Schätzen und Verwalten der Kapazität eines Suchdiensts
In Azure AI Search basiert die Kapazität auf Replikaten und Partitionen, die auf Ihre Workload skaliert werden können. Replikate sind Kopien des Suchmoduls. Partitionen sind Speichereinheiten. Jeder neue Suchdienst beginnt mit jeweils einem, Aber Sie können Replikate und Partitionen unabhängig voneinander hinzufügen oder entfernen, um schwankende Workloads zu berücksichtigen. Durch das Hinzufügen von Kapazität wird die Kosten für die Ausführung eines Suchdienstserhöht.
Die technischen Merkmale von Replikaten und Partitionen, z. B. Verarbeitungsgeschwindigkeit und Datenträger-E/A, variieren je nach Dienstebene. Bei einem Standardmäßigen Suchdienst sind die Replikate und Partitionen schneller und größer als die eines grundlegenden Diensts.
Wenn die Kapazität geändert wird, ist dies nicht sofort wirksam. Die Inbetrieb- bzw. Außerbetriebnahme von Partitionen kann bis zu eine Stunde dauern. Dies gilt vor allem für Dienste mit großen Datenmengen.
Beim Skalieren eines Suchdiensts können Sie zwischen den folgenden Tools und Ansätzen wählen:
Hinweis
Höhere Kapazitätspartitionen sind mit dem gleichen Abrechnungssatz für neuere Dienste verfügbar, die nach April und Mai 2024 erstellt wurden. Weitere Informationen für Upgrades zur Partitionsgröße finden Sie unter Dienstbeschränkungen.
Konzepte: Sucheinheiten, Replikate, Partitionen
Kapazität wird in Sucheinheiten ausgedrückt, die in Kombinationen von Partitionen und Replikaten zugeordnet werden können.
| Konzept | Definition |
|---|---|
| Sucheinheit | Eine einzelnes Inkrement der verfügbaren Gesamtkapazität (36 Einheiten). Zum Ausführen des Diensts ist mindestens eine Einheit erforderlich. Das erste Replikat- und Partitionspaar ist die erste Sucheinheit. Jede zusätzliche Instanz eines Replikats oder einer Partition verbraucht jedoch eine zusätzliche Sucheinheit. Sie beginnen z. B. mit einem Replikat und einer Partition (einer Sucheinheit), fügen ein zweites Replikat hinzu, sie verbrauchen jetzt zwei Sucheinheiten. Eine Sucheinheit ist auch die Abrechnungseinheit für einen Azure KI-Suche-Dienst. |
| Replikat | Replikate sind Instanzen des Suchdiensts und dienen in erster Linie zum Lastenausgleich bei Abfragevorgängen. Jedes Replikat hostet eine Kopie eines Indexes. Wenn Sie drei Replikate zuordnen, stehen Ihnen drei Kopien eines Indexes für die Bearbeitung von Abfrageanforderungen zur Verfügung. |
| Partition | Physischer Speicher und E/A für Lese-/Schreibvorgänge (z. B. bei der Neuerstellung oder Aktualisierung eines Index). Jede Partition hat einen Anteil am Gesamtindex. Wenn Sie drei Partitionen zuordnen, wird Ihr Index in Drittel aufgeteilt. |
In der Tabelle Partitions- und Replikatskombinationen finden Sie mögliche Kombinationen, die unter der Grenze von 36 Einheiten bleiben.
Wann Sie Kapazität hinzufügen sollten
Zunächst wird einem Dienst eine Mindestmenge von Ressourcen (bestehend aus einer Partition und einem Replikat) zugeordnet. Der ausgewählte Tarif bestimmt die Größe und Geschwindigkeit der Partition, und jeder Tarif ist um eine Reihe von Eigenschaften optimiert, die auf bestimmte Szenarien ausgerichtet sind. Wenn Sie sich für einen höherwertigen Tarif entscheiden, benötigen Sie möglicherweise weniger Partitionen als bei S1. Eine der Fragen, die Sie durch selbstgesteuerte Tests beantworten müssen, lautet: Bringt eine größere und teurere Partition eine bessere Leistung als zwei billigere Partitionen bei einem Dienst, der in einem niedrigeren Tarif bereitgestellt wird?
