Zwischenspeichern in einer cloudnativen App
Tipp
Diese Inhalte sind ein Auszug aus dem E-Book „Architecting Cloud Native .NET Applications for Azure“, verfügbar in der .NET-Dokumentation oder als kostenlos herunterladbare PDF-Datei, die offline gelesen werden kann.

Die Vorteile der Zwischenspeicherung sind hinlänglich bekannt. Bei dieser Technik werden Daten, auf die häufig zugegriffen wird, vorübergehend von einem Back-End-Datenspeicher in einen schnellen Speicher kopiert, der sich näher an der Anwendung befindet. Zwischenspeicherung wird häufig in folgenden Situationen implementiert:
- Daten verbleiben relativ statisch.
- Der Zugriff auf die Daten ist langsam, insbesondere im Vergleich zur Geschwindigkeit des Cache.
- Die Daten sind in hohem Maße konfliktanfällig.
Warum?
Wie im Leitfaden zur Zwischenspeicherung von Microsoft beschrieben, kann die Zwischenspeicherung die Leistung, Skalierbarkeit und Verfügbarkeit einzelner Microservices und des Systems als Ganzes erhöhen. Sie reduziert die Wartezeit und den Konflikt bei der Bearbeitung großer Mengen gleichzeitiger Anforderungen an einen Datenspeicher. Je größer das Datenvolumen und die Anzahl der Benutzer, desto größer sind die Vorteile der Zwischenspeicherung.
Die Zwischenspeicherung ist am effektivsten, wenn ein Client Daten wiederholt liest, die unveränderlich sind oder sich nur selten ändern. Beispiele hierfür sind Referenzinformationen wie Produkt- und Preisinformationen oder freigegebene statische Ressourcen, deren Erstellung sehr aufwändig ist.
Während Microservices zustandslos sein sollten, kann ein verteilter Cache gleichzeitigen Zugriff auf Sitzungszustandsdaten unterstützen, wenn dies unbedingt erforderlich ist.
Erwägen Sie das Zwischenspeichern ebenfalls, um sich wiederholende Berechnungen zu vermeiden. Wenn ein Vorgang Daten transformiert oder eine komplizierte Berechnung durchführt, speichern Sie das Ergebnis für nachfolgende Anforderungen zwischen.
Cachingarchitektur
Cloudnative Anwendungen implementieren in der Regel eine verteilte Cachearchitektur. Der Cache wird als cloudbasierter Unterstützungsdienst gehostet, der von den Microservices getrennt ist. Abbildung 5-15 zeigt die Architektur.
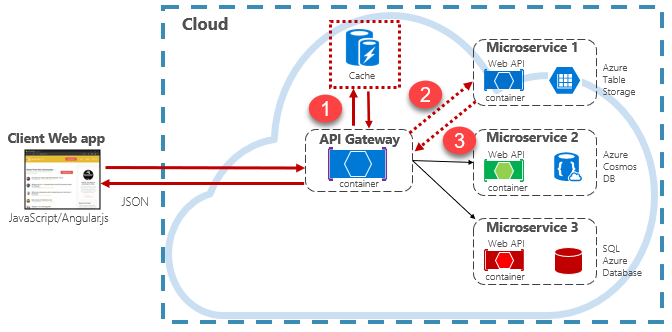
Abbildung 5-15: Zwischenspeichern in einer cloudnativen App
In der vorherigen Abbildung sehen Sie, dass der Cache unabhängig von den Microservices ist und von diesen gemeinsam genutzt wird. In diesem Szenario wird der Cache vom API-Gateway aufgerufen. Wie in Kapitel 4 beschrieben, dient das Gateway als Front-End für alle eingehenden Anforderungen. Der verteilte Cache erhöht die Reaktionsfähigkeit des Systems, indem nach Möglichkeit zwischengespeicherte Daten zurückgegeben werden. Durch die Trennung des Cache von den Diensten kann der Cache außerdem unabhängig hochskaliert werden, um den steigenden Anforderungen im Datenverkehr gerecht zu werden.
Die vorherige Abbildung zeigt ein gängiges Muster für das Zwischenspeichern, das so genannte Cachefremde Muster. Bei einer eingehenden Anforderung fragen Sie zunächst den Cache (Schritt 1) nach einer Antwort ab. Falls gefunden, werden die Daten sofort zurückgegeben. Wenn die Daten nicht im Cache vorhanden sind (so genannter Cachefehler), werden sie in einem nachgelagerten Dienst aus einer lokalen Datenbank abgerufen (Schritt 2). Sie werden dann für zukünftige Anforderungen in den Cache geschrieben (Schritt 3) und an den Aufrufer zurückgegeben. Es muss darauf geachtet werden, dass zwischengespeicherte Daten regelmäßig entfernt werden, sodass das System zeitnah und konsistent bleibt.
Mit zunehmender Größe eines freigegebenen Caches kann es sich als vorteilhaft erweisen, seine Daten auf mehrere Knoten zu verteilen. So können Sie Konflikte minimieren und die Skalierbarkeit verbessern. Viele Cachedienste unterstützen die Möglichkeit des dynamischen Hinzufügens und Entfernens von Knoten sowie die Neuverteilung der Daten auf Partitionen. Dieser Ansatz umfasst in der Regel das Clustering. Clustering macht eine Sammlung von Verbundknoten als reibungslosen, einzelnen Cache verfügbar. Intern werden die Daten jedoch nach einer vordefinierten Verteilungsstrategie, die die Last gleichmäßig verteilt, auf die Knoten verteilt.
Azure Cache for Redis
Azure Cache for Redis ist ein sicherer Dienst für Zwischenspeicherung und Nachrichtenbroker, der vollständig von Microsoft verwaltet wird. Als Platform-as-a-Service (PaaS)-Angebot bietet es einen hohen Durchsatz und einen Zugriff auf die Daten mit geringer Wartezeit. Der Dienst ist für jede Anwendung innerhalb oder außerhalb von Azure zugänglich.
Der Dienst Azure Cache for Redis verwaltet den Zugriff auf Open-Source-Redis-Server, die in Azure-Rechenzentren gehostet werden. Der Dienst fungiert als Fassade für Verwaltung, Zugriffssteuerung und Sicherheit. Der Dienst unterstützt nativ eine Vielzahl von Datenstrukturen, einschließlich Zeichenfolgen, Hashes, Listen und Sets. Wenn Ihre Anwendung bereits Redis verwendet, funktioniert sie mit Azure Cache for Redis wie gewohnt.
Azure Cache for Redis ist mehr als ein einfacher Cacheserver. Es kann eine Reihe von Szenarien zur Verbesserung einer Microservices-Architektur unterstützen:
- Ein In-Memory-Datenspeicher
- Eine verteilte nicht relationale Datenbank
- einen Nachrichtenbroker
- Ein Konfigurations- oder Ermittlungsserver
Bei erweiterten Szenarien kann eine Kopie der zwischengespeicherten Daten auf dem Datenträger gespeichert werden. Wenn ein katastrophales Ereignis sowohl den primären als auch den Replikatcache deaktiviert, wird der Cache anhand der letzten Momentaufnahme rekonstruiert.
Azure Redis Cache ist in einer Reihe vordefinierter Konfigurationen und Tarife verfügbar. Der Premium-Tarif bietet viele Features auf Unternehmensebene, z. B. Clustering, Datenpersistenz, Georeplikation und Isolation im virtuellen Netzwerk.