Erstellen einer Vektorabfrage in Azure KI Search
Wenn Sie in der Azure KI-Suche einen Vektorindex haben, wird in diesem Artikel Folgendes erläutert:
In diesem Artikel wird REST zur Veranschaulichung verwendet. Codebeispiele in anderen Sprachen finden Sie im GitHub-Repository für Azure-Search-Vektorbeispiele für End-to-End-Lösungen, die Vektorabfragen enthalten.
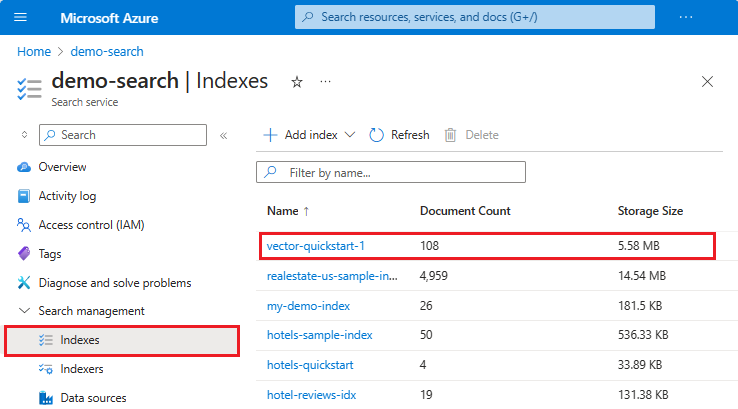
Sie können auch den Suchexplorer im Azure-Portal verwenden.
Voraussetzungen
Azure AI Search, in jeder Region und auf jeder Ebene.
Ein Vektorindex in der Azure KI-Suche. Suchen Sie in Ihrem Index nach einem
vectorSearchAbschnitt, um einen Vektorindex zu bestätigen.Sie können Ihrem Index optional eine Vektorisierung für integrierte Text-zu-Vektor- oder Bild-zu-Vektor-Konvertierungen während Abfragen hinzufügen.
Visual Studio Code mit einem REST-Client und Beispieldaten, wenn Sie diese Beispiele eigenständig ausführen möchten. Informationen zu den ersten Schritten mit dem REST-Client finden Sie unter Schnellstart: Azure KI-Suche mit REST.
Konvertieren einer Abfragezeichenfolgeneingabe in einen Vektor
Um ein Vektorfeld abzufragen, muss die Abfrage selbst ein Vektor sein.
Ein Ansatz zum Konvertieren der Textabfragezeichenfolge eines Benutzers in seine Vektordarstellung besteht darin, eine Einbettungsbibliothek oder API in Ihrem Anwendungscode aufzurufen. Verwenden Sie als bewährte Methode immer dieselben Einbettungsmodelle, die zum Generieren von Einbettungen in die Quelldokumenteverwendet werden. Sie finden Codebeispiele, die zeigen wie Einbettungen im Repository azure-search-vector-samples generiert werden.
Ein zweiter Ansatz ist die Verwendung der integrierten Vektorisierung, die jetzt allgemein verfügbar ist, damit Azure KI-Suche Ihre Abfragevektorisierungseingaben und -ausgaben verarbeitet.
Hier sehen Sie ein REST-API-Beispiel für einen Abfrage-String, der an eine Bereitstellung eines Azure OpenAI-Einbettungsmodells übermittelt wird:
POST https://{{openai-service-name}}.openai.azure.com/openai/deployments/{{openai-deployment-name}}/embeddings?api-version={{openai-api-version}}
Content-Type: application/json
api-key: {{admin-api-key}}
{
"input": "what azure services support generative AI'"
}
Die erwartete Antwort ist 202 für einen erfolgreichen Aufruf des bereitgestellten Modells.
Das Feld „Einbetten“ im Textkörper der Antwort ist die Vektordarstellung der Abfragezeichenfolge „input“. Zu Testzwecken würden Sie den Wert des Arrays „embedding“ in „vectorQueries.vector“ in einer Abfrage kopieren, wobei Sie die in den nächsten Abschnitten beschriebene Syntax verwenden.
