R Bibliotheksverwaltung
Bibliotheken stellen wiederverwendbaren Code bereit, den Sie möglicherweise in Ihre Programme oder Projekte für Microsoft Fabric Spark aufnehmen möchten.
Microsoft Fabric unterstützt eine R-Laufzeit mit vielen beliebten Open Source R-Paketen, einschließlich TidyVerse, vorinstalliert. Wenn eine Spark-Instanz gestartet wird, werden diese Bibliotheken automatisch und sofort in Notizbüchern oder Spark-Auftragsdefinitionen verwendet.
Möglicherweise müssen Sie Ihre R-Bibliotheken aus verschiedenen Gründen aktualisieren. Beispielsweise hat eine Ihrer Kernabhängigkeiten eine neue Version veröffentlicht, oder Ihr Team hat ein benutzerdefiniertes Paket erstellt, das Sie in Ihren Spark-Clustern benötigen.
Es gibt zwei Arten von Bibliotheken, die Sie basierend auf Ihrem Szenario einschließen möchten:
Feed-Bibliotheken beziehen sich auf diejenigen, die sich in öffentlichen Quellen oder Repositories befinden, z. B. CRAN oder GitHub.
Benutzerdefinierte Bibliotheken sind der Code, der von Ihnen oder Ihrer Organisation erstellt wurde, und .tar.gz können über Bibliotheksverwaltungsportale verwaltet werden.
Es gibt zwei Ebenen von Paketen, die in Microsoft Fabric installiert sind:
Umgebung: Verwalten Sie Bibliotheken über eine Umgebung, um dieselben Bibliotheken in mehreren Notebooks oder Aufträgen wiederzuverwenden.
Session: Eine sitzungsbezogene Installation erstellt eine Umgebung für eine bestimmte Notebook-Sitzung. Änderungen an Bibliotheken auf Sitzungsebene werden zwischen Sitzungen nicht beibehalten.
Zusammenfassung der aktuellen verfügbaren R-Bibliotheksverwaltungsverhalten:
| Bibliothekstyp | Umgebungsinstallation | Installation auf Sitzungsebene |
|---|---|---|
| R-Feedbibliotheken (CRAN) | Nicht unterstützt | Unterstützt |
| Benutzerdefinierte R-Bibliotheken | Unterstützt | Unterstützt |
Voraussetzungen
Erhalten Sie ein Microsoft Fabric-Abonnement. Oder registrieren Sie sich für eine kostenlose Microsoft Fabric-Testversion.
Melden Sie sich bei Microsoft Fabrican.
Verwenden Sie den Erfahrungsschalter auf der unteren linken Seite Ihrer Startseite, um zu Fabric zu wechseln.

R-Bibliotheken auf Sitzungsebene
Wenn Sie interaktive Datenanalysen oder maschinelles Lernen durchführen, können Sie neuere Pakete ausprobieren oder Pakete benötigen, die derzeit in Ihrem Arbeitsbereich nicht verfügbar sind. Anstatt die Arbeitsbereichseinstellungen zu aktualisieren, können Sie Sitzungspakete verwenden, um Sitzungsabhängigkeiten hinzuzufügen, zu verwalten und zu aktualisieren.
- Wenn Sie sitzungsbeschränkte Bibliotheken installieren, hat nur das aktuelle Notizbuch Zugriff auf die spezifizierten Bibliotheken.
- Diese Bibliotheken wirken sich nicht auf andere Sitzungen oder Aufträge aus, die denselben Spark-Pool verwenden.
- Diese Bibliotheken werden auf Basis der zugrunde liegenden Bibliotheken auf Runtime- und Poolebene installiert.
- Notizbuchbibliotheken haben höchste Priorität.
- Sitzungsbezogene R-Bibliotheken werden nicht sitzungsübergreifend beibehalten. Diese Bibliotheken werden zu Beginn jeder Sitzung installiert, wenn die zugehörigen Installationsbefehle ausgeführt werden.
- Sitzungsbezogene R-Bibliotheken werden automatisch über die Treiber- und Arbeitsknoten hinweg installiert.
