Konfigurieren von Apache Spark-Einstellungen
Ein HDInsight Spark-Cluster enthält eine Installation der Apache Spark-Bibliothek. Jeder HDInsight-Cluster enthält Standardkonfigurationsparameter für alle installierten Dienste, einschließlich Spark. Ein wesentlicher Aspekt bei der Verwaltung eines HDInsight Apache Hadoop-Clusters ist die Überwachung der Workload, einschließlich Spark-Aufträge. Um Spark-Aufträge optimal auszuführen, sollte bei der Festlegung der logischen Konfiguration des Clusters dessen physische Konfiguration berücksichtigt werden.
Der HDInsight Apache Spark-Standardcluster umfasst die folgenden Knoten: drei Apache ZooKeeper-Knoten, zwei Hauptknoten und mindestens einen Workerknoten.
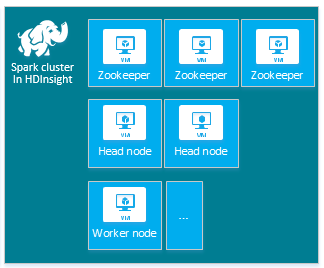
Die Anzahl der VMs und die VM-Größen für die Knoten in Ihrem HDInsight-Cluster können sich auf die Spark-Konfiguration auswirken. Nicht standardmäßige HDInsight-Konfigurationswerte machen häufig nicht standardmäßige Spark-Konfigurationswerte erforderlich. Wenn Sie einen HDInsight Spark-Cluster erstellen, werden für die einzelnen Komponenten jeweils empfohlene VM-Größen angezeigt. Derzeit sind die arbeitsspeicheroptimierten Größen virtueller Linux-Computer für Azure D12 v2 oder höher.
Apache Spark-Versionen
Verwenden Sie die am besten geeignete Spark-Version für Ihren Cluster. Der HDInsight-Dienst umfasst mehrere Versionen von Spark sowie auch von HDInsight. Jede Version von Spark umfasst einen Satz von Standardclustereinstellungen.
Beim Erstellen eines neuen Clusters können Sie zwischen verschiedenen Spark-Versionen wählen. Die vollständige Liste finden Sie unter HDInsight-Komponenten und -Versionen.
Hinweis
Die Standardversion von Apache Spark im HDInsight-Dienst kann ohne vorherige Ankündigung geändert werden. Wenn eine Versionsabhängigkeit vorliegt, empfiehlt Microsoft, die spezifische Version anzugeben, wenn Sie Cluster mit .NET SDK, Azure PowerShell und der klassischen Azure-Befehlszeilenschnittstelle erstellen.
Apache Spark verfügt über drei Speicherorte für die Systemkonfiguration:
- Spark-Eigenschaften steuern die meisten Anwendungsparameter und können durch Verwendung eines
SparkConf-Objekts oder über Java-Systemeigenschaften festgelegt werden. - Mithilfe von Umgebungsvariablen können über das Skript
conf/spark-env.shauf jedem Knoten Einstellungen pro Computer (z.B. die IP-Adresse) festgelegt werden. - Die Protokollierung kann über
log4j.propertieskonfiguriert werden.
Bei Auswahl einer bestimmten Version von Spark umfasst Ihr Cluster die entsprechenden Standardkonfigurationseinstellungen. Sie können die Spark-Standardkonfigurationswerte durch Angabe einer benutzerdefinierten Spark-Konfigurationsdatei ändern. Ein entsprechendes Beispiel ist nachfolgend dargestellt.
spark.hadoop.io.compression.codecs org.apache.hadoop.io.compress.GzipCodec
spark.hadoop.mapreduce.input.fileinputformat.split.minsize 1099511627776
spark.hadoop.parquet.block.size 1099511627776
spark.sql.files.maxPartitionBytes 1099511627776
spark.sql.files.openCostInBytes 1099511627776
In diesem Beispiel werden mehrere Standardwerte für fünf Spark-Konfigurationsparameter überschrieben. Bei diesen Werten handelt es sich um den Komprimierungscodec, die minimale Teilungsgröße für Apache Hadoop MapReduce und Parquet-Blockgrößen sowie die Standardwerte für die Größe der Spark SQL-Partition und geöffneter Dateien. Diese Konfigurationsänderungen werden ausgewählt, weil die zugehörigen Daten und Aufträge (in diesem Beispiel Genomdaten) bestimmte Merkmale aufweisen. Diese Merkmale funktionieren besser, wenn Sie diese benutzerdefinierten Konfigurationseinstellungen verwenden.