Ein einzelner Dienst muss über genügend Ressourcen verfügen, um sämtliche Workloads (Indizierung und Abfragen) bewältigen zu können. Beide Workloads laufen nicht im Hintergrund. Sie können die Indizierung für Zeiten planen, in denen Abfrageanforderungen naturgemäß weniger häufig sind, aber der Dienst priorisiert ansonsten keine Aufgabe gegenüber einer anderen. Zusätzlich gleicht ein gewisses Maß an Redundanz die Abfrageleistung aus, wenn Dienste oder Knoten intern aktualisiert werden.
Richtlinien für die Entscheidung, ob Kapazität hinzugefügt werden soll, sind z. B.:
- Erfüllen der Hochverfügbarkeitskriterien für die Vereinbarung zum Servicelevel
- Die Häufigkeit von HTTP 503-Fehlern nimmt zu
- Es werden große Abfragevolumina erwartet
Allgemein gilt: Suchanwendungen benötigen in der Regel mehr Replikate als Partitionen – insbesondere, wenn die Dienstvorgänge auf Abfrageworkloads ausgerichtet sind. Jedes Replikat ist eine Kopie Ihres Index und ermöglicht dem Dienst, die Anforderungslast auf verschiedene Kopien zu verteilen. Der gesamte Lastenausgleich und die Replikation eines Index werden von Azure AI Search verwaltet. Sie können die Anzahl der Replikate, die Ihrem Dienst zugeordnet sind, jederzeit ändern. In einem Suchdienst mit Tarif „Standard“ können Sie bis zu 12 Replikate zuordnen, im Tarif „Basic“ bis zu drei. Die Replikatzuordnung kann entweder über die Azure-Portal oder eine der programmgesteuerten Optionen vorgenommen werden.
Zusätzliche Partitionen sind hilfreich für intensive Indizierungsworkloads. Zusätzliche Partitionen verteilen Lese-/ Schreibvorgänge über eine größere Anzahl von Computerressourcen.
Schließlich erfordern größere Indizes eine längere Abfragezeit. Daher werden Sie feststellen, dass jede inkrementelle Zunahme an Partitionen einen kleineren, aber proportionalen Anstieg der Replikate erforderlich macht. Die Komplexität Ihrer Abfragen und das Abfragevolumen haben darauf Einfluss, wie schnell die Abfrage ausgeführt wird.
Hinweis
Wenn Sie weitere Replikate oder Partitionen hinzufügen, erhöhen sich die Kosten für die Ausführung des Diensts. Außerdem kann die Sortierung der Ergebnisse leicht variieren. Sie sollten daher den Preisrechner verwenden, um die Auswirkungen des Hinzufügens weiterer Knoten auf die Abrechnung zu verstehen. Das Diagramm unten kann Ihnen helfen, die Anzahl der für eine bestimmte Konfiguration erforderlichen Sucheinheiten zu ermitteln. Weitere Informationen dazu, wie sich zusätzliche Replikate auf die Abfrageverarbeitung auswirken, finden Sie unter Sortieren von Ergebnissen.
So ändern Sie die Kapazität
Um die Kapazität Ihres Suchdiensts zu erhöhen oder zu verringern, fügen Sie Partitionen und Replikate hinzu, oder entfernen Sie sie.
Melden Sie sich beim Azure-Portal an, und wählen Sie den Suchdienst aus.
Öffnen Sie unter Einstellungen die Seite Skalierung, um Replikate und Partitionen zu ändern.
Der folgende Screenshot zeigt einen Standarddienst, der mit einem Replikat und einer Partition bereitgestellt wurde. Die Formel im unteren Bereich gibt an, wie viele Sucheinheiten verwendet werden (1). Wenn der Preis pro Einheit 100 US-Dollar wäre (kein echter Preis), würden die monatlichen Kosten für die Ausführung dieses Diensts durchschnittlich 100 US-Dollar betragen.
