Verwenden von Tidyverse
Tidyverse ist eine Sammlung von R-Paketen, die Data Scientists häufig in alltäglichen Datenanalysen verwenden. Sie umfasst Pakete für Datenimport (readr), Datenvisualisierung (ggplot2), Datenbearbeitung (dplyr, tidyr), funktionale Programmierung (purrr) und Modellerstellung (tidymodels) usw. Die Pakete in tidyverse sind so konzipiert, dass sie nahtlos zusammenarbeiten und konsistenten Entwurfsprinzipien folgen.
Microsoft Fabric verteilt die neueste stabile Version von tidyverse mit jedem Runtime-Release. Importieren Sie Ihre vertrauten R-Pakete, und beginnen Sie mit der Verwendung.
Voraussetzungen
Erwerben Sie ein Microsoft Fabric-Abonnement. Registrieren Sie sich alternativ für eine kostenlose Microsoft Fabric-Testversion.
Melden Sie sich bei Microsoft Fabric an.
Verwenden Sie den Erfahrungsschalter auf der unteren linken Seite Ihrer Startseite, um zu Fabric zu wechseln.

Öffnen oder erstellen Sie ein Notebook. Informationen dazu finden Sie unter Verwenden von Microsoft Fabric-Notebooks.
Legen Sie zum Ändern der primären Sprache die Sprachoption auf SparkR (R) fest.
Verbinden Sie Ihr Notebook mit einem Lakehouse. Wählen Sie auf der linken Seite Hinzufügen aus, um ein vorhandenes Lakehouse hinzuzufügen oder ein Lakehouse zu erstellen.
Laden von tidyverse
# load tidyverse
library(tidyverse)
Datenimport
readr ist ein R-Paket, das Tools zum Lesen rechteckiger Datendateien wie CSV-, TSV-Dateien und Dateien mit fester Breite bereitstellt. readr bietet eine schnelle und benutzerfreundliche Möglichkeit zum Lesen rechteckiger Datendateien, z. B. Bereitstellung von read_csv()- und read_tsv()-Funktionen zum Lesen von CSV- bzw. TSV-Dateien.
Erstellen wir zunächst einen R-Datenrahmen (data.frame), schreiben Sie ihn mithilfe von readr::write_csv() in ein Lakehouse, und lesen sie ihn mit readr::read_csv() ein.
Hinweis
Um mithilfe von readr auf Lakehouse-Dateien zuzugreifen, müssen Sie den Datei-API-Pfad verwenden. Klicken Sie im Lakehouse-Explorer mit der rechten Maustaste auf die Datei oder den Ordner, auf die bzw. den Sie zugreifen möchten, und kopieren Sie den Datei-API-Pfad aus dem Kontextmenü.
# create an R data frame
set.seed(1)
stocks <- data.frame(
time = as.Date('2009-01-01') + 0:9,
X = rnorm(10, 20, 1),
Y = rnorm(10, 20, 2),
Z = rnorm(10, 20, 4)
)
stocks
Anschließend schreiben wir die Daten mithilfe des Datei-API-Pfads in ein Lakehouse.
# write data to lakehouse using the File API path
temp_csv_api <- "/lakehouse/default/Files/stocks.csv"
readr::write_csv(stocks,temp_csv_api)
Lesen Sie die Daten aus dem Lakehouse.
# read data from lakehouse using the File API path
stocks_readr <- readr::read_csv(temp_csv_api)
# show the content of the R date.frame
head(stocks_readr)
Datenbereinigung
tidyr ist ein R-Paket, das Tools zum Arbeiten mit unordentlichen Daten bereitstellt. Die Hauptfunktionen in tidyr sollen Ihnen helfen, Daten in ein übersichtliches Format umzustrukturieren. Übersichtliche Daten verfügen über eine bestimmte Struktur, wobei jede Variable eine Spalte und jede Beobachtung eine Zeile ist, was das Arbeiten mit Daten in R und anderen Tools erleichtert.