Anzeigen von Clusterkonfigurationseinstellungen
Überprüfen Sie die aktuellen HDInsight-Clusterkonfigurationseinstellungen, bevor Sie eine Leistungsoptimierung für den Cluster vornehmen. Starten Sie das HDInsight-Dashboard im Azure-Portal durch Klicken auf den Link Dashboard im Bereich für Spark-Cluster. Melden Sie sich mit dem Benutzernamen und dem Kennwort des Clusteradministrators an.
Die Apache Ambari-Webbenutzeroberfläche wird mit einem Dashboard mit den wichtigsten Metriken zur Ressourcennutzung des Clusters angezeigt. Im Ambari-Dashboard werden die Apache Spark-Konfiguration und andere installierte Dienste angezeigt. Das Dashboard enthält die Registerkarte Config History (Konfigurationsverlauf), auf der Sie Konfigurationsinformationen für installierten Dienste, darunter Spark, einsehen können.
Zum Anzeigen der Konfigurationswerte für Apache Spark wählen Sie Config History (Konfigurationsverlauf) und dann Spark2 aus. Wählen Sie die Registerkarte Configs (Konfigurationen) und dann in der Liste der Dienste den Link Spark (oder Spark2, abhängig von der verwendeten Version) aus. Eine Liste der Konfigurationswerte für Ihren Cluster wird angezeigt:
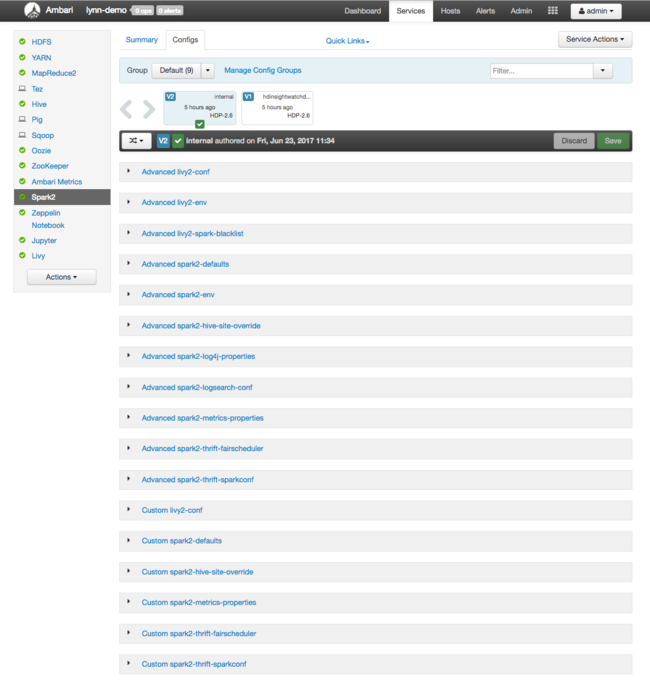
Zum Anzeigen und Ändern einzelner Spark-Konfigurationswerte wählen Sie einen beliebigen Link mit „spark“ im Titel aus. Konfigurationen für Spark umfassen sowohl benutzerdefinierte als auch erweiterte Konfigurationswerte in den folgenden Kategorien:
- Custom Spark2-defaults
- Custom Spark2-metrics-properties
- Advanced Spark2-defaults
- Advanced Spark2-env
- Advanced spark2-hive-site-override
Wenn Sie eine nicht standardmäßige Gruppe von Konfigurationswerten erstellen, ist Ihr Updateverlauf sichtbar. Dieser Konfigurationsverlauf kann sich als nützlich erweisen, wenn Sie überprüfen möchten, welche nicht standardmäßige Konfiguration eine optimale Leistung liefert.
Hinweis
Wenn Sie allgemeine Spark-Clusterkonfigurationseinstellungen anzeigen, jedoch nicht ändern möchten, wählen Sie die Registerkarte Environment (Umgebung) auf der Benutzeroberfläche der Spark-Aufträge der obersten Ebene aus.
Konfigurieren von Spark-Executors
In der folgenden Abbildung sind wichtige Spark-Objekte dargestellt: das Treiberprogramm und der zugeordnete Spark-Kontext sowie der Cluster-Manager und die zugehörigen n Workerknoten. Jeder Workerknoten enthält einen Executor, einen Cache und n Aufgabeninstanzen.
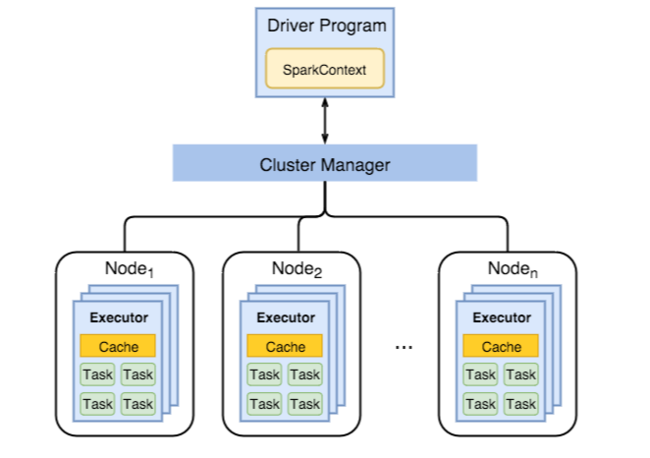
Spark-Aufträge verwenden Workerressourcen, insbesondere Arbeitsspeicher. Daher werden Spark-Konfigurationswerte für Executors von Workerknoten häufig angepasst.
Dabei werden die folgenden drei Schlüsselparameter zur Optimierung von Spark-Konfigurationen zur Verbesserung von Anwendungsanforderungen häufig angepasst: spark.executor.instances, spark.executor.cores und spark.executor.memory. Ein Executor ist ein Prozess, der für eine Spark-Anwendung gestartet wird. Ein Executor wird auf dem Workerknoten ausgeführt und ist für die Ausführung der Aufgaben für die Anwendung zuständig. Die Standardanzahl von Workerknoten und deren Größe für jeden Cluster bestimmen die Anzahl der Executors und deren Größe. Diese Werte werden in spark-defaults.conf auf den Hauptknoten des Clusters gespeichert. Sie können diese Werte in einem ausgeführten Cluster durch Auswählen von Custom spark-defaults auf der Ambari-Webbenutzeroberfläche bearbeiten. Nachdem Sie Änderungen vorgenommen haben, werden Sie aufgefordert, alle betroffenen Dienste neu zu starten (Restart).
Hinweis
Diese drei Konfigurationsparameter können auf Clusterebene (für alle Anwendungen, die im Cluster ausgeführt werden) konfiguriert und auch für jede einzelne Anwendung angegeben werden.
Die Spark-Anwendungsbenutzeroberfläche stellt eine weitere Informationsquelle zu den von Spark-Executors verwendeten Ressourcen dar. Auf der Benutzeroberfläche werden unter Executors Zusammenfassungs- und Detailansichten der Konfiguration und der beanspruchten Ressourcen gezeigt. Bestimmen Sie, ob die Executorwerte für den gesamten Cluster oder eine bestimmte Gruppe von Auftragsausführungen geändert werden sollen.
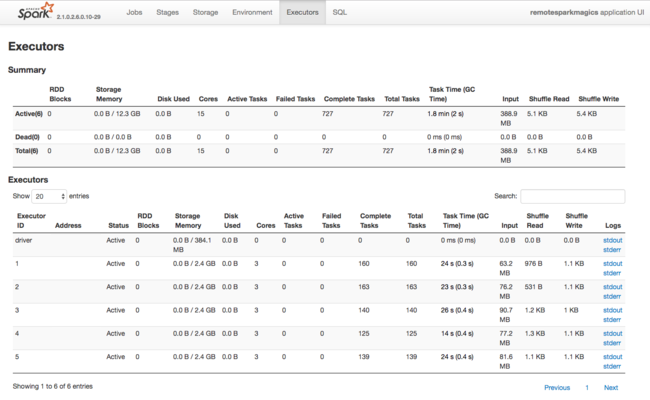
Sie können auch über die Ambari-REST-API die Konfigurationseinstellungen von HDInsight- und Spark-Clustern programmgesteuert ändern. Weitere Informationen stehen in der Apache Ambari-API-Referenz auf GitHub zur Verfügung.
Je nach Größe Ihrer Spark-Workload stellen Sie möglicherweise fest, dass Sie mit einer nicht standardmäßigen Spark-Konfiguration eine Optimierung der Spark-Auftragsausführung erzielen können. Führen Sie Benchmarktests mit Beispielworkloads durch, um verschiedene nicht standardmäßige Clusterkonfigurationen zu überprüfen. Folgende allgemeine Parameter können berücksichtigt werden:
| Parameter | BESCHREIBUNG |
|---|---|
| --num-executors | Legt die Anzahl von Executors fest. |
| --executor-cores | Legt die Anzahl von Kernen für jeden Executor fest. Es empfiehlt sich die Verwendung von Executors mittlerer Größe, da andere Prozesse auch einen Teil des verfügbaren Arbeitsspeicherplatzes nutzen. |
| --executor-memory | Steuert die Speichergröße (Heapgröße) der einzelnen Executors in Apache Hadoop YARN. Sie müssen etwas Arbeitsspeicher für den Ausführungsmehraufwand reservieren. |
Beispiel für zwei Workerknoten mit unterschiedlichen Konfigurationswerten:

In der folgenden Liste sind wichtige Arbeitsspeicherparameter für Spark-Executors aufgeführt.
| Parameter | BESCHREIBUNG |
|---|---|
| spark.executor.memory | Definiert die Gesamtmenge des verfügbaren Arbeitsspeichers für einen Executor. |
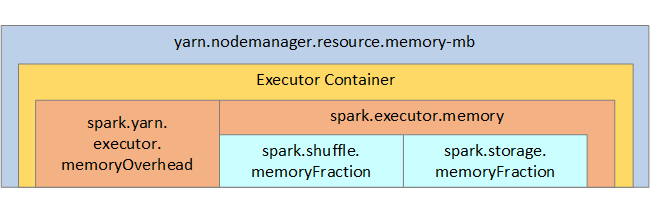
| spark.storage.memoryFraction | (standardmäßig ca. 60 %) definiert die Menge des verfügbaren Arbeitsspeichers zum Speichern von persistenten RDDs. |
| spark.shuffle.memoryFraction | (standardmäßig ca. 20 %) definiert die Größe des für Shuffle reservierten Arbeitsspeichers. |
| spark.storage.unrollFraction und spark.storage.safetyFraction | (insgesamt ca. 30 % des gesamten Arbeitsspeichers): Diese Werte werden in Spark intern verwendet und dürfen nicht geändert werden. |
YARN steuert den maximal von den Containern auf jedem Spark-Knoten verwendeten Gesamtarbeitsspeicher. In der folgenden Abbildung sind die Beziehungen pro Knoten zwischen YARN-Konfigurationsobjekten und Spark-Objekten dargestellt.
Ändern der Parameter für eine in Jupyter Notebook ausgeführte Anwendung
Spark-Cluster in HDInsight enthalten standardmäßig eine Reihe von Komponenten. Jede dieser Komponenten umfasst Standardkonfigurationswerte, die nach Bedarf überschrieben werden können.
| Komponente | BESCHREIBUNG |
|---|---|
| Spark Core | Spark Core, Spark SQL, Spark Streaming-APIs, GraphX und Apache Spark MLlib. |
| Anaconda | Ein Python-Paket-Manager. |
| Apache Livy | Die Apache Spark-REST-API, die zum Übermitteln von Remoteaufträgen an einen HDInsight Spark-Cluster verwendet wird. |
| Jupyter Notebooks und Apache Zeppelin-Notebooks | Interaktive browserbasierte Benutzeroberfläche zur Interaktion mit dem Spark-Cluster. |
| ODBC-Treiber | Verbindet Spark-Cluster in HDInsight mit BI-Tools (Business Intelligence), z. B. Microsoft Power BI und Tableau. |
Bei Anwendungen, die in Jupyter Notebook ausgeführt werden, können Sie mit dem Befehl %%configure Konfigurationsänderungen direkt im Notebook selbst vornehmen. Die Konfigurationsänderungen werden auf die Spark-Aufträge angewendet, die über Ihre Notebook-Instanz ausgeführt werden. Nehmen Sie diese Änderungen am Anfang der Anwendung vor, bevor Sie die erste Codezelle ausführen. Die geänderte Konfiguration wird auf die Livy-Sitzung angewendet, wenn sie erstellt wird.
Hinweis
Zum Ändern der Konfiguration zu einem späteren Zeitpunkt in der Anwendung verwenden Sie den Parameter -f (force). Dadurch geht jedoch der gesamte Fortschritt in der Anwendung verloren.
Der folgende Code zeigt, wie Sie die Konfiguration für eine in Jupyter Notebook ausgeführte Anwendung ändern.
%%configure
{"executorMemory": "3072M", "executorCores": 4, "numExecutors":10}
Zusammenfassung
Überwachen Sie die wesentlichen Konfigurationseinstellungen, um sicherzustellen, dass Ihre Spark-Aufträge vorhersehbar und effizient ausgeführt werden. Mit diesen Einstellungen kann die optimale Spark-Clusterkonfiguration für Ihre spezifischen Workloads festgelegt werden. Zudem müssen Sie die Ausführung von zeit- und/oder ressourcenintensiven Spark-Aufträgen überwachen. Die häufigsten Herausforderungen drehen sich um die hohe Arbeitsspeicherauslastung aufgrund falscher Konfigurationen, wie z. B. falsch dimensionierte Executors. Außerdem um Vorgänge mit langer Ausführungszeit und Aufgaben, die zu kartesischen Vorgängen führen.