Konfigurieren von Azure Event Hubs und Kafka-Dataflowendpunkten
Wichtig
Diese Seite enthält Anweisungen zum Verwalten der Komponenten von Azure IoT Einsatz mithilfe von Kubernetes-Bereitstellungsmanifesten. Diese Option befindet sich in der Vorschau. Dieses Feature wird mit einigen Einschränkungen bereitgestellt und sollte nicht für Produktionsworkloads verwendet werden.
Die zusätzlichen Nutzungsbestimmungen für Microsoft Azure-Vorschauen enthalten rechtliche Bedingungen. Sie gelten für diejenigen Azure-Features, die sich in der Beta- oder Vorschauversion befinden oder aber anderweitig noch nicht zur allgemeinen Verfügbarkeit freigegeben sind.
Zum Einrichten der bidirektionalen Kommunikation zwischen Azure IoT Einsatz und Apache Kafka-Brokern können Sie einen Dataflowendpunkt konfigurieren. Mit dieser Konfiguration können Sie den Endpunkt, Transport Layer Security (TLS), die Authentifizierung und andere Einstellungen angeben.
Voraussetzungen
- Eine Instanz von Azure IoT Einsatz
Azure Event Hubs
Azure Event Hubs ist mit dem Kafka-Protokoll kompatibel und kann mit einigen Einschränkungen mit Dataflows verwendet werden.
Erstellen eines Azure Event Hubs-Namespace und eines Event Hubs
Erstellen Sie zunächst einen Kafka-fähigen Azure Event Hubs-Namespace.
Erstellen Sie danach einen Event Hub im Namespace. Jeder einzelne Event Hub entspricht einem Kafka-Thema. Sie können mehrere Event Hubs im selben Namespace erstellen, um mehrere Kafka-Themen darzustellen.
Zuweisen von Berechtigungen zur verwalteten Identität
Um einen Datenflussendpunkt für Azure Event Hubs zu konfigurieren, empfehlen wir, entweder eine benutzerseitig zugewiesene oder systemseitig zugewiesene verwaltete Identität zu verwenden. Dieser Ansatz ist sicher und beseitigt die Notwendigkeit der manuellen Verwaltung von Anmeldeinformationen.
Nachdem der Azure Event Hubs-Namespace und der Event Hub erstellt wurden, müssen Sie der verwalteten Azure IoT Einsatz-Identität eine Rolle zuweisen, die die Berechtigung zum Senden oder Empfangen von Nachrichten an den Event Hub erteilt.
Wenn Sie systemseitig zugewiesene verwaltete Identität verwenden, wechseln Sie im Azure-Portal zu Ihrer Azure IoT Einsatz-Instanz, und wählen Sie Übersicht aus. Kopieren Sie den Namen der Erweiterung, die nach der Arc-Erweiterung für Azure IoT Einsatz aufgeführt ist. Beispiel: azure-iot-operations-xxxx7. Ihre systemseitig zugewiesene verwaltete Identität kann über denselben Namen der Azure IoT Einsatz Arc-Erweiterung gefunden werden.
Wechseln Sie dann zu „Event Hubs-Namespace“ >Zugriffssteuerung (IAM)>Rollenzuweisung hinzufügen.
- Wählen Sie auf der Registerkarte Rolle eine entsprechende Rolle aus, z. B.
Azure Event Hubs Data SenderoderAzure Event Hubs Data Receiver. Dadurch erhält die verwaltete Identität die erforderlichen Berechtigungen zum Senden oder Empfangen von Nachrichten für alle Event Hubs im Namespace. Weitere Informationen finden Sie unter Authentifizieren einer Anwendung mit Microsoft Entra ID für den Zugriff auf Event Hubs-Ressourcen. - Auf der Registerkarte Mitglieder:
- Wenn Sie die systemseitig zugewiesene verwaltete Identität verwenden, wählen Sie für Zugriff zuweisen zu die Option Benutzer, Gruppe oder Dienstprinzipal aus, wählen Sie dann + Mitglieder auswählen aus, und suchen Sie nach dem Namen der Azure IoT Einsatz Arc-Erweiterung.
- Wenn Sie die benutzerseitig zugewiesene verwaltete Identität verwenden, wählen Sie für Zugriff zuweisen zu die Option Verwaltete Identität aus, wählen Sie dann + Mitglieder auswählen aus, und suchen Sie nach Ihrer Einrichtung der benutzerseitig zugewiesenen verwalteten Identität für Cloudverbindungen.
Erstellen Sie den Datenflussendpunkt für Azure Event Hubs.
Nachdem der Azure Event Hubs-Namespace und der Event Hub konfiguriert wurden, können Sie einen Datenflussendpunkt für den Kafka-fähigen Azure Event Hubs-Namespace erstellen.
Wählen Sie auf der Einsatz-Benutzeroberfläche die Registerkarte Dataflowendpunkte aus.
Wählen Sie unter Neuen Dataflowendpunkt erstellen die Option Azure Event Hubs>Neu aus.
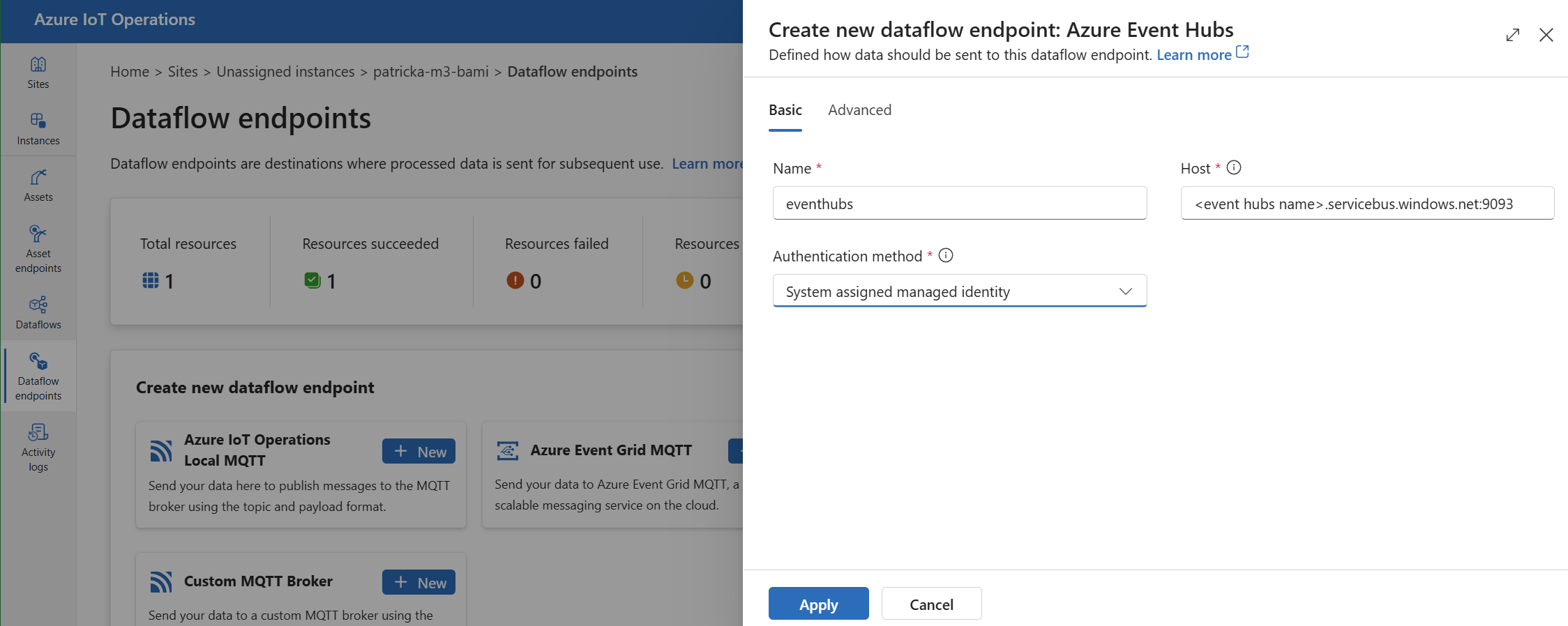
Geben Sie die folgenden Einstellungen für den Endpunkt ein:
Einstellung BESCHREIBUNG Name Der Name des Dataflowendpunkts. Host Der Hostname des Kafka-Brokers im Format <NAMESPACE>.servicebus.windows.net:9093. Fügen Sie die Portnummer9093in der Hosteinstellung für Event Hubs ein.Authentifizierungsmethode Die für die Authentifizierung verwendete Methode. Es wird empfohlen, Systemseitig zugewiesene verwaltete Identität oder Benutzerseitig zugewiesene verwaltete Identität auszuwählen. Wählen Sie Übernehmen aus, um den Endpunkt bereitzustellen.
Hinweis
Das Kafka-Thema oder der einzelne Event Hub wird später konfiguriert, wenn Sie den Dataflow erstellen. Das Kafka-Thema ist das Ziel für die Dataflownachrichten.
Verwenden der Verbindungszeichenfolge für die Authentifizierung bei Event Hubs
Wichtig
Um das Einsatz-Portal zum Verwalten von Geheimnissen zu verwenden, muss Azure IoT Einsatz zuerst mit sicheren Einstellungen aktiviert werden, indem Sie eine Azure Key Vault-Instanz konfigurieren und Workloadidentitäten aktivieren. Weitere Informationen finden Sie unter Aktivieren sicherer Einstellungen in der Bereitstellung von Azure IoT Einsatz.
Wählen Sie auf der Seite „Einstellungen“ für den Dataflowendpunkt auf der Einsatz-Benutzeroberfläche die Registerkarte Allgemeine Informationen und dann Authentifizierungsmethode>SASL aus.
Geben Sie die folgenden Einstellungen für den Endpunkt ein:
| Einstellung | Beschreibung |
|---|---|
| SASL-Typ | Klicken Sie auf die Option Plain. |
| Synchronisierter Geheimnisname | Geben Sie den Namen des Kubernetes-Geheimnisses ein, welches die Verbindungszeichenfolge enthält. |
| Benutzernamenverweis oder geheimer Tokenschlüssel | Der Verweis auf den Benutzernamen oder den geheimen Tokenschlüssels, der für die SASL-Authentifizierung verwendet wird. Wählen Sie ihn entweder aus der Key Vault-Liste aus, oder erstellen Sie einen neuen. Der Wert muss $ConnectionString sein. |
| Kennwortreferenz des geheimen Tokenschlüssels | Der Verweis auf das Kennwort oder den geheimen Tokenschlüssel, der für die SASL-Authentifizierung verwendet wird. Wählen Sie ihn entweder aus der Key Vault-Liste aus, oder erstellen Sie einen neuen. Der Wert muss im Format Endpoint=sb://<NAMESPACE>.servicebus.windows.net/;SharedAccessKeyName=<KEY-NAME>;SharedAccessKey=<KEY> angegeben werden. |
Nachdem Sie Verweis hinzufügen ausgewählt haben, geben Sie die folgenden Einstellungen ein, wenn Sie Neu erstellen ausgewählt haben:
| Einstellung | Beschreibung |
|---|---|
| Geheimnisname | Der Name des Geheimnisses in Azure Key Vault. Wählen Sie einen Namen aus, der sich einfach merken lässt, um das Geheimnis später in der Liste auswählen zu können. |
| Geheimer Wert | Geben Sie für den Benutzernamen $ConnectionString ein. Geben Sie für das Kennwort die Verbindungszeichenfolge im Format Endpoint=sb://<NAMESPACE>.servicebus.windows.net/;SharedAccessKeyName=<KEY-NAME>;SharedAccessKey=<KEY> ein. |
| Aktivierungsdatum festlegen | Wenn diese Option aktiviert ist, das Datum, an dem das Geheimnis aktiv wird. |
| Festlegen des Ablaufdatums | Wenn diese Option deaktiviert ist, das Datum, an dem das Geheimnis abläuft. |
Weitere Informationen zu Geheimnissen finden Sie unter Verwalten von Geheimnissen für Ihre Bereitstellung von Azure IoT Einsatz.
Begrenzungen
Azure Event Hubs unterstützt nicht alle Komprimierungstypen, die Kafka unterstützt. Nur GZIP-Komprimierung wird derzeit in Azure Event Hubs Premium- und Dedicated-Ebenen unterstützt. Die Verwendung anderer Komprimierungstypen kann zu Fehlern führen.
Benutzerdefinierte Kafka-Broker
Um einen Dataflowendpunkt für Kafka-Broker in einem Nicht-Event Hub zu konfigurieren, legen Sie den Host, TLS, die Authentifizierung und andere Einstellungen nach Bedarf fest.
Wählen Sie auf der Einsatz-Benutzeroberfläche die Registerkarte Dataflowendpunkte aus.
Wählen Sie unter Neuen Dataflowendpunkt erstellen die Option Benutzerdefinierter Kafka-Broker>Neu aus.
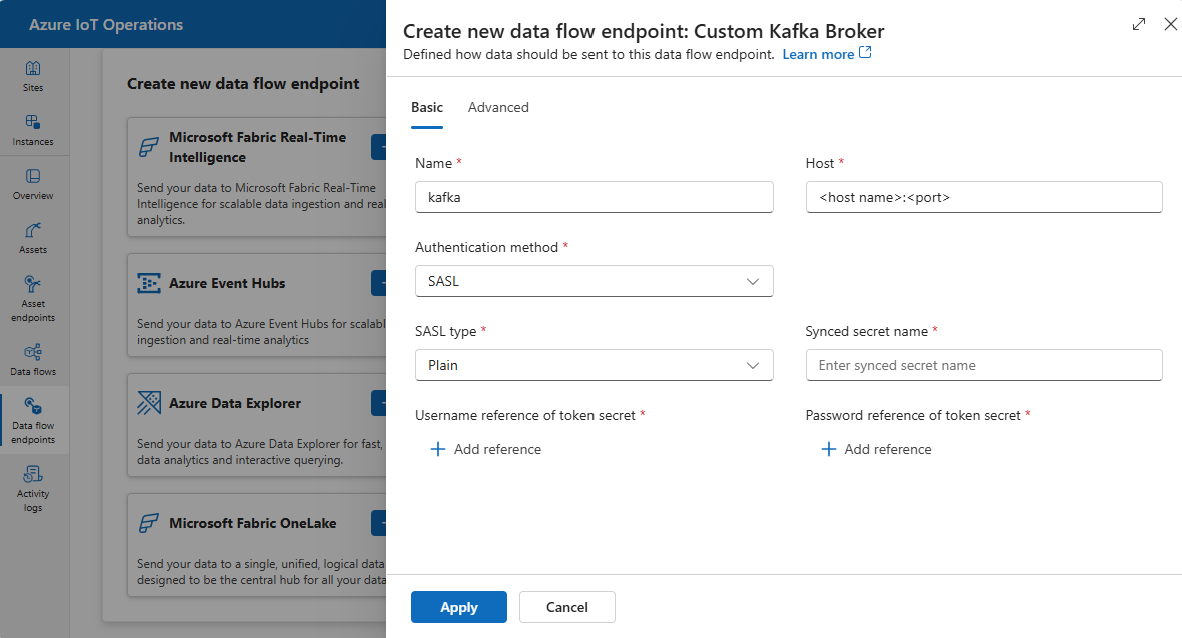
Geben Sie die folgenden Einstellungen für den Endpunkt ein:
Einstellung BESCHREIBUNG Name Der Name des Dataflowendpunkts. Host Der Hostname des Kafka-Brokers im Format <Kafka-broker-host>:xxxx. Fügen Sie die Portnummer in der Hosteinstellung ein.Authentifizierungsmethode Die für die Authentifizierung verwendete Methode. Wählen Sie SASL aus. SASL-Typ Der Typ der SASL-Authentifizierung. Wählen Sie Plain, ScramSha256 oder ScramSha512 aus. Erforderlich, wenn SASLverwendet wird. Synchronisierter Geheimnisname Der Name des Geheimnisses. Erforderlich, wenn SASLverwendet wird. Benutzernamenverweis des geheimen Tokenschlüssels Der Verweis auf den Benutzernamen im geheimen SASL-Tokenschlüssel. Erforderlich, wenn SASLverwendet wird. Wählen Sie Übernehmen aus, um den Endpunkt bereitzustellen.
Hinweis
Derzeit unterstützt die Einsatz-Benutzeroberfläche die Verwendung eines Kafka-Dataflowendpunkts als Quelle nicht. Sie können einen Dataflow mit einem Kafka-Dataflowendpunkt für die Quelle erstellen, indem Sie Kubernetes oder Bicep verwenden.
Weitere Informationen zum Anpassen von Endpunkteinstellungen finden Sie in den folgenden Abschnitten.
Verfügbare Authentifizierungsmethoden
Die folgenden Authentifizierungsmethoden sind für Dataflowendpunkte des Kafka-Brokers verfügbar.
Systemseitig zugewiesene verwaltete Identität
Bevor Sie den Datenflussendpunkt konfigurieren, weisen Sie der verwalteten Identität von Azure IoT Einsatz eine Rolle mit der Berechtigung zum Verbinden mit dem Kafka-Broker zu.
- Wechseln Sie im Azure-Portal zu Ihrer Azure IoT Einsatz-Instanz, und wählen Sie Übersicht aus.
- Kopieren Sie den Namen der Erweiterung, die nach der Arc-Erweiterung für Azure IoT Einsatz aufgeführt ist. Beispiel: azure-iot-operations-xxxx7.
- Wechseln Sie zu der Cloudressource, die Sie benötigen, um Berechtigungen zu erteilen. Wechseln Sie beispielsweise zu „Event Hubs-Namespace“ >Zugriffssteuerung (IAM)>Rollenzuweisung hinzufügen.
- Wählen Sie auf der Registerkarte Rolle eine entsprechende Rolle aus.
- Wählen Sie auf der Registerkarte Mitglieder für Zugriff zuweisen zu die Option Benutzer, Gruppe oder Dienstprinzipal nud anschließend + Mitglieder auswählen aus. Suchen Sie dann nach der verwalteten Identität von Azure IoT Einsatz. Beispiel: azure-iot-operations-xxxx7.
Konfigurieren Sie dann den Datenflussendpunkt mit den Einstellungen der systemseitig zugewiesenen verwalteten Identität.
Wählen Sie auf der Seite „Einstellungen“ für den Dataflowendpunkt auf der Einsatz-Benutzeroberfläche die Registerkarte Allgemeine Informationen und dann Authentifizierungsmethode>Systemseitig zugewiesene verwaltete Identität aus.
Diese Konfiguration erstellt eine verwaltete Identität mit der Standardzielgruppe, die dem Hostwert des Event Hubs-Namespace in Form von https://<NAMESPACE>.servicebus.windows.net entspricht. Wenn Sie jedoch die Standardzielgruppe überschreiben müssen, können Sie das Feld audience auf den gewünschten Wert festlegen.
Wird auf der Einsatz-Benutzeroberfläche nicht unterstützt.
Benutzerseitig zugewiesene verwaltete Identität
Um eine benutzerseitig zugewiesene verwaltete Identität für die Authentifizierung zu verwenden, müssen Sie zuerst Azure IoT Einsatz mit aktivierten sicheren Einstellungen bereitstellen. Anschließend müssen Sie eine benutzerseitig zugewiesene verwaltete Identität für Cloudverbindungen einrichten. Weitere Informationen finden Sie unter Aktivieren sicherer Einstellungen in der Bereitstellung von Azure IoT Einsatz.
Bevor Sie den Datenflussendpunkt konfigurieren, weisen Sie der benutzerseitig zugewiesenen verwalteten Identität eine Rolle mit der Berechtigung zum Verbinden mit dem Kafka-Broker zu.
- Wechseln Sie im Azure-Portal zu der Cloudressource, die Sie benötigen, um Berechtigungen zu erteilen. Navigieren Sie beispielsweise im Event Grid-Namespace zu >Zugriffssteuerung (IAM)>Rollenzuweisung hinzufügen.
- Wählen Sie auf der Registerkarte Rolle eine geeignete Rolle aus.
- Wählen Sie auf der Registerkarte Mitglieder für Zugriff zuweisen zu die Option Verwaltete Identität und anschließend + Mitglieder auswählen aus. Suchen Sie dann nach Ihrer benutzerseitig zugewiesenen verwalteten Identität.
Konfigurieren Sie danach den Datenflussendpunkt mit den Einstellungen der benutzerseitig zugewiesenen verwalteten Identität.
Wählen Sie auf der Seite „Einstellungen“ für den Dataflowendpunkt auf der Einsatz-Benutzeroberfläche die Registerkarte Allgemeine Informationen und dann Authentifizierungsmethode>Benutzerseitig zugewiesene verwaltete Identität aus.
Hier ist der Umfang die Zielgruppe der verwalteten Identität. Der Standardwert ist mit dem Hostwert des Event Hubs-Namespaces in Form von https://<NAMESPACE>.servicebus.windows.net identisch. Wenn Sie jedoch die Standardzielgruppe außer Kraft setzen müssen, können Sie das Umfangsfeld mit Bicep oder Kubernetes auf den gewünschten Wert festlegen.
SASL
Um SASL für die Authentifizierung zu verwenden, geben Sie die SASL-Authentifizierungsmethode an, und konfigurieren Sie den SASL-Typ sowie einen Geheimnisverweis mit dem Namen des Geheimnisses, das das SASL-Token enthält.
Wählen Sie auf der Seite „Einstellungen“ für den Dataflowendpunkt auf der Einsatz-Benutzeroberfläche die Registerkarte Allgemeine Informationen und dann Authentifizierungsmethode>SASL aus.
Geben Sie die folgenden Einstellungen für den Endpunkt ein:
| Einstellung | Beschreibung |
|---|---|
| SASL-Typ | Der Typ der zu verwendenden SASL-Authentifizierung. Unterstützte Typen: Plain, ScramSha256 und ScramSha512. |
| Synchronisierter Geheimnisname | Der Name des Kubernetes-Geheimnisses, welches das SASL-Token enthält. |
| Benutzernamenverweis oder geheimer Tokenschlüssel | Der Verweis auf den Benutzernamen oder den geheimen Tokenschlüssels, der für die SASL-Authentifizierung verwendet wird. |
| Kennwortreferenz des geheimen Tokenschlüssels | Der Verweis auf das Kennwort oder den geheimen Tokenschlüssel, der für die SASL-Authentifizierung verwendet wird. |
Die unterstützten SASL-Typen sind:
PlainScramSha256ScramSha512
Das Geheimnis muss sich im selben Namespace wie der Kafka-Datenflussendpunkt befinden. Das Geheimnis muss das SASL-Token als Schlüssel-Wert-Paar aufweisen.
Anonym
Um die anonyme Authentifizierung zu verwenden, aktualisieren Sie den Authentifizierungsabschnitt der Kafka-Einstellungen, um die Methode „Anonym“ zu verwenden.
Wählen Sie auf der Seite „Einstellungen“ für den Dataflowendpunkt auf der Einsatz-Benutzeroberfläche die Registerkarte Allgemeine Informationen und dann Authentifizierungsmethode>Keine aus.
Erweiterte Einstellungen
Sie können erweiterte Einstellungen für den Kafka-Dataflowendpunkt festlegen wie TLS, vertrauenswürdiges Zertifizierungsstellenzertifikat, Kafka-Nachrichteneinstellungen, Batchverarbeitung und CloudEvents. Sie können diese Einstellungen auf der Portalregisterkarte Erweitert des Dataflowendpunkts oder in der Ressource des Dataflowendpunkts festlegen.
Wählen Sie auf der Einsatz-Benutzeroberfläche die Registerkarte Erweitert für den Dataflowendpunkt aus.
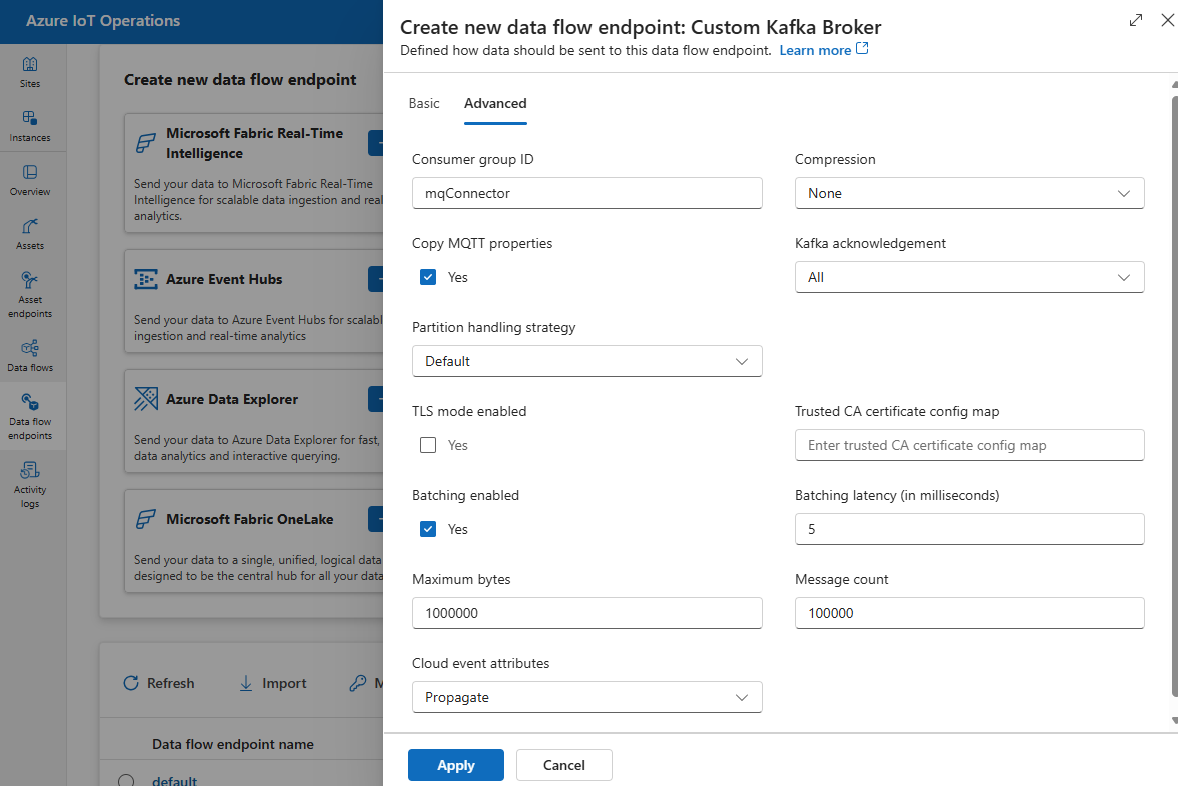
TLS-Einstellungen
TLS-Modus
Um TLS für den Kafka-Endpunkt zu aktivieren oder zu deaktivieren, aktualisieren Sie die Einstellung mode in den TLS-Einstellungen.
Wählen Sie auf der Seite „Einstellungen“ für den Dataflowendpunkt auf der Einsatz-Benutzeroberfläche die Registerkarte Erweitert aus, und verwenden Sie dann das Kontrollkästchen neben TLS-Modus aktiviert.
Der TLS-Modus kann auf Enabled oder Disabled festgelegt werden. Wenn der Modus auf Enabled festgelegt ist, verwendet der Dataflow eine sichere Verbindung zum Kafka-Broker. Wenn der Modus auf Disabled festgelegt ist, verwendet der Dataflow eine unsichere Verbindung mit dem Kafka-Broker.