Die eigentliche Antwort für diesen POST-Aufruf an das eingesetzte Modell enthält 1536 Einbettungen, die hier aus Gründen der Lesbarkeit auf die ersten paar Vektoren reduziert wurden.
{
"object": "list",
"data": [
{
"object": "embedding",
"index": 0,
"embedding": [
-0.009171937,
0.018715322,
...
-0.0016804502
]
}
],
"model": "ada",
"usage": {
"prompt_tokens": 7,
"total_tokens": 7
}
}
Bei diesem Ansatz ist Ihr Anwendungscode für die Verbindung mit einem Modell, das Generieren von Einbettungen und die Behandlung der Antwort verantwortlich.
Vektorabfrageanforderung
In diesem Abschnitt wird die grundlegende Struktur einer Vektorabfrage veranschaulicht. Sie können das Azure-Portal, REST-APIs oder die Azure-SDKs verwenden, um eine Vektorabfrage zu formulieren. Wenn Sie von 2023-07-01-Previewmigrieren, gibt es unterbrechungsfreie Änderungen. Details finden Sie unter Upgrade auf die neueste REST-API .
2024-07-01 ist die stabile REST-API-Version für Search POST. Diese Version unterstützt:
-
vectorQueriesist das Konstrukt für die Vektorsuche. - Festlegen von
vectorQueries.kindaufvectorfür ein Vektorarray bzw. auftext, wenn die Eingabe eine Zeichenfolge ist und Sie über eine Vektorisierung verfügen. -
vectorQueries.vectorist eine Abfrage (eine Vektordarstellung von Text oder ein Bild). -
vectorQueries.weight(optional) gibt die relative Gewichtung der einzelnen Vektorabfragen an, die in Suchvorgängen enthalten ist (siehe Vektorgewichtung). -
exhaustive(optional) ruft erschöpfende KNN zur Abfragezeit auf, auch wenn das Feld für HNSW indiziert ist.
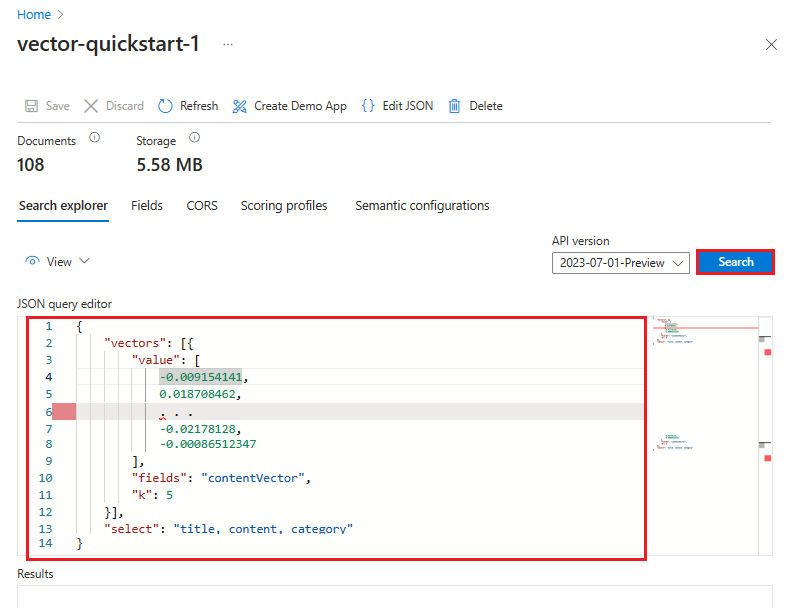
Im folgenden Beispiel ist der Vektor eine Darstellung dieser Zeichenfolge: „Welche Azure-Dienste unterstützen die Volltextsuche“. Die Abfrage zielt auf das contentVector-Feld ab. Die Abfrage gibt Ergebnisse zurück k. Der tatsächliche Vektor verfügt über 1536 Einbettungen, sodass er in diesem Beispiel zur Lesbarkeit gekürzt wird.
POST https://{{search-service-name}}.search.windows.net/indexes/{{index-name}}/docs/search?api-version=2024-07-01
Content-Type: application/json
api-key: {{admin-api-key}}
{
"count": true,
"select": "title, content, category",
"vectorQueries": [
{
"kind": "vector",
"vector": [
-0.009154141,
0.018708462,
. . .
-0.02178128,
-0.00086512347
],
"exhaustive": true,
"fields": "contentVector",
"weight": 0.5,
"k": 5
}
]
}
Vektorabfrageantwort
In Azure AI Search bestehen Abfrageantworten standardmäßig aus allen retrievable Feldern. Es ist jedoch üblich, Suchergebnisse auf eine Teilmenge von retrievable Feldern zu beschränken, indem sie sie in einer select Anweisung auflisten.
Berücksichtigen Sie in einer Vektorabfrage sorgfältig, ob Sie Felder in einer Antwort vektorieren müssen. Vektorfelder sind nicht lesbar. Wenn Sie also eine Antwort auf eine Webseite pushen, sollten Sie nicht Vektorfelder auswählen, die für das Ergebnis repräsentativ sind. Wenn die Abfrage beispielsweise ausgeführt wird, können Sie stattdessen contentVectorzurückgeben content .
Wenn Sie Vektorfelder im Ergebnis verwenden möchten, finden Sie hier ein Beispiel für die Antwortstruktur.
contentVector ist ein Zeichenfolgenarray von Einbettungen, die hier aus Platzgründen gekürzt werden. Die Suchbewertung gibt die Relevanz an. Andere Nichtvectorfelder sind für den Kontext enthalten.
{
"@odata.count": 3,
"value": [
{
"@search.score": 0.80025613,
"title": "Azure Search",
"category": "AI + Machine Learning",
"contentVector": [
-0.0018343845,
0.017952163,
0.0025753193,
...
]
},
{
"@search.score": 0.78856903,
"title": "Azure Application Insights",
"category": "Management + Governance",
"contentVector": [
-0.016821077,
0.0037742127,
0.016136652,
...
]
},
{
"@search.score": 0.78650564,
"title": "Azure Media Services",
"category": "Media",
"contentVector": [
-0.025449317,
0.0038463024,
-0.02488436,
...
]
}
]
}
Die wichtigsten Punkte:
kbestimmt, wie viele Ergebnisse der nächsten Nachbarn zurückgegeben werden, in diesem Fall drei. Vektorabfragen liefern immerk-Ergebnisse, vorausgesetzt, dass zumindestkDokumente vorhanden sind, selbst wenn die Dokumente sich nur wenig ähneln, da der Algorithmus nur diekPixelwiederholungen für den abgefragten Vektor ermittelt.Dies
@search.scorewird durch den Vektorsuchalgorithmusbestimmt.Felder in Suchergebnissen sind entweder alle
retrievableFelder oder Felder in einerselectKlausel. Bei der Ausführung von Vektorabfragen erfolgt die Übereinstimmung allein für Vektordaten. Eine Antwort kann jedoch ein beliebigesretrievableFeld in einem Index enthalten. Da es keine Möglichkeit zum Decodieren eines Vektorfeldergebnisses gibt, ist die Einbeziehung von Nichtvektortextfeldern für ihre lesbaren Werte hilfreich.
Mehrere Vektorfelder
Sie können die Eigenschaft „vectorQueries.fields“ auf mehrere Vektorfelder festlegen. Die Vektorabfrage wird für jedes Vektorfeld ausgeführt, das Sie in der fields Liste angeben. Stellen Sie beim Abfragen mehrerer Vektorfelder sicher, dass jedes Element Einbettungen aus demselben Einbettungsmodell enthält und dass die Abfrage auch aus dem gleichen Einbettungsmodell generiert wird.
POST https://{{search-service-name}}.search.windows.net/indexes/{{index-name}}/docs/search?api-version=2024-07-01
Content-Type: application/json
api-key: {{admin-api-key}}
{
"count": true,
"select": "title, content, category",
"vectorQueries": [
{
"kind": "vector",
"vector": [
-0.009154141,
0.018708462,
. . .