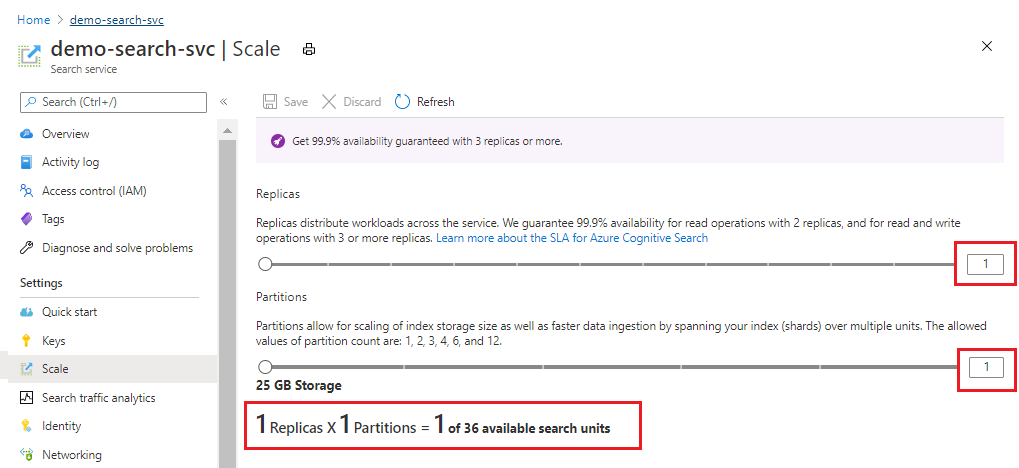
Mit dem Schieberegler können Sie die Anzahl der Partitionen erhöhen oder verringern. Wählen Sie Speichern aus.
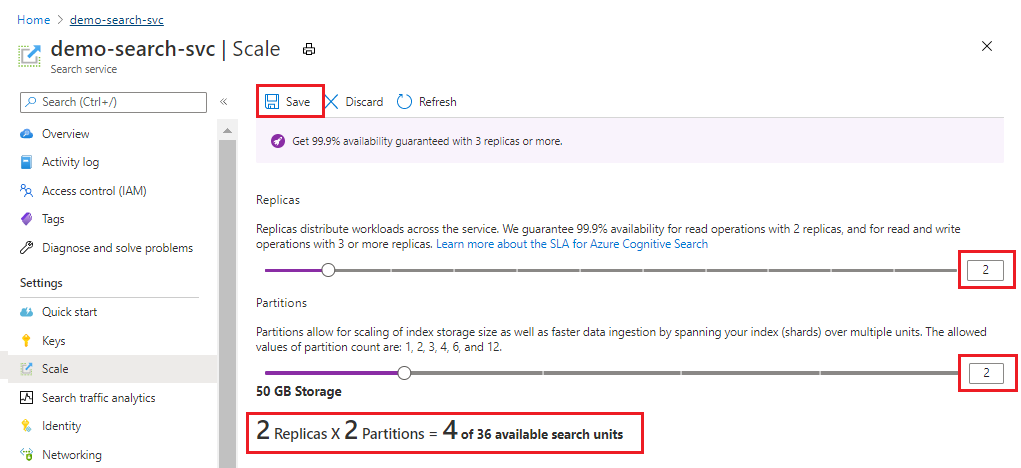
In diesem Beispiel werden ein zweites Replikat und eine zweite Partition hinzugefügt. Beachten Sie die Anzahl der Sucheinheiten. Sie beträgt jetzt vier, weil die Formel für die Abrechnung lautet: Replikate multipliziert mit Partitionen (2 x 2). Bei einer Verdopplung der Kapazität fallen mehr als doppelt so hohe Kosten für die Ausführung des Diensts an. Wenn die Kosten für die Sucheinheit 100 US-Dollar wären, würde die neue Monatsrechnung jetzt 400 US-Dollar betragen.
Wenn Sie die aktuellen Kosten pro Einheit für die einzelnen Tarife erfahren möchten, besuchen Sie die Seite mit der Preisübersicht.
Nach dem Speichern können Sie Benachrichtigungen überprüfen, um zu bestätigen, dass die Aktion erfolgreich war.
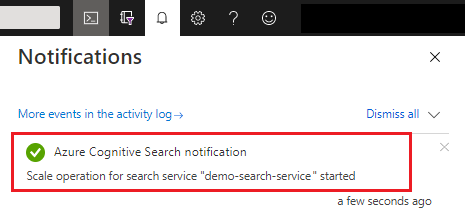
Es kann zwischen 15 Minuten und mehreren Stunden dauern, bis Änderungen bei der Kapazität abgeschlossen sind. Sie können den Prozess nach seinem Start nicht abbrechen, und es gibt keine Echtzeitüberwachung für Replikat- und Partitionsanpassungen. Allerdings bleibt die folgende Meldung sichtbar, während Änderungen vorgenommen werden.

Hinweis
Sobald ein Dienst bereitgestellt ist, kann kein direktes Upgrade auf einen höheren Tarif erfolgen. In diesem Fall müssen Sie einen Suchdienst unter dem neuen Tarif erstellen und Ihre Indizes neu laden. Weitere Informationen zur Dienstbereitstellung finden Sie unter Erstellen eines Azure KI-Suche-Diensts im Azure-Portal.
Verarbeiten von Skalierungsanforderungen
Nach dem Erhalt einer Skalierungsanforderung wird vom Suchdienst Folgendes durchgeführt:
- Er überprüft, ob die Anforderung gültig ist.
- Er beginnt mit der Sicherung von Daten und Systeminformationen.
- Er überprüft, ob sich der Dienst bereits in einem Bereitstellungsstatus befindet (aktive Vorgänge zum Hinzufügen oder Entfernen von Replikaten oder Partitionen).
- Er startet den Bereitstellungsvorgang.
Die Skalierung eines Diensts kann je nach seiner Größe und dem Umfang der Anforderung nur 15 Minuten oder auch deutlich länger als eine Stunde dauern. Der Sicherungsvorgang kann je nach Datenmenge und Anzahl von Partitionen und Replikaten mehrere Minuten dauern.
Die obigen Schritte folgen nicht unbedingt direkt aufeinander. Das System beginnt beispielsweise erst mit der Bereitstellung, wenn dieser Vorgang auf sichere Weise möglich ist, und dies kann auch gegen Ende des Sicherungsvorgangs der Fall sein.
Fehler während der Skalierung
Die Fehlermeldung der Art „Vorgänge zur Dienstaktualisierung sind derzeit nicht zulässig, weil eine vorherige Anforderung verarbeitet wird“ wird verursacht, wenn eine Anforderung zum Herunter- oder Hochskalieren wiederholt wird, während vom Dienst bereits eine vorherige Anforderung verarbeitet wird.
Beheben Sie diesen Fehler, indem Sie den Dienststatus überprüfen, um den Bereitstellungsstatus zu verifizieren:
- Verwenden Sie die Verwaltungs-REST-API, Azure PowerShell oder die Azure CLI, um den Dienststatus abzurufen.
- Rufen Sie den Get Service (REST) oder einen gleichwertigen für PowerShell oder die CLI auf.
- Überprüfen Sie die Antwort auf "provisioningState": "provisioning".
Wenn der Status „Provisioning“ (Bereitstellung wird durchgeführt) lautet, warten Sie, bis die Anforderung abgeschlossen ist. Der Status sollte entweder „Succeeded“ (Erfolgreich) oder „Failed“ (Fehler) lauten, bevor versucht wird, eine weitere Anforderung zu senden. Für die Sicherung wird kein Status angegeben. Die Sicherung ist ein interner Vorgang, und es ist unwahrscheinlich, dass dieser bei einer Störung einer Skalierungsübung eine Rolle spielt.
Wenn Ihr Suchdienst in einem Bereitstellungsstatus angehalten wird, überprüfen Sie, ob verwaiste Indizes nicht verwendbar sind, mit null Abfragevolumes und ohne Indexaktualisierungen. Ein nicht verwendbarer Index kann Änderungen an der Dienstkapazität blockieren. Suchen Sie insbesondere nach Indizes, die CMK-verschlüsselt sind, deren Schlüssel nicht mehr gültig sind. Sie sollten entweder den Index löschen oder die Schlüssel wiederherstellen, um den Index wieder online zu schalten und die Blockierung des Skalierungsvorgangs aufzuheben.
