Vektorspeicher in Azure KI-Suche
Azure KI-Suche bietet einen Vektorspeicher und Konfigurationen für die Vektorsuche und Hybridsuche. Die Unterstützung wird auf Feldebene implementiert, was bedeutet, dass Sie Vektor- und Nichtvektorfelder im gleichen Suchkorpus kombinieren können.
Vektoren werden in einem Suchindex gespeichert. Verwenden Sie die REST-API zum Erstellen von Indizes oder eine entsprechende Azure SDK-Methode, um den Vektorspeicher zu erstellen.
Überlegungen zur Vektorspeicherung umfassen die folgenden Punkte:
- Entwerfen eines Schemas, das basierend auf dem beabsichtigten Vektorabrufmuster für Ihren Anwendungsfall geeignet ist
- Schätzen der Indexgröße und Überprüfen der Suchdienstkapazität
- Verwalten eines Vektorspeichers
- Sichern eines Vektorspeichers
Vektorabrufmuster
In Azure KI-Suche gibt es zwei Muster für die Arbeit mit Suchergebnissen.
Generative Suche: Sprachmodelle formulieren mithilfe von Daten aus Azure KI-Suche eine Antwort auf die Abfrage der Benutzer. Dieses Muster umfasst eine Orchestrierungsschicht, um Prompts zu koordinieren und den Kontext beizubehalten. Bei diesem Muster werden Suchergebnisse an Promptflows übertragen, die von Chatmodellen wie GPT und Text-Davinci empfangen werden. Dieser Ansatz basiert auf der RAG-Architektur (Retrieval Augmented Generation), bei der der Suchindex die Basisdaten bereitstellt.
Klassische Suche mit Suchleiste, Abfrageeingabezeichenfolge und zurückgegebenen Ergebnissen. Die Suchmaschine empfängt die Vektorabfrage, führt sie aus und formuliert eine Antwort, und Sie geben diese Ergebnisse in einer Client-App aus. In der Azure KI-Suche werden die Ergebnisse in einem vereinfachten Zeilensatz zurückgegeben, und Sie können auswählen, welche Felder die Suchergebnisse enthalten sollen. Da es kein Chatmodell gibt, wird erwartet, dass Sie den Vektorspeicher (Suchindex) mit Nichtvektorinhalten auffüllen, die in Ihrer Antwort für Benutzer lesbar sind. Obwohl die Suchmaschine mit Vektoren arbeitet, sollten Sie Nichtvektorwerte verwenden, um die Suchergebnisse aufzufüllen. Vektorabfragen und Hybridabfragen decken die Arten von Abfrageanforderungen ab, die Sie für klassische Suchszenarien formulieren können.
Ihr Indexschema sollte Ihren primären Anwendungsfall widerspiegeln. Im folgenden Abschnitt werden die Unterschiede bei der Feldkomposition für Lösungen hervorgehoben, die für generative KI oder die klassische Suche konzipiert sind.
Schema eines Vektorspeichers
Das Indexschema eines Vektorspeichers erfordert einen Namen, ein Schlüsselfeld (Zeichenfolge), ein oder mehrere Vektorfelder und eine Vektorkonfiguration. Nichtvektorfelder werden für Hybridabfragen oder die Rückgabe von ausführlichen, lesbaren Inhalten empfohlen, die kein Sprachmodell durchlaufen müssen. Anweisungen zur Vektorkonfiguration finden Sie unter Erstellen eines Vektorspeichers.
Grundlegende Vektorfeldkonfiguration
Vektorfelder unterscheiden sich durch ihren Datentyp und vektorspezifische Eigenschaften. So sieht ein Vektorfeld in einer Feldsammlung aus:
{
"name": "content_vector",
"type": "Collection(Edm.Single)",
"searchable": true,
"retrievable": true,
"dimensions": 1536,
"vectorSearchProfile": "my-vector-profile"
}
Vektorfelder weisen spezifische Datentypen auf. Derzeit ist Collection(Edm.Single) am häufigsten, aber die Verwendung schmaler Datentypen kann Speicher einsparen.
