Konfigurieren von Dataflowendpunkten
Wichtig
Diese Seite enthält Anweisungen zum Verwalten der Komponenten von „Azure IoT Einsatz“ mithilfe von Kubernetes-Bereitstellungsmanifesten. Diese Option befindet sich in der Vorschau. Dieses Feature wird mit einigen Einschränkungen bereitgestellt und darf nicht für Produktionsworkloads verwendet werden.
Die zusätzlichen Nutzungsbestimmungen für Microsoft Azure-Vorschauen enthalten rechtliche Bedingungen. Sie gelten für diejenigen Azure-Features, die sich in der Beta- oder Vorschauversion befinden oder aber anderweitig noch nicht zur allgemeinen Verfügbarkeit freigegeben sind.
Um mit Datenflüssen zu beginnen, erstellen Sie zuerst Datenflussendpunkte. Ein Datenfluss ist der Verbindungspunkt für den Datenfluss. Sie können einen Endpunkt als Quelle oder Ziel für den Dataflow verwenden. Einige Endpunkttypen können als Quellen und Ziele verwendet werden, während andere nur für Ziele ausgelegt sind. Ein Dataflow benötigt mindestens einen Quell- und einen Zielendpunkt.
Verwenden Sie die folgende Tabelle, um den zu konfigurierenden Endpunkttyp auszuwählen:
| Endpunkttyp | Beschreibung | Kann als Quelle verwendet werden | Kann als Ziel verwendet werden |
|---|---|---|---|
| MQTT | Für bidirektionales Messaging mit MQTT-Brokern, einschließlich der integrierten, in Azure IoT Operations und Event Grid integrierten. | Ja | Ja |
| Kafka | Für bidirektionales Messaging mit Kafka-Brokern, einschließlich Azure Event Hubs. | Ja | Ja |
| Data Lake | Zum Hochladen von Daten in Azure Data Lake Gen2-Speicherkonten. | No | Ja |
| Microsoft Fabric OneLake | Zum Hochladen von Daten in Microsoft Fabric OneLake Lakehouses. | No | Ja |
| Azure Data Explorer | Zum Hochladen von Daten in Azure Data Explorer-Datenbanken. | No | Ja |
| Lokaler Speicher | Zum Senden von Daten an ein lokal verfügbares persistentes Volume, über das Sie Daten per Azure Container Storage hochladen können (ermöglicht durch Edgevolumes mit Azure Arc-Unterstützung). | No | Ja |
Wichtig
Speicherendpunkte erfordern ein Schema für die Serialisierung. Um den Datenfluss mit Microsoft Fabric OneLake, Azure Data Lake Storage, Azure Data Explorer oder Local Storage zu verwenden, müssen Sie einen Schemaverweis angeben.
Um das Schema aus einer Beispieldatendatei zu generieren, verwenden Sie das Schema Gen-Hilfsprogramm.
Dataflows müssen den lokalen MQTT-Broker-Endpunkt verwenden
Wenn Sie einen Datenfluss erstellen, geben Sie die Quell- und Zielendpunkte an. Der Datenfluss verschiebt Daten vom Quellendpunkt an den Zielendpunkt. Sie können denselben Endpunkt für mehrere Datenflüsse verwenden, und Sie können denselben Endpunkt wie die Quelle und das Ziel in einem Datenfluss verwenden.
Die Verwendung von benutzerdefinierten Endpunkten als Quelle und Ziel in einem Datenfluss wird jedoch nicht unterstützt. Diese Einschränkung bedeutet, dass der integrierte MQTT-Broker in Azure IoT Einsatz mindestens ein Endpunkt sein muss. Dies kann entweder die Quelle, das Ziel oder beides sein. Um Datenflussbereitstellungsfehler zu vermeiden, verwenden Sie den standardmäßigen MQTT-Datenflussendpunkt als Quelle oder Ziel für jeden Datenfluss.
Die spezifische Anforderung ist, dass jeder Datenfluss entweder die Quelle oder das Ziel mit einem MQTT-Endpunkt konfiguriert haben muss, der den Host aio-broker hat. Daher ist es nicht unbedingt erforderlich, den Standardendpunkt zu verwenden, und Sie können zusätzliche Datenflussendpunkte erstellen, die auf den lokalen MQTT-Broker verweisen, solange der Host aio-broker ist. Um Verwirrung und Verwaltbarkeitsprobleme zu vermeiden, ist der Standardendpunkt jedoch der empfohlene Ansatz.