Partitions- und Replikatskombinationen
Das folgende Diagramm gilt für die Standardebene und höher. Es zeigt alle möglichen Kombinationen von Partitionen und Replikaten, vorbehaltlich der Höchstzahl von 36 Sucheinheiten pro Dienst.
| 1 Partition | 2 Partitionen | 3 Partitionen | 4 Partitionen | 6 Partitionen | 12 Partitionen | |
|---|---|---|---|---|---|---|
| 1 Replikat: | 1 SU | 2 SU | 3 SU | 4 SU | 6 SU | 12 SU |
| 2 Replikate | 2 SU | 4 SU | 6 SU | 8 SU | 12 SU | 24 SU |
| 3 Replikate | 3 SU | 6 SU | 9 SU | 12 SU | 18 SU | 36 SU |
| 4 Replikate | 4 SU | 8 SU | 12 SU | 16 SU | 24 SU | Nicht zutreffend |
| 5 Replikate | 5 SU | 10 SU | 15 SU | 20 SU | 30 SU | Nicht zutreffend |
| 6 Replikate | 6 SU | 12 SU | 18 SU | 24 SU | 36 SU | Nicht zutreffend |
| 12 Replikate | 12 SU | 24 SU | 36 SU | – | – | – |
Bei Suchdiensten im Basic-Tarif gelten niedrigere Anzahlen für Sucheinheiten.
Bei Suchdiensten, die vor dem 3. April 2024 erstellt wurden, kann ein Basic-Suchdienst genau eine Partition und bis zu drei Replikate aufweisen, d. h. es können maximal drei Sucheinheiten vorhanden sein. Nur die Replikate können angepasst werden.
Bei Suchdiensten, die nach dem 3. April 2024 in unterstützten Regionen erstellt wurden, können Basic-Dienste bis zu drei Partitionen und drei Replikate aufweisen. Die maximale SU-Grenze ist neun, um eine vollständige Ergänzung von Partitionen und Replikaten zu unterstützen.
Für Suchdienste auf einer beliebigen abrechnenden Ebene benötigen Sie unabhängig vom Erstellungsdatum mindestens zwei Replikate für hohe Verfügbarkeit bei Abfragen.
Die Abrechnungssätze pro Tarif und Währung finden Sie auf der Seite Azure KI-Suche – Preise.
Schätzen der Kapazität mithilfe eines abrechenbaren Tarifs
Speicheranforderungen werden durch die Größe der Indizes bestimmt, die Sie für die Erstellung erwarten. Es gibt keine solide Heuristik oder allgemein gültige Regeln, die bei Schätzungen helfen. Die einzige Möglichkeit zur Ermittlung der Größe eines Indexes ist, einen zu erstellen. Seine Größe hängt von der Tokenisierung und den Einbettungen ab und davon, ob Sie Vorschlagsfunktionen, Filterung und Sortierung aktivieren oder die Vektorkomprimierung nutzen können.
Wir empfehlen eine Schätzung für eine kostenpflichtige Ebene, Basic oder höher. Der Free-Tarif wird auf physischen Ressourcen ausgeführt, die von mehreren Kunden gemeinsam genutzt werden, und unterliegt Faktoren, die sich Ihrer Kontrolle entziehen. Nur die dedizierten Ressourcen eines abrechenbaren Suchdiensts ermöglichen längere Sampling- und Verarbeitungszeiten und eignen sich besser für realistische Schätzungen bezüglich Indexmenge, Größe und Abfragevolumen während der Entwicklung.
Überprüfen Sie die Dienstgrenzwerte in jedem Tarif, um festzustellen, ob niedrigere Tarife die Anzahl der benötigten Indizes unterstützen können. Überlegen Sie, ob Sie mehrere Kopien eines Indexes für aktive Entwicklung, Tests und Produktion benötigen.
