Ein Schritt nach vorn für Tests in der Produktionsumgebung
Shift Right ist die Praxis, einige Tests im DevOps-Prozess nach hinten zu verschieben, um in der Produktion zu testen. Beim Testen in der Produktion werden echte Bereitstellungen verwendet, um das Verhalten und die Leistung einer Anwendung in der Produktionsumgebung zu validieren und zu messen.
Eine Möglichkeit für DevOps-Teams, die Geschwindigkeit zu erhöhen, ist eine Shift Left-Teststrategie. Shift Left verlagert die meisten Tests in der DevOps-Pipeline nach vorne, um die Zeit zu verkürzen, in der neuer Code die Produktion erreicht und zuverlässig funktioniert.
Aber während viele Arten von Tests, wie z. B. Unit-Tests, problemlos Shift Left ausführen können, sind einige Testklassen ohne die Bereitstellung eines Teils oder der gesamten Lösung nicht lauffähig. Die Bereitstellung in einem QA- oder Staging-Service kann eine vergleichbare Umgebung simulieren, aber es gibt keinen vollständigen Ersatz für die Produktionsumgebung. Teams stellen fest, dass bestimmte Arten als Test-in-Produktion durchgeführt werden müssen.
Test-in-Produktion bietet:
- Die ganze Bandbreite und Vielfalt der Produktionsumgebung.
- Die tatsächliche Arbeitsbelastung durch den Kundenverkehr.
- Profile und Verhaltensweisen, wenn sich die Produktionsnachfrage im Laufe der Zeit entwickelt.
Das Produktionsumfeld verändert sich ständig. Selbst wenn sich eine App nicht ändert, ändert sich die Infrastruktur, auf die sie angewiesen ist, ständig. Test-in-Produktion validiert den Zustand und die Qualität einer bestimmten Bereitstellung und der sich ständig ändernden Produktionsumgebung.
Shift Right to Test in der Produktion ist besonders wichtig für die folgenden Szenarien:
Microservices Bereitstellungen
Microservices-basierte Lösungen können eine große Anzahl von Microservices enthalten, die unabhängig voneinander entwickelt, bereitgestellt und verwaltet werden. Das Shift Right to Test ist für diese Projekte besonders wichtig, da verschiedene Versionen und Konfigurationen auf verschiedene Weise in die Produktion gelangen können. Unabhängig von der Testabdeckung vor der Produktion ist es notwendig, die Kompatibilität in der Produktion zu testen.
Sicherstellung der Qualität nach der Bereitstellung
Die Freigabe zur Produktion ist nur die Hälfte der Bereitstellung von Software. Die andere Hälfte ist die Sicherstellung von Qualität in großem Maßstab mit echter Arbeitsbelastung in der Produktion. Da sich die Umgebung ständig ändert, kann ein Team nie den Test-in-Produktion beenden.
Bei den Testdaten aus der Produktion handelt es sich um die Testergebnisse aus dem realen Workload des Kunden. Zu den Test-in-Produktion gehören Überwachung, Failover-Tests und Fehlersuche. Diese Tests verfolgen Fehler, Ausnahmen, Metriken und Sicherheitsereignisse. Die Testtelemetrie hilft auch, Anomalien zu erkennen.
Bereitstellungsringe
Um die Produktionsumgebung zu schützen, können Teams Änderungen schrittweise und kontrolliert einführen, indem sie ringbasierte Bereitstellungen und Feature Flags verwenden. Es ist zum Beispiel besser, einen Fehler zu finden, der einen Kunden daran hindert, seinen Kauf abzuschließen, wenn weniger als 1 % der Kunden in diesem Bereitstellungsring sind, als wenn alle Kunden auf einmal umgestellt werden. Der Merkmalswert mit erkannten Ausfällen muss die Nettoverluste dieser Ausfälle übersteigen, die für das jeweilige Unternehmen sinnvoll gemessen werden.
Der erste Ring sollte die kleinste Größe haben, die für die Ausführung der Standard-Integrationssuite erforderlich ist. Die Tests können denen ähneln, die bereits früher in der Pipeline in anderen Umgebungen durchgeführt wurden, aber das Testen validiert, dass das Verhalten in der Produktionsumgebung dasselbe ist. Dieser Ring identifiziert offensichtliche Fehler, wie z. B. Fehlkonfigurationen, bevor sie sich auf Kunden auswirken.
Nachdem der erste Ring validiert wurde, kann der nächste Ring erweitert werden, um eine Untergruppe echter Benutzer für den Testlauf einzubeziehen. Wenn das Ergebnis zufriedenstellend ist, kann die Bereitstellung weitere Ringe und Tests durchlaufen, bis sie von allen genutzt wird. Eine vollständige Bereitstellung bedeutet nicht, dass die Tests abgeschlossen sind. Die Verfolgung der Telemetrie ist für den Test-in-Produktion von entscheidender Bedeutung.
Einschleusen von Fehlern
Die Teams setzen häufig Fehlerinjektion und Chaos-Engineering ein, um zu sehen, wie sich ein System unter Fehlerbedingungen verhält. Diese Praktiken unterstützen:
- Überprüfung, ob die implementierten Ausfallsicherheitsmechanismen tatsächlich funktionieren.
- Überprüfung, ob ein Ausfall in einem Teilsystem auf dieses Teilsystem beschränkt ist und nicht zu einem größeren Ausfall führen kann.
- Nachweis, dass die Reparaturarbeiten für einen früheren Vorfall den gewünschten Effekt haben, ohne auf einen weiteren Vorfall warten zu müssen.
- Erstellung realistischerer Schulungen für Ingenieure vor Ort, damit sie sich besser auf Zwischenfälle vorbereiten können.
Es ist eine gute Praxis, Experimente zur Fehlerinjektion zu automatisieren, da es sich um teure Tests handelt, die auf sich ständig verändernden Systemen durchgeführt werden müssen.
Chaos-Engineering kann ein effektives Werkzeug sein, sollte aber auf kritische Umgebungen beschränkt werden, die keine oder nur geringe Auswirkungen auf die Kunden haben.
Failover-Tests
Eine Form der Fehlerinjektion sind Failover-Tests zur Unterstützung von Business Continuity und Disaster Recovery (BCDR). Teams sollten über Ausfallsicherungspläne für alle Dienste und Subsysteme verfügen. Die Pläne sollten Folgendes enthalten:
- Eine klare Erklärung der geschäftlichen Auswirkungen des Ausfalls des Dienstes.
- Eine Karte mit allen Abhängigkeiten in Bezug auf Plattform, Technologie und Personen, die die BCDR-Pläne entwickeln.
- Formelle Dokumentation der Verfahren zur Wiederherstellung im Notfall.
- Eine Kadenz für die regelmäßige Durchführung von Disaster Recovery-Übungen.
Prüfung von Leistungsschaltern auf Fehler
Ein Stromkreisunterbrecher trennt eine bestimmte Komponente von einem größeren System ab, in der Regel um zu verhindern, dass sich Ausfälle in dieser Komponente außerhalb der Grenzen des Systems ausbreiten. Sie können absichtlich Schutzschalter auslösen, um die folgenden Szenarien zu testen:
Ob ein Fallback funktioniert, wenn der Schutzschalter geöffnet wird. Der Fallback mag mit Unit-Tests funktionieren, aber die einzige Möglichkeit, herauszufinden, ob er sich in der Produktion wie erwartet verhält, besteht darin, einen Fehler zu injizieren, um ihn auszulösen.
Ob der Schutzschalter die richtige Empfindlichkeitsschwelle hat, um zu öffnen, wenn er muss. Die Fehlerinjektion kann Latenzzeiten erzwingen oder Abhängigkeiten aufheben, um die Reaktionsfähigkeit von Unterbrechern zu beobachten. Es ist wichtig, nicht nur zu überprüfen, ob das richtige Verhalten auftritt, sondern auch, ob es schnell genug geschieht.
Beispiel: Testen einer Redis-Cache-Sicherung
Der Redis-Cache verbessert die Produktleistung, indem er den Zugriff auf häufig verwendete Daten beschleunigt. Betrachten Sie ein Szenario, das eine unkritische Abhängigkeit von Redis annimmt. Wenn Redis ausfällt, sollte das System weiterhin funktionieren, da es für Anforderungen auf die ursprüngliche Datenquelle zurückgreifen kann. Um zu bestätigen, dass ein Redis-Ausfall einen Trigger auslöst und dass der Notfallmechanismus in der Produktion funktioniert, führen Sie in regelmäßigen Abständen Tests gegen diese Verhaltensweisen durch.
Das folgende Diagramm zeigt Tests für das Fallback-Verhalten der Redis-Schutzschalter. Das Ziel ist es, sicherzustellen, dass die Anfragen, wenn der Schalter geöffnet wird, letztendlich an SQL gehen.
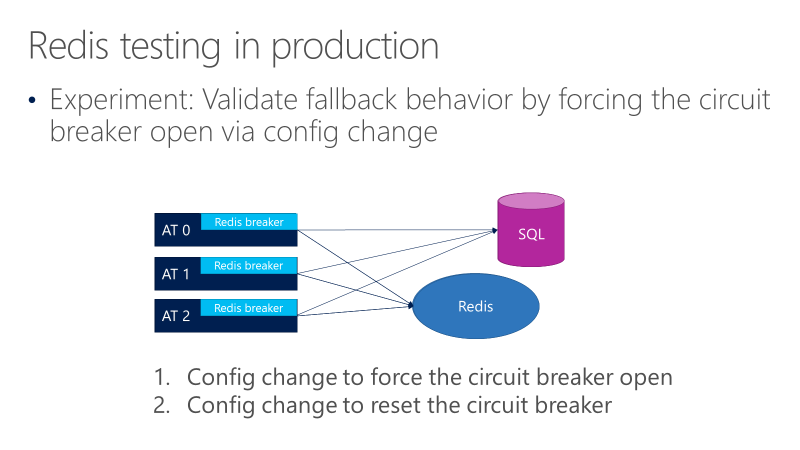
Das vorstehende Diagramm zeigt drei ATs, wobei die Unterbrecher vor den Zugriffen auf Redis stehen. Ein Test zwingt den Leistungsschalter durch eine Konfigurationsänderung zum Öffnen und beobachtet dann, ob die Anfragen an SQL gehen. Ein weiterer Test überprüft dann die gegenteilige Konfigurationsänderung, indem er den Stromkreisunterbrecher schließt, um zu bestätigen, dass die Anfragen wieder zu Redis zurückkehren.
Dieser Test bestätigt, dass das Fallback-Verhalten beim Öffnen des Schalters funktioniert, aber er bestätigt nicht, dass die Konfiguration des Leistungsschalters den Schalter zum richtigen Zeitpunkt öffnet. Um dieses Verhalten zu testen, müssen tatsächliche Ausfälle simuliert werden.
Ein Fehleragent kann Fehler in Anfragen an Redis einbringen. Das folgende Diagramm zeigt einen Test mit Fehlerinjektion.
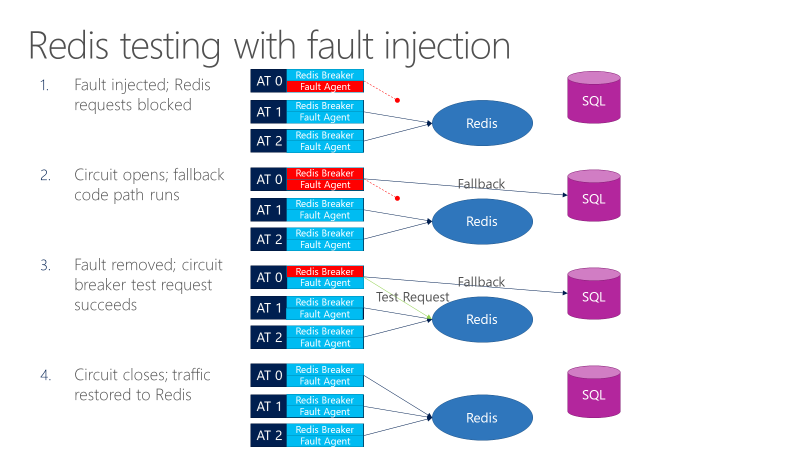
- Der Fehlerinjektor blockiert Redis-Anforderungen.
- Der Schutzschalter öffnet sich, und der Test kann beobachten, ob der Fallback funktioniert.
- Die Störung wird beseitigt, und der Schutzschalter sendet eine Testanforderung an Redis.
- Wenn die Anforderung erfolgreich ist, kehren die Anfragen zu Redis zurück.
Weitere Schritte könnten die Empfindlichkeit des Unterbrechers testen, ob der Schwellenwert zu hoch oder zu niedrig ist und ob andere Systemzeitüberschreitungen das Verhalten des Unterbrechers beeinträchtigen.
Wenn in diesem Beispiel der Unterbrecher nicht wie erwartet öffnet oder schließt, könnte dies einen Vorfall unter Spannung (LSI - Live Site Incident) verursachen. Ohne die Fehlerinjektionstests könnte das Problem unentdeckt bleiben, da es schwierig ist, diese Art von Tests in einer Laborumgebung durchzuführen.