-0.02178128,
-0.00086512347
],
"exhaustive": true,
"fields": "contentVector, titleVector",
"k": 5
}
]
}
Mehrere Vektorabfragen
Die Vektorsuche mit mehreren Abfragen sendet mehrere Abfragen über mehrere Vektorfelder in Ihrem Suchindex. Ein gängiges Beispiel für diese Abfrageanforderung ist die Verwendung von Modellen wie CLIP für eine mehr modale Vektorsuche, bei der dasselbe Modell Bild- und Nicht-Bildinhalte vektorisieren kann.
Das folgende Abfragebeispiel sucht nach Ähnlichkeiten in myImageVector und myTextVector, sendet jedoch jeweils zwei unterschiedliche Abfrageeinbettungen, die jeweils parallel ausgeführt werden. Diese Abfrage erzeugt ein Ergebnis, das mithilfe der reziproziierten Rangfusion (RRF) bewertet wird.
-
vectorQueriesstellt ein Array von Vektorabfragen bereit. -
vectorenthält die Bildvektoren und Textvektoren im Suchindex. Jede Instanz ist eine separate Abfrage. -
fieldsgibt an, welches Vektorfeld als Ziel verwendet werden soll. -
kist die Anzahl der Übereinstimmungen an Pixelwiederholungen, die in Ergebnisse eingeschlossen werden sollen.
{
"count": true,
"select": "title, content, category",
"vectorQueries": [
{
"kind": "vector",
"vector": [
-0.009154141,
0.018708462,
. . .
-0.02178128,
-0.00086512347
],
"fields": "myimagevector",
"k": 5
},
{
"kind": "vector"
"vector": [
-0.002222222,
0.018708462,
-0.013770515,
. . .
],
"fields": "mytextvector",
"k": 5
}
]
}
Suchergebnisse enthalten eine Kombination aus Text und Bildern, vorausgesetzt, Ihr Suchindex enthält ein Feld für die Bilddatei (ein Suchindex speichert keine Bilder).
Abfrage mit integrierter Vektorisierung
Dieser Abschnitt zeigt eine Vektorabfrage, die die integrierte Vektorisierung aufruft, die eine Text- oder Bildabfrage in einen Vektor konvertiert. Wir empfehlen die stabile REST-API 2024-07-01, den Suchexplorer oder neuere Azure SDK-Pakete für dieses Feature.
Eine Voraussetzung ist ein Suchindex, in dem eine Vektorisierung konfiguriert und einem Vektorfeld zugewiesen wurde. Die Vektorisierung stellt Verbindungsinformationen zu einem einbettenden Modell bereit, das zur Abfragezeit verwendet wird.
Der Suchexplorer unterstützt die integrierte Vektorisierung zur Abfragezeit. Wenn Ihr Index Vektorfelder enthält und über eine Vektorisierung verfügt, können Sie die integrierte Text-zu-Vektor-Konvertierung verwenden.
Melden Sie sich mit Ihrem Azure-Konto beim Azure Portal an und wechseln Sie zu Ihrem Azure AI Search-Dienst.
Erweitern Sie im linken Menü Suchverwaltung>Indizes, und wählen Sie Ihren Index aus. „Suchexplorer“ ist die erste Registerkarte auf der Indexseite.
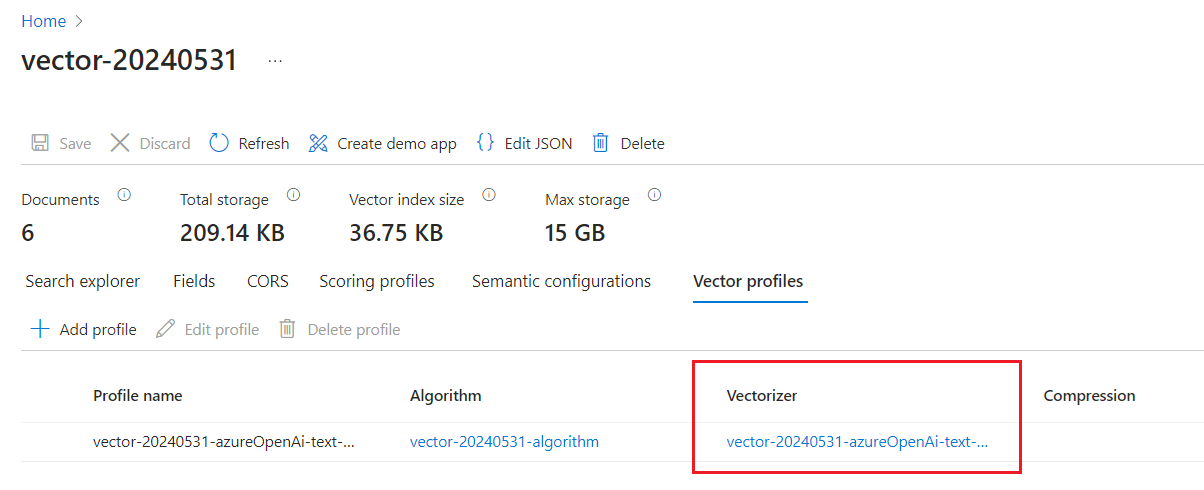
Überprüfen Sie unter Vektorprofile, ob Sie über eine Vektorisierung verfügen.
Im Suchexplorer können Sie eine Textzeichenfolge in die Standardsuchleiste in der Abfrageansicht eingeben. Die integrierte Vektorisierung konvertiert Ihre Zeichenfolge in einen Vektor, führt die Suche aus und gibt Ergebnisse zurück.
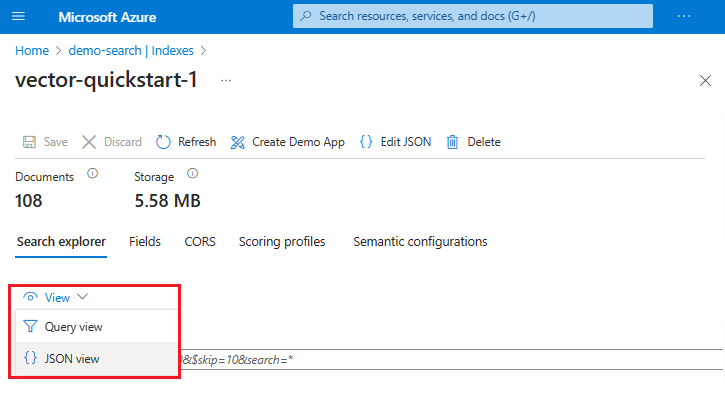
Alternativ können Sie Ansicht>JSON-Ansicht auswählen, um die Abfrage anzuzeigen oder zu ändern. Wenn Vektoren vorhanden sind, richtet der Suchexplorer automatisch eine Vektorabfrage ein. In der JSON-Ansicht können Sie Felder auswählen, die in der Suche und in der Antwort verwendet werden, Filter hinzufügen oder komplexere Abfragen wie Hybridabfragen erstellen. Auf der Registerkarte „REST-API“ dieses Abschnitts finden Sie ein JSON-Beispiel.
Anzahl der bewerteten Ergebnisse in einer Vektorabfrageantwort
Eine Vektorabfrage gibt den k-Parameter an, der festlegt, wie viele Übereinstimmungen in den Ergebnissen zurückgegeben werden. Die Suchmaschine gibt immer k Übereinstimmungen zurück. Wenn k die Anzahl der Dokumente im Index größer ist, bestimmt die Anzahl der Dokumente die Obergrenze, die zurückgegeben werden kann.
Wenn Sie mit der Volltextsuche vertraut sind, wissen Sie, dass Sie null Ergebnisse erwarten, wenn der Index keinen Ausdruck oder Ausdruck enthält. Bei der Vektorsuche identifiziert die Suche jedoch die Pixelwiederholungen. Sie gibt immer k Ergebnisse zurück, auch wenn die Pixelwiederholungen sich nicht stark ähneln. Es ist also möglich, Ergebnisse für unsinnige oder themenfremde Abfragen abzurufen, insbesondere, wenn Sie keine Eingabeaufforderungen zum Festlegen von Begrenzungen verwenden. Weniger relevante Ergebnisse haben eine schlechtere Ähnlichkeitsbewertung, aber sie sind immer noch die „nächstgelegenen“ Vektoren, wenn nichts näher ist. Daher kann eine Antwort ohne aussagekräftige Ergebnisse weiterhin Ergebnisse zurückgeben k, aber die Ähnlichkeitsbewertung jedes Ergebnisses wäre niedrig.
Ein hybrider Ansatz, der die Volltextsuche enthält, kann dieses Problem mindern. Eine weitere Entschärfung besteht darin, einen Mindestschwellenwert für den Score der Suche festzulegen, jedoch nur, wenn die Abfrage eine reine Einzelvektorabfrage ist. Hybride Abfragen sind nicht für Mindestschwellenwerte geeignet, da die RRF-Bereiche viel kleiner und volatiler sind.
Abfrageparameter, die die Ergebnisanzahl beeinflussen, sind unter anderem:
-
"k": n-Ergebnisse für Nur-Vektorabfragen -
"top": nErgebnisse für Hybridabfragen, die einen Parameter „search“ enthalten
Sowohl „k“ als auch „top“ sind optional. Nicht angegeben, die Standardanzahl der Ergebnisse in einer Antwort ist 50. Sie können „top“ und „skip“ festlegen, um weitere Ergebnisse zu durchlaufen oder den Standardwert zu ändern.
Bewertungsalgorithmen, die in einer Vektorabfrage verwendet werden
Die Rangfolge der Ergebnisse wird durch eine der folgenden Methoden berechnet:
- Ähnlichkeitsmetrik
- Reziprozimale Rangfusion (RRF), wenn mehrere Sätze von Suchergebnissen vorhanden sind.
Ähnlichkeitsmetrik
Die im Indexabschnitt vectorSearch für eine Vektorabfrage angegebene Ähnlichkeitsmetrik. Gültige Werte sind cosine, euclidean und dotProduct.
Azure OpenAI-Einbettungsmodelle verwenden kosinusgleichheit, wenn Sie also Azure OpenKI-Einbettungsmodelle verwenden, ist cosine die empfohlene Metrik. Weitere unterstützte Bewertungsmetriken sind euclidean und dotProduct.
Verwenden von RRF
Mehrere Sets werden erstellt, wenn die Abfrage auf mehrere Vektorfelder abzielt, mehrere Vektorabfragen parallel ausgeführt werden oder wenn die Abfrage eine Mischung aus Vektor- und Volltextsuche ist, mit oder ohne semantisches Ranking.
Während der Abfrageausführung kann eine Vektorabfrage nur auf einen internen Vektorindex abzielen. Für mehrere Vektorfelder und mehrere Vektorabfragengeneriert die Suchmaschine also mehrere Abfragen, die auf die jeweiligen Vektorindizes jedes Felds abzielen. Die Ausgabe ist eine Reihe von bewerteten Ergebnissen für jede Abfrage, die mit RRF fusioniert werden. Weitere Informationen finden Sie unter Relevanzbewertung mithilfe der reziprozien Rangfusion (RRF).
Vektorgewichtung
Fügen Sie einen weight-Abfrageparameter hinzu, um die relative Gewichtung der einzelnen Vektorabfrage anzugeben, die in Suchvorgängen enthalten ist. Dieser Wert wird verwendet, wenn die Ergebnisse mehrerer Bewertungslisten kombiniert werden, die von zwei oder mehr Vektorabfragen in derselben Anforderung oder aus dem Vektorteil einer Hybridabfrage erstellt werden.
Der Standardwert ist 1,0, und der Wert muss eine positive Zahl größer 0 sein.
Die Gewichte werden bei der Berechnung der reziproken Rangfusionswerte der einzelnen Dokumente verwendet. Die Berechnung erfolgt durch Multiplikation des weight-Wertes mit dem Rangwert des Dokuments innerhalb seiner jeweiligen Ergebnismenge.
Das folgende Beispiel ist eine Hybridabfrage mit zwei Vektorabfragezeichenfolgen und einer Textzeichenfolge. Den Vektorabfragen werden Gewichtungen zugewiesen. Die erste Abfrage ist 0,5 oder die Hälfte der Gewichtung, wodurch die Wichtigkeit in der Anforderung reduziert wird. Die zweite Vektorabfrage ist doppelt so wichtig.
POST https://[service-name].search.windows.net/indexes/[index-name]/docs/search?api-version=2024-07-01
{
"vectorQueries": [
{
"kind": "vector",
"vector": [1.0, 2.0, 3.0],
"fields": "my_first_vector_field",
"k": 10,
"weight": 0.5
},
{
"kind": "vector",
"vector": [4.0, 5.0, 6.0],
"fields": "my_second_vector_field",
"k": 10,
"weight": 2.0
}
],
"search": "hello world"
}
Die Vektorgewichtung gilt nur für Vektoren. Die Textabfrage in diesem Beispiel („hello world“) hat eine implizite Gewichtung von 1,0 oder eine neutrale Gewichtung. Bei einer Hybridabfrage können Sie jedoch die Wichtigkeit von Textfeldern durch Festlegen von maxTextRecallSize erhöhen oder verringern.
Festlegen von Schwellenwerten zum Ausschließen von Ergebnissen mit niedriger Bewertung (Preview)
Da die Suche nach dem nächsten Nachbarn immer die angeforderten k Nachbarn liefert, ist es möglich, dass Sie bei der Erfüllung der Anforderung an die Anzahl k der Suchergebnisse auch mehrere Treffer mit niedriger Punktzahl erhalten. Zum Ausschließen von Suchergebnissen mit niedriger Bewertung können Sie einen threshold-Abfrageparameter hinzufügen, der Ergebnisse basierend auf einer Mindestbewertung herausfiltert. Filterung erfolgt vor der Verschmelzung der Ergebnisse aus verschiedenen Abrufmengen.
Dieser Parameter befindet sich noch in der Vorschauphase. Wir empfehlen die REST-API-Vorschauversion 2024-05-01-preview.
In diesem Beispiel werden alle Übereinstimmungen, die unter 0,8 liegen, von Vektorsuchergebnissen ausgeschlossen, auch wenn die Anzahl der Ergebnisse unter k fällt.
POST https://[service-name].search.windows.net/indexes/[index-name]/docs/search?api-version=2024-05-01-preview
Content-Type: application/json
api-key: [admin key]
{
"vectorQueries": [
{
"kind": "vector",
"vector": [1.0, 2.0, 3.0],
"fields": "my-cosine-field",
"threshold": {
"kind": "vectorSimilarity",
"value": 0.8
}
}
]
}
MaxTextSizeRecall für die Hybridsuche (Preview)
Vektorabfragen werden häufig in Hybridkonstrukten verwendet, die Nichtvektorfelder enthalten. Wenn Sie feststellen, dass BM25-bewertete Ergebnisse in einem Hybridabfrageergebnis über- oder unterrepräsentiert sind, können Sie festlegen maxTextRecallSize, um die BM25-bewerteten Ergebnisse, die für die Hybridbewertung bereitgestellt wurden, zu verringern oder zu erhöhen.
Sie können diese Eigenschaft nur in Hybridanforderungen festlegen, die die Komponenten „search“ und „vectorQueries“ enthalten.
Dieser Parameter befindet sich noch in der Vorschauphase. Wir empfehlen die REST-API-Vorschauversion 2024-05-01-preview.
Weitere Informationen finden Sie unter Festlegen von maxTextRecallSize – Erstellen einer Hybridabfrage.
Nächste Schritte
Überprüfen Sie als nächsten Schritt Vektorabfragecodebeispiele in Python, C# oder JavaScript.