Anmerkung
Die Befehle zum Verwalten von R-Bibliotheken werden beim Ausführen von Pipelineaufträgen deaktiviert. Wenn Sie ein Paket in einer Pipeline installieren möchten, müssen Sie die Bibliotheksverwaltungsfunktionen auf Arbeitsbereichsebene verwenden.
Installieren von R-Paketen von CRAN
Sie können eine R-Bibliothek ganz einfach aus CRANinstallieren.
# install a package from CRAN
install.packages(c("nycflights13", "Lahman"))
Sie können CRAN-Momentaufnahmen auch als Repository verwenden, um sicherzustellen, dass sie jedes Mal dieselbe Paketversion herunterladen.
# install a package from CRAN snapsho
install.packages("highcharter", repos = "https://cran.microsoft.com/snapshot/2021-07-16/")
Installieren von R-Paketen mithilfe von DevTools
Die devtools-Bibliothek vereinfacht die Paketentwicklung, um allgemeine Aufgaben zu beschleunigen. Diese Bibliothek wird innerhalb der Microsoft Fabric-Standardlaufzeit installiert.
Sie können devtools verwenden, um eine bestimmte Version einer zu installierenden Bibliothek anzugeben. Diese Bibliotheken werden auf allen Knoten innerhalb des Clusters installiert.
# Install a specific version.
install_version("caesar", version = "1.0.0")
Ebenso können Sie eine Bibliothek direkt über GitHub installieren.
# Install a GitHub library.
install_github("jtilly/matchingR")
Derzeit werden die folgenden devtools-Funktionen in Microsoft Fabric unterstützt:
| Befehl | Beschreibung |
|---|---|
| install_github() | Installiert ein R-Paket von GitHub |
| install_gitlab() | Installiert ein R-Paket von GitLab |
| install_bitbucket() | Installiert ein R-Paket von BitBucket |
| install_url() | Installiert ein R-Paket aus einer beliebigen URL. |
| install_git() | Installiert aus einem beliebigen Git-Repository |
| install_local() | Installationen aus einer lokalen Datei auf dem Datenträger |
| install_version() | Installation über eine bestimmte Version aus CRAN |
Installieren von benutzerdefinierten R-Bibliotheken
Um eine benutzerdefinierte Bibliothek auf Sitzungsebene zu verwenden, müssen Sie sie zuerst in ein angefügtes Lakehouse hochladen.
Öffnen Sie das Notizbuch, in dem Sie die benutzerdefinierte Bibliothek verwenden möchten.
Wählen Sie auf der linken Seite Hinzufügen aus, um ein vorhandenes Seehaus hinzuzufügen oder ein Seehaus zu erstellen.
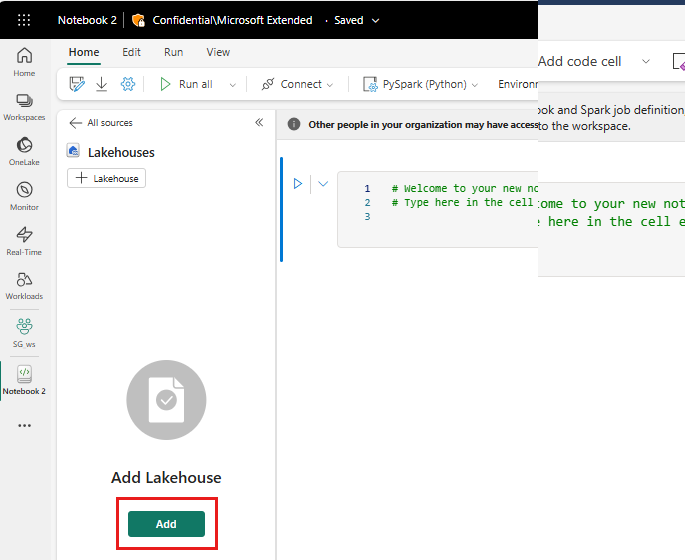
Klicken Sie mit der rechten Maustaste oder wählen Sie das "..." neben Dateien aus, um Ihre .tar.gz Datei hochzuladen.
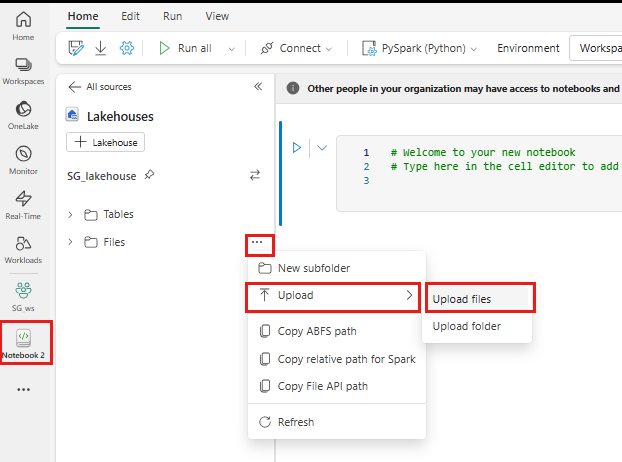
Wechseln Sie nach dem Hochladen wieder zu Ihrem Notizbuch. Verwenden Sie den folgenden Befehl, um die benutzerdefinierte Bibliothek in Ihrer Sitzung zu installieren:
install.packages("filepath/filename.tar.gz", repos = NULL, type = "source")
Anzeigen installierter Bibliotheken
Fragen Sie alle Bibliotheken ab, die in Ihrer Sitzung installiert sind, mithilfe des Befehls library.
# query all the libraries installed in current session
library()
Verwenden Sie die packageVersion-Funktion, um die Version der Bibliothek zu überprüfen:
# check the package version
packageVersion("caesar")
Entfernen eines R-Pakets aus einer Sitzung
Sie können die detach-Funktion verwenden, um eine Bibliothek aus dem Namespace zu entfernen. Diese Bibliotheken bleiben auf dem Datenträger, bis sie erneut geladen werden.
# detach a library
detach("package: caesar")
Um ein sesionbezogenes Paket aus einem Notizbuch zu entfernen, verwenden Sie den Befehl remove.packages(). Diese Bibliotheksänderung hat keine Auswirkungen auf andere Sitzungen im selben Cluster. Benutzer können integrierte Bibliotheken der Standardmäßigen Microsoft Fabric-Laufzeit nicht deinstallieren oder entfernen.
Anmerkung
Kernpakete wie SparkR, SparklyR oder R können nicht entfernt werden.
remove.packages("caesar")
Sitzungsbezogene R-Bibliotheken und SparkR
Bibliotheken im Notebookbereich sind in SparkR-Workern verfügbar.
install.packages("stringr")
library(SparkR)
str_length_function <- function(x) {
library(stringr)
str_length(x)
}
docs <- c("Wow, I really like the new light sabers!",
"That book was excellent.",
"R is a fantastic language.",
"The service in this restaurant was miserable.",
"This is neither positive or negative.")
spark.lapply(docs, str_length_function)
Sitzungsbezogene R-Bibliotheken und sparklyr
Mit spark_apply() in Sparklyr können Sie alle R-Pakete innerhalb von Spark verwenden. Standardmäßig wird in sparklyr::spark_apply()das Paketargument auf FALSE festgelegt. Dadurch werden die Bibliotheken in die aktuelle libPaths-Funktion der Worker kopiert, um sie in die Worker zu importieren und dort zu nutzen. Sie können beispielsweise Folgendes ausführen, um eine caesar-verschlüsselte Nachricht mit sparklyr::spark_apply()zu generieren:
install.packages("caesar", repos = "https://cran.microsoft.com/snapshot/2021-07-16/")
spark_version <- sparkR.version()
config <- spark_config()
sc <- spark_connect(master = "yarn", version = spark_version, spark_home = "/opt/spark", config = config)
apply_cases <- function(x) {
library(caesar)
caesar("hello world")
}
sdf_len(sc, 5) %>%
spark_apply(apply_cases, packages=FALSE)
Verwandte Inhalte
Weitere Informationen zu den R-Funktionen: