr ist und auf ein Problem mit der Datenqualität verweist.
Es gibt weitere Besonderheiten im Diagramm. Beispielsweise bestimmt NAME nicht GENDER, Id, SPECIALITYoder ORGANIZATION. Jede dieser Besonderheiten kann eine Untersuchung wert sein.
Werfen Sie einen tieferen Blick auf die ungefähre Beziehung zwischen
ZIPundCITY, indem Sie dielist_dependency_violations-Funktion von SemPy verwenden, um eine tabellarische Liste von Verletzungen zu sehen:providers.list_dependency_violations('ZIP', 'CITY')Zeichnen Sie ein Diagramm mit der
plot_dependency_violationsVisualisierungsfunktion von SemPy. Dieses Diagramm ist hilfreich, wenn die Anzahl der Verletzungen klein ist:providers.plot_dependency_violations('ZIP', 'CITY')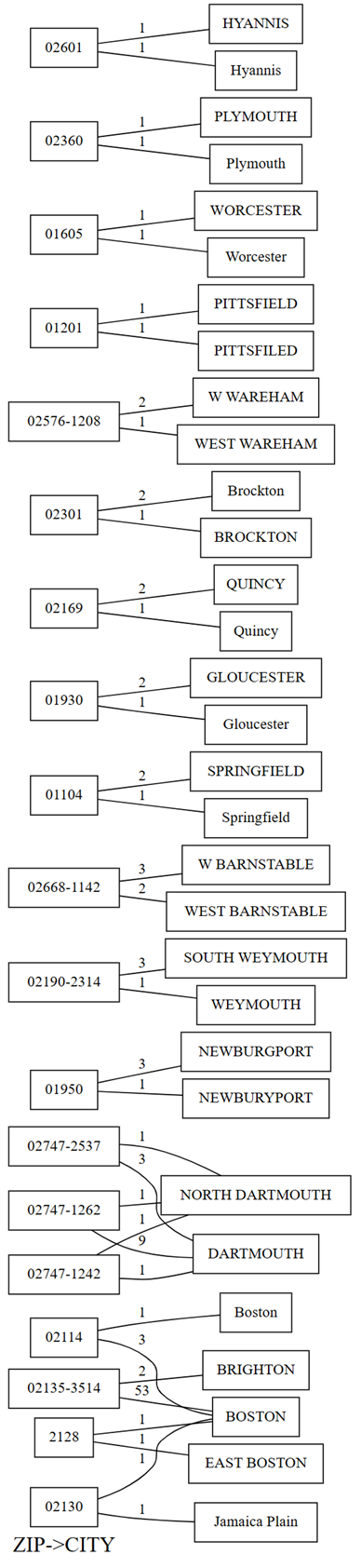
Die Darstellung von Abhängigkeitsverstößen zeigt Werte für
ZIPauf der linken Seite und Werte fürCITYauf der rechten Seite an. Ein Rand verbindet eine Postleitzahl auf der linken Seite des Grundstücks mit einer Stadt auf der rechten Seite, wenn eine Zeile mit diesen beiden Werten enthält. Die Ränder werden mit der Anzahl solcher Zeilen beschriftet. Beispielsweise gibt es zwei Zeilen mit Postleitzahl 02747-1242, eine Zeile mit der Stadt "NORTH DARTHMOUTH" und die andere mit der Stadt "DARTHMOUTH", wie in der vorherigen Zeichnung und dem folgenden Code gezeigt:Bestätigen Sie die Beobachtungen, die Sie im Plot der Abhängigkeitsverletzungen gemacht haben, indem Sie den folgenden Code ausführen:
providers[providers.ZIP == '02747-1242'].CITY.value_counts()Das Diagramm zeigt auch, dass unter den Zeilen, die "DARTHMOUTH" als
CITYhaben, neun Zeilen einenZIPvon 02747-1262 haben; eine Zeile hat einenZIPvon 02747-1242; und eine Zeile hat einenZIPvon 02747-2537. Bestätigt diese Beobachtungen mit dem folgenden Code:providers[providers.CITY == 'DARTMOUTH'].ZIP.value_counts()Es gibt andere Postleitzahlen, die mit "DARTMOUTH" verknüpft sind, aber diese Postleitzahlen werden nicht im Diagramm der Abhängigkeitsverstöße angezeigt, da sie nicht auf Probleme mit der Datenqualität hinweisen. Die Postleitzahl "02747-4302" ist beispielsweise eindeutig "DARTMOUTH" zugeordnet und wird nicht im Diagramm der Abhängigkeitsverstöße angezeigt. Bestätigen Sie, indem Sie den folgenden Code ausführen:
providers[providers.ZIP == '02747-4302'].CITY.value_counts()
Zusammenfassen von Problemen mit der Datenqualität, die mit SemPy erkannt wurden
Wenn Sie auf das Diagramm von Abhängigkeitsverstößen zurückgreifen, können Sie sehen, dass in diesem semantischen Modell mehrere interessante Probleme mit der Datenqualität auftreten:
- Einige Stadtnamen sind alle Großbuchstaben. Dieses Problem kann mit Zeichenfolgenmethoden problemlos behoben werden.
- Einige Stadtnamen haben Zusätze (oder Präfixe), wie beispielsweise "Nord" und "Ost". Beispiel: Die Postleitzahl „2128“ ist einmal „EAST BOSTON“ und einmal „BOSTON“ zugeordnet. Ein ähnliches Problem tritt zwischen "NORTH DARTHMOUTH" und "DARTHMOUTH" auf. Sie können versuchen, diese Qualifizierer wegzulassen oder die Postleitzahlen der Stadt mit den häufigsten Vorkommen zuzuordnen.
- In einigen Städten gibt es Tippfehler, z. B. "PITTSFIELD" vs. "PITTSFILED" und "NEWBURGPORT vs. "NEWBURYPORT". Bei "NEWBURGPORT" könnte dieser Tippfehler mithilfe des am häufigsten vorkommenden Typs behoben werden. Da „PITTSFIELD“ und „PITTSFILED“ nur je einmal vorkommen, ist eine automatische Auflösung der Mehrdeutigkeit ohne externes Wissen oder die Verwendung eines Sprachmodells wesentlich schwieriger.
- Manchmal werden Präfixe wie "West" mit einem einzelnen Buchstaben "W" abgekürzt. Dieses Problem könnte möglicherweise durch eine einfache Ersetzung behoben werden, wenn alle Vorkommen von "W" für "West" stehen.
- Die Postleitzahl „02130“ ist einmal „BOSTON“ und einmal „Jamaika Plain“ zugeordnet. Dieses Problem ist nicht einfach zu beheben, aber wenn mehr Daten vorhanden sind, könnte die Zuordnung zum häufigsten Vorkommen eine mögliche Lösung sein.
Bereinigen der Daten
Beheben Sie die Probleme mit der Groß-/Kleinschreibung, indem Sie alle Vorkommen so ändern, dass alle Wörter große Anfangsbuchstaben aufweisen:
providers['CITY'] = providers.CITY.str.title()Führen Sie die Verletzungserkennung erneut aus, um festzustellen, dass einige der Unklarheiten behoben wurden (die Anzahl der Verstöße ist geringer):
providers.list_dependency_violations('ZIP', 'CITY')An diesem Punkt könnten Sie Ihre Daten manuell verfeinern, aber eine potenzielle Datenbereinigungsaufgabe besteht darin, Zeilen abzulegen, die gegen funktionale Einschränkungen zwischen Spalten in den Daten verstoßen, indem Sie die
drop_dependency_violations-Funktion von SemPy verwenden.Für jeden Wert der Determinante funktioniert
drop_dependency_violations, indem der häufigste Wert der abhängigen Variablen ausgewählt wird und alle Zeilen mit anderen Werten entfernt werden. Sie sollten diesen Vorgang nur anwenden, wenn Sie sicher sind, dass diese statistische Heuristik zu den richtigen Ergebnissen für Ihre Daten führen würde. Andernfalls sollten Sie Ihren eigenen Code schreiben, um die erkannten Verstöße nach Bedarf zu behandeln.Führen Sie die
drop_dependency_violations-Funktion für die SpaltenZIPundCITYaus:providers_clean = providers.drop_dependency_violations('ZIP', 'CITY')Listen Sie alle Abhängigkeitsverletzungen zwischen
ZIPundCITYauf:providers_clean.list_dependency_violations('ZIP', 'CITY')Der Code gibt eine leere Liste zurück, um anzugeben, dass es keine weiteren Verstöße gegen die funktionale Einschränkung CITY -> ZIP-gibt.
Verwandte Inhalte
Schauen Sie sich weitere Lernprogramme für semantischen Link / SemPy an:
- Lernprogramm: Analysieren funktionaler Abhängigkeiten in einem Beispielsemantikmodell
- Lernprogramm: Extrahieren und Berechnen von Power BI-Measures aus einem Jupyter-Notizbuch
- Lernprogramm: Entdecken von Beziehungen in einem Semantikmodell mithilfe von semantischen Verknüpfungen
- Lernprogramm: Entdecken von Beziehungen im Synthea--Dataset mit semantischer Verknüpfung
- Lernprogramm: Überprüfen von Daten mithilfe von SemPy and Great Expectations (GX)