Vertrauenswürdiges Zertifizierungsstellenzertifikat
Konfigurieren Sie das vertrauenswürdige Zertifizierungsstellenzertifikat für den Kafka-Endpunkt, um eine sichere Verbindung mit dem Kafka-Broker herzustellen. Diese Einstellung ist wichtig, wenn der Kafka-Broker ein selbstsigniertes Zertifikat oder ein Zertifikat verwendet, das von einer benutzerdefinierten Zertifizierungsstelle signiert ist, die standardmäßig nicht vertrauenswürdig ist.
Wählen Sie auf der Seite „Einstellungen“ für den Dataflowendpunkt auf der Einsatz-Benutzeroberfläche die Registerkarte Erweitert aus, und verwenden Sie dann das Feld ConfigMap für vertrauenswürdige Zertifizierungsstellenzertifikate, um die ConfigMap anzugeben, die das vertrauenswürdige Zertifizierungsstellenzertifikat enthält.
Diese ConfigMap sollte das Zertifizierungsstellenzertifikat im PEM-Format enthalten. Die ConfigMap muss sich im selben Namespace wie die Kafka-Dataflowressource befinden. Zum Beispiel:
kubectl create configmap client-ca-configmap --from-file root_ca.crt -n azure-iot-operations
Tipp
Beim Herstellen einer Verbindung mit Azure Event Hubs ist das Zertifizierungsstellenzertifikat nicht erforderlich, da der Event Hubs-Dienst ein Zertifikat verwendet, das von einer öffentlichen Zertifizierungsstelle signiert ist, die standardmäßig vertrauenswürdig ist.
Consumergruppen-ID
Die Consumergruppen-ID wird verwendet, um die Consumergruppe zu identifizieren, die der Dataflow zum Lesen von Nachrichten aus dem Kafka-Thema verwendet. Die Consumergruppen-ID muss innerhalb des Kafka-Brokers eindeutig sein.
Wichtig
Wenn der Kafka-Endpunkt als Quelle verwendet wird, ist die Consumergruppen-ID erforderlich. Andernfalls kann der Datenfluss keine Nachrichten aus dem Kafka-Thema lesen, und Sie erhalten den Fehler „Kafka-Typquellendpunkte müssen über eine definierte consumerGroupId verfügen“.
Wählen Sie auf der Seite „Einstellungen“ für den Dataflowendpunkt auf der Einsatz-Benutzeroberfläche die Registerkarte Erweitert aus, und geben Sie dann im Feld Consumergruppen-ID die Consumergruppen-ID an.
Diese Einstellung wird nur wirksam, wenn der Endpunkt als Quelle verwendet wird (d. h. der Dataflow ist ein Consumer).
Komprimierung
Das Komprimierungsfeld ermöglicht die Komprimierung für die Nachrichten, die an Kafka-Themen gesendet werden. Die Komprimierung trägt dazu bei, die für die Datenübertragung erforderliche Netzwerkbandbreite und den Speicherplatz zu reduzieren. Die Komprimierung fügt dem Prozess jedoch auch zusätzlichen Aufwand und Wartezeit hinzu. Die unterstützten Komprimierungstypen sind in der folgenden Tabelle aufgeführt.
| Wert | Beschreibung |
|---|---|
None |
Es wird keine Komprimierung oder Batchverarbeitung angewendet. „Keine“ ist der Standardwert, wenn keine Komprimierung angegeben wird. |
Gzip |
GZIP-Komprimierung und Batchverarbeitung werden angewendet. GZIP ist ein universeller Komprimierungsalgorithmus, der ein gutes Gleichgewicht zwischen Komprimierungsrate und Geschwindigkeit bietet. Derzeit wird nur GZIP-Komprimierung in Azure Event Hubs Premium- und Dedicated-Ebenen unterstützt. |
Snappy |
Snappy-Komprimierung und Batchverarbeitung werden angewendet. Snappy ist ein schneller Komprimierungsalgorithmus, der eine moderate Komprimierungsrate und Geschwindigkeit bietet. Dieser Komprimierungsmodus wird von Azure Event Hubs nicht unterstützt. |
Lz4 |
LZ4-Komprimierung und Batchverarbeitung werden angewendet. LZ4 ist ein schneller Komprimierungsalgorithmus, der eine niedrige Komprimierungsrate und hohe Geschwindigkeit bietet. Dieser Komprimierungsmodus wird von Azure Event Hubs nicht unterstützt. |
So konfigurieren Sie die Komprimierung
Wählen Sie auf der Seite „Einstellungen“ für den Dataflowendpunkt auf der Einsatz-Benutzeroberfläche die Registerkarte Erweitert aus, und geben Sie dann im Feld Komprimierung den Komprimierungstyp an.
Diese Einstellung wird nur wirksam, wenn der Endpunkt als Ziel verwendet wird, bei dem der Dataflow ein Producer ist.
Batchverarbeitung
Neben der Komprimierung können Sie auch die Batchverarbeitung für Nachrichten konfigurieren, bevor Sie sie an Kafka-Themen senden. Mit der Batchverarbeitung können Sie mehrere Nachrichten zusammen gruppieren und als einzelne Einheit komprimieren, wodurch die Komprimierungseffizienz verbessert und der Netzwerkaufwand reduziert werden kann.
| Feld | Beschreibung | Erforderlich |
|---|---|---|
mode |
Kann Enabled oder Disabled sein. Der Standardwert lautet Enabled, da es bei Kafka kein Messaging ohne Batch gibt. Wenn dies auf Disabled festgelegt ist, wird die Batchverarbeitung minimiert, um jedes Mal einen Batch mit einer einzelnen Nachricht zu erstellen. |
No |
latencyMs |
Das maximale Zeitintervall in Millisekunden, in dem Nachrichten vor dem Senden gepuffert werden können. Wenn dieses Intervall erreicht ist, werden alle gepufferten Nachrichten unabhängig davon, wie groß sie sind, als Batch gesendet. Wenn nicht festgelegt, ist der Standardwert 5. | No |
maxMessages |
Die maximale Anzahl von Nachrichten, die vor dem Senden gepuffert werden können. Wenn diese Anzahl erreicht ist, werden alle gepufferten Nachrichten als Batch gesendet – unabhängig davon, wie groß sie sind oder wie lange sie gepuffert werden. Wenn nicht festgelegt, ist der Standardwert 100.000. | No |
maxBytes |
Die maximale Größe in Bytes, die vor dem Senden gepuffert werden kann. Wenn diese Größe erreicht ist, werden alle gepufferten Nachrichten als Batch gesendet – unabhängig davon, wie viele es sind oder wie lange sie gepuffert werden. Der Standardwert ist 1.000.000 (1 MB). | No |
Wenn Sie „latencyMs“ beispielsweise auf 1.000, „maxMessages“ auf 100 und „maxBytes“ auf 1.024 festlegen, werden Nachrichten entweder gesendet werden, wenn sich 100 Nachrichten im Puffer oder wenn sich 1.024 Bytes im Puffer befinden oder wenn 1.000 Millisekunden seit dem letzten Senden verstrichen sind, je nachdem, was zuerst eintritt.
So konfigurieren Sie die Batchverarbeitung
Wählen Sie auf der Seite „Einstellungen“ für den Dataflowendpunkt auf der Einsatz-Benutzeroberfläche die Registerkarte Erweitert aus, und aktivieren Sie dann über das Feld Batchverarbeitung aktiviert die Batchverarbeitung. Geben Sie mithilfe der Felder Batchverarbeitungswartezeit, Maximale Anzahl Bytes und Nachrichtenanzahl die Batcheinstellungen an.
Diese Einstellung wird nur wirksam, wenn der Endpunkt als Ziel verwendet wird, bei dem der Dataflow ein Producer ist.
Partitionsbehandlungsstrategie
Die Strategie für die Partitionsverarbeitung steuert, wie Nachrichten an Kafka-Partitionen zugewiesen werden, wenn sie an Kafka-Themen gesendet werden. Kafka-Partitionen sind logische Segmente eines Kafka-Themas, die parallele Verarbeitung und Fehlertoleranz ermöglichen. Jede Nachricht in einem Kafka-Thema verfügt über eine Partition und einen Offset, welche zum Identifizieren und Sortieren der Nachrichten verwendet werden.
Diese Einstellung wird nur wirksam, wenn der Endpunkt als Ziel verwendet wird, bei dem der Dataflow ein Producer ist.
Ein Dataflow weist Nachrichten standardmäßig zufälligen Partitionen zu, wobei ein Roundrobin-Algorithmus verwendet wird. Sie können jedoch verschiedene Strategien verwenden, um Nachrichten auf der Grundlage bestimmter Kriterien, wie dem MQTT-Themennamen oder einer MQTT-Nachrichteneigenschaft, den Partitionen zuzuweisen. Dadurch können Sie einen besseren Lastausgleich, eine bessere Datenlokalisierung oder eine bessere Nachrichtenanordnung erreichen.
| Wert | Beschreibung |
|---|---|
Default |
Weist Nachrichten standardmäßig zufälligen Partitionen zu, wobei ein Roundrobin-Algorithmus verwendet wird. Dies ist der Standardwert, wenn keine Strategie angegeben ist. |
Static |
Weist Nachrichten einer festen Partitionsnummer zu, die von der Instanz-ID des Dataflow abgeleitet wird. Dies bedeutet, dass jede Dataflowinstanz Nachrichten an eine andere Partition sendet. Dies kann dazu beitragen, einen besseren Lastenausgleich und eine bessere Datenlokalität zu erzielen. |
Topic |
Verwendet den MQTT-Themennamen aus der Dataflowquelle als Schlüssel für die Partitionierung. Dies bedeutet, dass Nachrichten mit demselben MQTT-Themennamen an dieselbe Partition gesendet werden. Dies kann dazu beitragen, eine bessere Nachrichtenanordnung und Datenlokalität zu erzielen. |
Property |
Verwendet eine MQTT-Nachrichteneigenschaft aus der Dataflowquelle als Schlüssel für die Partitionierung. Geben Sie den Namen der Eigenschaft im Feld partitionKeyProperty an. Dies bedeutet, dass Nachrichten mit demselben Eigenschaftswert an dieselbe Partition gesendet werden. Dies kann dazu beitragen, basierend auf einem benutzerdefinierten Kriterium eine bessere Nachrichtenanordnung und Datenlokalität zu erzielen. |
Wenn Sie beispielsweise die Partitionsbehandlungsstrategie auf Property und die Partitionsschlüsseleigenschaft auf device-id festlegen, werden Nachrichten mit derselben device-id-Eigenschaft an dieselbe Partition gesendet.
So konfigurieren Sie die Partitionsbehandlungsstrategie
Wählen Sie auf der Seite „Einstellungen“ für den Dataflowendpunkt auf der Einsatz-Benutzeroberfläche die Registerkarte Erweitert aus, und geben Sie dann im Feld Partitionsbehandlungsstrategie die Partitionsbehandlungsstrategie an. Geben Sie im Feld Partitionsschlüsseleigenschaft die Eigenschaft an, die für die Partitionierung verwendet wird, wenn die Strategie auf Property festgelegt ist.
Kafka-Bestätigungen
Kafka-Bestätigungen (acknowledgements, acks) werden verwendet, um die Dauerhaftigkeit und Konsistenz von Nachrichten zu steuern, die an Kafka-Themen gesendet werden. Wenn ein Producer eine Nachricht an ein Kafka-Thema sendet, kann er verschiedene Bestätigungsstufen vom Kafka-Broker anfordern, um sicherzustellen, dass die Nachricht erfolgreich in das Thema geschrieben und über den Kafka-Cluster repliziert wird.
Diese Einstellung wird nur wirksam, wenn der Endpunkt als Ziel verwendet wird (d. h. der Dataflow ist ein Producer).
| Wert | Beschreibung |
|---|---|
None |
Der Dataflow wartet nicht auf Bestätigungen des Kafka-Brokers. Diese Einstellung ist die schnellste, aber am wenigsten dauerhafte Option. |
All |
Der Dataflow wartet darauf, dass die Nachricht in die Leaderpartition und alle Followerpartitionen geschrieben wird. Diese Einstellung ist die langsamste, aber dauerhafteste Option. Diese Einstellung ist auch die Standardoption. |
One |
Der Dataflow wartet darauf, dass die Nachricht in die Leaderpartition und mindestens eine Followerpartition geschrieben wird. |
Zero |
Der Dataflow wartet darauf, dass die Nachricht in die Leaderpartition geschrieben wird, wartet aber nicht auf Bestätigungen der Follower. Dies ist schneller als One aber weniger dauerhaft. |
Wenn Sie die Kafka-Bestätigung beispielsweise auf All festlegen, wartet der Datenfluss darauf, dass die Nachricht in die Leaderpartition und alle Followerpartitionen geschrieben wird, bevor die nächste Nachricht gesendet wird.
So konfigurieren Sie die Kafka-Bestätigungen
Wählen Sie auf der Einstellungsseite für die Benutzeroberfläche des Datenflussendpunkts die Registerkarte Erweitert aus, und geben Sie dann im Feld Kafka-Bestätigung die Kafka-Bestätigungsstufe an.
Diese Einstellung wird nur wirksam, wenn der Endpunkt als Ziel verwendet wird, bei dem der Datenfluss ein Producer ist.
MQTT-Eigenschaften kopieren
Standardmäßig ist die Einstellung „MQTT-Eigenschaften kopieren“ aktiviert. Diese Benutzereigenschaften enthalten Werte wie subject, der den Namen der Ressource speichert, die die Nachricht sendet.
Wählen Sie auf der Seite „Einstellungen“ für den Dataflowendpunkt auf der Einsatz-Benutzeroberfläche die Registerkarte Erweitert aus, und aktivieren bzw. deaktivieren Sie dann über das Kontrollkästchen MQTT-Eigenschaften kopieren das Kopieren von MQTT-Eigenschaften.
In den folgenden Abschnitten wird beschrieben, wie MQTT-Eigenschaften in Kafka-Benutzerheader übersetzt werden und umgekehrt, wenn die Einstellung aktiviert ist.
Kafka-Endpunkt ist ein Ziel
Wenn ein Kafka-Endpunkt ein Dataflowziel ist, werden alle definierten Eigenschaften der MQTT v5-Spezifikation in Kafka-Benutzerheader übersetzt. Beispielsweise wird eine MQTT v5-Nachricht mit „Inhaltstyp“, die an Kafka weitergeleitet wird, in den Kafka-Benutzerheader"Content Type":{specifiedValue} übersetzt. Ähnliche Regeln gelten für andere integrierte MQTT-Eigenschaften, die in der folgenden Tabelle definiert sind.
| MQTT-Eigenschaft | Übersetztes Verhalten |
|---|---|
| Payloadformatindikator | Schlüssel: „Payloadformatindikator“ Wert: „0“ (Payload ist Bytes) oder „1“ (Payload ist UTF-8) |
| Antwortthema | Schlüssel: „Antwortthema“ Wert: Kopie des Antwortthemas aus der ursprünglichen Nachricht. |
| Nachrichtenablaufintervall | Schlüssel: „Nachrichtenablaufintervall“ Wert: UTF-8-Darstellung der Anzahl von Sekunden, bevor die Nachricht abläuft. Weitere Details finden Sie unter Eigenschaft „Nachrichtenablaufintervall“. |
| Korrelationsdaten: | Schlüssel: „Korrelationsdaten“ Wert: Kopie der Korrelationsdaten aus der ursprünglichen Nachricht. Im Gegensatz zu vielen MQTT v5-Eigenschaften, die UTF-8 codiert sind, können Korrelationsdaten beliebige Daten sein. |
| Inhaltstyp: | Schlüssel: „Inhaltstyp“ Wert: Kopie des Inhaltstyps aus der ursprünglichen Nachricht. |
Schlüssel-Wert-Paare der MQTT v5-Benutzereigenschaft werden direkt in Kafka-Benutzerheader übersetzt. Wenn ein Benutzerheader in einer Nachricht denselben Namen wie eine integrierte MQTT-Eigenschaft hat (z. B. ein Benutzerheader mit dem Namen „Korrelationsdaten“), dann ist nicht definiert, ob der Eigenschaftswert der MQTT v5-Spezifikation oder die Benutzereigenschaft weitergeleitet wird.
Dataflows empfangen diese Eigenschaften nie von einem MQTT-Broker. Somit leitet ein Dataflow diese niemals weiter:
- Themenalias
- Abonnement-IDs
Die Eigenschaft „Nachrichtenablaufintervall“
Das Nachrichtenablaufintervall gibt an, wie lange eine Nachricht in einem MQTT-Broker verbleiben kann, bevor sie verworfen wird.
Wenn ein Dataflow eine MQTT-Nachricht mit dem angegebenen Nachrichtenablaufintervall empfängt, geschieht Folgendes:
- Zeichnet die Uhrzeit auf, zu der die Nachricht empfangen wurde.
- Bevor die Nachricht an den Empfänger gesendet wird, wird die Zeit, welche die Nachricht in der Warteschlange verbracht hat, von der ursprünglichen Ablaufintervallzeit subtrahiert.
- Wenn die Nachricht noch nicht abgelaufen ist (der obige Vorgang ist > 0), dann wird die Nachricht an das Ziel ausgegeben und enthält die aktualisierte Nachrichtenablaufzeit.
- Wenn die Nachricht abgelaufen ist (der obige Vorgang ist <= 0), wird die Nachricht vom Ziel nicht ausgegeben.
Beispiele:
- Ein Dataflow empfängt eine MQTT-Nachricht mit dem Nachrichtenablaufintervall = 3600 Sekunden. Das entsprechende Ziel wird vorübergehend getrennt, kann aber erneut eine Verbindung herstellen. 1000 Sekunden vergehen, bevor diese MQTT-Nachricht an das Ziel gesendet wird. In diesem Fall ist für die Nachricht des Ziels das Nachrichtenablaufintervall auf 2600 (3600 - 1000) Sekunden festgelegt.
- Der Dataflow empfängt eine MQTT-Nachricht mit dem Nachrichtenablaufintervall = 3600 Sekunden. Das entsprechende Ziel wird vorübergehend getrennt, kann aber erneut eine Verbindung herstellen. In diesem Fall dauert es jedoch 4000 Sekunden, um die Verbindung wiederherzustellen. Die Nachricht ist abgelaufen, und der Dataflow leitet diese Nachricht nicht an das Ziel weiter.
Kafka-Endpunkt ist eine Datenquelle
Hinweis
Es gibt ein bekanntes Problem bei der Verwendung eines Event Hubs-Endpunkts als Datenquelle, bei dem der Kafka-Header bei der Übersetzung in MQTT beschädigt wird. Dies geschieht nur, wenn Event Hub über den Event Hub-Client verwendet wird, der AMQP im Versteckten verwendet. Wenn beispielsweise „foo“=“bar“, dann wird „foo“ übersetzt, aber der Wert wird „\xa1\x03bar“.
Wenn ein Kafka-Endpunkt eine Dataflowquelle ist, werden Kafka-Benutzerheader in MQTT v5-Eigenschaften übersetzt. Die folgenden Tabelle beschreibt, wie Kafka-Benutzerheader in MQTT v5-Eigenschaften übersetzt werden.
| Kafka-Header | Übersetztes Verhalten |
|---|---|
| Schlüssel | Schlüssel: „Schlüssel“ Wert: Kopie des Schlüssels aus der ursprünglichen Nachricht. |
| Timestamp | Schlüssel: „Zeitstempel“ Wert: UTF-8-Codierung des Kafka-Zeitstempels, was der Anzahl von Millisekunden seit Unix-Epoche entspricht. |
Schlüssel-Wert-Paare des Kafka-Benutzerheaders – vorausgesetzt, sie sind alle in UTF-8 codiert – werden direkt in die Eigenschaften MQTT-Benutzerschlüssel/Wert übersetzt.
UTF-8 / Binäre Konflikte
MQTT v5 kann nur UTF-8-basierte Eigenschaften unterstützen. Wenn der Dataflow eine Kafka-Nachricht empfängt, die einen oder mehrere Nicht-UTF-8-Header enthält, wird der Dataflow Folgendes tun:
- Entfernt die beanstandete Eigenschaft oder die beanstandeten Eigenschaften.
- Leitet den Rest der Nachricht weiter, und folgt den vorherigen Regeln.
Anwendungen, die eine binäre Übertragung in Kafka-Quellheader => MQTT-Zieleigenschaften benötigen, müssen diese zuerst UTF-8 codieren – z. B. über Base64.
>=64KB-Eigenschaftskonflikte
MQTT v5-Eigenschaften müssen kleiner als 64 KB sein. Wenn der Dataflow eine Kafka-Nachricht empfängt, die einen oder mehrere Header enthält, die >= 64KB sind, wird der Dataflow Folgendes tun:
- Entfernt die beanstandete Eigenschaft oder die beanstandeten Eigenschaften.
- Leitet den Rest der Nachricht weiter, und folgt den vorherigen Regeln.
Eigenschaftsübersetzung bei Verwendung von Event Hubs und Producern, die AMQP verwenden
Wenn Sie über eine Client verfügen, der Nachrichten an einen Kafka-Dataflowquellendpunkt weiterleitet, der eine der folgenden Aktionen ausführt:
- Senden von Nachrichten an Event Hubs mithilfe von Clientbibliotheken wie Azure.Messaging.EventHubs
- Direktes Verwenden von AMQP
Es gibt Eigenschaftsübersetzungsnuancen, die Sie beachten müssen.
Sie sollten eine der folgenden Aktionen ausführen:
- Vermeiden Sie das Senden von Eigenschaften
- Wenn Sie Eigenschaften senden müssen, senden Sie Werte, die als UTF-8 codiert sind.
Wenn Event Hubs die Eigenschaften von AMQP in Kafka übersetzt, schließt es die zugrunde liegenden AMQP-codierten Typen in ihrer Nachricht ein. Weitere Informationen zum Verhalten finden Sie unter Austauschen von Ereignissen zwischen Consumern und Producern mit unterschiedlichen Protokollen.
Wenn der Dataflowendpunkt im folgenden Beispiel den Wert "foo":"bar" empfängt, empfängt er die Eigenschaft als <0xA1 0x03 "bar">.
using global::Azure.Messaging.EventHubs;
using global::Azure.Messaging.EventHubs.Producer;
var propertyEventBody = new BinaryData("payload");
var propertyEventData = new EventData(propertyEventBody)
{
Properties =
{
{"foo", "bar"},
}
};
var propertyEventAdded = eventBatch.TryAdd(propertyEventData);
await producerClient.SendAsync(eventBatch);
Der Dataflowendpunkt kann die Payloadeigenschaft <0xA1 0x03 "bar"> nicht an eine MQTT-Nachricht weiterleiten, da die Daten nicht UTF-8 sind. Wenn Sie jedoch eine UTF-8-Zeichenfolge angeben, übersetzt der Dataflowendpunkt die Zeichenfolge vor dem Senden an MQTT. Wenn Sie eine UTF-8-Zeichenfolge verwenden, hätte die MQTT-Nachricht "foo":"bar" als Benutzereigenschaften.
Es werden nur UTF-8-Header übersetzt. Beispiel: In dem folgenden Szenario ist die Eigenschaft als Gleitkomma festgelegt wird:
Properties =
{
{"float-value", 11.9 },
}
Der Dataflowendpunkt verwirft Pakete, die das Feld "float-value"enthalten.
Nicht alle Ereignisdateneigenschaften werden weitergeleitet, unter anderem propertyEventData.correlationId. Weitere Informationen finden Sie unter Ereignisbenutzereigenschaften,
CloudEvents
CloudEvents sind eine Möglichkeit, Ereignisdaten in einer allgemeinen Weise zu beschreiben. Die CloudEvents-Einstellungen werden verwendet, um Nachrichten im CloudEvents-Format zu senden oder zu empfangen. Sie können CloudEvents für ereignisgesteuerte Architekturen verwenden, bei denen unterschiedliche Dienste in demselben oder in unterschiedlichen Cloudanbieter miteinander kommunizieren müssen.
Die CloudEventAttributes-Optionen sind Propagate oder CreateOrRemap.
Wählen Sie auf der Seite „Einstellungen“ für den Dataflowendpunkt auf der Einsatz-Benutzeroberfläche die Registerkarte Erweitert aus, und geben Sie dann im Feld Cloudereignisattribute die CloudEvents-Einstellung an.
In den folgenden Abschnitten wird beschrieben, wie CloudEvent-Eigenschaften weitergegeben oder erstellt und neu zugeordnet werden.
Verteilungseinstellung
CloudEvent-Eigenschaften werden für Nachrichten übergeben, welche die erforderlichen Eigenschaften enthalten. Wenn die Nachricht die erforderlichen Eigenschaften nicht enthält, wird die Nachricht unverändert übergeben. Wenn die erforderlichen Eigenschaften vorhanden sind, wird dem Namen der CloudEvent-Eigenschaft ein Präfix ce_ hinzugefügt.
| Name | Erforderlich | Beispielwert | Ausgabename | Ausgabewert |
|---|---|---|---|---|
specversion |
Ja | 1.0 |
ce-specversion |
Unverändert übergeben |
type |
Ja | ms.aio.telemetry |
ce-type |
Unverändert übergeben |
source |
Ja | aio://mycluster/myoven |
ce-source |
Unverändert übergeben |
id |
Ja | A234-1234-1234 |
ce-id |
Unverändert übergeben |
subject |
No | aio/myoven/telemetry/temperature |
ce-subject |
Unverändert übergeben |
time |
No | 2018-04-05T17:31:00Z |
ce-time |
Unverändert übergeben. Es ist nicht neu gestempelt. |
datacontenttype |
No | application/json |
ce-datacontenttype |
Der Inhaltstyp der Ausgabedaten wurde nach der optionalen Transformationsphase geändert. |
dataschema |
No | sr://fabrikam-schemas/123123123234234234234234#1.0.0 |
ce-dataschema |
Wenn in der Transformationskonfiguration ein Transformationsschema für Ausgabedaten angegeben wird, wird dataschema in das Ausgabeschema geändert. |
CreateOrRemap-Einstellung
CloudEvent-Eigenschaften werden für Nachrichten übergeben, welche die erforderlichen Eigenschaften enthalten. Wenn die Nachricht die erforderlichen Eigenschaften nicht enthält, werden die Eigenschaften generiert.
| Name | Erforderlich | Ausgabename | Generierter Wert bei fehlendem Wert |
|---|---|---|---|
specversion |
Ja | ce-specversion |
1.0 |
type |
Ja | ce-type |
ms.aio-dataflow.telemetry |
source |
Ja | ce-source |
aio://<target-name> |
id |
Ja | ce-id |
Generierte UUID im Zielclient |
subject |
No | ce-subject |
Das Ausgabethema, zu dem die Nachricht gesendet wird |
time |
No | ce-time |
Generiert als RFC 3339 im Zielclient |
datacontenttype |
No | ce-datacontenttype |
Der Inhaltstyp der Ausgabedaten wurde nach der optionalen Transformationsphase geändert |
dataschema |
No | ce-dataschema |
Schema, das in der Schemaregistrierung definiert ist |
Nächste Schritte
Weitere Informationen zu Datenflüssen finden Sie unter Erstellen eines Datenflusses.