Konfigurieren von Datenflüssen in Azure IoT Einsatz
Wichtig
Diese Seite enthält Anweisungen zum Verwalten der Komponenten von Azure IoT Einsatz mithilfe von Kubernetes-Bereitstellungsmanifesten. Diese Option befindet sich in der Vorschau. Dieses Feature wird mit einigen Einschränkungen bereitgestellt und sollte nicht für Produktionsworkloads verwendet werden.
Die zusätzlichen Nutzungsbestimmungen für Microsoft Azure-Vorschauen enthalten rechtliche Bedingungen. Sie gelten für diejenigen Azure-Features, die sich in der Beta- oder Vorschauversion befinden oder aber anderweitig noch nicht zur allgemeinen Verfügbarkeit freigegeben sind.
Ein Datenfluss ist der Pfad, den Daten von der Quelle zum Ziel mit optionalen Transformationen nehmen. Sie können den Datenfluss mithilfe des Azure IoT Einsatz Studio-Portals konfigurieren oder eine benutzerdefinierte Datenfluss-Ressource erstellen. Ein Datenfluss besteht aus drei Teilen: der Quelle, der Transformation und dem Ziel.

Um die Quelle und das Ziel zu definieren, müssen Sie die Datenflussendpunkte konfigurieren. Die Transformation ist optional und kann Vorgänge wie das Anreichern der Daten, das Filtern der Daten und das Zuordnen der Daten zu einem anderen Feld umfassen.
Wichtig
Jeder Dataflow muss den lokalen MQTT-Broker-Standardendpunkt von Azure IoT Operations als Quelle oder Zielaufweisen.
Sie können die Einsatz-Benutzeroberfläche in Azure IoT Einsatz verwenden, um einen Dataflow zu erstellen. Die Einsatz-Benutzeroberfläche bietet eine visuelle Schnittstelle zum Konfigurieren des Dataflows. Sie können auch Bicep verwenden, um einen Dataflow mithilfe einer Bicep-Vorlagendatei zu erstellen, oder Kubernetes, um einen Dataflow mithilfe einer YAML-Datei zu erstellen.
Lesen Sie weiter, um zu erfahren, wie Sie Quelle, Transformation und Ziel konfigurieren.
Voraussetzungen
Sie können Dataflows bereitstellen, sobald Sie über eine Instanz von Azure IoT Einsatz mit dem Standarddatenflussprofil und -endpunkt verfügen. Möglicherweise möchten Sie jedoch Dataflowprofile und -endpunkte konfigurieren, um den Dataflow anzupassen.
Dataflowprofil
Wenn Sie keine anderen Skalierungseinstellungen für Ihre Datenflüsse benötigen, verwenden Sie das von Azure IoT Einsatz bereitgestellte Standarddatenflussprofil. Informationen zum Konfigurieren eines Dataflowprofils finden Sie unter Konfigurieren von Dataflowprofilen.
Dataflowendpunkte
Dataflowendpunkte sind für das Konfigurieren der Quelle und des Ziels für den Dataflow erforderlich. Für den schnellen Einstieg können Sie den Standarddataflowendpunkt für den lokalen MQTT-Broker verwenden. Sie können auch andere Typen von Dataflowendpunkten wie Kafka, Event Hubs oder Azure Data Lake Storage erstellen. Informationen dazu, wie Sie die einzelnen Typen von Datenflussendpunkten konfigurieren, finden Sie unter Konfigurieren von Datenflussendpunkten.
Erste Schritte
Sobald Sie über die Voraussetzungen verfügen, können Sie mit dem Erstellen eines Dataflows beginnen.
Um einen Dataflow auf der Einsatz-Benutzeroberfläche zu erstellen, wählen Sie Dataflow>Dataflow erstellen aus. Anschließend wird die Seite angezeigt, auf der Sie Quelle, Transformation und Ziel für den Dataflow konfigurieren können.
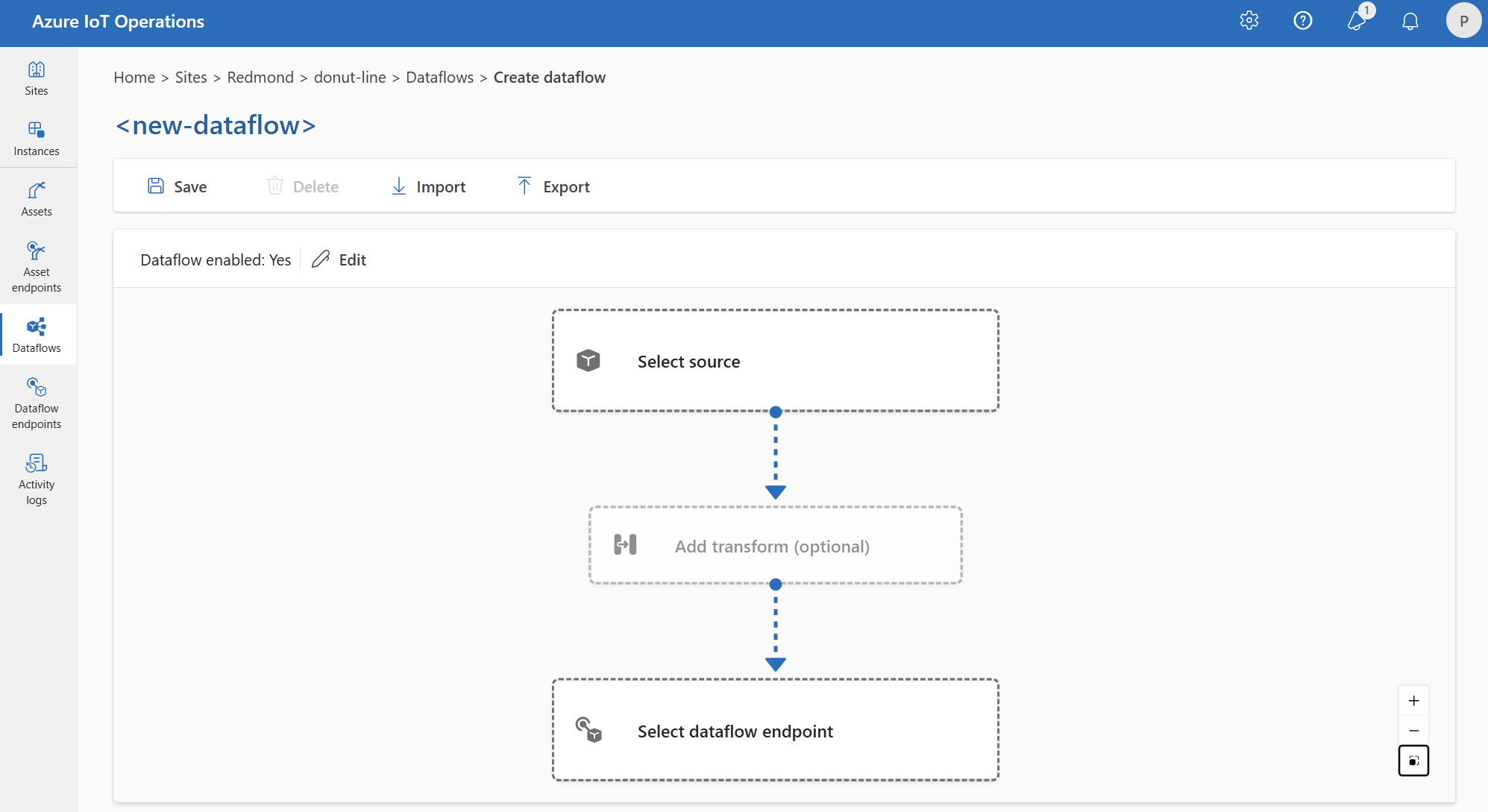
In den folgenden Abschnitten erfahren Sie, wie Sie die Vorgangstypen des Datenflusses konfigurieren.
Quelle
Um eine Quelle für den Dataflow zu konfigurieren, geben Sie den Endpunktverweis und eine Liste der Datenquellen für den Endpunkt an. Wählen Sie eine der folgenden Optionen als Quelle für den Datenfluss aus.
Wenn der Standardendpunkt nicht als Quelle verwendet wird, muss er als Zielverwendet werden. Weitere Informationen finden Sie unter Dataflows müssen den lokalen MQTT-Broker-Endpunkt verwenden.
Option 1: Verwenden des Nachrichtenbroker-Standardendpunkts als Quelle
Wählen Sie unter Quelldetails die Option Nachrichtenbroker aus.
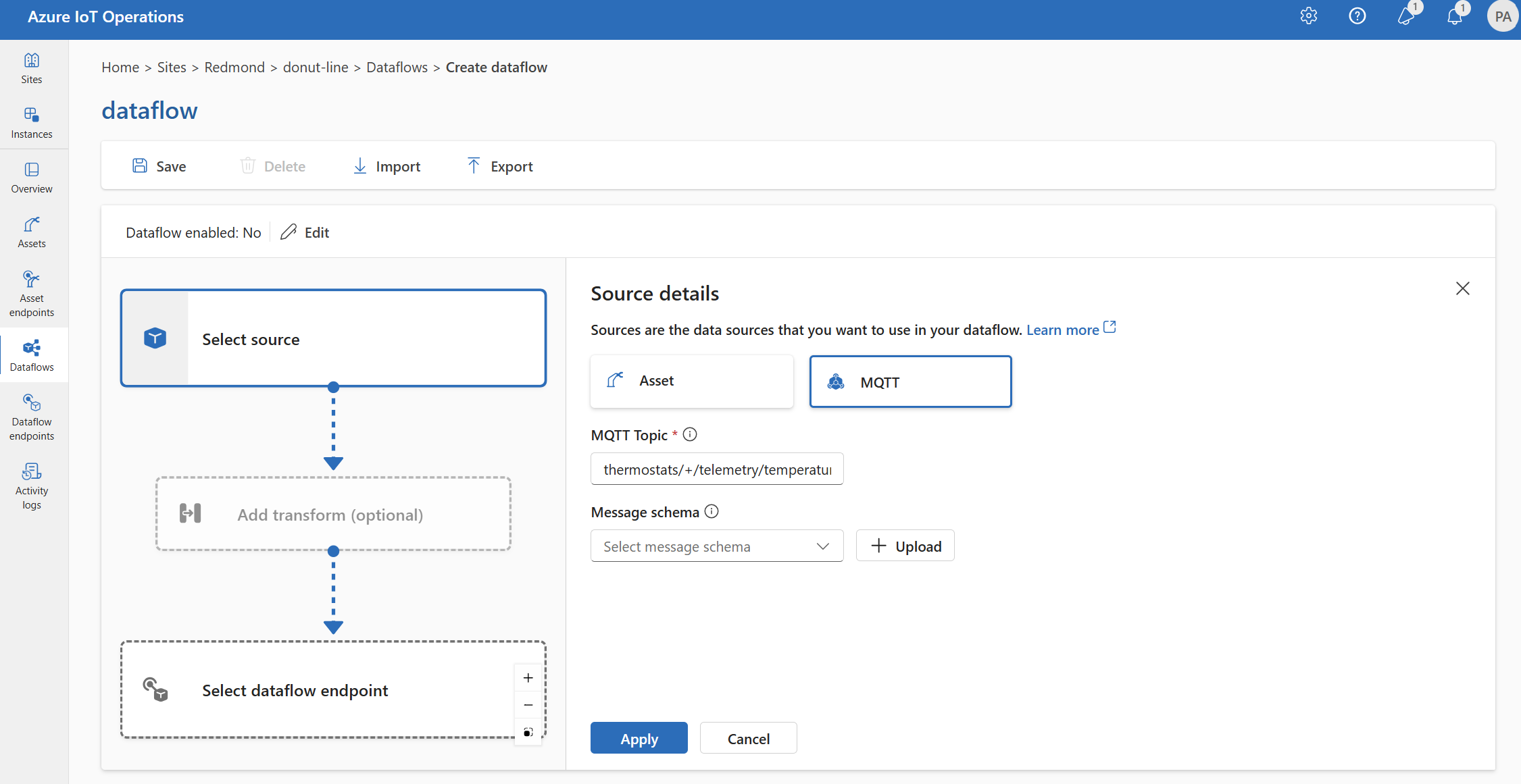
Geben Sie die folgenden Einstellungen für die Nachrichtenbrokerquelle ein:
Einstellung Beschreibung Dataflowendpunkt Wählen Sie Standard aus, um den standardmäßigen MQTT-Nachrichtenbroker-Endpunkt zu verwenden. Thema Der Themenfilter, der für eingehende Nachrichten abonniert werden soll. Weitere Informationen finden Sie unter Konfigurieren von MQTT- oder Kafka-Themen. Nachrichtenschema Das Schema, das zum Deserialisieren der eingehenden Nachrichten verwendet werden soll. Weitere Informationen finden Sie unter Angeben des Schemas zum Deserialisieren von Daten. Wählen Sie Übernehmen.
Option 2: Verwenden von Ressourcen als Quelle
Sie können eine Ressource als Quelle für den Datenfluss verwenden. Die Verwendung einer Ressource als Quelle ist nur auf der Einsatz-Benutzeroberfläche verfügbar.
Wählen Sie unter Quelldetails den Eintrag Ressource aus.
Wählen Sie die Ressource aus, die Sie als Quellendpunkt verwenden möchten.
Wählen Sie Proceed (Fortfahren) aus.
Es wird eine Liste der Datenpunkte für die ausgewählte Ressource angezeigt.
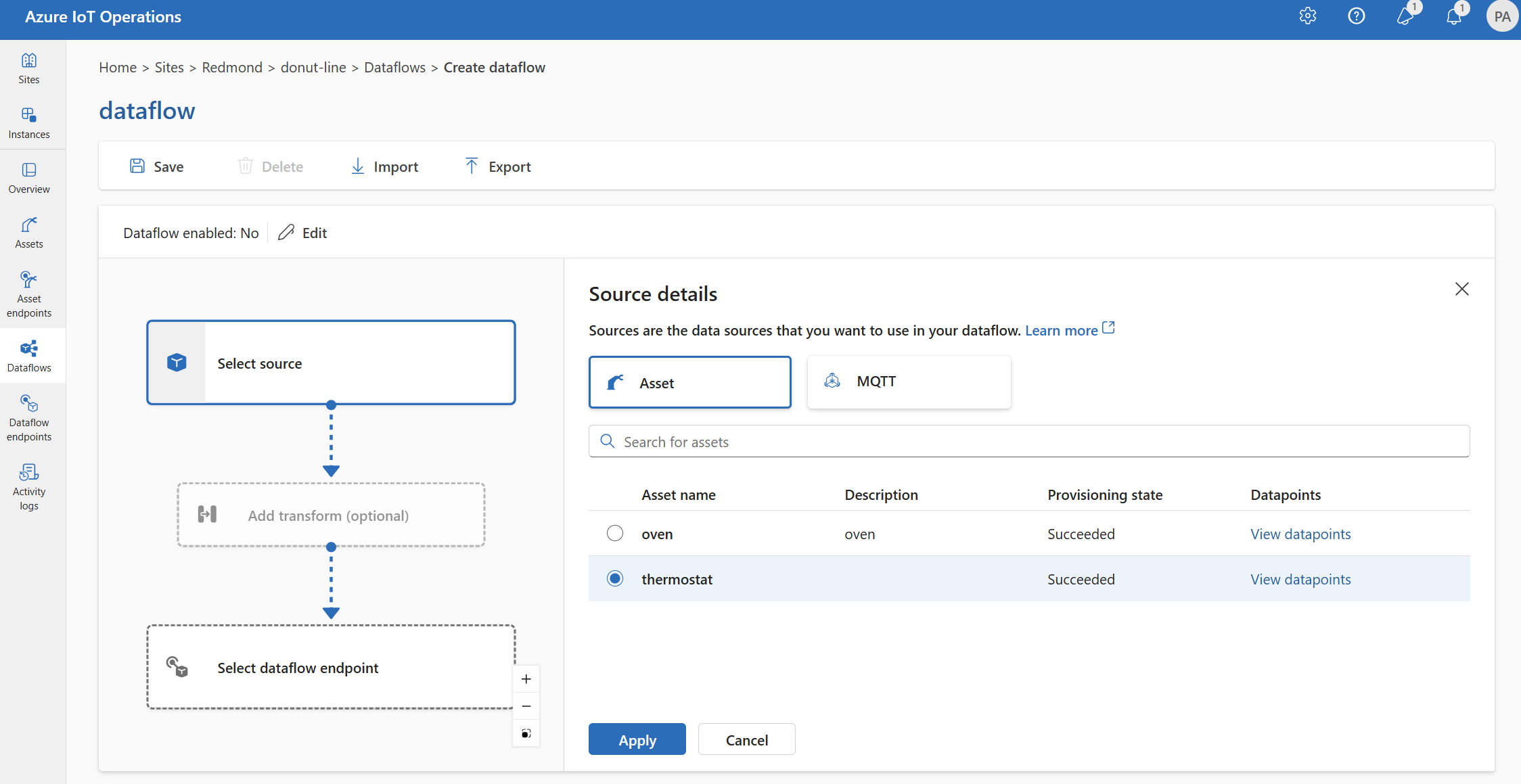
Wählen Sie Übernehmen aus, um die Ressource als Quellendpunkt zu verwenden.
Bei Verwendung einer Ressource als Quelle wird die Objektdefinition verwendet, um das Schema für den Datenfluss abzuleiten. Die Objektdefinition enthält das Schema für die Datenpunkte der Ressource. Weitere Informationen finden Sie unter Remoteverwaltung von Ressourcenkonfigurationen.
Nach der Konfiguration erreichen die Daten aus dem Objekt den Datenfluss über den lokalen MQTT-Broker. Wenn Sie also eine Ressource als Quelle verwenden, verwendet der Datenfluss den lokalen MQTT-Broker-Standardendpunkt als Quelle in der Realität.
Option 3: Verwenden eines benutzerdefinierten MQTT- oder Kafka-Datenflussendpunkts als Quelle
Wenn Sie einen benutzerdefinierten MQTT- oder Kafka-Dataflowendpunkt (z. B. für die Verwendung mit Event Grid oder Event Hubs) erstellt haben, können Sie ihn als Quelle für den Dataflow verwenden. Denken Sie daran, dass Speichertypendpunkte wie Data Lake oder Fabric OneLake nicht als Quelle verwendet werden können.
Wählen Sie unter Quelldetails die Option Nachrichtenbroker aus.
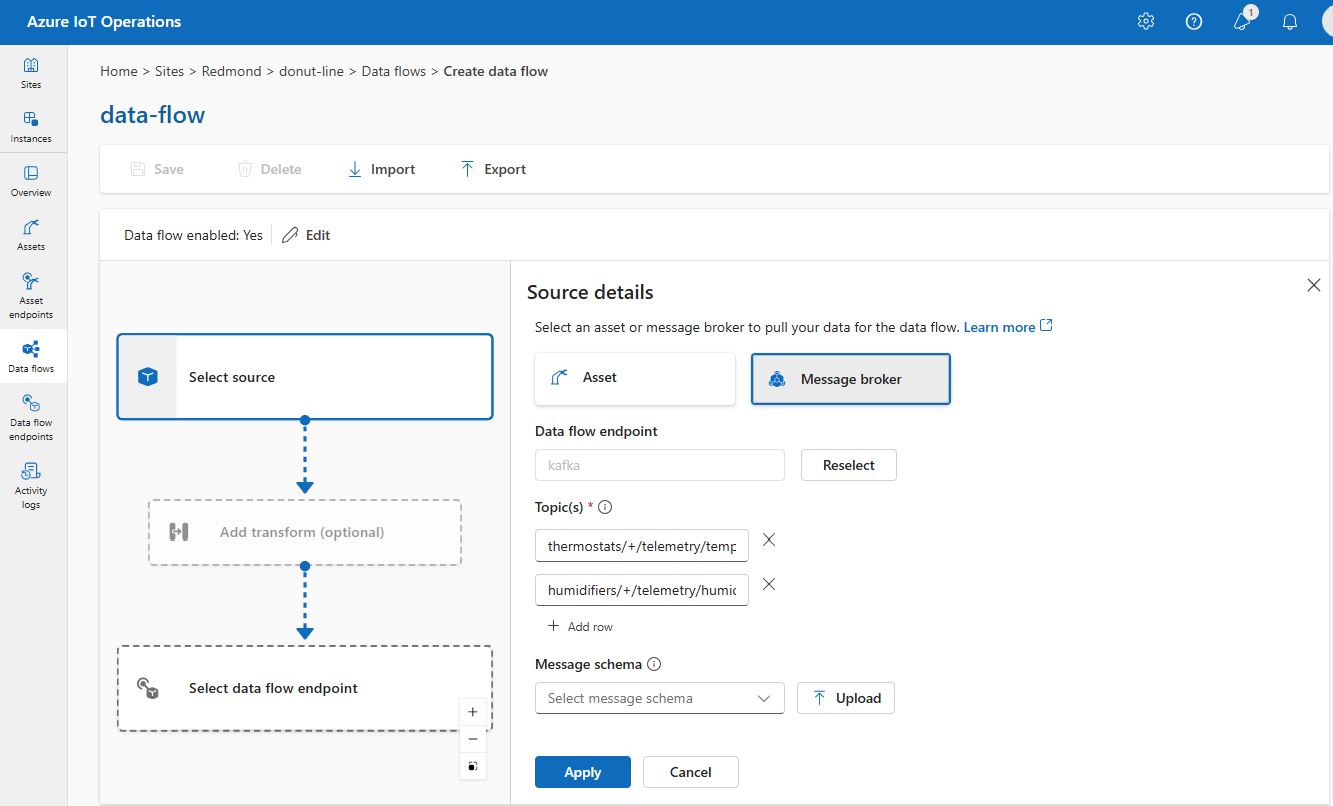
Geben Sie die folgenden Einstellungen für die Nachrichtenbrokerquelle ein:
Einstellung Beschreibung Dataflowendpunkt Verwenden Sie die Schaltfläche Erneut auswählen, um einen benutzerdefinierten MQTT- oder Kafka-Dataflowendpunkt auszuwählen. Weitere Informationen finden Sie unter Konfigurieren von MQTT-Dataflowendpunkten oder Konfigurieren von Azure Event Hubs und Kafka-Dataflowendpunkten. Thema Der Themenfilter, der für eingehende Nachrichten abonniert werden soll. Weitere Informationen finden Sie unter Konfigurieren von MQTT- oder Kafka-Themen. Nachrichtenschema Das Schema, das zum Deserialisieren der eingehenden Nachrichten verwendet werden soll. Weitere Informationen finden Sie unter Angeben des Schemas zum Deserialisieren von Daten. Wählen Sie Übernehmen.
Konfigurieren von Datenquellen (MQTT- oder Kafka-Themen)
Sie können mehrere MQTT- oder Kafka-Themen in einer Quelle angeben, ohne die Konfiguration des Dataflowendpunkts ändern zu müssen. Diese Flexibilität bedeutet, dass derselbe Endpunkt in mehreren Datenflüssen wiederverwendet werden kann, auch wenn die Themen variieren. Weitere Informationen finden Sie unter Wiederverwenden von Dataflowendpunkten.
MQTT-Themen
Wenn die Quelle ein MQTT-Endpunkt (Event Grid eingeschlossen) ist, können Sie den MQTT-Themenfilter verwenden, um eingehende Nachrichten zu abonnieren. Der Themenfilter kann Platzhalter enthalten, um mehrere Themen zu abonnieren. So abonniert thermostats/+/telemetry/temperature/# beispielsweise alle Temperaturtelemetriemeldungen von Thermostaten. So konfigurieren Sie die MQTT-Themenfilter
Wählen Sie auf der Einsatz-Benutzeroberfläche unter Quellendetails für den Dataflow die Option Nachrichtenbroker aus, und geben Sie dann im Feld Thema den MQTT-Themenfilter an, der für eingehende Nachrichten abonniert werden soll.
Hinweis
Auf der Einsatz-Benutzeroberfläche kann nur ein Themenfilter angegeben werden. Verwenden Sie Bicep oder Kubernetes, um mehrere Themenfilter zu verwenden.
Gemeinsame Abonnements
Um freigegebene Abonnements mit Nachrichtenbrokerquellen zu verwenden, können Sie das Thema für ein freigegebenes Abonnement in Form von $shared/<GROUP_NAME>/<TOPIC_FILTER> angeben.
Wählen Sie auf der Einsatz-Benutzeroberfläche unter Quellendetails für den Dataflow die Option Nachrichtenbroker aus, und geben Sie dann im Feld Thema die Gruppe und das Thema für das gemeinsame Abonnement an.
Wenn die Anzahl der Instanzen im Datenflussprofil größer als 1 ist, wird das gemeinsame Abonnement automatisch für alle Datenflüsse aktiviert, die eine Nachrichtenbrokerquelle verwenden. In diesem Fall wird das $shared Präfix hinzugefügt und der Name der gemeinsamen Abonnementgruppe automatisch generiert. Wenn Sie z. B. über ein Datenflussprofil mit einer Instanzenanzahl von 3 verfügen und Ihr Datenfluss einen Nachrichtenbroker-Endpunkt als Quelle verwendet, die mit Themen topic1 und topic2 konfiguriert ist, werden diese automatisch in gemeinsame Abonnements wie $shared/<GENERATED_GROUP_NAME>/topic1 und $shared/<GENERATED_GROUP_NAME>/topic2 konvertiert.
Sie können in Ihrer Konfiguration explizit ein Thema mit dem Namen $shared/mygroup/topic erstellen. Das explizite Hinzufügen des Themas $shared wird jedoch nicht empfohlen, da das Präfix $shared bei Bedarf automatisch hinzugefügt wird. Datenflüsse können Optimierungen mit dem Gruppennamen vornehmen, wenn dieser nicht festgelegt ist. Dies trifft beispielsweise zu, wenn $share nicht festgelegt ist und Datenflüsse ausschließlich den Themennamen verwenden.
Wichtig
Dies ist bei Datenflüssen wichtig, die ein gemeinsames Abonnement erfordern und die Anzahl der Instanzen größer als 1 ist, wenn Sie den MQTT-Broker von Event Grid als Quelle verwenden, da er keine gemeinsamen Abonnements unterstützt. Um fehlende Nachrichten zu vermeiden, legen Sie die Anzahl der Instanzen im Datenflussprofil bei Verwendung des MQTT-Brokers von Event Grid als Quelle auf 1 fest. Das ist der Zeitpunkt, an dem der Datenfluss der Abonnent ist und Nachrichten aus der Cloud empfängt.
Kafka-Themen
Wenn es sich bei der Quelle um einen Kafka-Endpunkt (einschließlich Event Hubs) handelt, geben Sie die einzelnen Kafka-Themen an, die für eingehende Nachrichten abonniert werden sollen. Platzhalter werden nicht unterstützt, daher müssen Sie jedes Thema statisch angeben.
Hinweis
Bei der Verwendung von Event Hubs über den Kafka-Endpunkt ist jeder einzelne Event Hub im Namespace das Kafka-Thema. Wenn Sie beispielsweise über einen Event Hubs-Namespace mit zwei Event Hubs verfügen (thermostats und humidifiers), können Sie jeden Event Hub als Kafka-Thema angeben.
So konfigurieren Sie Kafka-Themen
Wählen Sie auf der Einsatz-Benutzeroberfläche unter Quellendetails für den Dataflow die Option Nachrichtenbroker aus, und geben Sie dann im Feld Thema den Kafka-Themenfilter an, der für eingehende Nachrichten abonniert werden soll.
Hinweis
Auf der Einsatz-Benutzeroberfläche kann nur ein Themenfilter angegeben werden. Verwenden Sie Bicep oder Kubernetes, um mehrere Themenfilter zu verwenden.
Angeben des Quellschemas
Wenn Sie MQTT oder Kafka als Quelle verwenden, können Sie ein Schema angeben, um die Liste der Datenpunkte im Einsatz-Portal anzuzeigen. Die Verwendung eines Schemas zum Deserialisieren und Überprüfen eingehender Nachrichten wird zurzeit nicht unterstützt.
Wenn es sich bei der Quelle um eine Ressource handelt, wird das Schema automatisch aus der Ressourcendefinition abgeleitet.
Tipp
Um das Schema aus einer Beispieldatendatei zu generieren, verwenden Sie das Schema Gen-Hilfsprogramm.
So konfigurieren Sie das Schema, das zum Deserialisieren der eingehenden Nachrichten aus einer Quelle verwendet wird
Wählen Sie auf der Einsatz-Benutzeroberfläche unter Quellendetails für den Dataflow die Option Nachrichtenbroker aus, und geben Sie dann im Feld Nachrichtenschema das Schema an. Sie können die Schaltfläche Hochladen verwenden, um zuerst eine Schemadatei hochzuladen. Weitere Informationen finden Sie unter Grundlegendes zu Nachrichtenschemas.
Weitere Informationen finden Sie unter Grundlegendes zu Nachrichtenschemas.
Transformation
Mit dem Transformationsvorgang können Sie die Daten aus der Quelle transformieren, bevor Sie sie an das Ziel senden. Transformationen sind optional. Wenn Sie keine Änderungen an den Daten vornehmen müssen, schließen Sie den Transformationsvorgang nicht in die Datenflusskonfiguration ein. Mehrere Transformationen werden in Phasen verkettet, unabhängig von der Reihenfolge, in der sie in der Konfiguration angegeben sind. Die Reihenfolge der Phasen lautet immer wie folgt:
- Anreichern: Fügen Sie zusätzliche Daten zu den Quelldaten hinzu, die einem Dataset und einer Bedingung zugeordnet werden sollen.
- Filtern: Filtern Sie die Daten anhand einer Bedingung.
- Zuordnen, Berechnen, Umbenennen oder Hinzufügen einer neuen Eigenschaft: Verschieben Sie Daten aus einem Feld in ein anderes mit optionaler Konvertierung.
Dieser Abschnitt enthält eine Einführung in Datenflusstransformationen. Ausführlichere Informationen finden Sie unter Zuordnen von Daten mithilfe von Datenflüssen, Konvertieren von Daten mithilfe von Datenflusskonvertierungen und Anreichern von Daten mithilfe von Datenflüssen.
Wählen Sie auf der Einsatz-Benutzeroberfläche Dataflow>Transformation hinzufügen (optional) aus.
Anreichern: Hinzufügen von Verweisdaten
Fügen Sie zum Anreichern der Daten zunächst das Referenzdataset im Zustandsspeicher von Azure IoT Einsatz hinzu. Das Dataset wird verwendet, um zusätzliche Daten zu den Quelldaten basierend auf einer Bedingung hinzuzufügen. Die Bedingung wird als Feld in den Quelldaten angegeben, die einem Feld im Dataset entsprechen.
Sie können Beispieldaten mithilfe der Zustandsspeicher-CLI in den Zustandsspeicher laden. Die Schlüsselnamen im Zustandsspeicher entsprechen einem Dataset in der Datenflusskonfiguration.
Derzeit wird die Phase Anreichern auf der Benutzeroberfläche von Einsatz nicht unterstützt.
Wenn das Dataset über einen Datensatz mit dem Feld asset verfügt, ähnelt es Folgendem:
{
"asset": "thermostat1",
"location": "room1",
"manufacturer": "Contoso"
}
Die Daten aus der Quelle mit dem deviceId-Feld, das thermostat1 entspricht, verfügen über die Felder location und manufacturer in Filter- und Zuordnungsphasen.
Weitere Informationen zur Bedingungssyntax finden Sie unter Anreichern von Daten mithilfe von Datenflüssen und Konvertieren von Daten mithilfe von Datenflüssen.
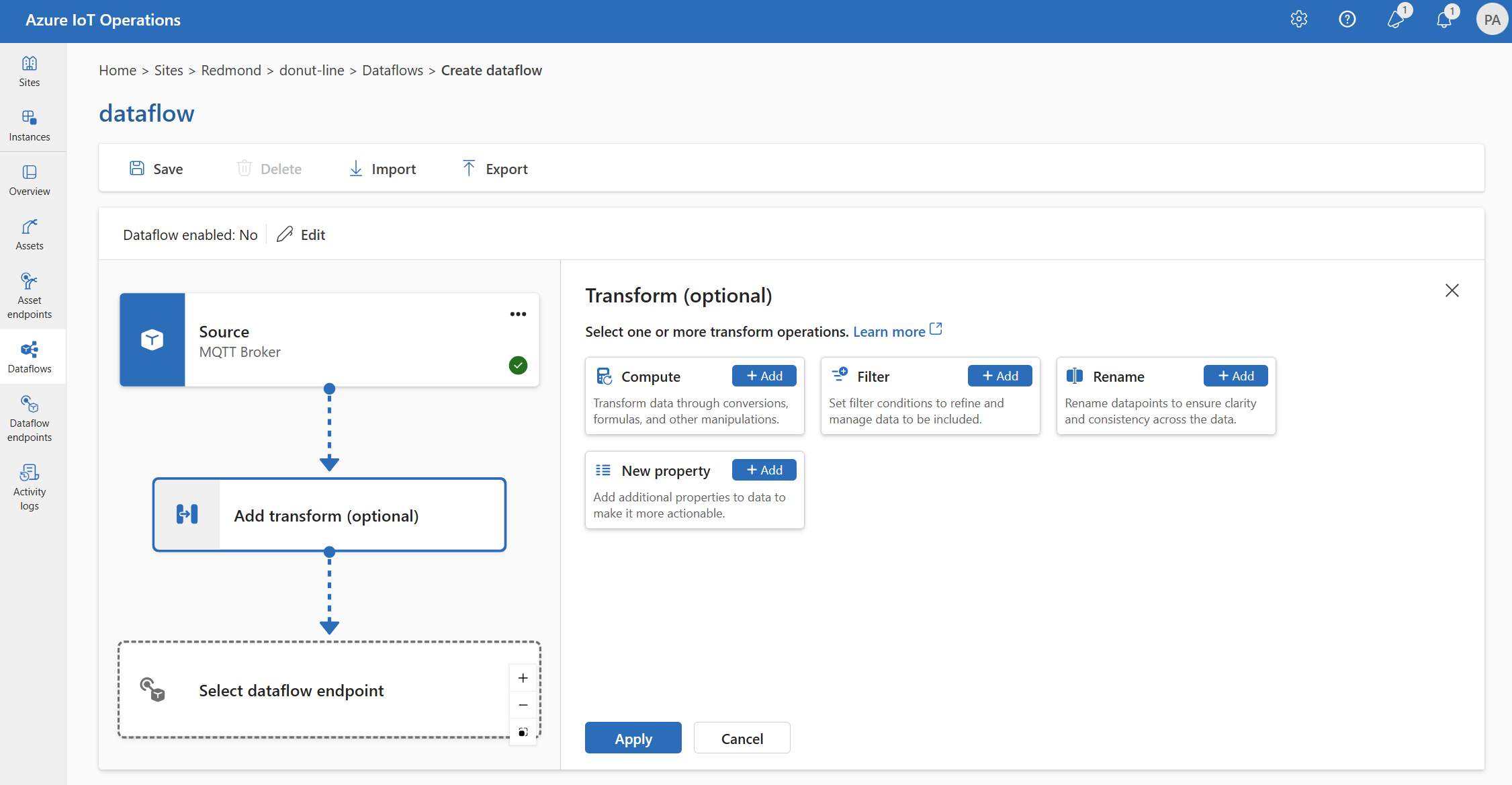
Filter: Filtern von Daten basierend auf einer Bedingung
Um die Daten nach einer Bedingung zu filtern, können Sie die filter-Phase verwenden. Die Bedingung wird als Feld in den Quelldaten angegeben, die einem Wert entsprechen.
Wählen Sie unter Transformieren (optional) die Option Filter>Hinzufügen aus.
Geben Sie die erforderlichen Einstellungen ein.
Einstellung Beschreibung Filter-Bedingung Die Bedingung zum Filtern der Daten basiert auf einem Feld in den Quelldaten. Beschreibung Geben Sie eine Beschreibung für die Filterbedingung an. Geben Sie im Feld „Filterbedingung“
@ein, oder drücken Sie STRG+LEERTASTE, um Datenpunkte aus einer Dropdownliste auszuwählen.Sie können MQTT-Metadateneigenschaften im Format
@$metadata.user_properties.<property>oder@$metadata.topiceingeben. Sie können auch $metadata-Header im Format@$metadata.<header>eingeben. Die$metadata-Syntax ist nur für MQTT-Eigenschaften erforderlich, die Teil des Nachrichtenkopfs sind. Weitere Informationen finden Sie unter Feldverweise.Die Bedingung kann die Felder in den Quelldaten verwenden. Sie können z. B. eine Filterbedingung wie
@temperature > 20verwenden, um Daten kleiner oder gleich 20 basierend auf dem Temperaturfeld zu filtern.Wählen Sie Übernehmen.
Zuordnung: Verschieben von Daten aus einem Feld in ein anderes
Um die Daten einem anderen Feld mit optionaler Konvertierung zuzuordnen, können Sie den map-Vorgang verwenden. Die Konvertierung wird als Formel angegeben, die die Felder in den Quelldaten verwendet.
Auf der Benutzeroberfläche von Einsatz wird derzeit die Zuordnung mithilfe der Transformationen Berechnen, Umbenennen und Neue Eigenschaft unterstützt.
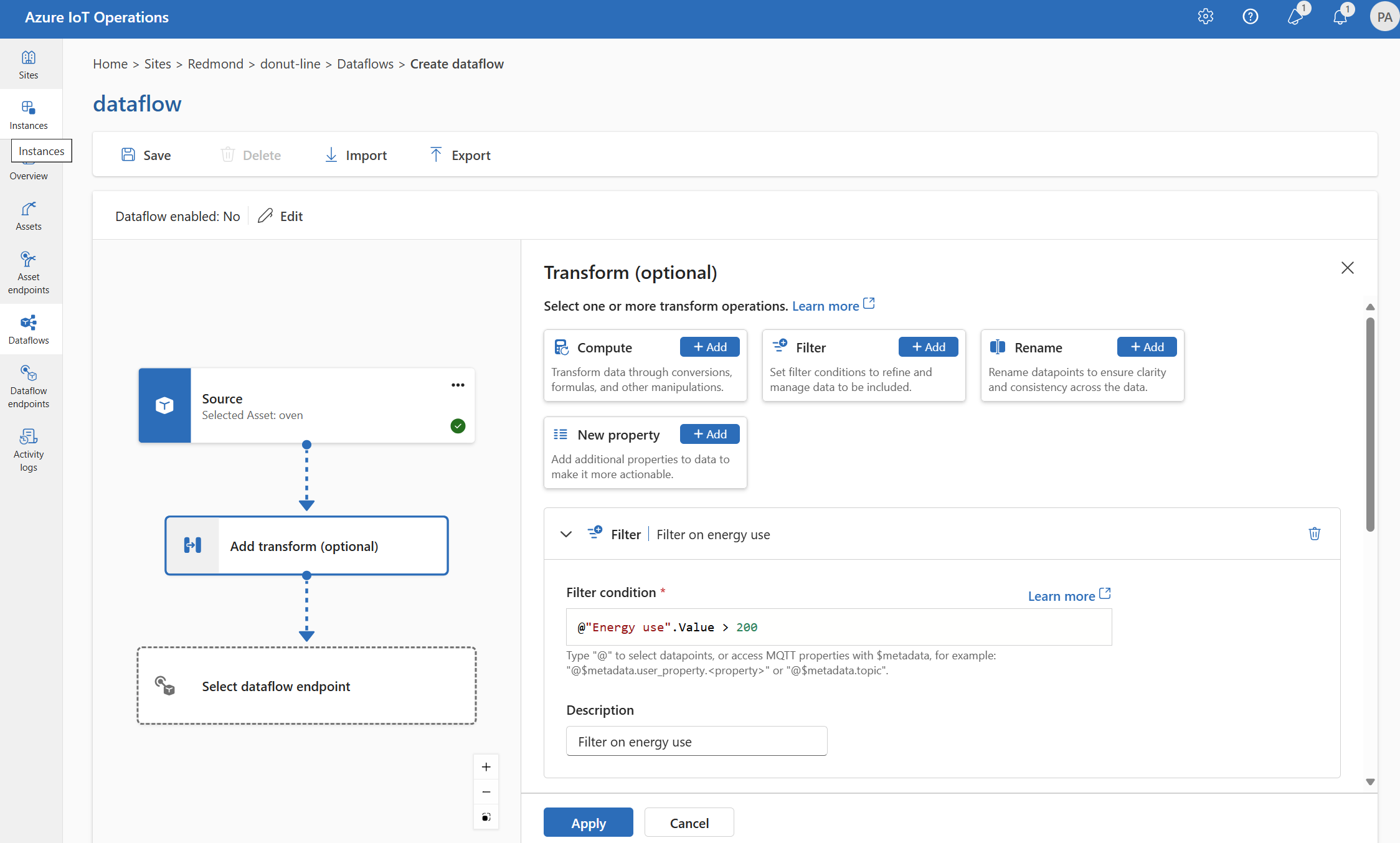
Compute
Sie können die Transformation Berechnen verwenden, um eine Formel auf die Quelldaten anzuwenden. Dieser Vorgang wird verwendet, um eine Formel auf die Quelldaten anzuwenden und das Ergebnisfeld zu speichern.
Wählen Sie unter Transformieren (optional) die Option Compute>Hinzufügen aus.
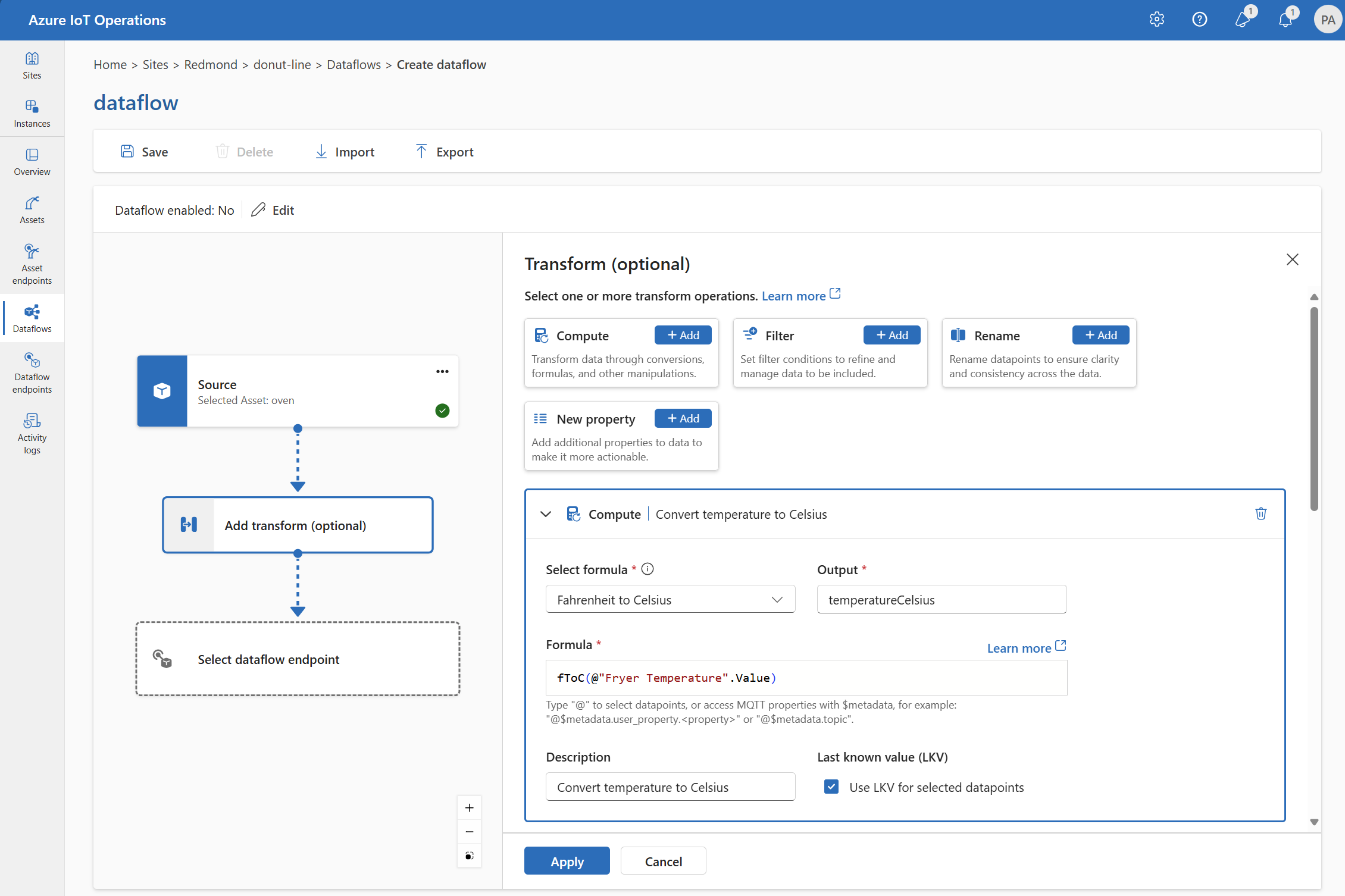
Geben Sie die erforderlichen Einstellungen ein.
Einstellung Beschreibung Auswählen einer Formel Wählen Sie eine vorhandene Formel aus der Dropdownliste aus, oder wählen Sie Benutzerdefiniert aus, um eine Formel manuell einzugeben. Output Geben Sie den Anzeigenamen für die Ausgabe des Ergebnisses an. Formel Geben Sie die Formel ein, die auf die Quelldaten angewendet werden soll. Beschreibung Geben Sie eine Beschreibung für die Transformation an. Letzter bekannter Wert Verwenden Sie optional den letzten bekannten Wert, wenn der aktuelle Wert nicht verfügbar ist. Sie können die Formel im Feld Formel eingeben oder bearbeiten. Die Formel kann die Felder in den Quelldaten verwenden. Geben Sie
@ein, oder drücken Sie STRG+LEERTASTE, um Datenpunkte aus einer Dropdownliste auszuwählen.Sie können MQTT-Metadateneigenschaften im Format
@$metadata.user_properties.<property>oder@$metadata.topiceingeben. Sie können auch $metadata-Header im Format@$metadata.<header>eingeben. Die$metadata-Syntax ist nur für MQTT-Eigenschaften erforderlich, die Teil des Nachrichtenkopfs sind. Weitere Informationen finden Sie unter Feldverweise.Die Formel kann die Felder in den Quelldaten verwenden. Sie können beispielsweise das Feld
temperaturein den Quelldaten verwenden, um die Temperatur in Celsius zu konvertieren und im AusgabefeldtemperatureCelsiuszu speichern.Wählen Sie Übernehmen.
Umbenennen
Sie können einen Datenpunkt mithilfe der Transformation Umbenennen umbenennen. Dieser Vorgang wird verwendet, um einem Datenpunkt in den Quelldaten einen neuen Namen zuzuweisen. Der neue Name kann in den nachfolgenden Phasen des Datenflusses verwendet werden.
Wählen Sie unter Transformieren (optional) die Option Umbenennen>Hinzufügen aus.
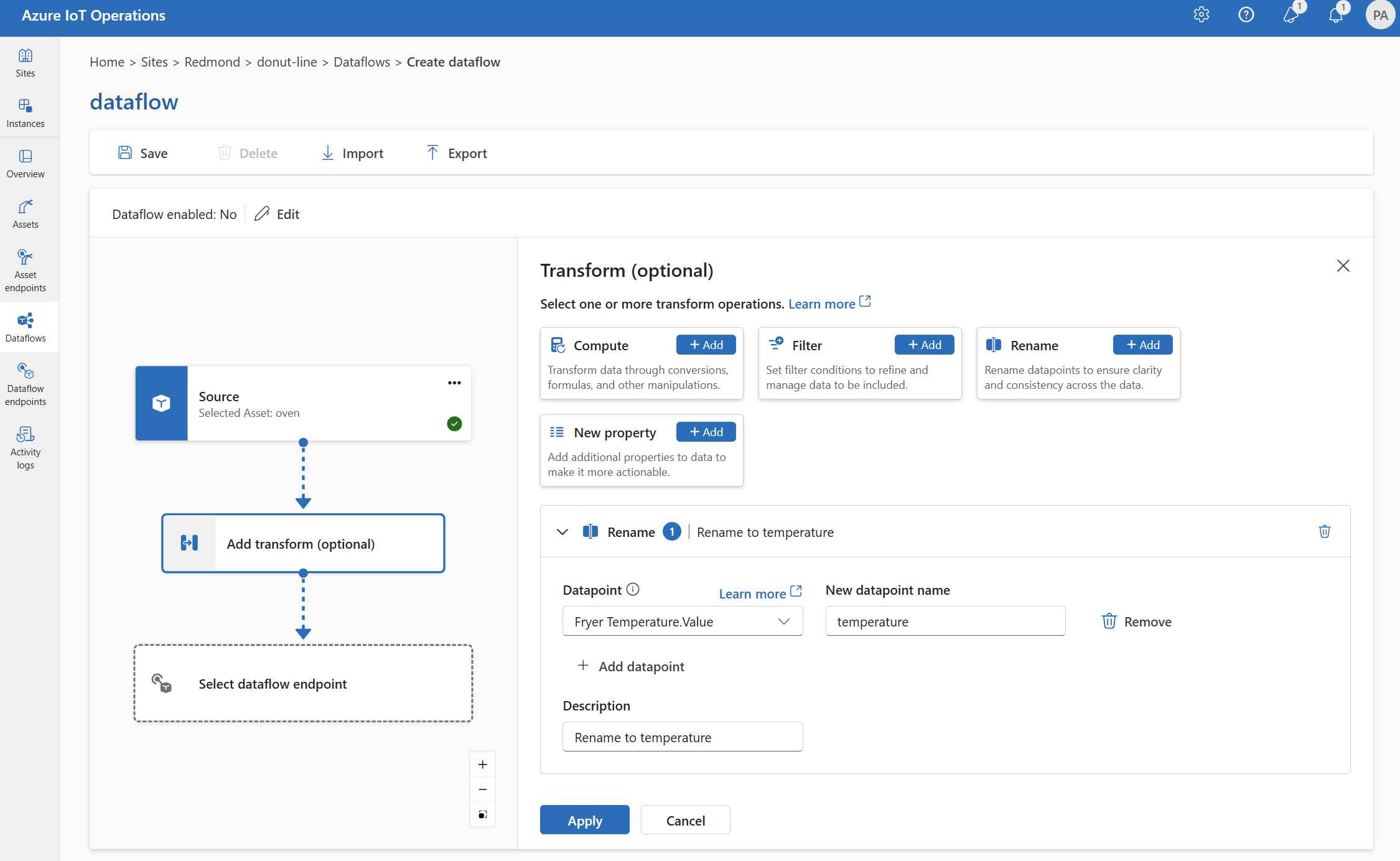
Geben Sie die erforderlichen Einstellungen ein.
Einstellung Beschreibung Datenpunkt Wählen Sie einen Datenpunkt aus der Dropdownliste aus, oder geben Sie einen $metadata-Header ein. Neuer Datenpunktname Geben Sie den neuen Namen für den Datenpunkt ein. Beschreibung Geben Sie eine Beschreibung für die Transformation an. Geben Sie
@ein, oder drücken Sie STRG+LEERTASTE, um Datenpunkte aus einer Dropdownliste auszuwählen.Sie können MQTT-Metadateneigenschaften im Format
@$metadata.user_properties.<property>oder@$metadata.topiceingeben. Sie können auch $metadata-Header im Format@$metadata.<header>eingeben. Die$metadata-Syntax ist nur für MQTT-Eigenschaften erforderlich, die Teil des Nachrichtenkopfs sind. Weitere Informationen finden Sie unter Feldverweise.Wählen Sie Übernehmen.
Neue Eigenschaft
Sie können den Quelldaten mithilfe der Transformation Neue Eigenschaft eine neue Eigenschaft hinzufügen. Dieser Vorgang wird verwendet, um den Quelldaten eine neue Eigenschaft hinzuzufügen. Die neue Eigenschaft kann in den nachfolgenden Phasen des Datenflusses verwendet werden.
Wählen Sie unter Transformieren (optional) die Option Neue Eigenschaft>Hinzufügen aus.
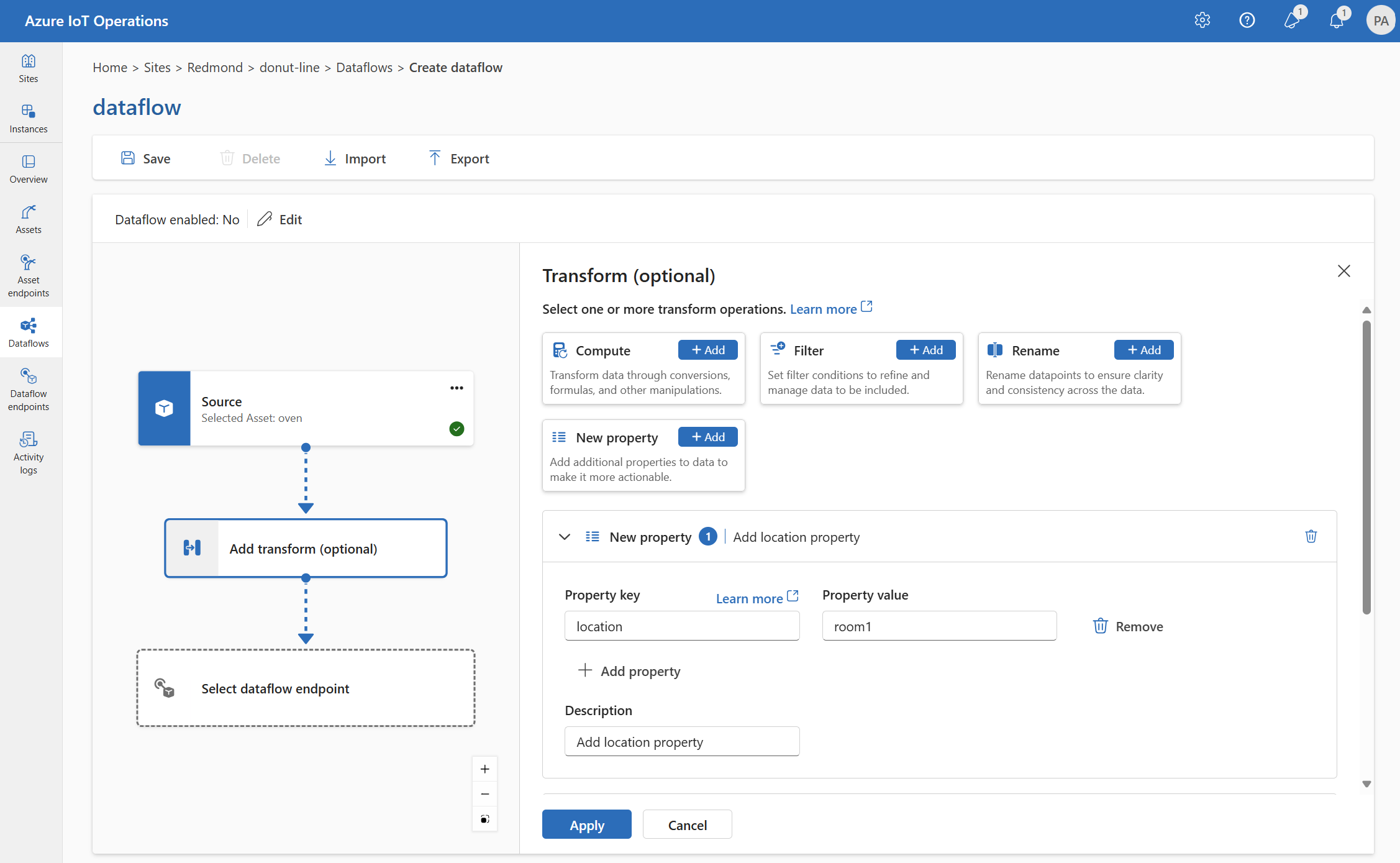
Geben Sie die erforderlichen Einstellungen ein.
Einstellung Beschreibung Eigenschaftsschlüssel Geben Sie den Schlüssel für die neue Eigenschaft ein. Eigenschaftswert Geben Sie den Wert für die neue Eigenschaft ein. Beschreibung Geben Sie eine Beschreibung für die neue Eigenschaft an. Wählen Sie Übernehmen.
Weitere Informationen finden Sie unter Zuordnen von Daten mithilfe von Datenflüssen und Konvertieren von Daten mithilfe von Datenflüssen.
Serialisieren von Daten nach einem Schema
Wenn Sie die Daten vor dem Senden an das Ziel serialisieren möchten, müssen Sie ein Schema- und Serialisierungsformat angeben. Andernfalls werden die Daten mit den abgeleiteten Typen in JSON serialisiert. Speicherendpunkte wie Microsoft Fabric oder Azure Data Lake benötigen ein Schema, um die Datenkonsistenz sicherzustellen. Unterstützt werden die Serialisierungsformate Parquet und Delta.
Tipp
Um das Schema aus einer Beispieldatendatei zu generieren, verwenden Sie das Schema Gen-Hilfsprogramm.
Sie geben das Schema- und Serialisierungsformat auf der Einsatz-Benutzeroberfläche in den Details des Datenflussendpunkts an. Die Endpunkte, die Serialisierungsformate unterstützen, sind Microsoft Fabric OneLake, Azure Data Lake Storage Gen2, Azure Data Explorer und lokaler Speicher. Um beispielsweise die Daten im Delta-Format zu serialisieren, müssen Sie ein Schema in die Schemaregistrierung hochladen und in der Konfiguration des Datenflussendpunkts darauf verweisen.
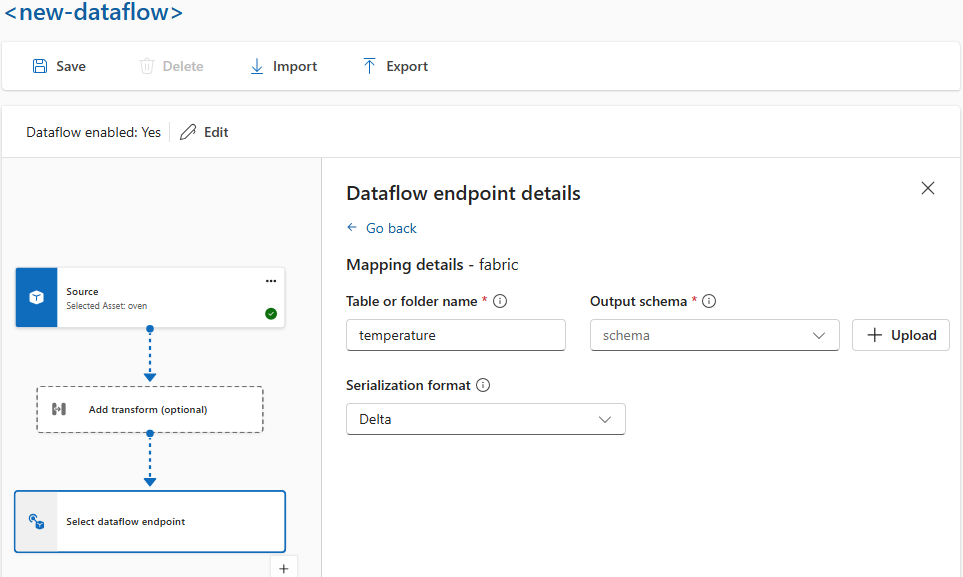
Weitere Informationen zur Schemaregistrierung finden Sie unter Grundlegendes zu Nachrichtenschemata.
Destination
Um ein Ziel für den Datenfluss zu konfigurieren, geben Sie den Endpunktverweis und das Datenziel an. Sie können eine Liste der Datenziele für den Endpunkt angeben.
Um Daten an ein anderes Ziel als den lokalen MQTT-Broker zu senden, erstellen Sie einen Dataflowendpunkt. Informationen zur Vorgehensweise finden Sie unter Konfigurieren von Dataflowendpunkten. Wenn das Ziel nicht der lokale MQTT-Broker ist, muss es als Quelle verwendet werden. Weitere Informationen finden Sie unter Dataflows müssen den lokalen MQTT-Broker-Endpunkt verwenden.
Wichtig
Speicherendpunkte erfordern ein Schema für die Serialisierung. Um den Datenfluss mit Microsoft Fabric OneLake, Azure Data Lake Storage, Azure Data Explorer oder lokalem Speicher zu verwenden, müssen Sie einen Schemaverweis angeben.
Wählen Sie den Datenflussendpunkt aus, der als Ziel dienen soll.
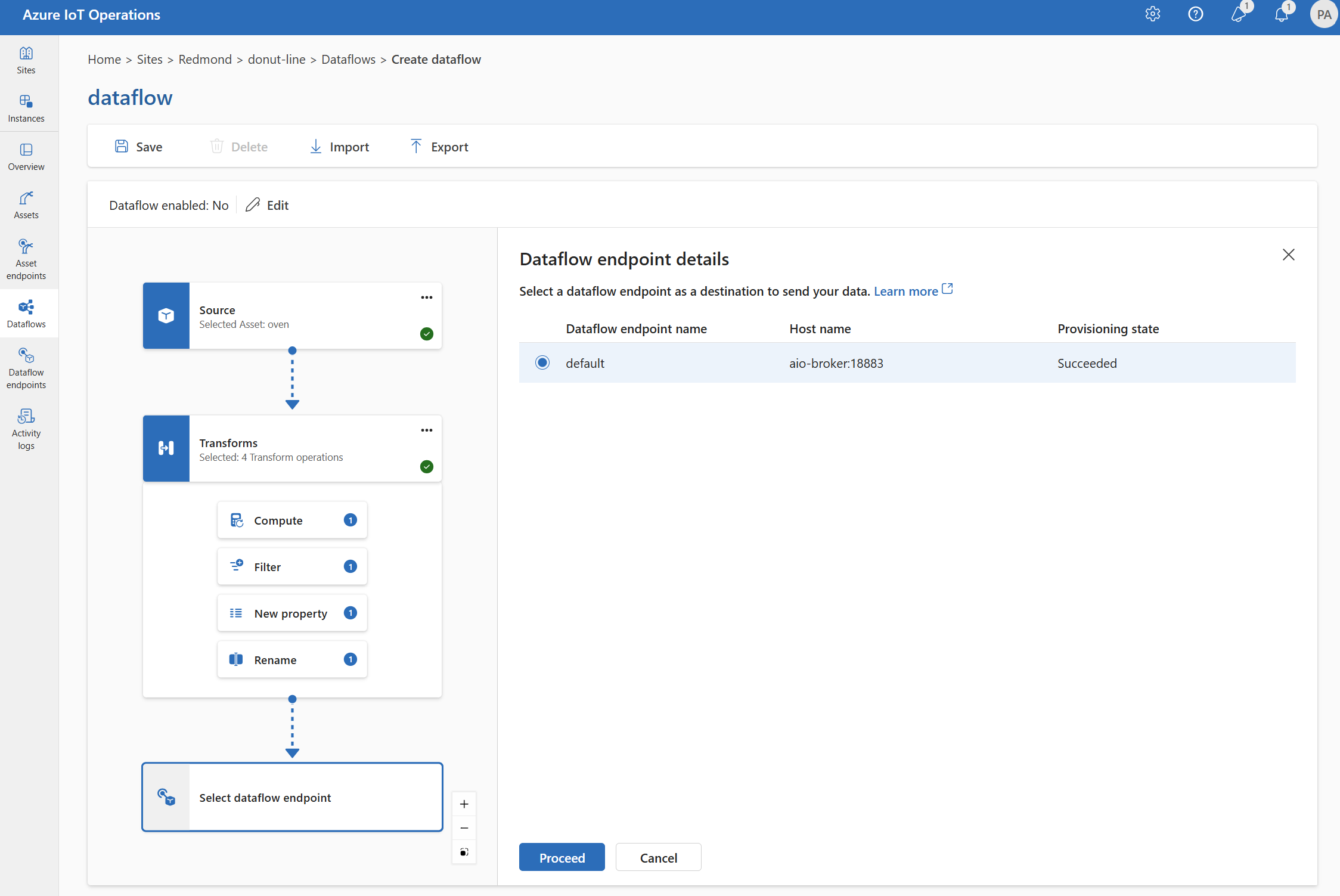
Speicherendpunkte erfordern ein Schema für die Serialisierung. Wenn Sie einen Microsoft Fabric OneLake-, Azure Data Lake Storage-, Azure Data Explorer- oder Local Storage-Zielendpunkt auswählen, müssen Sie einen Schemaverweisangeben. Um beispielsweise die Daten in einen Microsoft Fabric-Endpunkt serialisieren, müssen Sie ein Schema in die Schemaregistrierung hochladen und in der Konfiguration des Datenflussendpunkts darauf verweisen.
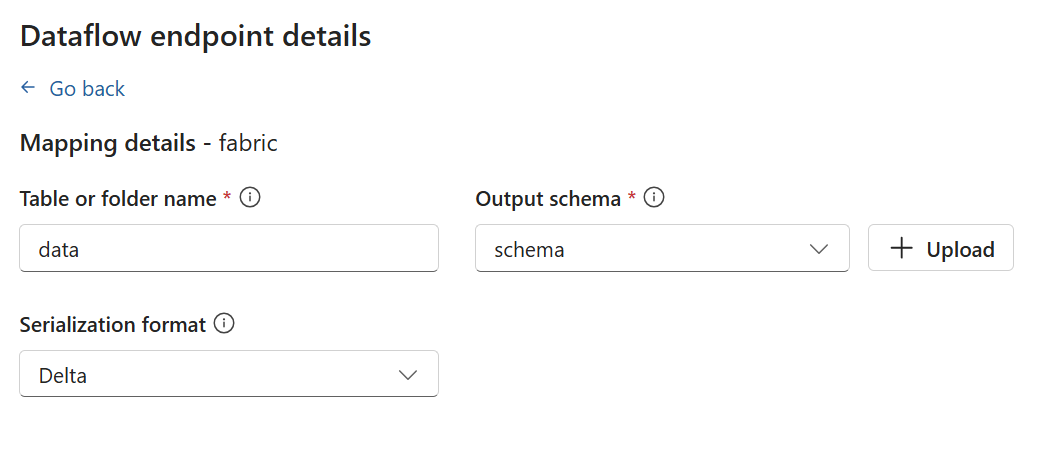
Wählen Sie Fortfahren aus, um das Ziel zu konfigurieren.
Geben Sie die erforderlichen Einstellungen für das Ziel ein, einschließlich des Themas oder der Tabelle, an das bzw. die die Daten gesendet werden sollen. Weitere Informationen finden Sie unter Konfigurieren des Datenziels (Thema, Container oder Tabelle).
Konfigurieren des Datenziels (Thema, Container oder Tabelle)
Ähnlich wie bei Datenquellen ist das Datenziel ein Konzept, das dazu dient, dass Dataflowendpunkte über mehrere Dataflows hinweg wiederverwendet werden können. Im Wesentlichen stellt es das Unterverzeichnis in der Konfiguration des Datenflussendpunkts dar. Wenn der Dataflowendpunkt beispielsweise ein Speicherendpunkt ist, ist das Datenziel die Tabelle im Speicherkonto. Wenn der Dataflowendpunkt ein Kafka-Endpunkt ist, ist das Datenziel das Kafka-Thema.
| Endpunkttyp | Bedeutung des Datenziels | Beschreibung |
|---|---|---|
| MQTT (oder Event Grid) | Thema | Das MQTT-Thema, an das die Daten gesendet werden. Nur statische Themen werden unterstützt, keine Platzhalter. |
| Kafka (oder Event Hubs) | Thema | Das Kafka-Thema, an das die Daten gesendet werden. Nur statische Themen werden unterstützt, keine Platzhalter. Wenn der Endpunkt ein Event Hubs-Namespace ist, ist das Datenziel der einzelne Event Hub innerhalb des Namespace. |
| Azure Data Lake Storage | Container | Der Container im Speicherkonto. Nicht die Tabelle. |
| Microsoft Fabric OneLake | Tabelle oder Ordner | Entspricht dem konfigurierten Pfadtyp für den Endpunkt. |
| Azure-Daten-Explorer | Tabelle | Tabelle in der Azure Data Explorer-Datenbank. |
| Lokaler Speicher | Ordner | Der Ordner- oder Verzeichnisname in der Einbindung des persistenten Volumes im lokalen Speicher. Wenn Sie Azure Container Storage auf Basis von Azure Arc Cloud Ingest Edge-Volumes verwenden, muss dies mit dem spec.path-Parameter für das von Ihnen erstellte Untervolume übereinstimmen. |
So konfigurieren Sie das Datenziel
Bei Verwendung der Einsatz-Benutzeroberfläche wird das Datenzielfeld basierend auf dem Endpunkttyp automatisch interpretiert. Wenn der Dataflowendpunkt beispielsweise ein Speicherendpunkt ist, werden Sie auf der Zieldetailseite aufgefordert, den Containernamen einzugeben. Wenn der Datenflussendpunkt ein MQTT-Endpunkt ist, werden Sie auf der Zieldetailseite aufgefordert, das Thema einzugeben, usw.
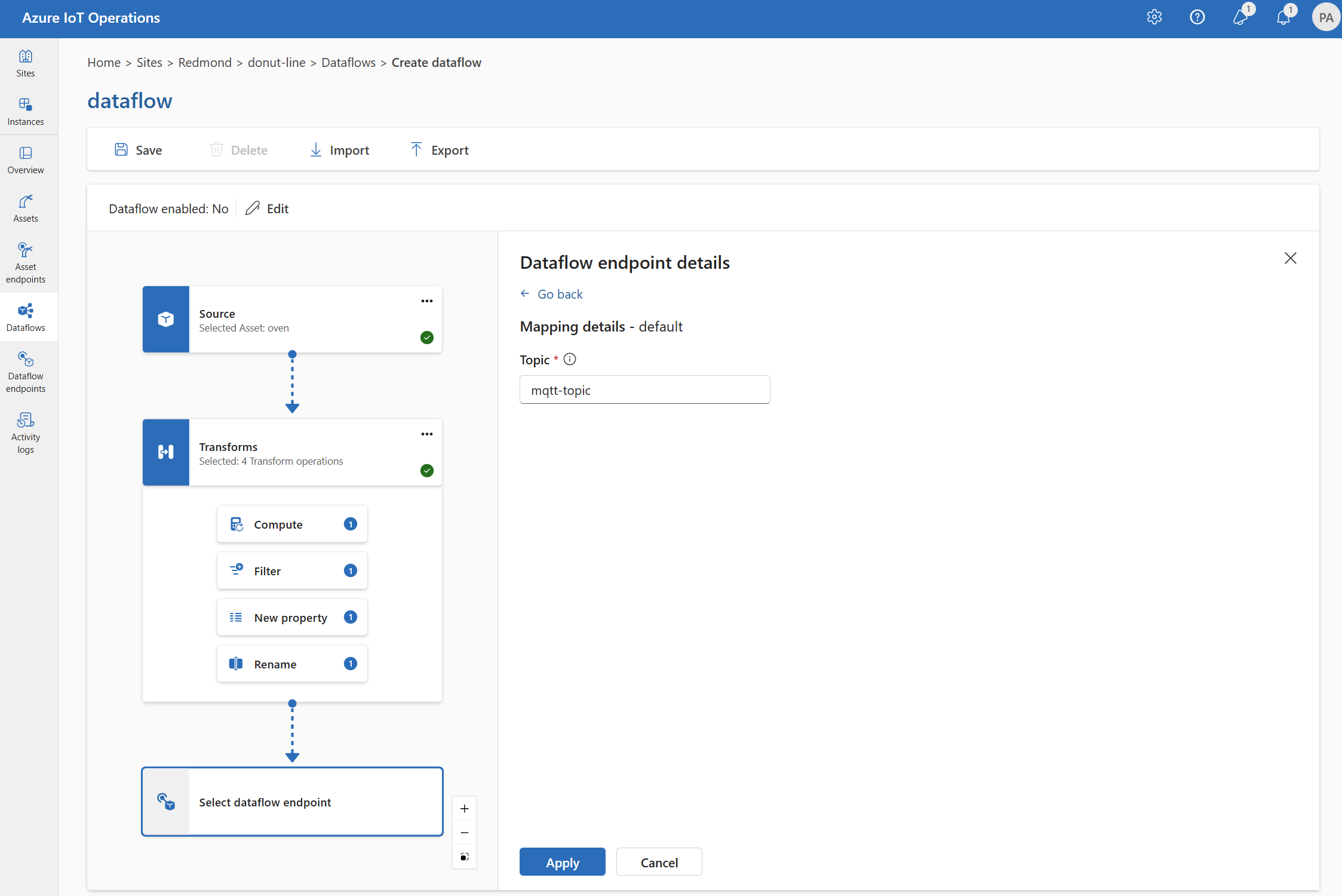
Beispiel
Das folgende Beispiel ist eine Datenflusskonfiguration, die den MQTT-Endpunkt als Quelle und Ziel verwendet. Die Quelle filtert die Daten aus dem MQTT-Thema azure-iot-operations/data/thermostat. Die Transformation konvertiert die Temperatur in Fahrenheit und filtert die Daten, bei denen das Verhältnis Temperatur multipliziert mit Luftfeuchtigkeit kleiner als 100.000 ist. Das Ziel sendet die Daten an das MQTT-Thema factory.

Weitere Beispiele für Datenflusskonfigurationen finden Sie unter Azure REST API – Dataflow und Schnellstart Bicep.
Überprüfen, ob ein Datenfluss funktioniert
Folgen Sie dem Tutorial: Bidirektionale MQTT-Brücke zu Azure Event Grid, um zu überprüfen, ob der Datenfluss funktioniert.
Exportieren der Datenflusskonfiguration
Zum Exportieren der Dataflowkonfiguration können Sie die Einsatz-Benutzeroberfläche verwenden oder die benutzerdefinierte Dataflowressource exportieren.
Wählen Sie den zu exportierenden Datenfluss aus, und wählen Sie auf der Symbolleiste Exportieren aus.
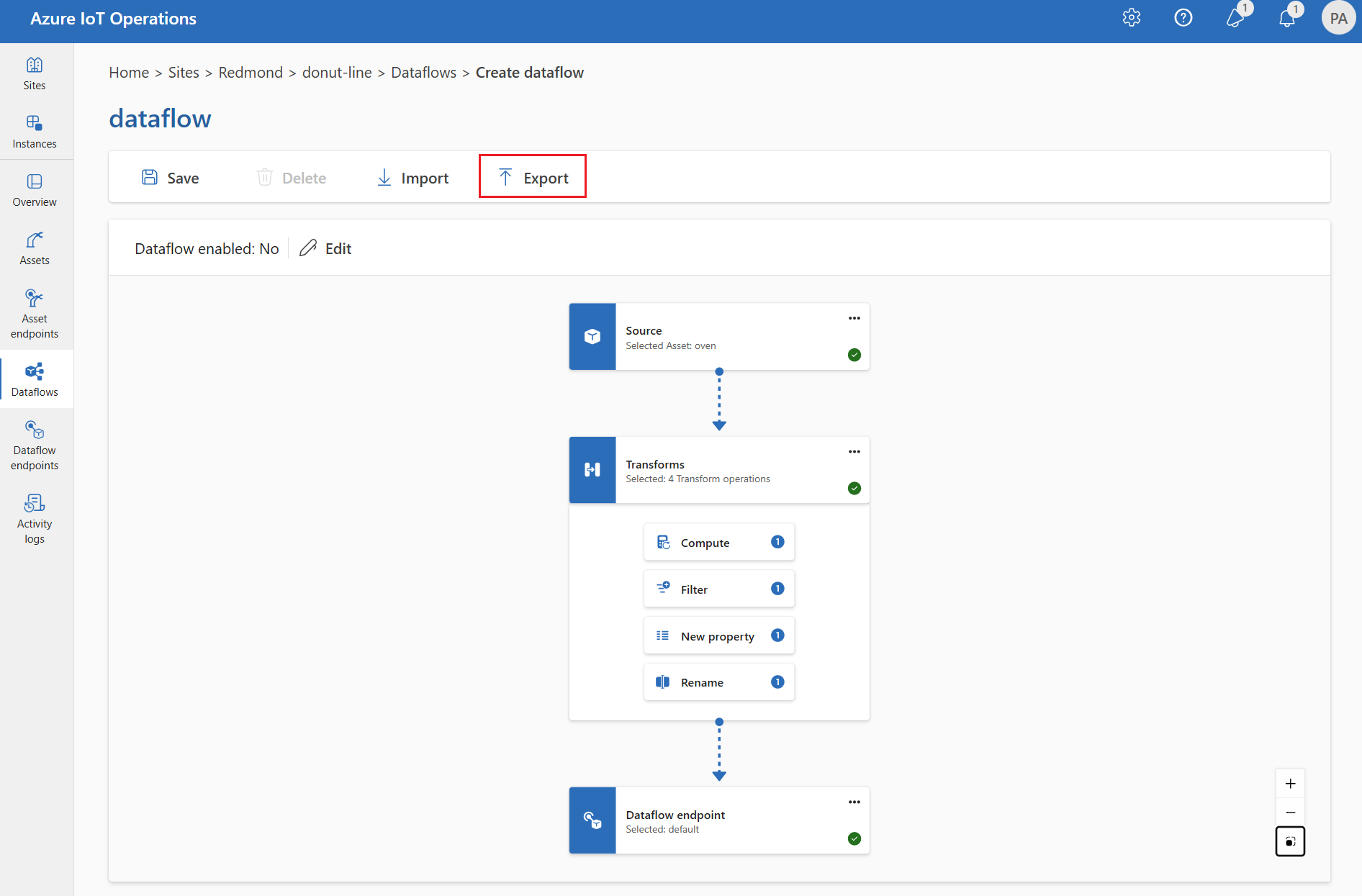
Richtige Datenflusskonfiguration
Um sicherzustellen, dass der Datenfluss wie erwartet funktioniert, überprüfen Sie Folgendes:
- Der standardmäßige MQTT-Datenflussendpunkt muss entweder als Quelle oder Ziel verwendet werden.
- Das Datenflussprofil ist vorhanden und wird in der Datenflusskonfiguration referenziert.
- Die Quelle ist entweder ein MQTT-Endpunkt, ein Kafka-Endpunkt oder eine Ressource. Speichertypendpunkte können nicht als Quelle verwendet werden.
- Wenn Sie Event Grid als Quelle verwenden, wird die Anzahl der Datenflussprofilinstanzen auf 1 festgelegt, da der Event Grid MQTT-Broker keine freigegebenen Abonnements unterstützt.
- Bei Verwendung von Event Hubs als Quelle ist jeder Event Hub im Namespace ein separates Kafka-Thema und muss als Datenquelle angegeben werden.
- Die Transformation wird, sofern verwendet, mit der richtigen Syntax konfiguriert, einschließlich der richtigen Maskierung von Sonderzeichen.
- Wenn Sie Speichertypendpunkte als Ziel verwenden, wird ein Schema angegeben.