Die folgende Tabelle zeigt unterstützte Szenarien:
| Szenario | Unterstützt |
|---|---|
| Standardendpunkt als Quelle | Ja |
| Standardendpunkt als Ziel | Ja |
| Benutzerdefinierter Endpunkt als Quelle | Ja, wenn das Ziel der Standardendpunkt oder ein MQTT-Endpunkt mit Host aio-broker ist |
| Benutzerdefinierter Endpunkt als Ziel | Ja, wenn das Ziel der Standardendpunkt oder ein MQTT-Endpunkt mit Host aio-broker ist |
| Benutzerdefinierter Endpunkt als Quelle und Ziel | Nein, es sei denn, einer von ihnen ist ein MQTT-Endpunkt mit Host aio-broker |
Wiederverwenden von Endpunkten
Stellen Sie sich jeden Datenfluss-Endpunkt als ein Bündel von Konfigurationseinstellungen vor, das enthält, von wo die Daten stammen sollen (der host Wert), wie Sie sich beim Endpunkt authentifizieren, und andere Einstellungen wie TLS-Konfiguration oder Batchverarbeitungseinstellung. Sie müssen sie also nur einmal erstellen und dann in mehreren Datenflüssen wiederverwenden, in denen diese Einstellungen identisch wären.
Um die Wiederverwendung von Endpunkten zu vereinfachen, ist der MQTT- oder Kafka-Themenfilter nicht Teil der Endpunktkonfiguration. Stattdessen geben Sie den Themenfilter in der Datenflusskonfiguration an. Dies bedeutet, dass Sie denselben Endpunkt für mehrere Datenflüsse verwenden können, die unterschiedliche Themenfilter verwenden.
Sie können z. B. den standardmäßigen MQTT-Broker-Datenflussendpunkt verwenden. Sie können es sowohl für die Quelle als auch für das Ziel mit unterschiedlichen Themenfiltern verwenden:
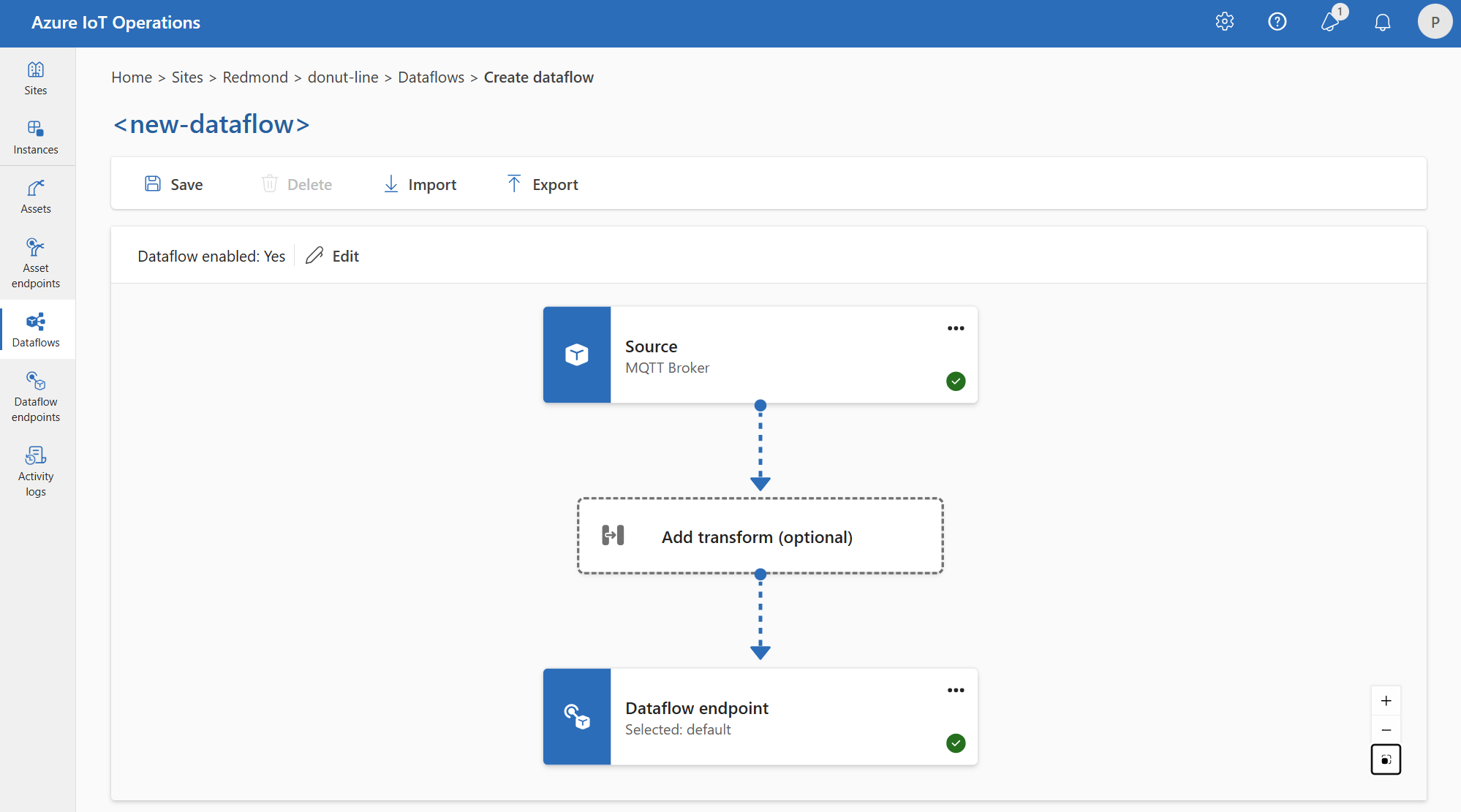
Ebenso können Sie mehrere Datenflüsse erstellen, die denselben MQTT-Endpunkt für andere Endpunkte und Themen verwenden. Sie können z. B. den gleichen MQTT-Endpunkt für einen Datenfluss verwenden, der Daten an einen Event Hubs-Endpunkt sendet.