Vektorfelder müssen durchsuchbar und abrufbar sein, können aber nicht gefiltert, facettiert oder sortiert werden, und können auch keine Analysetools, Normalisierungsfunktionen oder Synonymzuordnungsaufträge haben.
Vektorfelder müssen dimensions enthalten, die auf die Anzahl der Einbettungen festgelegt sind, die vom Einbettungsmodell generiert werden. Zum Beispiel werden 1.536 Einbettungen für jeden Textblock von „text-embedding-ada-002“ generiert.
Vektorfelder werden mit Algorithmen indiziert, die durch ein Vektorsuchprofil angegeben werden, das an anderer Stelle im Index definiert ist und somit nicht im Beispiel gezeigt wird. Weitere Informationen finden Sie unter Vektorsuchkonfiguration.
Sammlung der Felder für grundlegende Vektorworkloads
Vektorspeicher erfordern weitere Felder neben Vektorfeldern. Zum Beispiel ist ein Schlüsselfeld ("id" in diesem Beispiel) eine Indexanforderung.
"name": "example-basic-vector-idx",
"fields": [
{ "name": "id", "type": "Edm.String", "searchable": false, "filterable": true, "retrievable": true, "key": true },
{ "name": "content_vector", "type": "Collection(Edm.Single)", "searchable": true, "retrievable": true, "dimensions": 1536, "vectorSearchProfile": null },
{ "name": "content", "type": "Edm.String", "searchable": true, "retrievable": true, "analyzer": null },
{ "name": "metadata", "type": "Edm.String", "searchable": true, "filterable": true, "retrievable": true, "sortable": true, "facetable": true }
]
Andere Felder, wie das Feld "content", sind das für Benutzer lesbare Äquivalent zum Feld "content_vector". Wenn Sie Sprachmodelle ausschließlich für die Formulierung von Antworten verwenden, können Sie Nichtvektorinhaltsfelder weglassen, aber Lösungen, die Suchergebnisse direkt zu Client-Apps pushen, sollten Nichtvektorinhalte haben.
Metadatenfelder sind nützlich für Filter (insbesondere dann, wenn Metadaten Ursprungsinformationen zum Quelldokument enthalten). Sie können Filter nicht direkt auf Vektorfelder anwenden, allerdings können Sie Vor- oder Nachfiltermodi festlegen, um vor oder nach der Ausführung einer Vektorabfrage zu filtern.
Vom Assistenten zum Importieren und Vektorisieren von Daten generiertes Schema
Es wird empfohlen, den Assistenten zum Importieren und Vektorisieren von Daten für Auswertungen und Proof-of-Concept-Tests zu verwenden. Der Assistent generiert das Beispielschema in diesem Abschnitt.
Die Verzerrung dieses Schemas besteht darin, dass Suchdokumente auf Datenblöcken basieren. Wenn ein Sprachmodell die Antwort formuliert, wie es bei RAG-Apps üblich ist, sollten Sie ein Schema verwenden, das für Datenblöcke konzipiert ist.
Datenblöcke sind erforderlich, um innerhalb der Eingabegrenzen von Sprachmodellen zu bleiben. Sie verbessert jedoch auch die Genauigkeit bei der Ähnlichkeitssuche, wenn Abfragen mit kleineren Inhaltsblöcken abgeglichen werden können, die aus mehreren übergeordneten Dokumenten gepullt werden. Wenn Sie schließlich den semantischen Sortierer verwenden, weist er auch Tokenbeschränkungen auf, die einfacher einzuhalten sind, wenn die Datensegmentierung Teil Ihres Ansatzes ist.
Im folgenden Beispiel gibt es für jedes Suchdokument eine Block-ID, einen Block, einen Block, einen Titel und ein Vektorfeld. Die Block-ID und die übergeordnete ID werden vom Assistenten mit der Base64-Codierung von Blobmetadaten (Pfad) aufgefüllt. Block und Titel werden von den Blobinhalten und dem Blobnamen abgeleitet. Nur das Vektorfeld wird vollständig generiert. Es ist die vektorisierte Version des Blockfelds. Einbettungen werden durch das Aufrufen eines von Ihnen bereitgestellten Azure OpenAI-Einbettungsmodells generiert.
"name": "example-index-from-import-wizard",
"fields": [
{"name": "chunk_id", "type": "Edm.String", "key": true, "searchable": true, "filterable": true, "retrievable": true, "sortable": true, "facetable": true, "analyzer": "keyword"},
{ "name": "parent_id", "type": "Edm.String", "searchable": true, "filterable": true, "retrievable": true, "sortable": true},
{ "name": "chunk", "type": "Edm.String", "searchable": true, "filterable": false, "retrievable": true, "sortable": false},
{ "name": "title", "type": "Edm.String", "searchable": true, "filterable": true, "retrievable": true, "sortable": false},
{ "name": "vector", "type": "Collection(Edm.Single)", "searchable": true, "retrievable": true, "dimensions": 1536, "vectorSearchProfile": "vector-1707768500058-profile"}
]
Schema für RAG- und Chat-Apps
Wenn Sie einen Speicher für die generative Suche entwerfen, können Sie separate Indizes für die von Ihnen indizierten oder vektorisierten statischen Inhalte erstellen. Zudem können Sie einen zweiten Index für Unterhaltungen erstellen, die in Promptflows verwendet werden können. Die folgenden Indizes werden durch den Beschleuniger chat-with-your-data-solution-accelerator erstellt.
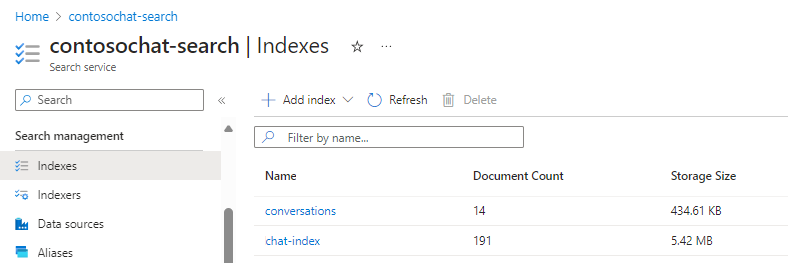
Felder aus dem Chatindex, die die generative Suche unterstützen:
"name": "example-index-from-accelerator",
"fields": [
{ "name": "id", "type": "Edm.String", "searchable": false, "filterable": true, "retrievable": true },
{ "name": "content", "type": "Edm.String", "searchable": true, "filterable": false, "retrievable": true },
{ "name": "content_vector", "type": "Collection(Edm.Single)", "searchable": true, "retrievable": true, "dimensions": 1536, "vectorSearchProfile": "my-vector-profile"},
{ "name": "metadata", "type": "Edm.String", "searchable": true, "filterable": false, "retrievable": true },
{ "name": "title", "type": "Edm.String", "searchable": true, "filterable": true, "retrievable": true, "facetable": true },
{ "name": "source", "type": "Edm.String", "searchable": true, "filterable": true, "retrievable": true },
{ "name": "chunk", "type": "Edm.Int32", "searchable": false, "filterable": true, "retrievable": true },
{ "name": "offset", "type": "Edm.Int32", "searchable": false, "filterable": true, "retrievable": true }
]
Felder aus dem Unterhaltungsindex, der die Orchestrierung und den Chatverlauf unterstützt:
"fields": [
{ "name": "id", "type": "Edm.String", "key": true, "searchable": false, "filterable": true, "retrievable": true, "sortable": false, "facetable": false },
{ "name": "conversation_id", "type": "Edm.String", "searchable": false, "filterable": true, "retrievable": true, "sortable": false, "facetable": true },
