SQL im Vergleich zu NoSQL-Daten
Tipp
Diese Inhalte sind ein Auszug aus dem E-Book „Architecting Cloud Native .NET Applications for Azure“, verfügbar in der .NET-Dokumentation oder als kostenlos herunterladbare PDF-Datei, die offline gelesen werden kann.

„Relational (SQL)“ und „nicht relational (NoSQL)“ sind zwei Arten von Datenbanksystemen, die häufig in cloudnativen Apps implementiert werden. Sie werden anders erstellt, speichern Daten anders und der Zugriff erfolgt unterschiedlich. In diesem Abschnitt werden wir beide betrachten. Später in diesem Kapitel befassen wir uns mit einer neuen Datenbanktechnologie namens NewSQL.
Relationale Datenbanken sind seit Jahrzehnten eine weit verbreitete Technologie. Sie sind ausgereift, bewährt und weit verbreitet. Konkurrierende Datenbankprodukte, Tools und Fachwissen gibt es reichlich. Relationale Datenbanken bieten einen Speicher für zusammengehörige Datentabellen. Diese Tabellen haben ein festes Schema, verwenden SQL (Structured Query Language) zur Datenverwaltung und unterstützen ACID-Garantien: Atomarität, Konsistenz, Isolation und Dauerhaftigkeit.
NoSQL-Datenbanken bezeichnen leistungsstarke, nicht relationale Datenspeicher. Sie zeichnen sich durch ihre Benutzerfreundlichkeit, Skalierbarkeit, Resilienz und Verfügbarkeit aus. Anstatt Tabellen mit normalisierten Daten zu verknüpfen, speichert NoSQL unstrukturierte oder halbstrukturierte Daten, oft in Schlüssel-Wert-Paaren oder JSON-Dokumenten. NoSQL-Datenbanken bieten in der Regel keine ACID-Garantien, die über den Rahmen einer einzelnen Datenbankpartition hinausgehen. Dienste mit hohem Volumen, die eine Antwortzeit von unter einer Sekunde erfordern, bevorzugen NoSQL-Datenspeicher.
Die Bedeutung von NoSQL-Technologien für verteilte cloudnative Systeme kann gar nicht hoch genug eingeschätzt werden. Die Verbreitung neuer Datentechnologien in diesem Bereich hat Lösungen, die früher ausschließlich auf relationalen Datenbanken basierten, in Frage gestellt.
NoSQL-Datenbanken umfassen mehrere unterschiedliche Modelle für den Zugriff auf und die Verwaltung von Daten, die jeweils für bestimmte Anwendungsfälle geeignet sind. In Abbildung 5-9 sind vier gängige Modelle dargestellt.
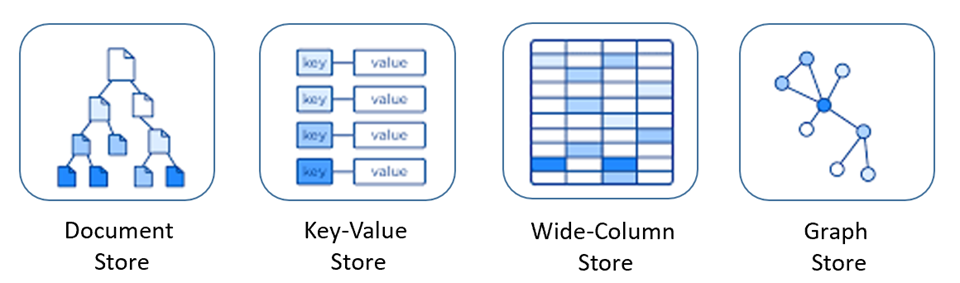
Abbildung 5-9: Datenmodelle für NoSQL-Datenbanken
| Modell | Merkmale |
|---|---|
| Dokumentspeicher | Daten und Metadaten werden hierarchisch in JSON-basierten Dokumenten innerhalb der Datenbank gespeichert. |
| Schlüssel-Wert-Speicher | Die einfachste der NoSQL-Datenbanken. Hier werden Daten als Sammlung von Schlüssel-Wert-Paaren dargestellt. |
| Wide-ColumnStore | Verknüpfte Daten werden als Gruppe geschachtelter Schlüssel-Wert-Paare innerhalb einer einzelnen Spalte gespeichert. |
| Graphspeicher | Daten werden in einer Graphstruktur als Knoten, Edge und Dateneigenschaften gespeichert. |
CAP- und PACELC-Theoreme
Um die Unterschiede zwischen diesen Datenbanktypen zu verstehen, betrachten Sie das CAP-Theorem, eine Reihe von Prinzipien, die auf verteilte Systeme angewendet werden, die Zustände speichern. Abbildung 5-10 zeigt die drei Eigenschaften des CAP-Theorems.
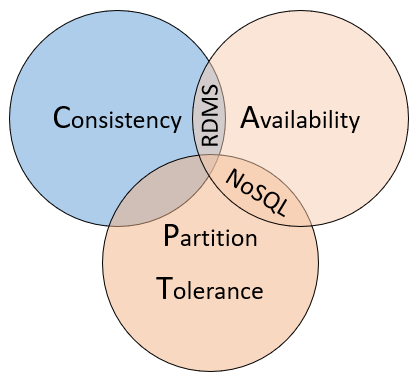
Abbildung 5-10. Das CAP-Theorem.
Der Theorem besagt, dass verteilte Datensysteme einen Kompromiss zwischen Konsistenz, Verfügbarkeit und Partitionstoleranz bieten. Außerdem könne jede Datenbank nur zwei der drei Eigenschaften garantieren:
Konsistenz. Jeder Knoten im Cluster antwortet mit den neuesten Daten, auch wenn das System die Anforderung blockieren muss, bis alle Replikate aktualisiert werden. Wenn Sie ein „konsistentes System“ nach einem Element abfragen, das derzeit aktualisiert wird, warten Sie auf diese Antwort, bis alle Replikate erfolgreich aktualisiert wurden. Sie erhalten jedoch die aktuellsten Daten. Beachten Sie, dass der Begriff „Konsistenz“ im Zusammenhang mit dem CAP-Theorem eine technische Bedeutung hat, die sich von der Art und Weise unterscheidet, wie „Konsistenz“ im Kontext von ACID-Garantien definiert wird.
Verfügbarkeit: Jede Anforderung, die von einem nicht fehlerhaften Knoten im System empfangen wird, muss zu einer Antwort führen. Einfach ausgedrückt: Wenn Sie ein „verfügbares System“ nach einem Element abfragen, das aktualisiert wird, erhalten Sie die bestmögliche Antwort, die der Dienst zu diesem Zeitpunkt geben kann. Beachten Sie jedoch, dass sich „Verfügbarkeit“ gemäß Definition des CAP-Theorems technisch von der „hohen Verfügbarkeit“ unterscheidet, wie sie üblicherweise für verteilte Systeme bekannt ist.
Partitionstoleranz Garantiert, dass das System auch dann weiterhin funktioniert, wenn ein replizierter Datenknoten ausfällt oder es die Konnektivität mit anderen replizierten Datenknoten verliert.
Das CAP-Theorem erläutert die Kompromisse, die mit der Verwaltung von Konsistenz und Verfügbarkeit während einer Netzwerkpartition verbunden sind. Kompromisse in Bezug auf Konsistenz und Leistung bestehen jedoch auch ohne eine Netzwerkpartition.
Hinweis
Selbst wenn Sie der Verfügbarkeit Vorzug vor der Konsistenz geben, leidet bei der Netzwerkpartition die Verfügbarkeit. Ein System mit CAP-Verfügbarkeit bietet einigen Clients mehr Verfügbarkeit, aber nicht unbedingt „hohe Verfügbarkeit“ für alle Clients.
Das CAP-Theorem wird oft auf PACELC erweitert, um die Kompromisse umfassender zu erklären. Das CAP-Theorem ist besonders relevant in intermittierend verbundenen Umgebungen, wie beispielsweise im Zusammenhang mit dem Internet der Dinge (IoT), der Umweltüberwachung und mobilen Anwendungen. In diesen Kontexten können Geräte aufgrund anspruchsvoller physischer Bedingungen, wie Stromausfälle oder beim Betreten von begrenzten Räumen wie Aufzüge, partitioniert werden. Für verteilte Systeme wie Cloudanwendungen ist das PACELC-Theorem besser geeignet, da es umfassender ist und Kompromisse wie Latenz und Konsistenz auch bei Abwesenheit von Netzwerkpartitionen berücksichtigt.
Relationale Datenbanken bieten in der Regel Konsistenz und Verfügbarkeit, aber keine Partitionstoleranz. Sie werden in der Regel für einen einzelnen Server bereitgestellt und vertikal skaliert, indem dem Computer weitere Ressourcen hinzugefügt werden.
Viele relationale Datenbanksysteme unterstützen integrierte Replikationsfeatures, mit denen Kopien der primären Datenbank auf anderen sekundären Serverinstanzen erstellt werden können. Schreibvorgänge werden auf der primären Instanz ausgeführt und auf jede der sekundären Instanzen repliziert. Bei einem Ausfall kann die primäre Instanz auf eine sekundäre Instanz ausweichen, um Hochverfügbarkeit zu gewährleisten. Sekundäre Instanzen können auch verwendet werden, um Lesevorgänge zu verteilen. Während Schreibvorgänge immer das primäre Replikat betreffen, können Lesevorgänge an jedes der sekundären Replikate weitergeleitet werden, um die Systemlast zu verringern.
Daten können auch horizontal auf mehrere Knoten aufgeteilt werden, z.B. mittels Sharding. Aber das Sharding erhöht den betrieblichen Aufwand dramatisch, da die Daten auf viele Teile verteilt werden, die nicht einfach miteinander kommunizieren können. Die Verwaltung kann kostspielig und zeitaufwendig sein. Relationale Features wie Tabellenjoins, Transaktionen und referentielle Integrität führen in Bereitstellungen mit Sharding zu erheblichen Leistungseinbußen.
Die Ziele für die Replikationskonsistenz und den Wiederherstellungspunkt können durch die Konfiguration, ob die Replikation synchron oder asynchron erfolgt, optimiert werden. Wenn die Netzwerkkonnektivität von Datenreplikaten in einem „hochkonsistenten“ oder synchronen relationalen Datenbankcluster ausfällt, können Sie nicht mehr in die Datenbank schreiben. Das System würde den Schreibvorgang ablehnen, da es diese Änderung nicht auf das andere Replikat replizieren kann. Jedes Datenreplikat muss aktualisiert werden, bevor die Transaktion abgeschlossen werden kann.
NoSQL-Datenbanken unterstützen in der Regel Hochverfügbarkeit und Partitionstoleranz. Sie lassen sich horizontal aufskalieren, oft über handelsübliche Server. Dieser Ansatz bietet eine enorme Verfügbarkeit, sowohl innerhalb als auch über geografische Regionen hinweg, und das zu geringeren Kosten. Sie partitionieren und replizieren Daten auf diesen Computern oder Knoten und sorgen so für Redundanz und Fehlertoleranz. Die Konsistenz wird in der Regel durch Konsensprotokolle oder Quorummechanismen optimiert. Sie bieten mehr Kontrolle, wenn es darum geht, Kompromisse zwischen synchroner und asynchroner Replikation in relationalen Systemen zu finden.
Wenn die Datenreplikate in einem NoSQL-Datenbankcluster mit Hochverfügbarkeit die Konnektivität verlieren, können Sie immer noch einen Schreibvorgang in der Datenbank abschließen. Der Datenbankcluster würde den Schreibvorgang zulassen und jedes Replikat aktualisieren, sobald es verfügbar ist. NoSQL-Datenbanken, die mehrere beschreibbare Replikate unterstützen, können die Hochverfügbarkeit weiter verbessern, indem sie bei der Optimierung der Wiederherstellungszeitvorgabe (Recovery Time Objective, RTO) die Notwendigkeit eines Failovers vermeiden.
Moderne NoSQL-Datenbanken implementieren in der Regel Partitionierungsfunktionen als Feature ihres Systementwurfs. Die Verwaltung von Partitionen ist oft in die Datenbank integriert, und das Routing wird durch Platzierungshinweise – oft Partitionsschlüssel genannt – erreicht. Dank flexibler Datenmodelle können NoSQL-Datenbanken den Aufwand für die Schemaverwaltung verringern und die Verfügbarkeit bei der Bereitstellung von Anwendungsupdates, die Änderungen am Datenmodell erfordern, verbessern.
Hochverfügbarkeit und massive Skalierbarkeit sind oft geschäftskritischer als relationale Tabellenjoins und referentielle Integrität. Entwickler können Techniken und Muster wie Sagas, CQRS und asynchrones Messaging implementieren, um eine eventuelle Konsistenz zu erreichen.
Heutzutage ist Vorsicht geboten, wenn es um die Einschränkungen des CAP-Theorems geht. Eine neue Art von Datenbank, NewSQL genannt, ist entstanden, die die relationale Datenbank-Engine erweitert, um sowohl die horizontale Skalierbarkeit als auch die skalierbare Leistung von NoSQL-Systemen zu unterstützen.
Überlegungen zu relationalen und NoSQL-Systemen
Je nach den spezifischen Datenanforderungen kann ein cloudnativer Microservice einen relationalen, einen NoSQL-Datenspeicher oder beides implementieren.
| Ziehen Sie einen NoSQL-Datenspeicher in folgenden Situationen in Betracht: | Ziehen Sie eine relationale Datenbank in folgenden Situationen in Betracht: |
|---|---|
| Sie verfügen über Workloads mit hohem Volumen, die vorhersehbare Wartezeiten im großen Stil erfordern (z. B. in Millisekunden gemessene Wartezeiten bei der Durchführung von Millionen von Transaktionen pro Sekunde). | Ihr Workloadvolumen liegt in der Regel bei Tausenden von Transaktionen pro Sekunde. |
| Ihre Daten sind dynamisch und ändern sich häufig. | Ihre Daten sind hochgradig strukturiert und erfordern referentielle Integrität. |
| Beziehungen können denormalisierte Datenmodelle sein. | Beziehungen werden durch Tabellenjoins auf normalisierten Datenmodellen ausgedrückt. |
| Der Datenabruf ist einfach und erfolgt ohne Tabellenjoins. | Sie arbeiten mit komplexen Abfragen und Berichten. |
| Daten werden in der Regel in verschiedenen Regionen repliziert und erfordern eine genauere Kontrolle über Konsistenz, Verfügbarkeit und Leistung. | Daten sind in der Regel zentralisiert oder können asynchron in Regionen repliziert werden. |
| Ihre Anwendung wird auf handelsüblicher Hardware bereitgestellt, z. B. in öffentlichen Clouds. | Ihre Anwendung wird auf leistungsstarker High-End-Hardware bereitgestellt. |
In den nächsten Abschnitten werden wir die in der Azure-Cloud verfügbaren Optionen für die Speicherung und Verwaltung Ihrer cloudnativen Daten untersuchen.
Database as a Service
Für den Anfang könnten Sie einen virtuellen Computer in Azure bereitstellen und die Datenbank Ihrer Wahl für jeden Dienst installieren. Sie hätten zwar die volle Kontrolle über die Umgebung, würden aber auf viele integrierte Features der Cloudplattform verzichten. Sie wären auch für die Verwaltung des virtuellen Computers und der Datenbank für jeden Dienst verantwortlich. Dieser Ansatz könnte schnell zeitaufwendig und kostenintensiv werden.
Stattdessen bevorzugen cloudnative Anwendungen Datendienste, die als Database-as-a-Service (DBaaS) angeboten werden. Diese Dienste, die vollständig von einem Cloudanbieter verwaltet werden, bieten integrierte Sicherheit, Skalierbarkeit und Überwachung. Anstatt den Dienst zu besitzen, nutzen Sie ihn einfach als Unterstützungsdienst. Der Anbieter betreibt die Ressource im großen Stil und trägt die Verantwortung für Leistung und Wartung.
Sie können über Cloudverfügbarkeitszonen und Regionen hinweg konfiguriert werden, um Hochverfügbarkeit zu erreichen. Sie alle unterstützen Just-In-Time-Kapazitäten und ein Modell mit nutzungsbasierter Bezahlung. Azure bietet verschiedenartige Optionen für verwaltete Dienste, die jeweils spezifische Vorteile bieten.
Wir werden uns zunächst die in Azure verfügbaren relationalen DBaaS-Dienste ansehen. Sie werden sehen, dass neben dem Vorzeigemodell von Microsoft, der SQL Server-Datenbank, auch mehrere Open-Source-Optionen verfügbar sind. Dann werden wir über die NoSQL-Datendienste in Azure sprechen.
Relationale Azure-Datenbanken
Für cloudnative Microservices, die relationale Daten benötigen, bietet Azure vier verwaltete relationale Datenbanken als Dienst (DBaaS) an, die in Abbildung 5-11 dargestellt sind.

Abbildung 5-11. In Azure verfügbare verwaltete relationale Datenbanken
Beachten Sie in der vorherigen Abbildung, dass beide auf einer gemeinsamen DBaaS-Infrastruktur basieren, die wichtige Funktionen ohne zusätzliche Kosten bietet.
Diese Features sind besonders wichtig für Unternehmen, die eine große Anzahl von Datenbanken bereitstellen, aber nur über begrenzte Ressourcen für deren Verwaltung verfügen. Sie können eine Azure-Datenbank in wenigen Minuten bereitstellen, indem Sie die Anzahl der Prozessorkerne, den Arbeitsspeicher und den zugrunde liegenden Speicher auswählen. Sie können die Datenbank spontan skalieren und die Ressourcen dynamisch anpassen – mit wenig bis gar keiner Downtime.