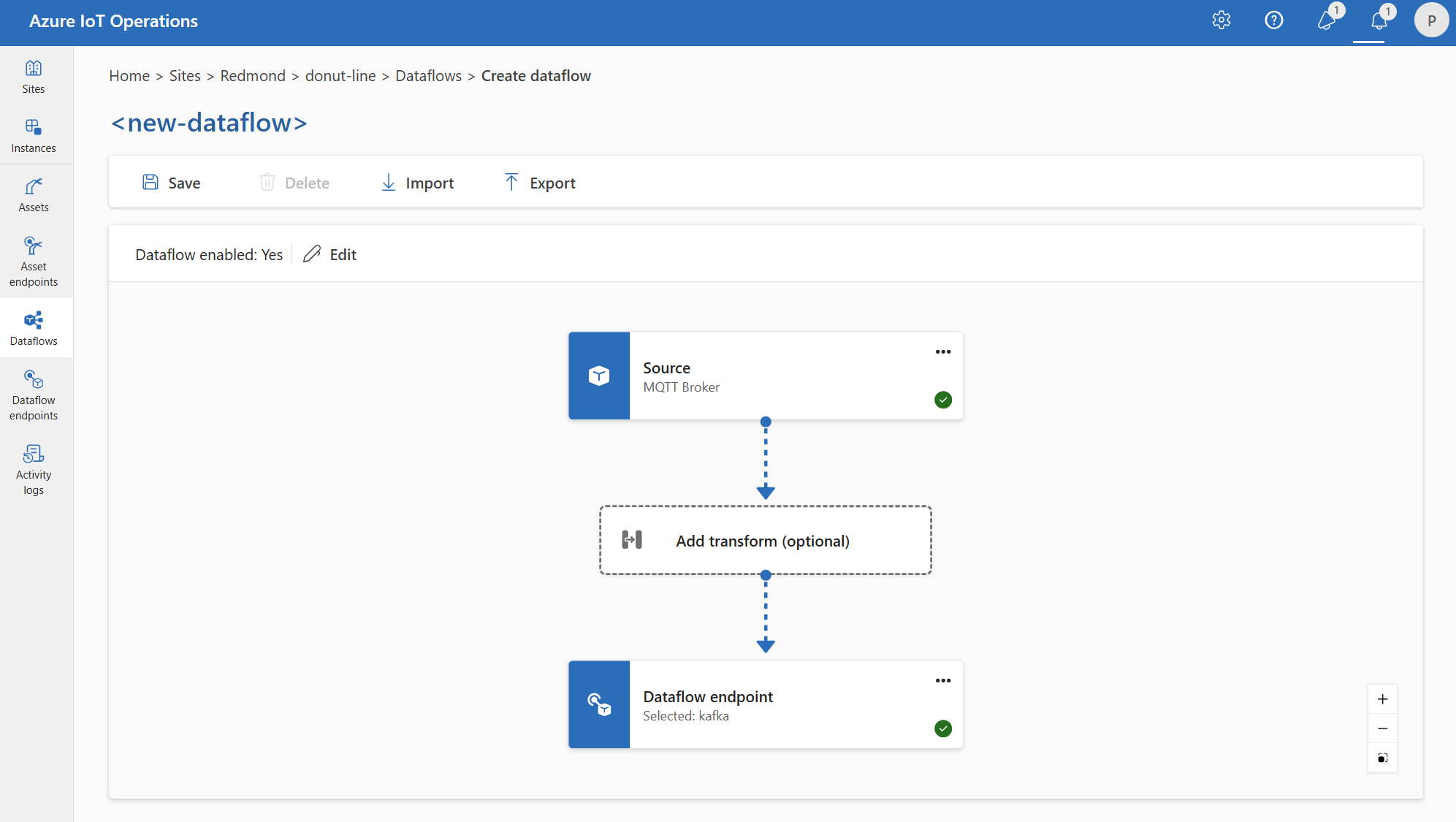
Ähnlich wie im MQTT-Beispiel können Sie mehrere Datenflüsse erstellen, die denselben Kafka-Endpunkt für verschiedene Themen oder denselben Data Lake-Endpunkt für verschiedene Tabellen verwenden.
Nächste Schritte
Erstellen eines Datenflussendpunkts: