Wie Microsoft mit DevOps zuverlässige Systeme betreibt
Microsoft betreibt seit den Anfängen des kommerziellen Internets komplexe Online-Plattformen. Im Laufe der Zeit haben wir eine ganze Reihe von Praktiken entwickelt, um die Verfügbarkeit, den Zustand und die Sicherheit unserer Systeme zu gewährleisten. Diese Praktiken sind Teil einer größeren Initiative zur Aufrechterhaltung und Verbesserung einer Live-Site-Kultur.
Lebendige Standortkultur
Live-Site-Kultur ist der Fokus einer Organisation, die der Erfahrung und Zuverlässigkeit der Live-Site Vorrang vor allem anderen gibt. Schließlich können die Kunden heutzutage mit der Cloud und den internetbasierten Diensten recht einfach den Anbieter wechseln, was die Bedeutung des Kundenvertrauens erheblich steigert. Die Live-Site muss immer verfügbar sein und den Kunden die versprochenen Leistungen bieten.
Es gibt verschiedene Faktoren, die zu einer erfolgreichen Live-Site-Kultur beitragen.
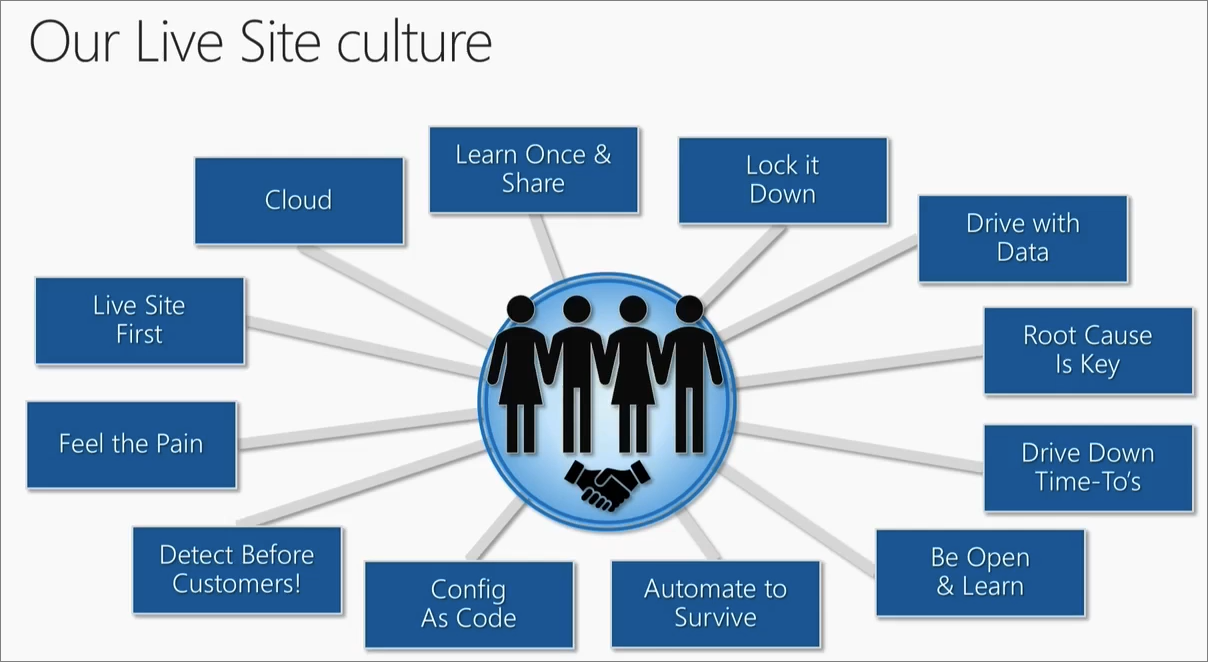
Live-Site zuerst
Für eine erfolgreiche Plattform ist es unabdingbar, dass das Erlebnis der Live-Site an erster Stelle steht. Teams können sich nicht ausschließlich auf neue, glänzende Funktionen konzentrieren und dabei die Art und Weise vernachlässigen, wie diese Funktionen den Benutzern präsentiert werden. Wir verlassen uns auf die sicheren Bereitstellungspraktiken von , die dazu beitragen, dass unsere Kunden ununterbrochenen Zugang zur Plattform haben. Dies kann besonders kompliziert werden, wenn es darum geht, versionierte Service-Updates ohne Ausfallzeiten zu veröffentlichen.
Steuerung der Belichtung durch Merkmalsauszeichnungen
Während wir unsere Ringe und Stufenimplementieren, die Exposition mit Feature-Flags kontrollieren, entdecken wir gelegentlich ein Problem in der Produktion. Trotz all unserer Automatisierungs- und Überprüfungsmaßnahmen kommt es immer wieder zu Zwischenfällen. Wie man so schön sagt: Es gibt keinen besseren Ort als die Produktion!
Normalerweise alarmieren uns die Gesundheitsüberwachung und die Telemetrie, wenn etwas nicht in Ordnung ist. Ein Entwickler kann einen Zweig von main erstellen, eine Korrektur vornehmen und einen Pull-Request auf main stellen. Die Beibehaltung des gleichen allgemeinen Arbeitsablaufs bedeutet, dass die Entwickler nicht den Kontext wechseln oder einen anderen Prozess für eine andere Codeänderung lernen müssen.
Für die Bereitstellung eines Hotfixes ist ein weiterer Schritt erforderlich, nämlich die Übernahme der Änderung in den Versionszweig. Wir führen jeden Werktag morgens eine Hotfix-Bereitstellung aus dem aktuellen Versionszweig durch, können dies aber auch bei dringenden Korrekturen auf Anfrage tun. Die Korrektur wird zuerst aus dem Release-Zweig in die Produktion übernommen. Da wir aber zuerst in main entwickeln, wissen wir, dass es im nächsten Sprint keinen Rückschritt geben wird, wenn ein neuer Release-Zweig von main erstellt wird.
Releases von On-Premises-Produkten sind weitgehend identisch, allerdings ohne die Bereitstellungsringe und -stufen. Da wir außerdem mehr manuelle Tests mit verschiedenen Konfigurationen und Datenformen durchführen, ist die Zeitspanne zwischen dem Schneiden des Freigabezweigs und der Übergabe des Produkts an den Kunden länger.
Sicherheit sollte persönlich genommen werden
Der Schwerpunkt liegt darauf, Schwachstellen real und persönlich zu machen. So wird sichergestellt, dass man sich wirklich kümmert. Wir nutzen auch ausgiebig War Games, um Sicherheitsrisiken im gesamten System zu finden und zu beseitigen, unabhängig davon, ob sie im Code enthalten sind oder nicht. Wenn das rote Team nachweisen kann, dass es in den Code eingedrungen ist, indem es ein Dialogfeld auf den Kopf gestellt hat, motiviert das den Code-Eigentümer, sich des Problems anzunehmen und dafür zu sorgen, dass es nirgendwo anders mehr auftritt. Diese Art von Wettbewerb ist viel realer und persönlicher als eine statische Analyse, die vor einem potenziellen XSS-Risiko warnt. Wir schaffen diese Art von Kultur und Dynamik durch Kriegsspiele und andere Sicherheitsübungen. Die Menschen sind stolz darauf, den Code der anderen zu hacken oder die Versuche zu blockieren. Dadurch wird eine sichere Code-Kultur geschaffen.
Wir können nicht jeden Angriffsvektor planen, aber wir können davon ausgehen, dass es einen Einbruch geben wird, und planen, wie schnell wir auf diesen Einbruch reagieren können. Ein großer Teil der Sicherheitsarbeit für unsere Teams dreht sich um diesen Bereich.
Schließlich machen auch Menschen Fehler. Manchmal werden sie faul und speichern z. B. Passwörter auf gemeinsamen Dateien. Wir können ihnen sagen, dass sie es nicht tun sollen, wir können sie zu einem Sicherheitstraining schicken und wir können alle möglichen anderen Dinge tun. Die meisten Menschen lernen, aber es braucht nur eine Person, um das System zu durchbrechen. Man kann alle möglichen Listen mit bewährten Praktiken aufstellen, aber solange man das nicht in die Tat umsetzt, muss man davon ausgehen, dass die Leute Fehler machen werden. Dies erfordert ein gewisses Maß an Aufsicht, um sicherzustellen, dass kritische Prozesse eingehalten werden.
Technik ist mehr als ein Partner für den Betrieb
Wir haben schon früh gelernt, die Live-Site zu einem wichtigen Bestandteil der Aufgaben des Ingenieurteams zu machen. Das war für uns sehr wichtig, denn in der Vergangenheit konnte es vorkommen, dass eine Person etwas bereitstellte, über das Wochenende wegfuhr und am Montag zurückkam, um 900 Kundenprobleme vorzufinden, mit denen der Kundensupport und die Betriebsteams das ganze Wochenende beschäftigt waren. Es ist wichtig, dass die Technik den Preis für die Probleme der Live-Site zahlt. Andernfalls gibt es keinen Anreiz, Systeme zu entwickeln, die diese Probleme vermeiden. Wenn man um 2 Uhr morgens angerufen wird, um etwas zu reparieren, das man kaputt gemacht hat, erinnert man sich daran.
Als wir diese Verantwortung übernommen haben, wurde „Live Site ist die wichtigste Angelegenheit für uns“ zum Mantra des gesamten Teams. Es ist die Erfahrung, die die Kunden jetzt machen, und es ist nicht nur eine Steuer. Das ist etwas, worauf die Menschen bei uns zählen und worauf wir stolz sind. Es muss ein Unterscheidungsmerkmal für unser Produkt sein.
Die Produktionstelemetrie ist der Herzschlag Ihres Dienstes
Um in der schnelllebigen Welt, in der praktisch alles schief gehen kann, überleben zu können, brauchen wir hervorragende Warnsysteme. Nicht umsetzbare Warnungen, redundante Warnungen oder eine zu große Anzahl von Warnungen veranlassen Sie dazu, alle Warnungen zu ignorieren. Es ist leicht, viel zu viele Warnmeldungen zu erstellen, so dass sich der Prozess eigentlich auf eine einfache Frage reduziert: Ist diese Meldung verwertbar? So können wir sicherstellen, dass wir uns um die richtigen Kundenprobleme kümmern und sie so schnell wie möglich bearbeiten.
Als das Technikteam sich auf umsetzbare Warnungen konzentrierte, stellte es fest, dass viele Probleme, die vor allem mitten in der Nacht auftauchen, zumindest vorübergehend ähnliche Lösungen haben. Dies führte dazu, dass man sich auf Systeme konzentrierte, die besser in der Lage waren, auszufallen und sich selbst zu reparieren. Jetzt treten die Probleme auf, lösen Warnungen aus und beheben sich dann von selbst, so dass das Technikteam bis zum Morgen warten kann, um sie zu beheben. Das wäre nicht passiert, wenn das Entwicklungsteam nur Teile herausgebracht hätte, die andere Leute nachts wach hielten. Jetzt arbeiten sie daran, diese Verbesserungen auszugleichen, und zwar nicht nur im Hinblick auf die Geschwindigkeit der Funktionen, sondern auch auf die Geschwindigkeit der technischen Verbesserungen.
Zusammenfassung
Die Einführung einer Live-Site-Kultur hat sich auf die Art und Weise ausgewirkt, wie Microsoft Software entwickelt und bereitstellt. Indem wir die technischen Teams zu einem wichtigen Bestandteil der Sicherheit und des Betriebs gemacht haben, haben sich die Qualität unseres Codes und die Erfahrung der Endbenutzer drastisch verbessert. Durch die umfassende Beteiligung an den Abläufen ist die Technik zu einem wichtigen Interessenvertreter geworden, was zu Systemen führt, die für bessere Abläufe konzipiert sind.