Azure SQL-Datenbank
Entwicklungsteams mit Fachwissen zu Microsoft SQL Server sollten Azure SQL-Datenbank in Betracht ziehen. Es handelt sich um ein vollständig verwaltetes relationales DBaaS-System (Datenbank-as-a-Service), das auf der Microsoft SQL Server-Datenbank-Engine basiert. Der Dienst teilt viele Features, die in der lokalen Version von SQL Server enthalten sind, und führt die neueste stabile Version der SQL Server-Datenbank-Engine aus.
Für die Verwendung mit einem cloudnativen Microservice steht Azure SQL-Datenbank mit drei Bereitstellungsoptionen zur Verfügung:
Eine einzelne Datenbank ist eine vollständig verwaltete SQL-Datenbank, die auf einem Azure SQL-Datenbank-Server in der Azure-Cloud ausgeführt wird. Die Datenbank gilt als eigenständig, da sie keine Konfigurationsabhängigkeiten vom zugrunde liegenden Datenbankserver hat.
Eine verwaltete Instanz ist eine vollständig verwaltete Instanz der Microsoft SQL Server-Datenbank-Engine, die nahezu 100 %ige Kompatibilität mit einem lokalen SQL Server bietet. Diese Option unterstützt größere Datenbanken, bis zu 35 TB, und wird zur besseren Isolation in einem Azure Virtual Network platziert.
Die serverlose Azure SQL-Datenbank ist ein Computetarif für eine einzelne Datenbank, die automatisch je nach Workloadnachfrage skaliert wird. Es wird nur die Menge der verwendeten Computeressourcen pro Sekunde berechnet. Der Dienst eignet sich gut für Workloads mit unregelmäßigen, unvorhersehbaren Nutzungsmustern, die sich mit Zeiten der Inaktivität abwechseln. Der serverlose Computetarif pausiert außerdem automatisch die Datenbanken während inaktiver Perioden, sodass nur die Speicherkosten in Rechnung gestellt werden. Er wird automatisch wieder fortgesetzt, wenn die Aktivität wieder einsetzt.
Neben dem herkömmlichen Microsoft SQL Server-Stapel bietet Azure auch verwaltete Versionen von drei beliebten Open-Source-Datenbanken.
Open-Source-Datenbanken in Azure
Relationale Open-Source-Datenbanken sind eine beliebte Wahl für cloudnative Anwendungen geworden. Viele Unternehmen bevorzugen sie gegenüber kommerziellen Datenbankprodukten, vor allem um Kosten zu sparen. Viele Entwicklerteams schätzen die Flexibilität, die von der Community unterstützte Entwicklung und das Ökosystem an Tools und Erweiterungen. Open-Source-Datenbanken können bei mehreren Cloudanbietern bereitgestellt werden, was die Sorge vor einer „Anbieterbindung“ minimiert.
Entwickler können jede Open-Source-Datenbank auf einer Azure-VM selbst hosten. Dieser Ansatz bietet Ihnen zwar die volle Kontrolle, aber Sie müssen sich um die Verwaltung, Überwachung und Wartung der Datenbank und der VM kümmern.
Microsoft setzt jedoch sein Engagement fort, Azure als „offene Plattform“ beizubehalten, indem mehrere beliebte Open-Source-Datenbanken als vollständig verwaltete DBaaS-Dienste angeboten werden.
Azure Database for MySQL
MySQL ist eine relationale Open-Source-Datenbank und eine Grundpfeiler für Anwendungen, die auf dem LAMP-Softwarestapel erstellt werden. Es wird von vielen großen Unternehmen verwendet, darunter Facebook, Twitter und YouTube, und eignet sich besonders für Workloads mit hohem Leseaufkommen. Die Community Edition ist kostenlos erhältlich, während für die Enterprise Edition eine Lizenz erworben werden muss. Das Produkt wurde ursprünglich 1995 erstellt und 2008 von Sun Microsystems aufgekauft. Oracle hat Sun und MySQL im Jahr 2010 übernommen.
Azure Database for MySQL ist ein verwalteter relationaler Datenbankdienst, der auf der Open-Source-Engine für den MySQL-Server basiert. Es verwendet die MySQL Community Edition. Der Azure MySQL-Server ist der Verwaltungspunkt für den Dienst. Es handelt sich um dieselbe MySQL-Server-Engine, die auch für lokale Bereitstellungen verwendet wird. Die Engine kann eine einzelne Datenbank pro Server oder mehrere Datenbanken pro Server erstellen, die Ressourcen gemeinsam nutzen. Sie können Ihre Daten weiterhin mit denselben Open-Source-Tools verwalten, ohne neue Qualifikationen erlernen oder virtuelle Computer verwalten zu müssen.
Azure Database for MariaDB
MariaDB-Server ist ein weiterer beliebter Open-Source-Datenbankserver. Es wurde als Fork (Abspaltung) von MySQL erstellt, als Oracle Sun Microsystems kaufte, das Besitzer von MySQL war. Die Absicht war, sicherzustellen, dass MariaDB Open-Source bleibt. Da MariaDB eine Abspaltung von MySQL ist, sind die Daten- und Tabellendefinitionen kompatibel und die Clientprotokolle, Strukturen und APIs eng miteinander verbunden.
MariaDB hat eine starke Community und wird von vielen großen Unternehmen verwendet. Während Oracle weiterhin MySQL pflegt, verbessert und unterstützt, verwaltet die MariaDB Foundation MariaDB und erlaubt öffentliche Beiträge zum Produkt und zur Dokumentation.
Azure Database for MariaDB ist ein vollständig verwaltetes relationales Database-as-a-Service-System in der Azure-Cloud. Der Dienst basiert auf der Server-Engine der MariaDB Community Edition. Er kann unternehmenskritische Workloads mit vorhersehbarer Leistung und dynamischer Skalierbarkeit verarbeiten.
Azure Database for PostgreSQL
PostgreSQL ist eine relationale Open-Source-Datenbank, die seit über 30 Jahren aktiv entwickelt wird. PostgresSQL hat einen guten Ruf hinsichtlich Zuverlässigkeit und Datenintegrität. Es verfügt über zahlreiche Features, ist SQL-kompatibel und gilt als leistungsfähiger als MySQL – insbesondere bei Workloads mit komplexen Abfragen und umfangreichen Schreibvorgängen. Viele große Unternehmen wie Apple, Red Hat und Fujitsu haben Produkte erstellt, die PostgreSQL verwenden.
Azure Database for PostgreSQL ist ein vollständig verwalteter relationaler Datenbankdienst, der auf der Open-Source-Postgres-Datenbank-Engine basiert. Der Dienst unterstützt viele Entwicklungsplattformen, darunter C++, Java, Python, Node, C# und PHP. Sie können PostgreSQL-Datenbanken mithilfe des Befehlszeilenschnittstellentools oder des Azure Data Migration Service dorthin migrieren.
Azure Database for PostgreSQL ist mit zwei Bereitstellungsoptionen verfügbar:
Die Single Server-Bereitstellungsoption ist ein zentraler Verwaltungspunkt für mehrere Datenbanken, an dem Sie viele Datenbanken bereitstellen können. Die Preise sind pro Server auf der Grundlage von Kernen und Speicherplatz strukturiert.
Die Option Hyperscale (Citus) wird von der Citus Data Technologie unterstützt. Sie ermöglicht hohe Leistung durch horizontale Skalierung einer einzelnen Datenbank über Hunderte von Knoten, um schnelle Leistung und Skalierung zu bieten. Mit dieser Option kann das Modul mehr Daten im Arbeitsspeicher unterbringen, Abfragen über Hunderte von Knoten parallel ausführen und Daten schneller indizieren.
NoSQL-Daten in Azure
Cosmos DB ist ein vollständig verwalteter, global verteilter NoSQL-Datenbankdienst in der Azure-Cloud. Es wurde von vielen großen Unternehmen auf der ganzen Welt übernommen, darunter Coca-Cola, Skype, ExxonMobil und Liberty Mutual.
Wenn Ihre Dienste eine schnelle Reaktion von überall auf der Welt, Hochverfügbarkeit oder elastische Skalierbarkeit erfordern, ist Cosmos DB eine gute Wahl. Abbildung 5-12 zeigt Cosmos DB.
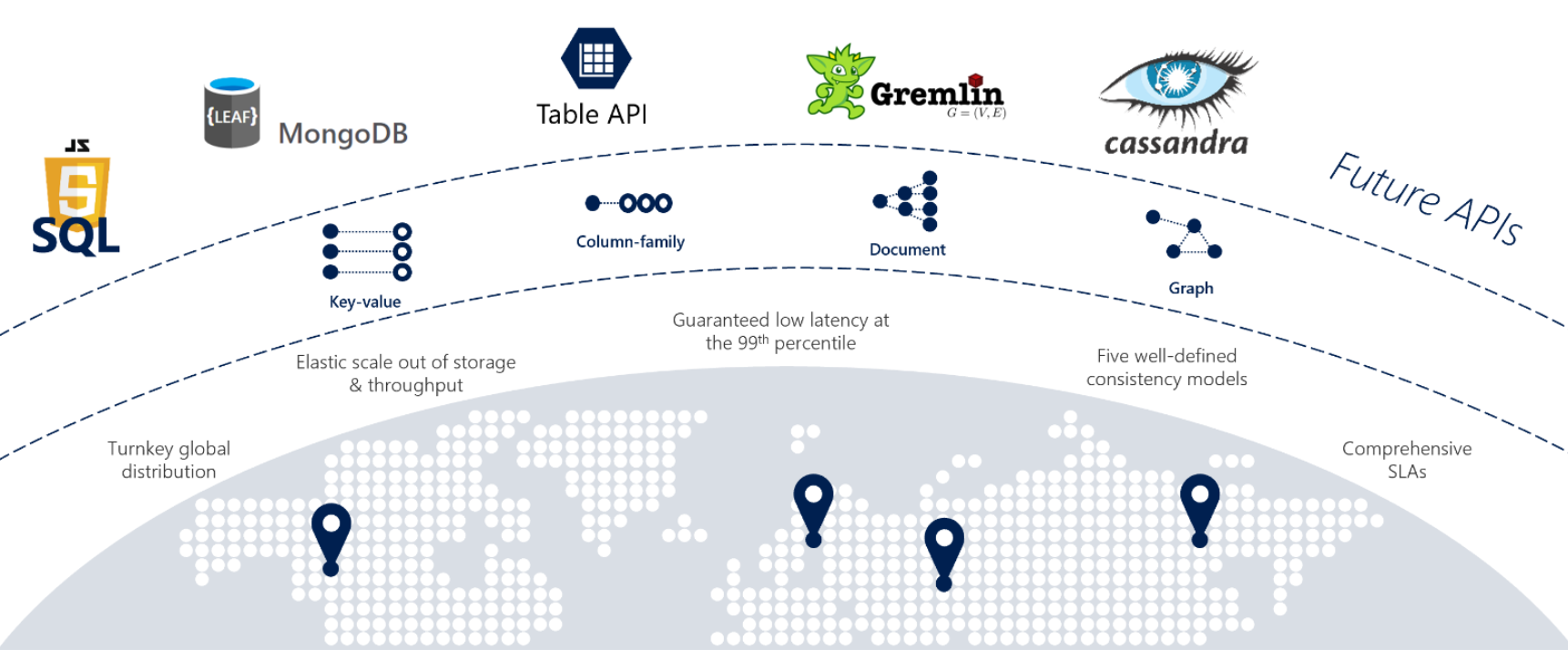
Abbildung 5-12: Übersicht über Azure Cosmos DB
Die vorherige Abbildung zeigt viele der integrierten cloudnativen Funktionen, die in Cosmos DB verfügbar sind. In diesem Abschnitt werden wir sie genauer betrachten.
Globaler Support
Cloudnative Anwendungen verfügen häufig über eine globale Zielgruppe und erfordern eine globale Skalierung.