Für einen Suchdienst gelten Objektgrenzwerte (maximale Anzahl von Indizes, Indexern, Skillsets usw.) und Speichergrenzwerte. Je nachdem, welcher Grenzwert zuerst erreicht wird, ist der effektive Grenzwert.
Erstellen Sie einen Dienst unter einem kostenpflichtigen Tarif. Dienstebenen sind für bestimmte Workloads optimiert. Beispielsweise ist die Ebene „Datenspeicheroptimiert“ auf zehn Indizes beschränkt, da sie für eine geringe Anzahl sehr großer Indizes ausgelegt ist.
Beginnen Sie mit einem niedrigen Tarif, z. B. „Basic“ oder „S1“, wenn Sie sich über die projizierte Last nicht sicher sind.
Starten Sie hoch, mit „S2“ oder sogar „S3“, wenn Tests umfangreiche Indizierungs- und Abfrageworkloads enthalten.
Beginnen Sie mit einem Tarif vom Typ „Speicheroptimiert“ („L1“ oder „L2“), wenn Sie sehr viele Daten indizieren möchten und die Abfragelast relativ gering ist (etwa im Fall einer internen Geschäftsanwendung).
Erstellen Sie einen anfänglichen Index, um zu bestimmen, wie Quelldaten in einen Index übersetzt werden. Dies ist die einzige Möglichkeit, die Größe des Indexes zu schätzen. Attribute für die Felddefinitionen wirken sich auf Anforderungen an den physischen Speicher aus:
Bei der Stichwortsuche erhöht das Markieren von Feldern als filterbar und sortierbar die Indexgröße.
Für die Vektorsuche können Sie Parameter festlegen, um die Vektorgröße zu reduzieren.
Überwachen von Speicher, Dienstgrenzwerten, Abfragevolumen und Latenz im Azure-Portal Im Azure-Portal werden die Abfragen pro Sekunde, gedrosselte Abfragen und die Wartezeit bei Suchvorgängen angezeigt. Diese Werte können Ihnen dabei helfen, den richtigen Tarif auszuwählen.
Fügen Sie Replikate für hohe Verfügbarkeit hinzu, oder verringern Sie die Abfrageleistung.
Es gibt keine Richtlinien zur Anzahl der Replikate, die für bestimmte Abfragelasten benötigt werden. Die Abfrageleistung hängt von der Komplexität der Abfrage und den konkurrierenden Workloads ab. Obwohl das Hinzufügen von Replikaten die Leistung deutlich erhöht, ist das Endergebnis nicht streng linear: Das Hinzufügen von 3 Replikaten garantiert keinen dreifachen Durchsatz. Leitlinien zur Schätzung der QPS (Queries per Second, Abfragen pro Sekunde) für Ihre Lösung finden Sie unter Analysieren der Leistung und Überwachen von Abfragen.
Bei einem invertierten Index werden Größe und Komplexität vom Inhalt bestimmt, nicht notwendigerweise von der Menge der Daten, die Sie eingeben. Eine große Datenquelle mit hoher Redundanz könnte einen kleineren Index ergeben als ein kleineres Dataset mit stark variierendem Inhalt. Daher ist es kaum möglich, die Indexgröße aus der Größe des ursprünglichen Datasets abzuleiten.
Speicheranforderungen können vergrößert werden, wenn Sie Daten einbeziehen, die nie durchsucht werden. Im Idealfall enthalten Dokumente nur die Daten, die Sie für die Suche benötigen.
Überlegungen zur Vereinbarung zum Servicelevel
Für Features des kostenlosen Tarifs (Free) und der Previewfunktionen gelten keine Vereinbarungen zum Servicelevel (Service Level Agreements, SLA). Für alle abrechenbaren Tarife gelten SLAs, wenn Sie genügend Redundanz für Ihren Dienst bereitstellen.
Mindestens zwei Replikate erfüllen Abfrage-SLAs (lesen).
Mindestens drei Replikate erfüllen Abfrage- und Indizierungs-SLAs (lesen/schreiben).
Die Anzahl der Partitionen hat keine Auswirkungen auf die SLAs.