Beispielsweise kann die gather()-Funktion in tidyr verwendet werden, um breite Daten in lange Daten zu konvertieren. Hier sehen Sie ein Beispiel:
# convert the stock data into longer data
library(tidyr)
stocksL <- gather(data = stocks, key = stock, value = price, X, Y, Z)
stocksL
Funktionale Programmierung
purrr ist ein R-Paket, das das Toolkit für die funktionale Programmierung von R verbessert, indem es einen vollständigen und konsistenten Satz von Tools zum Arbeiten mit Funktionen und Vektoren bereitstellt. Der beste Ausgangspunkt von purrr ist die Familie von map()-Funktionen, mit denen Sie viele for-Schleifen durch Code ersetzen können, der sowohl prägnant als auch einfacher zu lesen ist. Hier sehen Sie ein Beispiel für die Verwendung von map(), um eine Funktion auf jedes Element einer Liste anzuwenden:
# double the stock values using purrr
library(purrr)
stocks_double = map(stocks %>% select_if(is.numeric), ~.x*2)
stocks_double
Datenmanipulation
dplyr ist ein R-Paket, das einen konsistenten Satz von Verben bereitstellt, die Ihnen helfen, die häufigsten Probleme bei der Datenbearbeitung zu lösen, z. B. das Auswählen von Variablen basierend auf den Namen, das Auswählen von Fällen basierend auf den Werten, das Reduzieren mehrerer Werte auf eine einzelne Zusammenfassung und das Ändern der Reihenfolge der Zeilen usw. Im Folgenden finden Sie einige Beispiele:
# pick variables based on their names using select()
stocks_value <- stocks %>% select(X:Z)
stocks_value
# pick cases based on their values using filter()
filter(stocks_value, X >20)
# add new variables that are functions of existing variables using mutate()
library(lubridate)
stocks_wday <- stocks %>%
select(time:Z) %>%
mutate(
weekday = wday(time)
)
stocks_wday
# change the ordering of the rows using arrange()
arrange(stocks_wday, weekday)
# reduce multiple values down to a single summary using summarise()
stocks_wday %>%
group_by(weekday) %>%
summarize(meanX = mean(X), n= n())
Datenvisualisierung
ggplot2 ist ein R-Paket zum deklarativen Erstellen von Grafiken, basierend auf dem Buch „The Grammar of Graphics“. Sie stellen die Daten bereit, geben ggplot2 an, wie Variablen der Ästhetik zugeordnet werden, welche grafischen Grundtypen verwendet werden sollen, und es kümmert sich um die Details. Hier sehen Sie einige Beispiele:
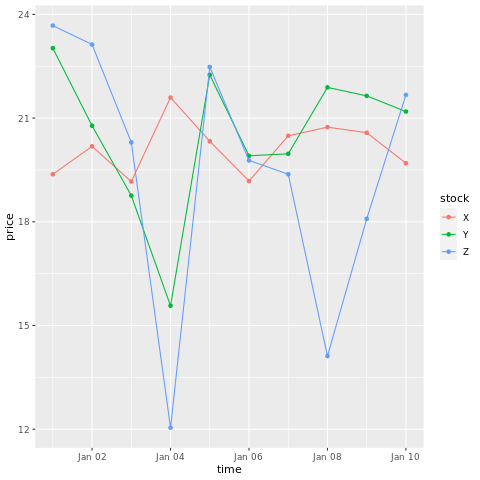
# draw a chart with points and lines all in one
ggplot(stocksL, aes(x=time, y=price, colour = stock)) +
geom_point()+
geom_line()
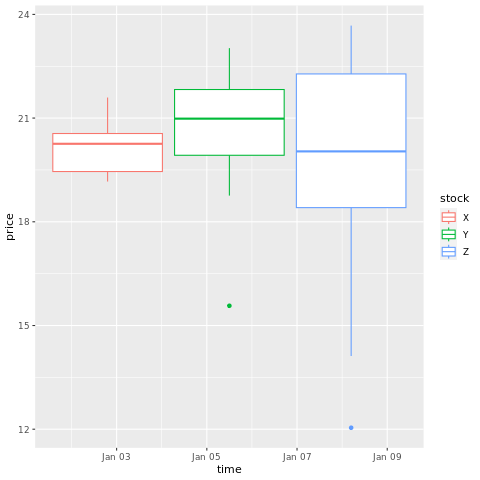
# draw a boxplot
ggplot(stocksL, aes(x=time, y=price, colour = stock)) +
geom_boxplot()
Modellerstellung
Das tidymodels-Framework ist eine Sammlung von Paketen für die Modellierung und maschinelles Lernen mithilfe von tidyverse-Prinzipien. Es enthält eine Liste der Kernpakete für eine Vielzahl von Modellerstellungsaufgaben, z. B. rsample für die Beispielaufteilung von Trainings-/Testdatasets, parsnip für die Modellspezifikation, recipes für die Vorverarbeitung von Daten, workflows für Modellierungsworkflows, tune für die Optimierung von Hyperparametern, yardstick für die Modellauswertung, broom für das Bereinigen von Modellausgaben und dials für die Verwaltung von Optimierungsparametern. Weitere Informationen zu den Paketen finden Sie auf der Tidymodels-Website. Hier finden Sie ein Beispiel für die Erstellung eines linearen Regressionsmodells, um die Meilen pro Gallone (mpg) eines Autos basierend auf seinem Gewicht (wt) vorherzusagen:
# look at the relationship between the miles per gallon (mpg) of a car and its weight (wt)
ggplot(mtcars, aes(wt,mpg))+
geom_point()
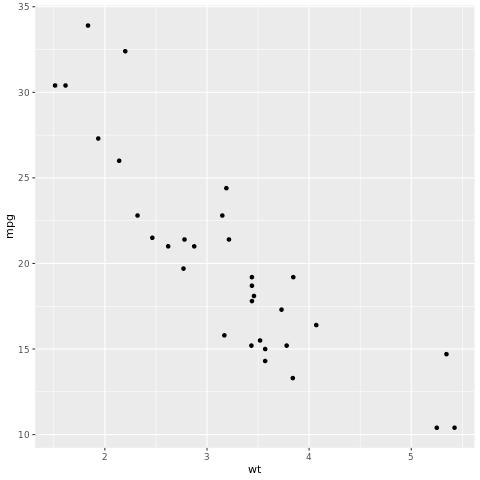
Auf dem Streudiagramm sieht die Beziehung annähernd linear aus, und die Varianz ist konstant. Versuchen wir, dies mithilfe einer linearen Regression zu modellieren.
library(tidymodels)
# split test and training dataset
set.seed(123)
split <- initial_split(mtcars, prop = 0.7, strata = "cyl")
train <- training(split)
test <- testing(split)
# config the linear regression model
lm_spec <- linear_reg() %>%
set_engine("lm") %>%
set_mode("regression")
# build the model
lm_fit <- lm_spec %>%
fit(mpg ~ wt, data = train)
tidy(lm_fit)
Wenden Sie das lineare Regressionsmodell an, um das Testdataset vorherzusagen.
# using the lm model to predict on test dataset
predictions <- predict(lm_fit, test)
predictions
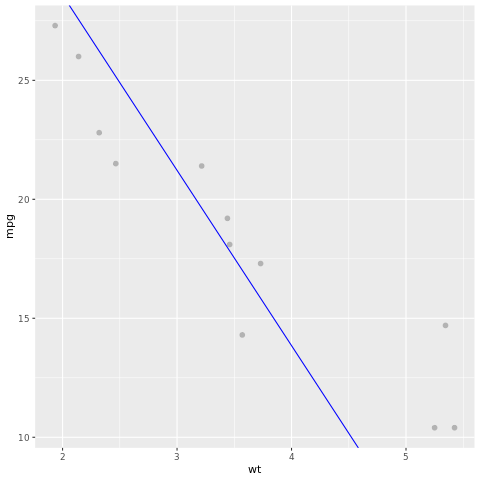
Sehen wir uns das Modellergebnis an. Wir können das Modell als Liniendiagramm und die Ground-Truth-Testdaten als Punkte im selben Diagramm zeichnen. Das Modell sieht gut aus.
# draw the model as a line chart and the test data groundtruth as points
lm_aug <- augment(lm_fit, test)
ggplot(lm_aug, aes(x = wt, y = mpg)) +
geom_point(size=2,color="grey70") +
geom_abline(intercept = lm_fit$fit$coefficients[1], slope = lm_fit$fit$coefficients[2], color = "blue")