Sie können Cosmos-Datenbanken über Regionen oder die ganze Welt verteilen und so die Daten in die Nähe Ihrer Benutzer platzieren, die Antwortzeit verbessern und die Wartezeit verringern. Sie können eine Datenbank zu einer Region hinzufügen oder aus ihr entfernen, ohne Ihre Dienste anzuhalten oder erneut bereitzustellen. Im Hintergrund repliziert Cosmos DB die Daten transparent in jede der konfigurierten Regionen.
Cosmos DB unterstützt Aktiv/Aktiv-Clustering auf globaler Ebene, sodass Sie alle Datenbankregionen so konfigurieren können, dass Schreib- und Lesevorgänge unterstützt werden.
Das Protokoll zum Schreiben in mehrere Regionen ist ein wichtiges Feature in Cosmos DB, das die folgenden Funktionen ermöglicht:
Unbegrenzte elastische Schreib und Leseskalierbarkeit.
99,999 % Lese- und Schreibverfügbarkeit weltweit.
Eine garantierte Verarbeitung von Lese-/Schreibvorgängen in weniger als 10 Millisekunden im 99. Perzentil.
Mit den APIs für Multihosting von Cosmos DB erkennt Ihr Microservice automatisch die nächstgelegene Azure-Region und sendet Anforderungen an diese. Die nächstgelegene Region wird von Cosmos DB ohne Konfigurationsänderungen identifiziert. Sollte eine Region nicht mehr verfügbar sein, leitet das Feature „Multihosting“ die Anforderungen automatisch an die nächstgelegene verfügbare Region weiter.
Unterstützung für mehrere Modelle
Wenn monolithische Anwendungen auf eine cloudnative Architektur umgestellt werden, müssen Entwicklungsteams manchmal Open-Source-NoSQL-Datenspeicher migrieren. Cosmos DB kann Ihnen mit seiner Datenplattform für mehrere Modelle helfen, Ihre Investitionen in diese NoSQL-Datenspeicher zu schützen. Die folgende Tabelle zeigt die unterstützten NoSQL-Kompatibilitäts-APIs.
| Anbieter | Beschreibung |
|---|---|
| NoSQL-API | Die API für NoSQL speichert Daten im Dokumentformat. |
| Mongo DB-API | Unterstützt Mongo DB-APIs und JSON-Dokumente |
| Gremlin-API | Unterstützt Gremlin-API mit diagrammbasierten Darstellungen von Knoten und Edgedaten |
| Cassandra-API | Unterstützt Casandra-API für Datendarstellungen in breiten Spalten |
| Tabellen-API | Unterstützt Azure Table Storage mit Premium-Erweiterungen |
| PostgreSQL-API | Verwalteter Dienst für die Ausführung von PostgreSQL in beliebigem Umfang |
Entwicklungsteams können bestehende Mongo-, Gremlin- oder Cassandra-Datenbanken mit minimalen Änderungen an Daten oder Code zu Cosmos DB migrieren. Für neue Apps können Entwicklungsteams zwischen Open-Source-Optionen oder dem integrierten SQL-API-Modell wählen.
Intern speichert Cosmos die Daten in einem einfachen struct-Format, das aus primitiven Datentypen besteht. Bei jeder Anforderung übersetzt die Datenbank-Engine die primitiven Daten in die von Ihnen gewählte Modelldarstellung.
Beachten Sie in der vorherigen Tabelle die Option Tabellen-API. Diese API ist eine Weiterentwicklung von Azure Table Storage. Beide teilen das gleiche zugrunde liegende Tabellenmodell, aber die Cosmos DB-Tabellen-API bietet Premium-Verbesserungen, die in der Azure Storage-API nicht verfügbar sind. In der folgenden Tabelle werden die Features gegenübergestellt.
| Funktion | Azure Table Storage | Azure Cosmos DB |
|---|---|---|
| Latency | Schnell | Wartezeiten im einstelligen Millisekundenbereich für Lese- und Schreibvorgänge überall auf der Welt |
| Throughput | Grenzwert von 20.000 Vorgängen pro Tabelle | Unbegrenzte Anzahl von Vorgängen pro Tabelle |
| Globale Verteilung | Einzelne Region mit optionaler einzelner sekundärer Leseregion | Sofort verwendbare Verteilungen an alle Regionen mit automatischem Failover |
| Indizierung | Nur für Partitions- und Zeilenschlüsseleigenschaften verfügbar | Automatische Indizierung aller Eigenschaften |
| Preise | Optimiert für kalte Workloads (geringer Durchsatz : Speicherverhältnis) | Optimiert für heiße Workloads (hoher Durchsatz : Speicherverhältnis) |
Microservices, die Azure-Tabellenspeicher nutzen, können problemlos zur Cosmos DB-Tabellen-API migrieren. Es sind keine Codeänderungen erforderlich.
Einstellbare Konsistenz
Weiter oben im Abschnitt Relational und NoSQL haben wir das Thema Datenkonsistenz erörtert. Die Datenkonsistenz bezieht sich auf die Integrität Ihrer Daten. Cloudnative Dienste mit verteilten Daten sind auf Replikation angewiesen und müssen einen grundlegenden Kompromiss zwischen Lesekonsistenz, Verfügbarkeit und Wartezeit eingehen.
Bei den meisten verteilten Datenbanken können die Entwickler zwischen zwei Konsistenzmodellen wählen: starke Konsistenz und letztliche Konsistenz. Starke Konsistenz ist der Goldstandard für die Programmierbarkeit von Daten. Sie garantiert, dass eine Abfrage immer die aktuellsten Daten zurückgibt – selbst wenn das System eine Wartezeit in Kauf nehmen muss, bis eine Aktualisierung über alle Datenbankkopien repliziert ist. Eine Datenbank, die für letztliche Konsistenz konfiguriert ist, gibt die Daten sofort zurück, auch wenn diese Daten nicht die aktuellste Kopie darstellen. Die letztere Option ermöglicht eine höhere Verfügbarkeit, eine größere Skalierbarkeit und eine bessere Leistung.
Azure Cosmos DB bietet fünf klar definierte Konsistenzmodelle, die in Abbildung 5-13 dargestellt sind.

Abbildung 5-13: Cosmos DB-Konsistenzebenen
Diese Optionen ermöglichen es Ihnen, präzise Entscheidungen zu treffen und differenzierte Kompromisse für die Konsistenz, Verfügbarkeit und Leistung Ihrer Daten zu finden. Die Ebenen sind in der folgenden Tabelle dargestellt.
| Konsistenzebene | Beschreibung |
|---|---|
| Letztlich | Es gibt keine Garantie der Reihenfolge von Lesevorgängen. Die Replikate werden schließlich zusammengeführt. |
| Konstantes Präfix | Die Lesevorgänge sind zwar immer noch möglich, aber die Daten werden in der Reihenfolge zurückgegeben, in der sie geschrieben wurden. |
| Sitzung | Garantiert, dass Sie alle Daten lesen können, die während der aktuellen Sitzung geschrieben wurden. Dies ist die Standardkonsistenzebene. |
| Begrenzte Veraltung (Bounded staleness) | Lesevorgänge folgen Schreibvorgängen in dem von Ihnen angegebenen Intervall. |
| STARK (Strong) | Bei Lesevorgängen wird garantiert, dass die letzte Version eines Elements mit Commit zurückgegeben wird. Einem Client wird nie ein partieller Lesevorgang bzw. ein Lesevorgang, für den kein Commit ausgeführt wurde, angezeigt. |
In dem Artikel Getting Behind the 9-Ball: Cosmos DB Consistency Levels Explained (Lösung zu 9-Ball: Erläuterung der Cosmos DB-Konsistenzebenen) liefert Microsoft Program Manager Jeremy Likness eine hervorragende Erklärung der fünf Modelle.
Partitionierung
Azure Cosmos DB umfasst eine automatische Partitionierung zur Skalierung einer Datenbank, um die Leistungsanforderungen Ihrer cloudnativen Dienste zu erfüllen.
Sie verwalten Daten in Cosmos DB-Daten, indem Sie Datenbanken, Container und Elemente erstellen.
Container befinden sich in einer Cosmos DB-Datenbank und stellen eine schemaunabhängige Gruppierung von Elementen dar. Elemente sind die Daten, die Sie dem Container hinzufügen. Sie werden als Dokumente, Zeilen, Knoten oder Edges dargestellt. Alle Elemente, die einem Container hinzugefügt werden, werden automatisch indiziert.
Um den Container zu partitionieren, werden die Elemente in verschiedene Teilmengen unterteilt, die als logische Partitionen bezeichnet werden. Logische Partitionen werden basierend auf dem Wert des Partitionsschlüssels gefüllt, die jedem Element in einem Container zugeordnet ist. Abbildung 5-14 zeigt zwei Container mit einer logischen Partition basierend auf einem Partitionsschlüsselwert.
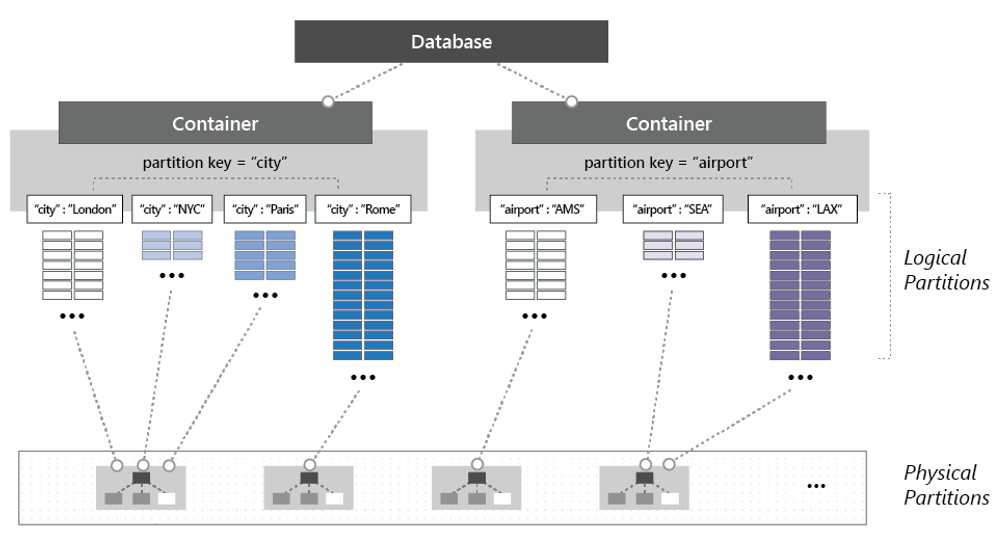
Abbildung 5-14: Mechanismen der Partitionierung von Cosmos DB
Beachten Sie in der vorherigen Abbildung, dass jedes Element einen Partitionsschlüssel von entweder „City“ (Ort) oder „Airport“ (Flughafen) enthält. Der Schlüssel bestimmt die logische Partition des Elements. Elemente mit einem Ortscode werden dem Container auf der linken Seite zugewiesen, Elemente mit einem Flughafencode dem Container auf der rechten Seite. Durch die Kombination des Partitionsschlüsselwerts mit dem ID-Wert wird ein Index für ein Element erstellt, der das Element eindeutig identifiziert.
Intern verwaltet Cosmos DB automatisch die Platzierung von logischen Partitionen auf physischen Partitionen, um die Skalierbarkeit und die Leistungsanforderungen des Containers zu erfüllen. Wenn der Durchsatz der Anwendung und die Speicheranforderungen steigen, verteilt Azure Cosmos DB die logischen Partitionen auf eine größere Anzahl von Servern um. Die Neuverteilungsvorgänge werden von Cosmos DB verwaltet und ohne Unterbrechung oder Downtime aufgerufen.