{ "name": "content", "type": "Edm.String", "searchable": true, "filterable": false, "retrievable": true },
{ "name": "content_vector", "type": "Collection(Edm.Single)", "searchable": true, "retrievable": true, "dimensions": 1536, "vectorSearchProfile": "default-profile" },
{ "name": "metadata", "type": "Edm.String", "searchable": true, "filterable": false, "retrievable": true },
{ "name": "type", "type": "Edm.String", "searchable": false, "filterable": true, "retrievable": true, "sortable": false, "facetable": true },
{ "name": "user_id", "type": "Edm.String", "searchable": false, "filterable": true, "retrievable": true, "sortable": false, "facetable": true },
{ "name": "sources", "type": "Collection(Edm.String)", "searchable": false, "filterable": true, "retrievable": true, "sortable": false, "facetable": true },
{ "name": "created_at", "type": "Edm.DateTimeOffset", "searchable": false, "filterable": true, "retrievable": true },
{ "name": "updated_at", "type": "Edm.DateTimeOffset", "searchable": false, "filterable": true, "retrievable": true }
]
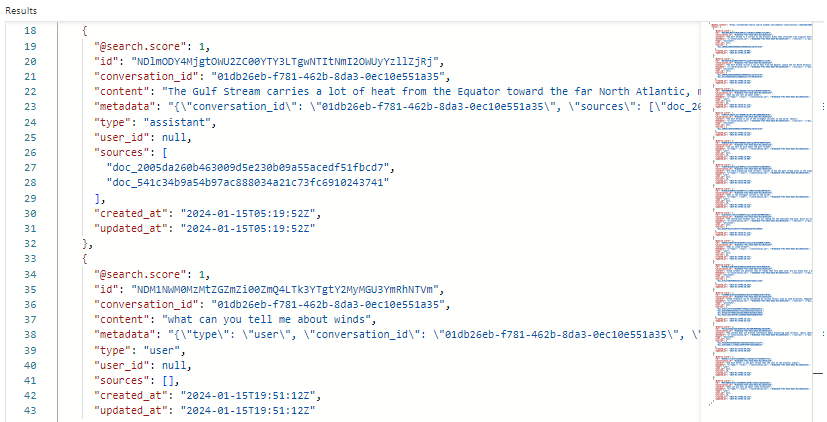
Auf diesem Screenshot werden Suchergebnisse für den Unterhaltungsindex im Such-Explorer dargestellt. Der Suchscore liegt bei 1,00, weil die Suche nicht qualifiziert war. Beachten Sie die Felder, die zur Unterstützung der Orchestrierung und der Promptflows vorhanden sind. Eine Unterhaltungs-ID identifiziert einen bestimmten Chat.
"type" gibt an, ob der Inhalt vom Benutzer oder vom Assistenten stammt. Datumsangaben werden verwendet, um Chats aus dem Verlauf nach ihrem Alter zu sortieren.
Physische Struktur und Größe
In Azure AI Search ist die physische Struktur eines Indexes weitgehend eine interne Implementierung. Sie können auf das Schema zugreifen, seinen Inhalt laden und abfragen, seine Größe überwachen und die Kapazität verwalten. Die Cluster selbst (invertierte Indizes und Vektorindizes) sowie andere Dateien und Ordner werden jedoch intern von Microsoft verwaltet.
Größe und Inhalt eines Indexes werden durch Folgendes bestimmt:
- Umfang und Zusammensetzung Ihrer Dokumente
- Attribute für einzelne Felder. Für filterbare Felder ist beispielsweise mehr Speicherplatz erforderlich.
- Die Indexkonfiguration, einschließlich der Vektorkonfiguration, die angibt, wie die internen Navigationsstrukturen basierend darauf erstellt werden, ob Sie HNSW oder das umfassende KNN-Modell für die Ähnlichkeitssuche auswählen
Azure KI-Suche erzwingt Grenzwerte für den Vektorspeicher, wodurch ein ausgewogenes und stabiles System für alle Workloads erhalten bleibt. Um Sie dabei zu unterstützen, die Grenzwerte nicht zu überschreiten, wird die Vektornutzung separat im Azure-Portal sowie programmgesteuert über Dienst- und Indexstatistiken nachverfolgt und gemeldet.
Der folgende Screenshot zeigt einen S1-Dienst, der mit einer Partition und einem Replikat konfiguriert ist. Dieser bestimmte Dienst verfügt über 24 kleine Indizes mit durchschnittlich einem Vektorfeld, wobei jedes Feld aus 1536 Einbettungen besteht. Die zweite Kachel zeigt das Kontingent und die Nutzung der Vektorindizes an. Ein Vektorindex ist eine interne Datenstruktur, die für jedes Vektorfeld erstellt wird. Darum ist der Speicher für Vektorindizes stets ein Bruchteil des vom Index insgesamt verwendeten Speichers. Andere Felder und Datenstrukturen ohne Vektoren belegen den übrigen Speicherplatz.
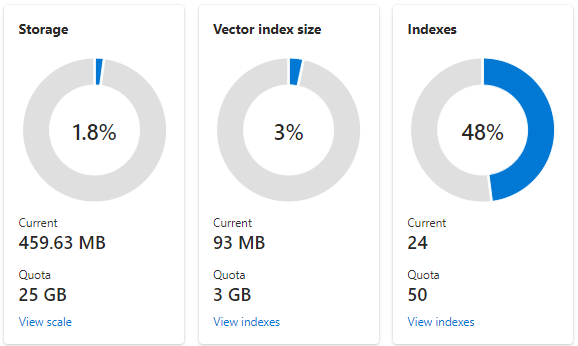
Grenzwerte und Schätzungen für Vektorindizes werden in einem anderen Artikel behandelt. Die zwei zu Beginn wichtigen Punkte sind jedoch die folgenden: Der maximale Speicherplatz unterscheidet sich je nach Dienstebene und nach dem Erstellungszeitpunkt des Suchdiensts. Neuere Dienste der gleichen Ebene weisen deutlich mehr Kapazität für Vektorindizes auf. Führen Sie aus diesen Gründen die folgenden Aktionen aus:
Überprüfen Sie das Bereitstellungsdatum Ihres Suchdiensts. Wenn er vor dem 3. April 2024 erstellt wurde, sollten Sie einen neuen Suchdienst erstellen, um eine größere Kapazität zu erhalten.
Wählen Sie eine skalierbare Ebene aus, wenn Sie von Schwankungen der Anforderungen an den Vektorspeicher ausgehen. Im Basic-Tarif kann bei älteren Suchdiensten lediglich eine Partition verwendet werden. Ziehen Sie Standard 1 (S1) und höher in Betracht, um mehr Flexibilität und schnellere Leistung zu erhalten, oder erstellen Sie einen neuen Suchdienst, der höhere Grenzwerte und mehr Partitionen auf jeder löschbaren Ebene verwendet.
Grundlegende Vorgänge und Interaktionen
In diesem Abschnitt werden Laufzeitvorgänge bei Vektoren vorgestellt, einschließlich der Verbindung mit einem einzelnen Index sowie dessen Sicherung.
Hinweis
Beachten Sie bei der Verwaltung eines Indexes, dass es keine Portal- oder API-Unterstützung für das Verschieben oder Kopieren eines Indexes gibt. Stattdessen richten die Kunden ihre Lösung zur Anwendungsbereitstellung in der Regel auf einen anderen Suchdienst aus (wenn sie denselben Indexnamen verwenden) oder ändern den Namen, um eine Kopie des aktuellen Suchdienstes zu erstellen, und bauen ihn dann auf.
Ständig verfügbar
Ein Index ist sofort für Abfragen verfügbar, sobald das erste Dokument indiziert ist, aber erst dann vollständig funktionsfähig, wenn alle Dokumente indiziert sind. Intern wird ein Index über Partitionen verteilt und auf Replikaten ausgeführt. Der physische Index wird intern verwaltet. Der logische Index wird von Ihnen verwaltet.
Ein Index ist ständig verfügbar, ohne dass er angehalten oder offline genommen werden kann. Da er für einen kontinuierlichen Betrieb ausgelegt ist, erfolgen alle Aktualisierungen seines Inhalts oder Ergänzungen des Index selbst in Echtzeit. Daher kann es vorkommen, dass Abfragen vorübergehend unvollständige Ergebnisse liefern, wenn eine Anforderung mit einer Dokumentenaktualisierung zusammenfällt.
Beachten Sie, dass die Abfragekontinuität für Dokumentoperationen (Aktualisieren oder Löschen) und für Änderungen besteht, die sich nicht auf die bestehende Struktur und Integrität des aktuellen Index auswirken (z. B. Hinzufügen neuer Felder). Wenn Sie strukturelle Aktualisierungen vornehmen müssen (Änderung vorhandener Felder), werden diese in der Regel durch einen Drop-and-Rebuild-Workflow in einer Entwicklungsumgebung oder durch die Erstellung einer neuen Version des Indexes im Produktionsdienst verwaltet.
Um die Neuerstellung eines Indexes zu vermeiden, entscheiden sich einige Kunden, die kleine Änderungen vornehmen, für die Versionsverwaltung eines Felds, indem sie ein neues Feld erstellen, das neben einer früheren Version existiert. Im Laufe der Zeit führt dies zu verwaisten Inhalten in Form von veralteten Feldern oder veralteten benutzerdefinierten Analyzer-Definitionen, insbesondere in einem Produktionsindex, der teuer zu replizieren ist. Sie können diese Probleme bei geplanten Aktualisierungen des Index im Rahmen des Index-Lebenszyklusverwaltung angehen.
Endpunktverbindung
Alle Indizierungs- und Abfrageanforderungen für Vektoren zielen auf einen Index ab. Endpunkte sind in der Regel einer der folgenden:
| Endpunkt | Verbindung und Zugangskontrolle |
|---|---|
<your-service>.search.windows.net/indexes |
Zielt auf die Sammlung der Indizes. Wird bei der Erstellung, Auflistung oder Löschung eines Index verwendet. Für diese Vorgänge sind Administratorrechte erforderlich, die über Administrator-API-Schlüssel oder eine Rolle für Mitwirkende an der Suche verfügbar sind. |
<your-service>.search.windows.net/indexes/<your-index>/docs |
Zielt auf die Dokumentensammlung eines einzelnen Indexes ab. Wird beim Abfragen eines Indexes oder einer Datenaktualisierung verwendet. Für Abfragen sind Leserechte ausreichend und über Abfrage-API-Schlüssel oder eine Datenleserrolle verfügbar. Für die Datenaktualisierung sind Administratorrechte erforderlich. |
Herstellen einer Verbindung mit Azure KI-Suche
Stellen Sie sicher, dass Sie Berechtigungen haben oder über einen API-Zugriffsschlüssel verfügen. Wenn Sie keinen vorhandenen Index abfragen, benötigen Sie Administratorrechte oder eine Rollenzuweisung als Mitwirkender, um Inhalte in einem Suchdienst zu verwalten und anzuzeigen.
Beginnen Sie mit dem Azure-Portal. Die Person, die den Suchdienst erstellt hat, kann den Suchdienst anzeigen und verwalten, einschließlich der Gewährung des Zugriffs für andere Personen über die Seite Zugriffssteuerung (IAM).
Fahren Sie fort mit anderen Clients für den programmgesteuerten Zugriff. Die Schnellstarts und Beispiele werden für die ersten Schritte empfohlen:
Sicherer Zugriff auf Vektordaten
Azure KI-Suche implementiert Datenverschlüsselung, private Verbindungen für Szenarios ohne Internet und Rollenzuweisungen für den sicheren Zugriff über Microsoft Entra ID. Die gesamte Bandbreite an Sicherheitsfeatures für Unternehmen wird in Sicherheit in Azure KI-Suche beschrieben.
Verwalten von Vektorspeichern
Azure bietet eine Überwachungsplattform, die die Diagnoseprotokollierung und Warnungen beinhaltet. Wir empfehlen die folgenden bewährten Methoden:
- Diagnoseprotokollierung aktivieren
- Einrichten von Warnungen
- Analysieren der Abfrage- und Indexleistung