Was ist cloudnativ?
Tipp
Diese Inhalte sind ein Auszug aus dem E-Book „Architecting Cloud Native .NET Applications for Azure“, verfügbar in der .NET-Dokumentation oder als kostenlos herunterladbare PDF-Datei, die offline gelesen werden kann.

Unterbrechen Sie Ihre Arbeit und bitten Sie Ihre Kollegen, den Begriff „cloudnativ“ zu definieren. Es ist gut möglich, dass Sie mehrere verschiedene Antworten erhalten werden.
Lassen Sie uns mit einer einfachen Definition beginnen:
Cloudnative Architekturen und Technologien sind ein Ansatz zum Entwerfen, Konstruieren und Betreiben von Workloads, die in der Cloud erstellt werden und die Vorteile des Cloud Computing-Modells voll ausschöpfen.
Die Cloud Native Computing Foundation bietet die offizielle Definition:
Cloudnative Technologien ermöglichen es Unternehmen, skalierbare Anwendungen in modernen, dynamischen Umgebungen wie öffentlichen, privaten und Hybrid Clouds zu erstellen und auszuführen. Container, Service Meshes, Microservices, unveränderliche Infrastruktur und deklarative APIs sind Beispiele für diesen Ansatz.
Diese Techniken ermöglichen lose gekoppelte Systeme, die resilient, verwaltbar und beobachtbar sind. In Kombination mit einer robusten Automatisierung ermöglichen sie es Technikern, mit minimalem Aufwand häufig und vorhersehbar Änderungen vorzunehmen, die von großer Bedeutung sind.
Bei Cloudnativ geht es um Geschwindigkeit und Flexibilität. Geschäftssysteme entwickeln sich von der Ermöglichung von Geschäftsfähigkeiten zu Werkzeugen der strategischen Transformation, die die Geschwindigkeit und das Wachstum von Unternehmen beschleunigen. Es ist zwingend erforderlich, dass Sie neue Ideen sofort auf den Markt bringen.
Gleichzeitig sind auch die Geschäftssysteme immer komplexer geworden, und die Benutzer stellen immer höhere Anforderungen. Sie erwarten schnelle Reaktionszeiten, innovative Features und keine Downtime. Leistungsprobleme, wiederkehrende Fehler und die Unfähigkeit, schnell zu arbeiten, sind nicht länger hinnehmbar. Ihre Benutzer werden Ihren Konkurrenten aufsuchen. Cloudnative Systeme sind auf schnellen Wandel, großen Umfang und Resilienz ausgelegt.
Hier sind einige Unternehmen, die cloudnative Techniken eingeführt haben. Beachten Sie die Geschwindigkeit, Flexibilität und Skalierbarkeit, die sie erreicht haben.
| Company | Erfahrung |
|---|---|
| Netflix | Verfügt über mehr als 600 Dienste in der Produktion. Die Bereitstellung erfolgt 100 Mal pro Tag. |
| Uber | Verfügt über mehr als 1.000 Dienste in der Produktion. Die Bereitstellung erfolgt mehrere tausend Mal pro Woche. |
| Verfügt über mehr als 3.000 Dienste in der Produktion. Die Bereitstellung erfolgt 1.000 Mal pro Tag. |
Wie Sie sehen können, machen Netflix, Uber und WeChat cloudnative Systeme verfügbar, die aus vielen unabhängigen Diensten bestehen. Dieser Architekturstil ermöglicht es ihnen, schnell auf die Marktbedingungen zu reagieren. Sie können kleine Bereiche einer komplexen Anwendung sofort aktualisieren, ohne dass eine vollständige erneute Bereitstellung erforderlich ist. Sie skalieren die Dienste individuell nach Bedarf.
Die Grundpfeiler von „cloudnativ“
Die Geschwindigkeit und Flexibilität von cloudnativen Lösungen ist auf viele Faktoren zurückzuführen. In erster Linie auf die Cloudinfrastruktur. Aber das ist noch nicht alles: Fünf weitere Grundpfeiler, die in Abbildung 1-3 dargestellt sind, bilden ebenfalls das Fundament für cloudnative Systeme.
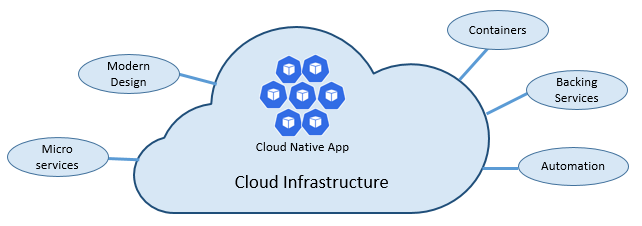
Abbildung 1–3. Cloudnative Grundpfeiler
Nehmen wir uns etwas Zeit, um die Bedeutung der einzelnen Pfeiler besser zu verstehen.
Cloud
Cloudnative Systeme nutzen das Clouddienstmodell voll aus.
Um in einer dynamischen, virtualisierten Cloudumgebung erfolgreich zu sein, nutzen diese Systeme die PaaS-Computeinfrastruktur (Platform-as-a-Service) und verwaltete Dienste umfassend. Sie behandeln die zugrunde liegende Infrastruktur als verwerfbar – sie wird in Minutenschnelle bereitgestellt und bei Bedarf durch Automatisierung in der Größe verändert, skaliert oder zerstört.
Beachten Sie den Unterschied zwischen der Behandlung von Haustieren und allgemeinen Waren. In einem herkömmlichen Rechenzentrum werden Server als Haustiere behandelt: ein physischer Computer, dem ein aussagekräftiger Name gegeben und der gepflegt wird. Sie führen die Skalierung durch, indem Sie demselben Computer mehr Ressourcen hinzufügen (hochskalieren). Wenn der Server „krank“ wird, pflegen Sie ihn wieder gesund. Wenn der Server nicht mehr verfügbar ist, merkt das jeder.
Das Dienstmodell für allgemeine Waren ist anders. Sie stellen jede Instanz als virtuellen Computer oder Container bereit. Sie sind identisch und erhalten eine Systemkennung wie Dienst-01, Dienst-02 usw. Man skaliert, indem man weitere Instanzen erstellt (hochskalieren). Niemand bemerkt, wenn eine Instanz nicht mehr verfügbar ist.
Das Warenmodell umfasst eine unveränderliche Infrastruktur. Server werden nicht repariert oder geändert. Wenn einer ausfällt oder aktualisiert werden muss, wird er zerstört und ein neuer bereitgestellt – alles erfolgt über Automatisierung.
Cloudnative Systeme nehmen das Dienstmodell für allgemeine Waren an. Sie werden weiterhin ausgeführt, wenn die Infrastruktur ab- oder aufskaliert wird, ohne Rücksicht auf die Computer, auf denen sie ausgeführt werden.
Die Azure-Cloudplattform unterstützt diese Art von hochelastischer Infrastruktur mit automatischer Skalierung, Selbstreparatur und Überwachungsfunktionen.
Modernes Design
Wie würden Sie eine cloudnative App entwickeln? Wie würde Ihre Architektur aussehen? An welche Prinzipien, Muster und bewährten Methoden würden Sie sich halten? Welche infrastrukturellen und betrieblichen Belange sind wichtig?
Die Zwölf-Faktoren-Anwendung
Eine weithin akzeptierte Methode zur Erstellung cloudbasierter Anwendungen ist die Twelve-Factor Application (Zwölf-Faktoren-Anwendung). Sie beschreibt eine Reihe von Prinzipien und Praktiken, die Entwickler befolgen, um Anwendungen zu erstellen, die für moderne Cloudumgebungen optimiert sind. Besonderes Augenmerk wird auf die Portabilität zwischen verschiedenen Umgebungen und die deklarative Automatisierung gelegt.
Obwohl die zwölf Faktoren auf jede webbasierte Anwendung anwendbar sind, betrachten viele Anwender sie als solide Grundlage für die Erstellung cloudnativer Apps. Systeme, die auf diesen Prinzipien beruhen, können schnell bereitgestellt und skaliert werden und Features hinzufügen, um schnell auf Marktveränderungen zu reagieren.
Die folgende Tabelle hebt die Zwölf-Faktoren-Methodik hervor:
| Faktor | Erklärung |
|---|---|
| 1 – Codebasis | Eine einzelne Codebasis für jeden Microservice, der in einem eigenen Repository gespeichert ist. Durch Versionskontrolle nachverfolgt, kann sie in mehreren Umgebungen (QA, Staging, Produktion) bereitgestellt werden. |
| 2 – Abhängigkeiten | Jeder Microservice isoliert und verpackt seine eigenen Abhängigkeiten, sodass Änderungen ohne Auswirkungen auf das gesamte System möglich sind. |
| 3 – Konfigurationen | Konfigurationsinformationen werden aus dem Microservice verschoben und durch ein Konfigurationsverwaltungstool außerhalb des Codes ausgelagert. Dieselbe Bereitstellung kann sich mit der richtigen Konfiguration über mehrere Umgebungen erstrecken. |
| 4 – Unterstützungsdienste | Zusätzliche Ressourcen (Datenspeicher, Caches, Nachrichtenbroker) sollten über eine adressierbare URL verfügbar gemacht werden. Dadurch wird die Ressource von der Anwendung entkoppelt und kann ausgetauscht werden. |
| 5 – Build, Release, Ausführung | Jedes Release muss eine strikte Trennung zwischen den Phasen „Build“, „Release“ und „Ausführung“ durchsetzen. Jede Option sollte mit einer eindeutigen ID markiert werden und die Möglichkeit zum Rollback unterstützen. Moderne CI/CD-Systeme tragen dazu bei, dieses Prinzip zu erfüllen. |
| 6 – Prozesse | Jeder Microservice sollte in einem eigenen Prozess ausgeführt werden, der von anderen ausgeführten Diensten isoliert ist. Lagern Sie den erforderlichen Zustand in einen Unterstützungsdienst aus, z. B. einen verteilten Cache oder Datenspeicher. |
| 7 – Portbindung | Jeder Microservice sollte eigenständig sein und seine Schnittstellen und Funktionen über einen eigenen Port zur Verfügung stellen. Dadurch wird die Isolation von anderen Microservices sichergestellt. |
| 8 – Parallelität | Wenn die Kapazität erhöht werden muss, skalieren Sie die Dienste horizontal über mehrere identische Prozesse (Kopien) auf, anstatt eine einzelne große Instanz auf dem leistungsstärksten verfügbaren Computer hochzuskalieren. Entwickeln Sie eine gleichzeitige Anwendung, damit die Aufskalierung in Cloudumgebungen problemlos verläuft. |
| 9 – Verwertbarkeit | Dienstinstanzen sollten verwerfbar sein. Bevorzugen Sie einen schnellen Start, um die Skalierbarkeitschancen zu erhöhen, und ein ordnungsgemäßes Herunterfahren, um das System in einem ordnungsgemäßen Zustand zu belassen. Docker-Container erfüllen zusammen mit einem Orchestrator von Haus aus diese Anforderung. |
| 10 – Dev/Prod-Parität | Halten Sie die Umgebungen über den gesamten Lebenszyklus der Anwendung so ähnlich wie möglich und vermeiden Sie kostspielige Verknüpfungen. Hier kann der Einsatz von Containern einen großen Beitrag leisten, indem er die gleiche Ausführungsumgebung fördert. |
| 11 – Protokollierung | Behandeln Sie von Microservices generierte Protokolle als Ereignisstreams. Verarbeiten Sie sie mit einem Ereignisaggregator. Verteilen Sie Protokolldaten an Data Mining-/Protokollverwaltungstools wie Azure Monitor oder Splunk und schließlich an die Langzeitarchivierung. |
| 12 – Administratorprozesse | Führen Sie Verwaltungs-/Managementaufgaben, z. B. Datenbereinigung oder Computing-Analysen, als einmalige Prozesse aus. Verwenden Sie unabhängige Tools, um diese Aufgaben von der Produktionsumgebung aus aufzurufen, aber getrennt von der Anwendung. |
In dem Buch Beyond the Twelve-Factor App beschreibt der Autor Kevin Hoffman jeden der ursprünglichen 12 Faktoren (geschrieben im Jahr 2011). Außerdem geht er auf drei zusätzliche Faktoren ein, die das heutige moderne Design von Cloudanwendungen widerspiegeln.
| Neuer Faktor | Erklärung |
|---|---|
| 13 – Zuerst API | Machen Sie alles zu einem Dienst. Gehen Sie davon aus, dass Ihr Code von einem Front-End-Client, einem Gateway oder einem anderen Dienst verwendet wird. |
| 14 – Telemetrie | Auf einer Arbeitsstation haben Sie einen detaillierten Einblick in Ihre Anwendung und deren Verhalten. In der Cloud ist das nicht der Fall. Stellen Sie sicher, dass Ihr Entwurf die Sammlung von Überwachungsdaten, domänenspezifischen Daten und Integritäts-/Systemdaten umfasst. |
| 15 – Authentifizierung/Autorisierung | Implementieren Sie die Identität von Anfang an. Erwägen Sie RBAC-Features (rollenbasierte Zugriffssteuerung), die in öffentlichen Clouds verfügbar sind. |
Wir werden in diesem Kapitel und im gesamten Buch auf viele der mehr als 12 Faktoren Bezug nehmen.
Azure Well-Architected Framework
Das Entwerfen und Bereitstellen von cloudbasierten Workloads kann schwierig sein, insbesondere bei der Implementierung der cloudnativen Architektur. Microsoft bietet branchenübliche bewährte Methoden, mit denen Sie und Ihr Team robuste Cloudlösungen bereitstellen können.
Das Microsoft Well-Architected Framework umfasst verschiedene Grundsätze, mit denen die Qualität einer cloudnativen Workload verbessert werden kann. Das Framework besteht aus fünf Säulen der Architekturexzellenz:
| Grundsätze | BESCHREIBUNG |
|---|---|
| Kostenmanagement | Konzentrieren Sie sich darauf, frühzeitig inkrementellen Wert zu generieren. Wenden Sie die Prinzipien von Erstellen-Messen-Lernen an, um die Markteinführung zu beschleunigen und kapitalintensive Lösungen zu vermeiden. Verwenden Sie eine nutzungsbasierte Bezahlungsstrategie und investieren Sie beim Aufskalieren, anstatt eine große Investition im Voraus zu tätigen. |
| Operational Excellence | Automatisieren Sie die Umgebung und die Vorgänge, um die Geschwindigkeit zu erhöhen und menschliche Fehler zu reduzieren. Führen Sie schnell ein Rollback oder Rollforward für Problemupdates aus. Implementieren Sie die Überwachung und Diagnose von Anfang an. |
| Effiziente Leistung | Erfüllen Sie die Anforderungen an Ihre Workloads effizient. Bevorzugen Sie die horizontale Skalierung (aufskalieren), und integrieren Sie sie in Ihre Systeme. Führen Sie fortlaufend Leistungs- und Auslastungstests durch, um mögliche Engpässe zu identifizieren. |
| Zuverlässigkeit | Erstellen Sie Workloads, die sowohl resilient als auch verfügbar sind. Resilienz ermöglicht es Workloads, sich von Ausfällen zu erholen und weiter zu funktionieren. Die Verfügbarkeit stellt sicher, dass die Benutzer jederzeit Zugriff auf Ihre Workload haben. Entwerfen Sie Anwendungen so, dass sie mit Fehlern rechnen und sich von ihnen erholen. |
| Security | Implementieren Sie Sicherheit über den gesamten Lebenszyklus einer Anwendung, vom Entwurf und der Implementierung bis zur Bereitstellung und dem Betrieb. Achten Sie genau auf Identitätsverwaltung, Zugriff auf die Infrastruktur, Sicherheit von Anwendungen, Datenhoheit und Verschlüsselung. |
Für die ersten Schritte bietet Microsoft eine Reihe von Onlinebewertungen an, mit deren Hilfe Sie Ihre aktuellen Workloads in der Cloud anhand der fünf wohlstrukturierten Pfeiler bewerten können.
Microservices
Cloudnative Systeme umfassen Microservices, einen beliebten Architekturstil zur Entwicklung von modernen Anwendungen.
Erstellt als verteilter Satz kleiner, unabhängiger Dienste, die über eine freigegebene Fabric interagieren, teilen sich Microservices die folgenden Merkmale:
Jeder implementiert eine bestimmte Geschäftsfunktion innerhalb eines größeren Domänenkontexts.
Jeder wird autonom entwickelt und kann unabhängig bereitgestellt werden.
Jeder ist eigenständig und kapselt seine eigene Datenspeichertechnologie, Abhängigkeiten und Programmierplattform.
Jeder wird in einem eigenen Prozess ausgeführt und kommuniziert mit anderen mithilfe von Standardkommunikationsprotokollen wie HTTP/HTTPS, gRPC, WebSockets oder AMQP.
Sie fügen sich zu einer Anwendung zusammen.
In Abbildung 1-4 wird ein monolithischer Anwendungsansatz einem Microservice-Ansatz gegenübergestellt. Beachten Sie, dass der monolithische Ansatz aus einer Architektur mit Ebenen besteht, die in einem einzelnen Prozess ausgeführt wird. In der Regel verwendet er eine relationale Datenbank. Der Microservice-Ansatz hingegen unterteilt die Funktionalität in unabhängige Dienste, die jeweils über eine eigene Logik, einen eigenen Zustand und eigene Daten verfügen. Jeder Microservice hostet seinen eigenen Datenspeicher.
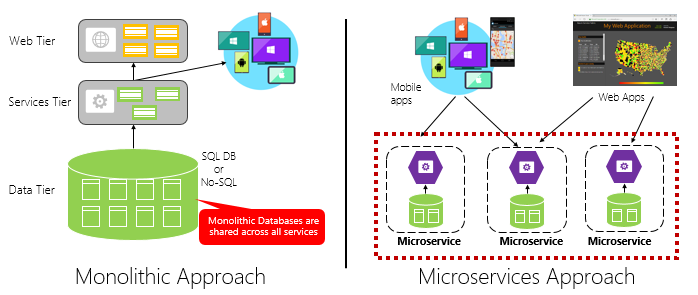
Abbildung 1-4. Monolithische Architektur im Vergleich zur Microservices-Architektur
Beachten Sie, wie Microservices das Prinzip der Prozesse aus der Zwölf-Faktoren-Anwendung fördern, die weiter oben in diesem Kapitel besprochen wurde.
Faktor 6 gibt Folgendes an: „Jeder Microservice sollte in einem eigenen Prozess ausgeführt werden, der von anderen ausgeführten Diensten isoliert ist.“
Gründe für die Verwendung von Microservices
Microservices bieten Flexibilität.
Weiter oben in diesem Kapitel haben wir eine als monolithisch erstellte eCommerce-Anwendung mit einer Anwendung mit Microservices verglichen. In diesem Beispiel haben wir einige klare Vorteile gesehen:
Jeder Microservice verfügt über einen autonomen Lebenszyklus und kann sich unabhängig weiterentwickeln und häufig bereitgestellt werden. Sie müssen nicht auf ein vierteljährliches Release warten, um ein neues Feature oder ein Update bereitzustellen. Sie können einen kleinen Bereich einer Liveanwendung aktualisieren, ohne dass das Risiko einer Unterbrechung des gesamten Systems besteht. Das Update kann ohne eine vollständige erneute Bereitstellung der Anwendung durchgeführt werden.
Jeder Microservice kann unabhängig voneinander skaliert werden. Anstatt die gesamte Anwendung als einzelne Einheit zu skalieren, skalieren Sie nur die Dienste auf, die mehr Rechenleistung benötigen, um die gewünschten Leistungsstufen und Service Level Agreements zu erfüllen. Eine differenzierte Skalierung ermöglicht eine bessere Kontrolle über Ihr System und trägt zur Senkung der Gesamtkosten bei, da Sie Teile Ihres Systems skalieren und nicht alles.
Ein ausgezeichneter Referenzleitfaden für das Verständnis von Microservices ist .NET Microservices: Architektur für .NET-Containeranwendungen. Das Buch beschäftigt sich eingehend mit dem Entwurf und der Architektur von Microservices. Es ist ein Begleiter für eine umfassende Microservice-Referenzarchitektur, die als kostenloser Download von Microsoft erhältlich ist.
Entwickeln von Microservices
Microservices können auf jeder modernen Entwicklungsplattform erstellt werden.
Die Microsoft .NET-Plattform ist eine ausgezeichnete Wahl. Sie ist kostenlos und Open Source und verfügt über viele integrierte Features, die die Entwicklung von Microservices vereinfachen. .NET ist plattformübergreifend. Anwendungen können unter Windows, macOS und den meisten Varianten von Linux erstellt und ausgeführt werden.
.NET ist sehr leistungsfähig und hat im Vergleich zu Node.js und anderen konkurrierenden Plattformen gut abgeschnitten. Interessanterweise hat TechEmpower eine umfangreiche Reihe von Leistungsbenchmarks über viele Webanwendungsplattformen und Frameworks hinweg festgelegt. .NET hat es in die Top 10 geschafft – weit vor Node.js und anderen konkurrierenden Plattformen.
.NET wird von Microsoft und der .NET-Community auf GitHub verwaltet.
Microservice-Herausforderungen
Verteilte cloudnative Microservices können zwar eine enorme Flexibilität und Geschwindigkeit bieten, stellen aber auch viele Herausforderungen dar:
Kommunikation
Wie kommunizieren Front-End-Clientanwendungen mit Back-End-Kern-Microservices? Werden Sie direkte Kommunikation zulassen? Oder könnten Sie die Back-End-Microservices mit einer Gatewayfassade abstrahieren, die Flexibilität, Kontrolle und Sicherheit bietet?
Wie werden die Back-End-Kern-Microservices miteinander kommunizieren? Werden Sie direkte HTTP-Aufrufe zulassen, die die Kopplung erhöhen und die Leistung und Flexibilität beeinträchtigen können? Oder könnten Sie entkoppelte Nachrichten mit Warteschlangen- und Thementechnologien in Betracht ziehen?
Die Kommunikation wird im Kapitel Cloudnative Kommunikationsmuster behandelt.
Resilienz
Eine Microservices-Architektur verlagert Ihr System von der In-Process- zur Out-of-Process-Netzwerkkommunikation. Was passiert in einer verteilten Architektur, wenn Dienst B nicht auf einen Netzwerkaufruf von Dienst A antwortet? Oder was passiert, wenn der Dienst C vorübergehend nicht verfügbar ist und andere Dienste, die ihn aufrufen, blockiert werden?
Resilienz wird im Kapitel Cloudnative Resilienz behandelt.
Verteilte Daten
Jeder Microservice kapselt entwurfsbedingt seine eigenen Daten und stellt Vorgänge über seine öffentliche Schnittstelle zur Verfügung. Wenn dies der Fall ist, wie können Sie Daten abfragen oder eine Transaktion über mehrere Dienste hinweg implementieren?
Verteilte Daten werden im Kapitel Cloudnative Datenmuster behandelt.
Geheimnisse
Wie werden Ihre Microservices Geheimnisse und vertrauliche Konfigurationsdaten sicher speichern und verwalten?
Geheimnisse werden eingehend unter Cloudnative Sicherheit behandelt.
Verwalten der Komplexität mit Dapr
Dapr ist eine verteilte Open-Source-Anwendungsruntime. Durch eine Architektur modularer Komponenten vereinfacht es die Implementierung verteilter Anwendungen erheblich. Sie bietet einen dynamischen Klebstoff, der Ihre Anwendung mit vordefinierten Infrastrukturfunktionen und Komponenten aus der Dapr-Runtime verbindet. Abbildung 1-5 zeigt Dapr aus 6000 m Höhe.
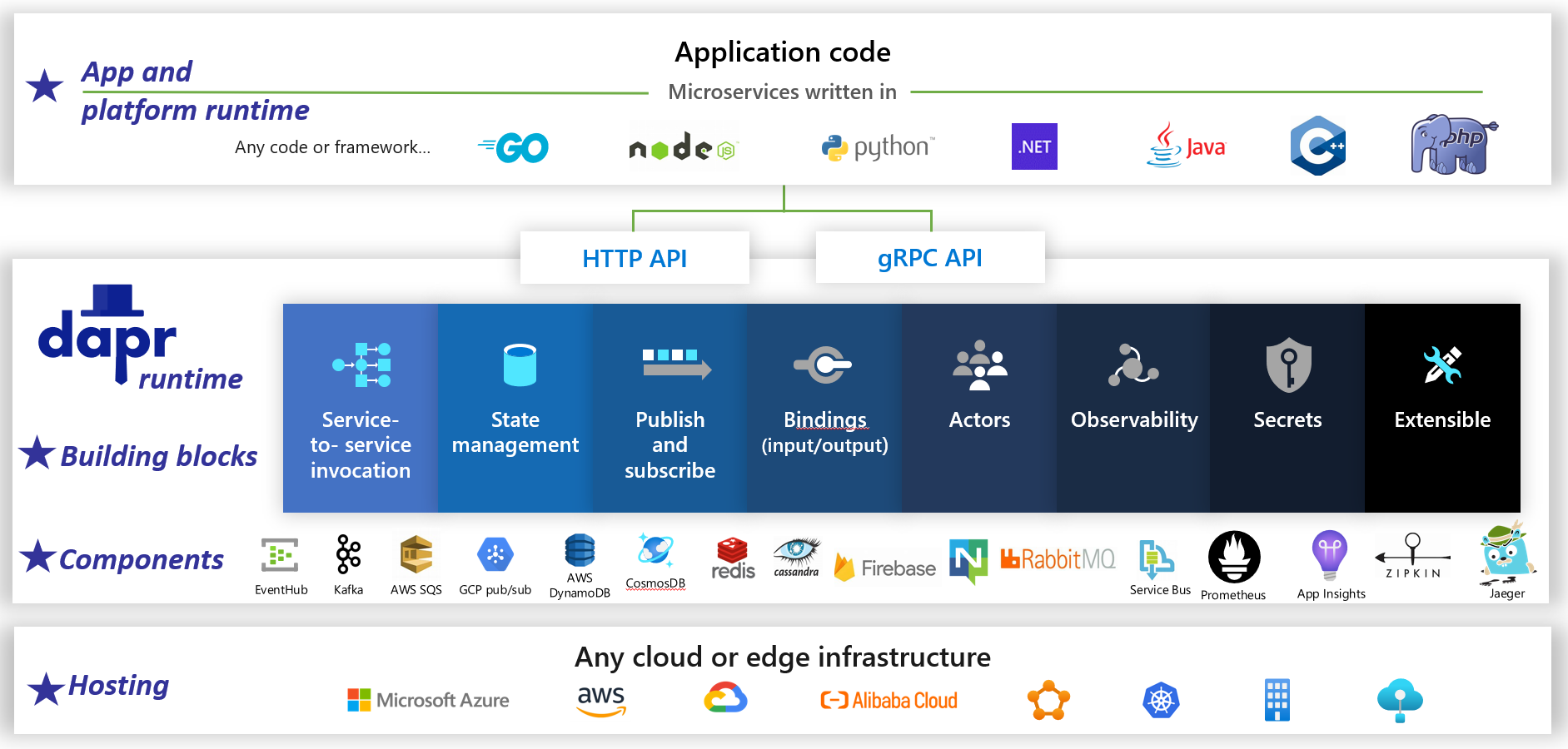 Abbildung 1-5. Dapr aus 6000 m Höhe.
Abbildung 1-5. Dapr aus 6000 m Höhe.
Der obere Bereich der Abbildung zeigt die sprachspezifischen SDKs, die Dapr für gängige Entwicklungsplattformen bereitstellt. Dapr v1 umfasst Unterstützung für .NET, Go, Node.js, Python, PHP, Java und JavaScript.
Obwohl sprachspezifische SDKs das Entwicklererlebnis verbessern, ist Dapr plattformunabhängig. Hinter den Kulissen macht das Programmiermodell von Dapr Funktionen über standardmäßige HTTP/gRPC-Kommunikationsprotokolle verfügbar. Über die nativen HTTP- und gRPC-APIs kann Dapr von beliebigen Programmierplattformen aus aufgerufen werden.
Die blauen Felder in der Mitte der Abbildung stellen die Dapr-Bausteine dar. Jedes stellt vordefinierten Code für eine verteilte Anwendung zur Verfügung, den Ihre Anwendung nutzen kann.
Die Zeile „Komponenten“ stellt eine große Anzahl vordefinierter Infrastrukturkomponenten dar, die Ihre Anwendung nutzen kann. Stellen Sie sich Komponenten als Infrastrukturcode vor, den Sie nicht schreiben müssen.
Der untere Bereich zeigt die Portabilität von Dapr und die verschiedenen Umgebungen, in denen es ausgeführt werden kann.
Mit Blick auf die Zukunft hat Dapr das Potenzial, tiefgreifenden Einfluss auf die Entwicklung cloudnativer Anwendungen auszuüben.
Container
Es ist natürlich, den Begriff Container in jeder cloudnativen Unterhaltung zu hören. In dem Buch Cloud Native Patterns (Cloudnative Muster) stellt die Autorin Cornelia Davis fest: „Container sind ein großartiger Wegbereiter für cloudnative Software.“ Die Cloud Native Computing Foundation stellt die Containerisierung von Microservices als ersten Schritt in ihrer Wegbeschreibung zum cloudnativen System vor – ein Leitfaden für Unternehmen, die ihre cloudnative Journey beginnen.
{kind=link}
Die Containerisierung von Microservices ist einfach und unkompliziert. Der Code, seine Abhängigkeiten und die Runtime werden in eine Binärdatei verpackt, die als Containerimage bezeichnet wird. Images werden in einer Containerregistrierung gespeichert, die als Repository oder Bibliothek für Images fungiert. Eine Registrierung kann sich auf Ihrem Entwicklungscomputer, in Ihrem Rechenzentrum oder in einer öffentlichen Cloud befinden. Docker selbst verwaltet eine öffentliche Registrierung über Docker Hub. Die Azure-Cloud verfügt über eine private Containerregistrierung, um Containerimages in der Nähe der Cloudanwendungen zu speichern, die sie ausführen.
Wenn eine Anwendung gestartet oder skaliert wird, transformieren Sie das Containerimage in eine ausgeführte Containerinstanz. Die Instanz wird auf jedem Computer ausgeführt, auf dem eine Containerruntime-Engine installiert ist. Sie können über beliebig viele Instanzen des containerisierten Diensts verfügen.
Abbildung 1-6 zeigt drei verschiedene Microservices, jeder in seinem eigenen Container, die alle auf einem einzelnen Host ausgeführt werden.
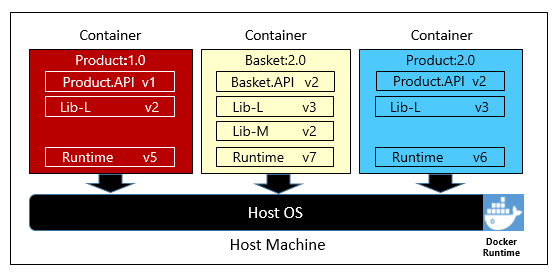
Abbildung 1-6. Mehrere Container, die auf einem Containerhost ausgeführt werden
Beachten Sie, dass jeder Container einen eigenen Satz von Abhängigkeiten und Runtimes verwaltet, die sich voneinander unterscheiden können. Hier sehen wir verschiedene Versionen des Microservices „Produkt“, die auf demselben Host ausgeführt werden. Jeder Container teilt sich ein Segment des zugrunde liegenden Hostbetriebssystems, des Arbeitsspeichers und des Prozessors, ist aber voneinander isoliert.
Beachten Sie, wie gut das Containermodell das Prinzip der Abhängigkeiten aus der Zwölf-Faktoren-Anwendung einbezieht.
Faktor 2 gibt Folgendes an: „Jeder Microservice isoliert und verpackt seine eigenen Abhängigkeiten, sodass Änderungen ohne Auswirkungen auf das gesamte System möglich sind.“
Container unterstützen sowohl Linux- als auch Windows-Workloads. Die Azure-Cloud umfasst beides. Interessanterweise ist Linux, nicht Windows Server, das beliebteste Betriebssystem in Azure.
Es gibt zwar mehrere Containeranbieter, aber Docker hat den Löwenanteil des Markts erobert. Das Unternehmen hat die Bewegung der Softwarecontainer vorangetrieben. Es hat sich zum De-facto-Standard für das Verpacken, Bereitstellen und Ausführen von cloudnativen Anwendungen entwickelt.
Warum Container?
Container bieten Portabilität und garantieren Konsistenz in verschiedenen Umgebungen. Indem Sie alles in einem einzelnen Paket kapseln, isolieren Sie den Microservice und seine Abhängigkeiten von der zugrunde liegenden Infrastruktur.
Sie können den Container in jeder Umgebung bereitstellen, die die Docker-Runtime-Engine hostet. Mit containerisierten Workloads entfallen auch die Kosten für die Vorkonfiguration jeder Umgebung mit Frameworks, Softwarebibliotheken und Runtime-Engines.
Durch die gemeinsame Nutzung des zugrunde liegenden Betriebssystems und der Hostressourcen hat ein Container einen wesentlich geringeren Speicherbedarf als ein vollständiger virtueller Computer. Die geringere Größe erhöht die Dichte bzw. die Anzahl der Microservices, die ein bestimmter Host gleichzeitig ausführen kann.
Containerorchestrierung
Während Tools wie Docker Images erstellen und Container ausführen, benötigen Sie auch Tools, um diese zu verwalten. Die Containerverwaltung erfolgt mit einem speziellen Softwareprogramm, das als Containerorchestrator bezeichnet wird. Wenn Sie im großen Stil mit vielen unabhängig voneinander ausgeführten Containern arbeiten, ist eine Orchestrierung unerlässlich.
Abbildung 1-7 zeigt die Verwaltungsaufgaben, die Containerorchestratoren automatisieren.
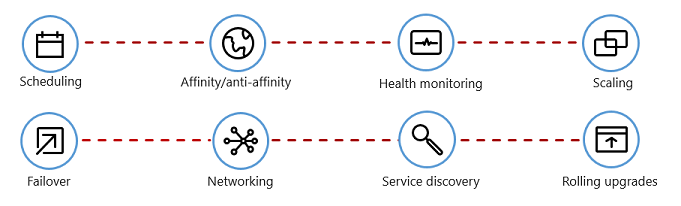
Abbildung 1-7. Aufgaben der Containerorchestratoren
In der folgenden Tabelle werden häufige Orchestratoraufgaben beschrieben.
| Aufgaben | Erklärung |
|---|---|
| Scheduling | Automatische Bereitstellung von Containerinstanzen. |
| Affinität/Anti-Affinität | Bereitstellung von Containern in der Nähe oder weit voneinander entfernt, um die Verfügbarkeit und Leistung zu verbessern. |
| Systemüberwachung | Automatisches Erkennen und Korrigieren von Fehlern. |
| Failover | Automatische erneute Bereitstellung einer fehlerhaften Instanz auf einem fehlerfreien Computer. |
| Skalierung | Automatisches Hinzufügen oder Entfernen einer Containerinstanz zur Erfüllung der Nachfrage. |
| Netzwerk | Verwalten einer Netzwerküberlagerung für die Containerkommunikation. |
| Dienstsuche | Ermöglichen der gegenseitigen Ortung für Container. |
| Parallele Upgrades | Koordinieren inkrementeller Upgrades mit Bereitstellung ohne Downtime. Ausführen eines automatischen Rollbacks problematischer Änderungen. |
Beachten Sie, wie Containerorchestratoren die Prinzipien der Verwertbarkeit und Parallelität der Zwölf-Faktoren-Anwendung nutzen.
Faktor 9 gibt Folgendes an: „Dienst-Instanzen sollten verwerfbar sein, d. h. sie sollten schnelle Starts zum Erhöhen der Skalierbarkeitschancen und das ordnungsgemäße Herunterfahren bevorzugen, um das System in einem ordnungsgemäßen Zustand zu belassen.“ Docker-Container erfüllen zusammen mit einem Orchestrator von Haus aus diese Anforderung.
Faktor 8 gibt Folgendes an: „Dienste werden über eine große Anzahl kleiner identischer Prozesse (Kopien) aufskaliert, im Gegensatz zu einer einzelnen großen Instanz auf dem leistungsstärksten verfügbaren Computer.“
Es gibt zwar mehrere Containerorchestratoren, aber Kubernetes hat sich zum De-facto-Standard für die cloudnative Welt entwickelt. Es ist eine portable, erweiterbare Open-Source-Plattform für die Verwaltung von containerisierten Workloads.
Sie könnten Ihre eigene Instanz von Kubernetes hosten, aber dann wären Sie für die Bereitstellung und Verwaltung der Ressourcen verantwortlich – was sehr komplex sein kann. Die Azure-Cloud unterstützt Kubernetes als verwalteten Dienst. Sowohl Azure Kubernetes Service (AKS) als auch Azure Red Hat OpenShift (ARO) ermöglichen es Ihnen, die Features und die Leistungsfähigkeit von Kubernetes als verwalteten Dienst voll auszuschöpfen, ohne dass Sie es installieren und warten müssen.
Die Containerorchestrierung wird in Skalieren cloudnativer Anwendungen ausführlich behandelt.
Unterstützungsdienste
Cloudnative Systeme hängen von vielen verschiedenen Zusatzressourcen ab, wie z. B. Datenspeichern, Nachrichtenbrokern, Überwachungs- und Identitätsdiensten. Diese Dienste werden als Unterstützungsdienste bezeichnet.
Abbildung 1-8 zeigt viele gängige Unterstützungsdienste, die cloudnative Systeme in Anspruch nehmen.
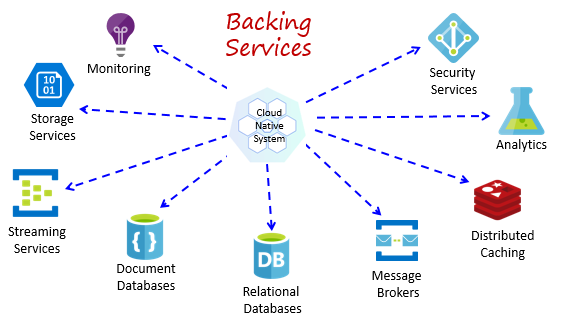
Abbildung 1-8. Allgemeine Unterstützungsdienste
Sie könnten Ihre eigenen Unterstützungsdienste hosten, aber dann wären Sie für die Lizenzierung, Bereitstellung und Verwaltung dieser Ressourcen verantwortlich.
Cloudanbieter bieten eine große Auswahl an verwalteten Unterstützungsdiensten. Anstatt den Dienst zu besitzen, nehmen Sie ihn einfach in Anspruch. Der Cloudanbieter betreibt die Ressource im großen Stil und trägt die Verantwortung für Leistung, Sicherheit und Wartung. Überwachung, Redundanz und Verfügbarkeit sind in den Dienst integriert. Anbieter garantieren die Leistung auf Dienstebene und unterstützen ihre verwalteten Dienste vollständig – öffnen Sie ein Ticket und sie beheben Ihr Problem.
Cloudnative Systeme bevorzugen verwaltete Unterstützungsdienste von Cloudanbietern. Die Ersparnis an Zeit und Aufwand kann erheblich sein. Das Betriebsrisiko, wenn Sie Ihr eigenes Hosting betreiben und es zu Problemen kommt, kann schnell teuer werden.
Eine bewährte Methode besteht darin, einen Unterstützungsdienst als angefügte Ressource zu behandeln, die dynamisch an einen Microservice gebunden ist und deren Konfigurationsinformationen (eine URL und Anmeldeinformationen) in einer externen Konfiguration gespeichert sind. Diese Anleitung wird in der Zwölf-Faktoren-Anwendung beschrieben, die weiter oben im Kapitel erläutert wird.
Faktor 4 gibt an, dass Unterstützungsdienste „über eine adressierbare URL verfügbar gemacht werden sollten. Dadurch wird die Ressource von der Anwendung entkoppelt und kann ausgetauscht werden.“
Faktor 3 gibt Folgendes an: „Konfigurationsinformationen werden aus dem Microservice verschoben und durch ein Konfigurationsverwaltungstool außerhalb des Codes ausgelagert.“
Mit diesem Muster kann ein Unterstützungsdienst ohne Codeänderungen hinzugefügt und entfernt werden. Sie könnten einen Microservice von der QA- in eine Stagingumgebung verschieben. Sie aktualisieren die Microservice-Konfiguration, um auf die Unterstützungsdienste im Staging zu verweisen, und schleusen die Einstellungen über eine Umgebungsvariable in Ihren Container ein.
Cloudanbieter stellen APIs zur Verfügung, über die Sie mit ihren proprietären Unterstützungsdiensten kommunizieren können. Diese Bibliotheken kapseln die proprietäre Installation und die Komplexität. Wenn Sie jedoch direkt mit diesen APIs kommunizieren, ist Ihr Code eng an diesen speziellen Unterstützungsdienst gebunden. Es ist eine weithin akzeptierte Praxis, die Implementierungsdetails der Anbieter-API zu isolieren. Führen Sie eine Zwischenebene bzw. eine Zwischen-API ein, die generische Vorgänge für Ihren Dienstcode bereitstellt, und verpacken Sie den Anbietercode darin. Diese lose Kopplung ermöglicht es Ihnen, einen Unterstützungsdienst gegen einen anderen auszutauschen oder Ihren Code in eine andere Cloudumgebung zu verlagern, ohne Änderungen am Hauptdienstcode vornehmen zu müssen. Das bereits erwähnte Dapr folgt diesem Modell mit seiner Reihe von vorgefertigten Bausteinen.
Schließlich fördern Unterstützungsdienste auch das Prinzip der Zustandslosigkeit aus der Zwölf-Faktoren-Anwendung, die weiter oben in diesem Kapitel besprochen wurde.
Faktor 6 gibt Folgendes an: „Jeder Microservice sollte in einem eigenen Prozess ausgeführt werden, der von anderen ausgeführten Diensten isoliert ist. Lagern Sie den erforderlichen Zustand in einen Unterstützungsdienst aus, z. B. einen verteilten Cache oder Datenspeicher.“
Unterstützungsdienste werden in cloudnativen Datenmustern und cloudnativen Kommunikationsmustern diskutiert.
Automation
Wie Sie gesehen haben, umfassen cloudnative Systeme Microservices, Container und modernes Systemdesign, um Geschwindigkeit und Flexibilität zu erzielen. Aber das ist nur ein Teil der Geschichte. Wie stellen Sie die Cloudumgebungen bereit, auf denen diese Systeme ausgeführt werden? Wie können Sie Features und Updates für Apps schnell bereitstellen? Wie runden Sie das Gesamtbild ab?
Hier kommt die weithin akzeptierte Praxis von Infrastructure-as-Code (IaC) ins Spiel.
Mit IaC automatisieren Sie die Bereitstellung von Plattformen und Anwendungen. Sie wenden im Wesentlichen Praktiken der Softwareentwicklung wie Testen und Versionsverwaltung auf Ihre DevOps-Methoden an. Ihre Infrastruktur und Bereitstellungen sind automatisiert, konsistent und wiederholbar.
Automatisieren der Infrastruktur
Tools wie Azure Resource Manager, Azure Bicep, Terraform von HashiCorp und die Azure CLI, ermöglichen es Ihnen, für die von Ihnen benötigte Cloudinfrastruktur ein deklaratives Skript zu verwenden. Ressourcennamen, Standorte, Kapazitäten und Geheimnisse sind parametrisiert und dynamisch. Das Skript wird mit Versionsangaben versehen und in die Quellcodeverwaltung als Artefakt Ihres Projekts eingecheckt. Sie rufen das Skript auf, um eine konsistente und wiederholbare Infrastruktur in verschiedenen Systemumgebungen, wie QA, Staging und Produktion, bereitzustellen.
Im Grunde ist IaC idempotent, d. h. Sie können das gleiche Skript immer wieder ausführen, ohne dass es zu Nebenwirkungen kommt. Wenn das Team eine Änderung vornehmen muss, bearbeiten sie das Skript und führen es erneut aus. Nur die aktualisierten Ressourcen sind betroffen.
In dem Artikel Was ist „Infrastructure-as-Code“? beschreibt Autor Sam Guckenheimer, wie Teams, die IaC implementieren, stabile Umgebungen schnell und im großen Stil bereitstellen können. Sie vermeiden die manuelle Konfiguration von Umgebungen und erzwingen Konsistenz, indem sie den gewünschten Zustand ihrer Umgebungen über Code darstellen. Infrastrukturbereitstellungen mit IaC sind wiederholbar und verhindern Laufzeitprobleme, die durch Konfigurationsabweichungen oder fehlende Abhängigkeiten verursacht werden. DevOps-Teams können mit einer einheitlichen Reihe von Methoden und Tools zusammenarbeiten, um Anwendungen und die dazugehörige Infrastruktur schnell, zuverlässig und im großen Stil bereitzustellen.
Automatisierte Bereitstellungen
Die Zwölf-Faktoren-Anwendung, die zuvor erläutert wurde, erfordert verschiedene Schritte, um den fertigen Code in eine ausführbare Anwendung zu verwandeln.
Faktor 5 gibt Folgendes an: „Jede Version muss eine strikte Trennung zwischen Build-, Release- und Ausführungsphasen erzwingen. Jede Option sollte mit einer eindeutigen ID markiert werden und die Möglichkeit zum Rollback unterstützen.“
Moderne CI/CD-Systeme tragen dazu bei, dieses Prinzip zu erfüllen. Sie bieten separate Schritte für die Erstellung und Lieferung, die dazu beitragen, konsistenten und hochwertigen Code zu gewährleisten, der den Benutzern sofort zur Verfügung steht.
Abbildung 1-9 zeigt die Trennung im gesamten Bereitstellungsprozess.
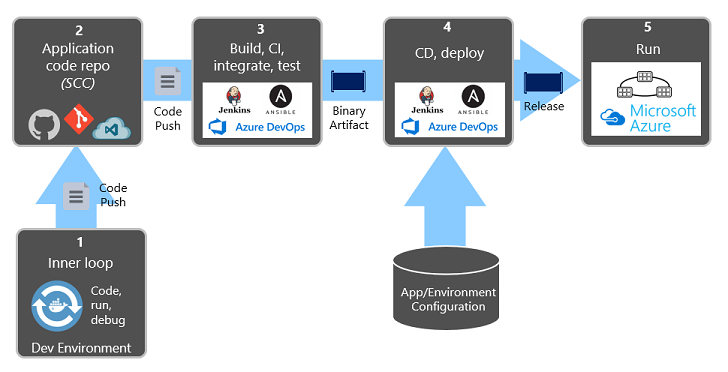
Abbildung 1-9. Bereitstellungsschritte in einer CI/CD-Pipeline
Achten Sie in der vorherigen Abbildung besonders auf die Trennung von Aufgaben:
- Der Entwickler konstruiert ein Feature in seiner Entwicklungsumgebung und durchläuft dabei die so genannte „innere Schleife“ aus Codieren, Ausführen und Debuggen.
- Nach Fertigstellung wird der Code per Push in ein Coderepository wie GitHub, Azure DevOps oder BitBucket übertragen.
- Der Push löst eine Buildphase aus, die den Code in ein binäres Artefakt transformiert. Die Arbeit wird mit einer Continuous Integration (CI)-Pipeline implementiert. Sie erstellt, testet und verpackt die Anwendung automatisch.
- Die Releasephase nimmt das binäre Artefakt auf, wendet externe Anwendungs- und Umgebungskonfigurationsinformationen an und erzeugt ein unveränderliches Release. Das Release wird in einer angegebenen Umgebung bereitgestellt. Die Arbeit wird mit einer Continuous Delivery (CD)-Pipeline implementiert. Jedes Release sollte identifizierbar sein. Sie können sagen: „Diese Bereitstellung führt Release 2.1.1 der Anwendung aus.“
- Schließlich wird das freigegebene Feature in der Zielausführungsumgebung ausgeführt. Releases sind unveränderlich, was bedeutet, dass jede Änderung ein neues Release erstellen muss.
Durch die Anwendung dieser Methoden haben Unternehmen die Art und Weise, wie sie Software ausliefern, radikal verändert. Viele sind von vierteljährlichen Releases zu On-Demand-Updates übergegangen. Das Ziel ist es, Probleme in einem frühen Stadium des Entwicklungszyklus zu erkennen, wenn sie weniger kostspielig zu beheben sind. Je länger die Zeitspanne zwischen den Integrationen ist, desto teurer wird die Lösung der Probleme. Durch die Konsistenz des Integrationsprozesses können Teams Codeänderungen häufiger committen, was zu einer besseren Zusammenarbeit und Softwarequalität führt.
Infrastructure-as-Code und Bereitstellungsautomatisierung sowie GitHub und Azure DevOps werden in DevOps ausführlich erläutert.