NewSQL-Datenbanken
NewSQL ist eine aufstrebende Datenbanktechnologie, die die verteilte Skalierbarkeit von NoSQL mit den ACID-Garantien einer relationalen Datenbank kombiniert. NewSQL-Datenbanken sind wichtig für Geschäftssysteme, die große Datenmengen in verteilten Umgebungen verarbeiten müssen, mit voller Transaktionsunterstützung und ACID-Konformität. Eine NoSQL-Datenbank kann zwar eine enorme Skalierbarkeit bieten, aber sie garantiert keine Datenkonsistenz. Zeitweilige Probleme durch inkonsistente Daten können eine Belastung für das Entwicklungsteam darstellen. Entwickler müssen in ihren Microservicecode Sicherheitsvorkehrungen integrieren, um Probleme zu bewältigen, die durch inkonsistente Daten entstehen.
Die Cloud Native Computing Foundation (CNCF) verfügt über mehrere NewSQL-Datenbankprojekte.
| Project | Merkmale |
|---|---|
| Cockroach DB | Eine ACID-konforme, relationale Datenbank, die global skalierbar ist. Fügen Sie einem Cluster einen neuen Knoten hinzu, und Cockroach DB kümmert sich um den Ausgleich der Daten über Instanzen und Geografien hinweg. Es erstellt, verwaltet und verteilt Replikate, um die Zuverlässigkeit sicherzustellen. Es ist Open Source und frei verfügbar. |
| TiDB | Eine Open-Source-Datenbank, die HTAP-Workloads (Hybrid Transactional and Analytical Processing) unterstützt. Es ist MySQL-kompatibel und bietet horizontale Skalierbarkeit, hohe Konsistenz und Hochverfügbarkeit. TiDB verhält sich wie ein MySQL-Server. Sie können die bestehenden MySQL Clientbibliotheken weiterhin verwenden, ohne dass umfangreiche Codeänderungen an Ihrer Anwendung erforderlich sind. |
| YugabyteDB | Eine verteilte Open-Source-SQL-Datenbank mit hoher Leistung. Es unterstützt niedrige Wartezeiten bei Abfragen, Resilienz gegen Ausfälle und eine globale Datenverteilung. YugabyteDB ist PostgressSQL-kompatibel und bewältigt horizontal skalierende RDBMS- und internetweite OLTP-Workloads. Das Produkt unterstützt auch NoSQL und ist mit Cassandra kompatibel. |
| Vitess | Vitess ist eine Datenbanklösung für die Bereitstellung, Skalierung und Verwaltung von großen Clustern von MySQL-Instanzen. Es kann in einer öffentlichen oder privaten Cloudarchitektur ausgeführt werden. Vitess kombiniert und erweitert viele wichtige MySQL Features und bietet sowohl vertikale als auch horizontale Sharding-Unterstützung. Vitess wurde von YouTube entwickelt und sorgt seit 2011 für den gesamten Datenverkehr der YouTube-Datenbank. |
Die Open-Source-Projekte in der vorherigen Abbildung sind bei der Cloud Native Computing Foundation erhältlich. Drei der Angebote sind vollständige Datenbankprodukte, die auch .NET-Unterstützung bieten. Das andere, Vitess, ist ein System für Datenbankclustering, das große Cluster von MySQL-Instanzen horizontal skaliert.
Ein wichtiges Ziel des Entwurfs von NewSQL-Datenbanken ist es, nativ in Kubernetes zu arbeiten und dabei die Resilienz und Skalierbarkeit der Plattform zu nutzen.
NewSQL-Datenbanken sind für kurzlebige Cloudumgebungen konzipiert, in denen die zugrunde liegenden virtuellen Computer in kürzester Zeit neu gestartet oder neu geplant werden können. Die Datenbanken sind so konzipiert, dass sie Knotenausfälle ohne Datenverlust und Downtime überstehen. Cockroach DB ist z. B. in der Lage, den Ausfall eines Computers zu überstehen, indem es drei konsistente Replikate aller Daten auf den Knoten eines Clusters vorhält.
Kubernetes verwendet ein Konstrukt aus Diensten, damit ein Client eine Gruppe identischer NewSQL-Datenbankprozesse über einen einzelnen DNS-Eintrag ansprechen kann. Durch die Entkopplung der Datenbankinstanzen von der Adresse des Diensts, dem sie zugeordnet sind, können wir die Skalierung durchführen, ohne die bestehenden Anwendungsinstanzen zu beeinträchtigen. Wenn Sie zu einem bestimmten Zeitpunkt eine Anforderung an einen beliebigen Dienst senden, erhalten Sie immer das gleiche Ergebnis.
In diesem Szenario sind alle Datenbankinstanzen identisch. Es gibt keine primären oder sekundären Beziehungen. Techniken wie die Konsensreplikation in Cockroach DB ermöglichen es jedem Datenbankknoten, jede Anforderung zu bearbeiten. Wenn der Knoten, der eine Anforderung mit Lastausgleich erhält, die benötigten Daten lokal vorliegen hat, antwortet er sofort. Andernfalls wird der Knoten zu einem Gateway und leitet die Anforderung an die entsprechenden Knoten weiter, um die richtige Antwort zu erhalten. Aus der Sicht des Clients ist jeder Datenbankknoten gleich: Sie wirken wie eine einzige logische Datenbank mit den Konsistenzgarantien eines Einzelcomputersystems, obwohl im Hintergrund Dutzende oder sogar Hunderte von Knoten arbeiten.
Einen detaillierten Einblick in die Funktionsweise von NewSQL-Datenbanken erhalten Sie im Artikel DASH: Four Properties of Kubernetes-Native Databases (DASH: Vier Eigenschaften von Kubernetes-nativen Datenbanken).
Datenmigration zur Cloud
Eine der zeitaufwendigen Aufgaben ist die Migration von Daten von einer Datenplattform zu einer anderen. Der Azure Data Migration Service kann dabei helfen, diese Maßnahmen zu beschleunigen. Er kann Daten aus verschiedenen externen Datenbankquellen mit minimaler Downtime zu Azure-Datenplattformen migrieren. Zielplattformen umfassen die folgenden Dienste:
- Azure SQL-Datenbank
- Azure Database for MySQL
- Azure Database for MariaDB
- Azure Database for PostgreSQL
- Azure Cosmos DB
Der Dienst bietet Empfehlungen, die Sie durch die Änderungen führen, die für die Durchführung einer kleinen oder großen Migration erforderlich sind.